《生成式 AI》课程 第5講:訓練不了人工智慧?你可以訓練你自己 (下)
资料来自李宏毅老师《生成式 AI》课程,如有侵权请通知下线
Introduction to Generative AI 2024 Spring![]() https://speech.ee.ntu.edu.tw/~hylee/genai/2024-spring.php
https://speech.ee.ntu.edu.tw/~hylee/genai/2024-spring.php
摘要
这一系列的作业是为 2024 年春季的《生成式 AI》课程设计的,共包含十个作业。每个作业都对应一个具体的主题,例如真假难辨的世界、AI 应用开发、AI催眠大师、LLM 微调等。
承接上一讲:
《生成式 AI》课程 第4講:訓練不了人工智慧?你可以訓練你自己 (中)_生成式人工智能训练-CSDN博客文章浏览阅读771次,点赞27次,收藏26次。这一系列的作业是为 2024 年春季的《生成式 AI》课程设计的,共包含十个作业。每个作业都对应一个具体的主题,例如真假难辨的世界、AI 应用开发、AI催眠大师、LLM 微调等。承接上一讲:《生成式 AI》课程 第3講:訓練不了人工智慧嗎?你可以訓練你自己-CSDN博客作业代码 ( 后续增加)强化语言模型的方法 - 拆解任务复杂任务可拆解为多个步骤,如先写大纲再生成摘要,以提升模型处理任务的能力。_生成式人工智能训练https://blog.csdn.net/chenchihwen/article/details/143829219?spm=1001.2014.3001.5501
主要内容总结
- 模型合作
- 任务分配:不同能力和成本的语言模型 A、B、C 等,根据任务选择合适模型执行,展示平台服务可能涉及多个模型(如论文 “FrugalGPT” 相关研究)。
- 模型讨论
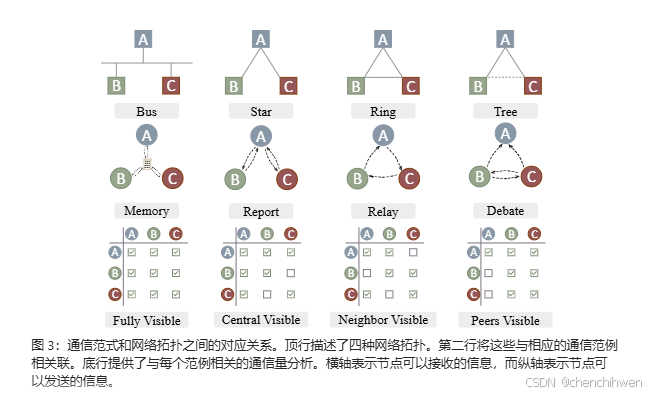
- 模型彼此讨论可提升效果,如 “Multi - Agent Debate” 等研究,不同任务有不同合适的讨论方式,如 “Exchange - of - Thought” 涉及 Debate、Memory、Report、Relay 等方式,且讨论可视范围不同(Fully Visible、Central Visible、Neighbor Visible、Peers Visible)。
- 讨论停止条件:未达成共识则继续,达成共识则得出结论;讨论有不同级别要求,从完全达成共识到允许一定分歧(如论文 “https://arxiv.org/abs/2305.19118” 所述)。同时存在为反对而反对的情况及相应处理方式(如论文 “https://arxiv.org/abs/2305.14325” 所述)。
- 引入不同角色
- 团队需要不同角色,不同模型有不同专长,可设定如 “project manager” 等角色。例如 Code llama 相关研究,不同角色如 Programmer、User、Project manager 等分工协作,根据贡献度打分优化团队(目前学术论文多在简单任务上测试)。
- 未来语言模型可专业分工,不同团队专注打造专业领域语言模型,如开发游戏、编写程序等任务中不同角色的协作(如 MetaGPT、ChatDev 等相关研究及项目实践),还可形成由 AI 组成的社群(如相关社交场景模拟研究及展示)。
重点投影片









