GM、BP、LSTM时间预测预测代码
GM
clc; clear; close all;%% 数据加载和预处理
[file, path] = uigetfile('*.xlsx', 'Select the Excel file');
filename = fullfile(path, file);
time_series = xlsread(filename);% 确保数据是一列
time_series = time_series(:);% 归一化数据
min_val = min(time_series);
max_val = max(time_series);
normalized_data = (time_series - min_val) / (max_val - min_val);% 训练/测试集划分
train_ratio = 0.8;
n = length(normalized_data);
M = floor(n * train_ratio);
train_data = normalized_data(1:M);
test_data = normalized_data(M+1:end);%% 构建 GM(1,1) 模型并预测
% 1. 原始序列
X0 = train_data(:); % 确保为列向量% 2. 累加生成序列(AGO)
X1 = cumsum(X0);% 3. 构造数据矩阵并计算参数
B = [-0.5 * (X1(1:end-1) + X1(2:end)), ones(M-1, 1)];
Y = X0(2:end);
U = (B \ Y); % 参数 a 和 ba = U(1); % 模型参数 a
b = U(2); % 模型参数 b% 4. 预测公式
X1_pred = zeros(M, 1);
X1_pred(1) = X0(1); % 初值
for k = 2:MX1_pred(k) = (X0(1) - b/a) * exp(-a * (k-1)) + b/a;
end% 还原到原始序列
X0_pred = [X1_pred(1); diff(X1_pred)];% 对测试集进行预测
N = length(test_data);
X_test_pred = zeros(N, 1);
X_test_pred(1) = X0_pred(end); % 使用最后一个训练值初始化
for k = 2:NX_test_pred(k) = (X_test_pred(1) - b/a) * exp(-a * (M + k - 2)) + b/a;
end%% 反归一化数据
T_train = train_data * (max_val - min_val) + min_val; % 真实训练集
T_test = test_data * (max_val - min_val) + min_val; % 真实测试集
T_train_pred = X0_pred * (max_val - min_val) + min_val; % 训练预测值
T_test_pred = X_test_pred * (max_val - min_val) + min_val; % 测试预测值%% 性能评估
% R² (决定系数)
R1 = 1 - norm(T_train - T_train_pred)^2 / norm(T_train - mean(T_train))^2;
R2 = 1 - norm(T_test - T_test_pred)^2 / norm(T_test - mean(T_test))^2;% MAE (平均绝对误差)
mae1 = mean(abs(T_train - T_train_pred));
mae2 = mean(abs(T_test - T_test_pred));% MAPE (平均相对误差)
mape1 = mean(abs((T_train - T_train_pred) ./ T_train));
mape2 = mean(abs((T_test - T_test_pred) ./ T_test));% MBE (平均偏差误差)
mbe1 = mean(T_train - T_train_pred); % 训练集 MBE
mbe2 = mean(T_test - T_test_pred); % 测试集 MBE% MSE (均方误差)
mse1 = mean((T_train - T_train_pred).^2); % 训练集 MSE
mse2 = mean((T_test - T_test_pred).^2); % 测试集 MSE% 显示性能指标
disp(['训练集 R²: ', num2str(R1)]);
disp(['测试集 R²: ', num2str(R2)]);
disp(['训练集 MAE: ', num2str(mae1)]);
disp(['测试集 MAE: ', num2str(mae2)]);
disp(['训练集 MAPE: ', num2str(mape1)]);
disp(['测试集 MAPE: ', num2str(mape2)]);
disp(['训练集 MBE: ', num2str(mbe1)]);
disp(['测试集 MBE: ', num2str(mbe2)]);
disp(['训练集 MSE: ', num2str(mse1)]);
disp(['测试集 MSE: ', num2str(mse2)]);%% 可视化
% 训练集预测结果
figure;
plot(1:M, T_train, '-', 'LineWidth', 2, 'Color', [0 0 1]); % 真实值(蓝色)
hold on;
plot(1:M, T_train_pred, '--', 'LineWidth', 2, 'Color', [1 0 0]); % 预测值(红色)
legend('True', 'Predicted', 'Location', 'best');
xlabel('Samples');
ylabel('Values');
title('Training Set Prediction');
grid on;% 测试集预测结果
figure;
