力扣面试经典 150(上)
文章目录
- 数组/字符串
- 1. 合并两个有序数组
- 2. 移除元素
- 3. 删除有序数组中的重复项
- 4. 删除有序数组的重复项II
- 5. 多数元素
- 6. 轮转数组
- 7. 买卖股票的最佳时机
- 8. 买卖股票的最佳时机II
- 9. 跳跃游戏
- 10. 跳跃游戏II
- 11. H 指数
- 12. O(1)时间插入、删除和获取随机元素
- 13. 除自身以外数组的乘积
- 14. 加油站
- 15. 分发糖果
- 16. 接雨水
- 17. 罗马数转整数
- 18. 整数转罗马数字
- 19. 最后一个单词的长度
- 20. 最长公共前缀
- 21. 反转字符串中的单词
- 22. Z 字形变换
- 23. 找出字符串中第一个匹配项的下标
- 24. 文本左右对齐
- 双指针
- 25. 验证回文串
- 26. 判断子序列
- 27. 两数之和|| -输入有序数组
- 28. 盛最多水的容器
- 30. 三数之和
- 滑动窗口
- 31. 长度最小的子数组
- 32. 无重复字符的最长子串
- 33. 串联所有单词的子串
- 34. 最小覆盖子串
- 矩阵
- 35. 有效的数独
- 36. 螺旋矩阵
- 37. 旋转图像
- 38. 矩阵置零
- 39. 生命游戏
- 哈希表
- 40. 赎金信
- 41. 同构字符串
- 42. 单词规律
- 43. 有效的字母异位词
- 44. 字母异位词分组
- 45. 两数之和
- 46. 快乐数
- 47. 存在重复元素II
- 48. 最长连续序列
- 区间
- 49. 汇总区间
- 50. 合并区间
- 51. 插入区间
- 52. 用最少数量的箭引爆气球
- 栈
- 53. 有效的括号
- 54. 简化路径
- 55. 最小栈
- 56. 逆波兰表达式求值
- 57. 基本计算器
- 链表
- 58. 环形链表
- 删除排序链表中重复的元素||
- 59. 两数相加
- 60. 合并两个有序链表
- 61. 随机链表的复制
- 62. 反转链表II
- 63. K 个一组翻转链表
- 64. 删除链表的倒数第N 个节点
- 65. 删除排序链表中的重复元素II
- 66. 旋转链表
- 66. 分隔链表
- 67. LRU 缓存
- 二叉树
- 68. 二叉树的最大深度
- 69. 相同的树
- 70. 翻转二叉树
- 71. 对称二叉树
- 72. 从前序与中序遍历序列构造二叉树
- 73. 从中序和后序构造二叉树
- 74. 填充每个节点的下一个右侧节点指针II
- 75. 二叉树展开为链表
- 76. 路径总和
- 77. 求根节点到叶节点数字之和
- 78. 二叉树中的最大路径和
- 79. 二叉树搜索迭代器
- 80. 完全二叉树的节点个数
- 81. 二叉树的最近公共祖先
数组/字符串
1. 合并两个有序数组

解法一:简单插入排序改造,由于num1 和num2都是非递减序列,所以对于num2的每个值a,都查找其在num1中的索引位置,然后从后往前遍历num1数组,将小于a的都往后移动一个位置,最后 将a插入。
代码:
class Solution {
public:int indexInNums(vector<int>&nums,int x,int len){int i;for(i=0;i<len;i++){if(nums[i]>x){break;}}return i;}void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {if(nums2.size()==0)return;if(nums1.size()==0){for(int i=0;i<n;i++){nums1[i]=nums2[i];}}for(int i=0;i<n;i++){int index=indexInNums(nums1,nums2[i],m+i);if(index==(m+i)){nums1[index]=nums2[i];}else{for(int j=m+i-1;j>=index;j--){nums1[j+1]=nums1[j];}nums1[index]=nums2[i];}}return;}
};
时间复杂度:O(n^2)
空间复杂度:O(1)
解法二:直接合并然后排序
直接把num2加入num1末尾,然后调用sort函数排序
class Solution {
public:void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {for (int i = 0; i != n; ++i) {nums1[m + i] = nums2[i];}sort(nums1.begin(), nums1.end());}
};
解法三:双指针
class Solution {
public:void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {int p1 = 0, p2 = 0;int sorted[m + n];int cur;while (p1 < m || p2 < n) {if (p1 == m) {cur = nums2[p2++];} else if (p2 == n) {cur = nums1[p1++];} else if (nums1[p1] < nums2[p2]) {cur = nums1[p1++];} else {cur = nums2[p2++];}sorted[p1 + p2 - 1] = cur;}for (int i = 0; i != m + n; ++i) {nums1[i] = sorted[i];}}
};时间复杂度:O(m+n)。
指针移动单调递增,最多移动 m+n 次,因此时间复杂度为 O(m+n)。
空间复杂度:O(m+n)。
需要建立长度为 m+n 的中间数组 sorted。
解法四:最优解法(逆向双指针)

class Solution {
public:void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {int p1 = m - 1, p2 = n - 1;int tail = m + n - 1;int cur;while (p1 >= 0 || p2 >= 0) {if (p1 == -1) {cur = nums2[p2--];} else if (p2 == -1) {cur = nums1[p1--];} else if (nums1[p1] > nums2[p2]) {cur = nums1[p1--];} else {cur = nums2[p2--];}nums1[tail--] = cur;}}
};
2. 移除元素


解法一:双指针【快慢指针】
由于题目要求删除数组中等于 val 的元素,因此输出数组的长度一定小于等于输入数组的长度,我们可以把输出的数组直接写在输入数组上。可以使用双指针:右指针 right 指向当前将要处理的元素,左指针 left 指向下一个将要赋值的位置。
- 即left是慢指针,right是快指针,right会跳过数字等于val的位置,而left指针的位置小于等于right,为慢指针;
- 如果右指针指向的元素不等于 val,它一定是输出数组的一个元素,我们就将右指针指向的元素复制到左指针位置,然后将左右指针同时右移;
- 如果右指针指向的元素等于 val,它不能在输出数组里,此时左指针不动,右指针右移一位。
- 整个过程保持不变的性质是:区间 [0,left)中的元素都不等于 val。当左右指针遍历完输入数组以后left 的值就是输出数组的长度。
这样的算法在最坏情况下(输入数组中没有元素等于val),左右指针各遍历了数组一次。
代码:
class Solution {
public:int removeElement(vector<int>& nums, int val) {int left=0;for(int right=0;right<nums.size();right++){if(nums[right]!=val){nums[left]=nums[right];left++;}}return left;}
};
时间复杂度:O(n),其中 n 为序列的长度。我们只需要遍历该序列至多两次。
空间复杂度:O(1)。我们只需要常数的空间保存若干变量。
解法二:双指针优化
思路
如果要移除的元素恰好在数组的开头,例如序列[1,2,3,4,5],当 val 为 1 时,我们需要把每一个元素都左移一位。注意到题目中说:「元素的顺序可以改变」。实际上我们可以直接将最后一个元素 5 移动到序列开头,取代元素 1,得到序列 [5,2,3,4],同样满足题目要求。这个优化在序列中 val 元素的数量较少时非常有效。
实现方面,我们依然使用双指针,两个指针初始时分别位于数组的首尾,向中间移动遍历该序列。
算法
如果左指针 left 指向的元素等于 val,此时将右指针 right 指向的元素复制到左指针left 的位置,然后右指针 right 左移一位。如果赋值过来的元素恰好也等于 val,可以继续把右指针 right 指向的元素的值赋值过来(左指针 left 指向的等于 val 的元素的位置继续被覆盖),直到左指针指向的元素的值不等于 val 为止。
当左指针 left 和右指针 right 重合的时候,左右指针遍历完数组中所有的元素。
这样的方法两个指针在最坏的情况下合起来只遍历了数组一次。与方法一不同的是,方法二避免了需要保留的元素的重复赋值操作。
注意代码实现的时候,right指针需要从nums.size()开始,因为假设right指针指向nums.size()-1,则可能出错,当nums只有一个元素,并且这个元素应该被去掉,此时left=0,right=0直接退出循环了,因此right应该从nums.size()-1开始
class Solution {
public:int removeElement(vector<int>& nums, int val) {if(nums.empty())return 0;int left=0,right=nums.size();while(left<right){if(nums[left]==val){nums[left]=nums[right-1];right--;}else{left++;}}return left; }
};
时间复杂度:O(n),其中 n 为序列的长度。我们只需要遍历该序列至多一次。
空间复杂度:O(1)。我们只需要常数的空间保存若干变量
3. 删除有序数组中的重复项

解法一:首先注意数组是有序的,那么重复的元素一定会相邻。
要求删除重复元素,实际上就是将不重复的元素移到数组的左侧。
考虑用 2 个指针,一个慢指针记作 slow,一个快指针记作 quick,算法流程如下:
比较 slow 和 quick 位置的元素是否相等。
- 如果相等,quick 后移 1 位
- 如果不相等,将 quick 位置的元素复制到 slow+1 位置上,slow 后移一位,quick 后移 1 位
- 重复上述过程,直到 quick 等于数组长度。
- 返回 slow + 1,即为新数组长度。
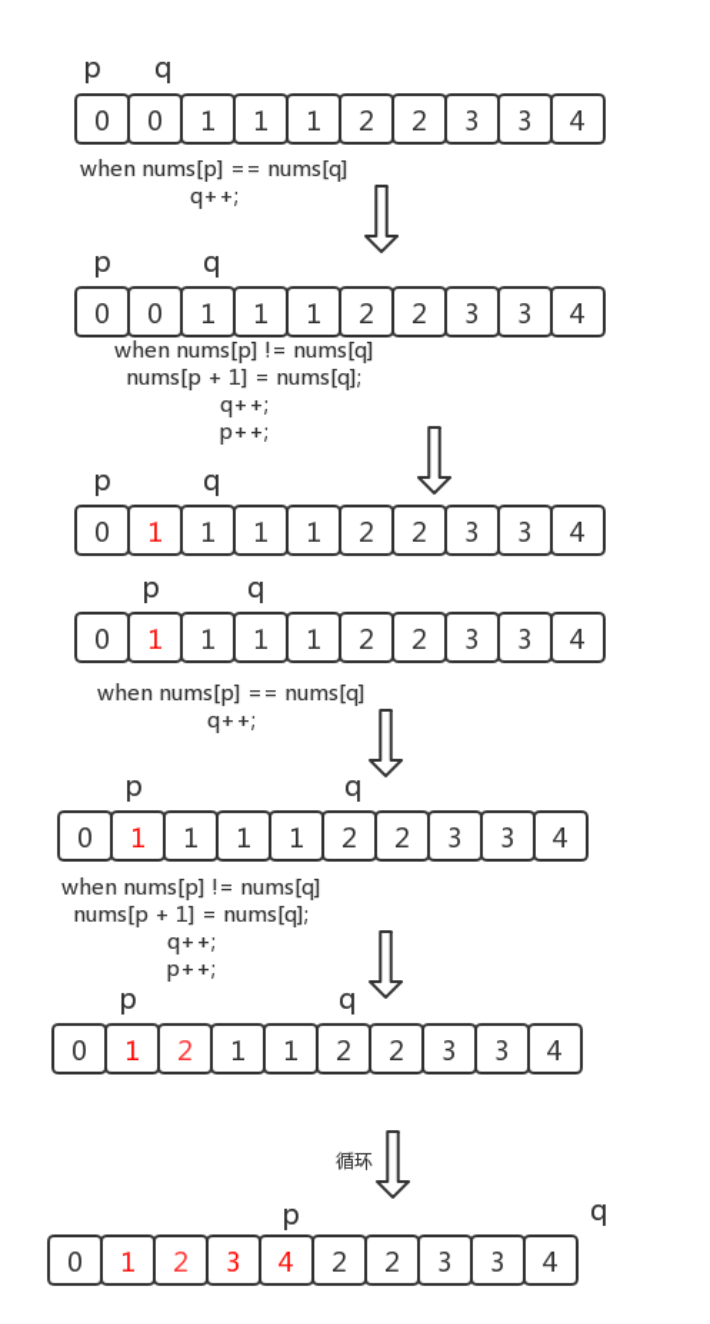
优化:
这是大部分题解都没有提出的,在这里提一下。
考虑如下数组:
此时数组中没有重复元素,按照上面的方法,每次比较时 nums[slow] 都不等于 nums[quick],因此就会将 quick 指向的元素原地复制一遍,这个操作其实是不必要的。
因此我们可以添加一个小判断,当 quick - slow > 1 时,才进行复制。
代码:
class Solution {
public:int removeDuplicates(vector<int>& nums) {if(nums.size()==0||nums.size()==1)return nums.size();int slow=0;int quick=1;while(quick<nums.size()){if(nums[slow]!=nums[quick]){if(quick-slow>1)nums[slow+1]=nums[quick];slow++;}quick++;}return slow+1;}
};
时间复杂度:O(n)。
空间复杂度:O(1)。
4. 删除有序数组的重复项II


解法:双指针,快慢指针
因为给定数组是有序的,所以相同元素必然连续。我们可以使用双指针解决本题,遍历数组检查每一个元素是否应该被保留,如果应该被保留,就将其移动到指定位置。具体地,我们定义两个指针 slow 和fast 分别为慢指针和快指针,其中慢指针表示处理出的数组的长度,快指针表示已经检查过的数组的长度,即 nums[fast]表示待检查的第一个元素,nums[slow−1] 为上一个应该被保留的元素所移动到的指定位置。
因为本题要求相同元素最多出现两次而非一次,所以我们需要检查上上个应该被保留的元素 nums[slow−2] 是否和当前待检查元素 nums[fast]相同。当且仅当 nums[slow−2]=nums[fast]时,当前待检查元素 nums[fast] 不应该被保留(因为此时必然有 nums[slow−2]=nums[slow−1]=nums[fast]。最后,slow即为处理好的数组的长度。
特别地,数组的前两个数必然可以被保留,因此对于长度不超过 2 的数组,我们无需进行任何处理,对于长度超过 2 的数组,我们直接将双指针的初始值设为 2 即可。
代码:
class Solution {
public:
int removeDuplicates(std::vector<int>& nums) {if (nums.size() < 3) return nums.size();int slow = 2,fast=2; // 从第三个元素开始检查和写入while(fast<nums.size()){if(nums[slow-2]!=nums[fast]){nums[slow]=nums[fast];slow++;}fast++;}return slow;
}
};
时间复杂度:O(n),其中 n是数组的长度。我们最多遍历该数组一次。
空间复杂度:O(1)。我们只需要常数的空间存储若干变量。
5. 多数元素

解法一:哈希表
使用hash表存储每个元素的数量,如果大于n/2,则返回,因为题目应该多数元素之存在一个
代码:
class Solution {
public:int majorityElement(vector<int>& nums) {unordered_map<int,int>numToSize;for(auto n:nums){numToSize[n]++;if(numToSize[n]>nums.size()/2){return n;}}return 0;}
};
时间复杂度:O(n)
空间复杂度:O(n)
解法二:Boyer-Moore 算法【实现O(1)的空间复杂度】
见官方题解169. 多数元素 - 力扣(LeetCode)
代码:
class Solution {
public:int majorityElement(vector<int>& nums) {int candidate=-1;int count=0;for(int num:nums){if(num==candidate)count++;else if(--count<0){candidate=num;count=1;}}return candidate;}
};
时间复杂度:O(n)
空间复杂度:O(1)
解法:排序法、分治法、随机化、可见官方题解
169. 多数元素 - 力扣(LeetCode)
6. 轮转数组

解法一:最开始解法使用就地移位的方式,n=数组的长度,那么每次都将前n-1个数字后移,然后将最后一个放到第一个位置。即按照题目的要去每次翻转一次。但是这种方式在37个案例的时候超时。
解法二:就地翻转。题目的意思就是将后k个数组移动到前k个上。
以例1为例:[1,2,3,4,5,6,7]
- 首先可以将整个数组翻转=>[7,6,5,4,3,2,1]
- 然后将前k个数字翻转:[5,6,7,4,3,2,1]
- 再将后n-k个数字翻转:[5,6,7,1,2,3,4]
class solution_18 {
public://打算向后移动位数的方法 超时void rotate2(vector<int>& nums, int k) {int temp;int n=nums.size()-1;while(k){temp=nums[n];for(int i=n-1;i>=0;i--){nums[i+1]=nums[i];}nums[0]=temp;k--;}
// for(int num:nums){
// cout<<num<<" ";
// }}//前后翻转 可用void rotate(vector<int>& nums, int k) {int n=nums.size()-1;k=k%nums.size();reverse(nums,0,n);reverse(nums,0,k-1);reverse(nums,k,n);}void reverse(vector<int>&nums,int start,int end){while(start<end){int temp=nums[end];nums[end]=nums[start];nums[start]=temp;start+=1;end-=1;}}
};
时间复杂度:O(n),其中 n 为数组的长度。每个元素被翻转两次,一共 n 个元素,因此总时间复杂度为 O(2n)=O(n)。
空间复杂度:O(1)
7. 买卖股票的最佳时机

解法1:一次遍历
假设给定的数组为:[7, 1, 5, 3, 6, 4]
我们来假设自己来购买股票。随着时间的推移,每天我们都可以选择出售股票与否。那么,假设在第 i 天,如果我们要在今天卖股票,那么我们能赚多少钱呢?
显然,如果我们真的在买卖股票,我们肯定会想:如果我是在历史最低点买的股票就好了,在题目中,我们只要用一个变量记录一个历史最低价格 minPrice,我们就可以假设自己的股票是在那天买的。那么我们在第 i 天卖出股票能得到的利润就是 prices[i] - minPrice。
因此,我们只需要遍历价格数组一遍,记录历史最低点,然后在每一天考虑这么一个问题:如果我是在历史最低点买进的,那么我今天卖出能赚多少钱?当考虑完所有天数之时,我们就得到了最好的答案。
代码:
class Solution {
public:int maxProfit(vector<int>& prices) {int len=prices.size();if(len<2)return 0;int minPrice=prices[0],maxProfit=0;for(int p:prices){maxProfit=max(maxProfit,p-minPrice);minPrice=min(p,minPrice);}return maxProfit;}
};
时间复杂度:O(n) 只遍历了一次
空间复杂度:O(1) 只使用了常量个变量。
解法2: 动态规划
思路:题目只问最大利润,没有问这几天具体哪一天买、哪一天卖,因此可以考虑使用 动态规划 的方法来解决。
买卖股票有约束,根据题目意思,有以下两个约束条件:
条件 1:你不能在买入股票前卖出股票;
条件 2:最多只允许完成一笔交易。
因此 当天是否持股 是一个很重要的因素,而当前是否持股和昨天是否持股有关系,为此我们需要把 是否持股 设计到状态数组中。
dp[i][j]:下标为 i 这一天结束的时候,手上持股状态为 j 时,我们持有的现金数。换种说法:dp[i][j] 表示天数 [0, i] 区间里,下标 i 这一天状态为 j 的时候能够获得的最大利润。其中:
j = 0,表示当前不持股;
j = 1,表示当前持股。
注意:下标为 i 的这一天的计算结果包含了区间 [0, i] 所有的信息,因此最后输出 dp[len - 1][0]。
使用「现金数」这个说法主要是为了体现 买入股票手上的现金数减少,卖出股票手上的现金数增加 这个事实;
「现金数」等价于题目中说的「利润」,即先买入这只股票,后买入这只股票的差价;
推导状态转移方程:
dp[i][0]:规定了今天不持股,有以下两种情况:
- 昨天不持股,今天什么都不做;
- 昨天持股,今天卖出股票(现金数增加),
dp[i][1]:规定了今天持股,有以下两种情况:
- 昨天持股,今天什么都不做(现金数与昨天一样);
- 昨天不持股,今天买入股票(注意:只允许交易一次,因此手上的现金数就是当天的股价的相反数)。
代码:
class Solution {
public:int maxProfit(vector<int>& prices) {int len=prices.size();if(len<2)return 0;int dp[len][2];// dp[i][0] 下标为 i 这天结束的时候,不持股,手上拥有的现金数// dp[i][1] 下标为 i 这天结束的时候,持股,手上拥有的现金数dp[0][0]=0;dp[0][1]=-prices[0];for(int i=1;i<len;i++){dp[i][0]=max(dp[i-1][0],dp[i-1][1]+prices[i]);dp[i][1]=max(dp[i-1][1],-prices[i]);}return dp[len-1][0];}
};
- 时间复杂度:O(N),遍历股价数组可以得到最优解;
- 空间复杂度:O(N),状态数组的长度为 N。
8. 买卖股票的最佳时机II

解法一:动态规划
考虑到「不能同时参与多笔交易」,因此每天交易结束后只可能存在手里有一支股票或者没有股票的状态。
定义状态 d p [ i ] [ 0 ] dp[i][0] dp[i][0] 表示第 i 天交易完后手里没有股票的最大利润, d p [ i ] [ 1 ] dp[i][1] dp[i][1] 表示第 i 天交易完后手里持有一支股票的最大利润(i 从 0 开始)。
考虑 $dp[i][0] $的转移方程,如果这一天交易完后手里没有股票,那么可能的转移状态为前一天已经没有股票,即 d p [ i − 1 ] [ 0 ] dp[i−1][0] dp[i−1][0],或者前一天结束的时候手里持有一支股票,即 d p [ i − 1 ] [ 1 ] dp[i−1][1] dp[i−1][1],这时候我们要将其卖出,并获得 prices[i] 的收益。因此为了收益最大化,我们列出如下的转移方程:
d p [ i ] [ 0 ] = m a x d p [ i − 1 ] [ 0 ] , d p [ i − 1 ] [ 1 ] + p r i c e s [ i ] dp[i][0]=max{dp[i−1][0],dp[i−1][1]+prices[i]} dp[i][0]=maxdp[i−1][0],dp[i−1][1]+prices[i]
再来考虑$ dp[i][1]$,按照同样的方式考虑转移状态,那么可能的转移状态为前一天已经持有一支股票,即 d p [ i − 1 ] [ 1 ] dp[i−1][1] dp[i−1][1],或者前一天结束时还没有股票,即 d p [ i − 1 ] [ 0 ] dp[i−1][0] dp[i−1][0],这时候我们要将其买入,并减少 prices[i] 的收益。可以列出如下的转移方程:
d p [ i ] [ 1 ] = m a x d p [ i − 1 ] [ 1 ] , d p [ i − 1 ] [ 0 ] − p r i c e s [ i ] dp[i][1]=max{dp[i−1][1],dp[i−1][0]−prices[i]} dp[i][1]=maxdp[i−1][1],dp[i−1][0]−prices[i]
对于初始状态,根据状态定义我们可以知道第 0 天交易结束的时候 d p [ 0 ] [ 0 ] = 0 dp[0][0]=0 dp[0][0]=0, d p [ 0 ] [ 1 ] = − p r i c e s [ 0 ] dp[0][1]=−prices[0] dp[0][1]=−prices[0]。
因此,我们只要从前往后依次计算状态即可。由于全部交易结束后,持有股票的收益一定低于不持有股票的收益,因此这时候 $dp[n−1][0] $的收益必然是大于 d p [ n − 1 ] [ 1 ] dp[n−1][1] dp[n−1][1] 的,最后的答案即为 d p [ n − 1 ] [ 0 ] dp[n−1][0] dp[n−1][0]。
class Solution {
public:int maxProfit(vector<int>& prices) {int n=prices.size();int dp[n][2];dp[0][0]=0;dp[0][1]=-prices[0];for(int i=1;i<n;++i){dp[i][0]=max(dp[i-1][0],dp[i-1][1]+prices[i]);dp[i][1]=max(dp[i-1][1],dp[i-1][0]-prices[i]);}return dp[n-1][0];}
};
时间复杂度:O(n),其中 n 为数组的长度。一共有 2n 个状态,每次状态转移的时间复杂度为 O(1),因此时间复杂度为 O(2n)=O(n)。
空间复杂度:O(n)。我们需要开辟 O(n) 空间存储动态规划中的所有状态。如果使用空间优化,空间复杂度可以优化至 O(1)。
优化空间复杂度
注意到上面的状态转移方程中,每一天的状态只与前一天的状态有关,而与更早的状态都无关,因此我们不必存储这些无关的状态,只需要将 d p [ i − 1 ] [ 0 ] dp[i−1][0] dp[i−1][0] 和 d p [ i − 1 ] [ 1 ] dp[i−1][1] dp[i−1][1] 存放在两个变量中,通过它们计算出 d p [ i ] [ 0 ] dp[i][0] dp[i][0] 和 d p [ i ] [ 1 ] dp[i][1] dp[i][1] 并存回对应的变量,以便于第 i+1 天的状态转移即可。
class Solution {
public:int maxProfit(vector<int>& prices) {int n = prices.size();int dp0 = 0, dp1 = -prices[0];for (int i = 1; i < n; ++i) {int newDp0 = max(dp0, dp1 + prices[i]);int newDp1 = max(dp1, dp0 - prices[i]);dp0 = newDp0;dp1 = newDp1;}return dp0;}
};
解法二:贪心算法
122. 买卖股票的最佳时机 II - 力扣(LeetCode)
9. 跳跃游戏

解法:贪心算法
我们可以用贪心的方法解决这个问题。
设想一下,对于数组中的任意一个位置 y,我们如何判断它是否可以到达?根据题目的描述,只要存在一个位置 x,它本身可以到达,并且它跳跃的最大长度为 x+nums[x],这个值大于等于 yyy,即 x+nums[x]≥y,那么位置 y 也可以到达。
换句话说,对于每一个可以到达的位置 x,它使得 x+1,x+2,⋯ ,x+nums[x] 这些连续的位置都可以到达。
这样以来,我们依次遍历数组中的每一个位置,并实时维护 最远可以到达的位置。对于当前遍历到的位置 x,如果它在 最远可以到达的位置 的范围内,那么我们就可以从起点通过若干次跳跃到达该位置,因此我们可以用 x+nums[x] 更新 最远可以到达的位置。
在遍历的过程中,如果 最远可以到达的位置 大于等于数组中的最后一个位置,那就说明最后一个位置可达,我们就可以直接返回 True 作为答案。反之,如果在遍历结束后,最后一个位置仍然不可达,我们就返回 False 作为答案。
以题目中的示例一
[2, 3, 1, 1, 4]
为例:
我们一开始在位置 0,可以跳跃的最大长度为 2,因此最远可以到达的位置被更新为 2;
我们遍历到位置 1,由于 1≤2,因此位置 1 可达。我们用 1 加上它可以跳跃的最大长度 3,将最远可以到达的位置更新为 4。由于 4 大于等于最后一个位置 4,因此我们直接返回 True。
我们再来看看题目中的示例二
[3, 2, 1, 0, 4]
我们一开始在位置 0,可以跳跃的最大长度为 3,因此最远可以到达的位置被更新为 3;
我们遍历到位置 1,由于 1≤3,因此位置 1可达,加上它可以跳跃的最大长度 2 得到 3,没有超过最远可以到达的位置;
位置 2、位置 3 同理,最远可以到达的位置不会被更新;
我们遍历到位置 4,由于 4>3,因此位置 4 不可达,我们也就不考虑它可以跳跃的最大长度了。
在遍历完成之后,位置 4 仍然不可达,因此我们返回 False。
class Solution {
public:bool canJump(vector<int>& nums) {int n=nums.size();int rightMost=0;for(int i=0;i<n;i++){if(i<=rightMost){rightMost=max(rightMost,i+nums[i]);if(rightMost>=n-1)return true;}}return false;}
};
时间复杂度:O(n),其中 n 为数组的大小。只需要访问 nums 数组一遍,共 n 个位置。
空间复杂度:O(1),不需要额外的空间开销。
10. 跳跃游戏II

解法:贪心 正向查找可到达的最大位置
如果我们「贪心」地进行正向查找,每次找到可到达的最远位置,就可以在线性时间内得到最少的跳跃次数。
例如,对于数组 [2,3,1,2,4,2,3],初始位置是下标 0,从下标 0 出发,最远可到达下标 2。下标 0 可到达的位置中,下标 1 的值是 3,从下标 1 出发可以达到更远的位置,因此第一步到达下标 1。
从下标 1 出发,最远可到达下标 4。下标 1 可到达的位置中,下标 4 的值是 4 ,从下标 4 出发可以达到更远的位置,因此第二步到达下标 4。
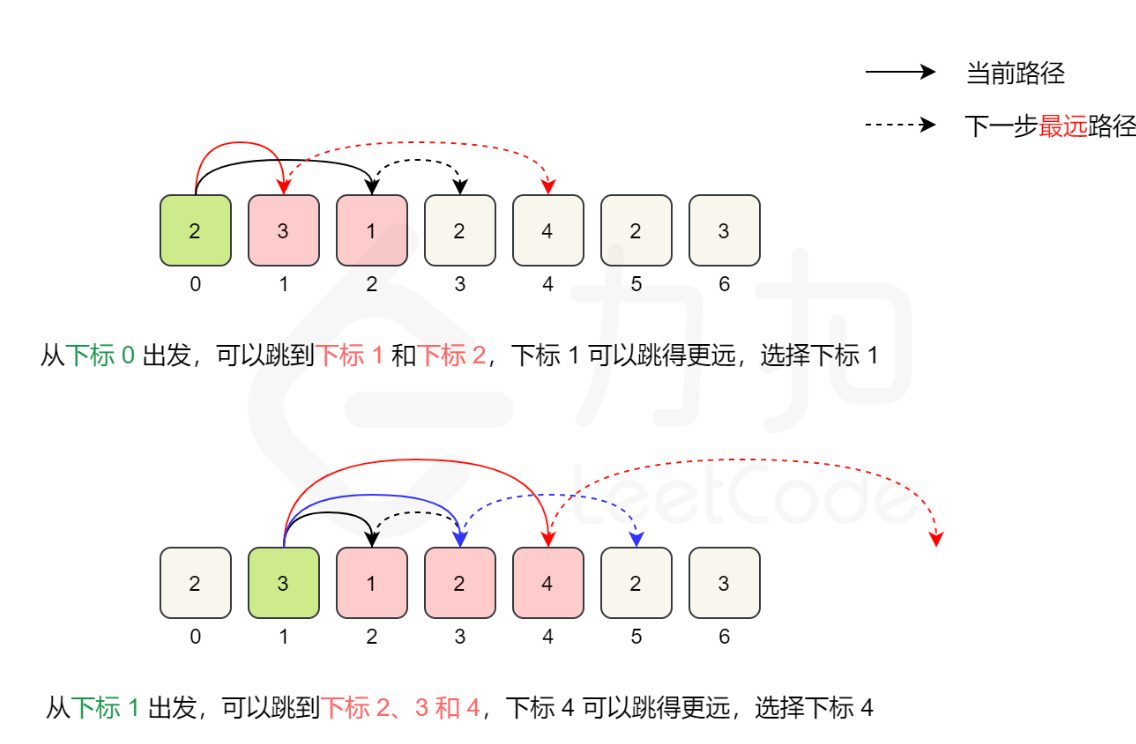
在具体的实现中,我们维护当前能够到达的最大下标位置,记为边界。我们从左到右遍历数组,到达边界时,更新边界并将跳跃次数增加 1。
在遍历数组时,我们不访问最后一个元素,这是因为在访问最后一个元素之前,我们的边界一定大于等于最后一个位置,否则就无法跳到最后一个位置了。如果访问最后一个元素,在边界正好为最后一个位置的情况下,我们会增加一次「不必要的跳跃次数」,因此我们不必访问最后一个元素。
end 维护的是当前这一跳能达到的最右位置,若要超过该位置必须要进行一次跳跃,因此需将跳跃次数加1,并更新这次跳跃能到达的最右位置
class Solution {
public:int jump(vector<int>& nums) {int max_far=0;//目前能够跳到的最远位置int step=0;//跳跃次数int end=0;//上次跳跃可达范围右边界(下次的最右起跳点)for(int i=0;i<nums.size()-1;i++){max_far=max(max_far,i+nums[i]);//到达上次跳跃能到达的右边界了if(i==end){end=max_far;//目前能到达的最远位置变成下次起跳位置的右边界step++;//进入下一次跳跃}}return step;}
};
- 时间复杂度:O(n),其中 n 是数组长度。
- 空间复杂度:O(1)。
11. H 指数
解法一:排序
首先我们可以将初始的}H 指数 h 设为 0,然后将引用次数排序,并且对排序后的数组从大到小遍历。
根据H 指数的定义,如果当前H 指数为 h 并且在遍历过程中找到当前值citations[i]>h,则说明我们找到了一篇被引用了至少 h+1 次的论文,所以将现有的 h 值加 1。继续遍历直到 h 无法继续增大。最后返回 h 作为最终答案。
class solution_9 {
public:int hIndex(vector<int>& citations) {sort(citations.begin(),citations.end());int n=citations.size()-1;int h=0;while(n>=0&&citations[n]>h){h++;n--;}return h;}
};时间复杂度:O(nlogN)
空间复杂度: O(log n)排序的空间复杂度
解法二:计数排序
根据上述解法我们发现,最终的时间复杂度与排序算法的时间复杂度有关,所以我们可以使用计数排序算法,新建并维护一个数组 counter 用来记录当前引用次数的论文有几篇。
根据定义,我们可以发现 H 指数不可能大于总的论文发表数,所以对于引用次数超过论文发表数的情况,我们可以将其按照总的论文发表数来计算即可。这样我们可以限制参与排序的数的大小为 [0,n](其中 n 为总的论文发表数),使得计数排序的时间复杂度降低到 O(n)。
最后我们可以从后向前遍历数组 counter,对于每个 0≤i≤n,在数组 counter 中得到大于或等于当前引用次数 i 的总论文数。当我们找到一个 H 指数时跳出循环,并返回结果。
注意:官方给出的counter是使用vector数组的形式声明,vectorcounter(n+1)
但是我在实现的时候,使用的是int counter[n+1],所以必须注意此时需要将counter数组初始化。
class Solution {
public:int hIndex(vector<int>& citations) {int n = citations.size(), tot = 0;int counter[n+1];fill(counter,counter+n+1,0);for (int i = 0; i < n; i++) {if (citations[i] >= n) {counter[n]++;} else {counter[citations[i]]++;}}for (int i = n; i >= 1; i--) {tot += counter[i];if (tot >= i) {return i;}}return 0;}
};时间复杂度:O(n)其中 n 为数组citations 的长度。需要遍历数组
空间复杂度:O(n)其中 nn 为数组citations 的长度。需要创建长度为n+1 的数组counter。
12. O(1)时间插入、删除和获取随机元素


解法一:vector+哈希表
这道题要求实现一个类,满足插入、删除和获取随机元素操作的平均时间复杂度为 O(1)。
变长数组可以在 O(1) 的时间内完成获取随机元素操作,但是由于无法在 O(1) 的时间内判断元素是否存在,因此不能在 O(1) 的时间内完成插入和删除操作。哈希表可以在 O(1) 的时间内完成插入和删除操作,但是由于无法根据下标定位到特定元素,因此不能在 O(1) 的时间内完成获取随机元素操作。为了满足插入、删除和获取随机元素操作的时间复杂度都是 O(1),需要将变长数组和哈希表结合,变长数组中存储元素,哈希表中存储每个元素在变长数组中的下标。
插入操作时,首先判断 val 是否在哈希表中,如果已经存在则返回 false,如果不存在则插入 val,操作如下:
- 在变长数组的末尾添加 val;
- 在添加 val 之前的变长数组长度为 val 所在下标 index,将 val 和下标 index 存入哈希表;返回 true。
删除操作时,首先判断 val 是否在哈希表中,如果不存在则返回 false,如果存在则删除 val,操作如下:
- 从哈希表中获得 val 的下标 index;
- 将变长数组的最后一个元素 last 移动到下标 index 处,在哈希表中将 last 的下标更新为 index;
- 在变长数组中删除最后一个元素,在哈希表中删除 val;返回 true。
- 删除操作的重点在于将变长数组的最后一个元素移动到待删除元素的下标处,然后删除变长数组的最后一个元素。该操作的时间复杂度是 O(1),且可以保证在删除操作之后变长数组中的所有元素的下标都连续,方便插入操作和获取随机元素操作。
获取随机元素操作时,由于变长数组中的所有元素的下标都连续,因此随机选取一个下标,返回变长数组中该下标处的元素。
- 还要注意,随机返回一个元素的时候,rand需要指定种子,不然返回的随机数不一样会通过不了案例
代码:
class RandomizedSet {
public:RandomizedSet() {}bool insert(int val) {if(valToIndex.count(val)){return false;}int index=nums.size();nums.emplace_back(val);valToIndex[val]=index;return true;}bool remove(int val) {if(!valToIndex.count(val))return false;int index=valToIndex[val];valToIndex[nums.back()]=index;nums[index]=nums.back();nums.pop_back();valToIndex.erase(val);return true;}int getRandom() {int randIndex=rand()%nums.size();return nums[randIndex];}vector<int>nums;unordered_map<int,int>valToIndex;
};/*** Your RandomizedSet object will be instantiated and called as such:* RandomizedSet* obj = new RandomizedSet();* bool param_1 = obj->insert(val);* bool param_2 = obj->remove(val);* int param_3 = obj->getRandom();*/
- 时间复杂度:初始化和各项操作的时间复杂度都是 O(1)。
- 空间复杂度:O(n),其中 n 是集合中的元素个数。存储元素的数组和哈希表需要 O(n) 的空间。
13. 除自身以外数组的乘积
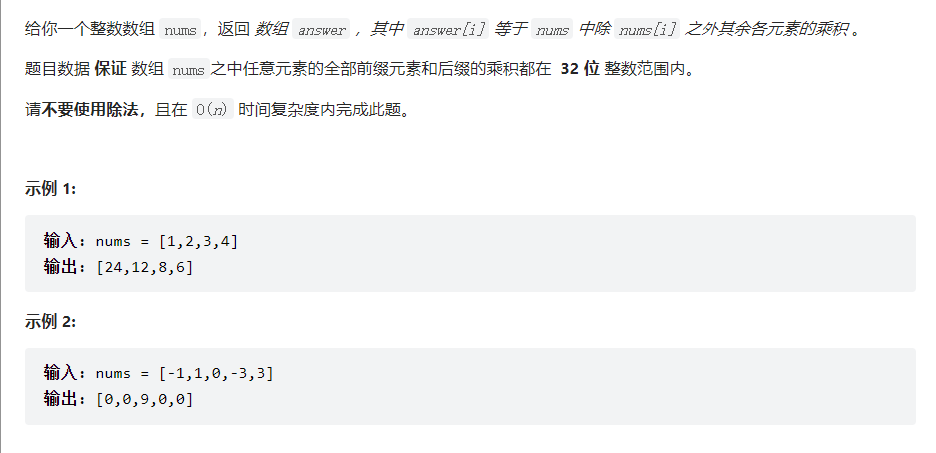
解法:注意题目要求不能使用除法,如果要求一个nums中除nums[i]之外的其余各元素的乘积。
一种方法是所有乘积除以nums[i],因为题目要求不能使用除法,所以这种方法不行。
因此可以换一种方式:nums[i]的左侧的数字乘积乘以nums[i]右侧的数字乘积。
通过预处理的方式得到两个数组,分别表示索引i位置左侧的乘积和右侧的乘积。
初始化两个空数组 L 和 R。对于给定索引 i,L[i] 代表的是 i 左侧所有数字的乘积,R[i] 代表的是 i 右侧所有数字的乘积。
用两个循环来填充 L 和 R 数组的值。对于数组 L,L[0] 应该是 1,因为第一个元素的左边没有元素。对于其他元素:L[i] = L[i-1] * nums[i-1]。
同理,对于数组 R,R[nums.size()-1] 应为 1。length 指的是输入数组的大小。
其他元素:R[i] = R[i+1] * nums[i+1]。
当 R 和 L 数组填充完成,我们只需要在输入数组上迭代,且索引 i 处的值为:L[i] * R[i]。
代码:
class solution_28 {
public:vector<int> productExceptSelf(vector<int>& nums) {vector<int>result(nums.size());vector<int>left(nums.size(),0);vector<int>right(nums.size(),0);left[0]=1;//left[i]表示索引i左侧所有元素乘积for(int i=1;i<nums.size();i++){left[i]=left[i-1]*nums[i-1];}right[nums.size()-1]=1;//right[i]表示索引i右侧所有元素乘积for(int i=nums.size()-2;i>=0;i--){right[i]=right[i+1]*nums[i+1];}for(int i=0;i<nums.size();i++){result[i]=left[i]*right[i];}return result;}
};时间复杂度:O(N),其中 N 指的是数组 nums 的大小。预处理 L 和 R 数组以及最后的遍历计算都是 O(N) 的时间复杂度。
空间复杂度:O(N),其中 N指的是数组 nums 的大小。使用了 L 和 R 数组去构造答案,L 和 R 数组的长度为数组 nums 的大小。
14. 加油站

解法:贪心+一次遍历
最容易想到的解法就是一次遍历,从头到尾遍历每个加油站,并检查该加油站为起点,最终能否行驶一周。我们可以通过减少被检查的加油站数目,来降低总的时间复杂度。
即假设从x开始行驶,无法到达y的下一站,那么[x,y]的中间某一点为起始点也肯定无法到达y的下一站,官方题解中包含详细证明:
134. 加油站 - 力扣(LeetCode)
直观的理解:如果能从x到达y的话,那么从x到达(x,y)中间任何一站时剩余的油量肯定都是>=0的,否则便无法一直到达y。
举例,从a出发,经过b,到达c,油量不够无法到达d。从a到达b的时候,剩余油量最坏的情况也是=0,而如果直接从b出发,初始油量只能=0。从a出发,在到达b点的时候油量还能>=0,无法到达d点;而如果直接从b点出发,此时初始油量=0,就更不可能到达d点了。
因此,在一次遍历起始点的时候,假如x为起始点,遍历到y时,无法到达y的下一个节点;那么下次遍历的起点就可以改为y+1
代码:
class Solution {
public:int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {int i=0;int n=gas.size();while(i<n){int sumGas=0,sumCost=0;int cnt=0;while(cnt<n){int j=(i+cnt)%n;sumGas+=gas[j];sumCost+=cost[j];if(sumCost>sumGas){break;}cnt++;}if(cnt==n){return i;}elsei=i+cnt+1;}return -1;}
};
- 时间复杂度:O(N),其中 N 为数组的长度。我们对数组进行了单次遍历。
- 空间复杂度:O(1)。
15. 分发糖果

