【大数据学习 | Spark-Core】RDD的概念与Spark任务的执行流程
1. RDD的设计背景
在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。显然,如果能将结果保存在内存当中,就可以大量减少IO。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的落地存储,大大降低了数据复制、磁盘IO和序列化开销。
2. RDD的概念
RDD(Resilient Distributed Datasets,弹性分布式数据集)代表可并行操作元素的不可变分区集合。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段(HDFS上的块),并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
RDD典型的执行过程
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
1)RDD读入外部数据源(或者内存中的集合)进行创建;
2)RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
3)最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala/JAVA集合或变量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作(行动算子底层代码调用了runJob函数),对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。


val conf = new SparkConf
val sparkContext = new SparkContext(conf)
val lines :RDD = sparkContext.textFile(logFile)
//lines.filter((a:String) => a.contains("hello world"))
val count = lines.filter(_.contains("hello world")).count()
println(count)可以看出,一个Spark应用程序,基本是基于RDD的一系列计算操作。
第1行代码用于创建JavaSparkContext对象;
第2行代码从HDFS文件中读取数据创建一个RDD;
第3行代码对fileRDD进行转换操作得到一个新的RDD,即filterRDD;
count()是一个行动操作,用于计算一个RDD集合中包含的元素个数。
这个程序的执行过程如下:
1)创建这个Spark程序的执行上下文,即创建SparkContext对象;
2)从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
3)构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
4)执行action代码时,count()是一个行动类型的操作,触发真正的计算,开始执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
3. spark任务的执行过程
每一个应用都是由driver端组成的,并且driver端可以解析用户的代码,并且在集群中并行执行,spark给大家提供了一个编程对象,它是一个抽象的,叫做弹性分布式数据集,这个数据集和一堆数据的集合并且是被分区的,因为分区的数据可以被并行的进行操作,rdd的创建方式有两种 1.读取hdfs的文件 2.在driver的一个集合可以转换为rdd,rdd可以被持久化到内存中,并且rdd可以实现更好的失败恢复容错。

为什么rdd是抽象的呢?因为rdd并不存在数据,它是虚拟的,我们在定义逻辑的时候要标识一个节点,表示数据在流动到此处的时候要进行什么样的处理,我们可以理解rdd是一个代理对象。

