卷积神经网络(CNN)中的批量归一化层(Batch Normalization Layer)
批量归一化层(BatchNorm层),或简称为批量归一化(Batch Normalization),是深度学习中常用的一种技术,旨在加速神经网络的训练并提高收敛速度。
一、基本思想
为了让数据在训练过程中保持同一分布,在神经网络的中间层(隐藏层)的一层或多层上进行批量归一化。对于每一个小批次数据(mini-batch),计算该batch的均值与方差,在将线性计算结果送入激活函数之前,先对计算结果进行批量归一化处理,即减均值、除标准差,保证计算结果符合均值为0、方差为1的标准正态分布,然后再将计算结果作为激活函数的输入值进行计算。这样可以使得网络中间层的输入保持相对稳定,有助于解决训练过程中的梯度消失或梯度爆炸问题。
批量归一化的本质:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的标准正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域。
一般而言,将数据转化为均值为0、方差为1的分布这一过程被称为标准化(Standardization),而归一化(Normalization)一般指的是将一列数据变化到某个固定区间(范围)中。
二、了解几个概念
1. 批次(batch)
神经网络处理数据,不是一个数据一个数据的处理,而是一次输入很大一个批次,比如99张图片,输入之后,再划分很多个批次,一次处理一个批次。

图1 神经网络中多批次数据输入
2. 均值与方差
在训练过程中,分批次训练,划分batch和batch_size,计算每一个批次(batch)的对应位置的均值和方差。如计算一个批次中所有图片的每一个位置的元素的均值与方差,一张图片有多少个元素,就有多少个均值与方差。最后得到的均值和方差是用向量的形式表现的。

图2 小批次中的计算机过程
例:一个batch有3个输入,每个输入是一个长度为4的向量

图3 归一化的均值计算
三、若干归一化要解决的问题
为什么要进行批量归一化,主要是在神经网络训练过程中,存在以下问题:
1. 协变量偏移
在机器学习中,一般假设模型输入数据的分布是稳定的,若是模型输入数据的分布发生变化,这种现象被称为协变量偏移(covariate shift);模型的训练集和测试集的分布不一致,也属于协变量偏移现象;同理,在一个复杂的机器学习系统中,也会要求系统的各个子模块在训练过程中输入分布是稳定的,若是不满足,则称为内部协变量偏移(internal covariate shift,ICS)。

图4 训练集和测试集的分布不一致导致的协变量偏移问题
2. 梯度消失问题
经过神经网络中多层的变换,很可能使得后面层的输入数据变得过大或过小,从而掉进激活函数(例如Sigmoid、Tanh)的饱和区。

图5 Sigmoid函数存在梯度消失问题
饱和区的梯度随x的变化y的变化很不明显,即会产生梯度消失问题,进而导致学习过程停止。为防止这个问题,我们希望,数据落入激活函数中间的非饱和区。为了降低内部协变量偏移所带来的负面影响,在训练过程中一般会采用非饱和型激活函数(ReLU)、精细的网络参数初始化,保守的学习率,但这不仅会使得网络的学习速度太慢,还会使得最终效果特别依赖于网络的初始化。
3. 梯度爆炸问题
梯度爆炸(Gradient Explosion)指的是在反向传播过程中,梯度值变得非常大,超出了网络的处理范围,从而导致权重更新变得不稳定甚至不收敛的现象。

图6 梯度爆炸问题
4. 过拟合问题
四、归一化的数学表达
对全连接层做批量归一化时。通常将批量归一化层置于全连接层中的仿射变换和激活函数之间。设全连接层的输入为u,权重参数和偏差参数分别为W和b,则批量归一化输入必由仿射变换x=Wu+b得到。

图7 全连接层结构
激活函数(sigmoid)为,设批量归一化的运算符为BN。那么,使用批量归一化的全连接层的输出为
。u是由多个小批量batch组成,其中一个batch由m个样本组成,仿射变换的输出为一个新的batch
,
正是批量归一化层的输入,中任意样本
,批量归一化层的输出
同样是d维向量。

