深度学习:GPT-1的MindSpore实践
GPT-1简介
GPT-1(Generative Pre-trained Transformer)是2018年由Open AI提出的一个结合预训练和微调的用于解决文本理解和文本生成任务的模型。它的基础是Transformer架构,具有如下创新点:
- NLP领域的迁移学习:通过最少的任务专项数据,利用预训练模型出色地完成具体的下游任务。
- 语言建模作为预训练任务:使用无监督学习和大规模的文本语料库来训练模型
- 为具体任务微调:采用预训练模型来适应监督任务
和BERT类似,GPT-1同样采取pre-train + fine-tune的思路:先基于大量未标注语料数据进行预训练, 后基于少量标注数据进行微调。但GPT-1在预训练任务思路和模型结构上与BERT有所差别。

GPT-1的目标是在预训练的过程中根据现有的所有词元,预测下一个词元。这个任务被称为“自回归语言建模”。
一个简单的例子:
输入序列为:“The sun rises in the”
训练数据的原句子为:“The sun rises in the east”
所以我们的目标输出为:“east”
将输入序列输入GPT模型,GPT根据输入预测下一个词元(“east”)在语料库中的概率分布
正确词元“east”作为一个“伪标签”来帮助模型训练
模型架构
GPT主要使用Transformer Decoder架构,但因为没有Encoder,所以在Transformer Decoder的基础上移除了计算Encoder与Decoder间注意力分数的Multi-Head Attention Layer。

Masked Multi-HeadSelf-Attention
Masked Multi-Head Self-Attention 是Multi-Head Attetion的变种。 最大的不同来自于MMSA的掩码机制,掩码机制防止模型通过观测未来的词元以进行“作弊”。
一个掩码词元<mask>被用于注意力分数矩阵,所以当前词元只能注意到序列中自己和自己之前的词元。未来的次元的注意力分数将被设为0以确保其在Softmax步骤后的实际贡献为0。
为什么掩码机制非常重要?
对于自回归任务,模型必须线性地生成词元,不能基于未来的信息预测下一个词元。

损失函数
GPT使用Cross-Entropy Loss作为损失函数:
交叉熵损失是这项任务的理想选择,因为它通过测量预测的概率分布与真实分布的距离来惩罚不正确的预测。它自然适于处理多类分类任务,其中模型从大量词汇表中选择一个标记。
模型输入
GPT-1的输入同样为句子或句子对,并添加Special Tokens。
- [BOS]:表示句子的开始,(论文中给出的token表示为[START]),添加到序列最前;
- [EOS]:表示序列的结束,(论文中的给出的[EXTRACT]),添加到序列最后,在进行分类任务时,会将 该special token对应的输出接入输出层;我们也可以理解为该token可以学习到整个句子的语义信息;
- [SEP]:用于间隔句子对中的两个句子;