上述任务执行过程可以划分为两个stage,从创建rdd开始到groupBy的shuffle,划分为一个stage,然后该shuffle到任务执行结束,又是一个stage。后面读源码我们会发现,当出现shuffle时,就要划分出一个阶段。因为业务逻辑发生了变化。
任务的执行和层架关系:
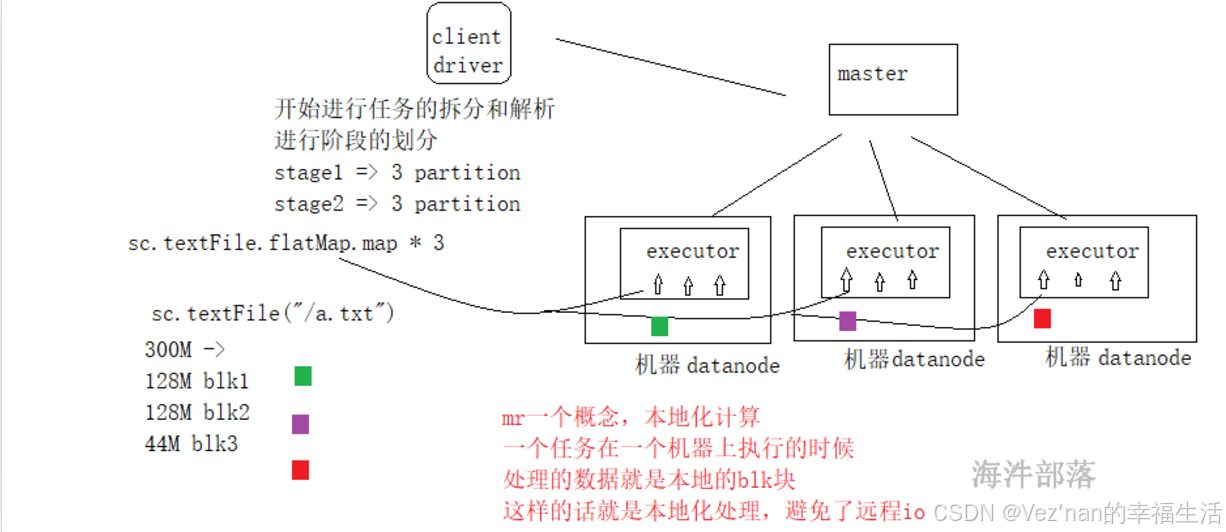
读取hdfs数据的时候映射应该是一个blk块对应一个分区
- 在一个任务中,一个action算子会生成一个job。(行动算子的源码都会包含runJob函数)
- 在一个job中存在shuffle算子,比如group sort切分阶段,shuffle+1个阶段。
- shuffle是任务的划分的重点,前面的任务会将数据放入到自己的本地存储,后续的任务进行数据的拉取。
- 在一个stage中任务都是管道形式执行的,避免了io,序列化和反序列化,这个就是dag切分的原理。
- 在一个阶段中分区数量就是task任务的数量,task任务就是一堆非shuffle类算子的整体任务链。
- 有几个分区就会并行的执行几个task任务。
- 有几个分区是根据读取的文件来进行适配的,比如有三个blk那么就会生成三个分区,因为我们可以在每个分区中进行处理数据,实现本地化的处理,避免远程io。
我们知道,分区的个数与读取的文件的Split切片数量有关。假如textFile读取文件的大小为400M,则会被物理切分为3个block,因为每个block-size的大小最大为128M,block1为128M,block2为128M,block3为144M。默认逻辑切片split-size的大小与block-size相适配,为128M,所以有三个分区。三个分区就会并行的执行3个task任务。
spark中一个executor可以执行多个task任务。这是通过将executor配置为拥有多个cores来实现的。每个核心可以并行执行一个task。即executor是一个JVM进程,负责在节点上运行任务。可以为executor配置多个核心来并行处理多个任务。
如果分区数多于executor的核心数,某些task必须等待其他task任务完成才能开始执行。
相关文章:
【大数据学习 | Spark-Core】RDD的概念与Spark任务的执行流程
1. RDD的设计背景 在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中&…...

一文读懂埋阻埋容工艺
PCB 埋阻埋容工艺是一种在 PCB 板内部埋入电阻和电容的工艺。通常情况下, PCB 上电阻和电容都是通过贴片技术直接焊接在板面上的,而埋阻埋容工艺则将电 阻和电容嵌入到 PCB 板的内部层中,这种印制电路板,其自下而上依次包括第一介电 层,隐埋电…...
)
mysql 数据表导出为 markdown(附 go 语言 gorm 的实际使用)
前言 通常业务系统开发中,数据库的设计与维护是至关重要的环节。而数据库的文档化则是确保团队成员之间有效沟通、快速理解系统架构的基础。 但目前数据文档都是手动写的,耗时费力,由于当前项目使用的是 mysql 作为存储引擎,找找…...

本地云存储 MinIO 中修改用户密码
本地云存储 MinIO 中修改用户密码 MinIO 中修改用户密码前提条件步骤 1:安装 MinIO Client对于 Linux/macOS:对于 Windows: 步骤 2:配置 MinIO Client步骤 3:查看现有用户步骤 4:修改用户密码步骤 5&#x…...