归一化层的输出由以下几步求得。
1. 求小批量的均值
和方差
。

其中的平方计算是按元素求平方。
2. 标准化和归一化。
(1)标准化。使用按元素开方和按元素除法的方法对进行标准化。

这里是一个很小的常数,保证分母大于0。
(2)归一化。在上面标准化的基础上,批量归一化层引入了两个可以学习的模型参数,缩放(scale)参数和偏移(shift)参数
。这两个参数和
形状相同,皆为d维向量。
3. 计算批量归一化层的输出,参数
和参数
与
分别做按元素乘法(符号⊙)和加法计算:

至此,我们得到了的批量归一化的输出
。
注意:当和
,可学习的拉伸和偏移两个参数对归一化操作无益,即学出的模型可以不使用批量归一化。
五、工作流程
批量归一化可以看作是在每一层输入和上一层输出之间加入了一个新的计算层,对数据的分布进行额外的约束,来解决以上问题。
在训练过程中,批量归一化会对每个神经元(卷积核中的一个通道)的激活输入进行如下变换,具体实现步骤如下:
- 计算批量均值与方差:对于给定的小批量数据,计算其特征的均值与方差。
- 归一化:使用计算出的均值和方差对小批量数据中的每个特征进行归一化处理,确保输出的均值接近0,方差接近1。
- 缩放与偏移:引入缩放因子(γ)和偏移因子(β)两个可学习的参数,这两个参数是在训练过程中学习得到的,归一化后的数据会通过这两个参数进行缩放和偏移,允许模型恢复可能被归一化操作去除的有用特征。
其算法流程如图所示:

图8 归一化算法流程
在模型推理或测试时,均值和方差不再针对每个小批量实时计算,而是使用整个训练集的移动平均值。
六、作用与优势
1. 加速训练收敛:通过减小内部协变量偏移(Internal Covariate Shift),使得输入分布更加稳定,从而可以使用更高的学习率,加速训练收敛速度,减少训练时间,加速神经网络的训练过程。
2. 提高稳定性:批量归一化有助于控制梯度的变化范围,防止梯度爆炸或消失,从而提高训练的稳定性。
3. 提高模型性能:稳定的输入数据分布有助于模型学习到更加鲁棒的特征表示,从而提高模型的性能。
4. 减少过拟合:BatchNorm层也可以被看作一种正则化方法,因为它可以减少模型的过拟合风险。
5. 减少对权重初始化的依赖和敏感性:使得网络对权重初始化的依赖减小,简化了超参数的选择。即使初始化不是最优的,模型也能较好地收敛。
七、注意事项
在使用BatchNorm层时,需要注意选择合适的小批量大小(Batch Size),过小或过大的小批量都可能影响BatchNorm层的效果。BatchNorm层通常位于卷积层或全连接层之后,激活函数之前。但也有一些变种将BatchNorm层放在激活函数之后。在训练过程中,BatchNorm层会维护均值和方差的指数移动平均,以供推理阶段使用。因此,在训练结束后,需要保存这些移动平均值作为模型的一部分。
八、应用场景
批量归一化在神经网络中广泛应用,特别是在卷积神经网络(CNN)和全连接网络(FCN)中。当神经网络各层的输入数据分布发生变化时,例如训练过程中每个批次的数据分布不一致,这种情况下适合使用批量归一化来稳定网络的训练。
而在深度学习框架中,BatchNorm层通常作为一层(如BatchNorm层)来实现,可以轻松地集成到神经网络模型中。在训练阶段,BatchNorm层会根据小批量的统计信息来规范化输入数据;在推理(测试)阶段,BatchNorm层则使用训练过程中计算得到的移动平均均值和方差来规范化输入数据。
九、PyTorch实现
在PyTorch中,可以通过nn.BatchNorm1d、nn.BatchNorm2d和nn.BatchNorm3d等类来实现一维、二维和三维的批量归一化。以下是一个简单的示例,展示了如何在全连接神经网络中使用批量归一化:
pythonimport torchimport torch.nn as nnimport torch.optim as optimclass SimpleNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.bn1 = nn.BatchNorm1d(hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, output_size)def forward(self, x):out = self.fc1(x)out = self.bn1(out)out = self.relu(out)out = self.fc2(out)return out# 定义模型、损失函数和优化器model = SimpleNN(input_size=20, hidden_size=50, output_size=10)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 模拟训练过程for epoch in range(100):inputs = torch.randn(32, 20) # 小批量数据labels = torch.randint(0, 10, (32,)) # 标签# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()在这个示例中,nn.BatchNorm1d用于对隐藏层的输出进行批量归一化,从而提高训练效率和稳定性。
相关文章:
卷积神经网络(CNN)中的批量归一化层(Batch Normalization Layer)
批量归一化层(BatchNorm层),或简称为批量归一化(Batch Normalization),是深度学习中常用的一种技术,旨在加速神经网络的训练并提高收敛速度。 一、基本思想 为了让数据在训练过程中保持同一分布…...

LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models 论文解读
目录 一、概述 二、相关工作 1、LLMs到多模态 2、3D对象生成 3、自回归的Mesh生成 三、LLaMA-Mesh 1、3D表示 2、预训练模型 3、有监督的微调数据集 4、数据集演示 四、实验 1、生成的多样性 2、不同模型text-to-Mesh的比较 3、通用语境的评估 一、概述 该论文首…...

【ESP32CAM+Android+C#上位机】ESP32-CAM在STA或AP模式下基于UDP与手机APP或C#上位机进行视频流/图像传输
前言: 本项目实现ESP32-CAM在STA或AP模式下基于UDP与手机APP或C#上位机进行视频流/图像传输。本项目包含有ESP32源码(arduino)、Android手机APP源码以及C#上位机源码,本文对其工程项目的配置使用进行讲解。实战开发,亲测无误。 AP模式,就是ESP32发出一个WIFI/热点提供给电…...

ESP-KeyBoard:基于 ESP32-S3 的三模客制化机械键盘
概述 在这个充满挑战与机遇的数字化时代,键盘已经成为我们日常学习、工作、娱乐生活必不可少的设备。而在众多键盘中,机械键盘,以其独特的触感、清脆的敲击音和经久耐用的特性,已经成为众多游戏玩家和电子工程师的首选。本文将为…...

28.UE5游戏框架,事件分发器,蓝图接口
3-3 虚幻游戏框架拆解,游戏规则基础_哔哩哔哩_bilibili 目录 1.游戏架构 2.事件分发器 2.1UI控件中的事件分发器 2.2Actor蓝图中的事件分发器 2.2.1动态决定Actor的分发事件 2.2.2父类中定义事件分发器,子类实现事件分发器 2.3组件蓝图中实现事件…...

Puppeteer 和 Cheerio 在 Node.js 中的应用
Puppeteer 和 Cheerio 在 Node.js 中的应用 引言 在现代 Web 开发中,自动化测试、数据抓取和页面分析是常见的需求。Node.js 提供了丰富的工具和库来满足这些需求。本文将介绍两个在 Node.js 中常用的库:Puppeteer 和 Cheerio,它们分别用于…...

Unity2D 关于N方向俯视角 中 角色移动朝向的问题
通常对俯视角2d游戏的角色移动我们使用简单2d混合树的方式,但是其不移动时的朝向该如何定义? 十分简单:移动和不移动之间形成逻辑自锁 详细说明思路就是再创建一个简单2d混合树 定义其N方向的idle 并用lastDirc二维向量保存玩家输入,当玩家输…...
` 只能用于只有一个元素的张量. 防止显存爆炸)
pytorch 和tensorflow loss.item()` 只能用于只有一个元素的张量. 防止显存爆炸
loss.item() 是 PyTorch 中的一个方法,它用于从一个只包含单个元素的张量(tensor)中提取出该元素的值,并将其转换为一个 Python 标量(即 int 或 float 类型)。这个方法在训练神经网络时经常用到,…...

