使用IDEA+Maven实现MapReduced的WordCount
使用IDEA+Maven实现MapReduce
准备工作
- 在桌面创建文件
wordfile1.txt
I love Spark
I love Hadoop
- 在桌面创建文件
wordfile2.txt
Hadoop is good
Spark is fast
上传文件到Hadoop
# 启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
# 删除HDFS的hadoop对应的input和output目录,确保后面程序运行不会出现问题(如果有)
cd /usr/local/hadoop
./bin/hdfs dfs -rm -r input
./bin/hdfs dfs -rm -r output
# 新建input目录
./bin/hdfs dfs -mkdir input
# 上传本地文件系统中的文件
./bin/hdfs dfs -put ~/Desktop/wordfile1.txt input
./bin/hdfs dfs -put ~/Desktop/wordfile2.txt input
IDEA创建项目
创建Maven项目
我的项目名是MapReduce,可以自己修改。
IDEA自带Maven,如果需要自己安装Maven可以参考安装Maven
创建项目,选择Maven,模板可以选择第一个maven-archetype-archetype
创建java 文件(WordCount)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;public class WordCount2 {public WordCount2() {}public static void main(String[] args) throws Exception {// 创建一个Configuration对象,用于配置MapReduce作业Configuration conf = new Configuration();// 使用GenericOptionsParser解析命令行参数并判断String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();if(otherArgs.length < 2) {System.err.println("Usage: buycount <in> [<in>...] <out>");System.exit(2);}// 创建一个MapReduce作业实例,并设置作业名称。Job job = Job.getInstance(conf, "buy count");// 指定包含作业类的jar文件job.setJarByClass(WordCount2.class);// 设置Mapper类。job.setMapperClass(WordCount2.TokenizerMapper.class);// 设置Combiner类,Combiner是Map端的一个可选优化步骤,可以减少传输到Reduce端的数据量。job.setCombinerClass(WordCount2.IntSumReducer.class);// 设置Reducer类job.setReducerClass(WordCount2.IntSumReducer.class);// 设置作业输出键和值的类型。job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 为作业添加输入路径。FileInputFormat.addInputPath(job, new Path(otherArgs[0]));// 设置作业的输出路径。FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));// 等待作业完成,并根据作业是否成功来设置退出状态。System.exit(job.waitForCompletion(true)?0:1);}/**定义了一个名为TokenizerMapper的Mapper类,* 它继承自Hadoop的Mapper类,* 并指定了输入键、输入值、输出键和输出值的类型。* 计算每个单词的个数* */public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {// one用于在map方法中输出计数为1private static final IntWritable one = new IntWritable(1);// word用于存储当前处理的单词。private Text word = new Text();public TokenizerMapper() {}// 接收输入键值对和上下文对象,public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {// 使用StringTokenizer分割输入文本行,并为每个单词输出一个键值对(单词,1)。StringTokenizer itr = new StringTokenizer(value.toString());while(itr.hasMoreTokens()) {this.word.set(itr.nextToken());context.write(this.word, one);}}}/** 定义了一个名为IntSumReducer的Reducer类,* 它继承自Hadoop的Reducer类,* 并指定了输入键、输入值、输出键和输出值的类型。* */public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {// 存储单词的总计数private IntWritable result = new IntWritable();public IntSumReducer() {}// reduce方法,它接收输入键、值的集合和上下文对象public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {// 遍历值的集合,计算单词的总计数。int sum = 0;IntWritable val;for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {val = (IntWritable)i$.next();}// 设置结果并输出。this.result.set(sum);context.write(key, this.result);}}
}
添加依赖(pom.xml)
记得修改自己的hadoop的版本和Java_Home的路径
打包时记得修改main方法的位置
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.6.0</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><!-- main()所在的类,注意修改 --><mainClass>WordCount</mainClass></transformer></transformers></configuration></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>7</source><target>7</target></configuration></plugin></plugins></build><!-- 环境配置 --><properties><hadoop.version>3.3.5</hadoop.version><JAVA_HOME>C:\lang\Java\jdk1.8.0_151</JAVA_HOME></properties><dependencies><!-- 打包工具 --><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency><!-- Hadoop --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency></dependencies>
设置完成后重新加载Maven

Maven 打包
在IDEA的终端运行以下代码
mvn clean package
打包完成后可以查看target文件夹中是否有MapReduce-2.0-SNAPSHOT.jar