plot(1:N, T_test, '-', 'LineWidth', 2, 'Color', [0 0 1]); % 真实值(蓝色)
hold on;
plot(1:N, T_test_pred, '--', 'LineWidth', 2, 'Color', [1 0 0]); % 预测值(红色)
legend('True', 'Predicted', 'Location', 'best');
xlabel('Samples');
ylabel('Values');
title('Test Set Prediction');
grid on;disp('GM(1,1) 预测完成!');BP
clc; clear; close all;% Load and preprocess data from Excel
[file, path] = uigetfile('*.xlsx', 'Select the Excel file');
filename = fullfile(path, file);
time_series = xlsread(filename);% Normalize data
min_val = min(time_series);
max_val = max(time_series);
normalized_data = (time_series - min_val) / (max_val - min_val);% Training/Test split
train_ratio = 0.8;
n = length(normalized_data);
M = floor(n * train_ratio);
train_data = normalized_data(1:M);
test_data = normalized_data(M+1:end);% Prepare data for BP network
P_train = train_data(1:end-1)';
T_train = train_data(2:end)';
P_test = test_data(1:end-1)';
T_test = test_data(2:end)';% Create and train BP neural network
net = feedforwardnet(10, 'trainlm'); % 10 hidden neurons
net.trainParam.epochs = 1000;
net.trainParam.goal = 1e-5;% Train the network
net = train(net, P_train, T_train);% Prediction
T_sim1 = net(P_train); % Training set prediction
T_sim2 = net(P_test); % Test set prediction% Denormalize predictions
T_sim1 = T_sim1 * (max_val - min_val) + min_val;
T_sim2 = T_sim2 * (max_val - min_val) + min_val;
T_train = T_train * (max_val - min_val) + min_val;
T_test = T_test * (max_val - min_val) + min_val;% Ensure dimensions match
if size(T_sim1, 1) ~= size(T_train, 1)T_sim1 = T_sim1'; % Ensure T_sim1 is a column vector
endif size(T_sim2, 1) ~= size(T_test, 1)T_sim2 = T_sim2'; % Ensure T_sim2 is a column vector
end%% Compute Metrics% R-squared (R²)
R2_train = 1 - sum((T_train - T_sim1).^2) / sum((T_train - mean(T_train)).^2);
R2_test = 1 - sum((T_test - T_sim2).^2) / sum((T_test - mean(T_test)).^2);% Mean Absolute Error (MAE)
MAE_train = sum(abs(T_train - T_sim1)) / length(T_train);
MAE_test = sum(abs(T_test - T_sim2)) / length(T_test);% Mean Absolute Percentage Error (MAPE)
MAPE_train = mean(abs((T_train - T_sim1) ./ T_train)) * 100;
MAPE_test = mean(abs((T_test - T_sim2) ./ T_test)) * 100;% Mean Bias Error (MBE)
MBE_train = sum(T_sim1 - T_train) / length(T_train);
MBE_test = sum(T_sim2 - T_test) / length(T_test);% Mean Squared Error (MSE)
MSE_train = sum((T_train - T_sim1).^2) / length(T_train);
MSE_test = sum((T_test - T_sim2).^2) / length(T_test);% Display Metrics
disp(['Training Set R²: ', num2str(R2_train)]);
disp(['Test Set R²: ', num2str(R2_test)]);
disp(['Training Set MAE: ', num2str(MAE_train)]);
disp(['Test Set MAE: ', num2str(MAE_test)]);
disp(['Training Set MAPE: ', num2str(MAPE_train), '%']);
disp(['Test Set MAPE: ', num2str(MAPE_test), '%']);
