探索PDFMiner:Python中的PDF解析利器
文章目录
- **探索PDFMiner:Python中的PDF解析利器**
- 1. 背景介绍:为何选择PDFMiner?
- 2. PDFMiner是什么?
- 3. 如何安装PDFMiner?
- 4. 简单库函数使用方法
- 4.1 提取文本
- 4.2 获取页面布局信息
- 4.3 提取表格数据
- 4.4 提取图像
- 5. 应用场景示例
- 5.1 文本数据提取
- 5.2 数据转换
- 5.3 元数据提取
- 6. 常见Bug及解决方案
- 6.1 环境配置问题
- 6.2 文本提取位置不准确
- 6.3 编码问题导致的乱码
- 7. 总结

探索PDFMiner:Python中的PDF解析利器
1. 背景介绍:为何选择PDFMiner?
在数字化时代,PDF文件因其便携性和广泛兼容性成为文档交换的标准格式。然而,从PDF中提取有用信息一直是个挑战。PDFMiner库应运而生,专门解决这一问题。它不仅能提取文本,还能获取字体信息、页面布局、表格、图片以及文档元数据。
2. PDFMiner是什么?
PDFMiner是一个强大的Python库,用于解析PDF文档并提取其中的文本内容和数据。它支持文本提取、字体信息获取、页面布局分析、表格解析、图像提取以及文档元数据获取等功能。
3. 如何安装PDFMiner?
安装PDFMiner非常简单,只需在命令行中输入以下命令:
pip install pdfminer.six
这条命令会安装PDFMiner的Python 3版本,兼容Python 2和Python 3。
4. 简单库函数使用方法
4.1 提取文本
from pdfminer.high_level import extract_text
text = extract_text("example.pdf")
print(text)
这段代码使用extract_text函数从PDF文件中提取全部文本。
4.2 获取页面布局信息
from pdfminer.layout import LAParams, LTTextBox, LTTextLine
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregatorresource_manager = PDFResourceManager()
fake_file_handle = io.StringIO()
converter = PDFPageAggregator(resource_manager, fake_file_handle, laparams=LAParams())
page_interpreter = PDFPageInterpreter(resource_manager, converter)with open("example.pdf", "rb") as pdf_file:for page in PDFPage.get_pages(pdf_file):page_interpreter.process_page(page)layout = converter.get_result()for lt_obj in layout:if isinstance(lt_obj, (LTTextBox, LTTextLine)):text = lt_obj.get_text()x, y, width, height = lt_obj.bboxfont = lt_obj._objs[0].fontnamefont_size = lt_obj._objs[0].sizeprint(f"Text: {text.strip()}, Position: ({x:.2f}, {y:.2f}), Font: {font}, Size: {font_size:.2f}")
这段代码获取文本块的位置、字体和字号等信息,并将其打印出来。
4.3 提取表格数据
from pdfminer.high_level import extract_text
import tabulatable_text = extract_text("table_example.pdf")
print(table_text)tables = tabula.read_pdf("table_example.pdf", pages="all")
for df in tables:print(df)
这段代码使用PDFMiner提取PDF文档中的表格,并使用tabula提取表格数据。
4.4 提取图像
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdftypes import PDFStream
import io
from PIL import Imagewith open('example.pdf', 'rb') as file:parser = PDFParser(file)document = PDFDocument(parser)if document.is_extractable:for xref in document.xrefs:if xref.get_subtype() == '/Image':stream_obj = xref.get_object()if isinstance(stream_obj, PDFStream):data = stream_obj.get_rawdata()image = Image.open(io.BytesIO(data))image.show()
这段代码提取PDF文档中的图像。
5. 应用场景示例
5.1 文本数据提取
从大量PDF文档中提取文本内容,以进行文本挖掘、自然语言处理或搜索。
5.2 数据转换
将PDF文档中的表格数据转换为结构化数据,以进一步分析或导入到数据库中。
5.3 元数据提取
获取PDF文档的元数据信息,如作者、标题、创建日期,以进行文档管理或分类。
6. 常见Bug及解决方案
6.1 环境配置问题
错误信息:ModuleNotFoundError: No module named 'pdfminer'
解决方案:确保使用正确的命令安装PDFMiner,pip install pdfminer.six。
6.2 文本提取位置不准确
错误信息:文本提取后位置信息不准确或丢失。
解决方案:调整LAParams参数,优化布局分析的精度。
6.3 编码问题导致的乱码
错误信息:非ASCII字符显示为乱码。
解决方案:指定正确的编码,例如使用codec='utf-8'参数。
7. 总结
PDFMiner是一个强大的工具,用于解析和提取PDF文档的文本内容和数据。无论是进行文本分析、数据提取还是自动化处理,PDFMiner都能够满足需求。希望本文能够帮助大家更好地理解PDFMiner的基本概念和使用方法,以便在实际工作中充分利用这个库。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!