打包过程可能存在的报错
No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK?
没有配置Java_Home,在系统环境变量中配置Java_Home
在虚拟机运行jar包
- 复制jar包(
MapReduce-2.0-SNAPSHOT.jar)到虚拟机的桌面或其他位置 - 在终端运行以下代码
cd /usr/local/hadoop
# jar包位置需要根据自己的位置修改
./bin/hadoop jar ~/Desktop/MapReduce-2.0-SNAPSHOT.jar input output
上面命令执行以后,当运行顺利结束时,屏幕上会显示类似如下的信息:
... //这里省略若干屏幕信息
2023-06-17 02:50:31,862 INFO mapred.LocalJobRunner: reduce task executor complete.
2023-06-17 02:50:32,532 INFO mapreduce.Job: map 100% reduce 100%
2023-06-17 02:50:32,533 INFO mapreduce.Job: Job job_local51129470_0001 completed successfully
2023-06-17 02:50:32,578 INFO mapreduce.Job: Counters: 36
... //这里省略若干屏幕信息

词频统计结果已经被写入了HDFS的“/user/hadoop/output”目录中,可以执行如下命令查看词频统计结果:
cd /usr/local/hadoop
./bin/hdfs dfs -cat output/*
如果要再次运行,需要首先删除HDFS中的output目录,否则会报错。

题目二
题目:
假设你有一个包含用户购买记录的文本文件,每行记录包含用户ID、商品ID和购买数量,格式如“user1,item1,2”。请编写一个MapReduce程序来处理这个文件,统计每个用户购买商品的总数量,并输出每个用户及其购买的总商品数。下面是一个示例
用户购买记录的文本文件
user1,item1,2
user1,item2,3
user2,item1,1
user3,item3,4
user1,item3,1
user2,item2,2
输出
user1 6 user2 3 user3 4
要求:
- 使用Java或Python等支持MapReduce的编程语言编写。
- 详细描述Map函数和Reduce函数的实现逻辑。
给出运行程序所需的输入文件示例和预期输出结果。
实现
- 在虚拟机桌面创建文件(
buy_count.txt)添加内容并上传文件到Hadoop
# 启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
# 删除HDFS的hadoop对应的input和output目录,确保后面程序运行不会出现问题
cd /usr/local/hadoop
./bin/hdfs dfs -rm -r input
./bin/hdfs dfs -rm -r output
# 新建input目录
./bin/hdfs dfs -mkdir input
# 上传本地文件系统中的文件
./bin/hdfs dfs -put ~/Desktop/buy_count.txt input
- 创建
Java文件(BuyCount)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;import java.io.IOException;
import java.util.Iterator;public class BuyCount {public BuyCount() {}public static void main(String[] args) throws Exception {// 创建一个Configuration对象,用于配置MapReduce作业Configuration conf = new Configuration();// 使用GenericOptionsParser解析命令行参数并判断String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();if(otherArgs.length < 2) {System.err.println("Usage: buycount <in> [<in>...] <out>");System.exit(2);}// 创建一个MapReduce作业实例,并设置作业名称。Job job = Job.getInstance(conf, "buy count");// 指定包含作业类的jar文件job.setJarByClass(BuyCount.class);// 设置Mapper类。job.setMapperClass(BuyCount.TokenizerMapper.class);// 设置Combiner类,Combiner是Map端的一个可选优化步骤,可以减少传输到Reduce端的数据量。job.setCombinerClass(BuyCount.IntSumReducer.class);// 设置Reducer类job.setReducerClass(BuyCount.IntSumReducer.class);// 设置作业输出键和值的类型。job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 为作业添加输入路径。FileInputFormat.addInputPath(job, new Path(otherArgs[0]));// 设置作业的输出路径。FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));// 等待作业完成,并根据作业是否成功来设置退出状态。System.exit(job.waitForCompletion(true)?0:1);}/**定义了一个名为TokenizerMapper的Mapper类,* 它继承自Hadoop的Mapper类,* 并指定了输入键、输入值、输出键和输出值的类型。* 计算每个单词的个数* */public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {// one用于在map方法中输出计数为1private static final IntWritable one = new IntWritable(1);// word用于存储当前处理的单词。private Text word = new Text();public TokenizerMapper() {}// 接收输入键值对和上下文对象,// 会得到每一行public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {String[] strs = value.toString().split(",");this.word.set(strs[0]);int num = Integer.parseInt(strs[2]);context.write(this.word, new IntWritable(num));}}/** 定义了一个名为IntSumReducer的Reducer类,* 它继承自Hadoop的Reducer类,* 并指定了输入键、输入值、输出键和输出值的类型。* */public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {// 存储单词的总计数private IntWritable result = new IntWritable();public IntSumReducer() {}// reduce方法,它接收输入键、值的集合和上下文对象// 将相同的结果进行相加public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {// 遍历值的集合,计算单词的总计数。int sum = 0;IntWritable val;for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {val = (IntWritable)i$.next();}// 设置结果并输出。this.result.set(sum);context.write(key, this.result);}}
}
- 修改
pom.xml中的mainClass