disp(['Training Set MBE: ', num2str(MBE_train)]);
disp(['Test Set MBE: ', num2str(MBE_test)]);
disp(['Training Set MSE: ', num2str(MSE_train)]);
disp(['Test Set MSE: ', num2str(MSE_test)]);%% Generate Plots% Training Set Prediction Plot
figure;
plot(1:length(T_train), T_train, '-', 'LineWidth', 2, 'Color', [0 0 1]); % True values (blue line)
hold on;
plot(1:length(T_train), T_sim1, '--', 'LineWidth', 2, 'Color', [1 0 0]); % Predicted values (red dashed line)
legend('True', 'Predicted', 'Location', 'best');
xlabel('Samples');
ylabel('Values');
title('Training Set Prediction');
grid on;% Test Set Prediction Plot
figure;
plot(1:length(T_test), T_test, '-', 'LineWidth', 2, 'Color', [0 0 1]); % True values (blue line)
hold on;
plot(1:length(T_test), T_sim2, '--', 'LineWidth', 2, 'Color', [1 0 0]); % Predicted values (red dashed line)
legend('True', 'Predicted', 'Location', 'best');
xlabel('Samples');
ylabel('Values');
title('Test Set Prediction');
grid on;disp('Model evaluation completed!');
LSTM
clc; clear; close all;% Load and preprocess data from Excel
[file, path] = uigetfile('*.xlsx', 'Select the Excel file');
filename = fullfile(path, file);
time_series = xlsread(filename);% Normalize data
min_val = min(time_series);
max_val = max(time_series);
normalized_data = (time_series - min_val) / (max_val - min_val);% Training/Test split
train_ratio = 0.8;
n = length(normalized_data);
M = floor(n * train_ratio);
train_data = normalized_data(1:M);
test_data = normalized_data(M+1:end);% Prepare data for LSTM network
X_train = train_data(1:end-1); % Input data for training
Y_train = train_data(2:end); % Target data for training
X_test = test_data(1:end-1); % Input data for testing
Y_test = test_data(2:end); % Target data for testing% Reshape data for LSTM input
X_train = reshape(X_train, [1, length(X_train), 1]); % [features, time_steps, samples]
Y_train = reshape(Y_train, [1, length(Y_train), 1]); % [features, time_steps, samples]
X_test = reshape(X_test, [1, length(X_test), 1]);
Y_test = reshape(Y_test, [1, length(Y_test), 1]);% Define LSTM network architecture
inputSize = 1; % One feature (time series value)
numHiddenUnits = 50; % Number of hidden units in the LSTM layer
outputSize = 1; % Output sizelayers = [sequenceInputLayer(inputSize) % Input layerlstmLayer(numHiddenUnits, 'OutputMode', 'sequence') % LSTM layerfullyConnectedLayer(outputSize) % Fully connected layerregressionLayer % Regression output layer
];% Training options
options = trainingOptions('adam', ...'MaxEpochs', 300, ...'GradientThreshold', 1, ...'InitialLearnRate', 0.01, ...'LearnRateSchedule', 'piecewise', ...'LearnRateDropFactor', 0.2, ...'LearnRateDropPeriod', 150, ...'Verbose', 0, ...'Plots', 'training-progress');% Train the LSTM network