链表刷题|判断回文结构
题目来自于牛客网,本文章仅记录学习过程的做题理解,便于梳理思路和复习 我做题喜欢先把时间复杂度和空间复杂度放一边,先得有大概的解决方案,最后如果时间或者空间超了再去优化即可。 思路一:要判断是否为回文结构则…...

海盗王集成网关和商城服务端功能golang版
之前用golang把海盗王的商城服务端和网关服务端都重写了一次。 后来在同时开启网关和商城服务时,发现窗口数量有点多,有时要找到商城窗口比较麻烦。 既然2个都是用golang govcl写的,是不是可以集成到一起,方便使用呢?…...

SCI 中科院分区中位于4区,JCR分区位于Q2 是什么水平?
环境: ACM Transactions on Interactive Intelligent Systems 《Acm Transactions On Interactive Intelligent Systems》(《交互式智能系统上的 Acm 事务》)是一本由ASSOC COMPUTING MACHINERY (ACM)出版的Computer Interaction-Computer Science-Human学术刊物&…...
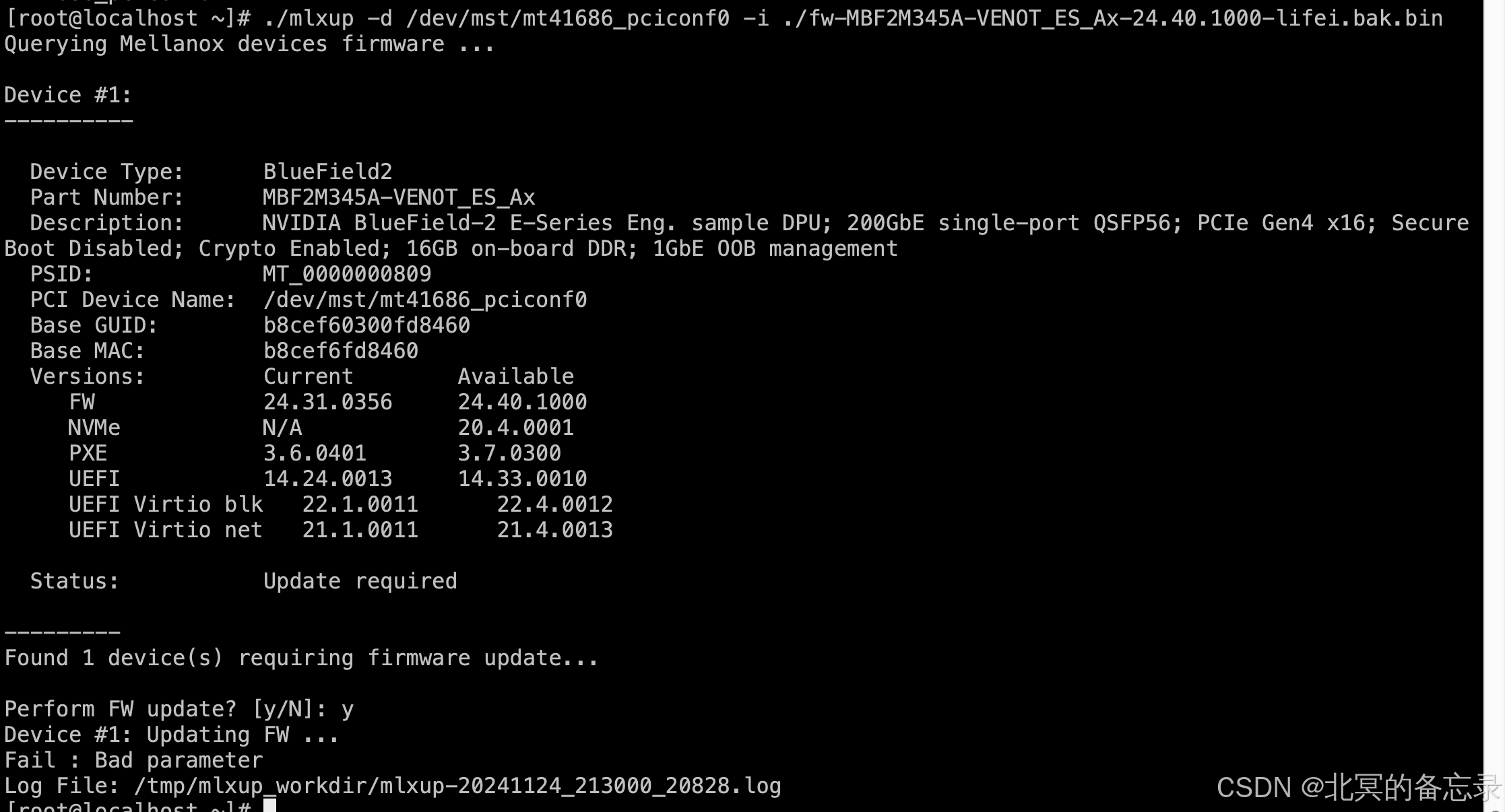
微知-Mellanox网卡的另外一种升级方式mlxup?(mlxup -d xxx -i xxx.bin)
背景 一般升级Mellanox网卡使用flint,还有另外一种叫做mlxup。 NVIDIA 提供了两种固件工具来更新和查询适配器固件: MLXUP - 固件更新和查询实用程序。该实用程序允许扫描服务器计算机以查找可用的 NVIDIA 适配器,并指示每个适配器是否需要…...