相关文章:
探索PDFMiner:Python中的PDF解析利器
文章目录 **探索PDFMiner:Python中的PDF解析利器**1. 背景介绍:为何选择PDFMiner?2. PDFMiner是什么?3. 如何安装PDFMiner?4. 简单库函数使用方法4.1 提取文本4.2 获取页面布局信息4.3 提取表格数据4.4 提取图像 5. 应…...

掌握Go语言中的异常控制:panic、recover和defer的深度解析
掌握Go语言中的异常控制:panic、recover和defer的深度解析 在Go语言的编程世界中,异常处理是一个不可忽视的话题。Go语言提供了panic、recover和defer三个关键字来处理程序中的异常情况。本文将深入探讨这三个关键字的工作原理、使用场景和最佳实践,帮助读者在实际编程中更…...

云讷科技Kerloud无人飞车专利发布
云讷科技Kerloud无人飞车获得了“一种室内外两用的四旋翼无人飞车”的实用新型专利证书,作为科教社区第一款四旋翼飞车,这项技术结合了无人机和无人车的优势,提供了一种能够在多种环境下使用的多功能飞行器。 这项设计的优势如下ÿ…...

企业信息化-走进身份管理之搭建篇
一、身份管理是什么 我们先要弄懂统一身份管理到底是什么? 统一身份管理(Unified Identity Manager,UIM),身份管理(Identity Management,简称IDM),也被称为IAM&#…...
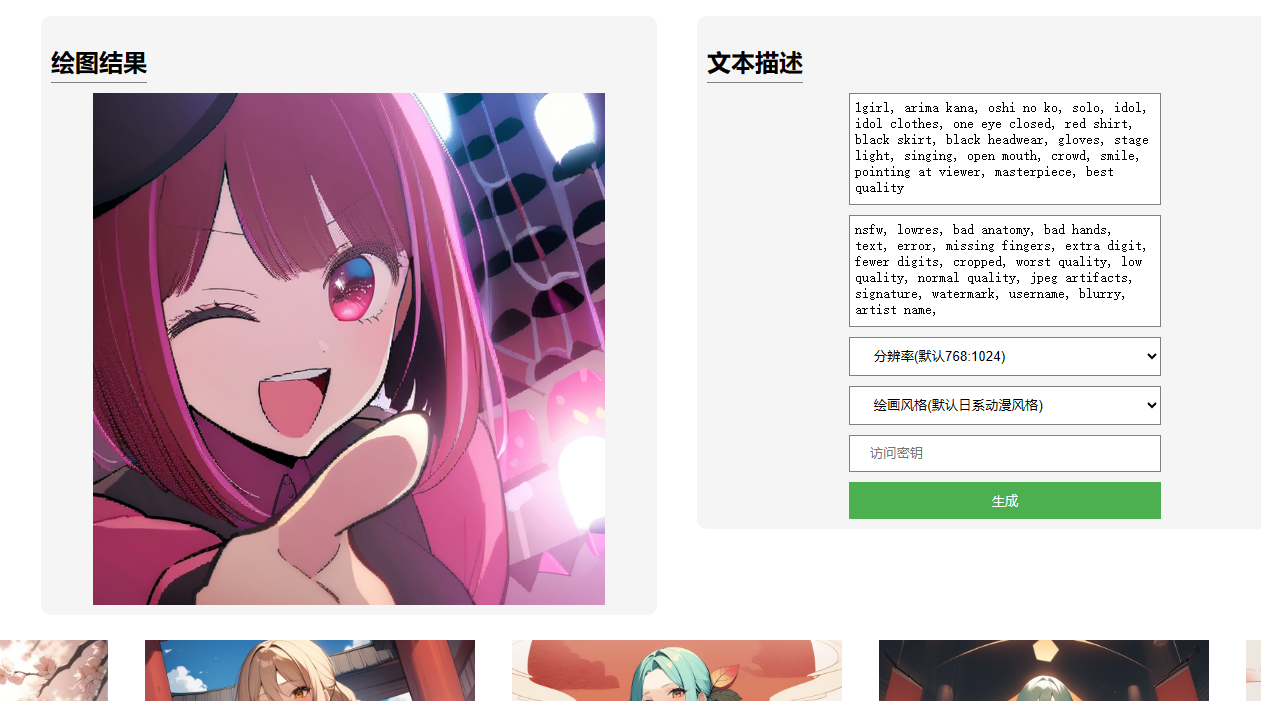
实践指南:EdgeOne与HAI的梦幻联动
在当今快速发展的数字时代,安全和速度已成为网络服务的基石。EdgeOne,作为腾讯云提供的边缘安全加速平台,以其全球部署的节点和强大的安全防护功能,为用户提供了稳定而高效的网络体验。而HAI(HyperApplicationInventor…...