net = trainNetwork(X_train, Y_train, layers, options);% Predict on training and test sets
Y_pred_train = predict(net, X_train, 'MiniBatchSize', 1);
Y_pred_test = predict(net, X_test, 'MiniBatchSize', 1);% Reshape predictions back to 1D
Y_pred_train = squeeze(Y_pred_train);
Y_pred_test = squeeze(Y_pred_test);% Denormalize predictions
Y_pred_train = Y_pred_train * (max_val - min_val) + min_val;
Y_pred_test = Y_pred_test * (max_val - min_val) + min_val;
Y_train = squeeze(Y_train) * (max_val - min_val) + min_val;
Y_test = squeeze(Y_test) * (max_val - min_val) + min_val;%% Compute Metrics% R-squared (R²)
R2_train = 1 - sum((Y_train - Y_pred_train).^2) / sum((Y_train - mean(Y_train)).^2);
R2_test = 1 - sum((Y_test - Y_pred_test).^2) / sum((Y_test - mean(Y_test)).^2);% Mean Absolute Error (MAE)
MAE_train = mean(abs(Y_train - Y_pred_train));
MAE_test = mean(abs(Y_test - Y_pred_test));% Mean Absolute Percentage Error (MAPE)
MAPE_train = mean(abs((Y_train - Y_pred_train) ./ Y_train)) * 100;
MAPE_test = mean(abs((Y_test - Y_pred_test) ./ Y_test)) * 100;% Mean Bias Error (MBE)
MBE_train = mean(Y_pred_train - Y_train);
MBE_test = mean(Y_pred_test - Y_test);% Mean Squared Error (MSE)
MSE_train = mean((Y_train - Y_pred_train).^2);
MSE_test = mean((Y_test - Y_pred_test).^2);% Display Metrics
disp(['Training Set R²: ', num2str(R2_train)]);
disp(['Test Set R²: ', num2str(R2_test)]);
disp(['Training Set MAE: ', num2str(MAE_train)]);
disp(['Test Set MAE: ', num2str(MAE_test)]);
disp(['Training Set MAPE: ', num2str(MAPE_train), '%']);
disp(['Test Set MAPE: ', num2str(MAPE_test), '%']);
disp(['Training Set MBE: ', num2str(MBE_train)]);
disp(['Test Set MBE: ', num2str(MBE_test)]);
disp(['Training Set MSE: ', num2str(MSE_train)]);
disp(['Test Set MSE: ', num2str(MSE_test)]);%% Generate Plots% Training Set Prediction Plot
figure;
plot(1:length(Y_train), Y_train, '-', 'LineWidth', 2, 'Color', [0 0 1]); % True values (blue line)
hold on;
plot(1:length(Y_train), Y_pred_train, '--', 'LineWidth', 2, 'Color', [1 0 0]); % Predicted values (red dashed line)
legend('True', 'Predicted', 'Location', 'best');
xlabel('Samples');
ylabel('Values');
title('Training Set Prediction');
grid on;% Test Set Prediction Plot
figure;
plot(1:length(Y_test), Y_test, '-', 'LineWidth', 2, 'Color', [0 0 1]); % True values (blue line)
hold on;
plot(1:length(Y_test), Y_pred_test, '--', 'LineWidth', 2, 'Color', [1 0 0]); % Predicted values (red dashed line)
legend('True', 'Predicted', 'Location', 'best');
xlabel('Samples');
ylabel('Values');
title('Test Set Prediction');
grid on;disp('LSTM model evaluation completed!');
相关文章:

