自然语言处理:第六十五章 MinerU 开源PDF文档解析方案
本人项目地址大全:Victor94-king/NLP__ManVictor: CSDN of ManVictor
原文地址:MinerU:精准解析PDF文档的开源解决方案
论文链接:MinerU: An Open-Source Solution for Precise Document Content Extraction
git地址:https://github.com/opendatalab/MinerU
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
当前PDF 文档广泛应用于各个领域,其中蕴含着丰富的信息。然而,从 PDF 中准确提取高质量的内容一直是计算机视觉领域的重要研究课题。随着大型语言模型(LLMs)的兴起,对高质量文档数据的需求愈发迫切,这也促使文档内容提取技术不断发展(利用LLM从非结构化PDF中提取结构化知识)。今天我们一起来聊一下MinerU,一款精准解析PDF文档的开源工具,这个也是我们正在使用的一款不错的PDF解析工具,希望对大家有所帮助。

一、MinerU简介
MinerU是一个功能强大的PDF文档内容提取工具,它利用了先进的PDF-Extract-Kit模型库,能够有效地从各种类型的文档中提取内容。该工具不仅具备高度的准确性,还通过精细的预处理和后处理规则,确保了最终结果的可靠性。MinerU的开源特性使得其成为广大开发者和研究者理想的选择,它不仅能够促进学术交流,还能够推动文档内容提取技术的进一步发展。
二、MinerU的框架与工作流程
MinerU的框架设计简洁而高效,主要包括文档预处理、文档内容解析、文档内容后处理和格式转换四个阶段。
1. 文档预处理
- 目标与功能
- 文档预处理主要有两个目标。一是筛选出无法处理的 PDF 文件,例如非 PDF 格式文件、加密文档以及受密码保护的文件,确保后续处理流程的顺利进行。二是获取 PDF 文档的元数据,这些元数据在后续的处理过程中具有重要作用。
- 具体操作与元数据获取
- 语言识别 :MinerU 当前仅能识别和处理中文和英文文档。在进行 OCR 操作时,需要指定语言类型,因为对于其他语言的处理质量无法保证。这一识别过程有助于后续针对特定语言的文本处理,提高处理的准确性。
- 内容乱码检测 :部分基于文本的 PDF 文档在复制文本时会出现乱码现象。在预处理阶段提前识别这类文档,以便在下一步骤中使用 OCR 进行文本识别,从而避免因乱码导致的内容提取错误。
- 扫描 PDF 识别 :对于文本型 PDF,MinerU 直接使用 PyMuPDF 进行文本提取;而对于扫描型 PDF,则需要启用 OCR。扫描型 PDF 的识别依据其特征,如图像区域较大(有时甚至覆盖整个页面)且每页平均文本长度接近零等,这种区分方式有助于选择合适的文本提取方式,提高提取效率和准确性。
- 页面元数据提取 :提取文档的总页数、页面尺寸(宽度和高度)等元数据,这些信息对于后续的布局分析、内容解析等操作提供了基础的页面信息,有助于确定文档的结构和元素分布。
2. 文档内容解析
核心模型库 - PDF - Extract - Kit
PDF - Extract - Kit 是 MinerU 用于解析文档的核心模型库,包含多种先进的开源 PDF 文档解析算法。与其他开源算法库不同,它致力于在处理现实世界多样化数据时确保准确性和速度。当特定领域的现有开源算法无法满足实际需求时,PDF - Extract - Kit 会通过数据工程构建高质量、多样化的数据集来进一步微调模型,从而显著增强模型对不同数据的鲁棒性。
解析流程与技术应用
布局分析
布局分析是文档解析的关键第一步,旨在区分页面上不同类型的元素及其对应区域。现有布局检测算法在处理纸质文档时表现尚可,但在面对教科书和考试试卷等多样化文档时存在困难。PDF - Extract - Kit 通过构建多样化布局检测训练集来解决这一问题。其数据工程训练方法包括多样化数据选择,收集各类 PDF 文档并聚类采样;数据标注,对文档组件的布局标注类型进行分类并建立详细标注标准;模型训练,基于现有布局检测模型进行微调;迭代数据选择和模型训练,根据验证集结果调整数据采样权重以优化模型。经过训练的模型在多样化文档上表现出色,远超开源的 SOTA 模型。
公式检测
由于公式(尤其是内联公式)在视觉上可能与文本难以区分,若不提前检测公式,后续文本提取可能出现乱码,影响文档整体准确性。因此,MinerU 训练了专门的公式检测模型。在数据集标注方面,定义了内联公式、显示公式和忽略类三个类别,最终在多类文档中进行了大量标注用于训练。训练后的基于 YOLO 的模型在速度和准确性上在各种文档中表现良好。