- 在虚拟机运行jar包
cd /usr/local/hadoop
# 删除output目录
./bin/hdfs dfs -rm -r output
# jar包位置需要根据自己的位置修改
./bin/hadoop jar ~/Desktop/MapReduce-2.0-SNAPSHOT.jar input output
# 查看统计结果
./bin/hdfs dfs -cat output/*

我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=156a5nk5kjl84
相关文章:
使用IDEA+Maven实现MapReduced的WordCount
使用IDEAMaven实现MapReduce 准备工作 在桌面创建文件wordfile1.txt I love Spark I love Hadoop在桌面创建文件wordfile2.txt Hadoop is good Spark is fast上传文件到Hadoop # 启动Hadoop cd /usr/local/hadoop ./sbin/start-dfs.sh # 删除HDFS的hadoop对应的input和out…...

go语言示例代码
go语言示例代码, package mainimport "fmt" import "encoding/json"func main() {list : []int{11, 12, 13, 14, 15}for i,x : range list {fmt.Println("i ", i, ",x ", x)}fmt.Println("")for i : range l…...

华为云容器监控平台
首先搜索CCE,点击云容器引擎CCE 有不同的测试,生产,正式环境 工作负载--直接查询服务名看监控 数据库都是走的一个 Redis的查看...

阿里短信发送报错 InvalidTimeStamp.Expired
背景 给客户做的人力资源系统,今天客户用阿里云短信,结果报错: nvalidTimeStamp.Expired Specified time stamp or date value is expired. HTTP Status: 400 RequestID: A 怎么办呢?搜资料, 是客户端时间ÿ…...

Ubuntu问题 -- 设置ubuntu的IP为静态IP (图形化界面设置) 小白友好
目的 为了将ubuntu服务器IP固定, 方便ssh连接人在服务器前使用图形化界面设置 设置 找到自己的网卡名称, 我的是 eno1, 并进入设置界面 查看当前的IP, 网关, 掩码和DNS (注意对应eno1) nmcli dev show掩码可以通过以下命令查看完整的 (注意对应eno1) , 我这里是255.255.255.…...

Sigrity SPEED2000 TDR TDT Simulation模式如何进行时域阻抗仿真分析操作指导-差分信号
Sigrity SPEED2000 TDR TDT Simulation模式如何进行时域阻抗仿真分析操作指导-差分信号 Sigrity SPEED2000 TDR TDT Simulation模式如何进行时域阻抗仿真分析操作指导-单端信号详细介绍了单端信号如何进行TDR仿真分析,下面介绍如何对差分信号进行TDR分析,还是以下图为例进行分…...

