Centos使用docker搭建Graylog日志平台
日志管理系统有很多,比如ELK,Graylog,Loki+Grafana+Promtail
适用场景:
1.如果需求复杂,服务器资源不受限制,推荐使用ELK(Logstash + Elasticsearch + Kibana)方案;
2.如果需求仅是将不同服务器上的日志采集上来集中展示和检索,且需要一个轻量级的框架,那使用PLG(Promtail + Loki + Grafana)最合适不过了。
3.Graylog专注于日志管理,内置报警功能,可配置当系统发生异常时下发邮件进行通知。
三者对比如下所示:
从左到右分别是: ELK Graylog Loki + Grafana + Promtail
| 资源消耗 | 高 | 中 | 低 |
| 部署复杂度 | 高 | 中 | 低 |
| 查询能力 | 强 | 中 | 弱 |
| 可视化能力 | 强(Kibana 丰富) | 一般 | 强(Grafana 丰富) |
| 适合场景 | 大规模日志,复杂查询和分析 | 中小型项目,快速部署 | 中等日志量,轻量化监控 |
Graylog是一款开源的日志管理系统,具备强大的过滤和搜索能力。
特点和适用场景:
- 适合中小型企业、日志量不大或希望快速部署日志管理平台的团队。
- 强调日志的聚合、报警、和简单分析。
- 可按需轻量配置,仅分析核心日志。
下面介绍下它的安装:
1. 准备环境
安装 Docker 和 Docker Compose
-
安装 Docker:
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install -y docker-ce docker-ce-cli containerd.io
sudo systemctl start docker
sudo systemctl enable docker
安装 Docker Compose:
1. sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
2. sudo chmod +x /usr/local/bin/docker-compose
3. docker-compose --version
2. 创建数据目录
为持久化存储 MongoDB 和 Elasticsearch 数据,创建本地目录:
mkdir -p /opt/graylog/mongo/data
mkdir -p /opt/graylog/elasticsearch/data
mkdir -p /opt/graylog/graylog
设置权限(确保 Docker 有权限写入):
sudo chown -R 1000:1000 /opt/graylog/elasticsearch/data
sudo chown -R 1000:1000 /opt/graylog/mongo/data
sudo chown -R 1000:1000 /opt/graylog/graylog
3. 创建 Docker Compose 配置文件
version: '3'
services:
mongo:
image: mongo:5.0
container_name: mongo
restart: always
volumes:
- /opt/graylog/mongo/data:/data/dbelasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.2
container_name: elasticsearch
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
ulimits:
memlock:
soft: -1
hard: -1
mem_limit: 2g
volumes:
- /opt/graylog/elasticsearch/data:/usr/share/elasticsearch/data
restart: alwaysgraylog:
image: graylog/graylog:5.0
container_name: graylog
environment:
- GRAYLOG_PASSWORD_SECRET=<生成的密码密钥>
- GRAYLOG_ROOT_PASSWORD_SHA2=<你的密码的 SHA-256 值>
- GRAYLOG_HTTP_BIND_ADDRESS=0.0.0.0:9000
depends_on:
- mongo
- elasticsearch
volumes:
- /opt/graylog/graylog:/usr/share/graylog/data
ports:
- "9000:9000"
- "12201:12201/udp"
restart: always
替换占位符
- 生成密码密钥 (
GRAYLOG_PASSWORD_SECRET):
pwgen -N 1 -s 96
如果没有pwgen,则先执行下面的命令安装:
sudo yum install -y epel-release
sudo yum install -y pwgen
再生成密码密钥:
pwgen -N 1 -s 96
生成管理员密码哈希 (GRAYLOG_ROOT_PASSWORD_SHA2),下面的yourpassword需替换为具体密码:
echo -n "yourpassword" | sha256sum
将生成的值填入 docker-compose.yml 的 GRAYLOG_PASSWORD_SECRET 和GRAYLOG_ROOT_PASSWORD_SHA2。
4. 启动服务
启动 Docker Compose
运行以下命令启动容器:
docker-compose up -d
查看容器状态
确保所有容器都在运行:
docker ps
5. 访问 Graylog
- 打开浏览器访问
http://<服务器IP>:9000。 - 使用以下登录:
- 用户名:
admin - 密码:在
GRAYLOG_ROOT_PASSWORD_SHA2中生成的原始密码。
- 用户名:
6. 防火墙配置
如果使用防火墙,确保开放必要的端口:
sudo firewall-cmd --add-port=9000/tcp --permanent
sudo firewall-cmd --add-port=12201/udp --permanent
sudo firewall-cmd --reload
7. 日志和数据持久化检查
检查 Graylog 日志:
docker logs graylog
数据持久化验证:
- MongoDB 数据存储在
/opt/graylog/mongo/data。 - Elasticsearch 数据存储在
/opt/graylog/elasticsearch/data。 - Graylog 配置和数据存储在
/opt/graylog/graylog。
8. 停止和重启服务
- 停止服务:
docker-compose down
重启服务:
docker-compose up -d
Graylog总内存需求
-
测试环境(低日志量、少并发):
总消耗约 4 GB(1 GB Graylog + 512 MB MongoDB + 2 GB Elasticsearch)。 -
小型生产环境(中等日志量、适度并发):
总消耗约 6 GB(1.5 GB Graylog + 1 GB MongoDB + 4 GB Elasticsearch)。 -
大型生产环境(高日志量、高并发):
总消耗可能在 8 GB - 16 GB 或更高。
内存优化建议
-
Elasticsearch 调优:
- 配置堆内存大小: 编辑
/etc/elasticsearch/jvm.options或 Docker Compose 的ES_JAVA_OPTS环境变量:-Xms2g -Xmx2g-Xmx2g
- 配置堆内存大小: 编辑
建议分配总系统内存的 50%,但不要超过 32 GB。
2.Graylog Server 调优:
- 配置 Graylog 的 JVM 堆内存大小: 编辑
/etc/graylog/server/server.conf或 Docker Compose 的GRAYLOG_SERVER_JAVA_OPTS:
GRAYLOG_SERVER_JAVA_OPTS="-Xms512m -Xmx1g"
3.MongoDB 调优:
使用 wiredTiger 存储引擎(默认),优化内存利用率。
4.日志清理:
配置日志保留时间,减少 Elasticsearch 的索引压力。
拓展:关于Loki + Grafana + Promtail安装和使用可参考:
轻量级日志系统docker-compose搭建Loki+Grafana+Promtail,配置、部署,查询全流程_docker compose loki-CSDN博客
使用 Loki、Loki4j、Grafana 和 Spring Boot 搭建一个轻量级、简单、易用的 Java 日志系统_loki springboot-CSDN博客
Promtail+Loki+Grafana搭建轻量级日志管理平台 - C3Stones - 博客园
相关文章:

Centos使用docker搭建Graylog日志平台
日志管理系统有很多,比如ELK,Graylog,LokiGrafanaPromtail 适用场景: 1.如果需求复杂,服务器资源不受限制,推荐使用ELK(Logstash Elasticsearch Kibana)方案; 2.如果需求仅是将…...

自定义 Kafka 脚本 kf-use.sh 的解析与功能与应用示例
Kafka:分布式消息系统的核心原理与安装部署-CSDN博客 自定义 Kafka 脚本 kf-use.sh 的解析与功能与应用示例-CSDN博客 Kafka 生产者全面解析:从基础原理到高级实践-CSDN博客 Kafka 生产者优化与数据处理经验-CSDN博客 Kafka 工作流程解析:…...

【SQL】【数据库】语句翻译例题
SQL自然语言到SQL翻译知识点 以下是将自然语言转化为SQL语句的所有相关知识点,分门别类详细列出,并结合技巧说明。 1. 数据库操作 创建数据库 自然语言:创建一个名为“TestDB”的数据库。 CREATE DATABASE TestDB;技巧:识别**“创…...

linux基本命令2
7. 文件查找和搜索 (继续) find — 查找文件 find /path/to/search -name "file_name" # 根据名称查找文件 find /path/to/search -type f # 查找所有普通文件 find /path/to/search -type d # 查找所有目录 find /path/to/search -name "*.txt" # 查找…...

Spring Boot项目集成Redisson 原始依赖与 Spring Boot Starter 的流程
Redisson 是一个高性能的 Java Redis 客户端,提供了丰富的分布式工具集,如分布式锁、Map、Queue 等,帮助开发者简化 Redis 的操作。在集成 Redisson 到项目时,开发者通常有两种选择: 使用 Redisson 原始依赖。使用 Re…...