GPT-1模型具体参数
模型架构
- 12个Transformer Decoder Block
- hidden_size为768(模型输入和输出的向量纬度)
- 注意力头数为12
- FFN维度为3072
- 词表(Vocab)大小为40000
- 序列长度为512(上下文窗口长度)
训练过程
- Adam优化器,超参数为:0.9, 0.99
- 学习率:最大学习率:2.5x10e-4 使用2000步作为热身,随后线性衰退
- 批大小:64
- 梯度剪裁:1.0
- Dropout率:0.1
训练过程
100000步,大约花费8张NVIDIA V100 GPU训练30天,共有117M参数。使用Xavier初始化,权重衰退为0.01。
下游任务 
基于MindSpore微调GPT-1进行情感分类
# #安装mindnlp 0.4.0套件
# !pip install mindnlp
# !pip uninstall soundfile -y
# !pip install download
# !pip install jieba
# !pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.3.1/MindSpore/unified/aarch64/mindspore-2.3.1-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simpleimport osimport mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nnfrom mindnlp.dataset import load_datasetfrom mindnlp.engine import Trainer# loading dataset
imdb_ds = load_dataset('imdb', split=['train', 'test'])
imdb_train = imdb_ds['train']
imdb_test = imdb_ds['test']imdb_train.get_dataset_size()import numpy as npdef process_dataset(dataset, tokenizer, max_seq_len=512, batch_size=4, shuffle=False):is_ascend = mindspore.get_context('device_target') == 'Ascend'def tokenize(text):if is_ascend:tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)else:tokenized = tokenizer(text, truncation=True, max_length=max_seq_len)return tokenized['input_ids'], tokenized['attention_mask']if shuffle:dataset = dataset.shuffle(batch_size)# map datasetdataset = dataset.map(operations=[tokenize], input_columns="text", output_columns=['input_ids', 'attention_mask'])dataset = dataset.map(operations=transforms.TypeCast(mindspore.int32), input_columns="label", output_columns="labels")# batch datasetif is_ascend:dataset = dataset.batch(batch_size)else:dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),'attention_mask': (None, 0)})return datasetfrom mindnlp.transformers import OpenAIGPTTokenizer
# tokenizer
gpt_tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')# add sepcial token: <PAD>
special_tokens_dict = {"bos_token": "<bos>","eos_token": "<eos>","pad_token": "<pad>",
}
num_added_toks = gpt_tokenizer.add_special_tokens(special_tokens_dict)#为方便体验流程,把原本数据集的十分之一拿出来体验训练和评估,
imdb_train, _ = imdb_train.split([0.1, 0.9], randomize=False)# split train dataset into train and valid datasets
imdb_train, imdb_val = imdb_train.split([0.7, 0.3])dataset_train = process_dataset(imdb_train, gpt_tokenizer, shuffle=True)
dataset_val = process_dataset(imdb_val, gpt_tokenizer)
dataset_test = process_dataset(imdb_test, gpt_tokenizer)# load GPT sequence classification model and set class=2
from mindnlp.transformers import OpenAIGPTForSequenceClassification # Import the GPT model for sequence classification
from mindnlp import evaluate # Import the evaluation module from MindNLP
import numpy as np # Import NumPy for numerical operations# Set up the GPT model for sequence classification with 2 output labels (binary classification).
model = OpenAIGPTForSequenceClassification.from_pretrained('openai-gpt', num_labels=2)# Set the padding token ID in the model configuration to match the tokenizer's padding token ID.
model.config.pad_token_id = gpt_tokenizer.pad_token_id# Resize the token embedding layer to account for any added tokens (e.g., special tokens).
model.resize_token_embeddings(model.config.vocab_size + 3)from mindnlp.engine import TrainingArguments # Import training arguments for model training configuration.# Define training arguments.
training_args = TrainingArguments(output_dir="gpt_imdb_finetune", # Directory to save model checkpoints and outputs.evaluation_strategy="epoch", # Evaluate the model at the end of each epoch.save_strategy="epoch", # Save model checkpoints at the end of each epoch.logging_strategy="epoch", # Log metrics and progress at the end of each epoch.load_best_model_at_end=True, # Automatically load the best model (based on evaluation metrics) at the end of training.num_train_epochs=1.0, # Number of training epochs (default is 1 for quick experimentation).learning_rate=2e-5 # Learning rate for the optimizer.
)# Load the accuracy metric for evaluation.
metric = evaluate.load("accuracy")# Define a function to compute metrics during evaluation.
def compute_metrics(eval_pred):logits, labels = eval_pred # Unpack predictions (logits) and true labels.predictions = np.argmax(logits, axis=-1) # Convert logits to class predictions using argmax.return metric.compute(predictions=predictions, references=labels) # Compute accuracy metric.# Initialize the Trainer class with the model, training arguments, datasets, and metric computation function.
trainer = Trainer(model=model, # The GPT model to be fine-tuned.args=training_args, # Training configuration arguments.train_dataset=dataset_train, # Training dataset (must be preprocessed and tokenized).eval_dataset=dataset_val, # Validation dataset for evaluation.compute_metrics=compute_metrics # Metric computation function for evaluation.
)# start training
trainer.train()trainer.evaluate(dataset_test)相关文章:
深度学习:GPT-1的MindSpore实践
GPT-1简介 GPT-1(Generative Pre-trained Transformer)是2018年由Open AI提出的一个结合预训练和微调的用于解决文本理解和文本生成任务的模型。它的基础是Transformer架构,具有如下创新点: NLP领域的迁移学习:通过最…...