Cesium 加载B3DM模型
一、引入Cesium,可以使用该链接下载cesium 链接: https://pan.baidu.com/s/1BRQyaFCkxO2xQQT5RzFUCw?pwdkcv9 提取码: kcv9 在index.html文件中引入cesium <script type"text/javascript" src"/Cesium/Cesium.js"></script> …...
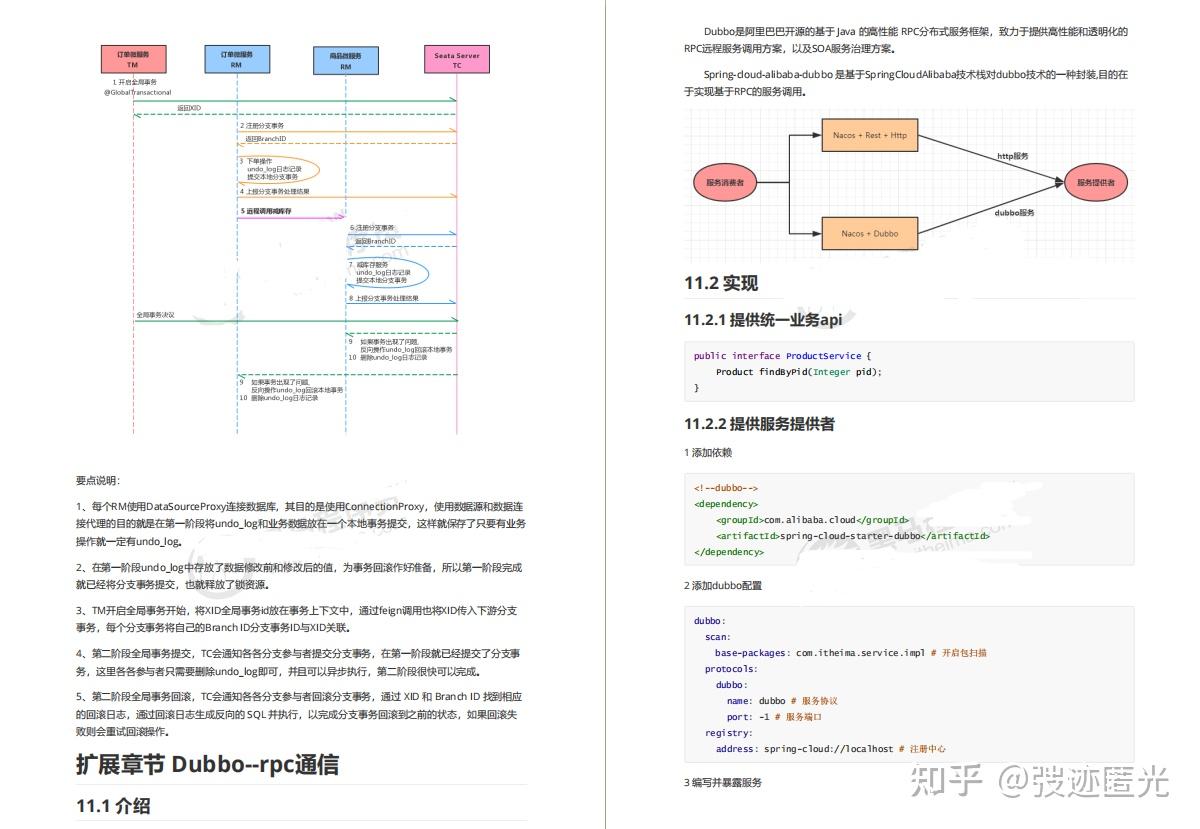
阿里巴巴官方「SpringCloudAlibaba全彩学习手册」限时开源!
最近我在知乎上看过的一个热门回答: 初级 Java 开发面临的最大瓶颈在于,脱离不出自身业务带来的局限。日常工作中大部分时间在增删改查、写写接口、改改 bug,久而久之就会发现,自己的技术水平跟刚工作时相比没什么进步。 所以我们…...

Docker是一个容器化平台注意事项
Docker本身是一个容器化平台,它允许你将应用及其依赖打包到一个可移植的容器中,然后可以在任何安装了Docker的机器上运行这个容器。Docker容器是跨平台的,但有一些限制和注意事项: 跨架构不可行 操作系统兼容性:Docke…...

Redis中的zset用法详解
文章目录 Redis中的zset用法详解一、引言二、zset的基本概念和操作1、zset的添加和删除1.1、添加元素1.2、删除元素 2、zset的查询2.1、获取元素分数2.2、获取元素排名 3、zset的范围查询3.1、按排名查询3.2、按分数查询 三、zset的应用场景1、排行榜1.1、添加玩家得分1.2、获取…...

上位机编程命名规范
1.大小写规范 文件名全部小写是一种广泛使用的命名约定,特别是在跨平台开发和开源项目中。主要原因涉及技术约束、可读性和一致性等方面。以下是原因和优劣势的详细分析: 1. 避免跨平台问题 不同操作系统对文件名的大小写处理方式不同: Li…...