解法一:贪心算法
规则定义: 设学生 A 和学生 B 左右相邻,A在 B 左边;
左规则: 当 ratings[B]>ratings[A]时候,B 的糖比 A 的糖数量多。
右规则: 当 ratings[A]>ratings[B]时,A 的糖比 B 的糖数量多。
相邻的学生中,评分高的学生必须获得更多的糖果 等价于 所有学生满足左规则且满足右规则。
根据以上规则,我们可以从左向右按照左规则遍历一遍,再从右向左按照右规则遍历一遍;之后每次都取位置i的糖果最大数目,可以保证即满足左规则又满足了右边规则;
算法流程:
- 先从左至右遍历学生成绩 ratings,按照以下规则给糖,并记录在 left 中,先给所有学生 1颗糖;
- 若 ratings[i]>ratings[i−1],则第 i名学生糖比第 i−1 名学生多 1 个。
- 若 ratings[i]<=ratings[i−1] ,则第 i名学生糖数量不变。(交由从右向左遍历时处理。)
经过此规则分配后,可以保证所有学生糖数量 满足左规则 。
同理,在此规则下从右至左遍历学生成绩并记录在 right 中,可以保证所有学生糖数量 满足右规则 。
最终,取以上 2轮遍历 left 和 right 对应学生糖果数的最大值 ,这样则 同时满足左规则和右规则 ,即得到每个同学的最少糖果数量。
【此过程可以在从右往左遍历右规则时完成】
代码:
class Solution {
public:int candy(vector<int>& ratings) {int n=ratings.size();int left[n];std::fill(left,left+n,1);int right[n];std::fill(right,right+n,1);for(int i=1;i<n;i++){if(ratings[i]>ratings[i-1]){left[i]=left[i-1]+1;}}int count=left[n-1];for(int i=n-2;i>=0;i--){if(ratings[i]>ratings[i+1]){
#从右边往左时候,递归记录的是最后一个位置的糖果个数,一直递归影响到前面位置的糖果个数 right[i]=right[i+1]+1;}count+=max(left[i],right[i]);}return count;}
};
时间复杂度:O(n),其中 n 是孩子的数量。我们需要遍历两次数组以分别计算满足左规则或右规则的最少糖果数量。
空间复杂度:O(n),其中 n 是孩子的数量。我们需要保存所有的左规则对应的糖果数量。
解法二:常数空间遍历
参考力扣官方题解:135. 分发糖果 - 力扣(LeetCode)
注意到糖果总是尽量少给,且从 11开始累计,每次要么比相邻的同学多给一个,要么重新置为 1。依据此规则,我们可以画出下图:
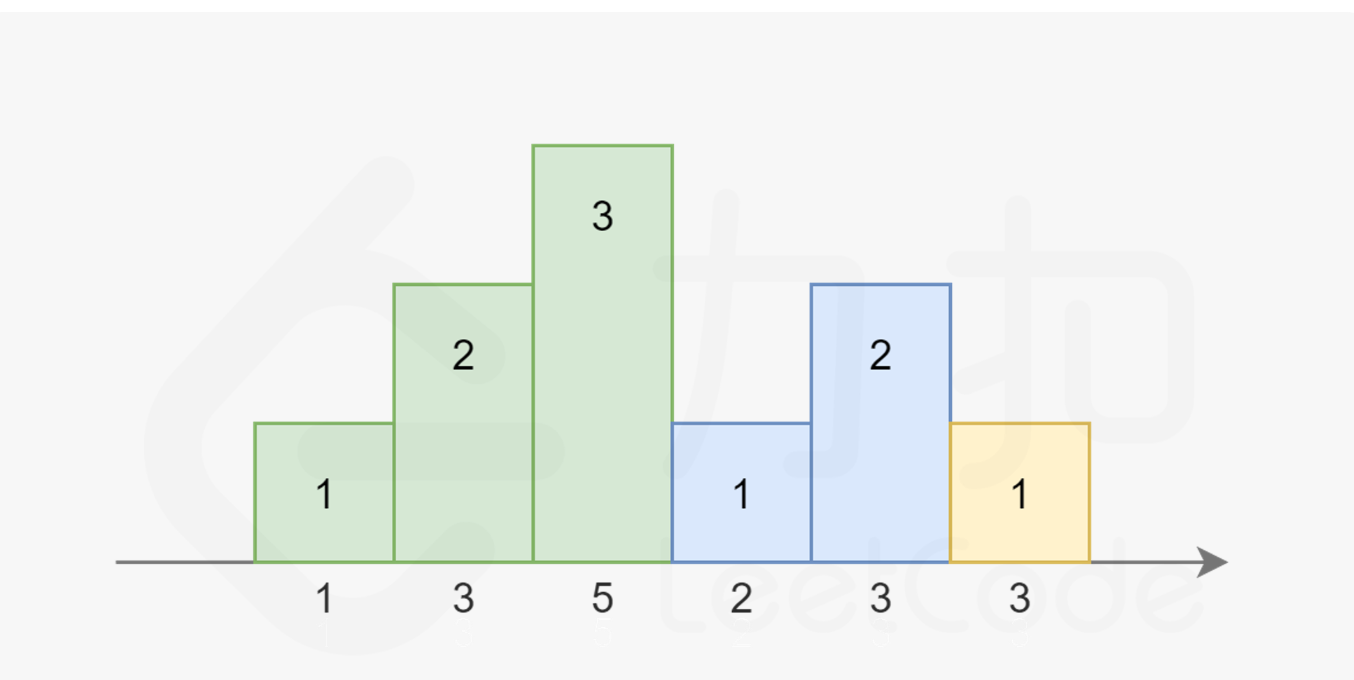
-
上述为例子[1,3,5,2,3,3]的最后的解
-
其中相同颜色的柱状图的高度总恰好为 1,2,3…。
而高度也不一定一定是升序,也可能是 …3,2,1的降序: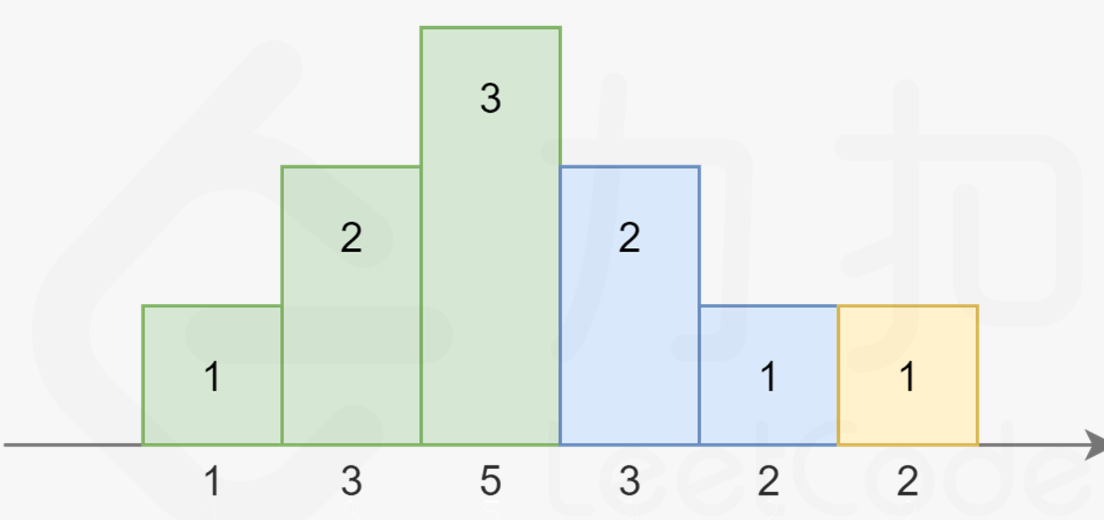
-
上述为数组[1,3,5,3,2,2]的解
-
注意到在上图中,对于第三个同学,他既可以被认为是属于绿色的升序部分,也可以被认为是属于蓝色的降序部分。因为他同时比两边的同学评分更高。我们对序列稍作修改:
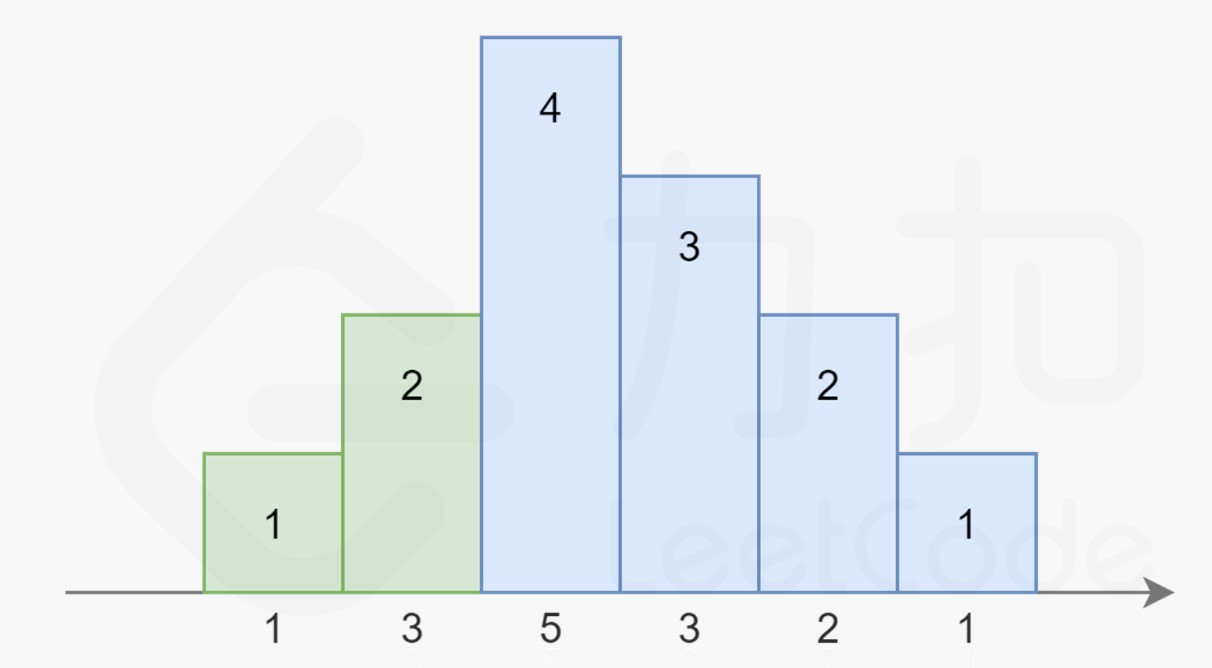
-
注意到右边的升序部分变长了,使得第三个同学不得不被分配 4个糖果。
-
依据前面总结的规律,我们可以提出本题的解法。我们从左到右枚举每一个同学,记前一个同学分得的糖果数量为 pre:
-
如果当前同学比上一个同学评分高,说明我们就在最近的递增序列中,直接分配给该同学 pre+1 个糖果即可。
-
否则我们就在一个递减序列中,我们直接分配给当前同学一个糖果,并把该同学所在的递减序列中所有的同学都再多分配一个糖果,以保证糖果数量还是满足条件。
-
我们无需显式地额外分配糖果,只需要记录当前的递减序列长度,即可知道需要额外分配的糖果数量。
-
同时注意当当前的递减序列长度和上一个递增序列等长时,需要把最近的递增序列的最后一个同学也并进递减序列中。
-
这样,我们只要记录当前递减序列的长度 dec,最近的递增序列的长度 inc 和前一个同学分得的糖果数量 pre 即可。
代码:
class Solution {
public:int candy(vector<int>& ratings) {int n=ratings.size();int ret=1;int inc=1,dec=0,pre=1;for(int i=1;i<n;i++){if(ratings[i]>=ratings[i-1]){//将递减序列的个数清0dec=0;pre=ratings[i]==ratings[i-1]?1:pre+1;ret+=pre;inc=pre;}else{//递减序列,记录递减序列的值dec++;//标志位置相同,如123321,此时递增序列的末尾3必须加1,合并到递减序列中if(dec==inc){dec++;}ret+=dec;//pre还原为初始值1,为了后续递增准备pre=1;}}return ret;}
};
时间复杂度:O(n),其中 n 是孩子的数量。我们需要遍历两次数组以分别计算满足左规则或右规则的最少糖果数量。
空间复杂度:O(1)。我们只需要常数的空间保存若干变量。
16. 接雨水

解法一:动态规划
按照列进行计算,可以看到第一列和最后一列肯定不能装水,那么中间的列可以装多少水,取决于它的左右两边。
求每一列的水,我们只需要关注当前列,以及左边最高的墙,右边最高的墙就够了。
装水的多少,当然根据木桶效应,我们只需要看左边最高的墙和右边最高的墙中较矮的一个就够了。
所以,根据较矮的那个墙和当前列的墙的高度可以分为三种情况。
1.较矮的墙的高度大于当前列的墙的高度。
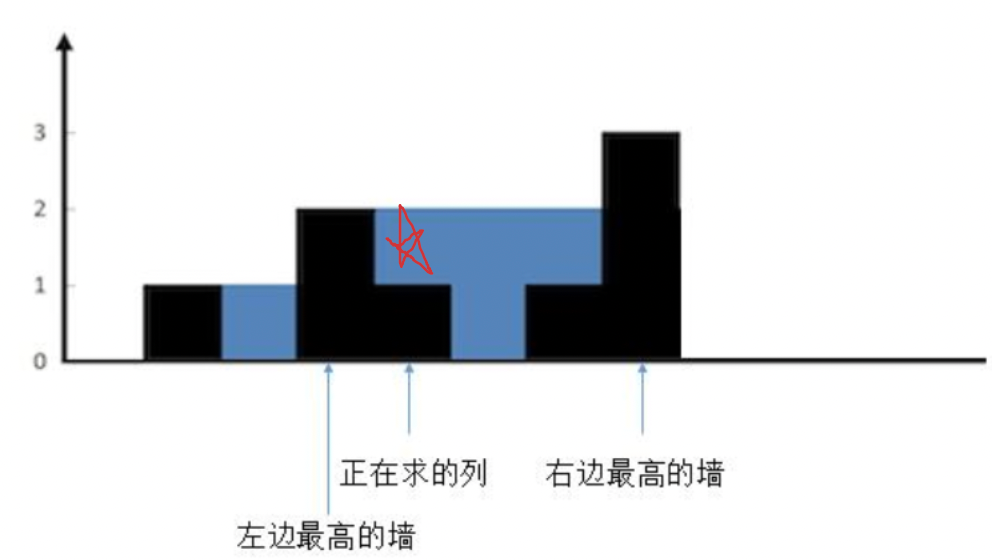
这样就很清楚了,现在想象一下,往两边最高的墙之间注水。正在求的列会有多少水?
很明显,较矮的一边,也就是左边的墙的高度,减去当前列的高度就可以了,也就是 2 - 1 = 1,可以存一个单位的水。
2.较矮的墙的高度小于当前列的墙的高度
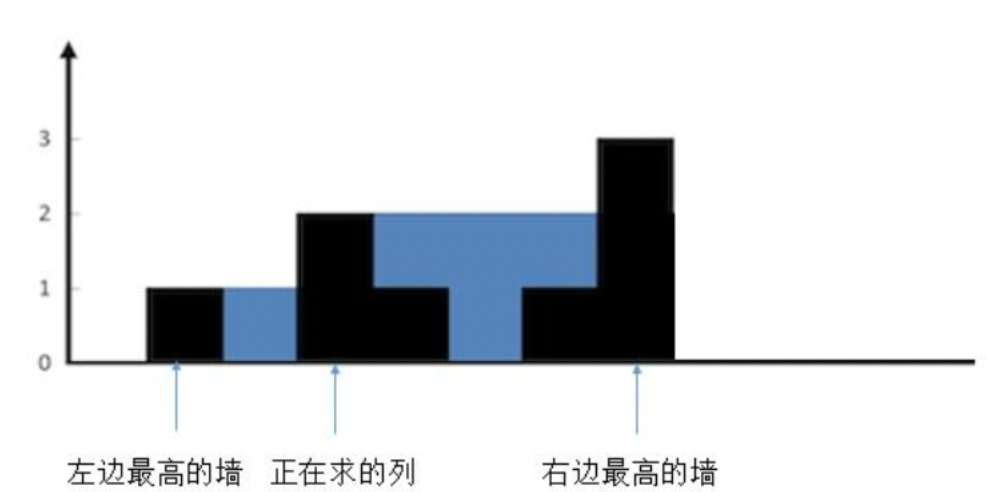
想象下,往两边最高的墙之间注水。正在求的列会有多少水?
正在求的列不会有水,因为它大于了两边较矮的墙。
3.较矮的墙的高度等于当前列的墙的高度
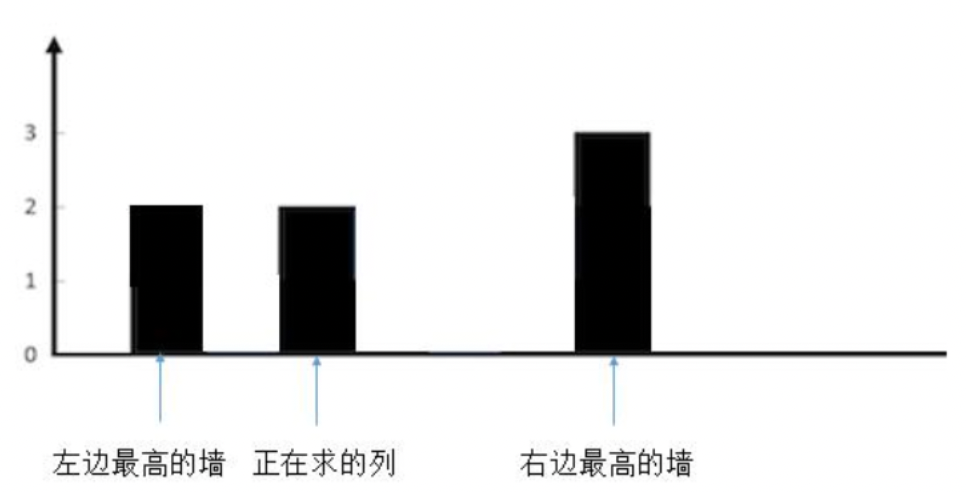
和第二种情况一样不会有水
因为求每列左边最高的墙和右边最高的墙的解法重复,其实可以使用动态规划的解法
- max_left [i] 代表第 i 列左边最高的墙的高度,max_right[i] 代表第 i 列右边最高的墙的高度。
- max_left [i] = Max(max_left [i-1],height[i-1])。它前边的墙的左边的最高高度和它前边的墙的高度选一个较大的,就是当前列左边最高的墙了。
- 而max_right[i] = Max(max_right[i+1],height[i+1]) 。它后边的墙的右边的最高高度和它后边的墙的高度选一个较大的,就是当前列右边最高的墙了。
- 同时可以知道max_left[0]=0,和max_right[height-1]=0,可以作为初始条件。
- 之后使用for循环找到每一类的max_left和max_right的最小值与自己作比较,如果最小值比自己大,那么可以装水,否则不行。
注意特殊情况判断,因为max_left涉及i-1的判断,如果height的个数为1,那么i-1会溢出,因此对于height.size()=0或者1的情况,直接返回0
代码:
class Solution {
public:int trap(vector<int>& height) {int result=0;int n=height.size();if(n==0||n==1)return 0;int max_left[n];int max_right[n];max_left[0]=max_right[n-1]=0;//最左边和最右边不用考虑,因此只需求出每一列的左边最高和右边最高for(int i=1;i<=height.size()-2;i++){max_left[i]=max(max_left[i-1],height[i-1]);}for(int i=height.size()-2;i>=1;i--){max_right[i]=max(max_right[i+1],height[i+1]);}for(int i=1;i<=height.size()-2;i++){int min_height=min(max_left[i],max_right[i]);if(min_height>height[i])result=result+(min_height-height[i]);}return result;}
};
时间复杂度:O(n)
空间复杂度:O(n)
解法二:优化双指针+动态规划
注意到下标 i 处能接的雨水量由 leftMax[i]和 rightMax[i]中的最小值决定。由于数组 eftMax 是从左往右计算,数组 rightMax 是从右往左计算,因此可以使用双指针和两个变量代替两个数组。
维护两个指针 left 和 right,以及两个变量 leftMax 和 rightMax,初始时 left=0,right=n−1,leftMax=0,rightMax=0。指针 left 只会向右移动,指针 right只会向左移动,在移动指针的过程中维护两个变量 eftMax 和rightMax 的值。
当两个指针没有相遇时,进行如下操作:
- 使用 height[left]和 height[right]的值更新 leftMax和 rightMax的值;
- 如果 height[left]<height[right],则必有 leftMax<rightMax,下标 left 处能接的雨水量等于 leftMax−height[left],将下标 left 处能接的雨水量加到能接的雨水总量,然后将 left加 1(即向右移动一位);
- 如果 height[left]≥height[right],则必有 leftMax≥rightMax,下标 right处能接的雨水量等于 rightMax−height[right],将下标 right\textit{right}right 处能接的雨水量加到能接的雨水总量,然后将 right 减 1(即向左移动一位)。
当两个指针相遇时,即可得到能接的雨水总量
对于官方题解中的一些解释:height[left]<height[right],则必有 leftMax<rightMax,相信这句话刚开始看很难理解,
但是我们换种方式思考一下,与11.盛水最多的容器相结合,由于每列中能接的雨水,是由左右两边最高的墙中的最小值决定的。
初始化时,leftMax=height[0],rightMax=height[n-1],能盛水的多少是由短板决定的,那么我们假设此时leftMax<rightMax的话,那么此时left能接到的雨水量为leftMax-height[0],初始化为0;
那么为了确定下一个和rightMax相比的最小值,我们移动left指针,此时的height[left]>=LeftMax,因此假如height[left]<height[right],由于是因为leftMax<rightMax,我们才移动的,此时一定能得到当前的leftMax<rightMax;
反之亦然
代码:
class Solution {
public:int trap(vector<int>& height) {int ans=0;int left=0,right=height.size()-1;int leftMax=0,rightMax=0;while(left<right){leftMax=max(leftMax,height[left]);rightMax=max(rightMax,height[right]);if(height[left]<height[right]){ans+=leftMax-height[left];left++;}else{ans+=rightMax-height[right];right--;}}return ans;}
};
时间复杂度:O(n)
空间复杂度:O(1)
解法三:单调栈
单调递减栈
- 理解题目,注意题目的性质,当后面的柱子高度比前面的低时,是无法接雨水的,当找到一根比前面高的柱子,就可以计算接到的雨水
所以使用单调递减栈,对更低的柱子入栈 - 更低的柱子以为这后面如果能找到高柱子,这里就能接到雨水,所以入栈把它保存起来
- 平地相当于高度 0 的柱子,没有什么特别影响
- 当出现高于栈顶的柱子时,说明可以对前面的柱子结算了
- 计算已经到手的雨水,然后出栈前面更低的柱子
注意:计算雨水的时候,雨水区域的右边 r 指的自然是当前索引 i 底部是栈顶 st.top() ,因为遇到了更高的右边,所以它即将出栈,使用 cur 来记录它,并让它出栈,左边 l 就是新的栈顶 st.top(),雨水的区域全部确定了,水坑的高度就是左右两边更低的一边减去底部,宽度是在左右中间
使用乘法即可计算面积
class Solution {
public:int trap(vector<int>& height) {int ans=0;stack<int>st;for(int i=0;i<height.size();i++){while(!st.empty()&&height[st.top()]<height[i]){int cur=st.top();st.pop();if(st.empty())break;int minHieght=min(height[st.top()],height[i])-height[cur];ans+=(i-st.top()-1)*minHieght;}st.push(i);}return ans;}
};
时间复杂度:O(n),其中 n 是数组height 的长度。从 0 到 n−1 的每个下标最多只会入栈和出栈各一次。
空间复杂度:O(n),其中 n 是数组height 的长度。空间复杂度主要取决于栈空间,栈的大小不会超过n
17. 罗马数转整数



解法一: 模拟
思路
通常情况下,罗马数字中小的数字在大的数字的右边。若输入的字符串满足该情况,那么可以将每个字符视作一个单独的值,累加每个字符对应的数值即可。
例如 XXVII 可视作 X+X+V+I+I=10+10+5+1+1=27。
若存在小的数字在大的数字的左边的情况,根据规则需要减去小的数字。对于这种情况,我们也可以将每个字符视作一个单独的值,若一个数字右侧的数字比它大,则将该数字的符号取反。
例如 XIV 可视作 X−I+V=10−1+5=14。
代码 :
class Solution {
public:unordered_map<char,int>romanToNum={{'I',1},{'V',5},{'X',10},{'L',50},{'C',100},{'D',500},{'M',1000},};int romanToInt(string s) {int sum=0;int n=s.size();for(int i=0;i<n;i++){int value=romanToNum[s[i]];if(i<n-1&&value<romanToNum[s[i+1]]){sum-=value;}else{sum+=value;}}return sum;}
};
- 时间复杂度:O(n),其中 n 是字符串 s 的长度。
- 空间复杂度:O(1)。
18. 整数转罗马数字



解法一:模拟
罗马数字符号
罗马数字由 7 个不同的单字母符号组成,每个符号对应一个具体的数值。此外,减法规则(如问题描述中所述)给出了额外的 6 个复合符号。这给了我们总共 13 个独特的符号(每个符号由 1 个或 2 个字母组成),如下图所示。
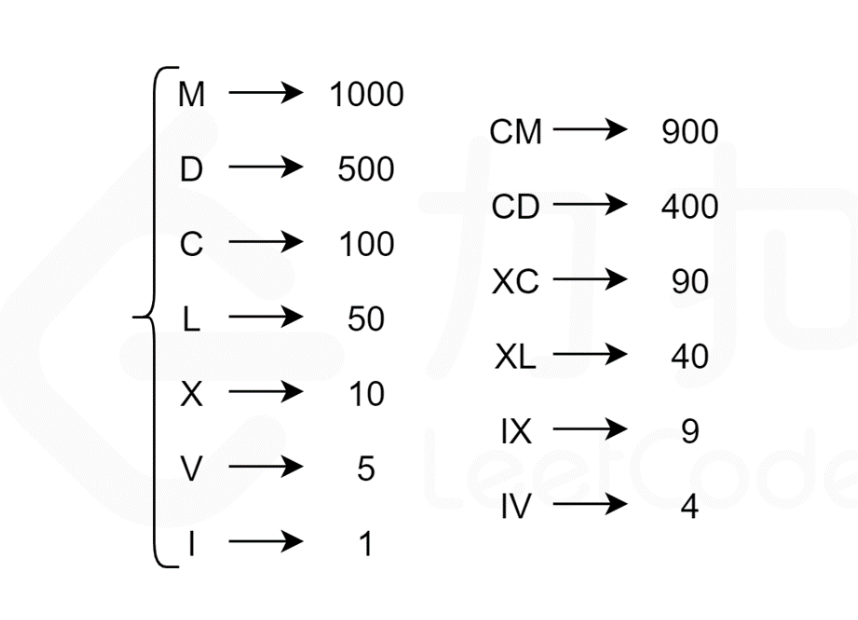
根据罗马数字的唯一表示法,为了表示一个给定的整数 num,我们寻找不超过 num 的最大符号值,将 num 减去该符号值,然后继续寻找不超过 num 的最大符号值,将该符号拼接在上一个找到的符号之后,循环直至 num 为 0。最后得到的字符串即为 num 的罗马数字表示。
编程时,可以建立一个数值-符号对的列表 valueSymbols,按数值从大到小排列。遍历 valueSymbols 中的每个数值-符号对,若当前数值 value 不超过 num,则从 num 中不断减去 value,直至 num 小于 value,然后遍历下一个数值-符号对。若遍历中 num 为 0 则跳出循环。
class Solution {
public:string intToRoman(int num) {int value[]={1000,900,500,400,100,90,50,40,10,9,5,4,1};string reps[]={"M","CM","D","CD","C","XC","L","XL","X","IX","V","IV","I"};string res;for(int i=0;i<13;i++){while(num>=value[i]){num-=value[i];res+=reps[i];if(num==0)break;}}return res;}
};
时间复杂度:O(1)。由于 valueSymbols 长度是固定的,且这 13 字符中的每个字符的出现次数均不会超过 3,因此循环次数有一个确定的上限。对于本题给出的数据范围,循环次数不会超过 15 次。
空间复杂度:O(1)。
解法二:硬编码数字
12. 整数转罗马数字 - 力扣(LeetCode)
19. 最后一个单词的长度

解法:反向遍历
题目要求得到字符串中最后一个单词的长度,可以反向遍历字符串,寻找最后一个单词并计算其长度。
由于字符串中至少存在一个单词,因此字符串中一定有字母。首先找到字符串中的最后一个字母,该字母即为最后一个单词的最后一个字母。
从最后一个字母开始继续反向遍历字符串,直到遇到空格或者到达字符串的起始位置。遍历到的每个字母都是最后一个单词中的字母,因此遍历到的字母数量即为最后一个单词的长度。
class Solution {
public:int lengthOfLastWord(string s) {int index=s.size()-1;int count=0;while(s[index]==' '){index--;}while(index>=0&&s[index]!=' '){count++;index--;}return count;}
};
- 时间复杂度:O(n),其中 n 是字符串的长度。最多需要反向遍历字符串一次。
- 空间复杂度:O(1)。
20. 最长公共前缀

解法一:二分查找
显然,最长公共前缀的长度不会超过字符串数组中的最短字符串的长度。用 minLength 表示字符串数组中的最短字符串的长度,则可以在 [0,minLength] 的范围内通过二分查找得到最长公共前缀的长度。每次取查找范围的中间值 mid,判断每个字符串的长度为 mid 的前缀是否相同,如果相同则最长公共前缀的长度一定大于或等于 mid,如果不相同则最长公共前缀的长度一定小于 mid,通过上述方式将查找范围缩小一半,直到得到最长公共前缀的长度。
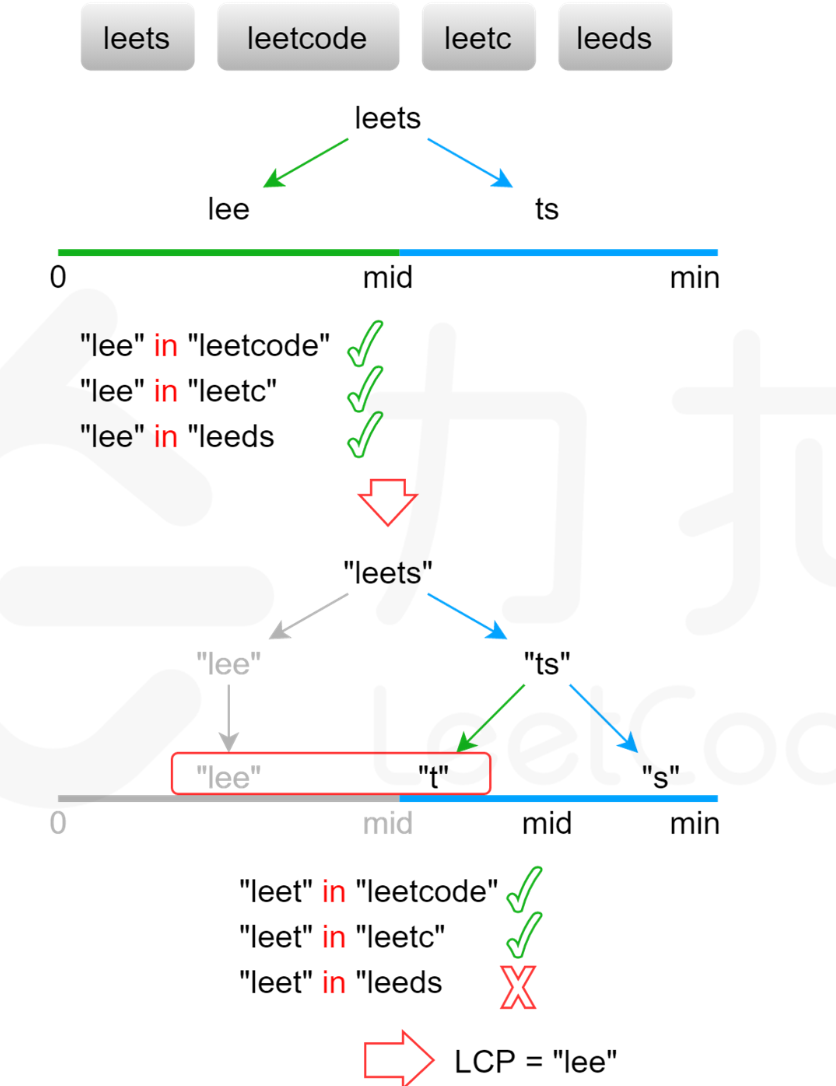
class Solution {
public:string longestCommonPrefix(vector<string>& strs) {if(!strs.size()){return "";}int minLength=INT_MAX;for(int i=0;i<strs.size();i++)minLength=min(minLength,(int)strs[i].size());int low=0,high=minLength;while(low<high){int mid=(high-low+1)/2+low;if(isComPrefix(strs,mid)){low=mid;}else{high=mid-1;}}return strs[0].substr(0,low);}bool isComPrefix(const vector<string>&strs,int length){string str0=strs[0].substr(0,length);int count=strs.size();for(int i=1;i<count;i++){string str=strs[i];for(int j=0;j<length;j++){if(str0[j]!=str[j])return false;}}return true;}
};
时间复杂度:O(mnlogm),其中 m 是字符串数组中的字符串的最小长度,n 是字符串的数量。二分查找的迭代执行次数是 O(logm),每次迭代最多需要比较 mn 个字符,因此总时间复杂度是 O(mnlogm)。
空间复杂度:O(1)。使用的额外空间复杂度为常数。
解法二:横向扫描;解法三:纵向扫描;解法四:分治
见:https://leetcode.cn/problems/longest-common-prefix/solutions/288575/zui-chang-gong-gong-qian-zhui-by-leetcode-solution/?envType=study-plan-v2&envId=top-interview-150
21. 反转字符串中的单词

解法一:使用c++语言string 的头插法,从s 的左边向右边遍历,遍历的结果按照头插法插入result
class Solution {
public:string reverseWords(string s) {string result;int index = 0;while (index < s.length()) {while (index < s.length() && s[index] == ' ') {index++;}int start = index;while (index < s.length() && s[index] != ' ') {index++;}if(index-start>0){string temp = s.substr(start, index - start);result.insert(0," ");result.insert(0, temp);}}result.erase(result.length() - 1,1);return result;}
};
- 时间复杂度:O(n),其中 n 为输入字符串的长度。
- 空间复杂度:O(1).
解法二:双端队列、解法三:利用语言特性
见:https://leetcode.cn/problems/reverse-words-in-a-string/solutions/194450/fan-zhuan-zi-fu-chuan-li-de-dan-ci-by-leetcode-sol/?envType=study-plan-v2&envId=top-interview-150
22. Z 字形变换
 字符串 s 是以 Z 字形为顺序存储的字符串,目标是按行打印。
字符串 s 是以 Z 字形为顺序存储的字符串,目标是按行打印。
设 numRows 行字符串分别为 s 1 , s 2 , … , s n s_1,s_2, … , s_n s1,s2,…,sn ,则容易发现:按顺序遍历字符串 s 时,每个字符 c 在 N 字形中对应的 行索引 先从 s 1 s_1 s1
增大至 s n s_n sn,再从 s n s_n sn减小至 s 1 s_1 s1…… 如此反复。
因此解决方案为:模拟这个行索引的变化,在遍历 s 中把每个字符填到正确的行 res[i] 。
算法流程:
- 按顺序遍历字符串 s :
- res[i] += c: 把每个字符 c 填入对应行 s i s_i si;
- i += flag: 更新当前字符 c 对应的行索引;
- flag = - flag: 在达到 Z 字形转折点时,执行反向。
class Solution {
public:string convert(string s, int numRows) {if (numRows < 2)return s;vector<string> rows(numRows);int i = 0, flag = -1;for (char c : s) {rows[i].push_back(c);if (i == 0 || i == numRows -1)flag = - flag;i += flag;}string res;for (const string &row : rows)res += row;return res;}
};
- 时间复杂度 O(N):遍历一遍字符串
s; - 空间复杂度 O(N) :各行字符串共占用 O(N) 额外空间。
23. 找出字符串中第一个匹配项的下标

解法一:简单双重遍历
直观的解法的是:枚举原串 ss 中的每个字符作为「发起点」,每次从原串的「发起点」和匹配串的「首位」开始尝试匹配:
- 匹配成功:返回本次匹配的原串「发起点」。
- 匹配失败:枚举原串的下一个「发起点」,重新尝试匹配。
class Solution {
public:int strStr(string haystack, string needle) {int minIndex=0;int i=0,j=0;if(haystack.size()<needle.size())return -1;while(i<=(haystack.size()-needle.size())){minIndex=i;j=0;int tmp=i;while(j<needle.size()&&haystack[tmp]==needle[j]){j++;tmp++;}if(j==needle.size()){return minIndex;}i++;}return -1;}
};
时间复杂度:n 为原串的长度,m 为匹配串的长度。其中枚举的复杂度为 O(n−m),构造和比较字符串的复杂度为 O(m)。整体复杂度为 O((n−m)∗m)。
空间复杂度:O(1)
解法二:kmp算法
28. 找出字符串中第一个匹配项的下标 - 力扣(LeetCode)
24. 文本左右对齐


解法一:模拟
根据题干描述的贪心算法,对于每一行,我们首先确定最多可以放置多少单词,这样可以得到该行的空格个数,从而确定该行单词之间的空格个数。
根据题目中填充空格的细节,我们分以下三种情况讨论:
- 当前行是最后一行:单词左对齐,且单词之间应只有一个空格,在行末填充剩余空格;
- 当前行不是最后一行,且只有一个单词:该单词左对齐,在行末填充空格;
- 当前行不是最后一行,且不只一个单词:设当前行单词数为 numWords,空格数为 numSpaces,我们需要将空格均匀分配在单词之间,则单词之间应至少有
a v g S p a c e s = [ n u m W o r d s − 1 n u m S p a c e s ] avgSpaces=[\frac{numWords−1} {numSpaces}] avgSpaces=[numSpacesnumWords−1]
个空格,对于多出来的
e x t r a S p a c e s = n u m S p a c e s m o d ( n u m W o r d s − 1 ) extraSpaces=numSpacesmod(numWords−1) extraSpaces=numSpacesmod(numWords−1)
个空格,应填在前 extraSpaces 个单词之间。因此,前 extraSpaces 个单词之间填充 avgSpaces+1 个空格,其余单词之间填充 avgSpaces 个空格。
class Solution {
public:string blank(int n){return string(n,' ');}//返回用sep 拼接[left,right)范围内的words组成的字符串,sep是空格string spliceStr(vector<string>&words,int left,int right,string sep){string s=words[left];for(int i=left+1;i<right;i++){s+=sep+words[i];}return s;}vector<string> fullJustify(vector<string>& words, int maxWidth) {vector<string>ans;int right=0;int n=words.size();while(1){int left=right;//第一个单词在words的位置int sumLen=0;//统计这一行单词只喝while(right<n&&sumLen+words[right].length()+right-left<=maxWidth){sumLen+=words[right].length();right++;}// 当前行是最后一行:单词左对齐,且单词之间应只有一个空格,在行末填充剩余空格if(right==n){string s=spliceStr(words,left,n," ");ans.emplace_back(s+blank(maxWidth-s.length())); return ans;}//不是最后一行int numsWords=right-left;int numSpaces=maxWidth-sumLen;// 当前行只有一个单词:该单词左对齐,在行末填充剩余空格if(numsWords==1){ans.emplace_back(words[left]+blank(numSpaces));continue;}//当前行不止一个单词int avgSpaces=numSpaces/(numsWords-1);int extraSpaces=numSpaces%(numsWords-1);string s1=spliceStr(words,left,left+extraSpaces+1,blank(avgSpaces+1));string s2=spliceStr(words,left+extraSpaces+1,right,blank(avgSpaces));ans.emplace_back(s1+blank(avgSpaces)+s2);}}
};
- 时间复杂度:O(m),其中 m 是数组 words 中所有字符串的长度之和。
- 空间复杂度:O(m)。
双指针
25. 验证回文串

解法:筛选 + 判断
最简单的方法是对字符串 s 进行一次遍历,并将其中的字母和数字字符进行保留,放在另一个字符串 sgood 中。这样我们只需要判断 sgood 是否是一个普通的回文串即可。
判断的方法有两种。第一种是使用语言中的字符串翻转 API 得到 sgood 的逆序字符串 sgood_rev,只要这两个字符串相同,那么 sgood 就是回文串。
第二种是使用双指针。初始时,左右指针分别指向 sgood 的两侧,随后我们不断地将这两个指针相向移动,每次移动一步,并判断这两个指针指向的字符是否相同。当这两个指针相遇时,就说明 sgood 时回文串。
class Solution {
public:bool isPalindrome(string s) {char copy[s.size()];int cnt=0;int index=0;while(cnt<s.size()){if(isalnum(s[cnt])){copy[index]=s[cnt];index++;}cnt++;}int left=0;int right=index-1;if(right<0){return true;}transform(copy,copy+index,copy,::tolower);while(left<right){if(copy[left]!=copy[right]){return false;}left++;right--;}return true;}
};
时间复杂度:O(∣s∣),其中 ∣s∣ 是字符串 s 的长度。
空间复杂度:O(∣s∣)。由于我们需要将所有的字母和数字字符存放在另一个字符串中,在最坏情况下,新的字符串 sgood 与原字符串 s 完全相同,因此需要使用 O(∣s∣) 的空间。
解法二:在原字符串上直接判断
见:https://leetcode.cn/problems/valid-palindrome/solutions/292148/yan-zheng-hui-wen-chuan-by-leetcode-solution/?envType=study-plan-v2&envId=top-interview-150
26. 判断子序列

解法一:双指针
思路及算法
本题询问的是,s 是否是 t 的子序列,因此只要能找到任意一种 s 在 t 中出现的方式,即可认为 s 是 t 的子序列。
而当我们从前往后匹配,可以发现每次贪心地匹配靠前的字符是最优决策。
假定当前需要匹配字符 c,而字符 c 在 t 中的位置 x 1 x_1 x1和 x 2 x_2 x2 出现( x 1 < x 2 x_1<x_2 x1<x2),那么贪心取 x 1 x_1 x1 是最优解,因为 x 2 x _2 x2
后面能取到的字符, x 1 x_1 x1也都能取到,并且通过 x 1 x_1 x1与 x 2 x_2 x2之间的可选字符,更有希望能匹配成功。
这样,我们初始化两个指针 i 和 j,分别指向 s 和 t 的初始位置。每次贪心地匹配,匹配成功则 i 和 j 同时右移,匹配 s 的下一个位置,匹配失败则 j 右移,i 不变,尝试用 t 的下一个字符匹配 s。
最终如果 i 移动到 s 的末尾,就说明 s 是 t 的子序列。
class Solution {
public://双指针bool isSubsequence(string s, string t) {int n=s.length();int m=t.length();int i=0,j=0;while(i<n&&j<m){if(s[i]==t[j]){i++;}j++;}return i==n;}
};
解法二:动态规划【当输入大量S的时候,适合动态规划】
考虑前面的双指针的做法,我们注意到我们有大量的时间用于在 t 中找到下一个匹配字符。
这样我们可以预处理出对于 t 的每一个位置,从该位置开始往后每一个字符第一次出现的位置。
我们可以使用动态规划的方法实现预处理,令 f [ i ] [ j ] f[i][j] f[i][j] 表示字符串 t 中从位置 i 开始往后字符 j 第一次出现的位置。在进行状态转移时,如果 t 中位置 i 的字符就是 j,那么$ f[i][j]=i ,否则 j 出现在位置 i + 1 开始往后,即 ,否则 j 出现在位置 i+1 开始往后,即 ,否则j出现在位置i+1开始往后,即 f[i][j]=f[i+1][j]$,因此我们要倒过来进行动态规划,从后往前枚举 i。
这样我们可以写出状态转移方程:
f [ i ] [ j ] = { i , t [ i ] = j f [ i + 1 ] [ j ] , t [ i ] ≠ j f[i][j]=\begin{cases} i,t[i]=j\\ f[i+1][j], t[i]\neq j\end{cases} f[i][j]={i,t[i]=jf[i+1][j],t[i]=j
假定下标从 0 开始,那么 f[i][j] 中有 0≤i≤m−1 ,对于边界状态 f [ m − 1 ] [ . . ] f[m−1][..] f[m−1][..],我们置 f [ m ] [ . . ] f[m][..] f[m][..] 为 m,让 f [ m − 1 ] [ . . ] f[m−1][..] f[m−1][..] 正常进行转移。这样如果 f [ i ] [ j ] = m f[i][j]=m f[i][j]=m,则表示从位置 i 开始往后不存在字符 j。
这样,我们可以利用 f 数组,每次 O(1) 地跳转到下一个位置,直到位置变为 m 或 s 中的每一个字符都匹配成功。
同时我们注意到,该解法中对 t 的处理与 s 无关,且预处理完成后,可以利用预处理数组的信息,线性地算出任意一个字符串 s 是否为 t 的子串。这样我们就可以解决「后续挑战」啦。
class Solution {
public://双指针bool isSubsequence(string s, string t) {int n=s.size(),m=t.size();vector<vector<int>>f(m+1,vector<int>(26,0));for(int i=0;i<26;i++){f[m][i]=m;}for(int i=m-1;i>=0;i--){for(int j=0;j<26;j++){if(t[i]==j+'a'){f[i][j]=i;}elsef[i][j]=f[i+1][j];}}int next_index=0;for(int i=0;i<n;i++){if(f[next_index][s[i]-'a']==m){return false;}//next_index=f[next_index][s[i]-'a']+1;}return true;}
};
时间复杂度:O(m×∣Σ∣+n),其中 n 为 s 的长度,m 为 t 的长度,Σ 为字符集,在本题中字符串只包含小写字母,∣Σ∣=26。预处理时间复杂度 O(m),判断子序列时间复杂度 O(n)。如果是计算 k 个平均长度为 n 的字符串是否为 t 的子序列,则时间复杂度为 O(m×∣Σ∣+k×n)。
空间复杂度:O(m×∣Σ∣),为动态规划数组的开销。
27. 两数之和|| -输入有序数组