前端图像处理(一)
目录 一、上传 1.1、图片转base64 二、图片样式 2.1、图片边框【border-image】 三、Canvas 3.1、把canvas图片上传到服务器 3.2、在canvas中绘制和拖动矩形 3.3、图片(同色区域)点击变色 一、上传 1.1、图片转base64 传统上传: 客户端选择图片…...

unity中:超低入门级显卡、集显(功耗30W以下)运行unity URP管线输出的webgl程序有那些地方可以大幅优化帧率
删除Global Volume: 删除Global Volume是一项简单且高效的优化措施。实测表明,这一改动可以显著提升帧率,甚至能够将原本无法流畅运行的场景变得可用。 更改前的效果: 更改后的效果: 优化阴影和材质: …...

ftdi_sio应用学习笔记 4 - I2C
目录 1. 查找设备 2. 打开设备 3. 写数据 4. 读数据 5. 设置频率 6 验证 6.1 遍历设备 6.2 开关设备 6.3 读写测试 I2C设备最多有6个(FT232H),其他为2个。和之前的设备一样,定义个I2C结构体记录找到的设备。 #define FT…...

如何更好的把控软件测试质量
如何更好的把控软件测试质量 在软件开发过程中,测试是确保软件质量、稳定性和用户体验的重要环节。随着需求的不断变化以及技术的不断进步,如何更好的把控软件测试质量已成为一个不可忽视的话题。本文将从几个维度探讨确保软件质量的方法和方案…...
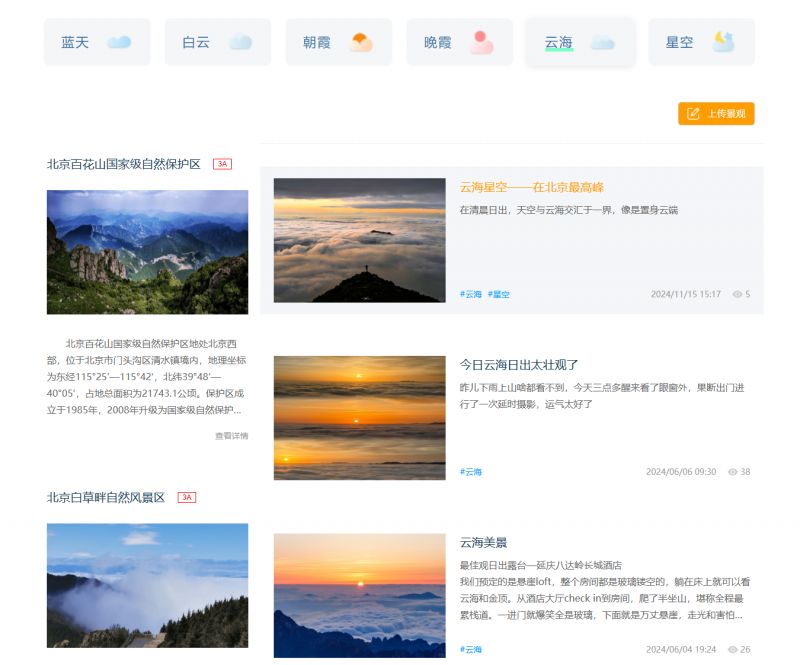
“漫步北京”小程序及“气象景观数字化服务平台”上线啦
随着科技的飞速发展,智慧旅游已成为现代旅游业的重要趋势。近日,北京万云科技有限公司联合北京市气象服务中心,打造的“气象景观数字化服务平台“和“漫步北京“小程序已经上线,作为智慧旅游的典型代表,以其丰富的功能…...

SOL链上的 Meme 生态发展:从文化到创新的融合#dapp开发#
一、引言 随着区块链技术的不断发展,Meme 文化在去中心化领域逐渐崭露头角。从 Dogecoin 到 Shiba Inu,再到更多细分的 Meme 项目,这类基于网络文化的加密货币因其幽默和社区驱动力吸引了广泛关注。作为近年来备受瞩目的区块链平台之一&…...

身份证实名认证API接口助力电商购物安全
亲爱的网购达人们,你们是否曾经因为网络上的虚假信息和诈骗而感到困扰?在享受便捷的网购乐趣时,如何确保交易安全成为了我们共同关注的话题。今天,一起来了解一下翔云身份证实名认证接口如何为电子商务保驾护航,让您的…...