Python 操作mysql - 关系型数据库存储
Python 操作mysql - 关系型数据库存储 文章目录 Python 操作mysql - 关系型数据库存储简单介绍连接数据库创建表插入数据更新数据删除数据查询数据 简单介绍 关系型数据库是一种以“关系”的方式来组织和存储数据的数据库。它使用表(也称为“关系”)来表…...

React基础知识一
写的东西太多了,照成csdn文档编辑器都开始卡顿了,所以分篇写。 1.安装React 需要安装下面三个包。 react:react核心包 react-dom:渲染需要用到的核心包 babel:将jsx语法转换成React代码的工具。(没使用jsx可以不装)1.1 在html中…...
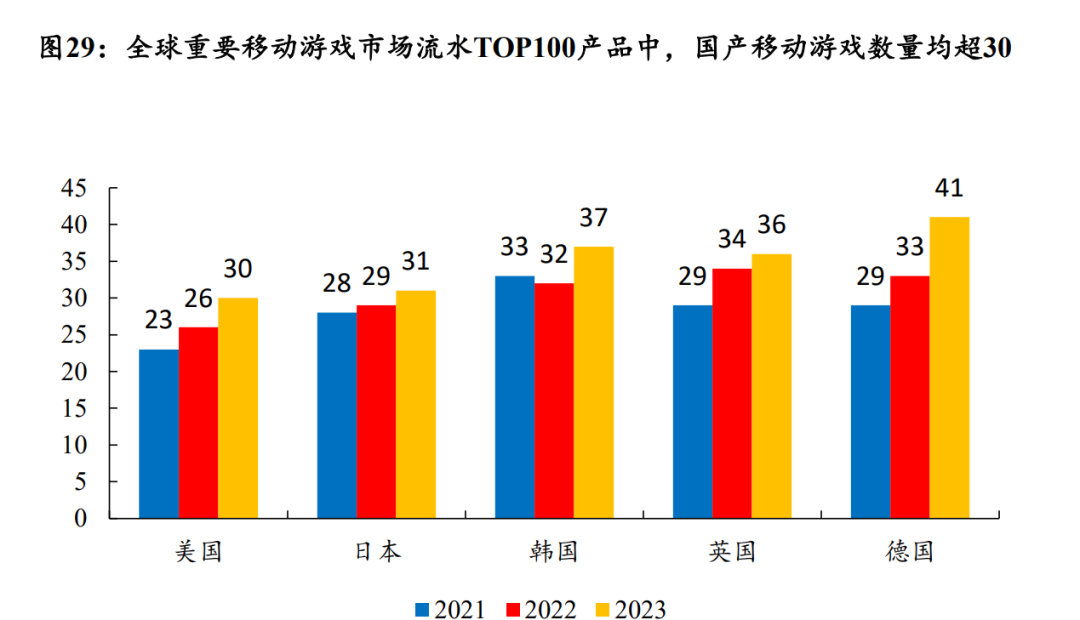
游戏行业趋势:“AI、出海、IP”大热下,如何提升竞争力?
游戏:新品供给影响业绩释放节奏,后续游戏新品逐步上线,或驱动板块业绩修复 2024年前三季度A股游戏板块实现营业收入681.8亿元,同比增长5.1%,实现归母净利润73.3亿元,同比下滑30.4%,或主要受 20…...

shell--第一次作业
1.接收用户部署的服务名称 # 脚本入口 read -p "请输入要部署的服务名称:" service_name 2.判断服务是否安装 # 判断服务是否安装 if rpm -q "$service_name" &>/dev/null; then echo "服务 $service_name 已安装。" 已…...

Rust:原子操作 AtomicBool
在 Rust 中,你可以使用 std::sync::atomic 模块来进行原子操作。原子操作在多线程环境中特别有用,因为它们可以确保操作的原子性和可见性,从而避免数据竞争和其他并发问题。 为了读取和设置布尔值,你可以使用 AtomicBool 类型。以…...

深入浅出学算法002-n个1
任务内容 Description 由n个1组成的整数能被K(K<10000)整除,n至少为多少? Input 多组测试数据,第一行输入整数T,表示组数 然后是T行,每行输入1个整 数代表K Output 对于每组测试数据输出1行,值为n Sampl…...