《Shader入门精要》透明效果
代码以及实例图可以看github :zaizai77/Shader-Learn: 实现一些书里讲到的shader 在实时渲染中要实现透明效果,通常会在渲染模型时控制它的透明通道(Alpha Channel)。当开启透明混合后,当一个物体被渲染到屏幕上时&…...

Linux之SELinux与防火墙
一、SELinux的说明 开发背景与目的: SELinux由美国国家安全局(NSA)开发,旨在避免资源的误用。传统的Linux基于自主访问控制(DAC),通过判断进程所有者/用户组与文件权限来控制访问,对…...

深度学习使用LSTM实现时间序列预测
大家好,LSTM是一种特殊的循环神经网络(RNN)架构,它被设计用来解决传统RNN在处理长序列数据时的梯度消失和梯度爆炸问题,特别是在时间序列预测、自然语言处理和语音识别等领域中表现出色。LSTM的核心在于其独特的门控机…...

Vue第一篇:组件模板总结
前言 本文希望读者有一定的Vue开发经验,样例采用vue中的单文件组件,也是我的个人笔记,欢迎一起进步 必须有根元素 这是一个最简单的vue单文件组件,<template></template>被称为模板,模板中必须有一个根元素…...

时钟使能、
时钟使能 如果正确使用,时钟使能能够显著地降低系统功耗,同时对面积或性能的影响极小。但是如果不正确地使用时钟使能, 可能会造成下列后果: • 面积增大 • 密度减小 • 功耗上升 • 性能下降 在许多使用大量控制集的…...
)
1. Autogen官网教程 (Introduction to AutoGen)
why autogen The whole is greater than the sum of its parts.(整体的功能或价值往往超过单独部分简单相加的总和。) -Aristotle autogen 例子 1. 导入必要的库 首先,导入os库和autogen库中的ConversableAgent类。 import os from autogen import Conversable…...