Exploring Prompt Engineering: A Systematic Review with SWOT Analysis
文章目录 题目摘要简介方法论背景相关工作评估结论 题目 探索快速工程:基于 SWOT 分析的系统评价 论文地址: https://arxiv.org/abs/2410.12843 摘要 在本文中,我们对大型语言模型 (LLM) 领域的提示工程技术进行了全面的 SWOT 分析。我们强…...

ByteBuffer 与 ByteBuf 的对比与优缺点分析
在 Java 网络编程和高性能 I/O 场景中,ByteBuffer 和 ByteBuf 是两种重要的缓冲区处理工具。ByteBuffer 是 Java NIO 标准库的一部分,而 ByteBuf 是由 Netty 框架提供的增强缓冲区工具。在实际开发中,选择哪一种取决于场景需求和性能目标。 …...
js高级06-ajax封装和跨域
8.1、ajax简介及相关知识 8.1.1、原生ajax 8.1.1.1、AJAX 简介 AJAX 全称为 Asynchronous JavaScript And XML,就是异步的 JS 和 XML。 通过 AJAX 可以在浏览器中向服务器发送异步请求,最大的优势:无刷新获取数据。 按需请求,可…...

RabbitMQ3:Java客户端快速入门
欢迎来到“雪碧聊技术”CSDN博客! 在这里,您将踏入一个专注于Java开发技术的知识殿堂。无论您是Java编程的初学者,还是具有一定经验的开发者,相信我的博客都能为您提供宝贵的学习资源和实用技巧。作为您的技术向导,我将…...

D 型 GaN HEMT 在功率转换方面的优势
氮化镓 (GaN) 是一种 III-V 族宽带隙半导体,由于在用作横向高电子迁移率晶体管 (HEMT) 时具有卓越的材料和器件性能,因此在功率转换应用中得到越来越多的采用。 HEMT 中产生的高击穿电场 (3.3 MV/cm) 和高二维电子气 (2DEG) 载流子迁移率 (2,000 cm 2 /…...

Java Web后端项目的特点和组成部分
技术栈 #### Java Web技术: - **Servlet**:Java Web的核心,用于处理HTTP请求。 - **WebServlet注解配置**:用于简化Servlet的配置。 - **HttpServlet基类**:大多数Servlet都继承自此基类。 - **请求响应处理**&#x…...

Vue3 + Vite + TS 项目引入 Eslint + Pritter
文章目录 一、ESLint 简介主要功能适用场景常用的 Eslint 配置项 二、Pritter 简介主要功能适用场景常用的 Prettier 配置项 三、Vue3 Vite TS 项目引入 Eslint Pritter1. 安装 ESLint2. 初始化 ESLint 配置3. 在 Vite 项目中启用 ESLint4. 在 VS Code 中启用 ESLint5. 集成…...

用Tauri框架构建跨平台桌面应用:1、Tauri快速开始
Tauri 是一个构建适用于所有主流桌面和移动平台的轻快二进制文件的框架。开发者们可以集成任何用于创建用户界面的可以被编译成 HTML、JavaScript 和 CSS 的前端框架,同时可以在必要时使用 Rust、Swift 和 Kotlin 等语言编写后端逻辑。 Tauri 是什么? |…...

Django实现智能问答助手-数据库方式读取问题和答案
扩展 增加问答数据库,通过 Django Admin 添加问题和答案。实现更复杂的问答逻辑,比如使用自然语言处理(NLP)库。使用前端框架(如 Bootstrap)增强用户界面 1.注册模型到 Django Admin(admin.py…...

stm32利用LED配置基础寄存器+体验滴答定时器+hal库环境配置
P1 LED控制与流水灯效果实现 概述 大家好,今天我们来学习一下如何在STM32上控制LED灯,并且实现一个流水灯的效果。这不仅是一个基础的实践,也是嵌入式开发中非常常见的需求。 LED控制 1. LED初始化 首先,我们需要对LED灯对应…...