解法一:双指针
初始时两个指针分别指向第一个元素位置和最后一个元素的位置。每次计算两个指针指向的两个元素之和,并和目标值比较。如果两个元素之和等于目标值,则发现了唯一解。如果两个元素之和小于目标值,则将左侧指针右移一位。如果两个元素之和大于目标值,则将右侧指针左移一位。移动指针之后,重复上述操作,直到找到答案。
使用双指针的实质是缩小查找范围。那么会不会把可能的解过滤掉?答案是不会。假设 numbers[i]+numbers[j]=target 是唯一解,其中 0≤i<j≤numbers.length−1。初始时两个指针分别指向下标 0 和下标numbers.length−1,左指针指向的下标小于或等于 i,右指针指向的下标大于或等于 j。除非初始时左指针和右指针已经位于下标 i和 j,否则一定是左指针先到达下标 i 的位置或者右指针先到达下标 j 的位置。
- 如果左指针先到达下标 i 的位置,此时右指针还在下标 j 的右侧,sum>target,因此一定是右指针左移,左指针不可能移到 i 的右侧。
- 如果右指针先到达下标 j 的位置,此时左指针还在下标 iii 的左侧,sum<target,因此一定是左指针右移,右指针不可能移到 j 的左侧。
由此可见,在整个移动过程中,左指针不可能移到 i 的右侧,右指针不可能移到 j 的左侧,因此不会把可能的解过滤掉。由于题目确保有唯一的答案,因此使用双指针一定可以找到答案。
class Solution {
public:vector<int> twoSum(vector<int>& numbers, int target) {int left=0,right=numbers.size()-1;while(left<right){if(numbers[left]+numbers[right]<target)left++;else if(numbers[left]+numbers[right]>target)right--;elsereturn {left+1,right+1}; } return {};}
};
- 时间复杂度:O(n),其中 n 是数组的长度。两个指针移动的总次数最多为 n 次。
- 空间复杂度:O(1)。
解法二:二分查找
在数组中找到两个数,使得它们的和等于目标值,可以首先固定第一个数,然后寻找第二个数,第二个数等于目标值减去第一个数的差。利用数组的有序性质,可以通过二分查找的方法寻找第二个数。为了避免重复寻找,在寻找第二个数时,只在第一个数的右侧寻找。
见官方题解:167. 两数之和 II - 输入有序数组 - 力扣(LeetCode)
28. 盛最多水的容器
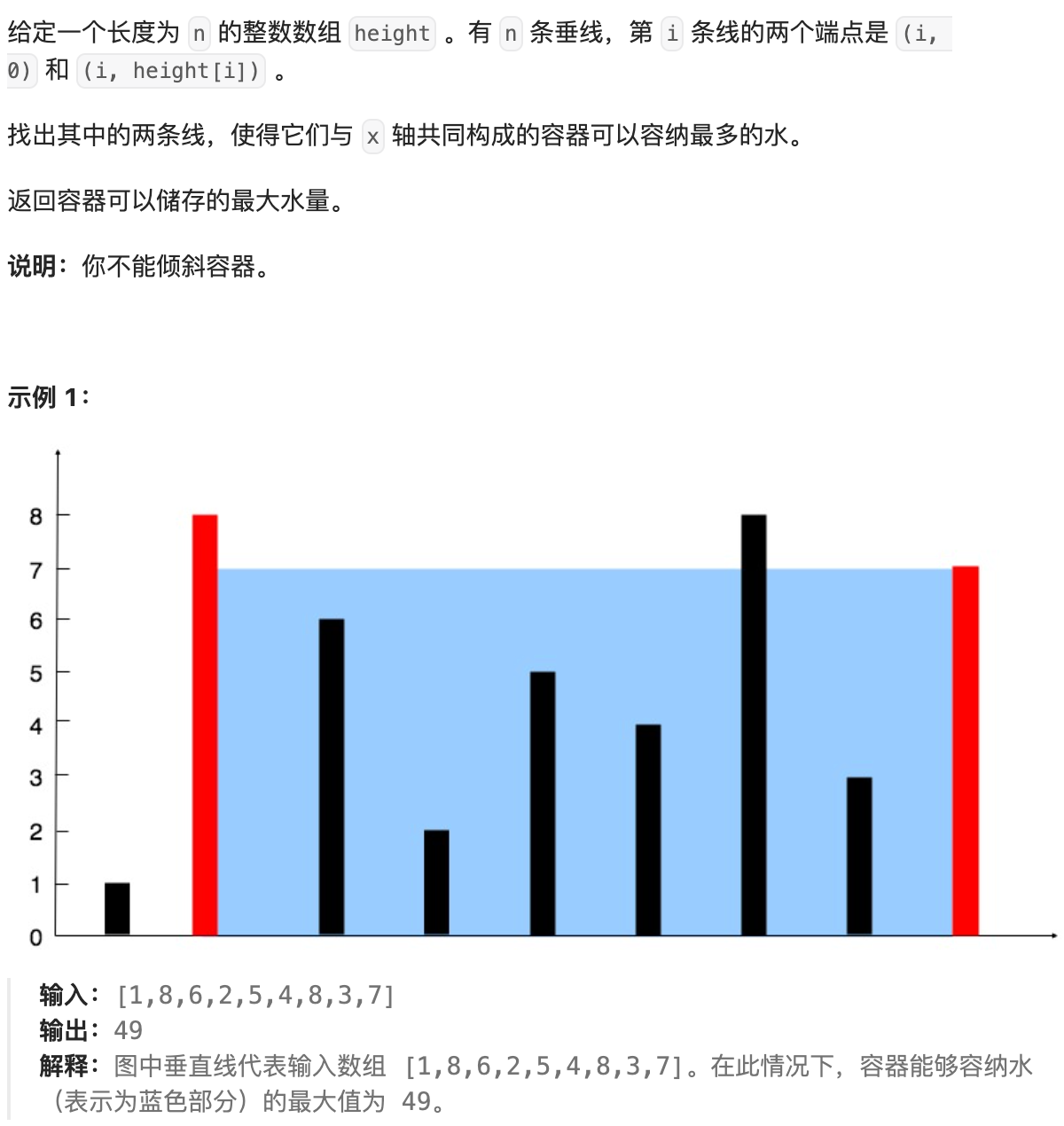

解法:设两指针 i , j ,指向的水槽板高度分别为 h[i] , h[j],此状态下水槽面积为 S(i,j)。由于可容纳水的高度由两板中的 短板 决定,因此可得如下 面积公式 :
S ( i , j ) = m i n ( h [ i ] , h [ j ] ) × ( j − i ) S(i,j)=min(h[i],h[j])×(j−i) S(i,j)=min(h[i],h[j])×(j−i)
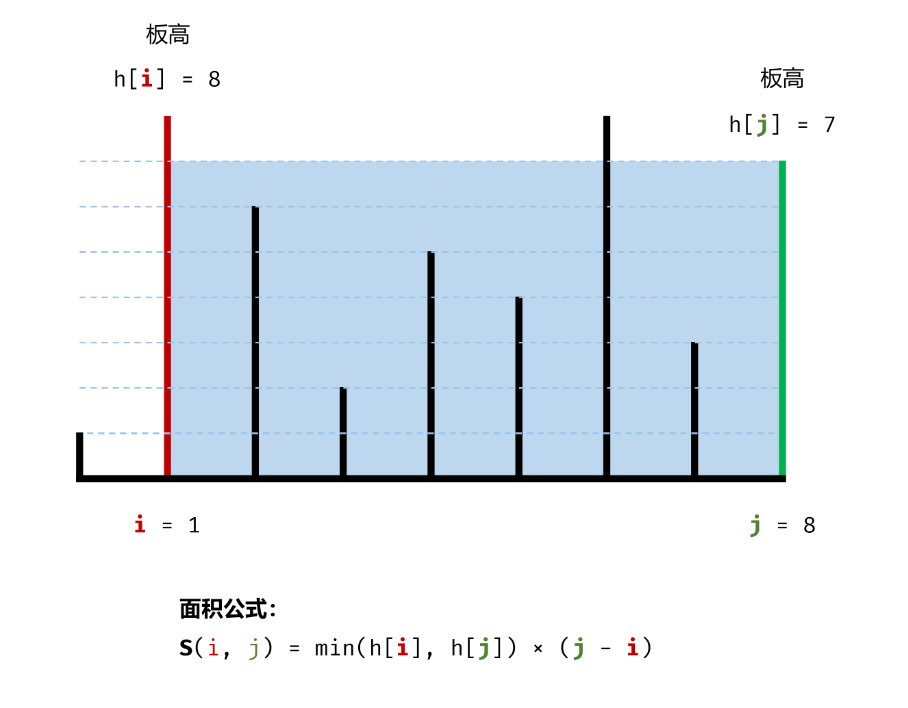
在每个状态下,无论长板或短板向中间收窄一格,都会导致水槽 底边宽度 −1 变短:
若向内移动短板 ,水槽的短板 min(h[i],h[j])) 可能变大,因此下个水槽的面积 可能增大 。
若向内 移动长板 ,水槽的短板 min(h[i],h[j]) 不变或变小,因此下个水槽的面积 一定变小 。
因此,初始化双指针分列水槽左右两端,循环每轮将短板向内移动一格,并更新面积最大值,直到两指针相遇时跳出;即可获得最大面积。
算法流程:
初始化: 双指针 i , j 分列水槽左右两端;
循环收窄: 直至双指针相遇时跳出;
更新面积最大值 res ;
选定两板高度中的短板,向中间收窄一格;
返回值: 返回面积最大值 res 即可;
class Solution {
public:int maxArea(vector<int>& height) {int res=0;int i=0,j=height.size()-1;while(i<j){int area=min(height[i],height[j])*(j-i);res=max(res,area);if(height[i]<height[j]){i++;}else{j--;}}return res;}
};
时间复杂度 O(N) : 双指针遍历一次底边宽度 N 。
空间复杂度 O(1) : 变量 i , j , res使用常数额外空间。
30. 三数之和

解法:排序+双指针
- 对数组进行排序。
遍历排序后数组:若 nums[i]>0:因为已经排序好,所以后面不可能有三个数加和等于 0,直接返回结果。 - 固定num[i]之后,说明nums[L]+nums[R]需要等于target,为-nums[i];
令左指针 L=i+1,右指针 R=n−1,当 L<R 时,执行循环:
当 nums[i]+nums[L]+nums[R]==0,执行循环,判断左界和右界是否和下一位置重复,去除重复解。并同时将 L,R移到下一位置,寻找新的解
若和大于 0,说明 nums[R] 太大,R左移
若和小于 0,说明 nums[L] 太小,L右移 - 判断重复,需要判断L指针是否和前一个指针重复,以及R指针是否和前一个重复,我实现的过程采取的是直接将result通过set去重,速度较慢
- 具体可见官方题解:15. 三数之和 - 力扣(LeetCode)
代码:
class Solution {
public:vector<vector<int>> threeSum(vector<int>& nums) {vector<vector<int>> result;sort(nums.begin(),nums.end());int first,second,third,target;for(int i=0;i<nums.size()-1;i++){first=nums[i];if(first>0)continue;second=i+1;third=nums.size()-1;target=0-first;while(second<third){while(second<third&&nums[second]+nums[third]<target){second++;}while(second<third&&nums[second]+nums[third]>target){third--;}if(second<third&&nums[second]+nums[third]==target){result.push_back({first,nums[second],nums[third]});second++;third--;}}if(nums[i+1]==first)i++;}set<vector<int>>s(result.begin(), result.end());result.assign(s.begin(), s.end());return result;}
};
- 时间复杂度:O(n2),数组排序 O(NlogN),遍历数组 O(n),双指针遍历 O(n),总体 O(NlogN)+O(n)∗O(n),O(n2)
- 空间复杂度:O(1)
滑动窗口
31. 长度最小的子数组


解法一:暴力解法,不详细些,双重循环找到每个下标作为子数组的开始下标之后的子数组的最小长度
O(n^2) 大概率超时
解法二:前缀和 + 二分查找
方法一的时间复杂度是 O(n^2),因为在确定每个子数组的开始下标后,找到长度最小的子数组需要 O(n) 的时间。如果使用二分查找,则可以将时间优化到 O(logn)。
为了使用二分查找,需要额外创建一个数组 sums 用于存储数组 nums 的前缀和,其中 sums[i] 表示从 nums[0] 到 nums[i−1] 的元素和。得到前缀和之后,对于每个开始下标 i,可通过二分查找得到大于或等于 i 的最小下标 bound,使得 sums[bound]−sums[i−1]≥target,并更新子数组的最小长度(此时子数组的长度是 bound−(i−1))。
即找到一个bound的位置,sum[bound]-sum[i-1]>=s,那么也就等于sum[bound]>=sum[i-1]+target。
所以只需要便利sum[i…n],以sum[i]为起点,我们找到第一个大于sum[i]+target的位置即可。
因为这道题保证了数组中每个元素都为正,所以前缀和一定是递增的,这一点保证了二分的正确性。如果题目没有说明数组中每个元素都为正,这里就不能使用二分来查找这个位置了。
class Solution {
public:int minSubArrayLen(int target, vector<int>& nums) {int n=nums.size();if(n==0){return 0;}int ans=INT_MAX;vector<int>sum(n+1,0);for(int i=1;i<=n;i++){sum[i]=sum[i-1]+nums[i-1];}for(int i=1;i<=n;i++){int tmp=target+sum[i-1];//tmp-sum[i]>target ->tmp>sum[i]+target 所以对于每个i,找到对应最小的j即可auto bound=lower_bound(sum.begin(),sum.end(),tmp);if(bound!=sum.end()){ans=min(ans,static_cast<int>(bound-sum.begin())-(i-1));}}return ans==INT_MAX?0:ans;}
};
时间复杂度:O(nlogn),其中 n 是数组的长度。需要遍历每个下标作为子数组的开始下标,遍历的时间复杂度是 O(n),对于每个开始下标,需要通过二分查找得到长度最小的子数组,二分查找得时间复杂度是 O(logn),因此总时间复杂度是 O(nlogn)。
空间复杂度:O(n),其中 n 是数组的长度。额外创建数组 sums 存储前缀和。
滑动窗口
在方法一和方法二中,都是每次确定子数组的开始下标,然后得到长度最小的子数组,因此时间复杂度较高。为了降低时间复杂度,可以使用滑动窗口的方法。
定义两个指针 left和 right分别表示子数组(滑动窗口窗口)的开始位置和结束位置,维护变量 sum 存储子数组中的元素和(即从 nums[ left] 到 nums[right] 的元素和)。
初始状态下,left 和 right 都指向下标 0,sum 的值为 0。
每一轮迭代,将 nums[right] 加到 sum,如果 sum≥s,则更新子数组的最小长度(此时子数组的长度是 end−start+1),然后将 nums[left] 从 sum 中减去并将 start 右移,直到 sum<s,在此过程中同样更新子数组的最小长度。在每一轮迭代的最后,将 right 右移。
class Solution {
public:int minSubArrayLen(int target, vector<int>& nums) {if(nums.size()==0)return 0;int left=0;int right=0;int sum=0;int ans=INT_MAX;while(right<nums.size()){sum+=nums[right];while(sum>=target){ans=min(ans,right-left+1);sum-=nums[left];left++;}right++;}return ans==INT_MAX?0:ans;}
};
- 时间复杂度:O(n),其中 n 是数组的长度。指针 start 和 end 最多各移动 n 次。
- 空间复杂度:O(1)。
32. 无重复字符的最长子串

解法一:动态规划+哈希表
状态定义: 设动态规划列表 dp ,dp[j] 代表以字符 s[j] 为结尾的 “最长不重复子字符串” 的长度。
转移方程: 固定右边界 j ,设字符 s[j] 左边距离最近的相同字符为 s[i] ,即 s[i]=s[j] 。
- 当 i<0 ,即 s[j] 左边无相同字符,则 dp[j]=dp[j−1]+1 。
- 当 dp[j−1]<j−i ,说明字符 s[i] 在子字符串 dp[j−1] 区间之外 ,则 dp[j]=dp[j−1]+1 。
- 当 dp[j−1]≥j−i ,说明字符 s[i] 在子字符串 dp[j−1] 区间之中 ,则 dp[j] 的左边界由 s[i] 决定,即 dp[j]=j−i 。
- 当 i<0 时,由于 dp[j−1]≤j 恒成立,因而 dp[j−1]<j−i 恒成立,因此分支 1. 和 2. 可被合并。
d p [ j ] = { d p [ j − 1 ] + 1 , d p [ j − 1 ] < j − i j − i , d p [ j − 1 ] ≥ j − i dp[j] = \begin{cases} dp[j-1] + 1, & dp[j-1] < j - i \\ j - i, & dp[j-1] \geq j - i \end{cases} dp[j]={dp[j−1]+1,j−i,dp[j−1]<j−idp[j−1]≥j−i
- 返回值: max(dp) ,即全局的 “最长不重复子字符串” 的长度。

状态压缩:
由于返回值是取 dp 列表最大值,因此可借助变量 tmp 存储 dp[j] ,变量 res 每轮更新最大值即可。
此优化可节省 dp 列表使用的 O(N) 大小的额外空间。
哈希表记录:
观察转移方程,可知关键问题:每轮遍历字符 s[j] 时,如何计算索引 i ?
哈希表统计: 遍历字符串 s 时,使用哈希表(记为 dic )统计 各字符最后一次出现的索引位置 。
左边界 i 获取方式: 遍历到 s[j] 时,可通过访问哈希表 dic[s[j]] 获取最近的相同字符的索引 i 。
class Solution {
public:int lengthOfLongestSubstring(string s) {unordered_map<char,int>dic;int res=0,tmp=0,len=s.size(),i;for(int j=0;j<len;j++){if(dic.find(s[j])==dic.end())i=-1;elsei=dic[s[j]];dic[s[j]]=j;tmp=tmp<j-i?tmp+1:j-i;//动态规划转化,tmp代表dp[j-1]res=max(res,tmp);}return res;}
};
时间复杂度 O(N) : 其中 N 为字符串长度,动态规划需遍历计算 dp 列表。
空间复杂度 O(1) : 字符的 ASCII 码范围为 0 ~ 127 ,哈希表 dic 最多使用 O(128)=O(1) 大小的额外空间。
解法二:滑动窗口
见:https://leetcode.cn/problems/longest-substring-without-repeating-characters/solutions/2361797/3-wu-zhong-fu-zi-fu-de-zui-chang-zi-chua-26i5/?envType=study-plan-v2&envId=top-interview-150
33. 串联所有单词的子串


解法一:
此题是「438. 找到字符串中所有字母异位词」的进阶版。不同的是第 438 题的元素是字母,而此题的元素是单词。可以用类似「438. 找到字符串中所有字母异位词的官方题解」的方法二的滑动窗口来解这题。
记 words 的长度为 m,words 中每个单词的长度为 n,s 的长度为 ls。首先需要将 s 划分为单词组,每个单词的大小均为 n (首尾除外)。这样的划分方法有 n 种,即先删去前 i (i=0∼n−1)个字母后,将剩下的字母进行划分,如果末尾有不到 n 个字母也删去。对这 n 种划分得到的单词数组分别使用滑动窗口对 words 进行类似于「字母异位词」的搜寻。
划分成单词组后,一个窗口包含 s 中前 m 个单词,用一个哈希表 differ 表示窗口中单词频次和 words 中单词频次之差。初始化 differ 时,出现在窗口中的单词,每出现一次,相应的值增加 1,出现在 words 中的单词,每出现一次,相应的值减少 1。然后将窗口右移,右侧会加入一个单词,左侧会移出一个单词,并对 differ 做相应的更新。窗口移动时,若出现 differ 中值不为 0 的键的数量为 0,则表示这个窗口中的单词频次和 words 中单词频次相同,窗口的左端点是一个待求的起始位置。划分的方法有 n 种,做 n 次滑动窗口后,即可找到所有的起始位置。
此题为困难题,可以参考官方题解以及注释理解
class Solution {
public:vector<int> findSubstring(string &s, vector<string> &words) {vector<int> res; // 存储结果的数组int m = words.size(), n = words[0].size(), ls = s.size(); // 单词数量、单词长度、字符串 s 的长度for (int i = 0; i < n && i + m * n <= ls; ++i) { // 外层循环,从每个可能的起始位置 i 开始unordered_map<string, int> differ; // 用于统计当前窗口内单词的出现次数// 统计从当前起始位置 i 开始的 m 个单词for (int j = 0; j < m; ++j) {++differ[s.substr(i + j * n, n)]; // 将子串加入到 differ 中并计数}// 遍历 words 中的每个单词,检查其在 differ 中的出现次数for (string &word: words) {if (--differ[word] == 0) { // 如果单词的计数减为 0,则从 differ 中删除differ.erase(word);}}// 内层循环,从起始位置 i 开始滑动窗口for (int start = i; start < ls - m * n + 1; start += n) {if (start != i) {// 添加新进入窗口的单词到 differ 中string word = s.substr(start + (m - 1) * n, n);//窗口右边加的单词if (++differ[word] == 0) {differ.erase(word);}// 移除窗口左侧移出的单词word = s.substr(start - n, n);if (--differ[word] == 0) {differ.erase(word);}}// 如果 differ 为空,表示当前窗口符合要求,将起始位置加入结果数组 resif (differ.empty()) {res.emplace_back(start);}}}return res; // 返回所有符合要求的起始位置数组}
};
34. 最小覆盖子串
 解法:滑动窗口
解法:滑动窗口
滑动窗口的思想:
用l,r表示滑动窗口的左边界和右边界,通过改变i,j来扩展和收缩滑动窗口,可以想象成一个窗口在字符串上游走,当这个窗口包含的元素满足条件,即包含字符串T的所有元素,记录下这个滑动窗口的长度r-l+1,这些长度中的最小值就是要求的结果。
- 不断增加r使滑动窗口增大,直到窗口包含了T的所有元素
- 不断增加l使滑动窗口缩小,因为是要求最小字串,所以将不必要的元素排除在外,使长度减小,直到碰到一个必须包含的元素,这个时候不能再扔了,再扔就不满足条件了,记录此时滑动窗口的长度,并保存最小值
- 让i再增加一个位置,这个时候滑动窗口肯定不满足条件了,那么继续从步骤一开始执行,寻找新的满足条件的滑动窗口,如此反复,直到j超出了字符串S范围。
面临的问题:
如何判断滑动窗口包含了T的所有元素?
我们用一个map,num2Count来表示当前滑动窗口中需要的各元素的数量,一开始滑动窗口为空,用T中各元素来初始化这个num2Count,当滑动窗口扩展或者收缩的时候,去维护这个num2Count,例如当滑动窗口包含某个元素,我们就让num2Count中这个元素的数量减1,代表所需元素减少了1个;当滑动窗口移除某个元素,就让num2Count中这个元素的数量加1。
记住一点:num2Count始终记录着当前滑动窗口下,我们还需要的元素数量,我们在改变l,r时,需同步维护num2Count。
值得注意的是,只要某个元素包含在滑动窗口中,我们就会在num2Count中存储这个元素的数量,如果某个元素存储的是负数代表这个元素是多余的。比如当num2Count等于{‘A’:-2,‘C’:1}时,表示当前滑动窗口中,我们有2个A是多余的,同时还需要1个C。这么做的目的就是为了步骤二中,排除不必要的元素,数量为负的就是不必要的元素,而数量为0表示刚刚好。
回到问题中来,那么如何判断滑动窗口包含了T的所有元素?结论就是当need中所有元素的数量都小于等于0时,表示当前滑动窗口不再需要任何元素。
优化
如果每次判断滑动窗口是否包含了T的所有元素,都去遍历num2Count看是否所有元素数量都小于等于0,这个会耗费O(k的时间复杂度,k代表字典长度,最坏情况下,k可能等于len(S)。
其实这个是可以避免的,我们可以维护一个额外的变量numCnt来记录所需元素的总数量,当我们碰到一个所需元素c,不仅num2Count[c]的数量减少1,同时numCnt,这样我们通过numCnt就可以知道是否满足条件,而无需遍历字典了。
前面也提到过,num2Count记录了遍历到的所有元素,而只有仅num2Count[c]>0大于0时,代表c就是所需元素

代码:
class Solution {
public:string minWindow(string s, string t) {unordered_map<int,int>char2Count;for(auto c:t){char2Count[c-'A']++;}int numCnt=t.size();int minlen=10e5;int l=0,r=0;int ansL=-1;while(r<s.size()){//当遇到S中的字符,并更新计数数组if(--char2Count[s[r]-'A']>=0){numCnt--;}//numCnt=0说明包含while(numCnt==0){if(++char2Count[s[l]-'A']>0){//此时左指针的位置在t中,不能收缩if(r-l+1<minlen){ansL=l;minlen=r-l+1;}numCnt++;}l++;}r++;}return ansL==-1?string():s.substr(ansL,minlen); }
};
时间复杂度:我们会用r扫描一遍S,也会用l扫描一遍S,最多扫描2次S,所以时间复杂度是O(n),
空间复杂度为O(k),k为S和T中的字符集合。
矩阵
35. 有效的数独


解法一:一次遍历
有效的数独满足以下三个条件:
- 同一个数字在每一行只能出现一次;
- 同一个数字在每一列只能出现一次;
- 同一个数字在每一个小九宫格只能出现一次。
可以使用哈希表记录每一行、每一列和每一个小九宫格中,每个数字出现的次数。只需要遍历数独一次,在遍历的过程中更新哈希表中的计数,并判断是否满足有效的数独的条件即可。
对于数独的第 i 行第 j 列的单元格,其中 0≤i,j<9,该单元格所在的行下标和列下标分别为 i 和 j,该单元格所在的小九宫格的行数和列数分别为 [ i 3 ] [\frac{i}{3}] [3i] 和 [ j 3 ] [\frac{j}{3}] [3j] ,其中 0 ≤ [ i 3 ] , [ j 3 ] ≤ 3 0\leq[\frac{i}{3}],[\frac{j}{3}]\leq3 0≤[3i],[3j]≤3。
由于数独中的数字范围是 1 到 9,因此可以使用数组代替哈希表进行计数。
具体做法是,创建二维数组 rows 和 columns 分别记录数独的每一行和每一列中的每个数字的出现次数,创建三维数组 subboxes 记录数独的每一个小九宫格中的每个数字的出现次数,其中 r o w s [ i ] [ i n d e x ] rows[i][index] rows[i][index]、 c o l u m n s [ j ] [ i n d e x ] columns[j][index] columns[j][index] 和 s u b b o x e s [ [ i 3 ] [ j 3 [ i n d e x ] ] subboxes[[\frac{i}{3}][\frac{j}{3}[index]] subboxes[[3i][3j[index]]分别表示数独的第 i 行第 j 列的单元格所在的行、列和小九宫格中,数字 index+1 出现的次数,其中 0≤index<9,对应的数字 index+1 满足 1≤index+1≤9。
如果 b o a r d [ i ] [ j ] board[i][j] board[i][j] 填入了数字 n,则将 r o w s [ i ] [ n − 1 ] rows[i][n−1] rows[i][n−1]、 c o l u m n s [ j ] [ n − 1 ] columns[j][n−1] columns[j][n−1] 和 s u b b o x e s [ [ i 3 ] [ j 3 [ i n d e x ] ] subboxes[[\frac{i}{3}][\frac{j}{3}[index]] subboxes[[3i][3j[index]]各加 1。如果更新后的计数大于 1,则不符合有效的数独的条件,返回 false。
class Solution {
public:bool isValidSudoku(vector<vector<char>>& board) {int rows[9][9];int columns[9][9];int subsudo[3][3][9];for(int i=0;i<9;i++){for(int j=0;j<9;j++){char c=board[i][j];if(c!='.'){int index=c-'0'-1;rows[i][index]++;columns[j][index]++;subsudo[i/3][j/3][index]++;if(rows[i][index]>1||columns[j][index]>1||subsudo[i/3][j/3][index]>1){return false;}}}}return true;}
};
- 时间复杂度:O(1)。数独共有 81 个单元格,只需要对每个单元格遍历一次即可。
- 空间复杂度:O(1)。由于数独的大小固定,因此哈希表的空间也是固定的。
36. 螺旋矩阵
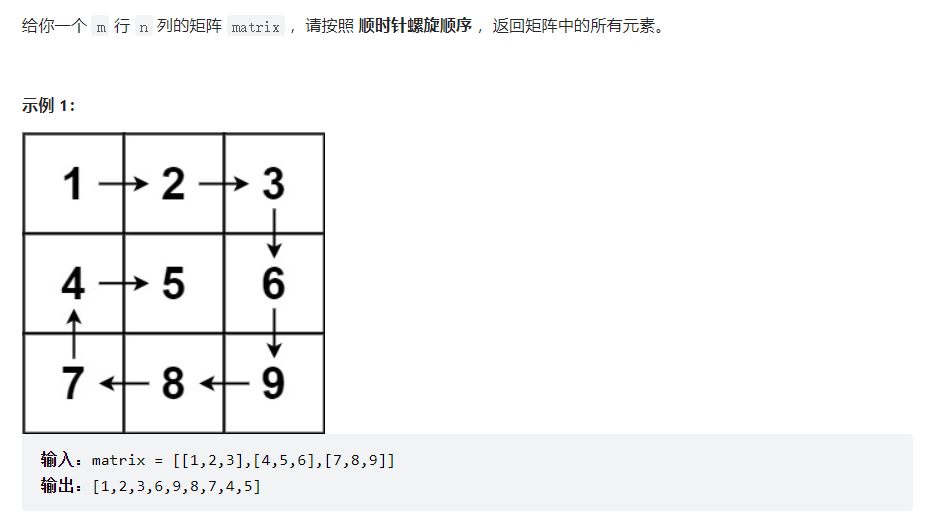
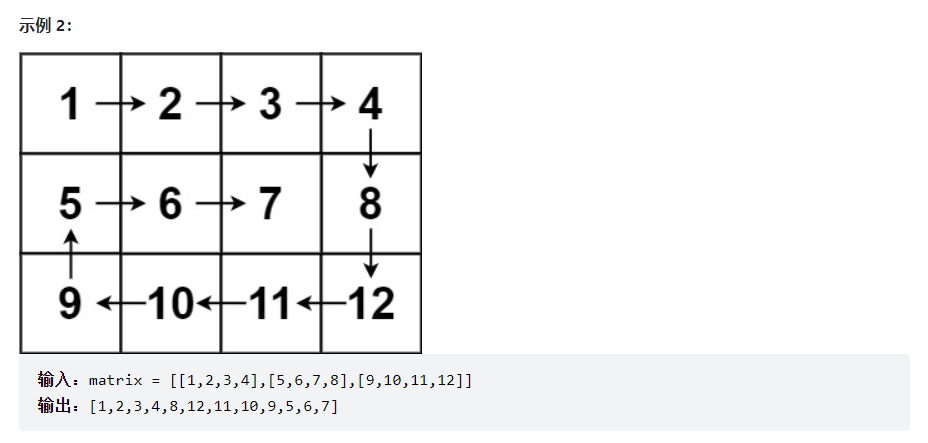 解法:因为观察到顺时针方向是按照右、下、左、上的顺序执行的,因此可以用递归的方式按照此顺序遍历矩阵,只有在遍历位置超出矩阵长度范围,或者此节点已经访问过,才会改变下一个方向。
解法:因为观察到顺时针方向是按照右、下、左、上的顺序执行的,因此可以用递归的方式按照此顺序遍历矩阵,只有在遍历位置超出矩阵长度范围,或者此节点已经访问过,才会改变下一个方向。
因此设置direction数组,表示右、下、左、上四个方向。status表示此次取到的direction的方向索引,可例2可以看到,当5遍历到1时,发现已经访问呢,因此会转向右方向,因此可以用取余的方式遇到阻碍需要转向。
需要注意dfs递归的终点是当result的结果等于矩阵的大小,说明已经遍历结束,可以返回。
代码:
const int direction[4][2]={{0,1},{1,0},{0,-1},{-1,0}};
class solution_20 {
public:vector<int> spiralOrder(vector<vector<int>>& matrix) {vector<int>result;vector<vector<int>>flag(matrix.size(),vector<int>(matrix[0].size(),0));int status=0;dfs(matrix,flag,result,0,0,status);for(int num:result){cout<<num<<" ";}return result;}void dfs(vector<vector<int>>&matrix,vector<vector<int>>&flag,vector<int> &result,int i,int j,int status){flag[i][j]=1;result.push_back(matrix[i][j]);if(result.size()==matrix.size()*matrix[0].size()){return ;}int nextI=i+direction[status][0];int nextJ=j+direction[status][1];if(nextI<0||nextI>=matrix.size()||nextJ<0||nextJ>=matrix[0].size()||flag[nextI][nextJ]==1){status=(status+1)%4;}dfs(matrix,flag,result,i+direction[status][0],j+direction[status][1],status);}
};时间复杂度:O(mn),其中 m 和 n 分别是输入矩阵的行数和列数。矩阵中的每个元素都要被访问一次。
空间复杂度:O(mn)。需要创建一个大小为 m×n 的矩阵 visited 记录每个位置是否被访问过。
37. 旋转图像
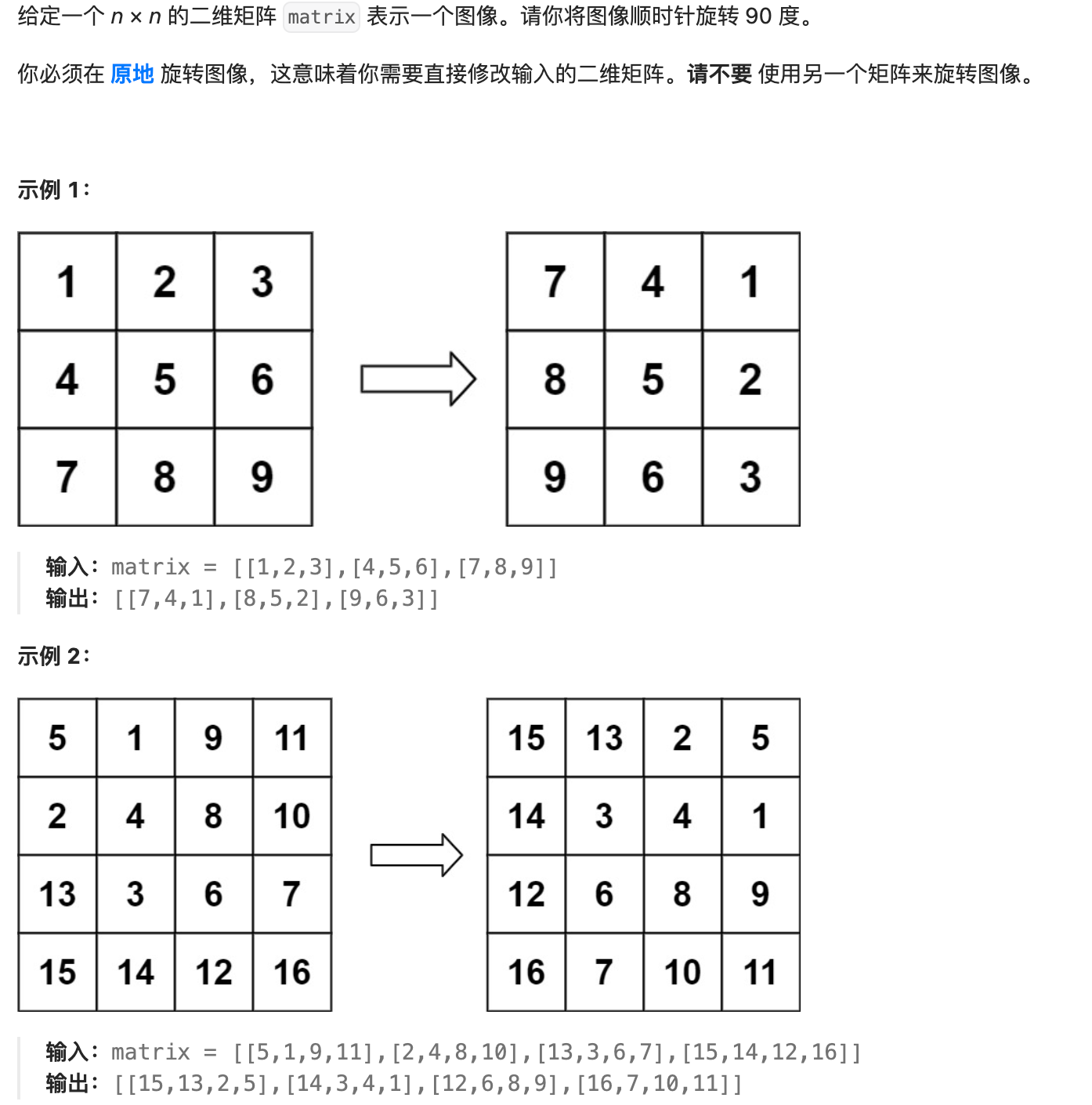
解法一:递推公式,分组旋转
首先我们由示例2可以观察到如下图所示,矩阵顺时针旋转 90º 后,可找到以下规律:
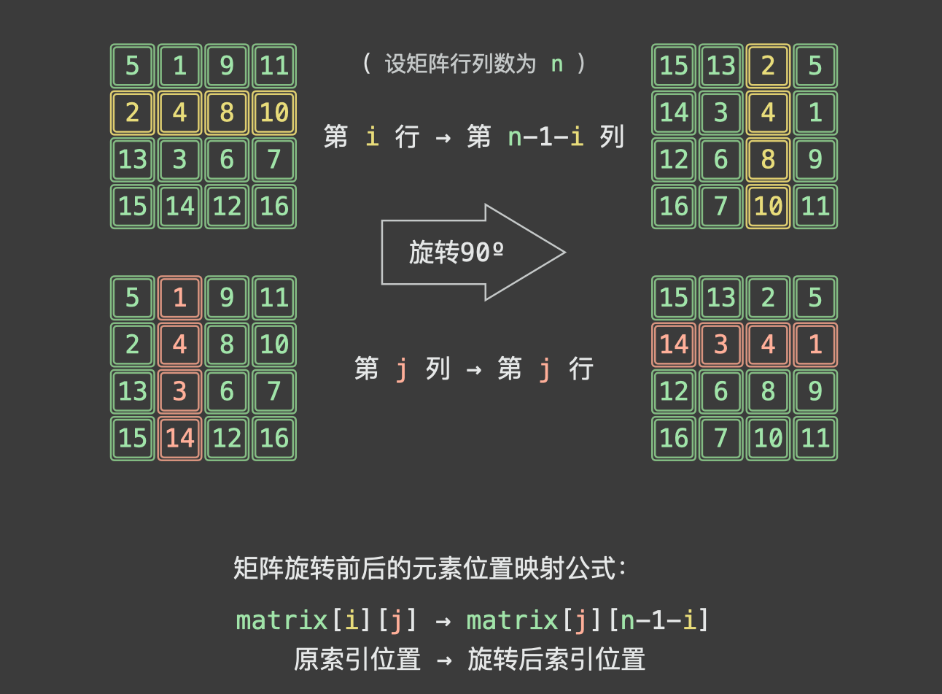
「第 i 行」元素旋转到「第 n−1−i列」元素;
「第 j列」元素旋转到「第 j 行」元素;
因此,对于矩阵任意第 i行、第 j 列元素 m a t r i x [ i ] [ j ] matrix[i][j] matrix[i][j] ,矩阵旋转 90º 后「元素位置旋转公式」为:
m a t r i x [ i ] [ j ] → m a t r i x [ j ] [ n − 1 − i ] \begin{aligned} matrix[i][j] & \rightarrow matrix[j][n - 1 - i]\end{aligned} matrix[i][j]→matrix[j][n−1−i]
原索引位置 → 旋转后索引位置 \begin{aligned}原索引位置 & \rightarrow 旋转后索引位置 \end{aligned} 原索引位置→旋转后索引位置
- 以位于矩阵四个角点的元素为例,设矩阵左上角元素 A 、右上角元素 B 、右下角元素 C 、左下角元素 D 。矩阵旋转 90º 后,相当于依次先后执行 D→A , C→D , B→C, A→B修改元素,即如下「首尾相接」的元素旋转操作:
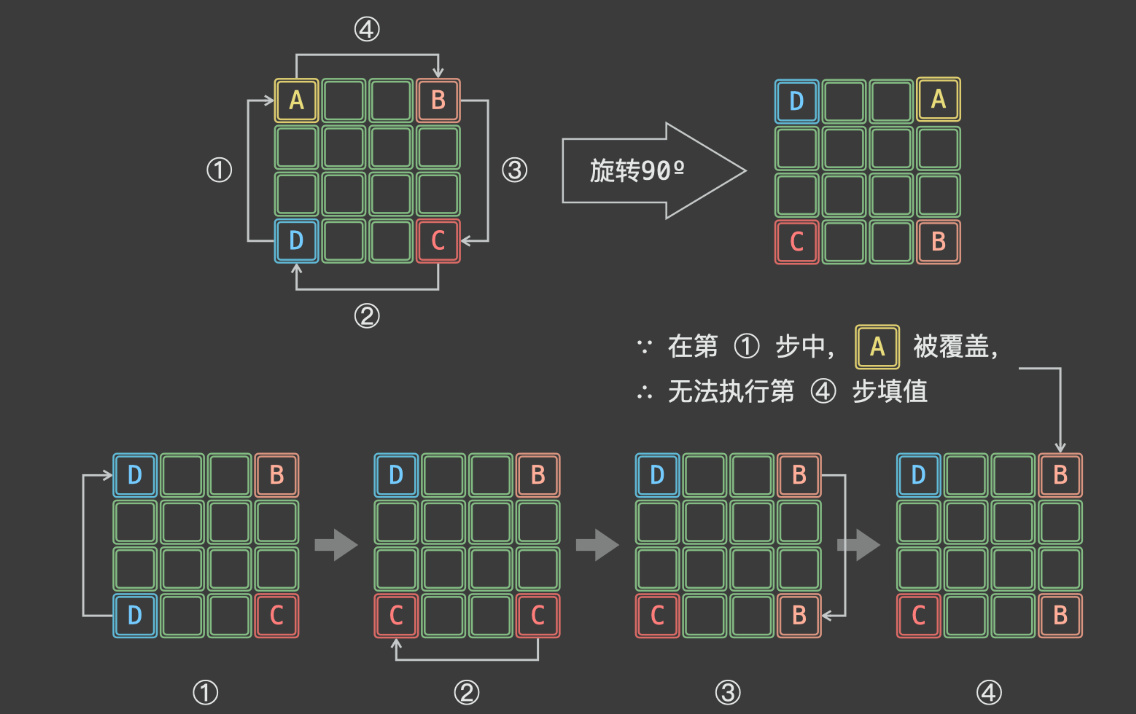
如上图所示,由于第 1 步 D→A 已经将 A覆盖(导致 A丢失),此丢失导致最后第 A→B 无法赋值。为解决此问题,考虑借助一个「辅助变量 tmp预先存储 A ,此时的旋转操作变为:
暂存 tmp=A
A←D←C←B←tmp
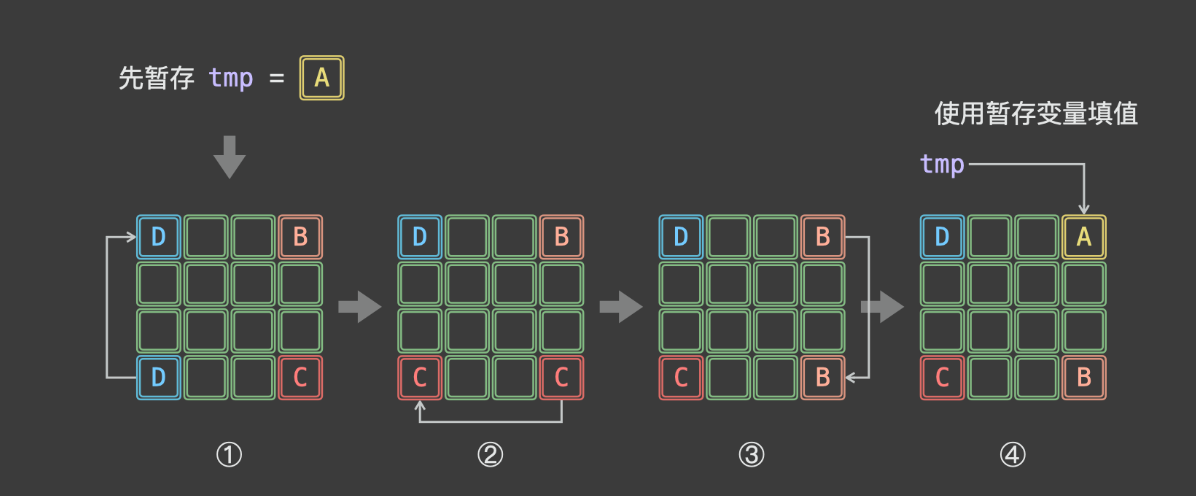
如上图所示,一轮可以完成矩阵 4 个元素的旋转。因而,只要分别以矩阵左上角 1/4 的各元素为起始点执行以上旋转操作,即可完整实现矩阵旋转。
具体来看,当矩阵大小 n 为偶数时,取前 n 2 \frac{n}{2} 2n 行、前 $\frac{n}{2} $列的元素为起始点;当矩阵大小 n 为奇数时,取前 $\frac{n}{2} $行、前 $\frac{n + 1}{2} $ 列的元素为起始点。
令 m a t r i x [ i ] [ j ] = A matrix[i][j]=A matrix[i][j]=A,根据文章开头的元素旋转公式,可推导得适用于任意起始点的元素旋转操作:
暂存
t m p = m a t r i x [ i [ j ] tmp=matrix[i[j] tmp=matrix[i[j]
m a t r i x [ i [ j ] ← m a t r i x [ n − 1 − j ] [ i ] ← m a t r i x [ n − 1 − i ] [ n − 1 − j ] ← m a t r i x [ j ] [ n − 1 − i ] ← t m p matrix[i[j] \leftarrow matrix[n - 1 - j][i] \leftarrow matrix[n - 1 - i][n - 1 - j] \leftarrow matrix[j][n - 1 - i] \leftarrow tmp matrix[i[j]←matrix[n−1−j][i]←matrix[n−1−i][n−1−j]←matrix[j][n−1−i]←tmp
代码:
class Solution {
public:void rotate(vector<vector<int>>& matrix) {int n=matrix.size();for(int i=0;i<n/2;i++)for(int j=0;j<(n+1)/2;j++){int tmp=matrix[i][j];matrix[i][j]=matrix[n-1-j][i];matrix[n-1-j][i]=matrix[n-1-i][n-1-j];matrix[n-1-i][n-1-j]=matrix[j][n-1-i];matrix[j][n-1-i]=tmp;}}
};
时间复杂度 O ( N 2 ) O(N^2) O(N2): 其中 N 为输入矩阵的行(列)数。需要将矩阵中每个元素旋转到新的位置,即对矩阵所有元素操作一次,使用 O ( N 2 ) O(N^2) O(N2)时间。
空间复杂度 O(1) : 临时变量 tmp 使用常数大小的额外空间。值得注意,当循环中进入下轮迭代,上轮迭代初始化的 tmp 占用的内存就会被自动释放,因此无累计使用空间。
解法二:用翻转代替旋转
见官方题解:48. 旋转图像 - 力扣(LeetCode)
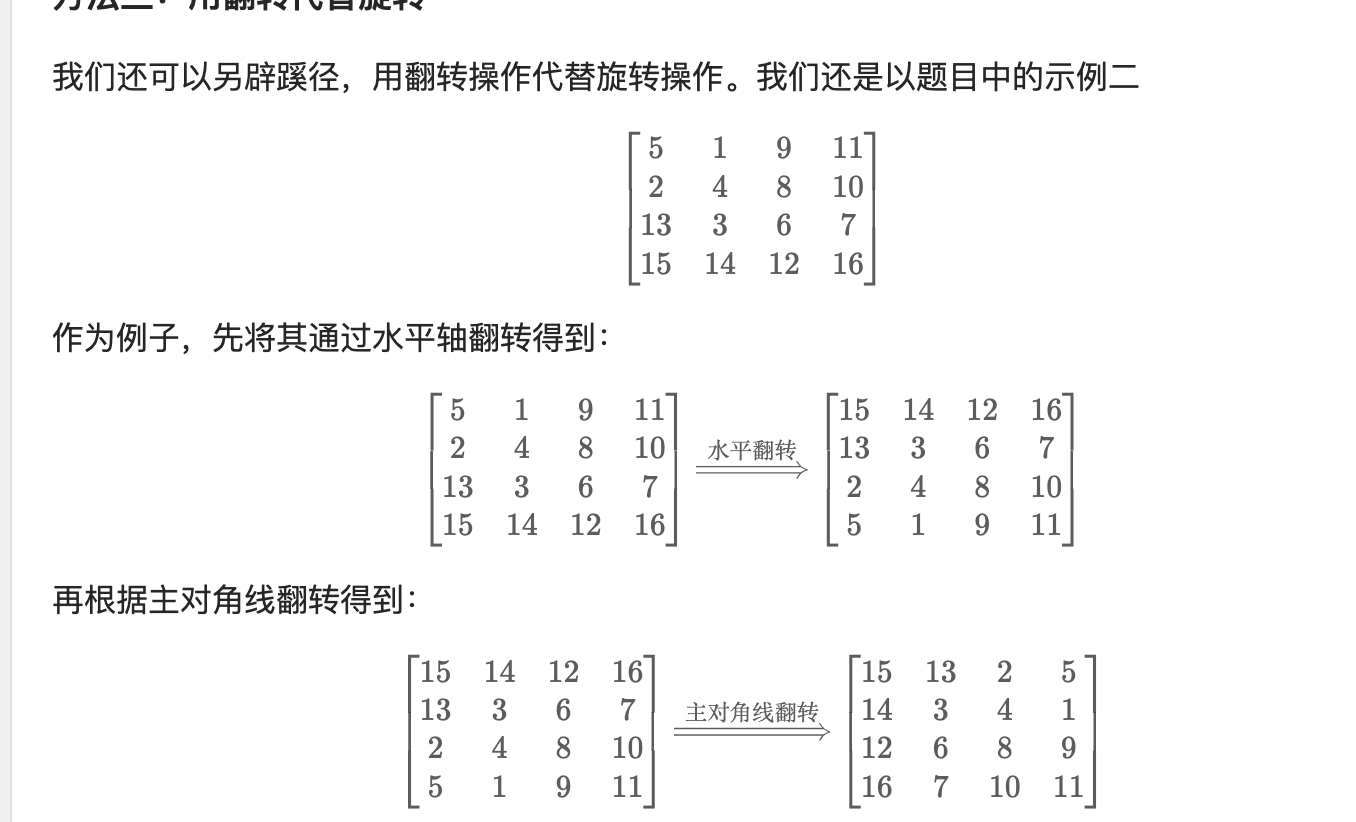