go项目中比较好的实践方案
工作两年来,我并未遇到太大的挑战,也没有特别值得夸耀的项目。尽管如此,在日常的杂项工作中,我积累了不少心得,许多实践方法也在思考中逐渐得到优化。因此,我在这里记录下这些心得。 转发与封装 这个需求…...
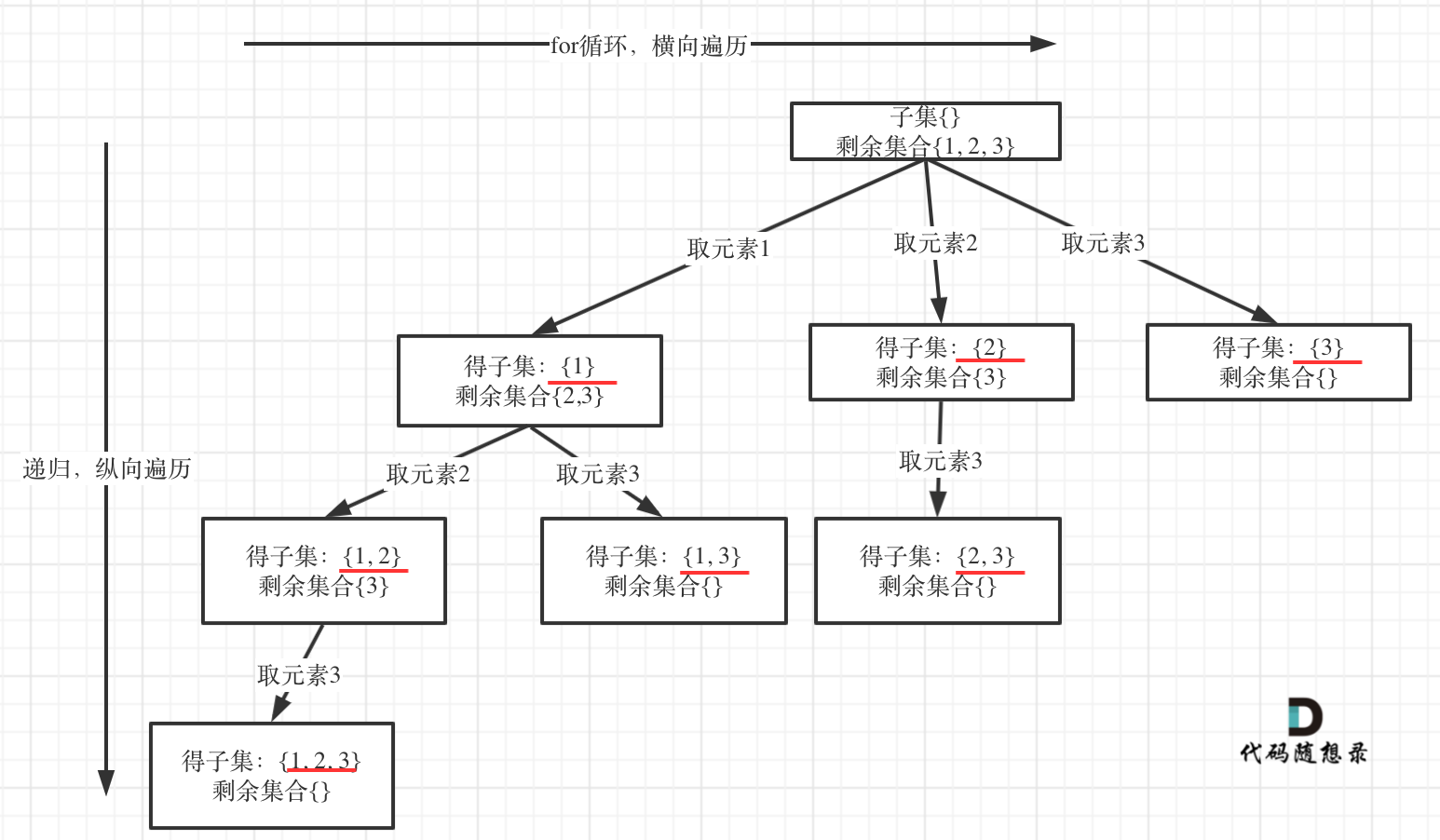
回溯法基础入门解析
回溯法 前 言 回溯法也可以叫做回溯搜索法,它是一种搜索的方式。回溯是递归的副产品,只要有递归就会有回溯。回溯法,一般可以解决如下几种问题: 组合问题:N个数里面按一定规则找出k个数的集合切割问题:一…...
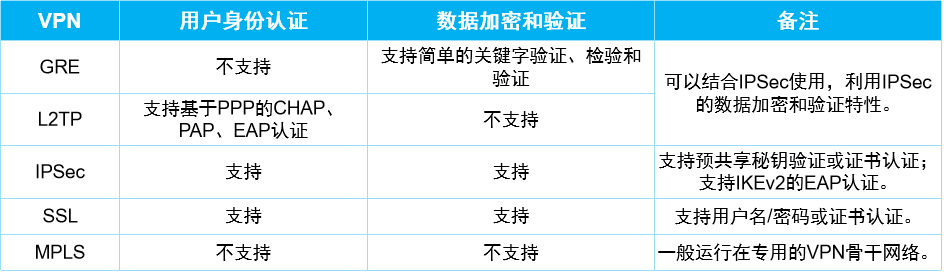
计算机网络-VPN虚拟专用网络概述
前面我们学习了在企业内部的二层交换机网络、三层路由网络包括静态路由、OSPF、IS-IS、NAT等,现在开始学习下VPN(Virtual Private Network,虚拟专用网络),其实VPN可能很多人听到第一反应就是梯子,但是其实这…...