GM、BP、LSTM时间预测预测代码
GM clc; clear; close all;%% 数据加载和预处理 [file, path] uigetfile(*.xlsx, Select the Excel file); filename fullfile(path, file); time_series xlsread(filename);% 确保数据是一列 time_series time_series(:);% 归一化数据 min_val min(time_series); max_v…...

《操作系统 - 清华大学》4 -5:非连续内存分配:页表一反向页表
文章目录 1. 大地址空间的问题2. 页寄存器( Page Registers )方案3. 基于关联内存(associative memory )的反向页表(inverted page table)4. 基于哈希(hashed)查找的反向页表5. 小结 1. 大地址空间的问题 …...

志愿者小程序源码社区网格志愿者服务小程序php
志愿者服务小程序源码开发方案:开发语言后端php,tp框架,前端是uniapp。 一 志愿者端-小程序: 申请成为志愿者,志愿者组织端进行审核。成为志愿者后,可以报名参加志愿者活动。 志愿者地图:可以…...

Java语言编程,通过阿里云mongo数据库监控实现数据库的连接池优化
一、背景 线上程序连接mongos超时,mongo监控显示连接数已使用100%。 java程序报错信息: org.mongodb.driver.connection: Closed connection [connectionId{localValue:1480}] to 192.168.10.16:3717 because there was a socket exception raised by…...

使用ufw配置防火墙,允许特定范围IP访问
文章目录 1. 安装 UFW(如果尚未安装)2. 允许特定 IP 地址访问 22 端口3. 允许特定子网访问 22 端口4. 启用 UFW5. 检查 UFW 状态6. 重新加载 UFW(如果需要)7. 删除规则(如果需要) 在ubuntu上使用 ufw&#…...