代码:
class Solution {
public:void rotate(vector<vector<int>>& matrix) {int n=matrix.size();//水平翻转for(int i=0;i<n/2;i++){for(int j=0;j<n;j++){swap(matrix[i][j],matrix[n-1-i][j]);}}//主对角线翻转for(int i=0;i<n;i++){for(int j=0;j<i;j++){swap(matrix[i][j],matrix[j][i]);}}}
};
时间复杂度: O ( N 2 ) O(N^2) O(N2),其中 N 是 matrix 的边长。对于每一次翻转操作,我们都需要枚举矩阵中一半的元素。
空间复杂度:O(1)。为原地翻转得到的原地旋转。
38. 矩阵置零
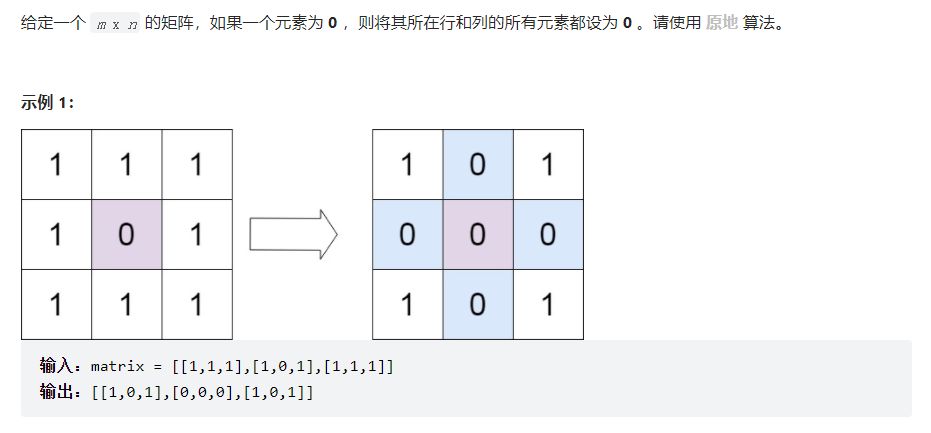
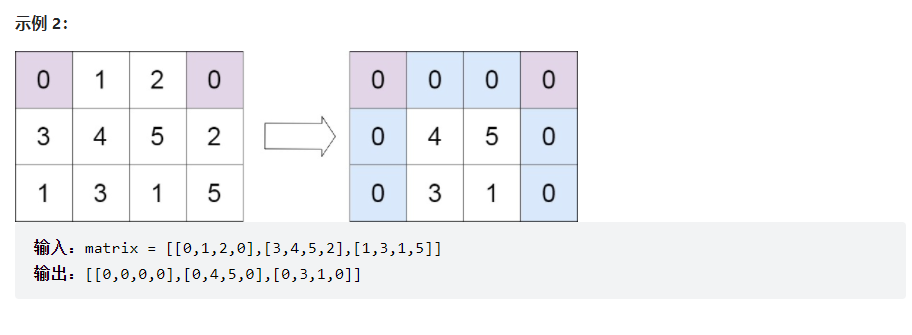
解法:简单标记,循环遍历矩阵,将矩阵为0的位置的行和列记录下来,放入set集合中去重,然后
再次遍历矩阵,若这个位置的行或者列在set集合中,那么就将这个位置置为1。
代码:
class solution_24 {
public:void setZeroes(vector<vector<int>>& matrix) {set<int>row;set<int>col;for(int i=0;i<matrix.size();i++)for(int j=0;j<matrix[0].size();j++){if(matrix[i][j]==0) {row.insert(i);col.insert(j);}}for(int i=0;i<matrix.size();i++)for(int j=0;j<matrix[0].size();j++){if(row.count(i)==1||col.count(j)==1){matrix[i][j]=0;}}}
};
时间复杂度:O(mn),其中 m是矩阵的行数,n 是矩阵的列数。我们至多只需要遍历该矩阵两次。
空间复杂度:O(m+n),其中 m 是矩阵的行数,n 是矩阵的列数。我们需要分别记录每一行或每一列是否有零出现。
39. 生命游戏

解法:
注意到不能根据每个细胞位置的八个方向的活细胞或者死细胞数字更新数组,这样无法做到题目中的同步更新。因为下一状态是根据当前状态生成的,如果更新后,后面的位置的细胞状态可能收到最新更新的细胞状态的影响。因此,我的解法是遍历这个board数组,对于每个位置的八个方向的活细胞数字进行统计,然后将原来数组中需要翻转数字的位置索引记录下来。
- 如果是活细胞,并且活细胞的数目<2或者>3,那么该活细胞要变成死细胞,所以该位置需要翻转,记录结果。
- 如果是死细胞,并且活细胞的数组=3,死细胞变为活细胞,也需要翻转
- 对于如果是活细胞,并且周围活细胞数组=2或者=2,仍然是活细胞,不需要翻转,即不需要记录。
- 最后遍历一次board,将索引的位置进行翻转。
class solution_25 {
public:int direction[8][2]={{-1,0},{1,0},{0,-1},{0,1},{-1,-1},{1,1},{-1,1},{1,-1}};void gameOfLife(vector<vector<int>>& board) {vector<pair<int,int>>result;int count=0;int x,y,nx,ny;for(int i=0;i<board.size();i++){for(int j=0;j<board[0].size();j++){count=0;x=i;y=j;for(int k=0;k<8;k++){nx=i+direction[k][0];ny=j+direction[k][1];if(nx>=0&&nx<board.size()&&ny>=0&&ny<board[0].size()){if(board[nx][ny]){count++;}}}if(board[x][y]==1){if(count<2||count>3){result.push_back(make_pair(x,y));}}if(board[x][y]==0&&count==3){result.push_back(make_pair(x,y));}}}//遍历修改for(int i=0;i<board.size();i++){for(int j=0;j<board[0].size();j++){if(find(result.begin(),result.end(), make_pair(i,j))!=result.end()){if(board[i][j]==0){board[i][j]=1;}else{board[i][j]=0;}cout<<board[i][j];}}}}
};
时间复杂度:O(mn)
空间复杂度:O(mn)
哈希表
40. 赎金信
 解法:构建哈希表,记录magazine 中每个字符出现的次数,然后遍历ransomNote,对哈希表中该字符的个数减1,如果该字符的个数小于0 了,说明不能构成,返回false;否则返回true.
解法:构建哈希表,记录magazine 中每个字符出现的次数,然后遍历ransomNote,对哈希表中该字符的个数减1,如果该字符的个数小于0 了,说明不能构成,返回false;否则返回true.
class Solution {
public:bool canConstruct(string ransomNote, string magazine) {vector<int>res(26,0);for(char c:magazine){res[c-'a']++;}for(char c:ransomNote){res[c-'a']--;if(res[c-'a']<0){return false;}}return true;}
};
时间复杂度:O(m+n),其中 m 是字符串 ransomNote 的长度,n 是字符串 magazine 的长度,我们只需要遍历两个字符一次即可。
空间复杂度:O(∣S∣),S 是字符集,这道题中 S 为全部小写英语字母,因此 ∣S∣=26。
41. 同构字符串

解法一:哈希表
此题是「290. 单词规律」的简化版,需要我们判断 s 和 t 每个位置上的字符是否都一一对应,即 s 的任意一个字符被 t 中唯一的字符对应,同时 t 的任意一个字符被 s 中唯一的字符对应。这也被称为「双射」的关系。
以示例 2 为例,t 中的字符 a 和 r 虽然有唯一的映射 o,但对于 s 中的字符 o 来说其存在两个映射 {a,r},故不满足条件。
因此,我们维护两张哈希表,第一张哈希表 s2t 以 s 中字符为键,映射至 t 的字符为值,第二张哈希表 t2s 以 t 中字符为键,映射至 s 的字符为值。从左至右遍历两个字符串的字符,不断更新两张哈希表,如果出现冲突(即当前下标 index 对应的字符 s[index] 已经存在映射且不为 t[index] 或当前下标 index 对应的字符 t[index] 已经存在映射且不为 s[index])时说明两个字符串无法构成同构,返回 false。
如果遍历结束没有出现冲突,则表明两个字符串是同构的,返回 true 即可。
class Solution {
public:bool isIsomorphic(string s, string t) {unordered_map<char,char>maps2t;unordered_map<char,char>mapt2s;int n=s.size();for(int i=0;i<n;i++){if(maps2t.count(s[i])){char c=maps2t[s[i]];if(c!=t[i]){return false;}}if(mapt2s.count(t[i])){char c=mapt2s[t[i]];if(c!=s[i]){return false;}}maps2t[s[i]]=t[i];mapt2s[t[i]]=s[i];}return true;}
};
时间复杂度:O(n),其中 n 为字符串的长度。我们只需同时遍历一遍字符串 s 和 t 即可。
空间复杂度:O(∣Σ∣),其中 Σ 是字符串的字符集。哈希表存储字符的空间取决于字符串的字符集大小,最坏情况下每个字符均不相同,需要 O(∣Σ∣) 的空间。
42. 单词规律


解法:
我们需要判断字符与字符串之间是否恰好一一对应。即任意一个字符都对应着唯一的字符串,任意一个字符串也只被唯一的一个字符对应。在集合论中,这种关系被称为「双射」。
- 本题使用两个哈希表分别表示字符到字符串的映射p2str,和字符串到字符的映射str2p。
- 然后遍历字符匹配pattern,以及按照空格切分的字符串,如果存在p2str的映射,但不存在str2p的映射,返回false;若存在str2p的映射,但是不存在p2str的映射,返回false
- 同时要注意c++没有很方便的切割字符串的方式,我们利用双指针wstart和wend找到一个单词的起始和结束位置,然后从wstart开始切割出wend-wstart个字符
- 循环的过程中若是wstart超过了s.size,说明pattern还没遍历完,但是s已经遍历完了返回false
- 最后wstart==s.size()+1,则返回true
class Solution {
public:bool wordPattern(string pattern, string s) {unordered_map<char,string>p2s;unordered_map<string,char>str2p;int m=s.size();int n=pattern.size();int wstart=0;int wend=0;for(int i=0;i<n;i++){if(wstart>=m){return false;}while(wend<m&&s[wend]!=' '){wend++;}string str=s.substr(wstart,wend-wstart);char ch=pattern[i];if(p2s.count(ch)&&p2s[ch]!=str){return false;}else if(str2p.count(str)&&str2p[str]!=ch){return false;}else{p2s[ch]=str;str2p[str]=ch;}wstart=wend+1;wend=wstart;}return wstart==(m+1);}
};
时间复杂度:O(n+m),其中 n 为 pattern 的长度,m 为str 的长度。插入和查询哈希表的均摊时间复杂度均为 O(n+m)。每一个字符至多只被遍历一次。
空间复杂度:O(n+m),其中 n 为 pattern 的长度,m 为 str 的长度。最坏情况下,我们需要存储 oattern 中的每一个字符和 str 中的每一个字符串。
43. 有效的字母异位词

解法一:哈希表
t 是 s 的异位词等价于「两个字符串中字符出现的种类和次数均相等」。由于字符串只包含 26 个小写字母,因此我们可以维护一个长度为 26 的频次数组 cnt,先遍历记录字符串 s 中字符出现的频次,然后遍历字符串 t,减去 cnt 中对应的频次,如果出现 cnt[i]<0,则说明 t 包含一个不在 s 中的额外字符,返回 false 即可。
class Solution {
public:bool isAnagram(string s, string t) {vector<int>cnt(26,0);for(char ch:s){cnt[ch-'a']++;}for(char ch:t){cnt[ch-'a']--;}for(int i=0;i<cnt.size();i++){if(cnt[i]!=0){return false;}}return true;}
};
- 时间复杂度:O(n),其中 n 为 s 的长度。
- 空间复杂度:O(S),其中 S 为字符集大小,此处 S=26。
解法二:排序 直接对于两个字符串暴力排序查看是否相同
44. 字母异位词分组

解法一:排序
由于互为字母异位词的两个字符串包含的字母相同,因此对两个字符串分别进行排序之后得到的字符串一定是相同的,故可以将排序之后的字符串作为哈希表的键。
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string,vector<string>>mp;for(string &str:strs){string key=str;sort(key.begin(),key.end());mp[key].emplace_back(str);}vector<vector<string>>ans;for(auto item:mp){ans.emplace_back(item.second);}return ans;}
};
时间复杂度:O(nklogk),其中 n 是 strs 中的字符串的数量,k 是 strs 中的字符串的的最大长度。需要遍历 n 个字符串,对于每个字符串,需要 O(klogk) 的时间进行排序以及 O(1) 的时间更新哈希表,因此总时间复杂度是 O(nklogk)。
空间复杂度:O(nk),其中 n 是 strs 中的字符串的数量,k 是 strs 中的字符串的的最大长度。需要用哈希表存储全部字符串。
解法二:计数
见:https://leetcode.cn/problems/group-anagrams/solutions/520469/zi-mu-yi-wei-ci-fen-zu-by-leetcode-solut-gyoc/?envType=study-plan-v2&envId=top-interview-150
45. 两数之和
 解法一:暴力双重循环,时间复杂度$O(n^2)$,空间复杂度$O(1)$不多说
解法一:暴力双重循环,时间复杂度$O(n^2)$,空间复杂度$O(1)$不多说
解法二:哈希表
- 创建unordered_map的numsToIndex的哈希表,记录nums中的数字的值和在数组中的索引位置的映射关系
- 然后按顺序遍历数组,若在nums[target-index]在numsToIndex出现,那么说明当前已出现可以组成Target的解,直接返回两个索引位置
- 否则,记录当前的num的值和索引i的映射关系
代码:
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {unordered_map<int,int>numsToIndex;for(int i=0;i<nums.size();i++){int flag=numsToIndex.count(target-nums[i]);if(flag){return {numsToIndex[target-nums[i]],i};}else{numsToIndex[nums[i]]=i;}}return {};}
};
时间复杂度:O(N)
空间复杂度:O(N)
46. 快乐数

解法一:
主要是平方最终会走向的可能情况的分析:
- 1.最终会得到1
- 2.最终会进入循环
- 3.值会越来越大,最后接近无穷大
情况三是否会发生?是否会继续变大?
官方中给出的解释列举了每一位数的最大数字的下一位:
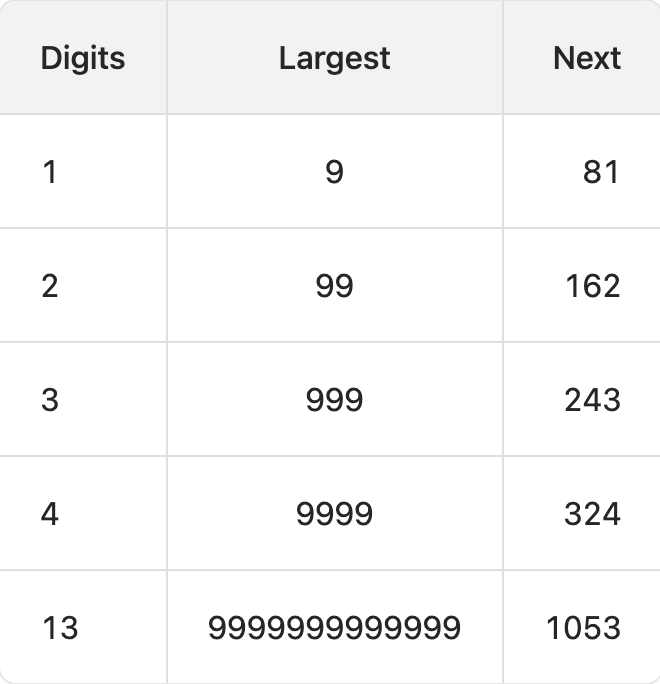
对于 3位数的数字,它不可能大于 243。这意味着它要么被困在 243以下的循环内,要么跌到 1。4 位或 4 位以上的数字在每一步都会丢失一位,直到降到 3位为止。所以我们知道,最坏的情况下,算法可能会在 243 以下的所有数字上循环,然后回到它已经到过的一个循环或者回到 1。但它不会无限期地进行下去,所以我们排除第三种选择。
快慢指针:经常使用到,在判断链表是否有环的场景下
即在找到下一个快乐数的过程中,实际上得到的是一个隐式的链表,其数据结构能形成链表结构。起始的数字是链表的头节点,链表中的其他数字都是节点。因此这个问题可以转换为链表是否有环,即使用快慢指针,慢指针移动一步,快指针移动两步,如果链表中存在环,那么快慢指针一定会相遇。
因此首先快慢指针都指向n的位置,之后每次快指针移动两步,慢指针移动一步,判断两个指针最后是否相遇,或者快指针=1。
class Solution {
public:int getNextHappyNum(int n){int sum=0;while(n>0){int d=n%10;n=n/10;sum+=d*d;}return sum;}bool isHappy(int n) {int lower=n;int faster=n;do{lower=getNextHappyNum(lower);faster=getNextHappyNum(getNextHappyNum(faster));}while(faster!=1&&lower!=faster);return faster==1;}
};
时间复杂度:O(logn)。该分析建立在对前一种方法的分析的基础上,但是这次我们需要跟踪两个指针而不是一个指针来分析,以及在它们相遇前需要绕着这个循环走多少次。
- 如果没有循环,那么快跑者将先到达 1,慢跑者将到达链表中的一半。我们知道最坏的情况下,成本是 O(2⋅logn)=O(logn)。
一旦两个指针都在循环中,在每个循环中,快跑者将离慢跑者更近一步。一旦快跑者落后慢跑者一步,他们就会在下一步相遇。假设循环中有 k 个数字。如果他们的起点是相隔 k−1这是他们可以开始的最远的距离),那么快跑者需要k−1 步才能到达慢跑者,这对于我们的目的来说也是不变的。因此,主操作仍然在计算起始 n 的下一个值,即O(logn)。
空间复杂度:O(1)。
解法二:使用哈希表来判断链表中是否有环:但是这个哈希表比较费空间,因为需要保存所有的平方和
解法三:数学法
解法二和三见官方题解:
202. 快乐数 - 力扣(LeetCode)
47. 存在重复元素II

解法一:hash表分桶法
分桶的方式其实类比于一个问题: 某天老师让全班同学各自说出自己的出生日期,然后统计一下出生日期相差小于等于30天的同学。我们很容易想到,出生在同一个月的同学,一定满足上面的条件。出生在相邻月的同学,也有可能满足那个条件,这就需要计算一下来确定了。但如果月份之间相差了两个月,那就不可能满足这个条件了。 例如某同学出生于6月10日,其他6月出生的同学,都与其相差小于30天。另一些5月20日和7月1日的同学也满足条件。但是4月份的和8月份的同学就不可能满足条件了。
我们按照元素的大小进行分桶,维护一个滑动窗口内的元素对应的元素。
对于元素 x,其影响的区间为 [x−t,x+t]。于是我们可以设定桶的大小为 t+1。如果两个元素同属一个桶,那么这两个元素必然符合条件。如果两个元素属于相邻桶,那么我们需要校验这两个元素是否差值不超过 t。如果两个元素既不属于同一个桶,也不属于相邻桶,那么这两个元素必然不符合条件。
具体地,我们遍历该序列,假设当前遍历到元素 x,那么我们首先检查 x所属于的桶是否已经存在元素,如果存在,那么我们就找到了一对符合条件的元素,否则我们继续检查两个相邻的桶内是否存在符合条件的元素。
如果按照valueDiff的大小进行分桶,那么则分桶公式为num/valuediff,但是这样处暑不能为零,并且假设valuediff=3,数组为[0,1,2,3],3会被分到另一个组,所以分桶的除数应该为valuediff+1;
对于负数,分桶公式应该为num+1/(valuediff+1) -1;
其详细解释见220. 存在重复元素 III - 力扣(LeetCode)
代码:
class Solution {
public:int getID(int x,int w){return x<0?(x+1)/w-1:x/w;}bool containsNearbyAlmostDuplicate(vector<int>& nums, int indexDiff, int valueDiff) {unordered_map<int,int>id2num;int n=nums.size();for(int i=0;i<n;i++){int n=nums[i];int id=getID(n,valueDiff+1);if(id2num.count(id)){return true;}if(id2num.count(id-1)&&abs(n-id2num[id-1])<=valueDiff){return true;}if(id2num.count(id+1)&&abs(n-id2num[id+1])<=valueDiff){return true;}id2num[id]=n;if(i>=indexDiff){id2num.erase(getID(nums[i-indexDiff],valueDiff+1));}}return false;}
};
时间复杂度:O(n),其中 n 是给定数组的长度。每个元素至多被插入哈希表和从哈希表中删除一次,每次操作的时间复杂度均为 O(1)。
空间复杂度:O(min(n,k)),其中 n是给定数组的长度。哈希表中至多包含 min(n,k+1) 个元素。
解法二:滑动窗口+有序集合
见题解:220. 存在重复元素 III - 力扣(LeetCode)
48. 最长连续序列

解法:
- 注意:这题使用到的set是unordered_set,因为其底层是哈希表实现的,可以实现常数O(1)时间的查询。
- 最常规的做法是对于每个数x,分别判断x+1,x+2…x+n是否在哈希表中,若在n+1为一个数字序列长度
- 但是这种做法也会导致 O ( n 2 ) O(n^2) O(n2)的时间复杂度
- 其实观察到这个求连续序列的过程其实是重复的,即对于x+1来说,x+1…x+n为其开始的最长数字序列,但是其已经包含于x…x+n序列中,并且一定不是最长的。
- 所以我们可以通过判断x-1是否在set中来判断其是否已经在其他序列中,然后通过循环查找x+1…x+n来判断最长数字序列长度
代码:
class Solution {
public:int longestConsecutive(vector<int>& nums) {unordered_set<int>set;for(auto n:nums)set.insert(n);int result=0;for(auto n:nums){if(!set.count(n-1)){int currnum=n;int length=1;while(set.count(currnum+1)){currnum++;length++;}result=max(result,length);}}return result;}
};
时间复杂度:O(n)
空间复杂度:O(n)
区间
49. 汇总区间


解法:一次遍历
我们从数组的位置 0 出发,向右遍历。每次遇到相邻元素之间的差值大于 1 时,我们就找到了一个区间。遍历完数组之后,就能得到一系列的区间的列表。
在遍历过程中,维护下标 i 和 end 分别记录区间的起点和终点,对于任何区间都有 i≤end。当得到一个区间时,根据 i和 end 的值生成区间的字符串表示。
- 当 i<end 时,区间的字符串表示为 ‘‘num[i]→num[end]";
- 当 i=end 时,区间的字符串表示为 ‘‘i"。
class Solution {
public:vector<string> summaryRanges(vector<int>& nums) {vector<string>result;int end=0;int i=0;while(i<nums.size()){end=i;while(end<nums.size()-1&&nums[end+1]==nums[end]+1){end++;}if(end==i){result.emplace_back(to_string(nums[end]));}else{result.emplace_back(to_string(nums[i])+"->"+to_string(nums[end]));}i=end;i++;}return result;}
};
- 时间复杂度:O(n),其中 n 为数组的长度。
- 空间复杂度:O(1)。除了用于输出的空间外,额外使用的空间为常数。
50. 合并区间

解法:排序+贪心
用数组res存储最终的答案。
首先,我们将列表中的区间按照左端点升序排序。然后我们将第一个区间加入 res 数组中,并按顺序依次考虑之后的每个区间:
如果当前区间的左端点在数组res 中最后一个区间的右端点之后,那么它们不会重合,我们可以直接将这个区间加入数组 merged 的末尾;
否则,它们重合,我们需要用当前区间的右端点更新数组 merged 中最后一个区间的右端点,将其置为二者的较大值。
其正确性可见官方题解:
56. 合并区间 - 力扣(LeetCode)
代码:
class Solution {
public:vector<vector<int>> merge(vector<vector<int>>& intervals) {vector<vector<int>>res;if(intervals.size()==1)return intervals;sort(intervals.begin(),intervals.end());res.push_back(intervals[0]);for(int i=1;i<intervals.size();i++){int left=res.back()[0];int right=res.back()[1];if(intervals[i][0]<=right){if(intervals[i][1]>right){res.pop_back();res.push_back({left,intervals[i][1]});} }else{res.push_back(intervals[i]);}}return res;}
};
时间复杂度:O(nlogn),其中 n 为区间的数量。除去排序的开销,我们只需要一次线性扫描,所以主要的时间开销是排序的O(nlogn)。
空间复杂度:O(logn),其中 n 为区间的数量。这里计算的是存储答案之外,使用的额外空间。O(logn) 即为排序所需要的空间复杂度。
51. 插入区间


解法:模拟+区间合并+一次遍历
-
对于区间 $S1=[l_1,r_1] $和 S 2 = [ l 2 , r 2 ] S_2 = [l_2, r_2] S2=[l2,r2]S,如果它们之间没有重叠(没有交集),说明要么 S 1 S_1 S1在 S 2 S_2 S2的左侧,此时有 r 1 < l 2 r_1 < l_2 r1<l2;要么 S 1 S_1 S1在 S 2 S_2 S2的右侧,此时有 l 1 > r 2 l_1 > r_2 l1>r2。
-
如果 r 1 < l 2 r_1 < l_2 r1<l2和 l 1 > r 2 l_1 > r_2 l1>r2二者均不满足,说明 S 1 S_1 S1 和 S 2 S_2 S2 必定有交集,它们的交集即为 [ max ( l 1 , l 2 ) , min ( r 1 , r 2 ) ] [\max(l_1, l_2), \min(r_1, r_2)] [max(l1,l2),min(r1,r2)],并集为 [ min ( l 1 , l 2 ) , max ( r 1 , r 2 ) ] [\min(l_1, l_2), \max(r_1, r_2)] [min(l1,l2),max(r1,r2)]
算法思路:
- 在给定的区间集合 X \mathcal{X} X 互不重叠的前提下,当我们需要插入一个新的区间 S = [ left , right ] S = [\textit{left}, \textit{right}] S=[left,right]时,我们只需要:
- 找出所有与区间 S 重叠的区间集合 X ′ \mathcal{X'} X′,将 X ′ \mathcal{X'} X′ 中的所有区间连带上区间 S 合并成一个大区间;
最终的答案即为不与 X ′ \mathcal{X}' X′ 重叠的区间以及合并后的大区间。
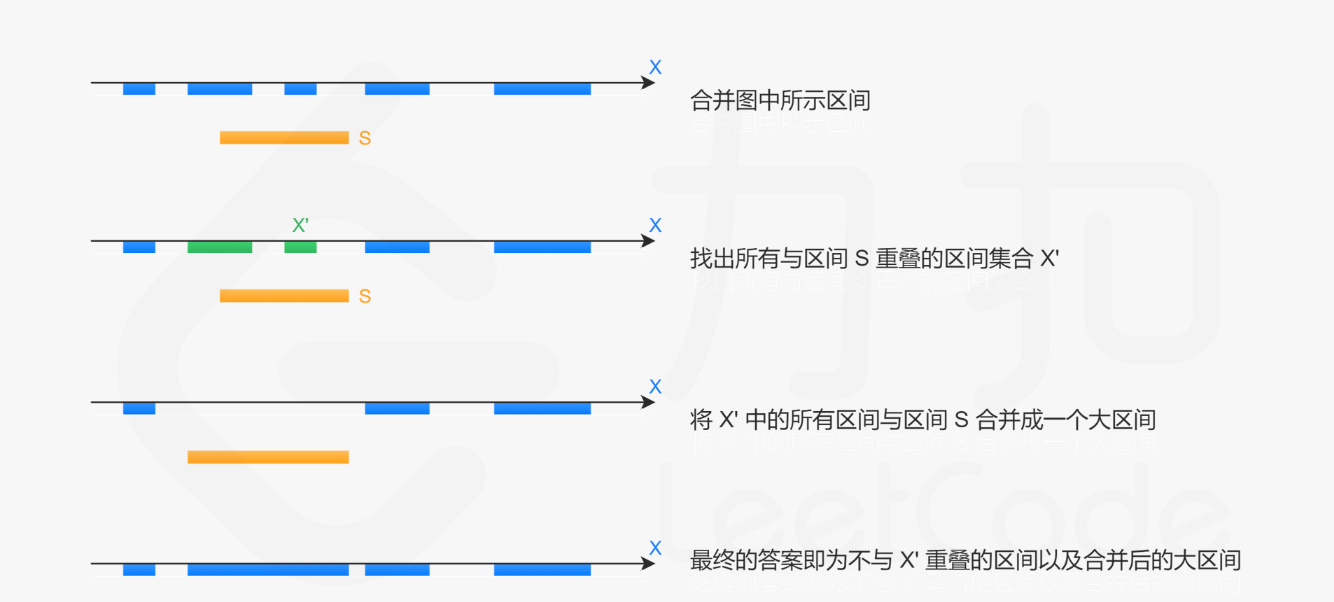
这样做的正确性在于,给定的区间集合中任意两个区间都是没有交集的,因此所有需要合并的区间,就是所有与区间 S 重叠的区间。
并且,在给定的区间集合已经按照左端点排序的前提下,所有与区间 S 重叠的区间在数组 intervals \textit{intervals} intervals 中下标范围是连续的,因此我们可以对所有的区间进行一次遍历,就可以找到这个连续的下标范围。
当我们遍历到区间 [ l i , r i ] [l_i,r_i] [li,ri]时:
如果 r i < left r_i < \textit{left} ri<left,说明 [ l i , r i ] [l_i,r_i] [li,ri] 与 S 不重叠并且在其左侧,我们可以直接将 [ l i , r i ] [l_i,r_i] [li,ri]加入答案;
如果 l i > right l_i > \textit{right} li>right,说明 [ l i , r i ] [l_i,r_i] [li,ri]与 S 不重叠并且在其右侧,我们可以直接将 [ l i , r i ] [l_i,r_i] [li,ri]加入答案;
如果上面两种情况均不满足,说明 [ l i , r i ] [l_i,r_i] [li,ri]与 S 重叠,我们无需将 [ l i , r i ] [l_i,r_i] [li,ri] 加入答案。此时,我们需要将 S 与 [ l i , r i ] [l_i,r_i] [li,ri]
合并,即将 S 更新为其与 [ l i , r i ] [l_i,r_i] [li,ri]的并集。
那么我们应当在什么时候将区间 S 加入答案呢?由于我们需要保证答案也是按照左端点排序的,因此当我们遇到第一个 满足 l i > right l_i > \textit{right} li>right
的区间时,说明以后遍历到的区间不会与 S 重叠,并且它们左端点一定会大于 S 的左端点。此时我们就可以将 S 加入答案。特别地,如果不存在这样的区间,我们需要在遍历结束后,将 S 加入答案。
代码:
class Solution {
public:vector<vector<int>> insert(vector<vector<int>>& intervals, vector<int>& newInterval) {vector<vector<int>>res;int n=intervals.size();bool isInsert=false;int left=newInterval[0];int right=newInterval[1];for(int i=0;i<n;i++){if(intervals[i][1]<left){res.push_back(intervals[i]);}else if(intervals[i][0]>right){if(!isInsert){//找到了插入位置res.push_back({left,right});isInsert=true;}res.push_back(intervals[i]);}else{//有交集left=min(left,intervals[i][0]);right=max(right,intervals[i][1]);}}if(!isInsert){res.push_back({left,right});}return res;}
};
时间复杂度:O(n),其中 n 是数组 intervals 的长度,即给定的区间个数。
空间复杂度:O(1)。除了存储返回答案的空间以外,我们只需要额外的常数空间即可。
52. 用最少数量的箭引爆气球

解法:排序+贪心
我们把气球看做区间,箭还是箭,箭是垂直向上射出。
首先,对于右端点最小的那个区间,如果想要用箭穿过它,那么一定从它的右端点穿过(从右端点穿过才只会穿过更多的区间)。
接下来,对于这只箭能未能穿过的区间,再从中找出右端点最小的区间。对于这只箭未能穿过的区间,如此往复的找下去。最终我们使用的箭数就是最少的。
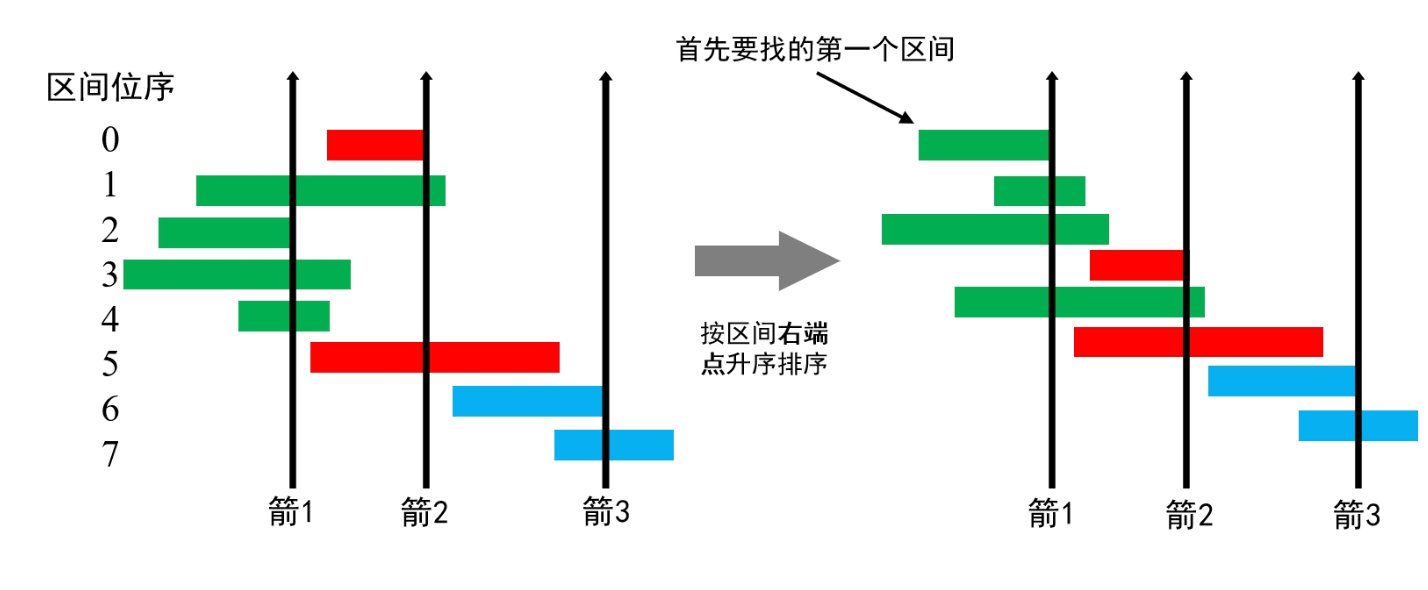 如何寻找第一个右端点最小的区间,以及在未被第一支箭穿过的剩余区间中,继续寻找第一个右端点最小的区间呢? 当我们把每个区间按照右端点升序排序后,显然第一个区间就是我们最开始要找的第一个区间,后序也可以进一步找到满足条件的最小右端点区间。具体的过程如下:
如何寻找第一个右端点最小的区间,以及在未被第一支箭穿过的剩余区间中,继续寻找第一个右端点最小的区间呢? 当我们把每个区间按照右端点升序排序后,显然第一个区间就是我们最开始要找的第一个区间,后序也可以进一步找到满足条件的最小右端点区间。具体的过程如下:
首先将区间按照右端点升序排序,此时位序为1的区间就是我们要找的第一个区间(如图),我们需要记录下第一个区间的右端点right(射出第一支箭),然后继续遍历,此时就会存在两种情况:
- 对于左端点小于等于right的区间,说明该区间能被前面的箭(right)穿过。
- 对于接下来左端点大于right的区间,说明前面这支箭无法穿过该区间(即:该区间就是未被箭穿过的区间集合的第一个区间),我们又找到了第一个未被箭穿过的区间,此时我们用一把新的箭穿过该区间的右端点(即更新
right = points[i][1]),并将使用的箭数+1。如此往复。
代码:
bool pointscmp(const vector<int>&a,const vector<int>&b){return a[1]<b[1];
}
class Solution {
public:int findMinArrowShots(vector<vector<int>>& points) {sort(points.begin(),points.end(),pointscmp);int result=1;int arrow=points[0][1];int n=points.size();for(int i=1;i<n;i++){if(points[i][0]<=arrow){continue;}arrow=points[i][1];result++;}return result;}
};
时间复杂度:O(nlogn),其中 nn是数组 points 的长度。排序的时间复杂度为 O(nlogn),对所有气球进行遍历并计算答案的时间复杂度为 O(n),其在渐进意义下小于前者,因此可以忽略。
空间复杂度:O(logn),即为排序需要使用的栈空间。
栈
53. 有效的括号

解法:利用栈来解决,首先字符串为空或者长度为1,一定返回false;
然后便利字符串中的括号,如果是左括号则入栈,如果碰到右括号,如果栈中非空,并且栈顶有对应的左括号与其匹配,则弹栈;否则将右括号入栈;
最后如果栈为空,说明匹配,否则不匹配
class solution67 {
public:bool isValid(string s) {vector<char>stack;if(s.empty()||s.size()==1)return false;for( auto item:s){if(item=='('||item=='['||item=='{')stack.emplace_back(item);else if(item==')'){if(stack.empty()||stack.back()!='(')stack.emplace_back(item);elsestack.pop_back();}else if(item==']'){if(stack.empty()||stack.back()!='[')stack.emplace_back(item);elsestack.pop_back();}else if(item=='}'){if(stack.empty()||stack.back()!='{')stack.emplace_back(item);elsestack.pop_back();}}return stack.empty();}
};时间复杂度:O(n)
空间复杂度:O(n)
54. 简化路径


解法:使用栈来解决,首先将path根据/分隔为由若干个字符串组成的列表,因为多个/最终也表示/。但是由于c++没有split函数,因此要自己手动实现一个split方法。之后对于vector内的元素,如果是一个点,保持不变,两个点目录切换到上一级,对应弹栈,若都不是,代表目录名,则入栈。
最后将目录名用“/”连接输出即可
class solution62 {public:string simplifyPath(string path) {vector<string>result;int n=path.length();//split path by /for(int i=0;i<n;){if(path[i]=='/'){i++;if(i==n)break;string tmp="";while(path[i]!='/'&&i<n){tmp+=path[i];i++;}if(!tmp.empty()){result.emplace_back(tmp);}}}vector<string>last;for(auto r:result){if(r==".")continue;else if(r==".."){if(!last.empty())last.pop_back();}elselast.emplace_back(r);}string lastreuslt="/";int m=last.size();for(int i=0;i<m;i++){lastreuslt+=last[i];if(i!=m-1){lastreuslt+="/";}}return lastreuslt;}
};时间复杂度:O(n),其中 n 是字符串path 的长度。
空间复杂度:O(n)。我们需要 O(n) 的空间存储names 中的所有字符串。
55. 最小栈


解法:用一个辅助栈 min_stack,用于存获取 stack 中最小值。
算法流程:
- push() 方法: 每当push()新值进来时,如果 小于等于 min_stack 栈顶值,则一起 push() 到 min_stack,即更新了栈顶最小值;
- pop() 方法: 判断将 pop() 出去的元素值是否是 min_stack 栈顶元素值(即最小值),如果是则将 min_stack 栈顶元素一起 pop(),这样可以保证 min_stack 栈顶元素始终是 stack 中的最小值。
- getMin()方法: 返回 min_stack 栈顶即可。
min_stack 作用分析:
min_stack 等价于遍历 stack所有元素,把升序的数字都删除掉,留下一个从栈底到栈顶降序的栈。
相当于给 stack 中的降序元素做了标记,每当 pop() 这些降序元素,min_stack 会将相应的栈顶元素 pop() 出去,保证其栈顶元素始终是 stack 中的最小元素。
class MinStack {
public:::stack<int> stack;::stack<int> min_stack;MinStack() {}void push(int val) {stack.push(val);if(min_stack.empty()||val<=min_stack.top()){min_stack.push(val);}}void pop() {int val=stack.top();stack.pop();if(val==min_stack.top()){min_stack.pop();}}int top() {return stack.top();}int getMin() {return min_stack.top();}
};/*** Your MinStack object will be instantiated and called as such:* MinStack* obj = new MinStack();* obj->push(val);* obj->pop();* int param_3 = obj->top();* int param_4 = obj->getMin();*/
时间复杂度 O(1) :压栈,出栈,获取最小值的时间复杂度都为 O(1) 。
空间复杂度 O(N) :包含 N 个元素辅助栈占用线性大小的额外空间。
56. 逆波兰表达式求值