信创时代的数据库之路:2024 Top10 国产数据库迁移与同步指南
数据库一直是企业数字化和创新的重要基础设施之一。从传统的关系型数据库到非关系型数据库、分析型数据库,再到云数据库和多模数据库,这一领域仍在持续变革中,各种新型数据库产品涌现,数据管理的能力和应用场景也由此得到了扩展。…...

自制游戏:监狱逃亡
第一个游戏,不喜勿喷: #include<bits/stdc.h> #include<windows.h> using namespace std; int xz; int ruond_1(int n){if(xz1){printf("撬开了,但站在你面前的是俄罗斯内务部特种部队的奥摩大帝,你被九把加特…...

小雪时节,阴盛阳衰,注意禁忌
宋张嵲《小雪作》 霜风一夜落寒林,莽苍云烟结岁阴。 把镜渐无勋业念,爱山唯驻隐沦心。 冰花散落衡门静,黄叶飘零一迳深。 世乱身穷无可奈,强将悲慨事微吟。 网络图片:小雪时节 笔者禁不住喟然而叹:“冰…...

CPU性能优化--微操作
x86 架构处理器吧复杂的CISC指令转为简单的RISC微操作。这样做最大的优势是微操作可以乱序执行,一条简单的相加指令--比如ADD,EAX, EBX,只产生一个微操作,而很多复杂指令--比如ADD, EAX 可能会产生两个微操作,一个将数…...

工厂模式
主要解决对象的创建问题 首先是简单工厂 只有一个工厂类,每次有新的产品就需要修改里面接口的内容,违反了封闭原则 //1、定义抽象产品类 class AbstractCar { public:AbstractCar() default;virtual ~AbstractCar() default;virtual void showName(…...