延伸阅读
mproving Factuality and Reasoning in Language Models through Multiagent Debate![]() https://arxiv.org/pdf/2305.14325文章摘要如下
https://arxiv.org/pdf/2305.14325文章摘要如下
不训练模型强化语言模型的方法总结
一、模型合作
(一)任务分配
不同能力和成本的语言模型(如模型 A、B、C 等)可根据任务选择合适的模型执行。展示平台上为用户服务的不一定是同一个模型,相关研究如 “FrugalGPT”(https://arxiv.org/abs/2305.05176)。
(二)模型讨论
- 提升效果:模型彼此讨论能强化语言模型,如 “Multi - Agent Debate” 等研究。不同任务有不同合适的讨论方式,如 “Exchange - of - Thought” 包含 Debate、Memory、Report、Relay 等,且讨论可视范围不同(Fully Visible、Central Visible、Neighbor Visible、Peers Visible)。
- 停止条件
- 未达成共识则继续讨论,达成共识则得出结论。
- 讨论有不同级别要求,从完全达成共识(Level 0)到允许一定分歧(Level 1),默认(Level 2)是为找到正确答案不一定要完全同意彼此观点,还有要求双方必须在每个辩论点上都不同意(Level 3)。
- 为反对而反对情况及处理:存在为反对而反对的情况,可根据其他模型的解决方案给出更新回应,如短提示(Short)基于其他答案给出新回应,长提示(Long)将其他答案作为额外建议给出新回应(相关研究https://arxiv.org/abs/2305.14325)。
二、引入不同角色
- 团队需要不同角色,不同模型有专长差异,可设定如 “project manager” 等角色。例如 Code llama 相关研究中,不同角色如 Programmer、User、Project manager 等分工协作,根据贡献度打分优化团队(目前学术论文多在简单任务上测试)。
- 未来语言模型可专业分工,不同团队专注打造专业领域语言模型,如 MetaGPT、ChatDev 等在开发游戏(如开发五子棋、编写 Flappy Bird 游戏)、编写程序等任务中不同角色协作(相关研究https://arxiv.org/abs/2308.00352、https://arxiv.org/abs/2310.02170),还可形成由 AI 组成的社群(相关研究及展示https://arxiv.org/abs/2304.03442、https://youtu.be/G44Lkj7XDsA?si=cMbKG3tqPbIgnnBq)
通过跨模型通信来增强大型语言模型(LLM)的能力![]() https://arxiv.org/pdf/2312.01823
https://arxiv.org/pdf/2312.01823
“Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication”
由复旦大学、新加坡国立大学和上海人工智能实验室的研究人员撰写,提出了一种名为 Exchange-of-Thought(EoT)的框架,通过跨模型通信来增强大型语言模型(LLM)的能力。
- 研究背景
- LLMs 在复杂推理任务中存在局限性,尽管通过 Chain-of-Thought(CoT)等技术取得进展,但推理仍受限于模型自身理解,缺乏外部视角123。
- 现有方法如 CoT 和自校正方法在推理过程中依赖模型自身,难以克服固有局限,且获取高质量外部见解存在挑战436。
- 研究方法
- 提出 EoT 框架:通过跨模型通信整合外部见解,包含四个通信范式(Memory、Report、Relay、Debate),并设计信心评估机制以减少错误推理影响578。
- 通信范式:Memory 范式下模型记录并共享信息,通信成本高但信息流动快;Report 范式指定中心节点收集和分发信息;Relay 范式中模型按顺序传递信息;Debate 范式采用树形结构,叶节点交换信息,父节点聚合信息91011。
- 终止条件:包括一致输出终止(当模型当前轮输出与上一轮相同时停止通信)和多数共识终止(当多数模型达成一致时停止通信)121314。
- 信心评估:根据模型回答的变化计算信心水平,帮助接收方验证信息可靠性151617。
- 实验结果
- 在数学推理、常识推理和符号推理任务中,EoT 显著优于基线方法,如在数学推理任务中,EoT 的四个通信范式比 CoT 和 ComplexCoT 有显著改进181920。
- 多数共识终止在 AQuA 数据集上比一致输出终止表现更好;信心评估使模型在通信中能更早考虑其他模型的信心,平均提高准确率 2.92%;多数样本在三轮内达成终止条件,EoT 计算成本低于 CoT-SC (5) 且性能更优,还适用于不同 LLMs,模型多样性可提升 EoT 性能212223。
- 研究结论
- EoT 通过跨模型通信丰富模型的外部见解,四个通信范式在不同任务中有各自优势,信心评估机制有效减少错误推理影响24。
- EoT 在多个推理任务中表现出色,具有成本效益,适用于多种模型,模型多样性可进一步增强其性能24。
- 未来展望
- 开源模型有望通过协作交换见解提升性能,但当前受通信和分析能力及计算资源需求限制。处理长文本能力的提升将有助于增加参与通信的模型数量,模型通信在降低计算资源下实现有效性能,符合 AI 可持续发展目标,未来将推动 AI 系统向更先进、协作方向发展252627。
内容如下
大型语言模型 (LLM) 最近通过 Chain-of-Thought 技术在复杂推理任务方面取得了重大进展。尽管取得了这些进步,但他们的推理往往受到内在理解的制约,缺乏外部洞察力。为了解决这个问题,我们提出了思想交流 (EoT),这是一种新颖的框架,可以在解决问题时实现跨模型通信。EoT 从网络拓扑中汲取灵感,集成了四种独特的通信范式:内存、报告、中继和辩论。本文深入探讨了与每种范式相关的通信动态和数量。为了抵消错误推理链的风险,我们在这些通信中实施了强大的置信度评估机制。我们在各种复杂推理任务中的实验表明,EoT 明显超过了既定的基线,强调了外部洞察在提高 LLM 绩效方面的价值。此外,我们表明 EoT 以具有成本效益的方式实现了这些卓越的结果,这标志着高效和协作解决 AI 问题的有希望的进步。
“两个脑袋总比一个好。” –英国谚语
1 引言
GPT4 等大型语言模型 (LLM)(OpenAI,2023 年)正在通过利用庞大的训练语料库和巨大的计算资源(Bai et al., 2022a;Ouyang et al., 2022;Chowdhery 等人,2022 年;Zhang et al., 2022;Touvron等人,2023a,除其他外)。尽管 LLM 在广泛的 NLP 任务中取得了模范性能(Wei et al., 2022a;Chung et al., 2022),但他们一直在努力在
推理任务,而这种限制不能仅仅通过增加模型的大小来克服(Rae et al., 2022;bench authors, 2023)。