实现 UniApp 右上角按钮“扫一扫”功能实战教学
实现 UniApp 右上角按钮“扫一扫”功能实战教学 需求 点击右上角扫一扫按钮(onNavigationBarButtonTap监听),打开扫一扫页面(uni.scanCode) 扫描后,以网页的形式打开扫描内容(web-view组件),限制只能浏览带有执行域名的网站,例如…...

【2024亚太杯亚太赛APMCM C题】数学建模竞赛|宠物行业及相关产业的发展分析与策略|建模过程+完整代码论文全解全析
第一个问题是:请基于附件 1 中的数据以及你的团队收集的额外数据,分析过去五年中国宠物行业按宠物类型的发展情况。并分析中国宠物行业发展的因素,预测未来三年中国宠物行业的发展。 第一个问题:分析中国宠物行业按宠物类型的发展…...

ubtil循环函数调用
什么是until until循环是一种控制流结构。它与while循环相反,while循环是在条件为真时执行循环体,而until循环是在条件为假时执行循环体,直到条件为真时才停止循环。 until代码示例: i0 do until [ ! $i -lt 10 ] echo $…...

使用EFK收集k8s日志
首先我们使用EFK收集Kubernetes集群中的日志,本次实验讲解的是在Kubernetes集群中启动一个Elasticsearch集群,如果企业内已经有了Elasticsearch集群,可以直接将日志输出至已有的Elasticsearch集群。 文章目录 部署elasticsearch创建Kibana创建…...
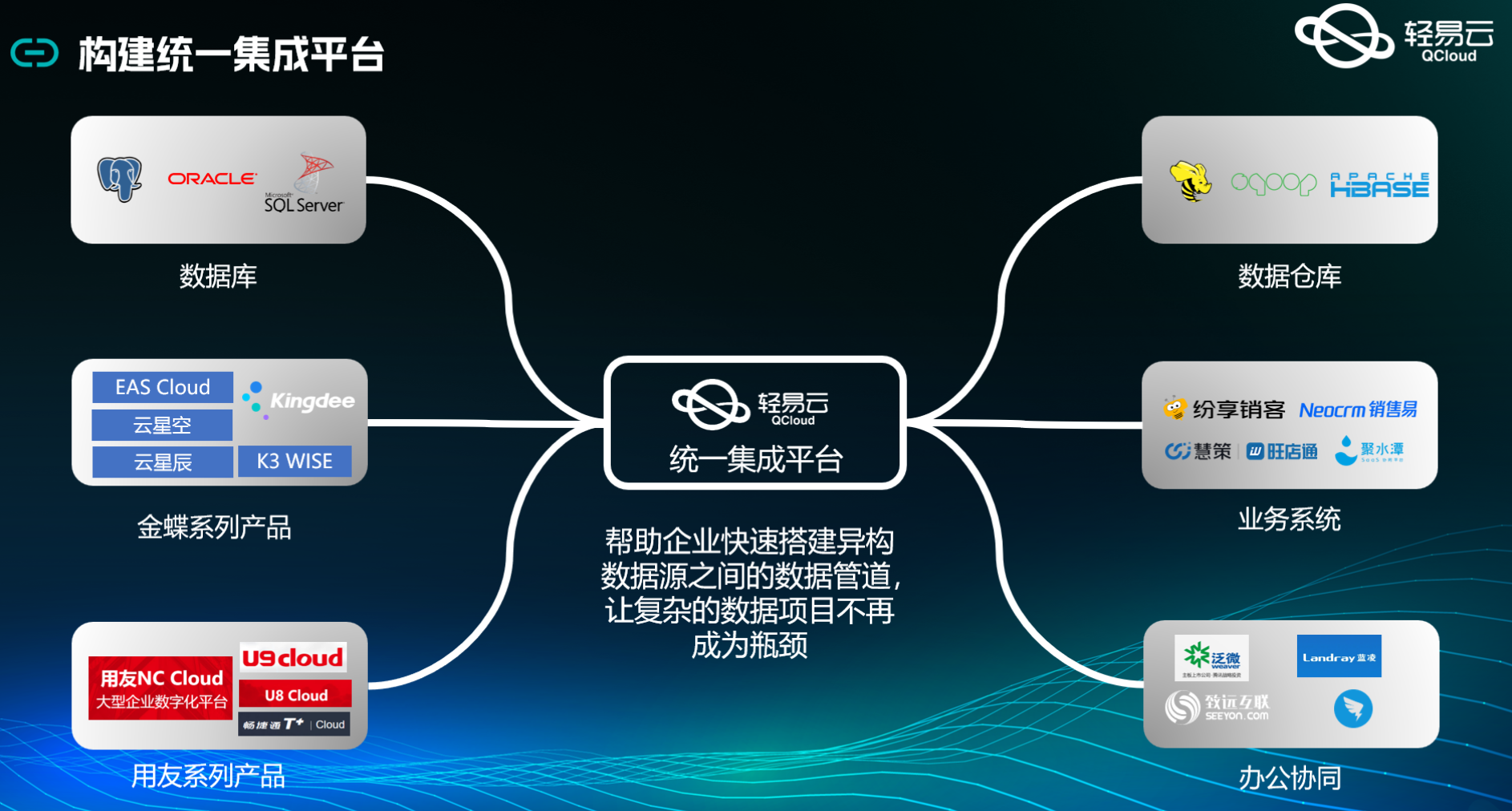
聚水潭与MySQL数据集成案例分享
聚水潭数据集成到MySQL的技术案例分享 在现代数据驱动的业务环境中,如何高效、可靠地实现不同系统之间的数据对接成为企业关注的焦点。本次案例将详细介绍如何通过轻易云数据集成平台,将聚水潭的数据无缝集成到MySQL数据库中,实现从“聚水谭…...