解法:中缀表达式可以使用栈来维护,首先遍历算数表达式,如果遇到数字入栈,如果遇到符号,则出栈两个数字,并且与符号相作用然后入栈,最后栈中剩余的唯一数字则为最后结果。
代码:
class solution64 {
public:int evalRPN(vector<string>& tokens) {vector<int>stacks;for(auto item:tokens){if(item=="+"){int t1=stacks.back();stacks.pop_back();int t2=stacks.back();stacks.pop_back();int tmp=t2+t1;stacks.emplace_back(tmp);}else if(item=="-"){int t1=stacks.back();stacks.pop_back();int t2=stacks.back();stacks.pop_back();int tmp=t2-t1;stacks.emplace_back(tmp);}else if(item=="*"){int t1=stacks.back();stacks.pop_back();int t2=stacks.back();stacks.pop_back();int tmp=t2*t1;stacks.emplace_back(tmp);}else if(item=="/"){int t1=stacks.back();stacks.pop_back();int t2=stacks.back();stacks.pop_back();int tmp=t2/t1;stacks.emplace_back(tmp);}else{int t= std::atoi(item.c_str());stacks.emplace_back(t);}}return stacks.back();}
};
时间复杂度:O(n),其中 n 是数组 tokens 的长度。需要遍历数组 tokens 一次,计算逆波兰表达式的值。
空间复杂度:O(n),其中 n是数组tokens 的长度。使用栈存储计算过程中的数,栈内元素个数不会超过逆波兰表达式的长度。
57. 基本计算器

解法:使用两个栈 num 和 op 。
num: 存放所有的数字 op :存放所有的数字以外的操作。(±)
1.首先预处理字符串,将所有空格去掉。
2.然后对于所有的"(“直接放入符号栈
3.如果有新的符号入栈,且不是”)“,可以将当前栈内可以计算的符号进行计算,避免在通过”)“进行判断计算的时候,将(-+)操作顺序变换导致出错。
4.如果遇到”)“将当前”("前的所有符号都计算,并且弹出左括号,计算结果加入num
时刻注意一些细节:由于第一个数可能是负数,如“-2+1”,为了减少边界判断,先往 nums 添加一个 0;
为防止 () 内出现的首个字符为运算符如(-2)(+2),如果遇到(-,(+,在num中添加0
代码:
class solution66 {
public:int calculate(string s) {vector<int>num;//为了防止第一个数是负数num.emplace_back(0);vector<char>op;bool flag=false;string ns="";for(int i=0;i<s.size();i++){if(s[i]==' ')continue;ns+=s[i];}int n=ns.size();for(int i=0;i<n;i++){if(ns[i]=='('){if(ns[i+1]=='-'||ns[i+1]=='+'){num.emplace_back(0);}op.emplace_back(ns[i]);}else{if(isdigit(ns[i])){int m=0;while(isdigit(ns[i])){m=m*10+int(ns[i]-'0');i++;}num.emplace_back(m);i--;}else if(ns[i]=='+'||ns[i]=='-'){//将栈内能算的先算,避免之后算让如(-+)操作的+号运算比-前int t1,t2,tmp;while(!op.empty()&&op.back()!='('){t1=num.back();num.pop_back();t2=num.back();num.pop_back();char o=op.back();op.pop_back();if(o=='+')tmp=t2+t1;else if(o=='-')tmp=t2-t1;num.emplace_back(tmp);}op.emplace_back(ns[i]);}else if(ns[i]==')'){int t1,t2,tmp;while(op.back()!='('){t1=num.back();num.pop_back();t2=num.back();num.pop_back();char o=op.back();op.pop_back();if(o=='+')tmp=t2+t1;else if(o=='-')tmp=t2-t1;num.emplace_back(tmp);}op.pop_back();}}}int t1,t2,tmp;while(!op.empty()){char o=op.back();op.pop_back();t1=num.back();num.pop_back();t2=num.back();num.pop_back();if(o=='+')tmp=t2+t1;else if(o=='-')tmp=t2-t1;num.emplace_back(tmp);}return num.back();}
};
时间复杂度:o(n)
空间复杂度:o(n)
链表
58. 环形链表
删除排序链表中重复的元素||

解法一:一次遍历
由于给定的链表是排好序的,因此重复的元素在链表中出现的位置是连续的,因此我们只需要对链表进行一次遍历,就可以删除重复的元素。由于链表的头节点可能会被删除,因此我们需要额外使用一个哑节点(dummy node)指向链表的头节点。
具体地,我们从指针 cur 指向链表的哑节点,随后开始对链表进行遍历。如果当前 cur.next 与 cur.next.next 对应的元素相同,那么我们就需要将 cur.next 以及所有后面拥有相同元素值的链表节点全部删除。我们记下这个元素值 x,随后不断将 cur.next 从链表中移除,直到 cur.next 为空节点或者其元素值不等于 x 为止。此时,我们将链表中所有元素值为 x 的节点全部删除。
如果当前 cur.next 与 cur.next.next 对应的元素不相同,那么说明链表中只有一个元素值为 cur.next 的节点,那么我们就可以将 cur 指向 cur.next。
当遍历完整个链表之后,我们返回链表的的哑节点的下一个节点 dummy.next 即可。
细节
需要注意 cur.next 以及 cur.next.next 可能为空节点,如果不加以判断,可能会产生运行错误。
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* deleteDuplicates(ListNode* head) {ListNode*dumpy=new ListNode(0);dumpy->next=head;ListNode*cur=dumpy;while(cur->next&&cur->next->next){if(cur->next->val==cur->next->next->val){int x=cur->next->val;while(cur->next&&cur->next->val==x){cur->next=cur->next->next;}}else{cur=cur->next;}}return dumpy->next;}
};
- 时间复杂度:O(n),其中 n 是链表的长度。
- 空间复杂度:O(1)。
59. 两数相加
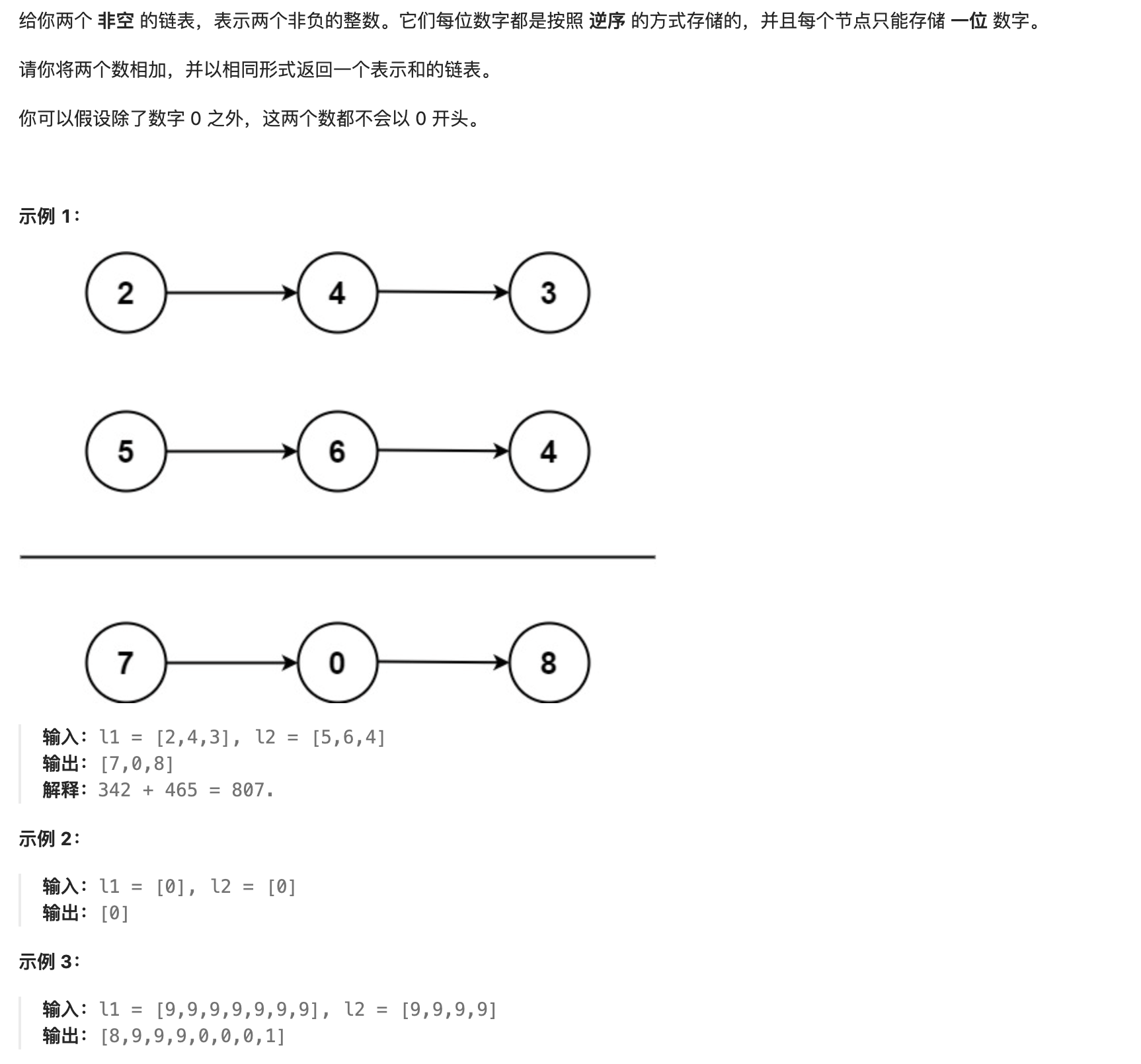 解法: * 首先采用哑节点dumpy,dumpy的next即我们需要返回的头节点,之后由节点相加产生的新节点都连接在dumpy之后。 * 由于输入的两个链表都是逆序存储数字的位数的,因此两个链表中同一位置的数字可以直接相加。 * 我们同时遍历两个链表,逐位计算它们的和,并与当前位置的进位值相加。具体而言,如果当前两个链表处相应位置的数字为 n1,n2,进位值为 carry,则它们的和n1+n2+carry;其中,答案链表处相应位置的数字为 $(n1+n2+carry)mod10$,而新的进位值为$\lfloor\frac{n1+n2+\textit{carry}}{10}\rfloor$ * 如果两个链表的长度不同,则可以认为长度短的链表的后面有若干个 0 。
解法: * 首先采用哑节点dumpy,dumpy的next即我们需要返回的头节点,之后由节点相加产生的新节点都连接在dumpy之后。 * 由于输入的两个链表都是逆序存储数字的位数的,因此两个链表中同一位置的数字可以直接相加。 * 我们同时遍历两个链表,逐位计算它们的和,并与当前位置的进位值相加。具体而言,如果当前两个链表处相应位置的数字为 n1,n2,进位值为 carry,则它们的和n1+n2+carry;其中,答案链表处相应位置的数字为 $(n1+n2+carry)mod10$,而新的进位值为$\lfloor\frac{n1+n2+\textit{carry}}{10}\rfloor$ * 如果两个链表的长度不同,则可以认为长度短的链表的后面有若干个 0 。
注意容易错的位置:
如果链表遍历结束后,有carry>0,还需要在答案链表的后面附加一个节点,节点的值为 carry。
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {ListNode*dumpy=new ListNode();ListNode*cur;cur=dumpy;int carry=0;while(l1||l2){int n1=l1?l1->val:0;int n2=l2?l2->val:0;int sum=n1+n2+carry;carry=sum/10;sum=sum%10;ListNode*node=new ListNode(sum);cur->next=node;cur=cur->next;if(l1)l1=l1->next;if(l2)l2=l2->next;}if(carry>0){cur->next=new ListNode(carry);}return dumpy->next; }
};
时间复杂度:O(max(m,n))其中m和n分别为两个链表的长度。
空间复杂度:O(1)
60. 合并两个有序链表
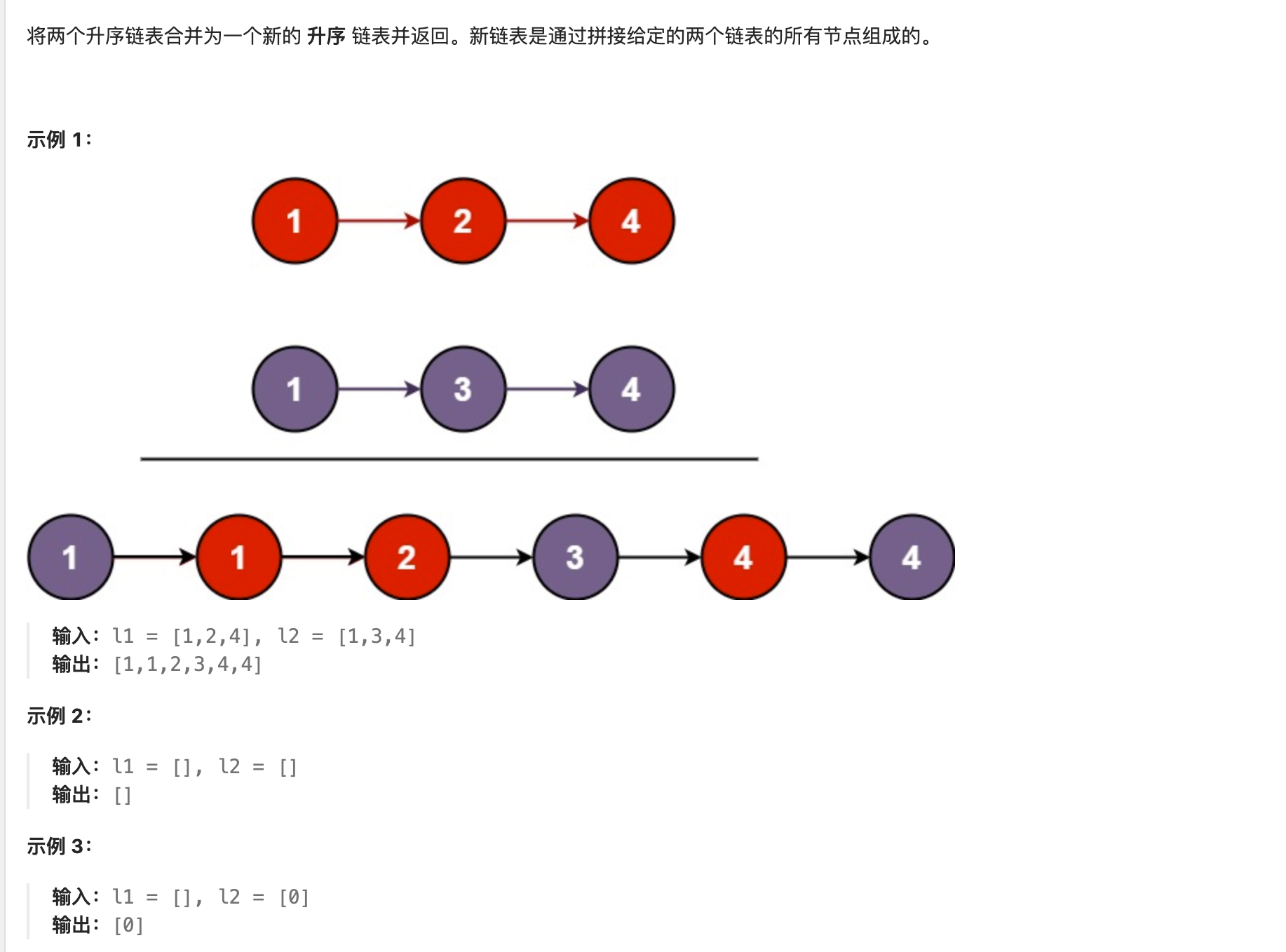 解法一:迭代 * 对于合并有序链表,可以和合并两个有序数组的相同处理方式,利用first的second指针分别指向list1和list2的头节点 * 同时设置哑节点dumpy,为了避免格外一些特殊情况判断 * 初始化时,cur=dumpy * 那么则移动first和second指针,将其val值较小的节点连在cur之后,并且将这个指针后移动 * 如果两个指针指向的val相同,则两个指针都需要向后移动,并且这两个节点都需要移到cur之后 * 当first或者second有一个为null结束循环,对于非空的指针,直接将cur->next与其相连
解法一:迭代 * 对于合并有序链表,可以和合并两个有序数组的相同处理方式,利用first的second指针分别指向list1和list2的头节点 * 同时设置哑节点dumpy,为了避免格外一些特殊情况判断 * 初始化时,cur=dumpy * 那么则移动first和second指针,将其val值较小的节点连在cur之后,并且将这个指针后移动 * 如果两个指针指向的val相同,则两个指针都需要向后移动,并且这两个节点都需要移到cur之后 * 当first或者second有一个为null结束循环,对于非空的指针,直接将cur->next与其相连
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {ListNode * dump=new ListNode();ListNode*first=list1;ListNode*second=list2;ListNode*cur=dump;while(first!=nullptr&&second!=nullptr){if(first->val<second->val){ListNode*tmp=first;first=first->next;cur->next=tmp;cur=cur->next;}else if(first->val>second->val){ListNode*tmp=second;second=second->next;cur->next=tmp;cur=cur->next;}else{ListNode*tmp1=first;first=first->next;ListNode*tmp2=second;second=second->next;cur->next=tmp1;cur=cur->next;cur->next=tmp2;cur=cur->next;}}if(first==nullptr&&second!=nullptr){cur->next=second;}else {cur->next=first;}return dump->next;}
};
时间复杂度:O(m+n)
空间复杂度:O(1)
解法二:递归 见官方题解21. 合并两个有序链表 - 力扣(LeetCode)
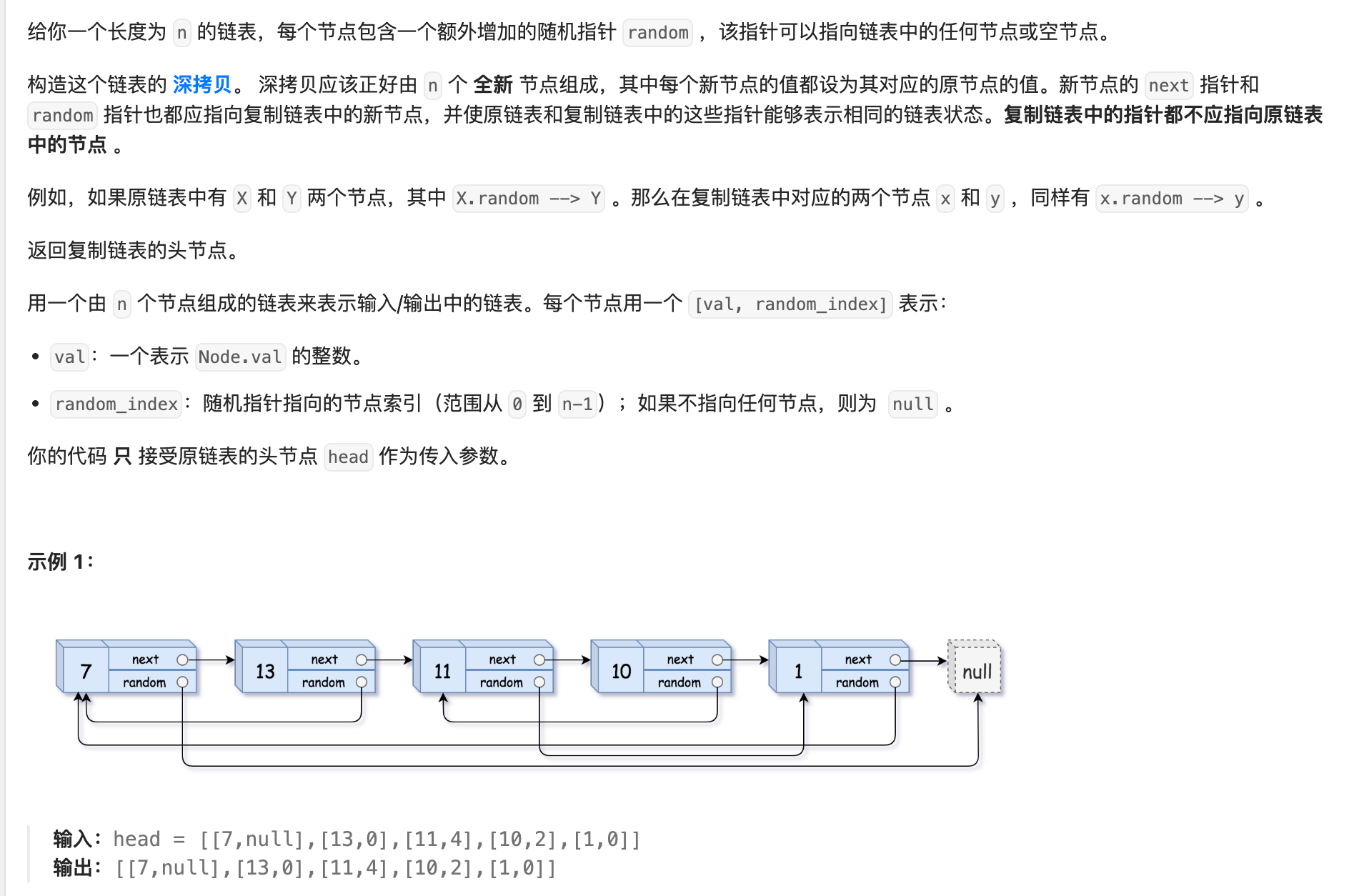
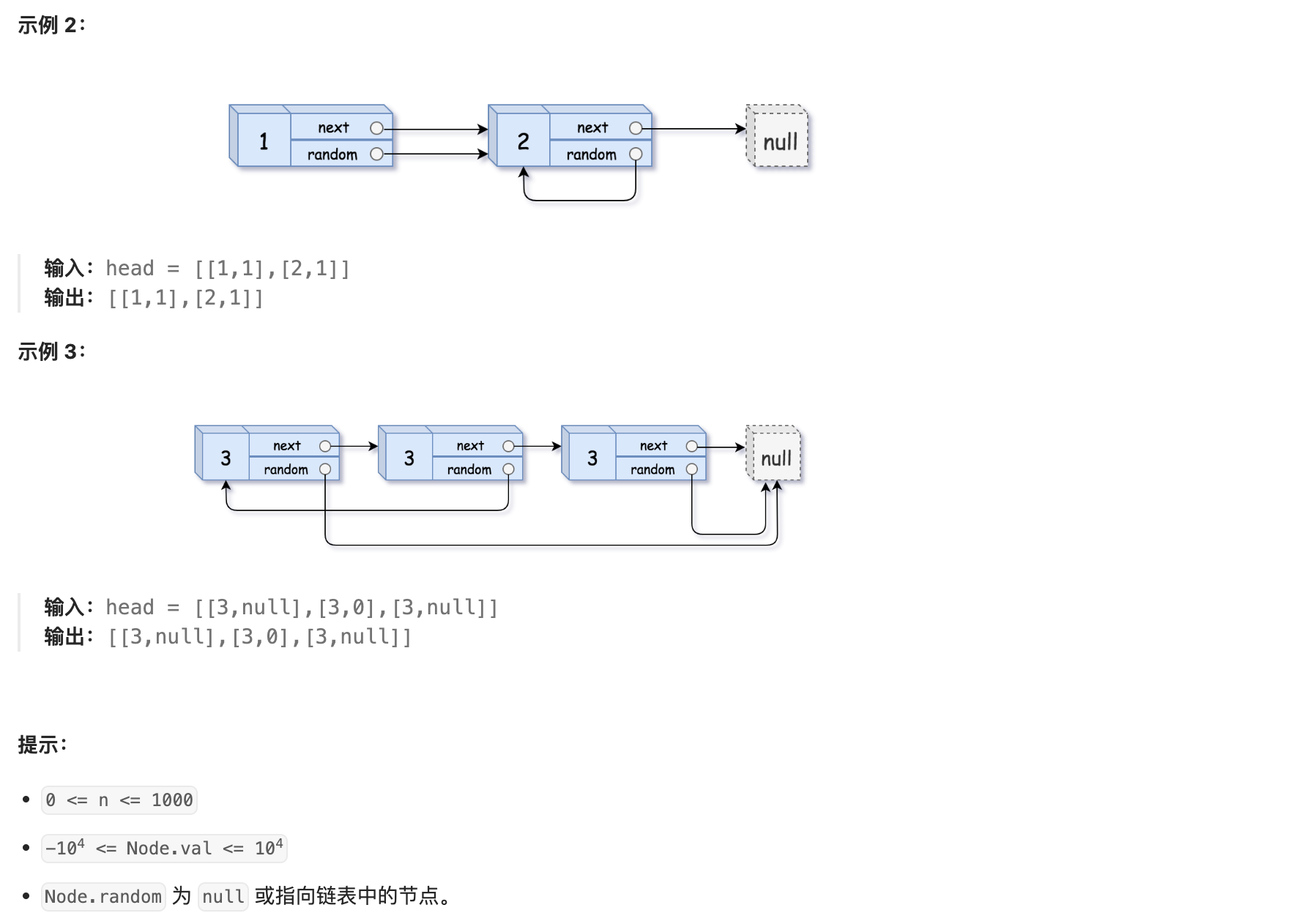
61. 随机链表的复制
解法1:哈希表
因为单链表的复制比较简单,只需要扫描一遍。但是这个链表多了一个Random指针,有可能顺序复制的时候,Radom指针指向的位置的节点还未创建。因此,利用哈希表的查询特点,考虑构建 原链表节点 和 新链表对应节点 的键值对映射关系,提前创建好所有的复制节点,再遍历构建新链表各节点的 next 和 random 引用指向即可。
算法流程:
- 若头节点 head 为空节点,直接返回 lnull 。
- 初始化: 哈希表 map,节点 cur 指向头节点。
- 复制链表:
- 建立新节点,并向 map添加键值对 (原 cur 节点, 新 cur 节点【
为新建节点】)。 - cur 遍历至原链表下一节点。
- 建立新节点,并向 map添加键值对 (原 cur 节点, 新 cur 节点【
- 构建新链表的引用指向:
- 构建新节点的 next 和 random 引用指向。
- cur 遍历至原链表下一节点。
- 返回值: 新链表的头节点。
/*
// Definition for a Node.
class Node {
public:int val;Node* next;Node* random;Node(int _val) {val = _val;next = NULL;random = NULL;}
};
*/class Solution {
public:Node* copyRandomList(Node* head) {if(head==nullptr)return nullptr; Node*cur=head;Node*copyhead=new Node(cur->val);unordered_map<Node*,Node*>map;map[cur]=copyhead;cur=cur->next;while(cur!=nullptr){map[cur]=new Node(cur->val);cur=cur->next;}cur=head;while(cur!=nullptr){map[cur]->next=map[cur->next];map[cur]->random=map[cur->random];cur=cur->next;}return copyhead;}
};
时间复杂度 O(N) : 两轮遍历链表,O(N) 时间。
空间复杂度 O(N) : 哈希表 map使用线性大小的额外空间。
解法二:递归+哈希表
本题要求我们对一个特殊的链表进行深拷贝。如果是普通链表,我们可以直接按照遍历的顺序创建链表节点。而本题中因为随机指针的存在,当我们拷贝节点时,「当前节点的随机指针指向的节点」可能还没创建,因此我们需要变换思路。一个可行方案是,我们利用回溯的方式,让每个节点的拷贝操作相互独立。对于当前节点,我们首先要进行拷贝,然后我们进行「当前节点的后继节点」和「当前节点的随机指针指向的节点」拷贝,拷贝完成后将创建的新节点的指针返回,即可完成当前节点的两指针的赋值。
具体地,我们用哈希表记录每一个节点对应新节点的创建情况。遍历该链表的过程中,我们检查「当前节点的后继节点」和「当前节点的随机指针指向的节点」的创建情况。如果这两个节点中的任何一个节点的新节点没有被创建,我们都立刻递归地进行创建。当我们拷贝完成,回溯到当前层时,我们即可完成当前节点的指针赋值。注意一个节点可能被多个其他节点指向,因此我们可能递归地多次尝试拷贝某个节点,为了防止重复拷贝,我们需要首先检查当前节点是否被拷贝过,如果已经拷贝过,我们可以直接从哈希表中取出拷贝后的节点的指针并返回即可。
见官方题解:138. 随机链表的复制 - 力扣(LeetCode)
62. 反转链表II
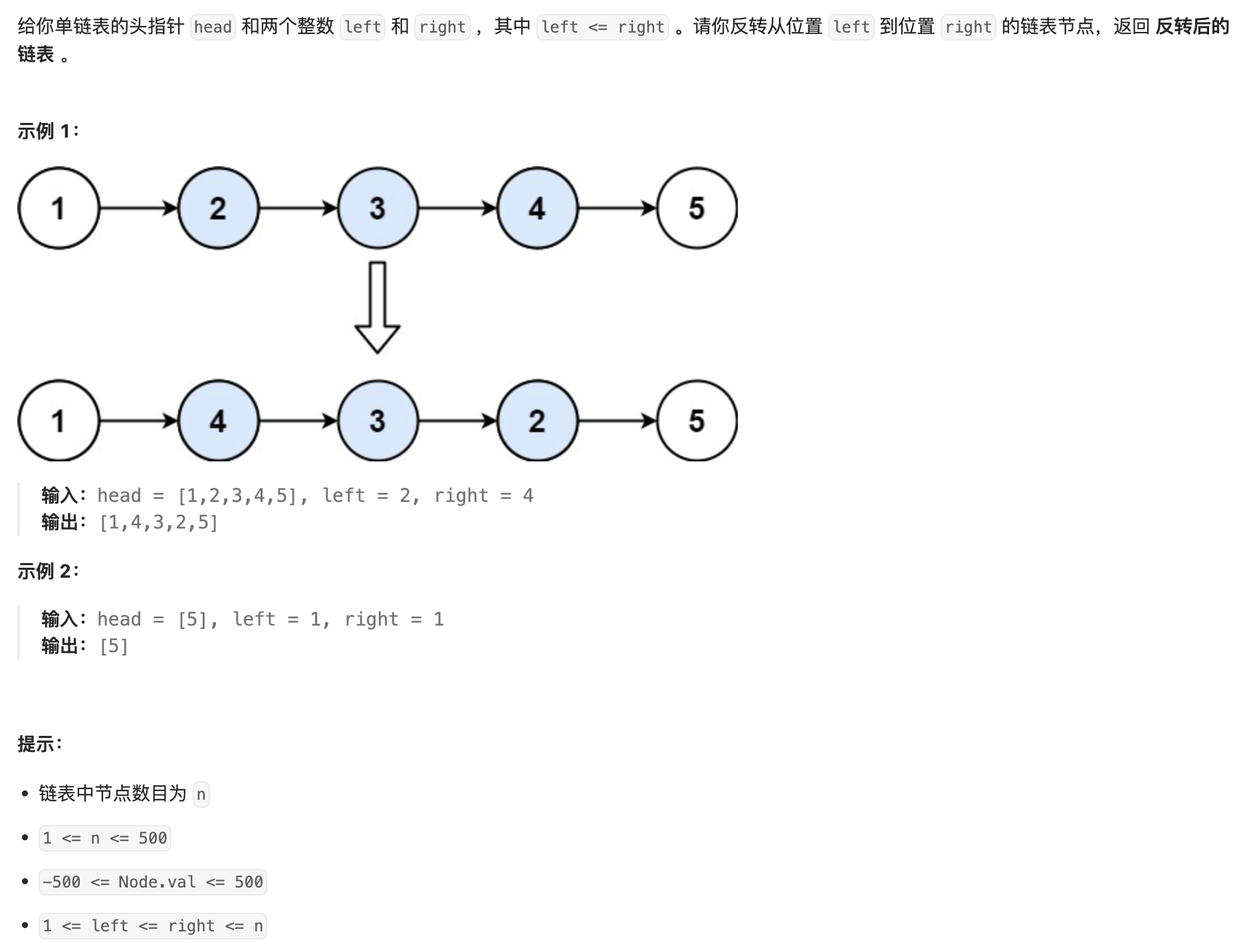
解法一:
- 一次遍历找到反转区间的前一个节点pre和后一个节点next
- 利用栈将区间翻转:即弹栈并将pre与栈中节点相连
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* reverseBetween(ListNode* head, int left, int right) {int len=right-left+1;ListNode *dumpy=new ListNode();ListNode*cur=dumpy;dumpy->next=head;int cnt=0;ListNode*pre,*next;stack<ListNode*>s;while(cnt<left-1){cur=cur->next;cnt++;}pre=cur;cnt++;cur=cur->next;while(cnt<=right){s.push(cur);cur=cur->next;cnt++;}next=cur;while(!s.empty()){ListNode*tmp=s.top();s.pop();pre->next=tmp;pre=pre->next;}pre->next=next;return dumpy->next;}
};
时间复杂度:O(N)
空间复杂度:O(1)
解法二:**一次遍历。**将需要逆转的链表区间的左节点不动 ,将区间内的节点以此头插入左节点之后,实现反转链表,见官方题解
92. 反转链表 II - 力扣(LeetCode)
63. K 个一组翻转链表
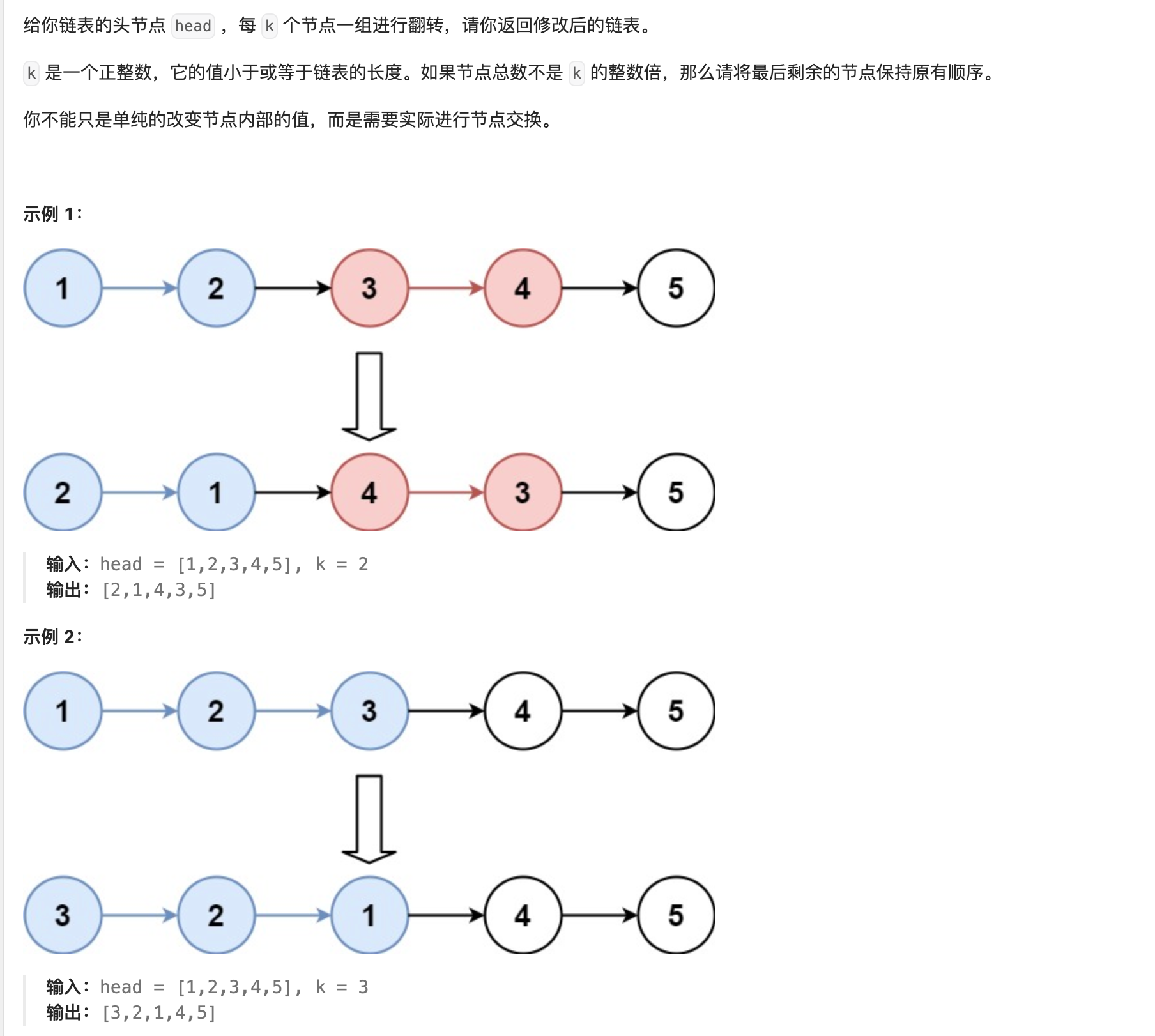
解法:本题需要对局部区间链表进行翻转,主要抓住四个关键节点位置:
- reversePre:反转区间的前一个节点;
- reverseHead:反转区间的头节点;
- reverseTail:反转区间的尾节点;
- reverseNext:反转区间的下一个节点;
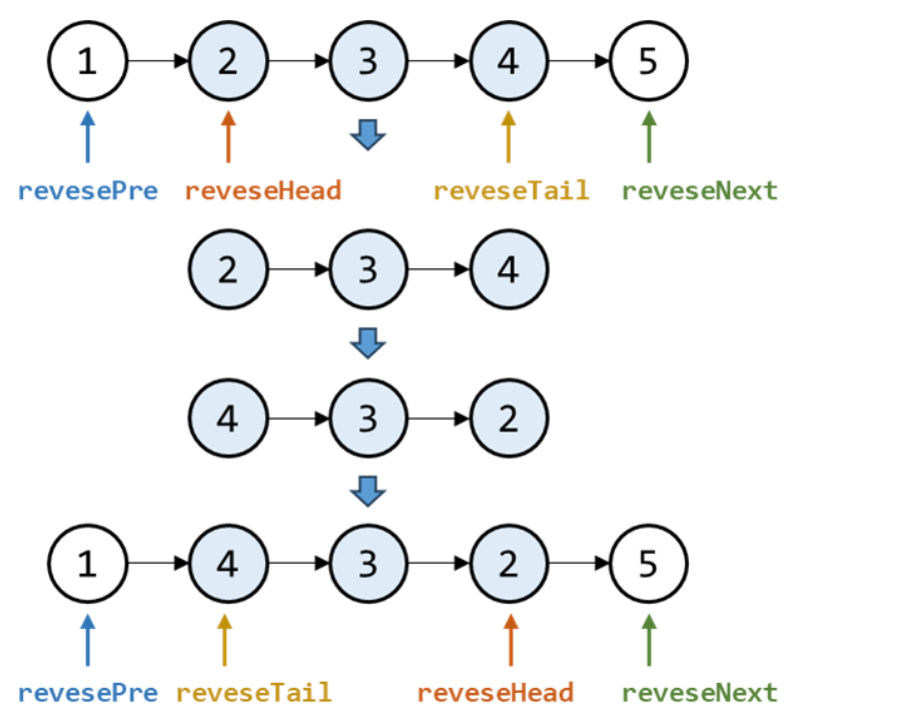
首先,引入dumpy节点,dumpy->next=head;
初始化:
- rPre=dumpy;
- rHead=dumpy->next;
- rTail=rPre;
然后移动rTail指针k次,移动的过程中判断是否rTail指针为空,若为空,则直接返回dumpy->next为翻转链表的头节点。
移动k次之后,我们翻转【rHead,rTail】之间的链表。
反转区间链表的过程:
- pre=rHead;
- cur=rHead->next;
- 注意cur的循环退出条件为当前rTail的next节点,因为反转过程中rTail的next节点会改变,可能造成问题。
因此,while循环前,需要用rNext记录当前rTail的next节点。 - 翻转链表的过程如就是将cur指向pre的过程,然后移动pre和cur指针。
区间循环结束之后,此时的cur指针恰好为rNext位置,pre的位置是当前区间的头指针即rTail,此时将rPre连接pre,rHead连接cur;
然后更新rTail和rPre指针的位置为rHead,rHead的位置为rNext
代码:
class solution75 {
public:ListNode* reverseKGroup(ListNode* head, int k) {ListNode *dumpy=new ListNode();dumpy->next=head;ListNode*rPre=dumpy;ListNode*rHead=dumpy->next;ListNode*rTail=dumpy;while(rTail!=nullptr){for(int i=0;i<k;i++){rTail=rTail->next;if(rTail==nullptr){return dumpy->next;}}//翻转rHead,rtail的链表ListNode*pre=rHead;ListNode*cur=rHead->next;ListNode*rNext=rTail->next;while(cur!=rNext){ListNode* tmp=cur->next;cur->next=pre;pre=cur;cur=tmp;}rPre->next=pre;rHead->next=cur;rTail=rHead;rPre=rHead;rHead=cur;}return dumpy->next;}
};
时间复杂度:O(n),其中 n 为链表的长度。
空间复杂度:O(1,我们只需要建立常数个变量。
64. 删除链表的倒数第N 个节点
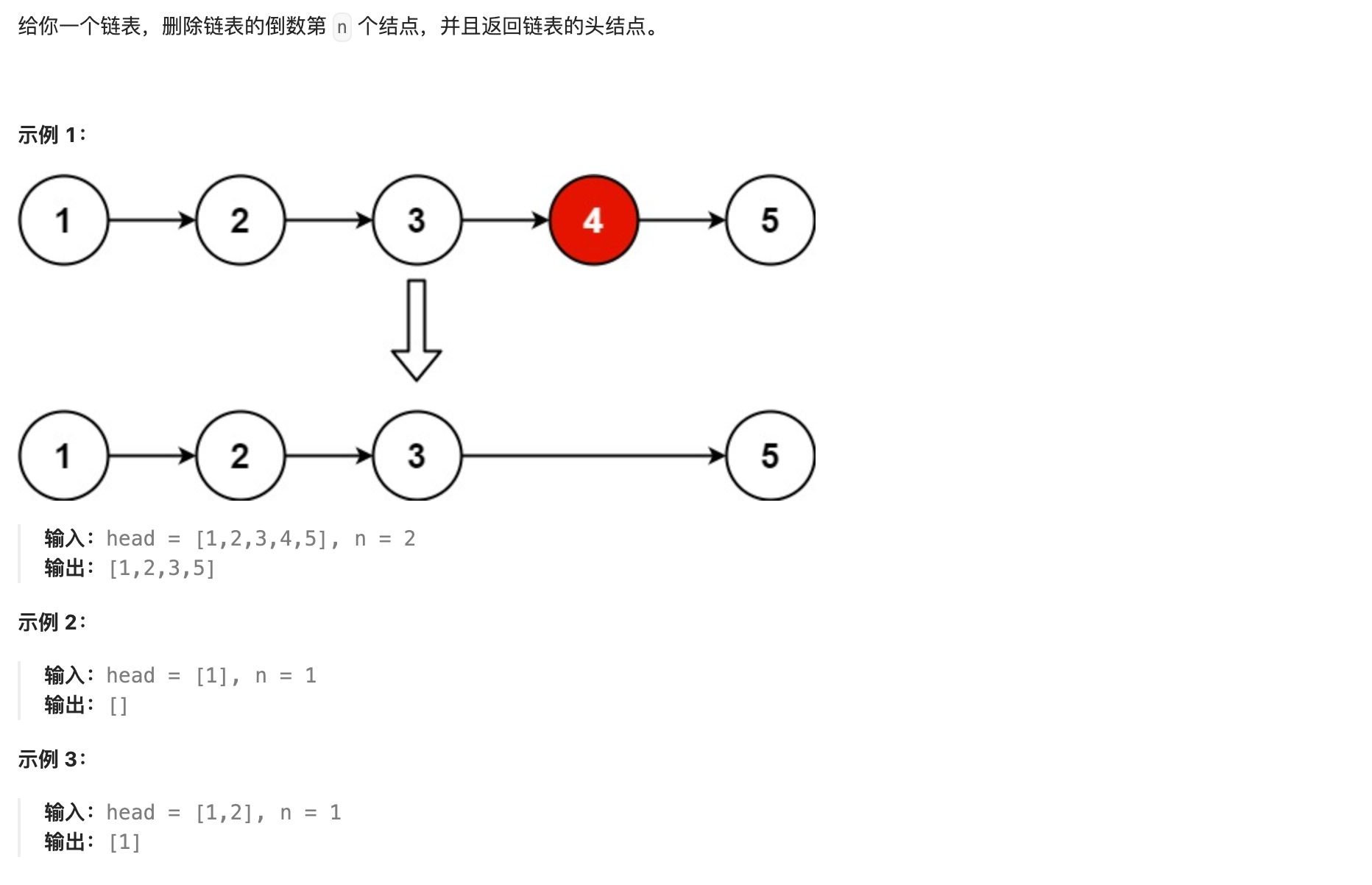
解法一:双指针(使用)
- 引入虚拟头节点dumpy,以及快慢指针【也常用的判断链表有环的场景】first,second,first领先second指针n个节点
- 那么当first指针的next为null的时候,second正好指在待删除节点的前驱节点,按照链表删除节点的逻辑进行删除即可
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {ListNode * dummy=new ListNode(0,head);ListNode *first,*second;first=dummy;second=dummy;for(int i=0;i<n;i++){first=first->next;}while(first->next!=NULL){first=first->next;second=second->next;}ListNode * tmp=second->next;second->next=tmp->next;delete tmp;ListNode*ans=dummy->next;delete dummy;return ans;}
};
时间复杂度:o(n)
空间复制度:o(1)
解法二:计算链表长度
最容易的方法:从头节点开始对链表进行一次遍历,得到链表的长度L。然后就能得到要删除的节点的位置是L-n+1。
删除链表的其中的一个节点的话,最经常会添加一个虚拟头节点。这样会使得删除的节点不管是否为头节点的逻辑相同。
解法三:用栈
我们也可以在遍历链表的同时将所有节点依次入栈。根据栈「先进后出」的原则,我们弹出栈的第 nnn 个节点就是需要删除的节点,并且目前栈顶的节点就是待删除节点的前驱节点。
解法二和三见:19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode)
65. 删除排序链表中的重复元素II
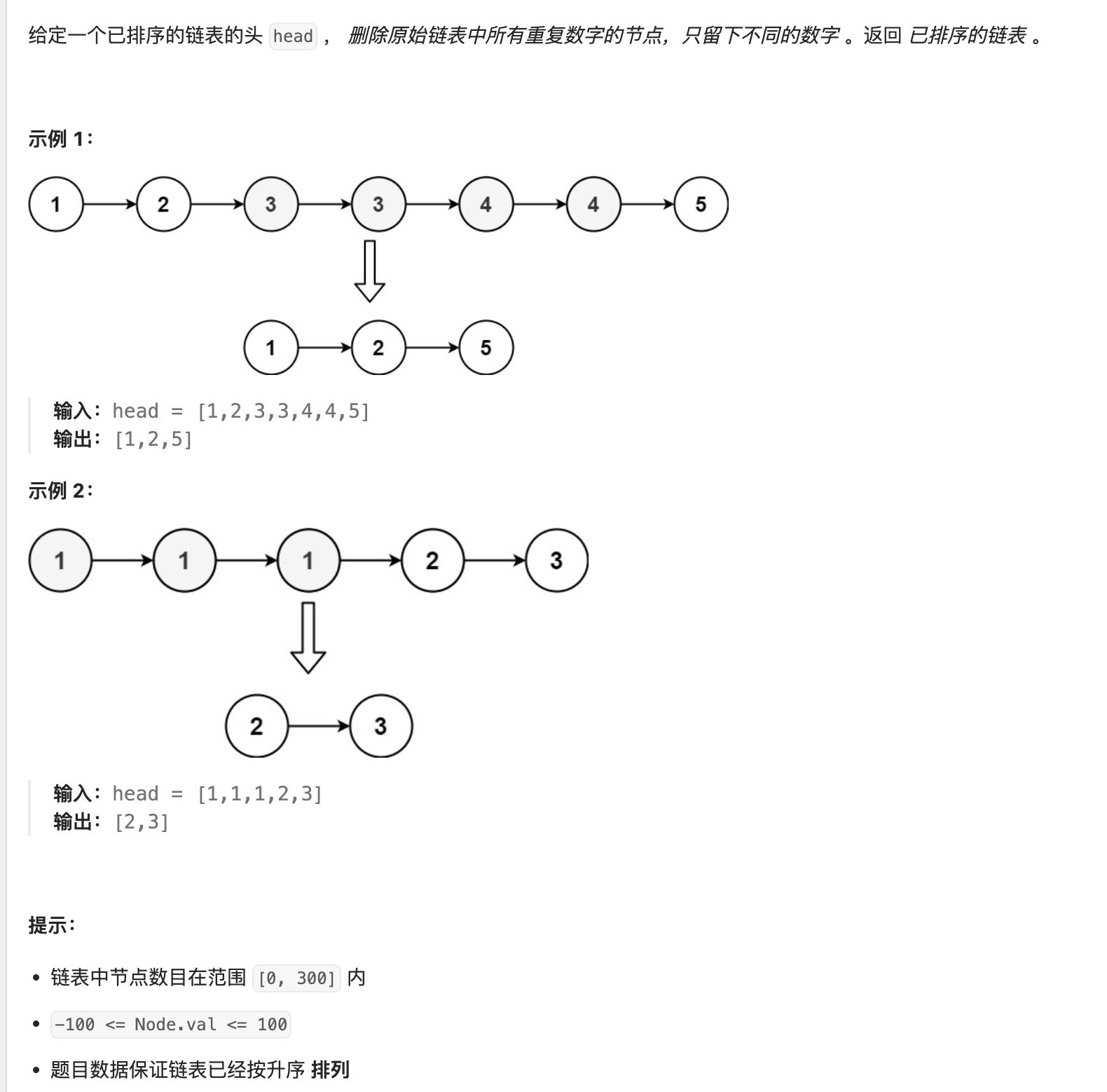
解法一:一次遍历
由于给定的链表是排好序的,因此重复的元素在链表中出现的位置是连续的,因此我们只需要对链表进行一次遍历,就可以删除重复的元素。由于链表的头节点可能会被删除,因此我们需要额外使用一个哑节点(dummy node)指向链表的头节点。
具体地,我们从指针 cur 指向链表的哑节点,随后开始对链表进行遍历。如果当前 cur.next 与 cur.next.next 对应的元素相同,那么我们就需要将 cur.next 以及所有后面拥有相同元素值的链表节点全部删除。我们记下这个元素值 x,随后不断将 cur.next 从链表中移除,直到 cur.next 为空节点或者其元素值不等于 x 为止。此时,我们将链表中所有元素值为 x 的节点全部删除。
如果当前 cur.next 与 cur.next.next 对应的元素不相同,那么说明链表中只有一个元素值为 cur.next 的节点,那么我们就可以将 cur 指向 cur.next。
当遍历完整个链表之后,我们返回链表的的哑节点的下一个节点 dummy.next 即可。
细节
需要注意 cur.next 以及 cur.next.next 可能为空节点,如果不加以判断,可能会产生运行错误。
代码
注意下面 C++ 代码中并没有释放被删除的链表节点以及哑节点的空间。如果在面试中遇到本题,读者需要针对这一细节与面试官进行沟通。
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* deleteDuplicates(ListNode* head) {ListNode*dumpy=new ListNode(0);dumpy->next=head;ListNode*cur=dumpy;while(cur->next&&cur->next->next){if(cur->next->val==cur->next->next->val){int x=cur->next->val;while(cur->next&&cur->next->val==x){cur->next=cur->next->next;}}else{cur=cur->next;}}return dumpy->next;}
};
- 时间复杂度:O(n),其中 n 是链表的长度。
- 空间复杂度:O(1)。
66. 旋转链表
解法一:用双端队列迭代
-
首先解决特殊情况,若head为null或者head->next为null则可以直接返回head
-
注意到旋转1次就是将最末尾的节点移动到第一个,并修改相应的next指针,k为几则移动几次
-
因此,使用双端队列,队列的尾部为每次需要移动的节点,移动一次需要将队列末尾节点移动到队首,并且此时队列末尾的节点的next指针为null。新队首指针的next也需要指向原来的队首节点
-
循环k次返回队首为此时的head
注意这种做法可能使得k很大的时候超时,当k>=链表长度n时,如上述例子,k=4,n=3,其实旋转四次的结果就等于在最原始的基础上旋转一次
因此k%n为真正需要旋转的次数
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* rotateRight(ListNode* head, int k) {vector<ListNode*>stack;ListNode*cur=head;ListNode*pre,*next;if(head==nullptr||head->next==nullptr)return head;int len=0;while(cur!=nullptr){stack.push_back(cur);cur=cur->next;len++;}int l=k%len;for(int i=0;i<l;i++){cur=stack.back();stack.pop_back();pre=stack.back();pre->next=nullptr;if(!stack.empty())next=stack.front();cur->next=next;stack.insert(stack.begin(),cur);}return stack.front();}
};
时间复杂度:O(n)
空间复杂度:O(n)
解法二:闭合为环(官方解法)
记给定链表的长度为 n,注意到当向右移动的次数 k≥n 时,我们仅需要向右移动kmodn 次即可。因为每 n 次移动都会让链表变为原状。这样我们可以知道,新链表的最后一个节点为原链表的第(n−1)−(k mod n) 个节点(从 0 开始计数)。
这样,我们可以先将给定的链表连接成环,然后将指定位置断开。
具体代码中,我们首先计算出链表的长度 n,并找到该链表的末尾节点,将其与头节点相连。这样就得到了闭合为环的链表。然后我们找到新链表的最后一个节点(即原链表的第 (n−1)−(kmodn) 个节点),将当前闭合为环的链表断开,即可得到我们所需要的结果。
特别地,当链表长度不大于 1,或者 kkk 为 n 的倍数时,新链表将与原链表相同,我们无需进行任何处理。
代码:
class Solution {
public:ListNode* rotateRight(ListNode* head, int k) {if (k == 0 || head == nullptr || head->next == nullptr) {return head;}int n = 1;ListNode* iter = head;while (iter->next != nullptr) {iter = iter->next;n++;}int add = n - k % n;if (add == n) {return head;}iter->next = head;while (add--) {iter = iter->next;}ListNode* ret = iter->next;iter->next = nullptr;return ret;}
};
- 时间复杂度:O(n),最坏情况下,我们需要遍历该链表两次。
- 空间复杂度:O(1), 需要常数的空间存储若干变量。
66. 分隔链表