图 1:CoT、自我校正和 EoT 的比较。CoT 和 Self-Correction 都依赖于模型的先天能力来生成和优化输出,缺乏外部洞察力。EoT 通过将其他模型的思想作为外部见解来增强模型的推理能力。
为了克服这个缺点,Wei et al. (2022b) 提出了思维链 (CoT) 提示,它指导模型在得出最终答案之前生成一系列中间推理步骤。同时,一系列自我纠正方法(Welleck et al., 2023;Ganguli et al., 2023)的回答,旨在通过利用模型对先前输出的反馈来迭代提高答案的质量(Madaan et al., 2023;Shinn et al., 2023)。
然而,CoT 和自我纠正完全基于模型在推理过程中对问题的理解和观点。最近的研究(Huang等人,2023 年;Valmeekam等人,2023 年;Stechly et al., 2023)表明,在没有外部反馈的情况下,LLM 很难修改他们的回答。这可以归因于该模型完全依赖内部表示来生成响应,这使得很难克服能力的固有限制(Yin et al., 2023)。

图 2:三个推理数据集的试点实验。包含正确答案的错误样本的数量明显高于不包含正确答案的错误样本。
尽管外部见解的重要性无可否认 (Yao et al., 2023),但获得高质量的外部见解仍然是一个挑战。Wang et al. (2023c) 的研究表明,CoT 生成的单一推理链限制了模型的推理性能。通过提高温度对不同的推理链进行采样,并通过多数投票选择答案,可以进一步提高模型的推理性能。但是,当面临困难的问题时,该模型通常会产生更多数量的错误回答。在图 2 中,我们对来自三个推理数据集的错误样本中的正确和错误答案的分析表明,在大多数情况下,模型可以推断出正确答案。
在人类社会中,真理,即使由少数人持有,也可以通过清晰和有说服力的沟通获得广泛的接受和认可(Le Bon,1897)。他人的正确推理可以作为高质量的外部见解,丰富和提升我们的集体理解。因此,我们提出了思想交流 (EoT),这是一种在解决问题过程中促进跨模型交流的新型框架。此计划使模型能够将他人的推理作为外部见解纳入其中。
图 1 将 EoT 与 CoT 和自我校正方法进行了对比,突出了 EoT 在整合外部视角方面的独特方法。受网络拓扑学原理(Bisht 和 Singh,2015 年)和代理通信(Parsons 和 McBurney,2003 年)的启发,我们提出了四种通信范式:记忆、报告、中继和辩论。这些范式旨在促进模型之间的思想交流和推理链,从而丰富问题
具有多种见解的解决过程。此外,我们深入研究了每种通信范式的复杂性,分析了信息流的动态和通信量。意识到正确和错误的推理链都会在通信中传播,我们引入了置信度评估机制,该机制采用答案变化分析来评估模型的置信度。它旨在减轻错误推理的影响,从而确保解决问题过程的完整性和可靠性。
各种复杂推理任务的实验表明,EoT 的性能明显优于既定的强基线,强调了外部洞察力在增强 LLM 能力方面的关键作用。我们将我们的贡献总结如下:
・我们引入了思想交流 (EoT),这是一个开创性的跨模型通信框架,在解决问题时结合了来自其他 LLM 的外部见解。
・我们提出并检查了四种通信范式以及一种置信度评估机制,该机制通过答案的可变性评估模型确定性,减轻错误推理的影响。
・各种复杂推理任务的实验结果强调了 EoT 的有效性和成本效益,突出了在解决问题中结合外部见解和沟通的重要性。
2 相关工作
2.1 LLM 中的思维链提示
Wei et al. (2022b) 强调,当受到具有中间推理步骤的演示的提示时,LLM 可以表现出增强的推理能力。该技术可以有效提高 LLM 在复杂推理任务上的性能(Wei et al., 2022a;Kojima et al., 2022)。已经提出了一系列增强 CoT 的策略,以进一步提高 LLM 的性能。其中一种方法是程序辅助语言模型(Gao et al., 2022;Chen et al., 2022),旨在通过程序合成将推理和计算解耦。此外,复杂的任务也可以通过模块化方法转化为可委派的子任务(Khot et al., 2023)。选择合适的演示可以