公式识别
多样化文档中的公式类型多样,包括短打印内联公式、复杂显示公式,甚至可能存在扫描文档中的手写公式和噪声公式内容。MinerU 采用自研的 UniMERNet 模型进行公式识别,该模型在大规模多样化公式识别数据集 UniMER - 1M 上进行训练,通过优化模型结构,在各种类型公式的识别上表现优异,与商业软件 MathPix 相当。
表格识别
表格是呈现结构化数据的有效方式,但从视觉表格图像中提取表格数据具有挑战性。MinerU 利用 TableMaster 和 StructEqTable 进行表格识别任务,用户可通过其执行 Table - to - LaTex 或 Table - to - HTML 任务。TableMaster 使用 PubTabNet 数据集训练,将任务分为四个子任务;StructEqTable 使用 DocGenome 基准数据进行端到端训练,在复杂表格识别上表现更强。
OCR
在排除文档中的特殊区域(表格、公式、图像等)后,MinerU 使用集成在 PDF - Extract - Kit 中的 Paddle - OCR 进行文本区域识别。为避免整页 OCR 导致的文本顺序错误,它基于布局分析检测到的文本区域(标题、文本段落)进行 OCR 操作。对于包含内联公式的文本块,先使用公式检测模型提供的坐标掩蔽公式,然后进行 OCR,最后将公式重新插入 OCR 结果中,确保了文本识别的准确性和阅读顺序。
3. 文档内容后处理
- 处理的主要问题与挑战
- 文档内容后处理阶段主要解决内容排序问题。由于模型输出的文本、图像、表格和公式框之间可能存在重叠,以及通过 OCR 或 API 获得的文本行之间也经常重叠,这给文本和元素的排序带来了巨大挑战。
- 解决方法与算法
- 处理边界框关系
- 包含关系 :去除图像和表格区域内包含的公式和文本块,以及公式框内包含的框,以简化元素关系,便于后续处理。
- 部分重叠关系 :对于部分重叠的文本框,通过垂直和水平收缩来避免相互覆盖,确保最终位置和内容不受影响,方便后续排序;对于文本与表格 / 图像的部分重叠,暂时忽略表格和图像以确保文本完整性。
- 基于阅读顺序的分割算法 :在处理完嵌套和部分重叠的边界框后,MinerU 开发了基于 “从上到下,从左到右” 人类阅读顺序的分割算法。该算法将整个页面划分为多个区域,每个区域包含多个边界框,且每个区域最多包含一列,确保文本按自然阅读顺序逐行读取。然后根据位置关系对分割后的组进行排序,确定 PDF 中每个元素的阅读顺序。
4. 格式转换
最后,在格式转换阶段,MinerU将处理后的PDF数据转换为用户所需的机器可读格式(如Markdown或JSON)。这一步骤使得MinerU的输出更加灵活和易于使用。
三、MinerU的核心技术与优势
MinerU之所以能够在文档内容提取领域脱颖而出,主要得益于其先进的核心技术和显著的优势。
1. 先进的模型库与算法
PDF-Extract-Kit作为MinerU的核心模型库,包含了多种先进的文档解析算法。这些算法不仅经过了严格的训练和验证,还针对多样化文档进行了优化。这使得MinerU在处理复杂布局和精细公式时表现出色。
2. 精细的预处理与后处理
MinerU在预处理和后处理阶段采用了多种精细的算法和技术。例如,在预处理阶段,它使用PyMuPDF等工具来准确提取PDF的元数据;在后处理阶段,它则利用规则-基于和模型-基于的混合方法来确保内容的准确性和可读性。
3. 高效的数据工程与迭代优化
为了进一步提高模型的准确性和鲁棒性,MinerU在数据工程和迭代优化方面下足了功夫。它通过收集多样化文档、构建高质量数据集以及采用迭代训练等方法,不断提升模型的性能和适应性。
4. 开源与易用性
作为一款开源工具,MinerU不仅提供了丰富的文档和示例代码,还支持多种输出格式和自定义配置。这使得用户能够轻松上手并快速应用于实际场景中。
从 PDF 中准确提取高质量的内容一直是计算机视觉领域的重要研究课题(PymuPDF4llm:PDF 提取的革命)。MinerU 在 PDF 文档解析领域已经取得了显著的成果,其未来的发展将进一步提升其性能和适用性,为文档处理相关工作提供更强大的支持。希望这款开源利器对大家有所帮助。
相关文章:
自然语言处理:第六十五章 MinerU 开源PDF文档解析方案
本人项目地址大全:Victor94-king/NLP__ManVictor: CSDN of ManVictor 原文地址:MinerU:精准解析PDF文档的开源解决方案 论文链接:MinerU: An Open-Source Solution for Precise Document Content Extraction git地址࿱…...