嵌入式系统与OpenCV
目录 一、OpenCV 简介 二、嵌入式 OpenCV 的安装方法 1. Ubuntu 系统下的安装 2. 嵌入式 ARM 系统中的安装 3. Windows10 和树莓派系统下的安装 三、嵌入式 OpenCV 的性能优化 1. 介绍嵌入式平台上对 OpenCV 进行优化的必要性。 2. 利用嵌入式开发工具,如优…...
编程之路,从0开始:动态内存笔试题分析
Hello大家好,很高兴我们又见面啦! 给生活添点passion,开始今天的编程之路。 今天我们来看几个经典的动态内存笔试题。 1、题目1 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<string.h> void GetMemory(char* …...
物联网研究实训室建设方案
一、引言 随着物联网技术的快速发展,其在各个行业的应用越来越广泛,对物联网专业人才的需求也日益增加。为满足这一需求,建设一个符合现代化教学需求的物联网研究实训室,对于提高学生的实践能力和创新能力具有重要意义。本方案旨…...
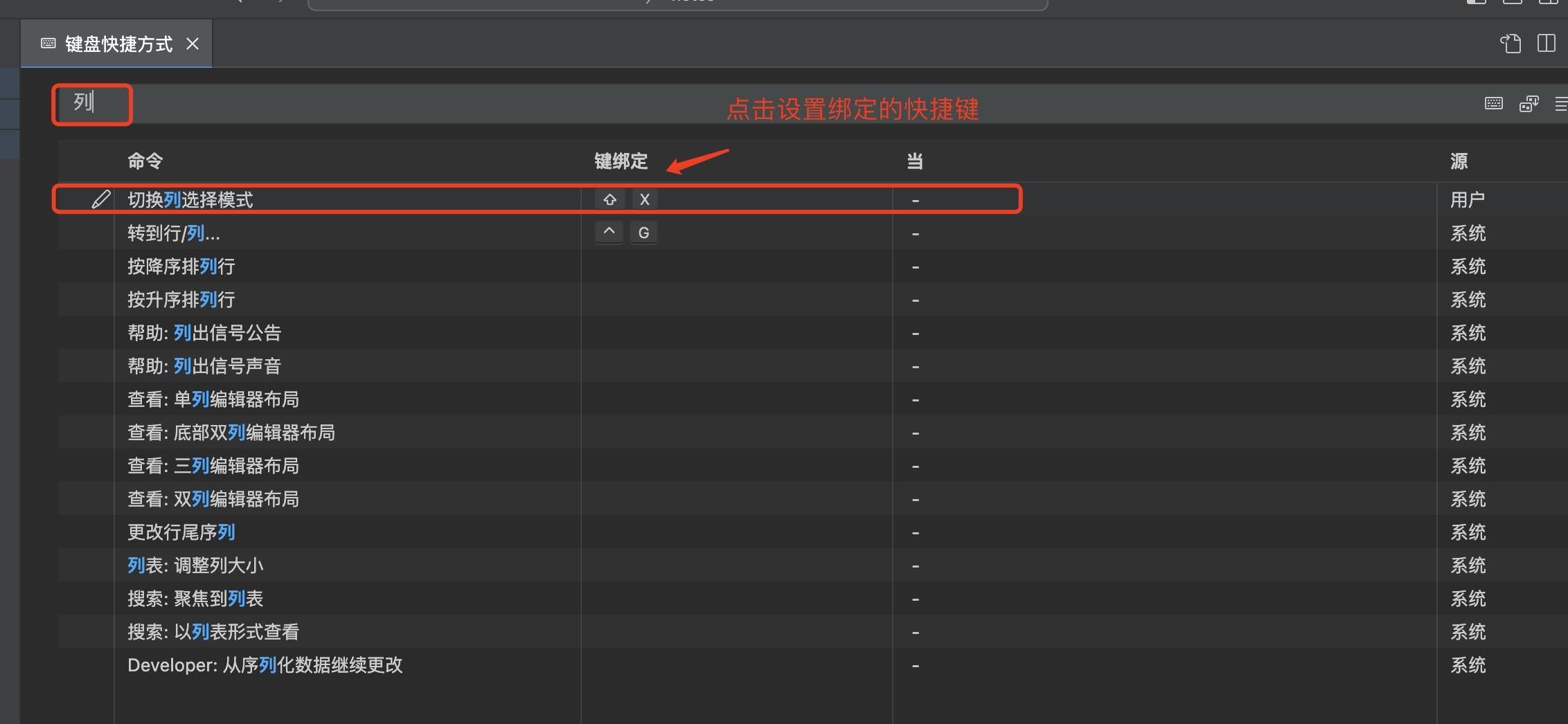
Mac vscode 激活列编辑模式
列编辑模式在批量处理多行文本时,非常有效,但 vscode 默认情况下,又没有激活,因此记录一下启动方法: 激活列编辑模式 然后就可以使用 Alt(Mac 上是 Option 或 Command 键) 鼠标左键 滑动选择了…...