还可以提高 CoT 的性能(Li et al., 2023a;Li 和 Qiu,2023a)。其中值得注意的是,AutoCoT (Zhang et al., 2023b) 使用自动化方式来构建和采样各种演示。主动提示 (Diao et al., 2023) 根据模型在输出中的不确定性选择最有用的样本进行标记。最近,Li 和 Qiu (2023b) 采用了一种将高置信度的思想存储为外部记忆的策略,并检索这些见解以帮助推理过程。
2.2 推理路径的集合
LLM 能够使用温度调整和提示抽样等技术探索多种推理路径(Chu et al., 2023)。Wang et al. (2023c) 认为,对于复杂的问题,可能有几种正确的路径来解决一个问题,这导致了自洽的提出。这种方法用多个推理路径的采样并选择最一致的答案来取代贪婪解码策略,从而显著提高了性能。除此之外,Fu et al. (2023b) 发现,推理复杂度较高的提示可以在多步推理任务中取得更好的表现,从而提出了基于复杂性的提示。虽然其他方法,例如重新排名(Cobbe et al., 2021;Thoppilan et al., 2022)也被应用于选择合适的推理路径,它们通常依赖于启发式或训练有素的较小模型。最近,Li et al. (2023b) 对不同的演示进行了抽样,并使用分步验证来过滤掉错误的答案。然而,获得步骤级标签可能具有挑战性,并且使用较小的模型进行判断很难处理复杂的推理过程。相比之下,我们的方法充分利用了 LLM 的沟通和决策能力来得出最终答案,而无需额外的训练和注释数据。
2.3 推理路径细化
尽管 CoT(Wei et al., 2022b)有效地提高了 LLM 在复杂推理任务中的表现,但它们在推理过程中仍然容易受到错误的影响,从而导致错误的答案(Bai et al., 2022b;Lyu et al., 2023)。为了缓解这个问题,Shinn 等人(2023 年)和 Madaan 等人(2023 年)利用模型自己的反馈和过去的错误来改进推理过程。Yao et al. (2023) 探讨了推理之间的协同作用
链和行动计划。对于数值问题,Zheng et al. (2023) 通过使用先前生成的答案作为提示,逐渐引导模型找到正确答案。在外部知识的帮助下,Wang et al. (2023a) 引入了知识链提示,它使用证据三元组来遏制不真实和不忠实答案的产生。考虑到模型交互,多智能体辩论(Du et al., 2023;Liang et al., 2023)的引入是为了提高生成内容的事实准确性并减少谬误和幻觉。EoT 与这些工作不同,因为我们通过跨模型通信将其他模型的推理过程整合为外部洞察,从而优先增强单个模型生成的当前推理过程。
6 总结
我们介绍了 Exchange-of-Thought (EoT),这是一个新颖的框架,它通过跨模型通信为模型提供了外部见解。我们开发了四种通信范式,并对通信量和信息传播速度进行了全面分析。为了防止错误推理过程的中断,我们设计了一个置信度评估机制。数学、常识和符号推理任务的实验表明,EoT 超越了一系列强大的基线,同时也提供了成本优势。进一步分析表明,EoT 对各种模型具有适应性,更多样化的模型的参与可以进一步增强 EoT 的性能。
相关文章:
《生成式 AI》课程 第5講:訓練不了人工智慧?你可以訓練你自己 (下)
资料来自李宏毅老师《生成式 AI》课程,如有侵权请通知下线 Introduction to Generative AI 2024 Springhttps://speech.ee.ntu.edu.tw/~hylee/genai/2024-spring.php 摘要 这一系列的作业是为 2024 年春季的《生成式 AI》课程设计的,共包含十个作业。…...