Arcpy 多线程批量重采样脚本
Arcpy 多线程批量重采样脚本 import arcpy import os import multiprocessingdef resample_tifs(input_folder, output_folder, cell_size0.05, resampling_type"BILINEAR"):"""将指定文件夹下的所有 TIFF 文件重采样到指定分辨率,并输出…...

python 画图例子
目录 多组折线图点坐标的折线图 多组折线图 数据: 第1行为x轴标签第2/3/…行等为数据,其中第一列为标签,后面为y值 图片: 代码: import matplotlib.pyplot as plt# 原始数据字符串 # 第1行为x轴标签 # 第2/3/...行等为数据,其中第一列为标签,后面…...

Win11 22H2/23H2系统11月可选更新KB5046732发布!
系统之家11月22日报道,微软针对Win11 22H2/23H2版本推送了2024年11月最新可选更新补丁KB5046732,更新后,系统版本号升至22621.4541和22631.4541。本次更新后系统托盘能够显示缩短的日期和时间,文件资源管理器窗口很小时搜索框被切…...

【STM32】MPU6050初始化常用寄存器说明及示例代码
一、MPU6050常用配置寄存器 1、电源管理寄存器1( PWR_MGMT_1 ) 此寄存器允许用户配置电源模式和时钟源。 DEVICE_RESET :用于控制复位的比特位。设置为1时复位 MPU6050,内部寄存器恢复为默认值,复位结束…...

深度学习中的mAP
在深度学习中,mAP是指平均精度均值(mean Average Precision),它是深度学习中评价模型好坏的一种指标(metric),特别是在目标检测中。 精确率和召回率的概念: (1).精确率(Precision):预测阳性结果中实际正确的比例(TP / …...

Redis设计与实现 学习笔记 第二十章 Lua脚本
Redis从2.6版本引入对Lua脚本的支持,通过在服务器中嵌入Lua环境,Redis客户端可以使用Lua脚本,直接在服务器端原子地执行多个Redis命令。 其中EVAL命令可以直接对输入的脚本进行求值: 而使用EVALSHA命令则可以根据脚本的SHA1校验…...

大模型(LLMs)推理篇
大模型(LLMs)推理篇 1. 为什么大模型推理时显存涨的那么多还一直占着? 首先,序列太长了,有很多Q/K/V;其次,因为是逐个预测next token,每次要缓存K/V加速解码。 大模型在gpu和cpu上…...

Leetcode 412. Fizz Buzz
Problem Given an integer n, return a string array answer (1-indexed) where: answer[i] “FizzBuzz” if i is divisible by 3 and 5.answer[i] “Fizz” if i is divisible by 3.answer[i] “Buzz” if i is divisible by 5.answer[i] i (as a string) if none of t…...

双因子认证:统一运维平台安全管理策略
01双因子认证概述 双因子认证(Two-Factor Authentication,简称2FA)是一种身份验证机制,它要求用户提供两种不同类型的证据来证明自己的身份。这通常包括用户所知道的(如密码)、用户所拥有的(如…...

CMake笔记:install(TARGETS target,...)无法安装的Debug/lib下
1. 问题描述 按如下CMake代码,无法将lib文件安装到Debug/lib或Release/lib目录下,始终安装在CMAKE_INSTALL_PREFIX/lib下。 install(TARGETS targetCONFIGURATIONS DebugLIBRARY DESTINATION Debug/lib) install(TARGETS targetCONFIGURATIONS Release…...

使用ENSP实现NAT
一、项目拓扑 二、项目实现 1.路由器AR1配置 进入系统试图 sys将路由器命名为R1 sysname R1关闭信息中心 undo info-center enable进入g0/0/0接口 int g0/0/0将g0/0/0接口IP地址配置为12.12.12.1/30 ip address 12.12.12.1 30进入e0/0/1接口 int g0/0/1将g0/0/1接口IP地址配置…...