开源账目和账单
开源竞争: 开源竞争(当你无法彻底掌握技术的时候,你就开源这个技术,让更多的人了解这个技术,形成更多的技术依赖,你会说这不就是在砸罐子吗?一个行业里面总会有人砸罐子,你不如先砸…...

vue2面试题10|[2024-11-24]
问题1:vue设置代理 如果你的前端应用和后端API服务器没有运行在同一个主机上,你需要在开发环境下将API请求代理到API服务器。这个问题可以通过vue.config.js中的devServer.proxy选项来配置。 1.devServer.proxy可以是一个指向开发环境API服务器的字符串&…...
:零基础看懂TVA智能体:不是大模型噱头,是工业落地刚需技术)
TVA视觉智能体专栏(三):零基础看懂TVA智能体:不是大模型噱头,是工业落地刚需技术
摘要:很多新人误以为TVA是概念炒作,实则是智能制造柔性质检的核心解决方案。本文用通俗工程视角拆解TVA核心架构,详解Transformer注意力机制、DRL强化学习、FRA因式分解的协同逻辑,新手也能快速读懂智能体视觉底层逻辑。一、前言&…...

2025-2026年全球DHA品牌推荐:五大榜单评测婴幼儿纯净藻油口感无腥味适用场景
摘要 当家长与个体健康管理者纷纷将DHA纳入日常营养补充方案,面对市场上琳琅满目的品牌与产品,却陷入了“如何甄别纯度、规避过敏原、匹配不同年龄段需求”的现实困境:是追求高纯度藻油,还是优先考虑配方安全性?根据Gr…...
:3个隐藏技能断层导致输出质量长期停滞)
AI视频生成“假熟练”陷阱(83%用户未察觉):3个隐藏技能断层导致输出质量长期停滞
更多请点击: https://kaifayun.com 第一章:AI视频生成工具学习曲线分析 AI视频生成工具的学习曲线呈现出显著的非线性特征:初学者可在数小时内完成基础视频合成,但要稳定产出符合商业标准的高质量内容,通常需跨越模型…...
)
B站视频策划效率提升300%的ChatGPT实战手册(含18个领域专属Prompt库+自动打标/分镜/口播时长优化工具链)
更多请点击: https://intelliparadigm.com 第一章:B站视频策划的AI范式迁移与效能革命 传统B站视频策划高度依赖人工选题、脚本撰写与热点预判,响应周期长、个性化不足、数据洞察滞后。随着多模态大模型与垂类Agent技术成熟,策划…...

高效拦截微信撤回消息:WeChatIntercept一站式解决方案
高效拦截微信撤回消息:WeChatIntercept一站式解决方案 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 还在为微信聊天…...

YOLOv11农田烟草叶片病害目标检测数据集-470张-tobacco-plant-1
YOLOv11农田烟草叶片病害目标检测数据集 📊 数据集基本信息 目标类别: [‘Black shank’, ‘Healthy Leaf’, ‘Tobacco leaf curl disease -TLCD-’, ‘Tobacco mosaic virus -TMV-’, ‘brown sport’, ‘frogeye leaf spot’]中文类别:[‘…...

Windows触控板终极优化:三指拖拽功能完整配置指南
Windows触控板终极优化:三指拖拽功能完整配置指南 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/ThreeFingersDragOnWind…...

从机器学习到生化电路:基于维度缩减与内部模型的趋势预测设计
1. 项目概述:当机器学习遇见生化电路在合成生物学和计算神经科学的交叉地带,有一个问题一直让我着迷:一个由简单化学反应构成的生物系统,如何能像一台精密的计算机一样,对未来做出预测?这听起来像是科幻小说…...

TPS不是数字而是手术刀:JMeter性能诊断核心原理
1. 为什么TPS不是“点一下就出来的数字”,而是一把性能诊断的手术刀很多人第一次用JMeter跑完脚本,盯着监听器里跳出来的“TPS:42.3”发呆——这数字到底准不准?它和我写的接口响应时间有什么关系?为什么加了10个线程&…...

显存直降68%、推理提速3.2倍,DeepSeek-V2量化部署方案全解析,仅限首批内测团队流出
更多请点击: https://codechina.net 第一章:DeepSeek-V2量化部署方案全景概览 DeepSeek-V2作为高性能开源大语言模型,在实际生产环境中面临显存占用高、推理延迟大等挑战。量化部署是实现低资源开销与高吞吐并存的关键路径,本章…...