深度学习:GPT-1的MindSpore实践
GPT-1简介 GPT-1(Generative Pre-trained Transformer)是2018年由Open AI提出的一个结合预训练和微调的用于解决文本理解和文本生成任务的模型。它的基础是Transformer架构,具有如下创新点: NLP领域的迁移学习:通过最…...

前端图像处理(一)
目录 一、上传 1.1、图片转base64 二、图片样式 2.1、图片边框【border-image】 三、Canvas 3.1、把canvas图片上传到服务器 3.2、在canvas中绘制和拖动矩形 3.3、图片(同色区域)点击变色 一、上传 1.1、图片转base64 传统上传: 客户端选择图片…...

unity中:超低入门级显卡、集显(功耗30W以下)运行unity URP管线输出的webgl程序有那些地方可以大幅优化帧率
删除Global Volume: 删除Global Volume是一项简单且高效的优化措施。实测表明,这一改动可以显著提升帧率,甚至能够将原本无法流畅运行的场景变得可用。 更改前的效果: 更改后的效果: 优化阴影和材质: …...

ftdi_sio应用学习笔记 4 - I2C
目录 1. 查找设备 2. 打开设备 3. 写数据 4. 读数据 5. 设置频率 6 验证 6.1 遍历设备 6.2 开关设备 6.3 读写测试 I2C设备最多有6个(FT232H),其他为2个。和之前的设备一样,定义个I2C结构体记录找到的设备。 #define FT…...

App Inventor蓝牙调试避坑指南:从连接失败到数据乱码,一次讲清所有常见问题
App Inventor蓝牙调试避坑指南:从连接失败到数据乱码的实战解决方案在移动应用开发领域,蓝牙通信一直是实现设备间短距离数据交换的核心技术之一。对于使用App Inventor的开发者而言,蓝牙模块提供了无需复杂编码即可实现无线通信的便捷途径。…...

森优时铁锌维发根养黑用三个月真实效果实测:内服营养养黑的客观测评
"森优时铁锌维发根养黑用三个月真实效果实测显示,针对压力、熬夜引发的早白问题,通过内服补充毛囊所需营养的方式,多数使用者能感受到发根韧性提升、新生发色素沉淀改善,整体改善效果因人而异,合规的营养补充是目…...

解决Claude Code Token不足问题并享受Taotoken活动价
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code Token不足问题并享受Taotoken活动价 应用场景类,聚焦于使用Claude Code时遇到Token配额紧张的开发者&…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

自然语言处理的实战项目:从0到1搭建属于自己的文本分类系统
对于软件测试从业者而言,日常工作中我们每天都会接触大量的文本数据:缺陷管理系统中的bug描述、测试用例的步骤说明、用户反馈的问题报告、需求文档的规格描述,甚至是接口返回的异常信息文本。这些非结构化文本往往隐含着关键业务信息&#x…...

告别Selenium?手把手教你用Playwright录制脚本,5分钟搞定Web自动化测试
5分钟极速上手Playwright脚本录制:零代码实现Web自动化测试当产品经理突然丢给你一个刚上线的电商活动页,要求半小时内完成所有核心链路测试时,传统的手写Selenium脚本显然来不及。作为测试工程师,我最近发现微软开源的Playwright…...

终极Obsidian笔记模板指南:如何用kepano-obsidian构建你的第二大脑
终极Obsidian笔记模板指南:如何用kepano-obsidian构建你的第二大脑 【免费下载链接】kepano-obsidian My personal Obsidian vault template. A bottom-up approach to note-taking and organizing things I am interested in. 项目地址: https://gitcode.com/gh_…...

小学阶段物理学习书籍推荐
结合小学阶段认知特点,推荐以下几本兼具趣味性和实用性的物理启蒙书籍,适配不同年级孩子的学习需求: 一、低龄(1-2年级/6-8岁):趣味感知,激发好奇 1、漫画物理全套6册 用孩子最喜欢的漫画形式拆…...