Vue 动态给 data 添加新属性深度解析:问题、原理与解决方案
在 Vue 中,动态地向 data 中添加新的属性是一个常见的需求,但它也可能引发一些问题,尤其是关于 响应式更新 和 数据绑定 的问题。Vue 的响应式系统通过 getter 和 setter 来追踪和更新数据,但 动态添加新属性 时,Vue 并不会自动为这些新属性创建响应式链接。 1. 直接向 V…...
【Pytest+Yaml+Allure】实现接口自动化测试框架
一、框架思想 requestsyamlpytestallure实现接口自动化框架。结合数据驱动和分层思想,将代码与数据分离,易维护,易上手。使用yaml编写编写测试用例,利用requests库发送请求,使用pytest管理用例,allure生成…...

el-input绑定点击回车事件意外触发页面刷新
小伙伴们在项目中应该还是比较常用键盘指定按键事件的,尤其是一些筛选条件的通过点击键盘回车按键去触发搜索 例如: <el-form><el-form-item label条件title><el-input v-modelformData.searchKey keydown.entersearch></el-input…...

Golang的语言特性与鸭子类型
Golang的语言特性与鸭子类型 前言 什么是鸭子类型? Suppose you see a bird walking around in a farm yard. This bird has no label that says ‘duck’. But the bird certainly looks like a duck. Also, he goes to the pond and you notice that he swims l…...

如何在Linux系统中排查GPU上运行的程序
如何在Linux系统中排查GPU上运行的程序 在Linux系统中,随着深度学习和高性能计算的普及,GPU资源的管理和监控变得越来越重要。当您遇到GPU资源不足或性能下降的问题时,需要能够快速定位并解决这些问题。本文将介绍几种常用的方法来帮助您排查…...