JAVA开源项目 桂林旅游景点导游平台 计算机毕业设计
博主说明:本文项目编号 T 079 ,文末自助获取源码 \color{red}{T079,文末自助获取源码} T079,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析…...

docker安装使用Elasticsearch,解决启动后无法访问9200问题
1.docker安装、启动es docker pull elasticsearch:8.13.0docker images启动容器 docker run -d -p 9200:9200 -p 9300:9300 -e ES_JAVA_OPTS"-Xms256m -Xmx256m" --name es01 8ebd258614f1-d 后台运行-p 9200:9200 -p 9300:9300 开放与主机映射端口-e ES_JAVA_OPTS…...

GM、BP、LSTM时间预测预测代码
GM clc; clear; close all;%% 数据加载和预处理 [file, path] uigetfile(*.xlsx, Select the Excel file); filename fullfile(path, file); time_series xlsread(filename);% 确保数据是一列 time_series time_series(:);% 归一化数据 min_val min(time_series); max_v…...

《操作系统 - 清华大学》4 -5:非连续内存分配:页表一反向页表
文章目录 1. 大地址空间的问题2. 页寄存器( Page Registers )方案3. 基于关联内存(associative memory )的反向页表(inverted page table)4. 基于哈希(hashed)查找的反向页表5. 小结 1. 大地址空间的问题 …...

志愿者小程序源码社区网格志愿者服务小程序php
志愿者服务小程序源码开发方案:开发语言后端php,tp框架,前端是uniapp。 一 志愿者端-小程序: 申请成为志愿者,志愿者组织端进行审核。成为志愿者后,可以报名参加志愿者活动。 志愿者地图:可以…...

ARM SME指令集:SQCVT与SQRSHR深度解析与应用
1. ARM SME指令集概述在当今处理器架构设计中,向量化计算已成为提升性能的关键技术。作为ARMv9架构的重要扩展,可扩展矩阵扩展(Scalable Matrix Extension,SME)指令集引入了多项创新特性,其中FEAT_SME2扩展…...

实战精通openpilot自动驾驶系统:从安装到深度定制的完整指南
实战精通openpilot自动驾驶系统:从安装到深度定制的完整指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_T…...

给客户打电话经常被挂?电话号码企业认证来帮忙
忙碌的销售部门里,电话铃声此起彼伏,但回应往往是沉默。销售员小张今天拨出了150个电话,其中有120个被直接挂断,剩下的30个里,有一半在听到自我介绍的一瞬间就收到了“嘟嘟”的忙音。这种困境不是个案。在防骚扰软件普…...
)
在CentOS7服务器上装Win10?手把手教你用Ventoy搞定双系统(附网卡驱动安装避坑指南)
在CentOS7服务器上实现Win10双系统:Ventoy实战与驱动避坑指南 当Linux服务器遇上Windows需求,双系统成为了一种优雅的解决方案。本文将带你深入探索在CentOS7生产环境中部署Win10双系统的完整流程,特别针对服务器硬件特性提供定制化指导。 …...

Unity UI实战:Input Field输入框从入门到精通,搞定用户交互与数据获取
Unity UI实战:Input Field输入框从入门到精通,搞定用户交互与数据获取在游戏和应用开发中,用户输入是不可或缺的交互环节。无论是简单的登录界面、复杂的设置面板,还是实时聊天系统,Input Field都是连接用户与程序的关…...
)
GCN vs MLP:在Cora数据集上,图神经网络到底强在哪?(附可视化对比)
GCN与MLP在Cora数据集上的本质差异:从特征聚合到空间重构的认知升级当我们面对学术文献分类任务时,传统机器学习方法往往将每篇文献视为独立个体进行处理。这种处理方式在Cora数据集上通常只能获得约50%的分类准确率,而图卷积网络(GCN)却能轻…...

李白的思乡诗 / 山水诗 / 豪放诗有哪些?诗词在线app手工整理
"酒入豪肠,七分酿成了月光,余下的三分啸成剑气,绣口一吐就半个盛唐。" 李白的诗,是盛唐最耀眼的星,既有 "天生我材必有用" 的豪放,也有 "低头思故乡" 的柔情,更有…...

小学期学习——第二周
一、本周学习视频6-7学习了单电源供电的二阶低通滤波器以及电子计数法,并对仿真进行了改进。二、绘制了PCB原理图学习使用嘉立创EDA,并且绘制了PCB原理图。...

构建高效的 Agent 任务队列
构建高效Agent任务队列:从第一性原理到生产级落地全指南 关键词 Agent任务队列、多智能体调度、优先级抢占、延迟敏感任务、分布式一致性、负载均衡、容错机制 摘要 随着大模型驱动的多Agent系统在企业服务、具身智能、自动驾驶等领域的规模化落地,传统消息队列与批处理调…...

BetterGI:解放双手的5大自动化场景终极解决方案
BetterGI:解放双手的5大自动化场景终极解决方案 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连音游 | 自动烹饪…...