Python 版本的 2024详细代码
2048游戏的Python实现 概述: 2048是一款流行的单人益智游戏,玩家通过滑动数字瓷砖来合并相同的数字,目标是合成2048这个数字。本文将介绍如何使用Python和Pygame库实现2048游戏的基本功能,包括游戏逻辑、界面绘制和用户交互。 主…...

SpringCloud框架学习(第四部分:Gateway网关)
目录 十一、Gateway新一代网关 1.概述 2.Gateway三大核心 3.工作流程 4.入门配置 5.路由映射 (1)8001 外部添加网关 (2)服务间调用添加网关 (3)存在问题 6.Gateway高级特性 (1&#x…...
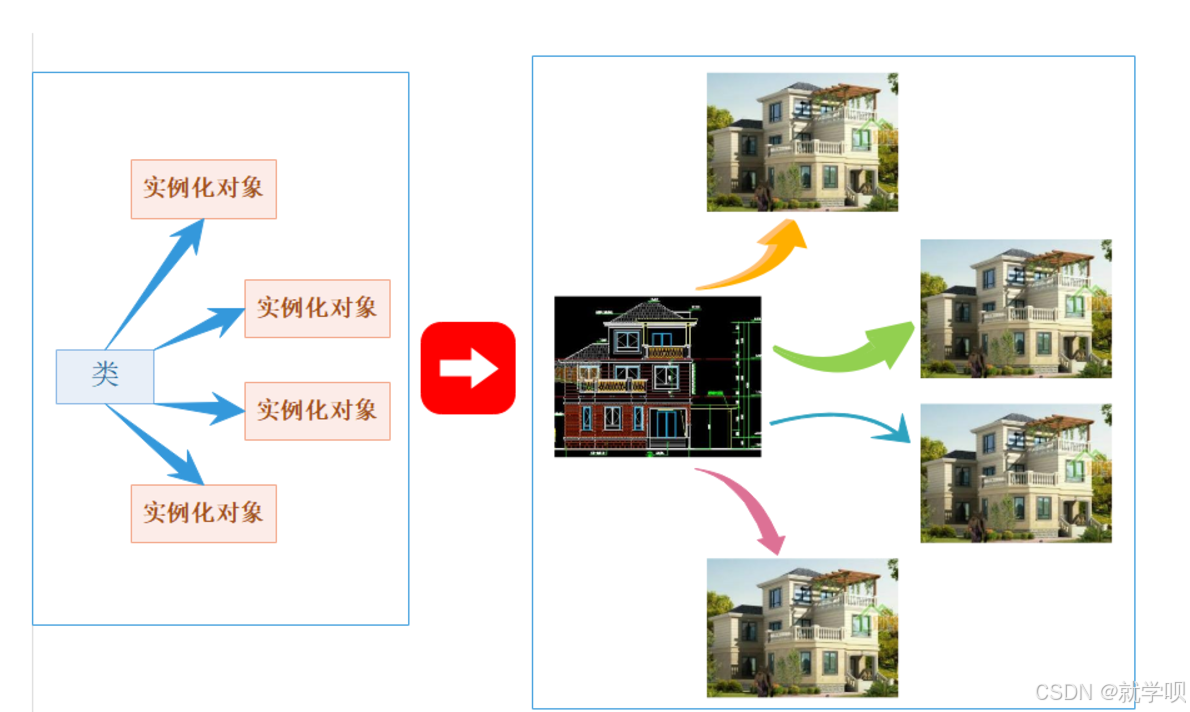
C++ 类和对象 (上 )
学习本身就是一件很快乐的事情 一. 面向对象和面向过程 我们在学习计算机的过程中经常会听到xxx是一门面向对象的语言 xxx是一门面向过程的语言 那么到底什么是面向对象 什么是面向过程呢? 简单介绍下 面向过程 面向过程关注的是过程 分析出求解问题的步骤&…...
)
HAProxy面试题及参考答案(精选80道面试题)
目录 什么是 HAProxy? HAProxy 主要有哪些功能? HAProxy 的关键特性有哪些? HAProxy 的主要功能是什么? HAProxy 的作用是什么? 解释 HAProxy 在网络架构中的作用。 HAProxy 与负载均衡器之间的关系是什么? HAProxy 是如何实现负载均衡的? 阐述 HAProxy 的四层…...
探索PyCaret:一个简化机器学习的全栈库
探索PyCaret:一个简化机器学习的全栈库 机器学习领域充满了挑战,从数据预处理、特征工程到模型训练与评估,再到模型部署。对于数据科学初学者或者时间有限的开发者,这一流程可能显得繁琐且复杂。幸运的是,PyCaret 提供…...

英语写作中“联系、关联”associate correlate 及associated的用法
似乎是同义词的associate correlate 实际上意思差别明显,associate 是人们把两者联系在一起(主观联系),而correlate 指客观联系。 例如: We always associate sports with health.(我们总是将运动和健康联…...

深度学习之目标检测的技巧汇总
1 Data Augmentation 介绍一篇发表在Big Data上的数据增强相关的文献综述。 Introduction 数据增强与过拟合 验证是否过拟合的方法:画出loss曲线,如果训练集loss持续减小但是验证集loss增大,就说明是过拟合了。 数据增强目的 通过数据增强…...
【Flask+Gunicorn+Nginx】部署目标检测模型API完整解决方案
【Ubuntu 22.04FlaskGunicornNginx】部署目标检测模型API完整解决方案 文章目录 1. 搭建深度学习环境1.1 下载Anaconda1.2 打包环境1.3 创建虚拟环境1.4 报错 2. 安装flask3. 安装gunicorn4. 安装Nginx4.1 安装前置依赖4.2 安装nginx4.3 常用命令 5. NginxGunicornFlask5.1 ng…...

Spark核心组件解析:Executor、RDD与缓存优化
Spark核心组件解析:Executor、RDD与缓存优化 Spark Executor Executor 是 Spark 中用于执行任务(task)的执行单元,运行在 worker 上,但并不等同于 worker。实际上,Executor 是一组计算资源(如…...