VSCode 新建 Python 包/模块 Pylance 无法解析
问题描述: 利用 VSCode 写代码,在项目里新建一个 Python 包或者模块,然后在其他文件里正常导入这个包或者模块时出现: Import “xxxx” could not be resolved Pylance (reportMissingImports) 也就是说 Pylance 此时无法解析我们…...

Unet++改进44:添加MogaBlock(2024最新改进模块)|在纯基于卷积神经网络的模型中进行判别视觉表示学习,具有良好的复杂性和性能权衡。
本文内容:添加MogaBlock 目录 论文简介 1.步骤一 2.步骤二 3.步骤三 4.步骤四 论文简介 通过将内核尽可能全局化,现代卷积神经网络在计算机视觉任务中显示出巨大的潜力。然而,最近在深度神经网络(dnn)内的多阶博弈论相互作用方面的进展揭示了现代卷积神经网络的表示瓶…...

计算机网络(14)ip地址超详解
先看图: 注意看第三列蓝色标注的点不会改变,A类地址第一个比特只会是0,B类是10,C类是110,D类是1110,E类是1111. IPv4地址根据其用途和网络规模的不同,分为五个主要类别(A、B、C、D、…...

【C语言】野指针问题详解及防范方法
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C语言 文章目录 💯前言💯什么是野指针?💯未初始化的指针代码示例问题分析解决方法 💯指针越界访问代码示例问题分析解决方法 💯指向已释放内存的…...

【SVN和GIT】版本控制系统详细下载使用教程
文章目录 ** 参考文章一、什么是SVN和GIT二、软件使用介绍1 SVN安装1.1 服务端SVN下载地址1.2 客户端SVN下载地址2 SVN使用2.1 服务端SVN基础使用2.1.1 创建存储库和用户成员2.1.2 为存储库添加访问人员2.2 客户端SVN基础使用2.2.1 在本地下载库中的内容2.2.2 版本文件操作--更…...

【Vue】Vue3.0(二十六)Vue3.0中的作用域插槽
上篇文章 【Vue】Vue3.0(二十五)Vue3.0中的具名插槽 的概念和使用场景 🏡作者主页:点击! 🤖Vue专栏:点击! ⏰️创作时间:2024年11月20日17点30分 文章目录 概念使用场景示…...
神经网络(系统性学习二):单层神经网络(感知机)
此前篇章: 神经网络中常用的激活函数 神经网络(系统性学习一):入门篇 单层神经网络(又叫感知机) 单层网络是最简单的全连接神经网络,它仅有输入层和输出层,没有隐藏层。即&#x…...
)
CTF之密码学(BF与Ook)
BrainFuck(通常也被称为Brainfuck或BF)和Ook是两种非常特殊且有趣的编程语言。以下是对这两种语言的详细介绍: 一、BrainFuck 简介: BrainFuck是一种极小化的计算机语言,由Urban Mller在1993年创建。由于“fuck”在英…...

【TEST】Apache JMeter + Influxdb + Grafana
介绍 使用Jmeter发起测试,测试结果存入Influxdb,Grafana展示你的测试结果。 环境 windows 10docker desktopJDK17 安装 Apache JMeter 访问官网(Apache JMeter - Apache JMeter™)下载JMeter(目前最新版本5.6.3&a…...

SpringBoot集成多个rabbitmq
1、pom文件 <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-amqp --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId><versio…...
)
从零开始学习数据库 day0(基础)
在当今的信息时代,数据已经成为了企业和组织最重要的资产之一。无论是电子商务平台,社交媒体,还是科研机构,几乎每个地方都离不开数据库。今天,我们将一起走进数据库的世界,学习它的基础知识,帮…...