【过程控制系统】第6章 串级控制系统
目录 6. l 串级控制系统的概念 6.1.2 串级控制系统的组成 6.l.3 串级控制系统的工作过程 6.2 串级控制系统的分析 6.2.1 增强系统的抗干扰能力 6.2.2 改善对象的动态特性 6.2.3 对负荷变化有一定的自适应能力 6.3 串级控制系统的设计 6.3.1 副回路的选择 2.串级系…...

YOLOv11融合针对小目标FFCA-YOPLO中的FEM模块及相关改进思路
YOLOv11v10v8使用教程: YOLOv11入门到入土使用教程 YOLOv11改进汇总贴:YOLOv11及自研模型更新汇总 《FFCA-YOLO for Small Object Detection in Remote Sensing Images》 一、 模块介绍 论文链接:https://ieeexplore.ieee.org/document/10…...

qt+opengl 三维物体加入摄像机
1 在前几期的文章中,我们已经实现了三维正方体的显示了,那我们来实现让物体的由远及近,和由近及远。这里我们需要了解一个概念摄像机。 1.1 摄像机定义:在世界空间中位置、观察方向、指向右侧向量、指向上方的向量。如下图所示: …...

day05(单片机高级)PCB基础
目录 PCB基础 什么是PCB?PCB的作用? PCB的制作过程 PCB板的层数 PCB设计软件 安装立创EDA PCB基础 什么是PCB?PCB的作用? PCB(Printed Circuit Board),中文名称为印制电路板,又称印刷…...

全球天气预报5天-经纬度版免费API接口教程
接口简介: 获取全球任意地区未来5天天气预报,必须传经纬度参数。可先调用【位置坐标】分类下相关接口获取地区经纬度坐标。 请求地址: https://cn.apihz.cn/api/tianqi/tqybjw5.php 请求方式: POST或GET。 请求参数:…...

Shell编程8
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...
)
python语言基础-5 进阶语法-5.5 上下文管理协议(with语句)
声明:本内容非盈利性质,也不支持任何组织或个人将其用作盈利用途。本内容来源于参考书或网站,会尽量附上原文链接,并鼓励大家看原文。侵删。 5.5 上下文管理协议(with语句)(参考链接࿱…...