Git命令使用与原理详解
1.仓库 # 在当前目录新建一个Git代码库 $ git init # 新建一个目录,将其初始化为Git代码库 $ git init [project-name] # 下载一个项目和它的整个代码历史 $ git clone [url]2.配置 # 显示当前的Git配置 $ git config --list # 编辑Git配置文件 $ git co…...
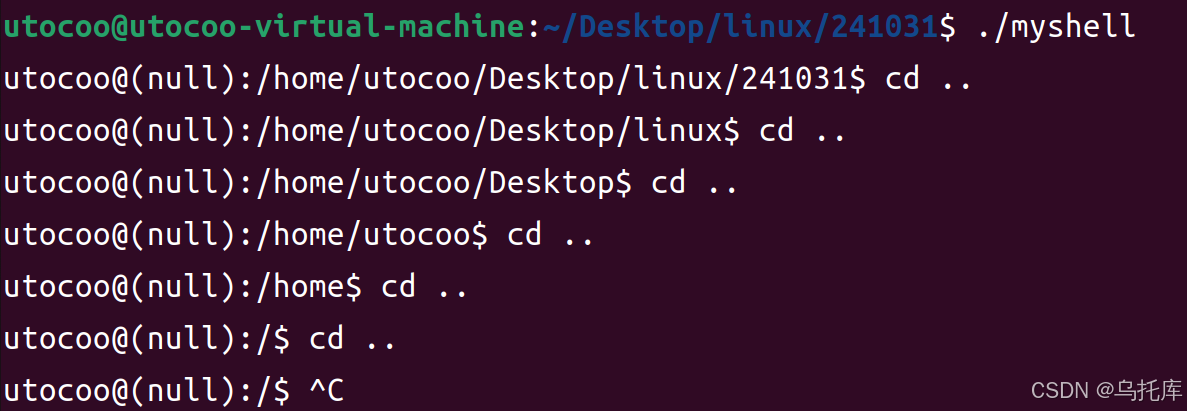
Linux:自定义Shell
本文旨在通过自己完成一个简单的Shell来帮助理解命令行Shell这个程序。 目录 一、输出“提示” 二、获取输入 三、切割字符串 四、执行指令 1.子进程替换 2.内建指令 一、输出“提示” 这个项目基于虚拟机Ubuntu22.04.5实现。 打开终端界面如图所示。 其中。 之前&#x…...

vue项目中中怎么获取环境变量
在 Vue 项目中,有几种获取环境变量的方法。最常用的是通过 import.meta.env 来访问。 1.首先在项目根目录创建环境变量文件: .env # 所有环境都会加载 .env.development # 开发环境 .env.production # 生产环境2.在环境变量文件…...

C#里怎么样使用正则表达式?
C#里怎么样使用正则表达式? 正则表达式是由普通字符(如英文字母)以及特殊字符(也称为元字符)组成的一种文字模式 这种文字模式可用于检查字符串的值是否满足一定的规则,例如: 验证输入的邮箱是否合法 输入的身份证号码是否合法 输入的用户名是否满足条件等 也可以…...
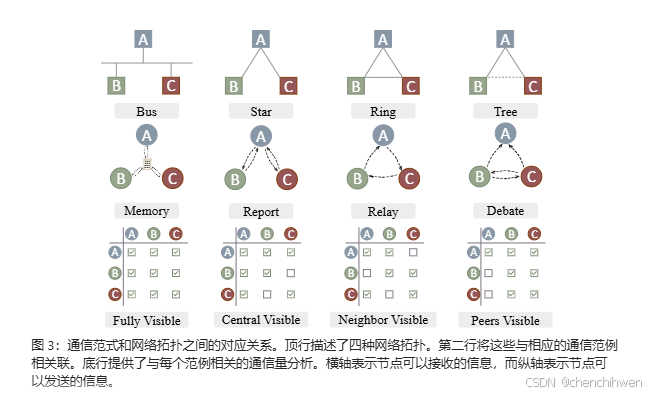
《生成式 AI》课程 第5講:訓練不了人工智慧?你可以訓練你自己 (下)
资料来自李宏毅老师《生成式 AI》课程,如有侵权请通知下线 Introduction to Generative AI 2024 Springhttps://speech.ee.ntu.edu.tw/~hylee/genai/2024-spring.php 摘要 这一系列的作业是为 2024 年春季的《生成式 AI》课程设计的,共包含十个作业。…...