解法:双指针
如下图所示,题目要求实现链表所有「值 <x 节点」出现在「值 ≥x 节点」前面
根据题意,考虑通过「新建两个链表」实现原链表分割,算法流程为:
- 新建两个链表 sml_dummy , big_dummy ,分别用于添加所有「节点值 <x 」、「节点值 ≥x 」的节点。
- 遍历链表 head 并依次比较各节点值 head.val 和 x 的大小:
- 若 head.val < x ,则将节点 head 添加至链表 sml_dummy 最后面;
- 若 head.val >= x ,则将节点 head 添加至链表 big_dummy 最后面;
- 遍历完成后,拼接 sml_dummy 和 big_dummy 链表。
- 最终返回头节点 sml_dummy.next 即可。
代码 :
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* partition(ListNode* head, int x) {ListNode*smallDumpy=new ListNode(0);ListNode*bigDumpy=new ListNode(0);ListNode*curSmall=smallDumpy;ListNode*curBig=bigDumpy;while(head!=nullptr){if(head->val<x){curSmall->next=head;curSmall=curSmall->next;}else{curBig->next=head;curBig=curBig->next;}head=head->next;}curSmall->next=bigDumpy->next;curBig->next=nullptr;return smallDumpy->next;}
};
时间复杂度 O(N) :其中 N 为链表长度;遍历链表使用线性时间。
空间复杂度 O(1) : 假头节点使用常数大小的额外空间。
67. LRU 缓存

解法一:哈希表+双向链表
算法
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1)的时间内完成 get 或者 put 操作。具体的方法如下:
对于 get 操作,首先判断 key 是否存在:
- 如果 key 不存在,则返回 −1;
- 如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
对于 put 操作,首先判断 key 是否存在:
- 如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
- 如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
上述各项操作中,访问哈希表的时间复杂度为 O(1)在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1) 时间内完成。
struct DlinkedNode{int key,value;DlinkedNode* prev;DlinkedNode* next;DlinkedNode():key(0),value(0),prev(nullptr),next(nullptr){}DlinkedNode(int _key,int _value):key(_key),value(_value),prev(nullptr),next(nullptr){}
};class LRUCache {
private:
unordered_map<int,DlinkedNode*>cache;
DlinkedNode*head;
DlinkedNode*tail;
int size;
int capacity;
public:LRUCache(int capacity) {this->capacity=capacity;this->size=0;head=new DlinkedNode();tail=new DlinkedNode();head->next=tail;tail->prev=head;}int get(int key) {if(!cache.count(key))return -1;DlinkedNode* node=cache[key];moveToHead(node);return node->value;}void put(int key, int value) {if(cache.count(key)){DlinkedNode* node=cache[key];moveToHead(node);node->value=value;}else{size++;DlinkedNode*node=new DlinkedNode(key,value);cache[key]=node;if(size>capacity){DlinkedNode*tmp=tail->prev;removeNode(tail->prev);cache.erase(tmp->key);addToHead(node);size--;delete tmp;}else{addToHead(node);}}}void removeNode(DlinkedNode*node){node->prev->next=node->next;node->next->prev=node->prev;}void moveToHead(DlinkedNode*node){removeNode(node);addToHead(node);} void addToHead(DlinkedNode*node){node->next=head->next;head->next->prev=node;head->next=node;node->prev=head;}};/*** Your LRUCache object will be instantiated and called as such:* LRUCache* obj = new LRUCache(capacity);* int param_1 = obj->get(key);* obj->put(key,value);*/
时间复杂度:对于 put 和 get 都是O(1)。
空间复杂度:O(capacity),因为哈希表和双向链表最多存储 capacity+1 个元素。
二叉树
68. 二叉树的最大深度
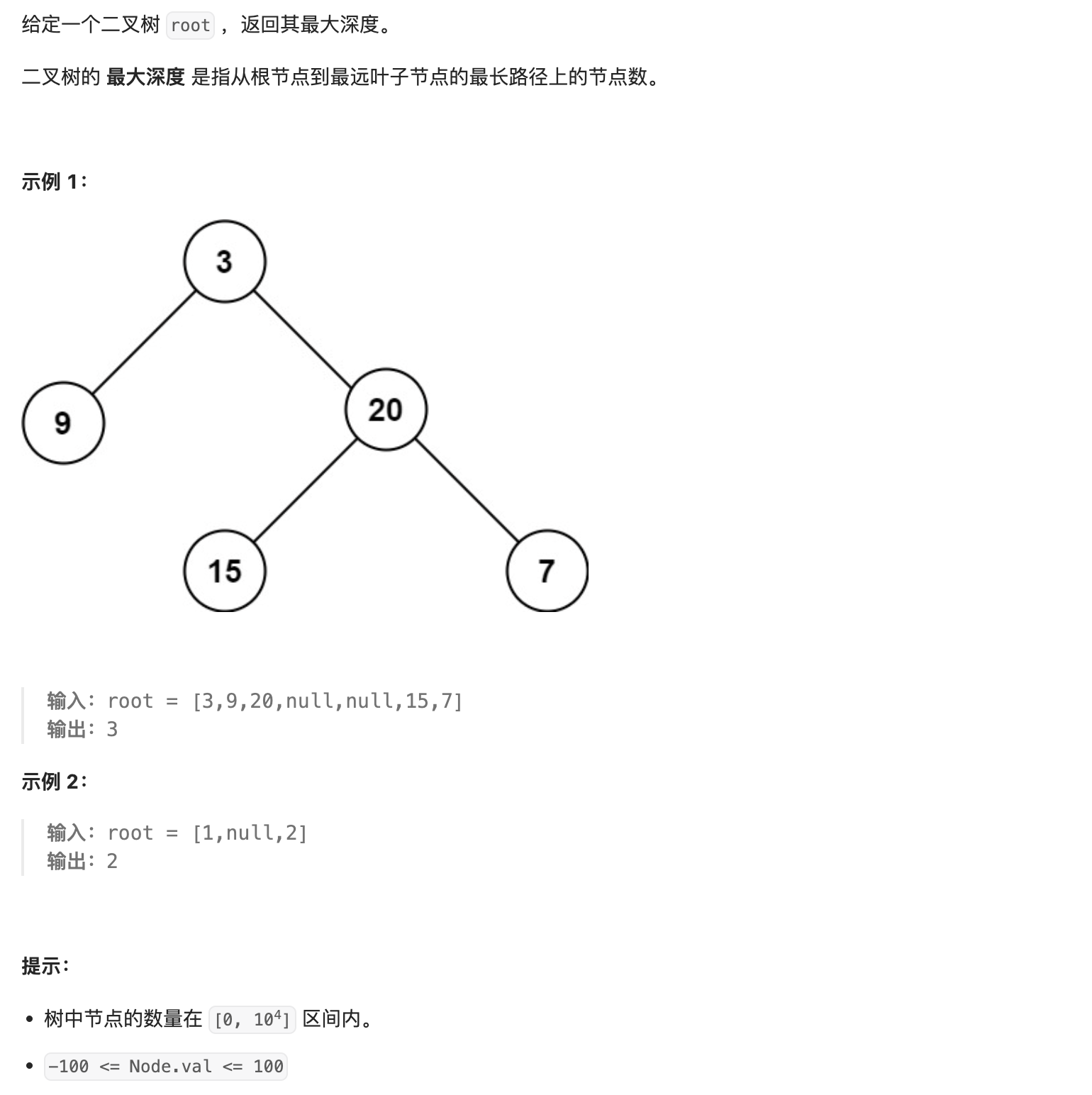
解法一:DFS(改造后序遍历)
树的后序遍历 / 深度优先搜索往往利用 递归 或 栈 实现,本文使用递归实现。
关键点: 此树的深度和其左(右)子树的深度之间的关系。显然,此树的深度 等于 左子树的深度 与 右子树的深度中的 最大值 +1 。
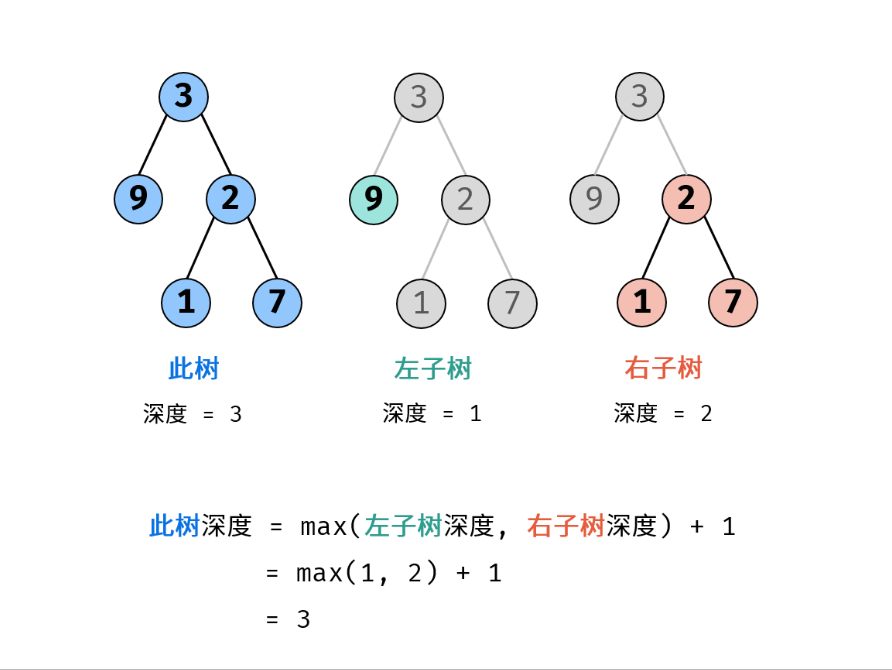
算法解析:
终止条件: 当 root 为空,说明已越过叶节点,因此返回 深度 0 。
递推工作: 本质上是对树做后序遍历。
计算节点 root 的 左子树的深度 ,即调用 maxDepth(root.left)。
计算节点 root 的 右子树的深度 ,即调用 maxDepth(root.right)。
返回值: 返回 此树的深度 ,即 max(maxDepth(root.left), maxDepth(root.right)) + 1。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int maxDepth(TreeNode* root) {return maxPostOrder(root);}int maxPostOrder(TreeNode*root){if(root==nullptr){return 0;}return max(maxPostOrder(root->left),maxPostOrder(root->right))+1;}
};
时间复杂度 O(N) : N 为树的节点数量,计算树的深度需要遍历所有节点。
空间复杂度 O(N) : 最差情况下(当树退化为链表时),递归深度可达到 N 。
解法二:BFS
树的层序遍历 / 广度优先搜索往往利用 队列 实现。
关键点: 每遍历一层,则计数器 +1 ,直到遍历完成,则可得到树的深度。
算法解析:
特例处理: 当 root 为空,直接返回 深度 0 。
初始化: 队列 queue (加入根节点 root ),计数器 res = 0。
循环遍历: 当 queue 为空时跳出。
初始化一个空列表 tmp ,用于临时存储下一层节点。
遍历队列: 遍历 queue 中的各节点 node ,并将其左子节点和右子节点加入 tmp。
更新队列: 执行 queue = tmp ,将下一层节点赋值给 queue。
统计层数: 执行 res += 1 ,代表层数加 1。
返回值: 返回 res 即可。
class Solution {
public:int maxDepth(TreeNode* root) {if (root == nullptr) return 0;queue<TreeNode*> Q;Q.push(root);int ans = 0;while (!Q.empty()) {int sz = Q.size();while (sz > 0) {TreeNode* node = Q.front();Q.pop();if (node->left) Q.push(node->left);if (node->right) Q.push(node->right);sz -= 1;}ans += 1;} return ans;}
};时间复杂度:O(N),其中 N 为二叉树节点的数目。我们会遍历二叉树中的每一个节点,对每个节点而言,我们在常数时间内交换其两棵子树。
空间复杂度:O(N)。使用的空间由递归栈的深度决定,它等于当前节点在二叉树中的高度。在平均情况下,二叉树的高度与节点个数为对数关系,即 O(logN)。而在最坏情况下,树形成链状,空间复杂度为 O(N)。
69. 相同的树
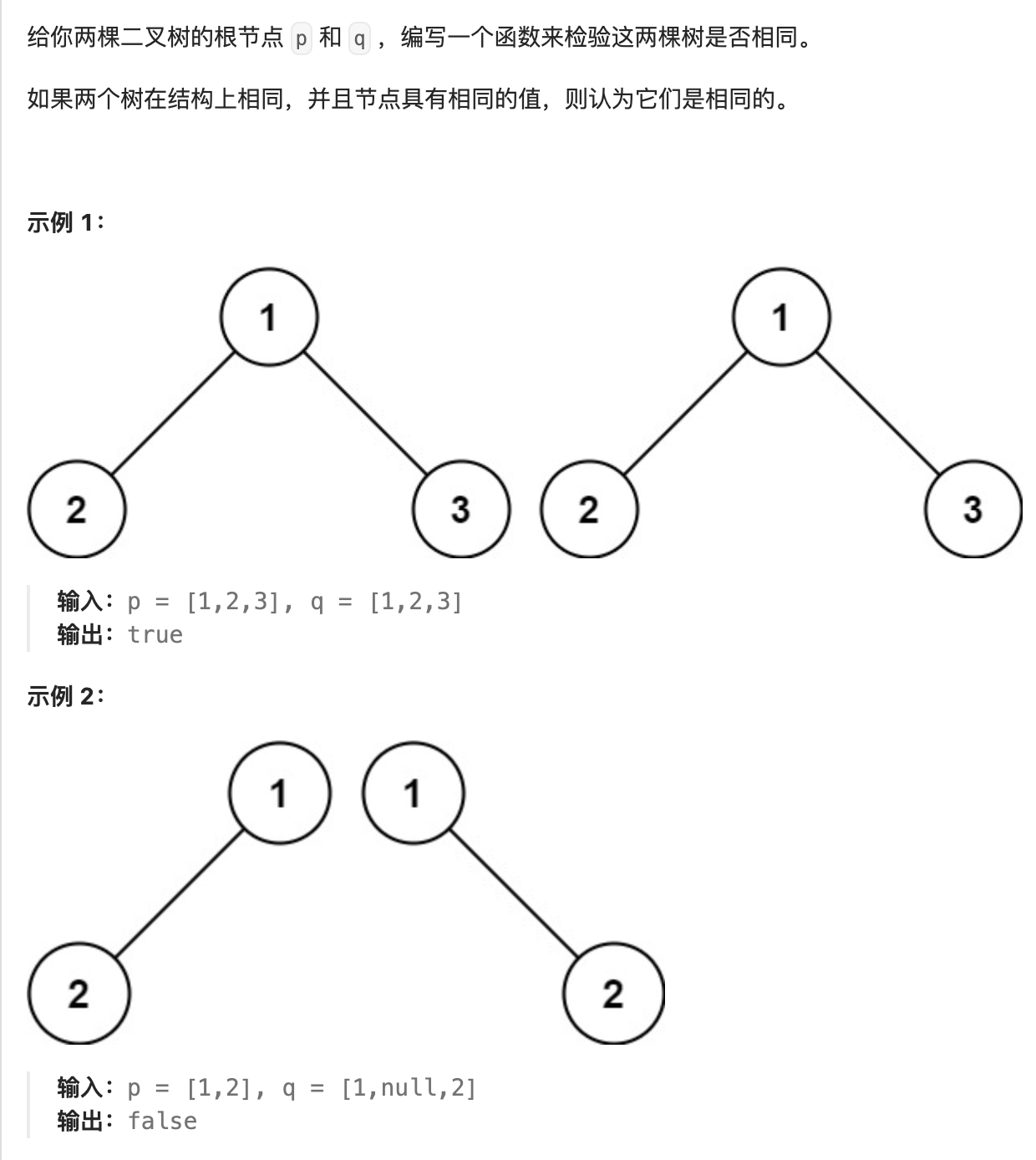
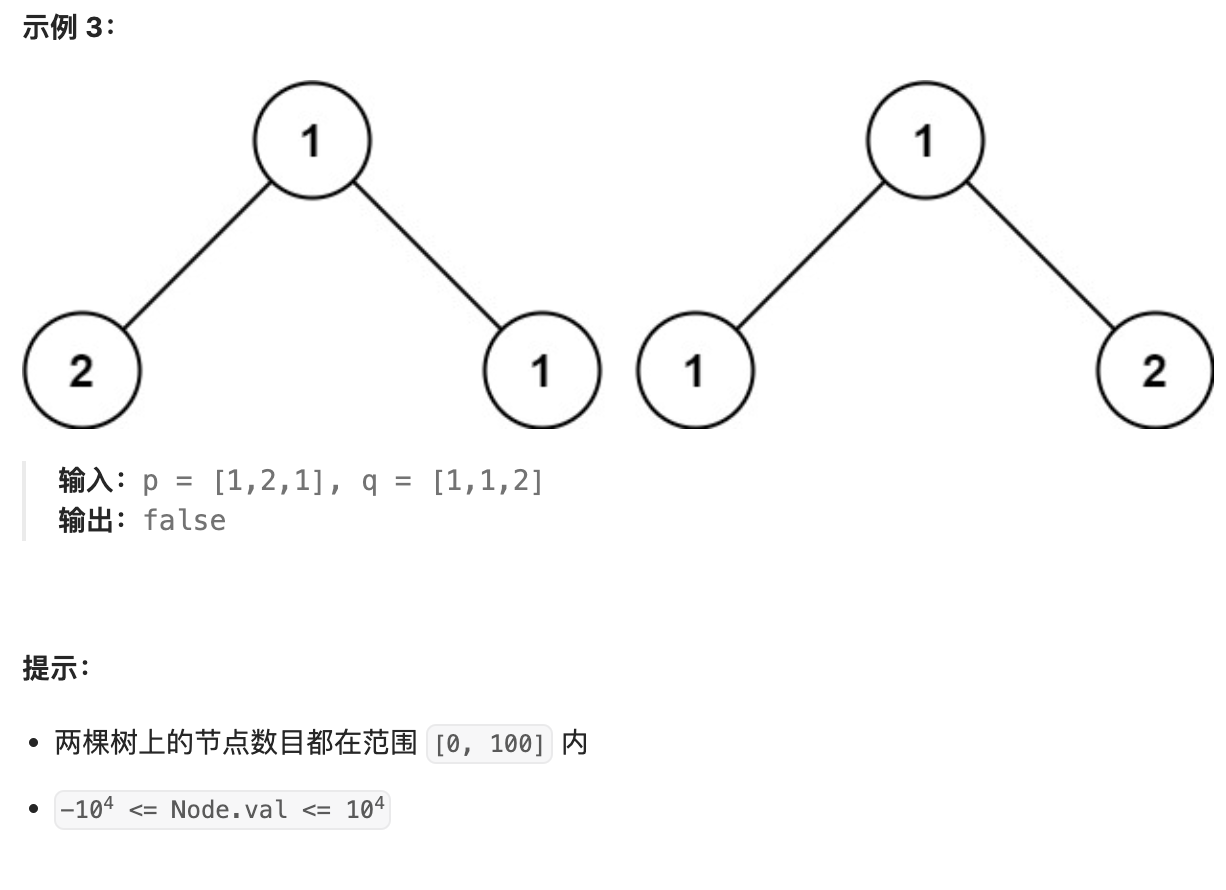
解法一:深度优先搜索
如果两个二叉树都为空,则两个二叉树相同。如果两个二叉树中有且只有一个为空,则两个二叉树一定不相同。
如果两个二叉树都不为空,那么首先判断它们的根节点的值是否相同,若不相同则两个二叉树一定不同,若相同,再分别判断两个二叉树的左子树是否相同以及右子树是否相同。这是一个递归的过程,因此可以使用深度优先搜索,递归地判断两个二叉树是否相同。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:bool preOrder(TreeNode* p, TreeNode* q){if(p==nullptr&&q==nullptr)return true;else if(p!=nullptr&&q!=nullptr){if(p->val==q->val)return preOrder(p->left,q->left)&& preOrder(p->right,q->right);}return false; }bool isSameTree(TreeNode* p, TreeNode* q) {return preOrder(p,q);}
};
时间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点数。对两个二叉树同时进行深度优先搜索,只有当两个二叉树中的对应节点都不为空时才会访问到该节点,因此被访问到的节点数不会超过较小的二叉树的节点数。
空间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点数。空间复杂度取决于递归调用的层数,递归调用的层数不会超过较小的二叉树的最大高度,最坏情况下,二叉树的高度等于节点数。
解法二:广度优先搜索
也可以通过广度优先搜索判断两个二叉树是否相同。同样首先判断两个二叉树是否为空,如果两个二叉树都不为空,则从两个二叉树的根节点开始广度优先搜索。
使用两个队列分别存储两个二叉树的节点。初始时将两个二叉树的根节点分别加入两个队列。每次从两个队列各取出一个节点,进行如下比较操作。
- 比较两个节点的值,如果两个节点的值不相同则两个二叉树一定不同;
如果两个节点的值相同,则判断两个节点的子节点是否为空,如果只有一个节点的左子节点为空,或者只有一个节点的右子节点为空,则两个二叉树的结构不同,因此两个二叉树一定不同;
如果两个节点的子节点的结构相同,则将两个节点的非空子节点分别加入两个队列,子节点加入队列时需要注意顺序,如果左右子节点都不为空,则先加入左子节点,后加入右子节点。
如果搜索结束时两个队列同时为空,则两个二叉树相同。如果只有一个队列为空,则两个二叉树的结构不同,因此两个二叉树不同。
class Solution {
public:bool isSameTree(TreeNode* p, TreeNode* q) {if (p == nullptr && q == nullptr) {return true;} else if (p == nullptr || q == nullptr) {return false;}queue <TreeNode*> queue1, queue2;queue1.push(p);queue2.push(q);while (!queue1.empty() && !queue2.empty()) {auto node1 = queue1.front();queue1.pop();auto node2 = queue2.front();queue2.pop();if (node1->val != node2->val) {return false;}auto left1 = node1->left, right1 = node1->right, left2 = node2->left, right2 = node2->right;if ((left1 == nullptr) ^ (left2 == nullptr)) {return false;}if ((right1 == nullptr) ^ (right2 == nullptr)) {return false;}if (left1 != nullptr) {queue1.push(left1);}if (right1 != nullptr) {queue1.push(right1);}if (left2 != nullptr) {queue2.push(left2);}if (right2 != nullptr) {queue2.push(right2);}}return queue1.empty() && queue2.empty();}
};
时间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点数。对两个二叉树同时进行广度优先搜索,只有当两个二叉树中的对应节点都不为空时才会访问到该节点,因此被访问到的节点数不会超过较小的二叉树的节点数。
空间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点数。空间复杂度取决于队列中的元素个数,队列中的元素个数不会超过较小的二叉树的节点数。
70. 翻转二叉树
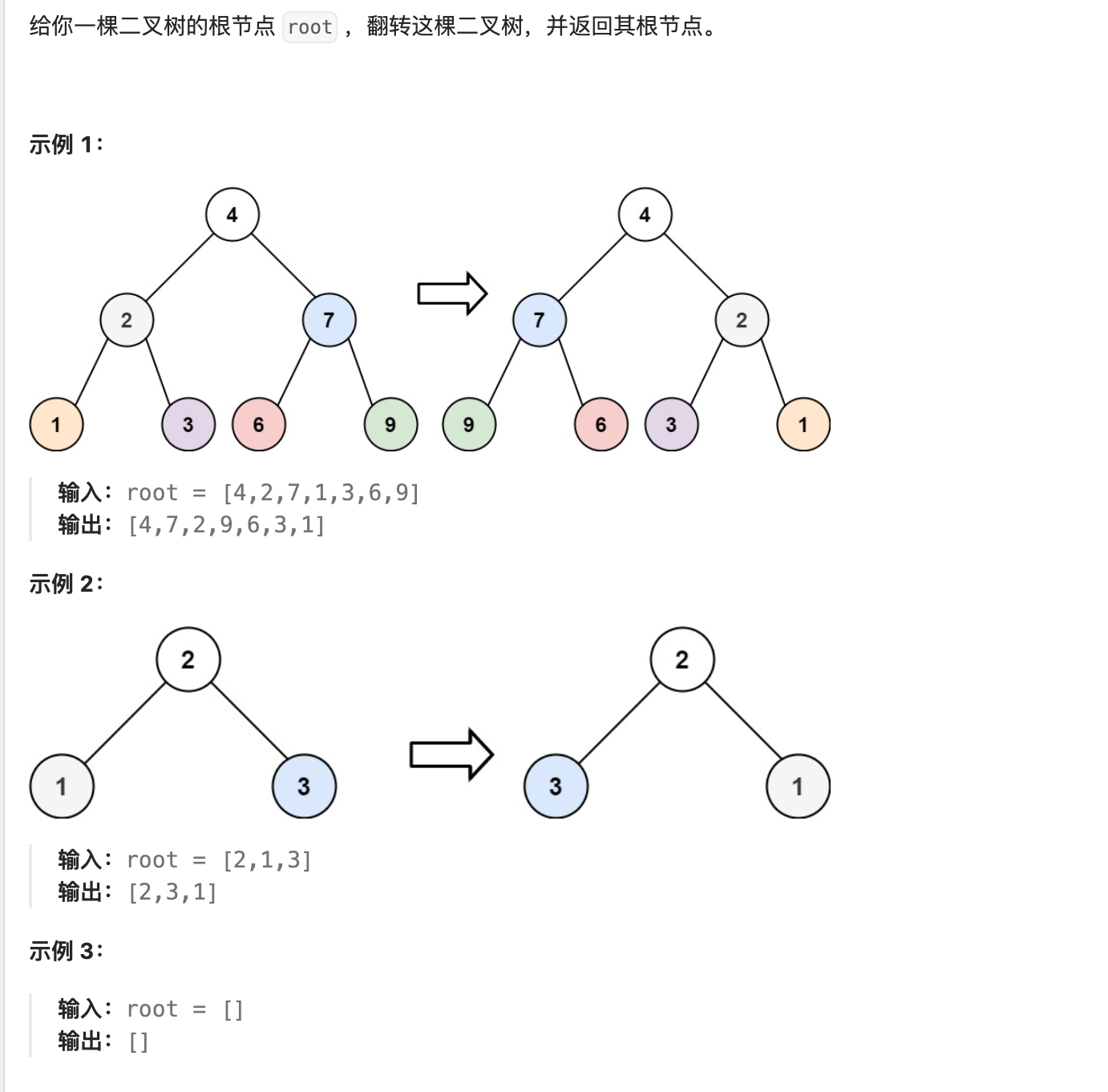