GPT1.0 和 GPT2.0 的联系与区别
随着自然语言处理技术的飞速发展,OpenAI 提出的 GPT 系列模型成为了生成式预训练模型的代表。作为 GPT 系列的两代代表,GPT-1 和 GPT-2 虽然在架构上有着继承关系,但在设计理念和性能上有显著的改进。本文将从模型架构、参数规模、训练数据和…...
STM32F103 GPIO和串口实战
本节我们将会对STM32F103的硬件资源GPIO和串口进行介绍。 一、GPIO 1.1 电路原理图 LED电路原理图如下图所示: 其中: LED1连接到PA8引脚,低电平点亮;LED2连接到PD2引脚,低电平点亮; 1.2 GPIO引脚介绍 STM32…...

Go 并发
Go 并发 Go 语言,自2009年发布以来,以其独特的并发模型和简洁的语法在编程界崭露头角。Go 语言的并发机制是其最大的亮点之一,它通过轻量级的线程——goroutine,以及通道(channel)和同步原语,为开发者提供了一种高效、易用的并发编程方式。 Goroutine:Go 语言的并发基…...

Karpathy投奔Anthropic:一个顶级AI天才的四次人生豪赌
5月19日,一条推文炸了整个AI圈。 Andrej Karpathy——OpenAI联合创始人、前特斯拉AI总监、AI教育布道师——宣布加入Anthropic。 英伟达具身智能负责人Jim Fan评论说:"这比Google I/O的Keynote更重磅。" 网友打了个比方:"堪…...

DLSS Swapper:3分钟掌握游戏性能调优的终极秘诀
DLSS Swapper:3分钟掌握游戏性能调优的终极秘诀 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否厌倦了等待游戏开发商更新DLSS版本?是否曾因DLSS版本不兼容导致游戏崩溃而烦恼?…...

Taotoken用量看板如何帮助团队管理API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队管理API成本 对于团队技术负责人或项目管理者而言,在引入大模型能力后,一个核…...
:3分钟掌握浏览器资源嗅探的终极解决方案)
猫抓(Cat-Catch):3分钟掌握浏览器资源嗅探的终极解决方案
猫抓(Cat-Catch):3分钟掌握浏览器资源嗅探的终极解决方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为无法保存在线视频而烦恼…...

Mythos模型:通用AI在漏洞挖掘与 exploit 生成中的范式跃迁
1. 这不是一次普通升级:Mythos 的能力跃迁到底意味着什么“Claude Mythos Preview”——这个名字在2026年4月的AI圈里炸开时,我正调试一个用Opus 4.6做代码审计的自动化流水线。看到基准测试数据的第一反应不是兴奋,而是下意识关掉了终端窗口…...

【NotebookLM关键词提取实战指南】:20年AI工程师亲授3步精准提取法,90%用户忽略的隐藏参数曝光
更多请点击: https://kaifayun.com 第一章:NotebookLM关键词提取的核心原理与适用场景 NotebookLM 是 Google 推出的面向研究者与知识工作者的 AI 助手,其关键词提取能力并非依赖传统 TF-IDF 或 TextRank 等静态统计方法,而是深度…...
)
告别虚拟机!用WSL2自带的SSH服务连接VSCode远程开发(附端口冲突解决)
告别虚拟机!用WSL2自带的SSH服务连接VSCode远程开发(附端口冲突解决) 在Windows系统上进行Linux开发时,传统虚拟机方案往往显得笨重且资源占用高。WSL2的出现彻底改变了这一局面,它提供了近乎原生的Linux内核体验&…...

Fusion360新手必看:这10个隐藏快捷键和技巧,让你建模效率翻倍
Fusion360效率革命:10个被低估的实战技巧与深度应用 第一次打开Fusion360时,我被它复杂的界面吓到了——工具栏密密麻麻的图标,嵌套多层的右键菜单,还有那些隐藏在角落里的功能选项。直到一位资深用户向我演示了如何用长按左键快…...

09_AI审计平台设计:从风险识别出发而非从底稿编号出发
09 AI审计平台设计:从风险识别出发而非从底稿编号出发摘要:如果你打开一个审计系统,首页显示的是E1000、E2000、E3000这些底稿编号,那这个系统的设计者一定没搞明白审计师每天到底在想什么。我做了八年审计系统UX设计,…...

Sunshine游戏串流服务器:5步搭建你的终极私人云游戏平台
Sunshine游戏串流服务器:5步搭建你的终极私人云游戏平台 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏,却受限于硬件性能&…...