自动驾驶3D目标检测综述(三)
前两篇综述阅读理解放在这啦,有需要自行前往观看: 第一篇:自动驾驶3D目标检测综述(一)_3d 目标检测-CSDN博客 第二篇:自动驾驶3D目标检测综述(二)_子流行稀疏卷积 gpu实现-CSDN博客…...
【GESP】C++三级练习 luogu-B3661, [语言月赛202209] 排排
三级知识点一维数组练习,除了应用了数组以外,其余逻辑比较简单,适合初学者。 题目题解详见:https://www.coderli.com/gesp-3-luogu-b3661/ 【GESP】C三级练习 luogu-B3661, [语言月赛202209] 排排队 | OneCoder三级知识点一维数…...
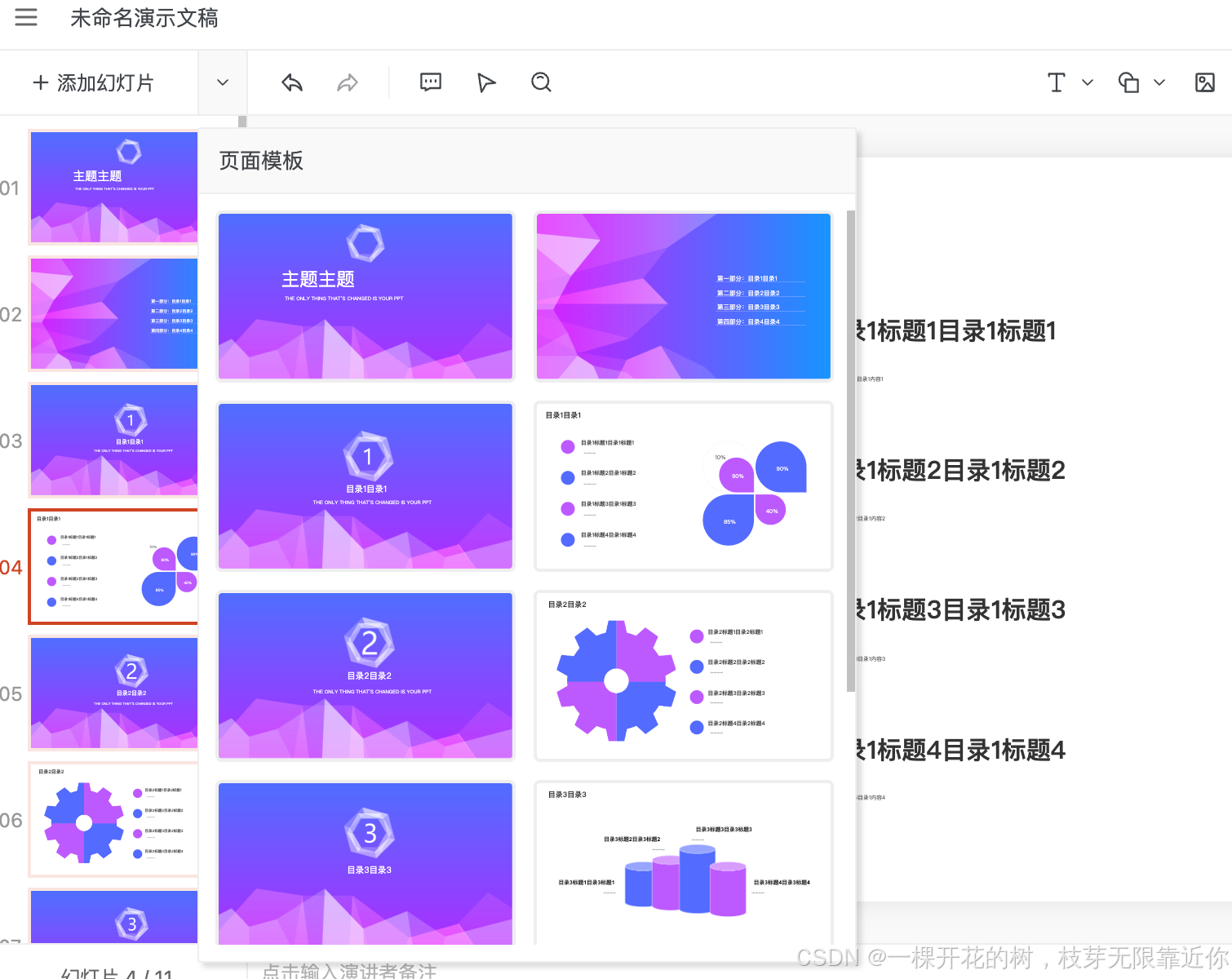
【PPTist】添加PPT模版
前言:这篇文章来探索一下如何应用其他的PPT模版,给一个下拉菜单,列出几个项目中内置的模版 PPT模版数据 (一)增加菜单项 首先在下面这个菜单中增加一个“切换模版”的菜单项,点击之后在弹出框中显示所有的…...

大疆上云api开发
目前很多公司希望使用上云api开发自己的无人机平台,但是官网资料不是特别全,下面浅谈一下本人开发过程中遇到的一系列问题。 本人使用机场为大疆机场2,飞机为M3TD,纯内网使用 部署 链接: 上云api代码. 首先从github上面拉去代码 上云api代码github. 后…...

IDEA2023 SpringBoot整合MyBatis(三)
一、数据库表 CREATE TABLE students (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(100) NOT NULL,age INT,gender ENUM(Male, Female, Other),email VARCHAR(100) UNIQUE,phone_number VARCHAR(20),address VARCHAR(255),date_of_birth DATE,enrollment_date DATE,cours…...

Taotoken的TokenPlan套餐如何实现更经济的模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的TokenPlan套餐如何实现更经济的模型调用 1. 理解TokenPlan的计费模式 在模型应用开发过程中,成本的可预测性…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析
CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析 【免费下载链接】CausalVLR CausalVLR: A Toolbox and Benchmark for Vision-Language Causal Reasoning (多模态因果推理开源框架) 项目地址: https://gitcode.com/gh_mirrors/ca/CausalVLR …...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...