解法一:经典递归
思路与算法
这是一道很经典的二叉树问题。显然,我们从根节点开始,递归地对树进行遍历,并从叶子节点先开始翻转。如果当前遍历到的节点 root 的左右两棵子树都已经翻转,那么我们只需要交换两棵子树的位置,即可完成以 root 为根节点的整棵子树的翻转。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:TreeNode* invertTree(TreeNode* root) {if(root==nullptr){return root;}TreeNode*left=invertTree(root->left);TreeNode*right=invertTree(root->right);root->left=right;root->right=left;return root;}
};
时间复杂度:O(N),其中 N 为二叉树节点的数目。我们会遍历二叉树中的每一个节点,对每个节点而言,我们在常数时间内交换其两棵子树。
空间复杂度:O(N)。使用的空间由递归栈的深度决定,它等于当前节点在二叉树中的高度。在平均情况下,二叉树的高度与节点个数为对数关系,即 O(logN)。而在最坏情况下,树形成链状,空间复杂度为 O(N)。
71. 对称二叉树
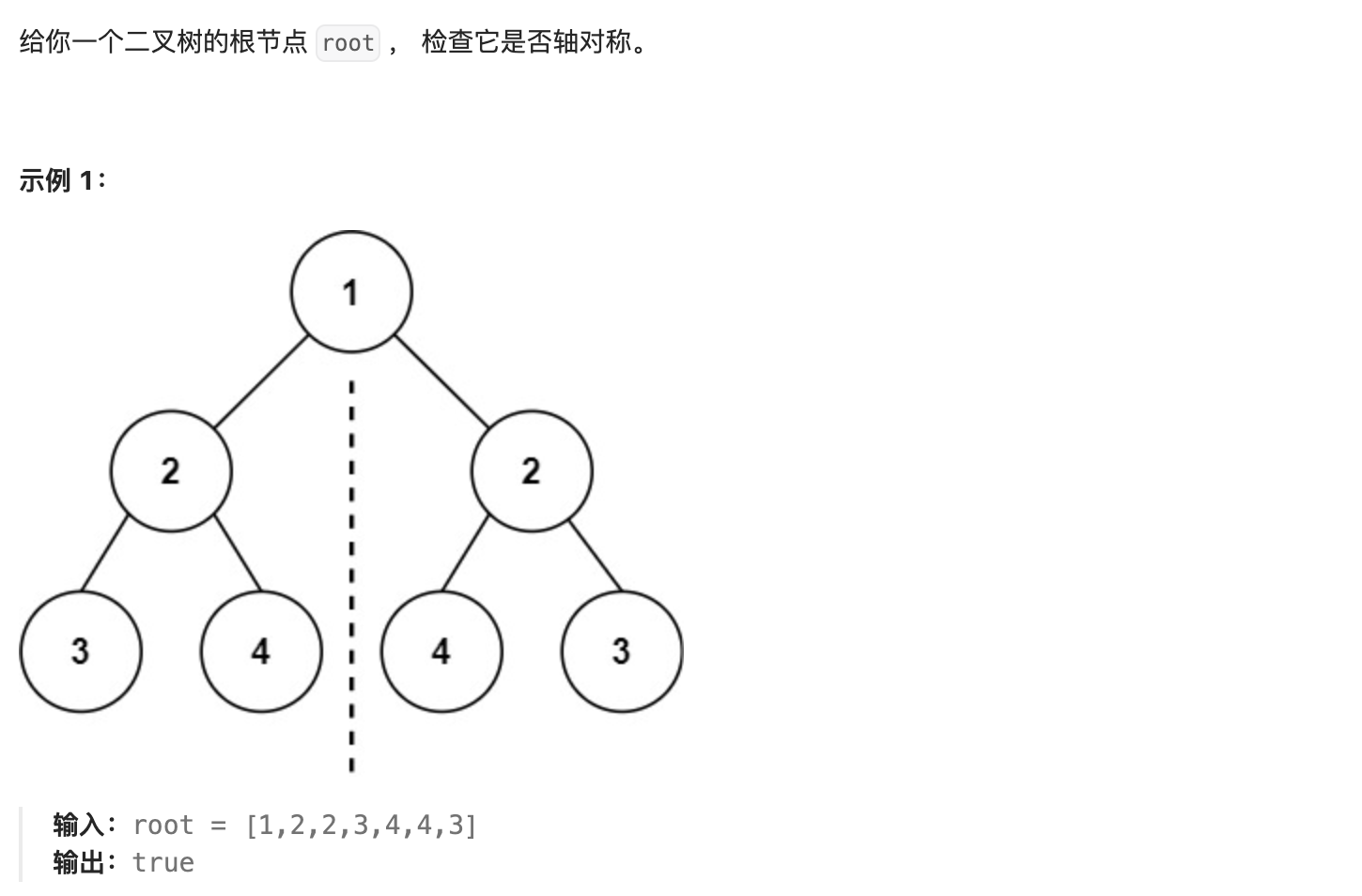
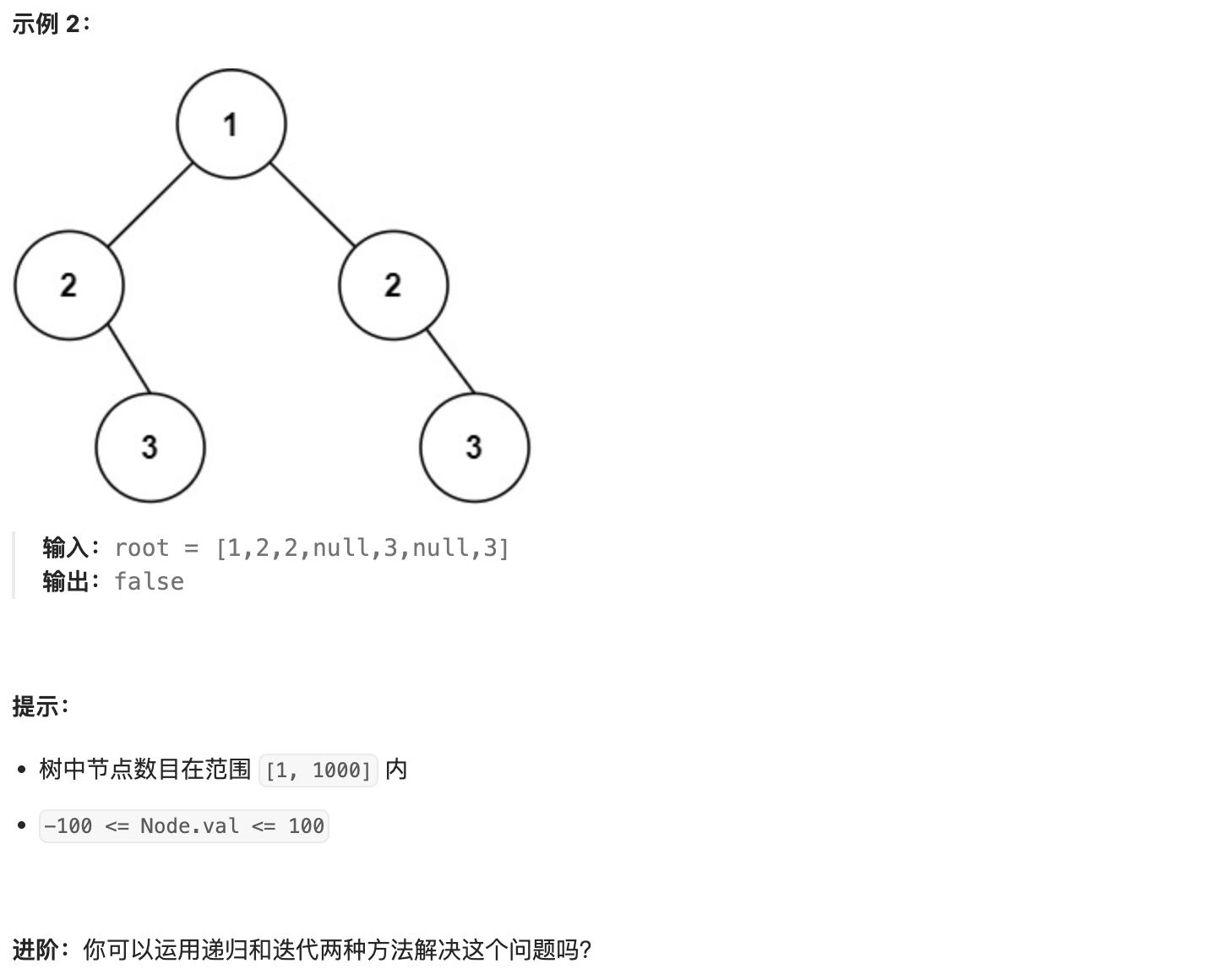
解法一:递归
对称二叉树定义: 对于树中 任意两个对称节点 L 和 R ,一定有:
L.val = R.val :即此两对称节点值相等。
L.left.val = R.right.val :即 L 的 左子节点 和 R 的 右子节点 对称。
L.right.val = R.left.val :即 L 的 右子节点 和 R 的 左子节点 对称。
根据以上规律,考虑从顶至底递归,判断每对左右节点是否对称,从而判断树是否为对称二叉树。
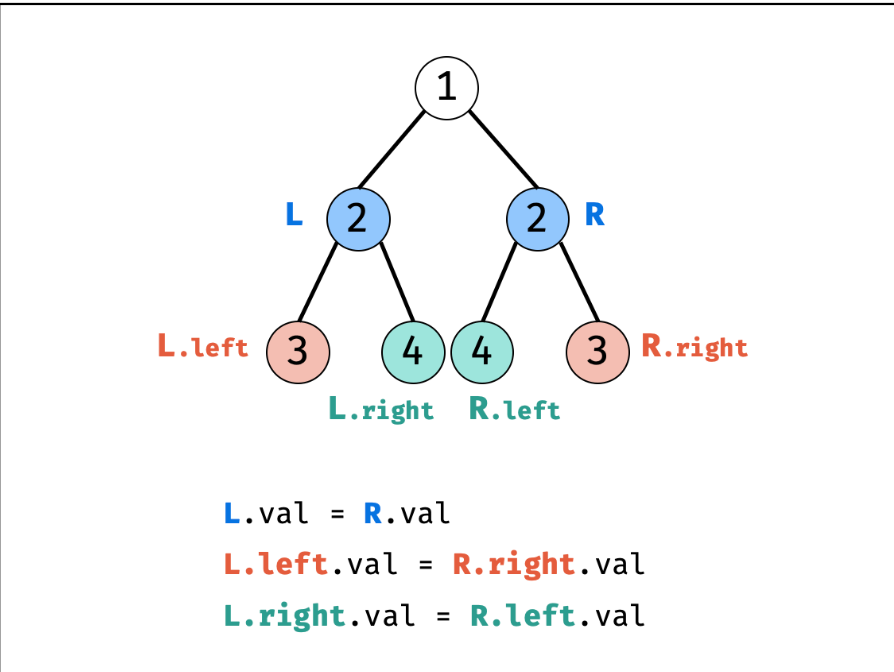
算法流程:
函数 isSymmetric(root) :
特例处理: 若根节点 root 为空,则直接返回 true 。
返回值: 即 recur(root.left, root.right) ;
函数 recur(L, R) :
终止条件:
当 L 和 R 同时越过叶节点: 此树从顶至底的节点都对称,因此返回 true 。
当 L 或 R 中只有一个越过叶节点: 此树不对称,因此返回 false 。
当节点 L 值 ≠ 节点 R 值: 此树不对称,因此返回 false。
递推工作:
判断两节点 L.left 和 R.right 是否对称,即 recur(L.left, R.right) 。
判断两节点 L.right 和 R.left 是否对称,即 recur(L.right, R.left) 。
返回值: 两对节点都对称时,才是对称树,因此用与逻辑符 && 连接。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:bool isSymmetric(TreeNode* root) {if(root==nullptr){return true;}return recur(root->left,root->right);}bool recur(TreeNode*L,TreeNode*R){if(L==nullptr&& R==nullptr)return true;if(L==nullptr||R==nullptr||L->val!=R->val)return false;return recur(L->left,R->right)&&recur(L->right,R->left);}
};
时间复杂度:这里遍历了这棵树,渐进时间复杂度为 O(n)。
空间复杂度:这里的空间复杂度和递归使用的栈空间有关,这里递归层数不超过 n,故渐进空间复杂度为 O(n)。
解法二:迭代
解法一中我们用递归的方法实现了对称性的判断,那么如何用迭代的方法实现呢?首先我们引入一个队列,这是把递归程序改写成迭代程序的常用方法。初始化时我们把根节点入队两次。每次提取两个结点并比较它们的值(队列中每两个连续的结点应该是相等的,而且它们的子树互为镜像),然后将两个结点的左右子结点按相反的顺序插入队列中。当队列为空时,或者我们检测到树不对称(即从队列中取出两个不相等的连续结点)时,该算法结束。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:bool isSymmetric(TreeNode* root) {if(root==nullptr)return true;queue<TreeNode*>queue;queue.push(root->left);queue.push(root->right);TreeNode*left;TreeNode*right;while(!queue.empty()){right=queue.front();queue.pop();left=queue.front();queue.pop();if(!left&&!right)continue;if((!left)||(!right)||(left->val!=right->val))return false;queue.push(left->right);queue.push(right->left);queue.push(left->left);queue.push(right->right); }return true; }};
时间复杂度:O(n),同「方法一」。
空间复杂度:这里需要用一个队列来维护节点,每个节点最多进队一次,出队一次,队列中最多不会超过n 个点,故渐进空间复杂度为 O(n)。
72. 从前序与中序遍历序列构造二叉树
解法一:递归
二叉树前序遍历的顺序为:
-
先遍历根节点;
-
随后递归地遍历左子树;
-
最后递归地遍历右子树。
二叉树中序遍历的顺序为:
-
先递归地遍历左子树;
-
随后遍历根节点;
-
最后递归地遍历右子树。
在「递归」地遍历某个子树的过程中,我们也是将这颗子树看成一颗全新的树,按照上述的顺序进行遍历。挖掘「前序遍历」和「中序遍历」的性质,我们就可以得出本题的做法。
对于任意一颗树而言,前序遍历的形式总是
[ 根节点, [左子树的前序遍历结果], [右子树的前序遍历结果] ]
即根节点总是前序遍历中的第一个节点。而中序遍历的形式总是
[ [左子树的中序遍历结果], 根节点, [右子树的中序遍历结果] ]
只要我们在中序遍历中定位到根节点,那么我们就可以分别知道左子树和右子树中的节点数目。由于同一颗子树的前序遍历和中序遍历的长度显然是相同的,因此我们就可以对应到前序遍历的结果中,对上述形式中的所有左右括号进行定位。
这样以来,我们就知道了左子树的前序遍历和中序遍历结果,以及右子树的前序遍历和中序遍历结果,我们就可以递归地对构造出左子树和右子树,再将这两颗子树接到根节点的左右位置。
细节
在中序遍历中对根节点进行定位时,一种简单的方法是直接扫描整个中序遍历的结果并找出根节点,但这样做的时间复杂度较高。我们可以考虑使用哈希表来帮助我们快速地定位根节点。对于哈希映射中的每个键值对,键表示一个元素(节点的值),值表示其在中序遍历中的出现位置。在构造二叉树的过程之前,我们可以对中序遍历的列表进行一遍扫描,就可以构造出这个哈希映射。在此后构造二叉树的过程中,我们就只需要 O(1) 的时间对根节点进行定位了。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:unordered_map<int,int>num2Index;TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {for(int i=0;i<inorder.size();i++){num2Index[inorder[i]]=i;}return setTree(preorder,inorder,0,preorder.size()-1,0);}TreeNode* setTree(vector<int>& preorder,vector<int>& inorder,int preleft,int preright,int inleft){if(preleft>preright)return nullptr;int preroot=preleft;//在中序遍历中定位根节点int inroot=num2Index[preorder[preroot]];TreeNode *root=new TreeNode(preorder[preroot]);int size_left_subtree=inroot-inleft;root->left=setTree(preorder,inorder,preleft+1,preleft+size_left_subtree,inleft);root->right=setTree(preorder,inorder,preleft+size_left_subtree+1,preright,inroot+1);return root;}};
时间复杂度:O(n),其中 n 是树中的节点个数。
空间复杂度:O(n),除去返回的答案需要的 O(n) 空间之外,我们还需要使用 O(n) 的空间存储哈希映射,以及 O(h)(其中 h 是树的高度)的空间表示递归时栈空间。这里 h<n,所以总空间复杂度为 O(n)。
解法二:迭代
见:https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/solutions/255811/cong-qian-xu-yu-zhong-xu-bian-li-xu-lie-gou-zao-9/?envType=study-plan-v2&envId=top-interview-150
73. 从中序和后序构造二叉树
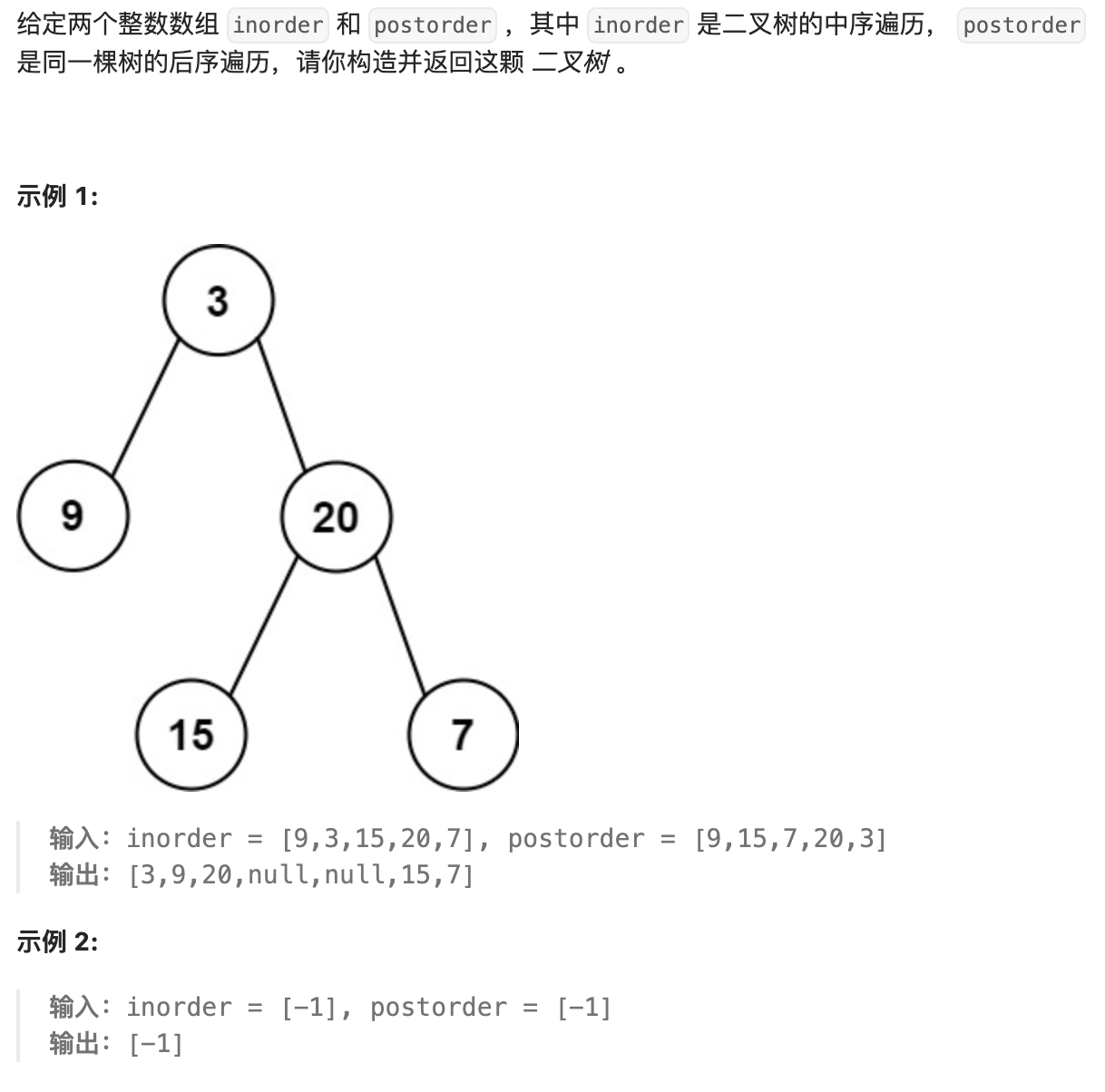

解法一:递归
首先解决这道题我们需要明确给定一棵二叉树,我们是如何对其进行中序遍历与后序遍历的:
中序遍历的顺序是每次遍历左孩子,再遍历根节点,最后遍历右孩子。
后序遍历的顺序是每次遍历左孩子,再遍历右孩子,最后遍历根节点。
我们可以发现后序遍历的数组最后一个元素代表的即为根节点。知道这个性质后,我们可以利用已知的根节点信息在中序遍历的数组中找到根节点所在的下标,然后根据其将中序遍历的数组分成左右两部分,左边部分即左子树,右边部分为右子树,针对每个部分可以用同样的方法继续递归下去构造。
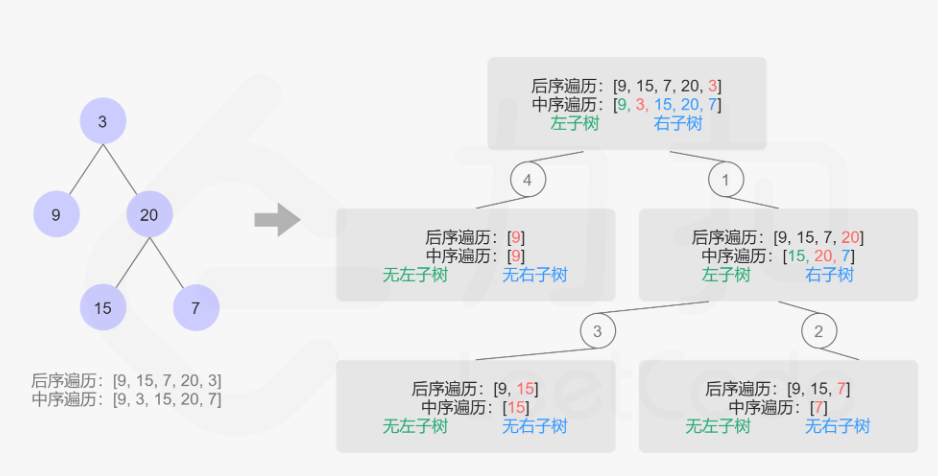
为了高效查找根节点元素在中序遍历数组中的下标,我们选择创建哈希表来存储中序序列,即建立一个(元素,下标)键值对的哈希表。
- 定义递归函数 helper(in_left, in_right) 表示当前递归到中序序列中当前子树的左右边界,递归入口为helper(0, n - 1) :
- 如果 in_left > in_right,说明子树为空,返回空节点。
- 选择后序遍历的最后一个节点作为根节点。
- 利用哈希表 O(1) 查询当根节点在中序遍历中下标为 index。从 in_left 到 index - 1 属于左子树,从 index + 1 到 in_right 属于右子树。
- 根据后序遍历逻辑,递归创建右子树 helper(index + 1, in_right) 和左子树 helper(in_left, index - 1)。注意这里有需要先创建右子树,再创建左子树的依赖关系。可以理解为在后序遍历的数组中整个数组是先存储左子树的节点,再存储右子树的节点,最后存储根节点,如果按每次选择「后序遍历的最后一个节点」为根节点,则先被构造出来的应该为右子树。
- 返回根节点 root。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:unordered_map<int, int> inorder2Index;TreeNode* setTree(vector<int>& inorder, vector<int>& postorder, int inleft, int inright, int& postright) {if (inleft > inright) {return nullptr;}// 根节点是后序遍历的最后一个节点int rootVal = postorder[postright];TreeNode* root = new TreeNode(rootVal);// 找到中序遍历中根节点的位置int inroot = inorder2Index[rootVal];// 递减postright,因为我们刚刚用了一个元素作为根节点postright--;// 先构造右子树,再构造左子树root->right = setTree(inorder, postorder, inroot + 1, inright, postright);root->left = setTree(inorder, postorder, inleft, inroot - 1, postright);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {// 将中序遍历的值及其索引存入哈希表,便于查找for (int i = 0; i < inorder.size(); i++) {inorder2Index[inorder[i]] = i;}// 从后序遍历的最后一个元素开始构造树int postright = postorder.size() - 1;return setTree(inorder, postorder, 0, inorder.size() - 1, postright);}
};
时间复杂度:O(n),其中 n 是树中的节点个数。
空间复杂度:O(n)。我们需要使用 O(n) 的空间存储哈希表,以及 O(h)(其中 h 是树的高度)的空间表示递归时栈空间。这里 h<n,所以总空间复杂度为 O(n)。
解法二:迭代
106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode)
74. 填充每个节点的下一个右侧节点指针II
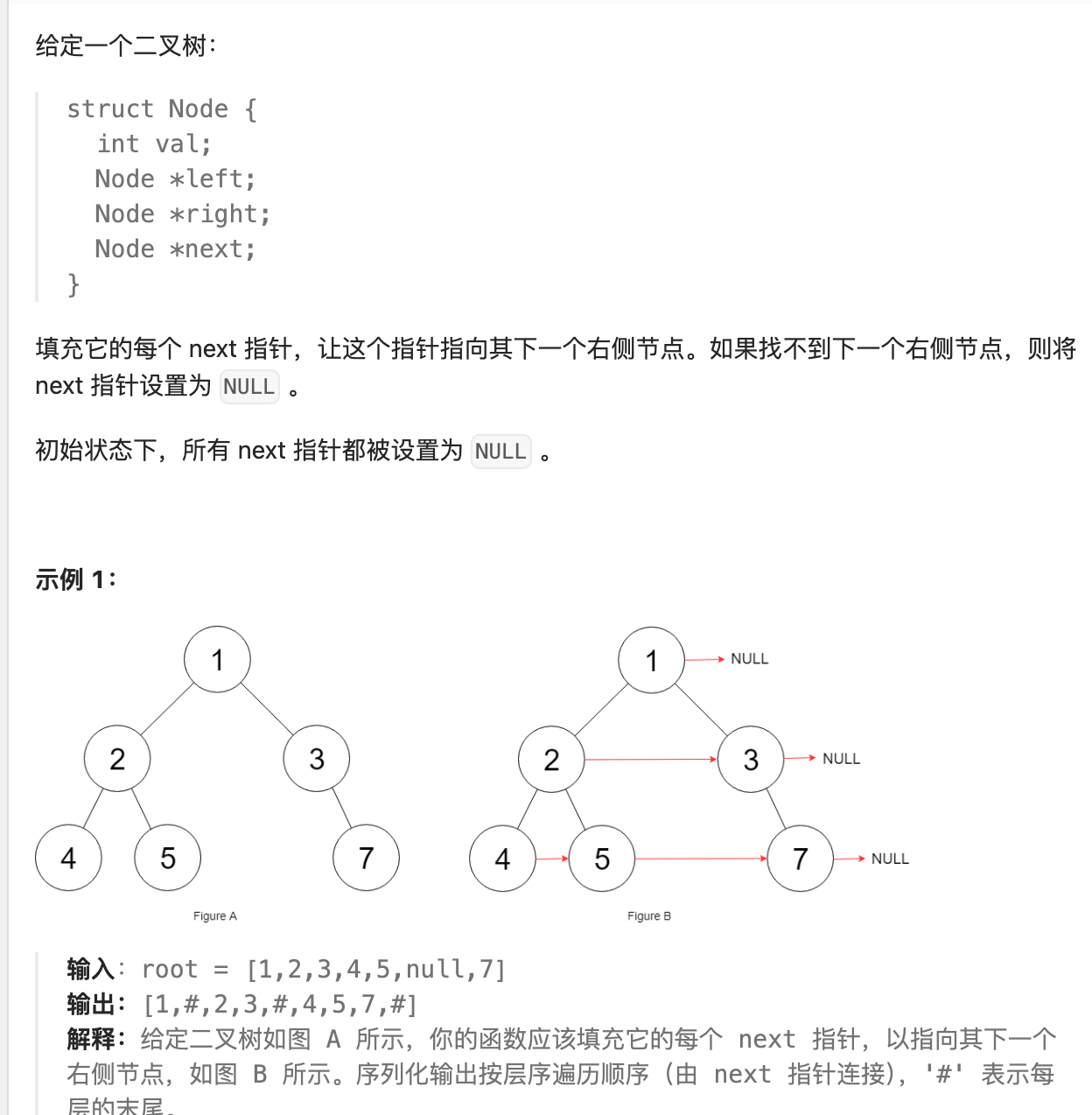

解法一:广度优先遍历
这道题希望我们把二叉树各个层的点组织成链表,一个非常直观的思路是层次遍历。树的层次遍历基于广度优先搜索,它按照层的顺序遍历二叉树,在遍历第 i 层前,一定会遍历完第 i−1 层。
算法如下:初始化一个队列 q,将根结点放入队列中。当队列不为空的时候,记录当前队列大小为 n,从队列中以此取出 n 个元素并通过这 n 个元素拓展新节点。如此循环,直到队列为空。遍历第i层时,构建该层的next关系,然后将下一层的节点加入队列中
/*
// Definition for a Node.
class Node {
public:int val;Node* left;Node* right;Node* next;Node() : val(0), left(NULL), right(NULL), next(NULL) {}Node(int _val) : val(_val), left(NULL), right(NULL), next(NULL) {}Node(int _val, Node* _left, Node* _right, Node* _next): val(_val), left(_left), right(_right), next(_next) {}
};
*/class Solution {
public:Node* connect(Node* root) {if(!root)return NULL;std::queue<Node*>queue;queue.push(root);Node*cur=NULL;while(!queue.empty()){int len=queue.size();Node*pre=NULL;for(int i=0;i<len;i++){cur=queue.front();queue.pop();if(pre){pre->next=cur;}pre=cur;if(cur->left){queue.push(cur->left);}if(cur->right){queue.push(cur->right);}}cur->next=NULL;}return root;}
};
- 时间复杂度:O(N)。我们需要遍历这棵树上所有的点,时间复杂度为 O(N)。
- 空间复杂度:O(N)。即队列的空间代价。
解法二:使用已经建立的next指针(O(1)空间复杂度)
上述解法中,每一层节点的 next 关系的构建都是独立的。我们构建第 k 层的 next 关系时,并没有利用已建好的到第 k−1 层的 next 关系。
实际上,每一层构建好的 next 关系都可看做「链表」,可参与到下一层 next 关系的构建,同时由于所有节点的起始 next 指向都是 null,相当于首层的 next 关系已经默认建好了。
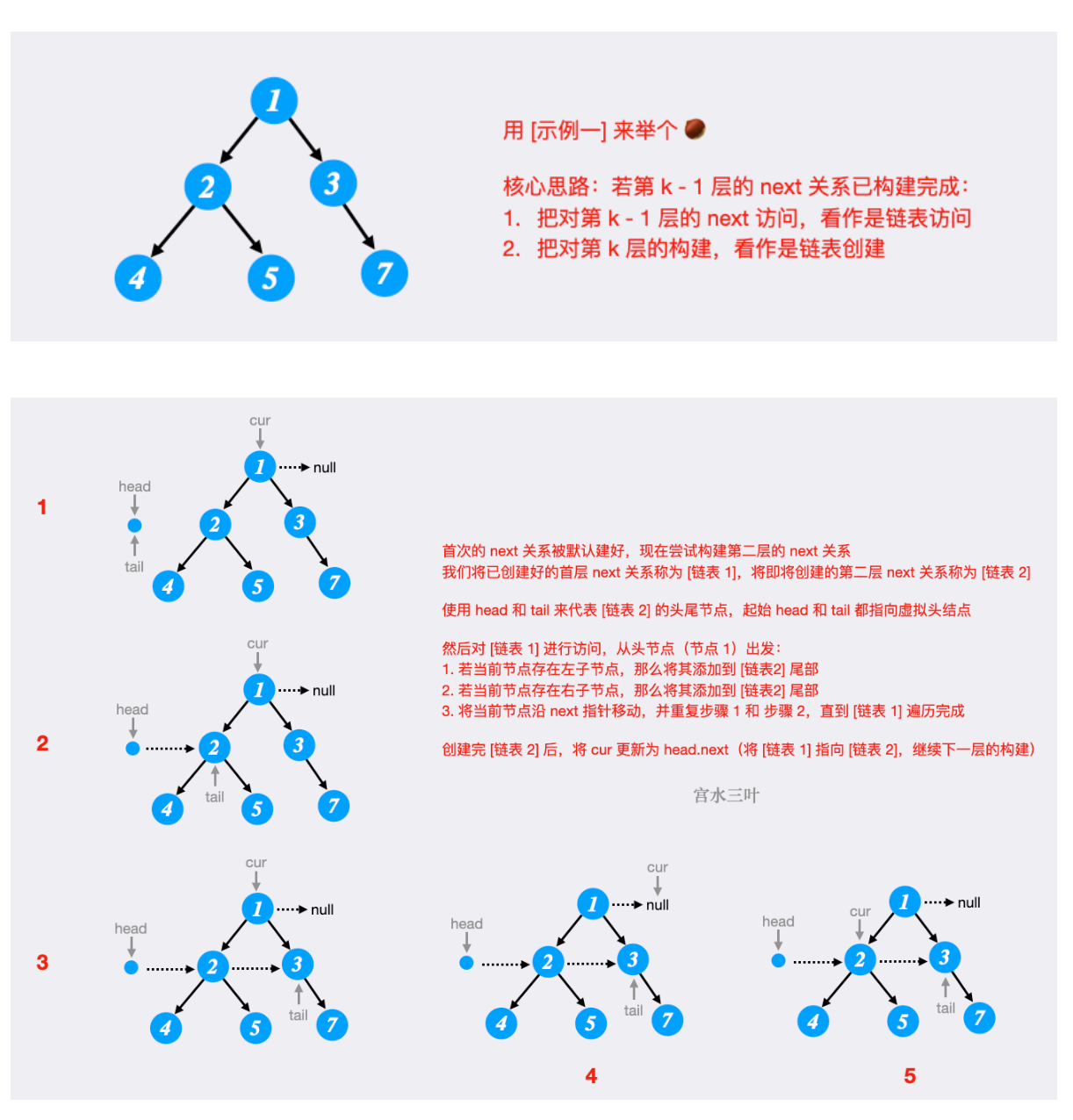
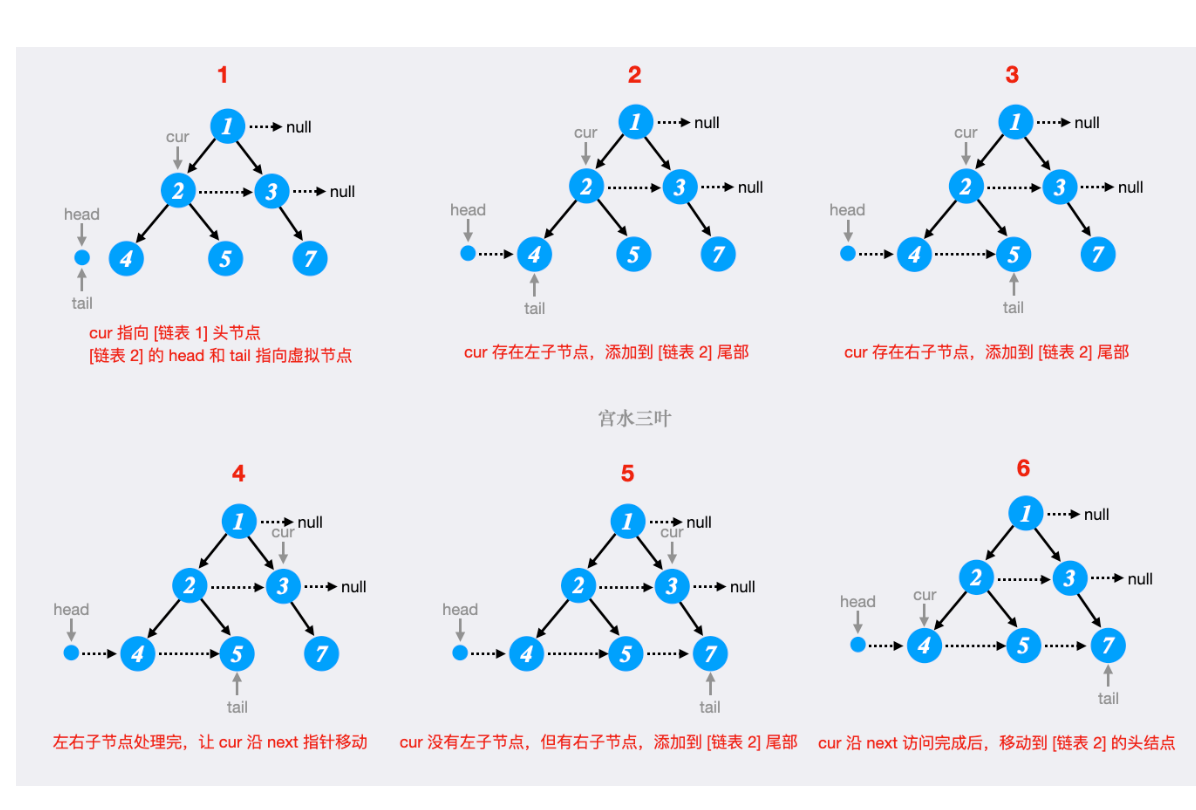
/*
// Definition for a Node.
class Node {
public:int val;Node* left;Node* right;Node* next;Node() : val(0), left(NULL), right(NULL), next(NULL) {}Node(int _val) : val(_val), left(NULL), right(NULL), next(NULL) {}Node(int _val, Node* _left, Node* _right, Node* _next): val(_val), left(_left), right(_right), next(_next) {}
};
*/class Solution {
public:Node* connect(Node* root) {Node* ans=root;if(root==NULL)return ans;Node*cur=root;while(cur){Node* head=new Node(-1);Node *tail=head;for(auto i=cur;i!=NULL;i=i->next){if(i->left){tail->next=i->left;tail=tail->next;}if(i->right){tail->next=i->right;tail=tail->next;}}cur=head->next;}return ans;}
};
- 时间复杂度:O(N)。我们需要遍历这棵树上所有的点,时间复杂度为 O(N)。
- 空间复杂度:O(1)。
75. 二叉树展开为链表

进阶:O(1)额外空间?
解法一:
将二叉树展开为单链表之后,单链表中的节点顺序即为二叉树的前序遍历访问各节点的顺序。因此,可以对二叉树进行前序遍历,获得各节点被访问到的顺序。由于将二叉树展开为链表之后会破坏二叉树的结构,因此在前序遍历结束之后,将前后节点的顺序存储在数组中,然后更新每个节点的左右子节点的信息,将二叉树展开为单链表。
前序遍历可以通过递归或者迭代的方式实现。以下代码通过递归实现前序遍历。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:void flatten(TreeNode* root) {vector<TreeNode*>listNode;preOrder(root,listNode);int n=listNode.size();TreeNode *next,*cur;for(int i=0;i<n-1;i++){cur=listNode.at(i);next=listNode.at(i+1);cur->left=nullptr;cur->right=next;}}void preOrder(TreeNode*root,vector<TreeNode*>&listNode){if(root==nullptr)return;listNode.push_back(root);preOrder(root->left,listNode);preOrder(root->right,listNode);}
};
时间复杂度:O(n),其中 n 是二叉树的节点数。前序遍历的时间复杂度是 O(n),前序遍历之后,需要对每个节点更新左右子节点的信息,时间复杂度也是 O(n)。
空间复杂度:O(n),其中 n是二叉树的节点数。空间复杂度取决于栈(递归调用栈或者迭代中显性使用的栈)和存储前序遍历结果的列表的大小,栈内的元素个数不会超过 n,前序遍历列表中的元素个数是 n
解法二:优化方法O(1)空间
可以发现展开的顺序其实就是二叉树的先序遍历。算法和 94 题中序遍历的 Morris 算法有些神似,我们需要两步完成这道题。
- 将左子树插入到右子树的地方
- 将原来的右子树接到左子树的最右边节点
- 考虑新的右子树的根节点,一直重复上边的过程,直到新的右子树为 null


/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:void flatten(TreeNode* root) {if(root==nullptr)return;while(root!=nullptr){//左子树为null,直接考虑下一个节点if(root->left==nullptr){root=root->right;}else{//找左子树最右边的节点TreeNode*pre=root->left;while(pre->right!=nullptr){pre=pre->right;}//将原来的右子树接到左子树的最右边节点pre->right=root->right;//将左子树插入右子树的地方root->right=root->left;root->left=nullptr;//考虑下一个节点root=root->right;}}}
};
时间复杂度:O(n)
空间复杂度:O(1)
76. 路径总和
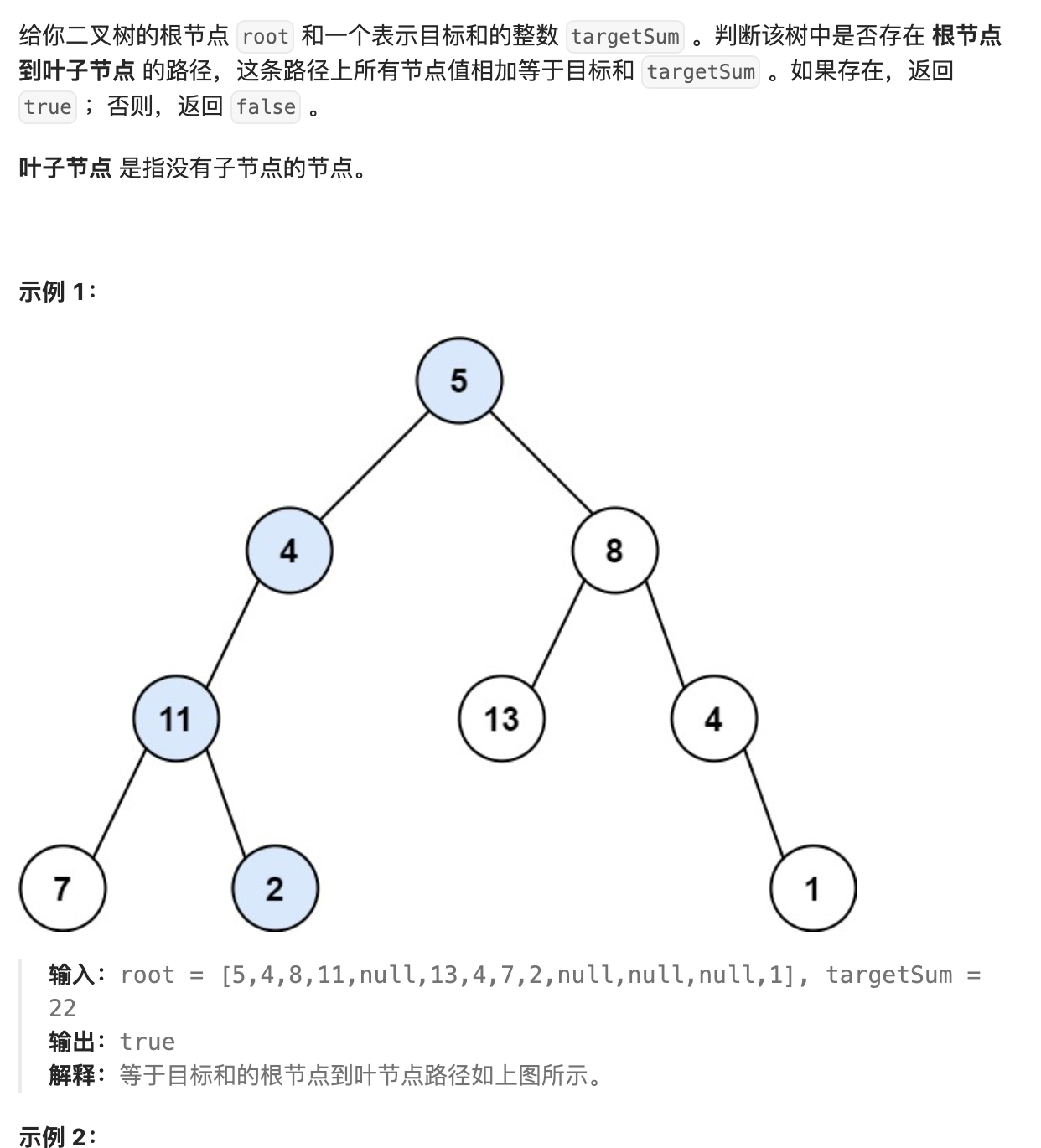
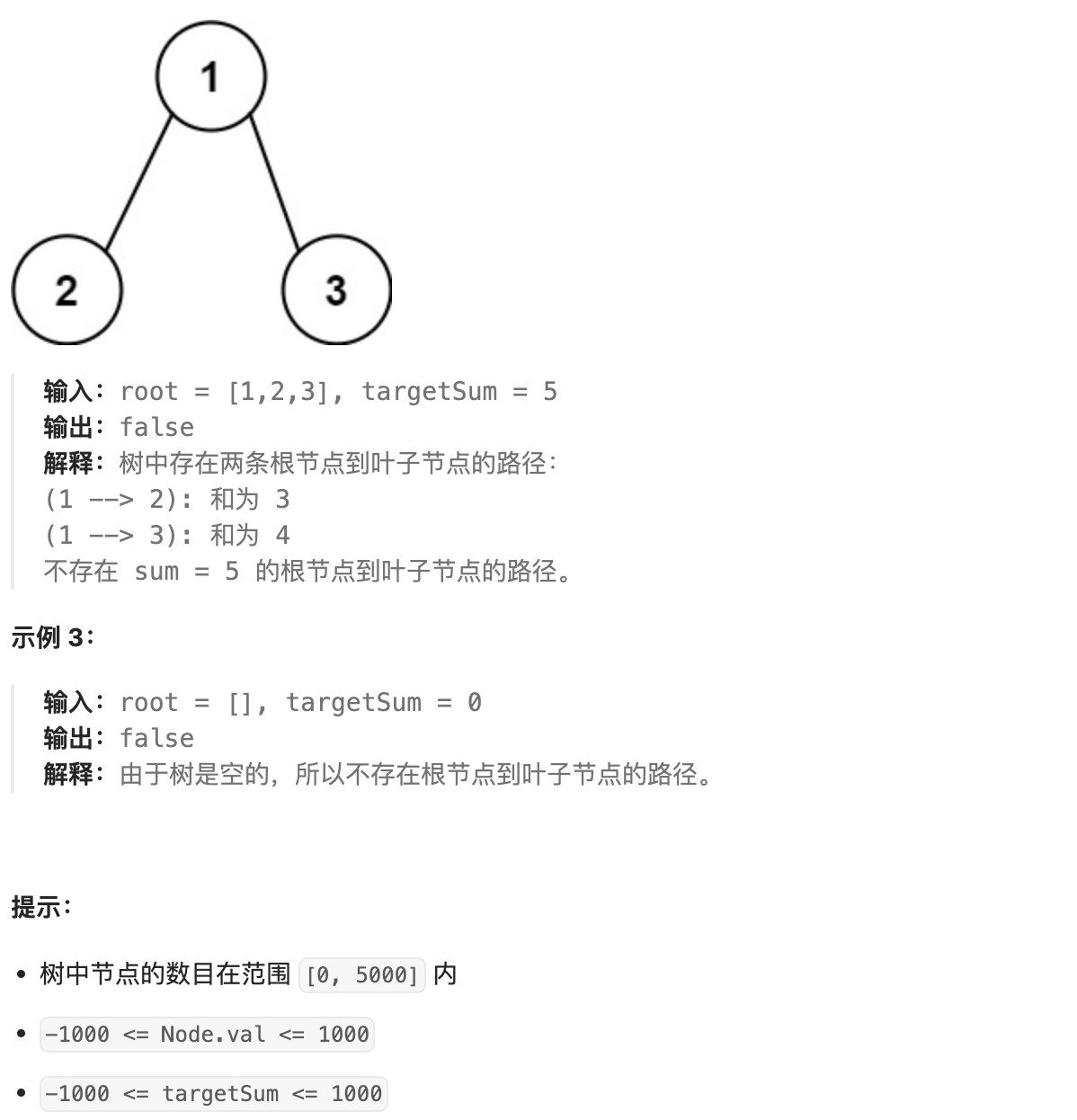
解法一:深度优先遍历DFS
观察要求我们完成的函数,我们可以归纳出它的功能:询问是否存在从当前节点 root 到叶子节点的路径,满足其路径和为 sum。
假定从根节点到当前节点的值之和为 val,我们可以将这个大问题转化为一个小问题:是否存在从当前节点的子节点到叶子的路径,满足其路径和为 sum - val。
不难发现这满足递归的性质,若当前节点就是叶子节点,那么我们直接判断 sum 是否等于 val 即可(因为路径和已经确定,就是当前节点的值,我们只需要判断该路径和是否满足条件)。若当前节点不是叶子节点,我们只需要递归地询问它的子节点是否能满足条件即可。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:bool hasPathSum(TreeNode* root, int targetSum) {if(!root)return false;if(root->left==nullptr&&root->right==nullptr)return targetSum==root->val;return hasPathSum(root->left,targetSum-root->val)||hasPathSum(root->right,targetSum-root->val);}
};
时间复杂度:O(N),其中 N 是树的节点数。对每个节点访问一次。
空间复杂度:O(H),其中 H 是树的高度。空间复杂度主要取决于递归时栈空间的开销,最坏情况下,树呈现链状,空间复杂度为 O(N)。平均情况下树的高度与节点数的对数正相关,空间复杂度为 O(logN)。
解法二:迭代
首先我们可以想到使用广度优先搜索的方式,记录从根节点到当前节点的路径和,以防止重复计算。
这样我们使用两个队列,分别存储将要遍历的节点,以及根节点到这些节点的路径和即可。
112. 路径总和 - 力扣(LeetCode)
77. 求根节点到叶节点数字之和
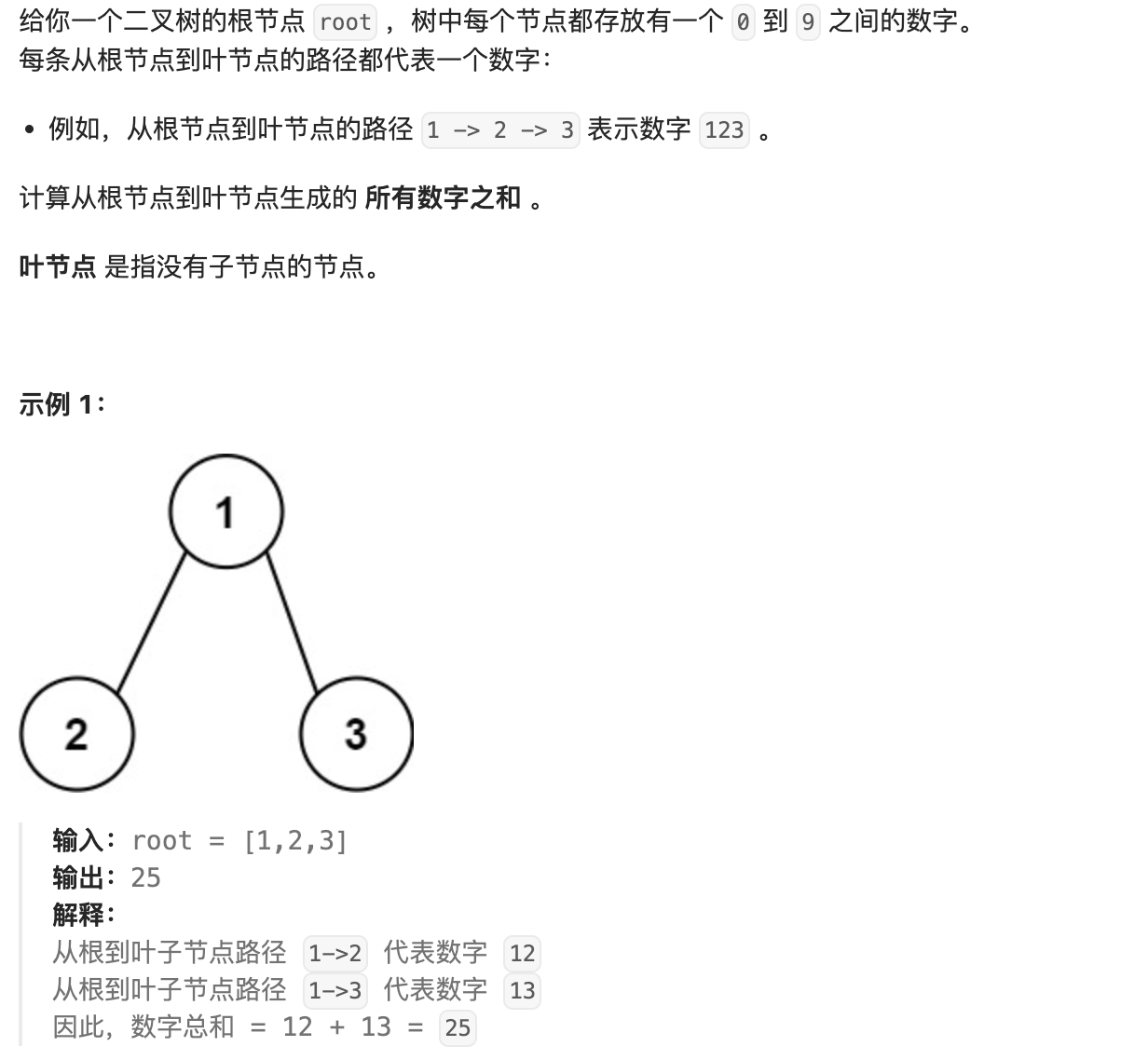
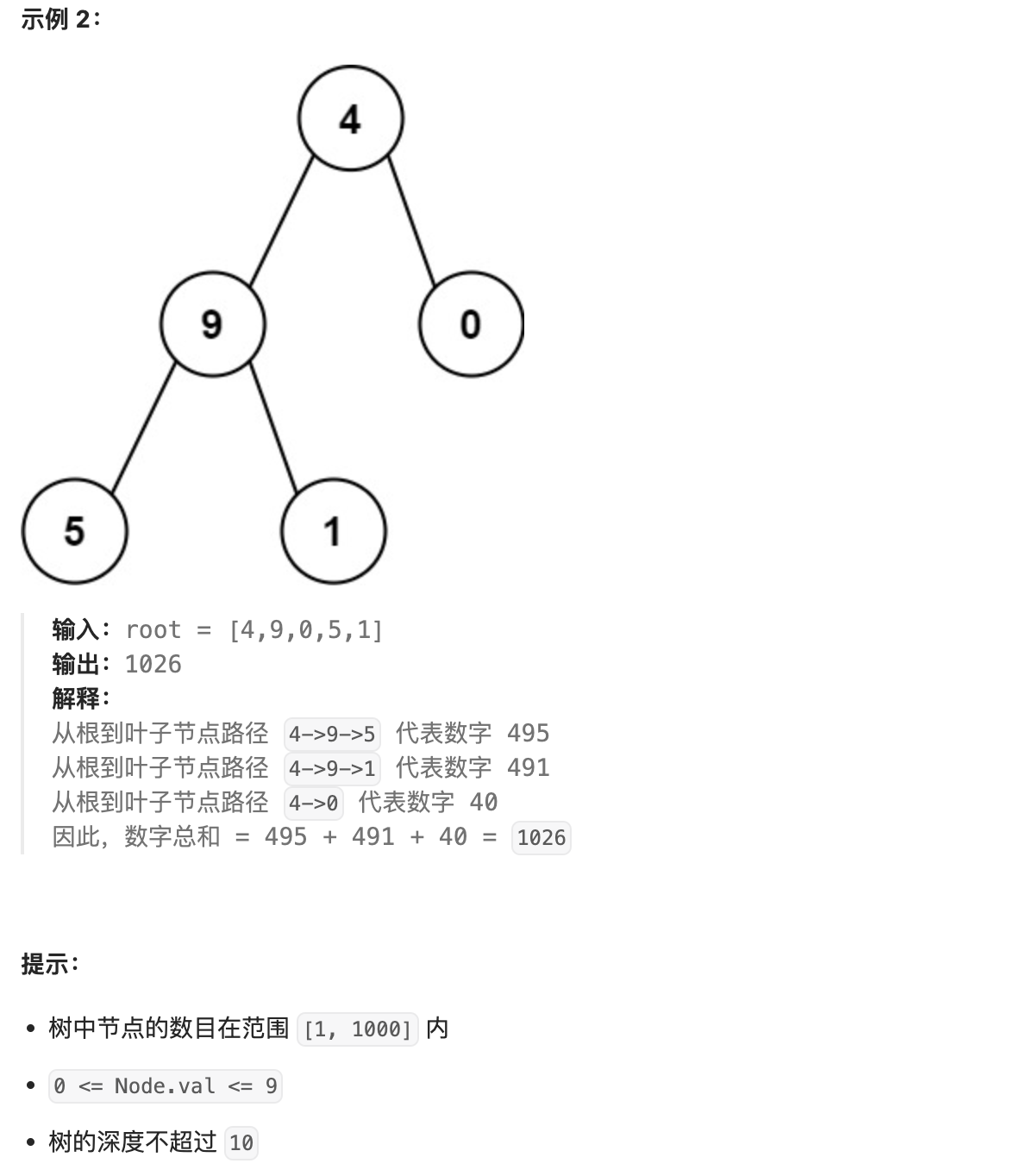
解法一:深度优先遍历
这道题中,二叉树的每条从根节点到叶子节点的路径都代表一个数字。其实,每个节点都对应一个数字,等于其父节点对应的数字乘以 10 再加上该节点的值(这里假设根节点的父节点对应的数字是 0)。只要计算出每个叶子节点对应的数字,然后计算所有叶子节点对应的数字之和,即可得到结果。可以通过深度优先搜索和广度优先搜索实现。
深度优先搜索是很直观的做法。从根节点开始,遍历每个节点,如果遇到叶子节点,则将叶子节点对应的数字加到数字之和。如果当前节点不是叶子节点,则计算其子节点对应的数字,然后对子节点递归遍历。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int total_sum=0;void dfs(TreeNode* root,int cur_sum){if(root->left==nullptr&&root->right==nullptr){total_sum+=cur_sum;}if(root->left){int next_sum=cur_sum*10+root->left->val; dfs(root->left,next_sum);}if(root->right){int next_sum=cur_sum*10+root->right->val; dfs(root->right,next_sum);}}int sumNumbers(TreeNode* root) {if(root==nullptr)return 0;dfs(root,root->val);return total_sum;}
};
时间复杂度:O(n),其中 n 是二叉树的节点个数。对每个节点访问一次。
空间复杂度:O(n),其中 n 是二叉树的节点个数。空间复杂度主要取决于递归调用的栈空间,递归栈的深度等于二叉树的高度,最坏情况下,二叉树的高度等于节点个数,空间复杂度为 O(n)。
解法二:广度优先遍历
使用广度优先搜索,需要维护两个队列,分别存储节点和节点对应的数字。
初始时,将根节点和根节点的值分别加入两个队列。每次从两个队列分别取出一个节点和一个数字,进行如下操作:
- 如果当前节点是叶子节点,则将该节点对应的数字加到数字之和;
- 如果当前节点不是叶子节点,则获得当前节点的非空子节点,并根据当前节点对应的数字和子节点的值计算子节点对应的数字,然后将子节点和子节点对应的数字分别加入两个队列。
- 搜索结束后,即可得到所有叶子节点对应的数字之和。
class Solution {
public:int sumNumbers(TreeNode* root) {if (root == nullptr) {return 0;}int sum = 0;queue<TreeNode*> nodeQueue;queue<int> numQueue;nodeQueue.push(root);numQueue.push(root->val);while (!nodeQueue.empty()) {TreeNode* node = nodeQueue.front();int num = numQueue.front();nodeQueue.pop();numQueue.pop();TreeNode* left = node->left;TreeNode* right = node->right;if (left == nullptr && right == nullptr) {sum += num;} else {if (left != nullptr) {nodeQueue.push(left);numQueue.push(num * 10 + left->val);}if (right != nullptr) {nodeQueue.push(right);numQueue.push(num * 10 + right->val);}}}return sum;}
};
时间复杂度:O(n),其中 n 是二叉树的节点个数。对每个节点访问一次。
空间复杂度:O(n),其中 n 是二叉树的节点个数。空间复杂度主要取决于队列,每个队列中的元素个数不会超过 n
78. 二叉树中的最大路径和
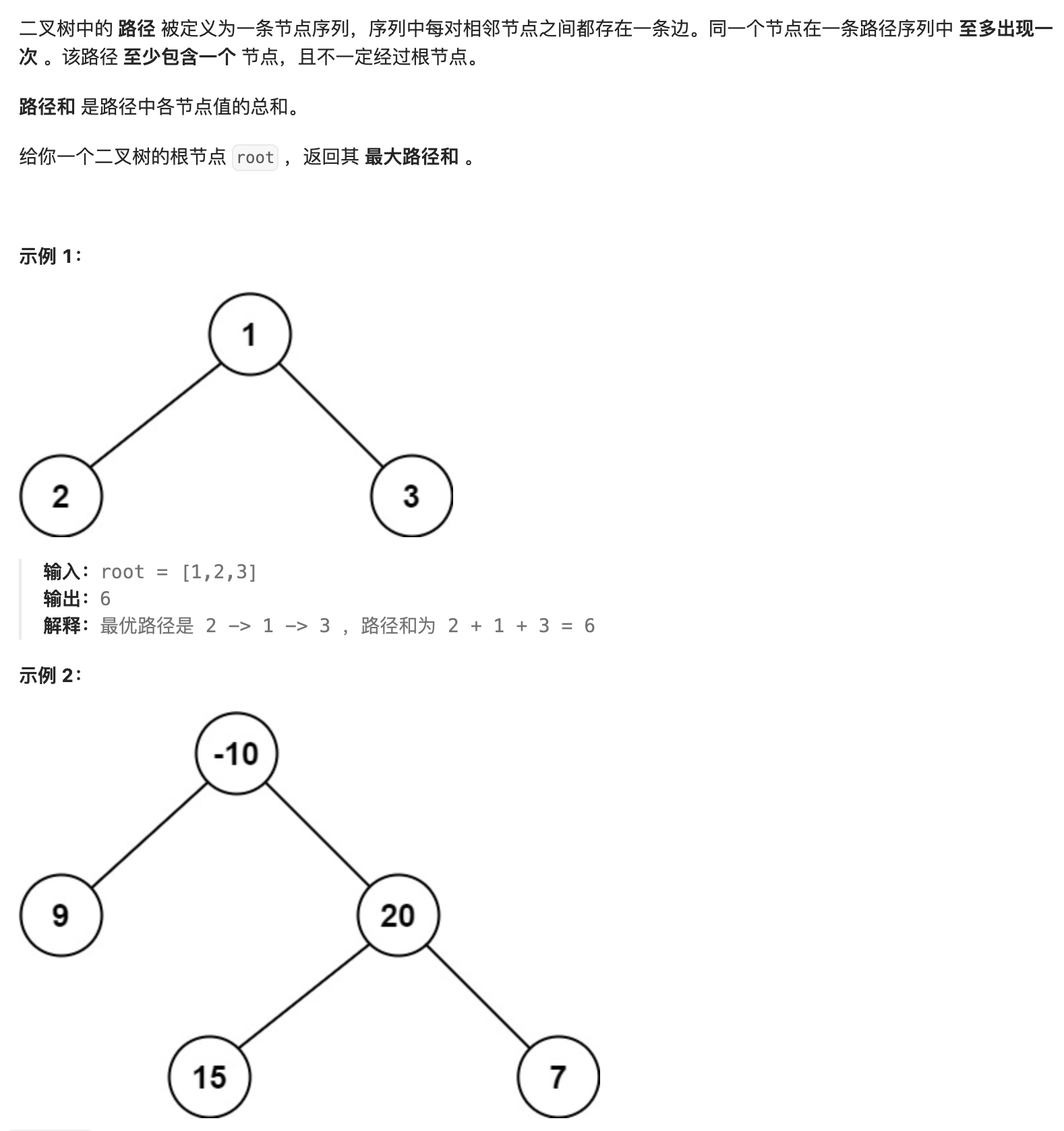