“AI玩手机”原理揭秘:大模型驱动的移动端GUI智能体
作者|郭源 前言 在后LLM时代,随着大语言模型和多模态大模型技术的日益成熟,AI技术的实际应用及其社会价值愈发受到重视。AI智能体(AI Agent)技术通过集成行为规划、记忆存储、工具调用等机制,为大模型装上…...

2026年了,还在为电力负荷预测发愁?基于XGBoost的多变量单步预测全栈实战!
大家好,我是你们的技术伙伴。👋在2026年的今天,随着“双碳”目标的推进,智能电网和能源互联网成为了技术的热点。而这一切的基础,就是精准的电力负荷预测。很多初学者觉得负荷预测很难,觉得需要复杂的深度学…...

小学期学习——第二周
一、本周学习视频6-7学习了单电源供电的二阶低通滤波器以及电子计数法,并对仿真进行了改进。二、绘制了PCB原理图学习使用嘉立创EDA,并且绘制了PCB原理图。...

从集合运算到代码:一文搞懂Jaccard系数,附Python/NumPy/Pandas三种实现方法对比
从集合运算到代码:一文搞懂Jaccard系数,附Python/NumPy/Pandas三种实现方法对比在数据挖掘和机器学习领域,衡量两个集合的相似度是一项基础而重要的任务。Jaccard相似系数作为一种简单直观的度量方法,广泛应用于推荐系统、文本挖掘…...

【SpringBoot+Elasticsearch 内容搜索系统实战】:架构设计与全流程实现
🔥你好我是fengxin_rou这是我的个人主页fengxin_rou的主页 ❄️欢迎查看我的专栏我的专栏 《Java后端学习》、《JAVASE基础》、《JUC并发》、《redis》、《JVM虚拟机》、《MYSQL》、《黑马点评》、《rabbitmq》、《JavaWebAI的talis学习系统》、《苍穹外卖》 目录…...

Qwen模型 LeetCode 2603. 收集树中金币 Java实现
哎呀,这道题我可太熟啦!2603. 收集树中金币,看着挺复杂的,其实想通了就特别有意思~让我跟你聊聊我的思路~这题本质上是个树形DP问题,我们需要在无向树上进行两次遍历。先说说我的理解哈…...

LangGraph 状态存储优化:处理大规模多智能体数据的高效方案
LangGraph 状态存储优化:处理大规模多智能体数据的高效方案 本文面向有LangGraph开发经验、需要落地大规模多智能体应用的开发者,从底层原理、架构设计到代码实现全方位讲解如何将LangGraph状态存储的性能提升10倍、成本降低80%,支撑10万+级多智能体并发运行。 引言 痛点引…...

Go语言ORM框架GORM深度解析
Go语言ORM框架GORM深度解析 引言 GORM是Go语言中最流行的ORM(对象关系映射)框架,提供了强大的数据访问能力和优雅的API设计。本文将深入探讨GORM的核心功能、高级特性和最佳实践。 一、环境配置 1.1 安装GORM go get gorm.io/gorm go get gor…...

2026保姆级免费照片去水印教程:不用下载App,微信小程序3步搞定!
你是不是也遇到过这种崩溃瞬间?刷到一张绝美壁纸想存下来当背景,结果水印刚好挡住主角的脸;看到一段搞笑视频想转发给朋友,结果水印横在中间像个挡箭牌;想拿一张素材做作业PPT,结果水印比内容还显眼。更烦的…...

UnrealPakViewer:虚幻引擎Pak文件分析终极可视化工具
UnrealPakViewer:虚幻引擎Pak文件分析终极可视化工具 【免费下载链接】UnrealPakViewer 查看 UE4 Pak 文件的图形化工具,支持 UE4 pak/ucas 文件 项目地址: https://gitcode.com/gh_mirrors/un/UnrealPakViewer UnrealPakViewer是一款专业的开源工…...
)
Python算法基础篇之深度优先搜索(DFS)
一、什么是深度优先搜索(DFS)? 深度优先搜索(Depth-First Search, DFS) 是一种用于遍历或搜索图、树的算法。其核心策略是:从起始节点出发,沿着一条路径尽可能深入地探索,直到无法继…...