MongoDB相关问题
视频教程 【GeekHour】20分钟掌握MongoDB Complete MongoDB Tutorial by Net Ninja MongoDB开机后调用缓慢的原因及解决方法 问题分析: MongoDB开机后调用缓慢,通常是由于以下原因导致: 索引重建: MongoDB在启动时会重建索引…...
)
linux基本命令(1)
1. 文件和目录操作 ls — 列出目录内容 ls # 显示当前目录的文件和目录 ls -l # 显示详细的文件信息(权限、大小、修改时间等) ls -a # 显示所有文件(包括隐藏文件) ls -lh # 显示详细信息并以易读的方式显示文件大小 cd — 改…...

【机器学习】超简明Python基础教程
Python是一种简单易学、功能强大的编程语言,适用于数据分析、人工智能、Web开发、自动化脚本等多个领域。本教程面向零基础学习者,逐步讲解Python的基本概念、语法和操作。 1. 安装与运行 安装Python 从官网 Welcome to Python.org 下载适合自己系统的…...

CANN NPU 功耗优化:推理服务的能效比提升实战
功耗直接影响部署成本和设备寿命。同样的推理任务,功耗优化后能省 30% 电费,设备温度降低 10C。本文讲解 NPU 功耗的来源、动态调频策略、算子级功耗控制,以及在 CANN 上实现绿色推理的实战方法。一、NPU 功耗从哪来 1.1 功耗的三个来源 计算…...
)
Codex CLI 接 Gemini 3.5 Flash 实测:代码生成、推理速度、价格三维度横评(2026)
上周 Google 发了 Gemini 3.5 Flash,我当天晚上就拿 Codex CLI 接上跑了几个项目里的真实任务。原因很简单——我们团队最近 token 开销涨得太快,老板让我找个"又快又便宜还不太拉胯"的模型顶日常编码场景。Claude Sonnet 4.6 质量没话说但贵&…...

联发科MT6833与MT6853 5G核心板:规格对比与产品选型实战指南
1. 项目概述:两款5G安卓核心板的定位与价值在当前的移动设备开发领域,尤其是面向中高端市场的智能手机、平板电脑以及各类智能终端,选择一颗性能强劲、功能集成度高且成本可控的核心处理器平台,是决定产品成败的关键。联发科&…...

代数拓扑运算流程
文章目录0、背景一、标准计算流程:以单纯同调为例空间剖分,构建单纯复形生成各维度链群定义边界算子定义闭链群与边缘链群计算同调群并解读拓扑信息推导最终拓扑结论二、其他核心概念的典型计算逻辑0、背景 之前为了做一个东西学习TDA&…...

暗黑2存档修改终极指南:5分钟学会免费d2s文件编辑器
暗黑2存档修改终极指南:5分钟学会免费d2s文件编辑器 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 暗黑破坏神2的d2s存档编辑器是一款专为玩家设计的强大工具,让你能够轻松修改角色属性、管理装备和调整…...

为开源 AI 工具 OpenClaw 配置 Taotoken 作为其模型供应商的步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源 AI 工具 OpenClaw 配置 Taotoken 作为其模型供应商的步骤 对于使用 OpenClaw 这类开源 AI 工具链的开发者而言,…...

ViGEmBus虚拟手柄驱动深度解析与实战指南
ViGEmBus虚拟手柄驱动深度解析与实战指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的困境:手头有一款独特的游戏控制…...
,python和c++哪个更值得学)
python入门教程(非常详细),python和c++哪个更值得学
python入门教程(非常详细),python和c哪个更值得学 这篇文章主要介绍了python入门教程(非常详细),具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。 python 怎么读 python&…...

[具身智能-855]:什么是AI应用?AI 应用、AI 模型、AI Agent三者区别?
一、定义AI 应用:搭载人工智能技术,具备智能理解、推理、生成、识别、决策能力,能自主完成人类事务的软件、程序、系统、设备。二、狭义 AI 应用(纯 AI 工具,最常见)专门靠 AI 干活,一眼看出是 …...
GeoSeg:突破性混合Transformer架构实现高效遥感图像语义分割
GeoSeg:突破性混合Transformer架构实现高效遥感图像语义分割 【免费下载链接】GeoSeg UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery, ISPRS. Also, including other vision transformers and C…...