漫步北京小程序构建智慧出行,打造旅游新业态模式
近年来,北京市气象服务中心持续加强推进旅游气象服务,将旅游气象监测预警基础设施纳入景区配套工程,提升气象和旅游融合发展水平,服务建设高品质智慧旅游强市。 天气条件往往影响着旅游景观的体验,北京万云科技有限公…...

对齐输出
对齐输出 C语言代码C 语言代码Java语言代码Python语言代码 💐The Begin💐点点关注,收藏不迷路💐 输入三个整数,按每个整数占8个字符的宽度,右对齐输出它们。 输入 只有一行,包含三个整数&…...
Wekan看板安装部署与使用介绍
Wekan看板安装部署与使用介绍 1. Wekan简介 Wekan 是一个开源的看板式项目管理工具,它的配置相对简单,因为大多数功能都是开箱即用的。它允许用户以卡片的形式组织和跟踪任务,非常适合敏捷开发和日常任务管理。Wekan 的核心功能包括看板…...

VisionPro 机器视觉案例 之 黑色齿轮
第十五篇 机器视觉案例 之 齿轮齿数检测 文章目录 第十五篇 机器视觉案例 之 齿轮齿数检测1.案例要求2.实现思路2.1 统计齿轮齿数使用模板匹配工具CogPMAlignTool,并从模板匹配工具的结果集中得到每一个齿的中心点。2.2 测量距离需要知道两个坐标点,一个…...

学习python的第十三天之数据类型——函数传参中的传值和传址问题
学习python的第十三天之数据类型——函数传参中的传值和传址问题 函数传参中的传值和传址问题 函数传参的机制可以理解为传值(pass-by-value)和传址(pass-by-reference)的混合体,但实际上更接近于传对象引用ÿ…...

Windows11深度学习环境配置
CUDA、CUDNN 一、安装另一个版本的CUDA 下载.exe文件,网址打不开自己开热点就能解决:CUDA Toolkit 11.2 Downloads | NVIDIA Developer 若遇到“You already have a newer version of the NVIDIA Frameview SDK installed” 1.把电脑已经存在的FrameVi…...
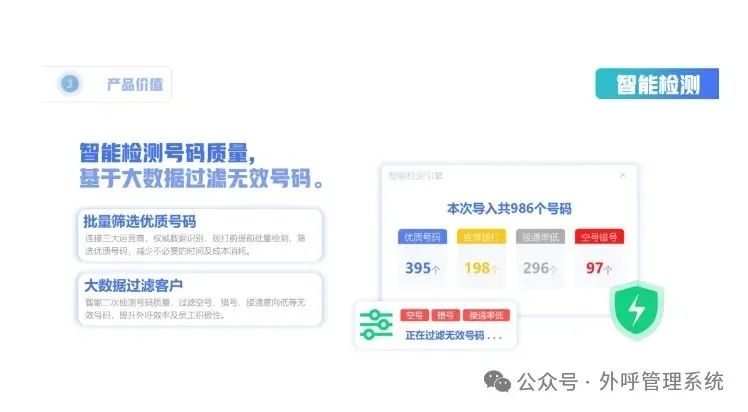
电销老是被标记,该如何解决!!!
在当今的商业世界中,电话销售依然是许多企业拓展业务、接触客户的重要手段。然而,电销人员常常面临一个令人头疼的问题 —— 老是被标记。 一、电销被标记的困扰 当你的电话号码被频繁标记为 “骚扰电话”“推销电话” 等,会带来一系列不良…...
MyBatis入门——基本的增删改查
目录 一、MyBatis简介 二、搭建MyBatis (一)配置依赖 (二)log4j日志功能 (三)数据库配置文件——jdbc.properties (四)创建MyBatis的核心配置文件 (五)使用MyBatisX插件 三、项目其他配置搭建 (一)创建数据库连接工具类 (二)创建表 (三)创建数据库的实体类 (四)Use…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...

NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制
NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制 副标题: 从预分配+Attention Mask到三层软件栈,完整解析NPU推理架构 痛点:为什么NPU跑LLM这么难? LLM的生成机制和NPU的硬件特性存在根本冲突: LLM特性 NPU特性 冲突点 逐token生成 固定shape执行 KV Cache动态增长 动…...

每日一书㉗ | 刻意练习:为什么有些人努力一辈子还是平庸?
“本文来自「乐想屋」公众号,系列更新[每日一书],每次5分钟,帮你把书读薄,把知识用活”先问你一个问题。你身边有没有这样的人:入行时间比你短,但能力已经甩你好几条街。他们好像没有特别刻苦,但…...