解法:递归
首先,考虑实现一个简化的函数 maxGain(node),该函数计算二叉树中的一个节点的最大贡献值,具体而言,就是在以该节点为根节点的子树中寻找以该节点为起点的一条路径,使得该路径上的节点值之和最大。
具体而言,该函数的计算如下。
空节点的最大贡献值等于 0。
非空节点的最大贡献值等于节点值与其子节点中的最大贡献值之和(对于叶节点而言,最大贡献值等于节点值)。
例如,考虑如下二叉树。
-10
/
9 20
/
15 7
叶节点 9、15、7 的最大贡献值分别为 9、15、7。
得到叶节点的最大贡献值之后,再计算非叶节点的最大贡献值。节点 20 的最大贡献值等于 20+max(15,7)=35,节点 −10 的最大贡献值等于 −10+max(9,35)=25。
上述计算过程是递归的过程,因此,对根节点调用函数 maxGain,即可得到每个节点的最大贡献值。
根据函数 maxGain 得到每个节点的最大贡献值之后,如何得到二叉树的最大路径和?对于二叉树中的一个节点,该节点的最大路径和取决于该节点的值与该节点的左右子节点的最大贡献值,如果子节点的最大贡献值为正,则计入该节点的最大路径和,否则不计入该节点的最大路径和。维护一个全局变量 maxSum 存储最大路径和,在递归过程中更新 maxSum 的值,最后得到的 maxSum 的值即为二叉树中的最大路径和。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int maxSum=INT_MIN;int dfs(TreeNode*root){if(root==nullptr)return 0;//递归计算左右子节点的最大贡献值//只有在最大贡献值大于0的时候,才取得对应自己饿点int leftMax=max(dfs(root->left),0);int rightMax=max(dfs(root->right),0);//节点的最大路径取决于该节点的值和该节点的左右子节点的最大贡献值int rootMax=root->val+leftMax+rightMax;maxSum=max(maxSum,rootMax);//返回节点的最大贡献值return root->val+max(leftMax,rightMax);}int maxPathSum(TreeNode* root) {dfs(root);return maxSum;}
};
时间复杂度:O(N),其中 N 是二叉树中的节点个数。对每个节点访问不超过 2 次。
空间复杂度:O(N),其中 N 是二叉树中的节点个数。空间复杂度主要取决于递归调用层数,最大层数等于二叉树的高度,最坏情况下,二叉树的高度等于二叉树中节点的个数。
79. 二叉树搜索迭代器


解法一:做一次完全的中序遍历
我们可以直接对二叉搜索树做一次完全的递归遍历,获取中序遍历的全部结果并保存在数组中。随后,我们利用得到的数组本身来实现迭代器。
class BSTIterator {
private:void inorder(TreeNode* root, vector<int>& res) {if (!root) {return;}inorder(root->left, res);res.push_back(root->val);inorder(root->right, res);}vector<int> inorderTraversal(TreeNode* root) {vector<int> res;inorder(root, res);return res;}vector<int> arr;int idx;
public:BSTIterator(TreeNode* root): idx(0), arr(inorderTraversal(root)) {}int next() {return arr[idx++];}bool hasNext() {return (idx < arr.size());}
};
时间复杂度:初始化需要 O(n) 的时间,其中 n 为树中节点的数量。随后每次调用只需要 O(1) 的时间。
空间复杂度:O(n),因为需要保存中序遍历的全部结果。
解法二:迭代【此方法才符合迭代器的原理】
除了递归的方法外,我们还可以利用栈这一数据结构,通过迭代的方式对二叉树做中序遍历。此时,我们无需预先计算出中序遍历的全部结果,只需要实时维护当前栈的情况即可。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class BSTIterator {
public:TreeNode*cur;stack<TreeNode*>stk;BSTIterator(TreeNode* root) :cur(root){};int next() {while(cur!=nullptr){stk.push(cur);cur=cur->left;}cur=stk.top();stk.pop();int ret=cur->val;cur=cur->right;return ret;}bool hasNext() {return cur!=nullptr||!stk.empty();}
};/*** Your BSTIterator object will be instantiated and called as such:* BSTIterator* obj = new BSTIterator(root);* int param_1 = obj->next();* bool param_2 = obj->hasNext();*/
时间复杂度:显然,初始化和调用 hasNext() 都只需要 O(1) 的时间。每次调用 next() 函数最坏情况下需要 O(n) 的时间;但考虑到 n 次调用 next() 函数总共会遍历全部的 n 个节点,因此总的时间复杂度为 O(n),因此单次调用平均下来的均摊复杂度为 O(1)。
空间复杂度:O(n),其中 n 是二叉树的节点数量。空间复杂度取决于栈深度,而栈深度在二叉树为一条链的情况下会达到 O(n) 的级别。
80. 完全二叉树的节点个数
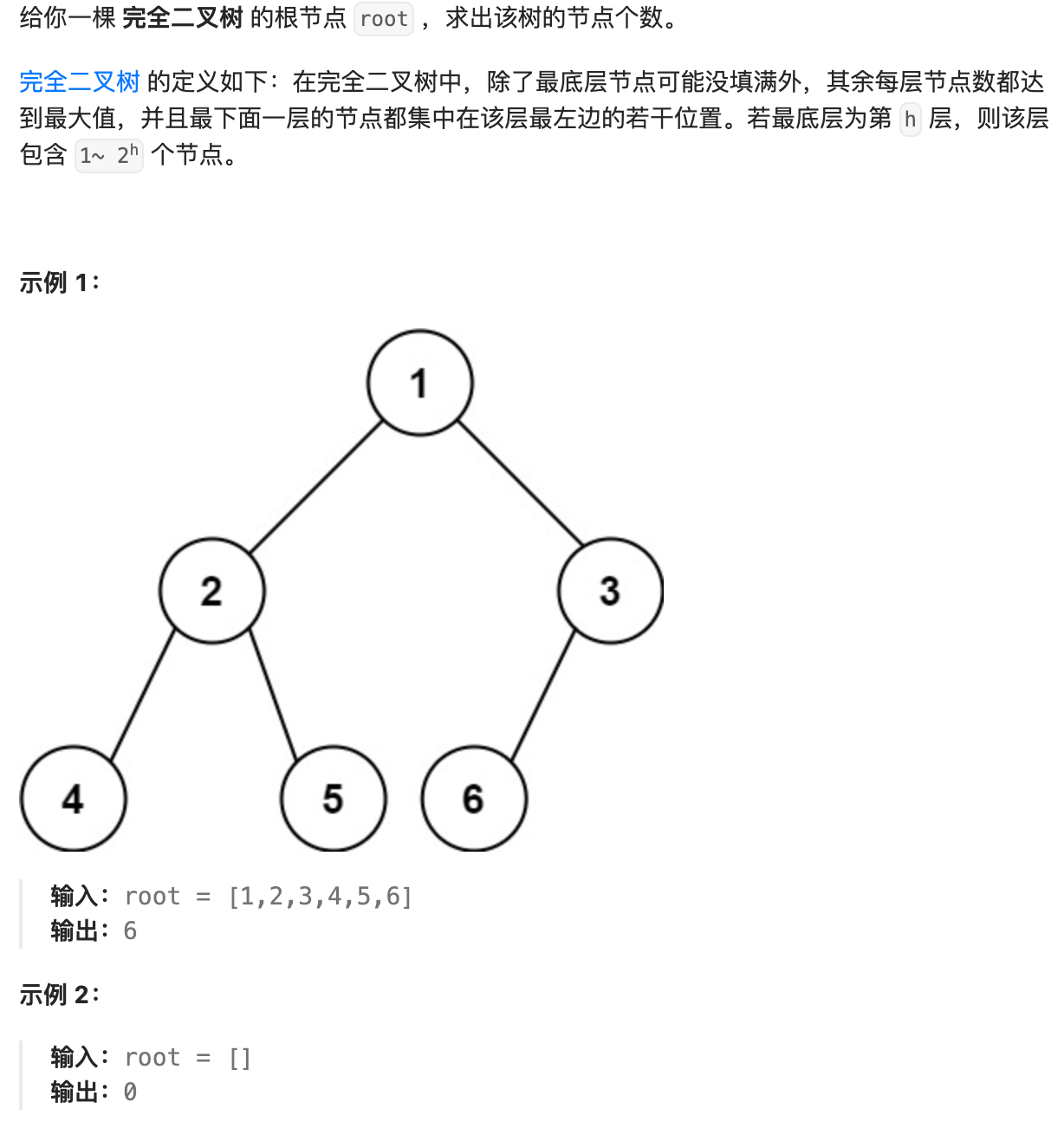

解法一:深度优先遍历或者广度优先遍历记录所有节点的个数
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int node_num=0;void dfs(TreeNode*root){node_num++;if(root->left!=nullptr){dfs(root->left);}if(root->right!=nullptr){dfs(root->right);}}int countNodes(TreeNode* root) {if(root==nullptr)return 0; dfs(root);return node_num; }
};
时间复杂度:O(n)
空间复杂度:O(1)
解法二:二分法加位运算
对于任意二叉树,都可以通过广度优先搜索或深度优先搜索计算节点个数,时间复杂度和空间复杂度都是 O(n),其中 n 是二叉树的节点个数。这道题规定了给出的是完全二叉树,因此可以利用完全二叉树的特性计算节点个数。
规定根节点位于第 0 层,完全二叉树的最大层数为 h。根据完全二叉树的特性可知,完全二叉树的最左边的节点一定位于最底层,因此从根节点出发,每次访问左子节点,直到遇到叶子节点,该叶子节点即为完全二叉树的最左边的节点,经过的路径长度即为最大层数 h。
当 0≤i<h 时,第 i 层包含 2 i 2^i 2i个节点,最底层包含的节点数最少为 1,最多为 2 h 2^h 2h。
当最底层包含 1 个节点时,完全二叉树的节点个数是
∑ i = 0 h − 1 2 i + 1 = 2 h \sum_{i=0}^{h-1}2^i+1=2^h i=0∑h−12i+1=2h
当最底层包含 2 h 2^h 2h个节点时,完全二叉树的节点个数是
∑ i = 0 h 2 i = 2 h + 1 − 1 \sum_{i=0}^{h}2^i=2^{h+1}-1 i=0∑h2i=2h+1−1
因此对于最大层数为 h 的完全二叉树,节点个数一定在 [ 2 h ] , 2 h + 1 − 1 [2^h],2^{h+1}-1 [2h],2h+1−1的范围内,可以在该范围内通过二分查找的方式得到完全二叉树的节点个数。
具体做法是,根据节点个数范围的上下界得到当前需要判断的节点个数 k,如果第 k 个节点存在,则节点个数一定大于或等于 k,如果第 k 个节点不存在,则节点个数一定小于 k,由此可以将查找的范围缩小一半,直到得到节点个数。
如何判断第 k 个节点是否存在呢?如果第 k 个节点位于第 h 层,则 k 的二进制表示包含 h+1 位,其中最高位是 1,其余各位从高到低表示从根节点到第 k 个节点的路径,0 表示移动到左子节点,1 表示移动到右子节点。通过位运算得到第 k 个节点对应的路径,判断该路径对应的节点是否存在,即可判断第 k 个节点是否存在。
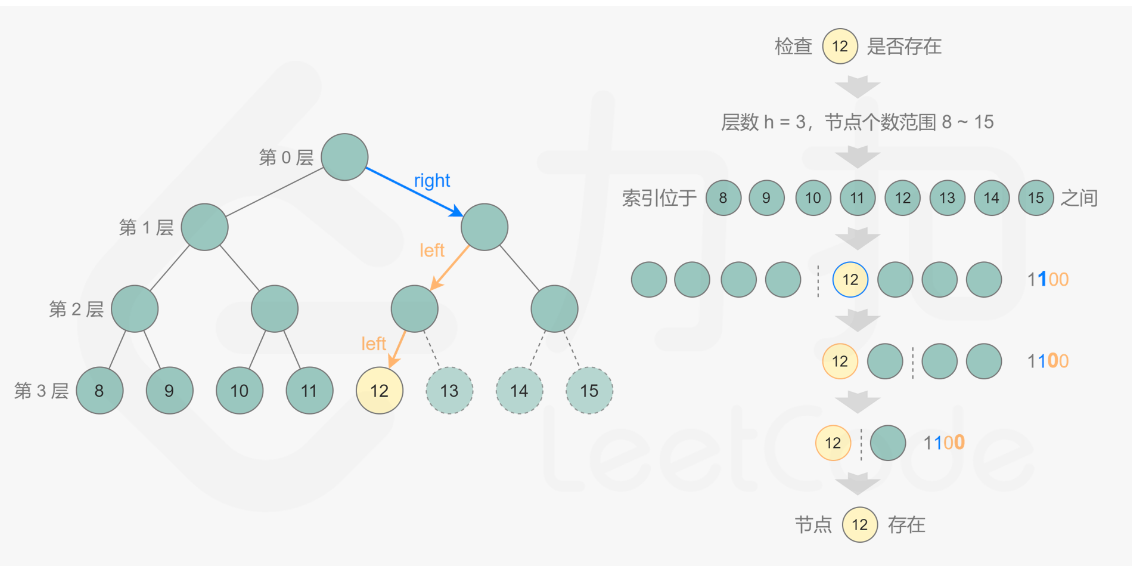
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:
int countNodes(TreeNode* root) {if(root==nullptr)return 0;int level=0;TreeNode*node=root;while(node->left!=nullptr){level++;node=node->left;}int low = 1 << level, high = (1 << (level + 1)) - 1;while(low<high){int mid=(high-low+1)/2+low;if(exists(root,level,mid)){low=mid;}else{high=mid-1;}}return low;
}
bool exists(TreeNode*root,int level,int k){int bits=1<<(level-1);TreeNode* node=root;while(node!=nullptr&&bits>0){if(!(bits&k)){node=node->left;}else{node=node->right;}bits>>=1;}return node!=nullptr;
}
};
注意,对于exits的函数的解释为:
1 h = 0/ \2 3 h = 1/ \ / 4 5 6 h = 2现在这个树中的值都是节点的编号,最底下的一层的编号是[2^h ,2^h - 1],现在h = 2,也就是4, 5, 6, 7。
4, 5, 6, 7对应二进制分别为 100 101 110 111 不看最左边的1,从第二位开始,0表示向左,1表示向右,正好可以表示这个节点相对于根节点的位置。
比如4的 00 就表示从根节点 向左 再向左。6的 10 就表示从根节点 向右 再向左那么想访问最后一层的节点就可以从节点的编号的二进制入手。从第二位开始的二进制位表示了最后一层的节点相对于根节点的位置。
那么就需要一个bits = 2^(h - 1) 上面例子中的bits就是2,对应二进制为010。这样就可以从第二位开始判断。(树三层高,需要向左或向右走两次才能到叶子)
比如看5这个节点存不存在,先通过位运算找到编号为5的节点相对于根节点的位置。010 & 101 发现第二位是0,说明从根节点开始,第一步向左走。
之后将bit右移一位,变成001。001 & 101 发现第三位是1,那么第二步向右走。
最后bit为0,说明已经找到编号为5的这个节点相对于根节点的位置,看这个节点是不是空,不是说明存在,exist返回真
编号为5的节点存在,说明总节点数量一定大于等于5。所以二分那里low = mid再比如看7存不存在,010 & 111 第二位为1,第一部从根节点向右;001 & 111 第三位也为1,第二步继续向右。
然后判断当前节点是不是null,发现是null,exist返回假。
编号为7的节点不存在,说明总节点数量一定小于7。所以high = mid - 1
时间复杂度: O ( l o g n 2 ) O(log^2_n) O(logn2),其中 n 是完全二叉树的节点数。
首先需要 O(h) 的时间得到完全二叉树的最大层数,其中 h 是完全二叉树的最大层数。
使用二分查找确定节点个数时,需要查找的次数为 O ( l o g 2 h ) = O ( h ) O(log2^h)=O(h) O(log2h)=O(h),每次查找需要遍历从根节点开始的一条长度为 h 的路径,需要 O(h) 的时间,因此二分查找的总时间复杂度是 O ( h 2 ) O(h^2) O(h2)。
因此总时间复杂度是 O ( h 2 ) O(h^2) O(h2)。由于完全二叉树满足 KaTeX parse error: Undefined control sequence: \textless at position 9: 2^h\le n\̲t̲e̲x̲t̲l̲e̲s̲s̲ ̲2^{h+1} ,因此有 O ( h ) = O ( l o g n ) O(h)=O(logn) O(h)=O(logn), O ( h 2 ) = O ( l o g n 2 ) O(h^2)=O(log^2_n) O(h2)=O(logn2)。
空间复杂度:O(1)。只需要维护有限的额外空间。
81. 二叉树的最近公共祖先


解法一:递归
解题思路:
祖先的定义: 若节点 p 在节点 root的左(右)子树中,或 p=root,则称 root是 p 的祖先。
最近公共祖先的定义: 设节点 root为节点 p,q的某公共祖先,若其左子节点 root.left 和右子节点 root.right 都不是 p,q的公共祖先,则称 root 是 “最近的公共祖先” 。
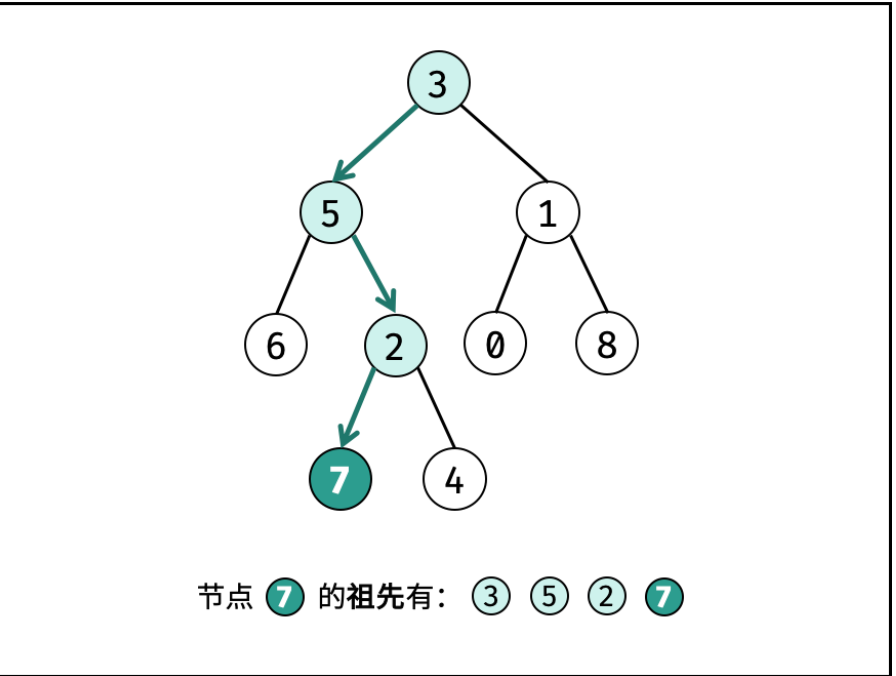
根据以上定义,若 root是 p,q 的 最近公共祖先 ,则只可能为以下情况之一:
p 和 q 在 root 的子树中,且分列 root的 异侧(即分别在左、右子树中);
p=root ,且 q 在 root 的左或右子树中;
q=root,且 p 在 root的左或右子树中;
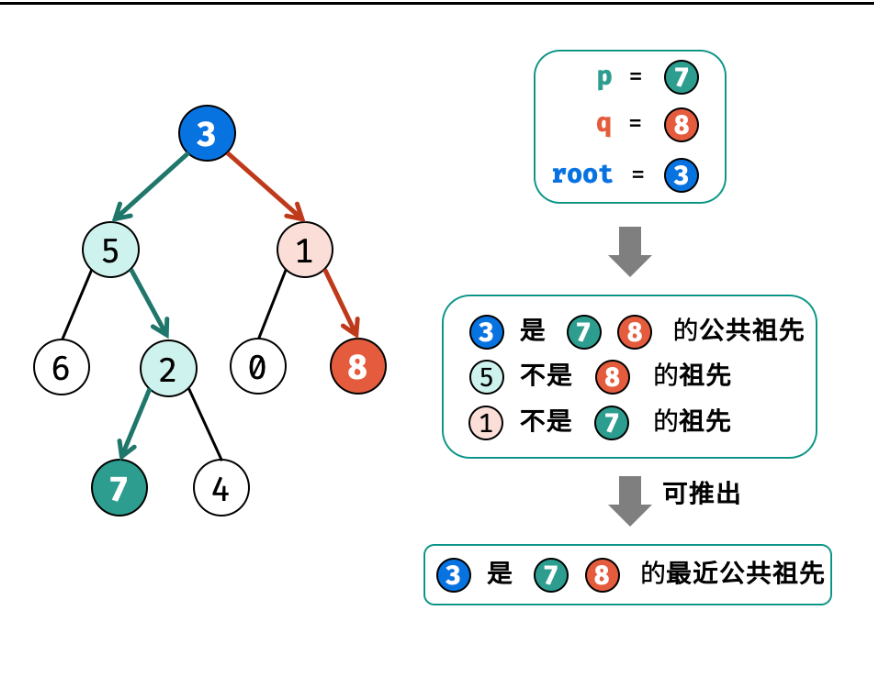
考虑通过递归对二叉树进行先序遍历,当遇到节点 p 或 q时返回。从底至顶回溯,当节点 p,q在节点 root 的异侧时,节点 root 即为最近公共祖先,则向上返回 root 。
递归解析:
终止条件:
- 当越过叶节点,则直接返回 nul;
- 当 root 等于 p,q ,则直接返回 root ;
递推工作: - 开启递归左子节点,返回值记为 left;
- 开启递归右子节点,返回值记为 right;
返回值: 根据 left 和 right ,可展开为四种情况;
当 left 和 right 同时为空 :说明 root的左 / 右子树中都不包含 p,q,返回 null ;
当 left 和 right 同时不为空 :说明 p,q分列在 root的 异侧 (分别在 左 / 右子树),因此 root为最近公共祖先,返回 root ;
当 left为空 ,right 不为空 :p,q都不在 root 的左子树中,直接返回 right 。具体可分为两种情况:
p,q 其中一个在 root 的 右子树 中,此时 right 指向 p(假设为 p );
p,q 两节点都在 root 的 右子树 中,此时的 right 指向 最近公共祖先节点 ;
当 left 不为空 , right 为空 :与情况 3. 同理;
代码:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) : val(x), left(NULL), right(NULL) {}* };*/
class Solution {
public:TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {if(root==nullptr||root==p||root==q)return root;TreeNode *left=lowestCommonAncestor(root->left,p,q);TreeNode *right=lowestCommonAncestor(root->right,p,q);if(left!=nullptr&&right!=nullptr)return root;else if(left==nullptr)return right;elsereturn left;}
};
时间复杂度:O(N),其中 N 是二叉树的节点数。二叉树的所有节点有且只会被访问一次,因此时间复杂度为 O(N)。
空间复杂度:O(N) ,其中 N 是二叉树的节点数。递归调用的栈深度取决于二叉树的高度,二叉树最坏情况下为一条链,此时高度为 N,因此空间复杂度为 O(N)。
解法二:存储父节点,注意到题目给的条件中,有每个节点的值各不相同,可以使用哈希表存储父节点
思路
我们可以用哈希表存储所有节点的父节点,然后我们就可以利用节点的父节点信息从 p 结点开始不断往上跳,并记录已经访问过的节点,再从 q 节点开始不断往上跳,如果碰到已经访问过的节点,那么这个节点就是我们要找的最近公共祖先。
算法
从根节点开始遍历整棵二叉树,用哈希表记录每个节点的父节点指针。
从 p 节点开始不断往它的祖先移动,并用数据结构记录已经访问过的祖先节点。
同样,我们再从 q 节点开始不断往它的祖先移动,如果有祖先已经被访问过,即意味着这是 p 和 q 的深度最深的公共祖先,即 LCA 节点。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) : val(x), left(NULL), right(NULL) {}* };*/
class Solution {
public:unordered_map<int,TreeNode*>fa;unordered_map<int,bool>visited;void dfs(TreeNode*root){if(root->left!=nullptr){fa[root->left->val]=root;dfs(root->left);}if(root->right!=nullptr){fa[root->right->val]=root;dfs(root->right);}}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {fa[root->val]=nullptr;dfs(root);while(p!=nullptr){visited[p->val]=true;p=fa[p->val];}while(q!=nullptr){if(visited[q->val])return q;q=fa[q->val];}return nullptr;}
};
时间复杂度:O(N),其中 N 是二叉树的节点数。二叉树的所有节点有且只会被访问一次,从 p 和 q 节点往上跳经过的祖先节点个数不会超过 N,因此总的时间复杂度为 O(N)。
空间复杂度:O(N) ,其中 N 是二叉树的节点数。递归调用的栈深度取决于二叉树的高度,二叉树最坏情况下为一条链,此时高度为 N,因此空间复杂度为 O(N),哈希表存储每个节点的父节点也需要 O(N)的空间复杂度,因此最后总的空间复杂度为 O(N)。
相关文章:
力扣面试经典 150(上)
文章目录 数组/字符串1. 合并两个有序数组2. 移除元素3. 删除有序数组中的重复项4. 删除有序数组的重复项II5. 多数元素6. 轮转数组7. 买卖股票的最佳时机8. 买卖股票的最佳时机II9. 跳跃游戏10. 跳跃游戏II11. H 指数12. O(1)时间插入、删除和获取随机元素13. 除自身以外数组的…...

鸿蒙开发-音视频
Media Kit 特点 一般场合的音视频处理,可以直接使用系统集成的Video组件,不过外观和功能自定义程度低Media kit:轻量媒体引擎,系统资源占用低支持音视频播放/录制,pipeline灵活拼装,插件化扩展source/demu…...

第一个autogen与docker项目
前提条件:在windows上安装docker 代码如下: import os import autogen from autogen import AssistantAgent, UserProxyAgentllm_config {"config_list": [{"model": "GLM-4-Plus","api_key": "your api…...

第三十四篇 MobileNetV1、V2、V3模型解析
摘要 这篇文章将 MobileNetV1、V2、V3汇在一起,解析移动端网络的结构。MobileNet系列的模型是非常经典的模型,值得深入研究一番。 MobileNetV1、V2、V3是MobileNet系列的三个重要版本,它们均针对移动和嵌入式设备进行了优化,具有轻量化、高效能的特点。以下是这三个模型的…...

Python学习——字符串操作方法
mystr “hello word goodbye” str “bye” Find函数:检测一个字符串中是否包含另一个字符串,找到了返回索引值,找不到了返回-1 print(mystr.find(str,0,len(mystr))) print(mystr.find(str,0,13)) index函数:检测一个字符串是否包含另一…...

力扣—15.三数之和
15. 三数之和 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元…...

容器安全检测和渗透测试工具
《Java代码审计》http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247484219&idx1&sn73564e316a4c9794019f15dd6b3ba9f6&chksmc0e47a67f793f371e9f6a4fbc06e7929cb1480b7320fae34c32563307df3a28aca49d1a4addd&scene21#wechat_redirect Docker-bench-…...

sqlite3自动删除数据的两种设置方式记录
文章概要 〇、背景一、基本思路1.1 按时间分多文件,限制文件的个数1.2 按时间分数据表,限制表的个数1.3 按记录的时间删除超过规定时间数据,限制记录数据的时间1.4 按记录的数据条数删除多余的数据,限制记录数据的个数二、实现代码三、测试方式〇、背景 基于嵌入式编程,在…...

Hive分桶超详细!!!
1、分桶的意义 数据分区可能导致有些分区,数据过多,有些分区,数据极少。分桶是将数据集分解为若干部分(数据文件)的另一种技术。 分区和分桶其实都是对数据更细粒度的管理。当单个分区或者表中的数据越来越大,分区不能细粒度的划分数据时,我…...
【深度学习之回归预测篇】 深度极限学习机DELM多特征回归拟合预测(Matlab源代码)
深度极限学习机 (DELM) 作为一种新型的深度学习算法,凭借其独特的结构和训练方式,在诸多领域展现出优异的性能。本文将重点探讨DELM在多输入单输出 (MISO) 场景下的应用,深入分析其算法原理、性能特点以及未来发展前景。 1、 DELM算法原理及其…...
Android mk/bp构建工具介绍
零. 前言 由于Bluedroid的介绍文档有限,以及对Android的一些基本的知识需要了(Android 四大组件/AIDL/Framework/Binder机制/JNI/HIDL等),加上需要掌握的语言包括Java/C/C等,加上网络上其实没有一个完整的介绍Bluedroid系列的文档࿰…...

数据源及分层开发
数据源及分层开发 1. 使用Tomcat数据源 连接池工作原理: 连接池是由容器提供的,用来管理池中连接对象。 连接池自动分配连接对象并对闲置的连接进行回收。 数据源(DataSource): javax.sql.DataSource接口负责建立…...

气膜场馆照明设计:科技与环保的完美结合—轻空间
气膜场馆的照明设计,选用高效节能的400瓦LED灯具,结合现代节能技术,提供强大而均匀的光照。LED灯具在光效和寿命方面优势显著,不仅降低运营能耗,还有效减少碳排放,为绿色场馆建设贡献力量。 科学分布&…...

并行IO接口8255
文章目录 8255A芯片组成外设接口三个端口两组端口关于C口(★) 内部逻辑CPU接口 8255A的控制字(★)位控字(D70)方式选择控制字(D71) 8255A的工作方式工作方式0(基本输入/输…...

Level DB --- SkipList
class SkipList class SkipList 是Level DB中的重要数据结构,存储在memtable中的数据通过SkipList来存储和检索数据,它有优秀的读写性能,且和红黑树相比,更适合多线程的操作。 SkipList SkipList还是一个比较简单的数据结构&a…...

第二十二周机器学习笔记:动手深度学习之——线性代数
第二十周周报 摘要Abstract一、动手深度学习1. 线性代数1.1 标量1.2 向量1.3 矩阵1.4 张量1.4.1 张量算法的基本性质 1.5 降维1.5.1 非降维求和 1.6 点积1.6.1 矩阵-向量积1.6.2 矩阵-矩阵乘法 1.7 范数 总结 摘要 本文深入探讨了深度学习中的数学基础,特别是线性代…...

leetcode 50个简单和中等难度的题
简单难度题目(25个) 两数之和 (Two Sum)有效的括号 (Valid Parentheses)罗马数字转整数 (Roman to Integer)最长公共前缀 (Longest Common Prefix)合并两个有序链表 (Merge Two Sorted Lists)移除链表元素 (Remove Linked List E…...

多模态大模型(5)--LLaVA
人类通过如视觉、语言、听觉等多种渠道与世界互动,每个单独的渠道在表示和传达某些概念时都有其独特的优势,人工智能(AI)的一个核心愿景是开发一个能够有效遵循多模态视觉和语言指令的通用助手,与人类意图一致…...

Vue实训---3-element plus的使用与布局
1.引入ElementPlus ElementPlus官网指南:快速开始 | Element Plus 在我们的项目main.js文件中,加入红框里的内容: import { createApp } from vue import App from ./App.vue // 引入全局样式,是对样式的初始化 import "/a…...

TritonServer中加载模型,并在Gunicorn上启动Web服务调用模型
TritonServer中加载模型,并在Gunicorn上启动Web服务调用模型 一、TritonServer中加载模型1.1 搭建本地仓库1.2 配置文件1.3 服务端代码1.4 启动TritonServer二、Gunicorn上启动Web服务2.1 安装和配置Gunicorn2.2 启动Gunicorn三、调用模型四、性能优化与监控五、总结在深度学习…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

鸿蒙HarmonyOS 5与Unity跨运行时通信实战指南
1. 这不是“调个API”那么简单:为什么鸿蒙Unity通信总在临门一脚卡住我第一次把Unity打包的AR模块塞进HarmonyOS 5 App里时,信心满满——毕竟文档里写着“支持JS/ArkTS调用Native能力”,Unity也标榜“跨平台通用”。结果呢?App一启…...

终极虚拟显示器解决方案:ParsecVDisplay完整使用指南
终极虚拟显示器解决方案:ParsecVDisplay完整使用指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一个基于Parsec虚拟显示驱动(VDD)的独立应用程序…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...

Apple Silicon Mac 电池管理的终极解决方案:Battery Toolkit 完整指南
Apple Silicon Mac 电池管理的终极解决方案:Battery Toolkit 完整指南 【免费下载链接】Battery-Toolkit Control the platform power state of your Apple Silicon Mac. 项目地址: https://gitcode.com/gh_mirrors/ba/Battery-Toolkit 在当今移动办公时代&a…...

3分钟掌握PUBG罗技鼠标宏:新手也能轻松压枪的完整指南
3分钟掌握PUBG罗技鼠标宏:新手也能轻松压枪的完整指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制…...

SSH 远程连接效率提升:5个你可能不知道的实用技巧
SSH 是后端开发中最常用的远程连接工具之一。但大多数人只用 ssh userhost 连上去就完了,其实 SSH 还有很多隐藏技巧可以大幅提升效率。1. 使用配置文件简化连接每次敲一长串 ssh user192.168.1.100 -p 2222 太麻烦了。只需在 ~/.ssh/config 里加上:Host…...
的使用场景)
Python运算符:成员运算符(in/not in)的使用场景
Python运算符:成员运算符(in/not in)的使用场景📚 本章学习目标:深入理解成员运算符(in/not in)的使用场景的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最…...

洛雪音乐音源:从零到一的音乐聚合解决方案实战指南
洛雪音乐音源:从零到一的音乐聚合解决方案实战指南 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 你是否曾经为了找到一首歌而辗转于多个音乐平台?是否因为音质选择有限而…...

深入理解css-grid-polyfill原理:从源码角度解析实现机制
深入理解css-grid-polyfill原理:从源码角度解析实现机制 【免费下载链接】css-grid-polyfill A working implementation of css grids for current browsers. 项目地址: https://gitcode.com/gh_mirrors/cs/css-grid-polyfill CSS Grid布局是现代Web开发中强…...