Vue 动态给 data 添加新属性深度解析:问题、原理与解决方案
在 Vue 中,动态地向 data 中添加新的属性是一个常见的需求,但它也可能引发一些问题,尤其是关于 响应式更新 和 数据绑定 的问题。Vue 的响应式系统通过 getter 和 setter 来追踪和更新数据,但 动态添加新属性 时,Vue 并不会自动为这些新属性创建响应式链接。 1. 直接向 V…...
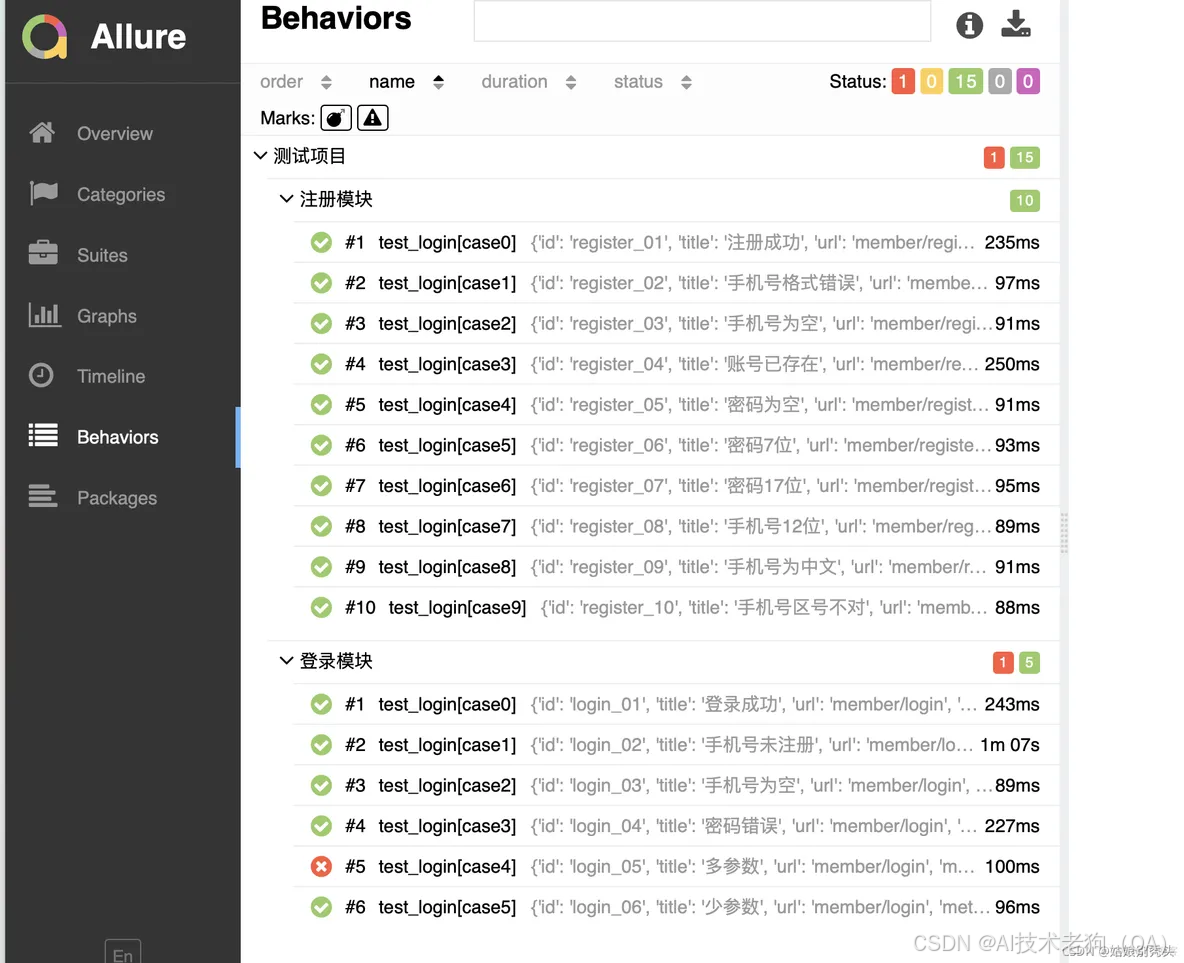
【Pytest+Yaml+Allure】实现接口自动化测试框架
一、框架思想 requestsyamlpytestallure实现接口自动化框架。结合数据驱动和分层思想,将代码与数据分离,易维护,易上手。使用yaml编写编写测试用例,利用requests库发送请求,使用pytest管理用例,allure生成…...

el-input绑定点击回车事件意外触发页面刷新
小伙伴们在项目中应该还是比较常用键盘指定按键事件的,尤其是一些筛选条件的通过点击键盘回车按键去触发搜索 例如: <el-form><el-form-item label条件title><el-input v-modelformData.searchKey keydown.entersearch></el-input…...

Golang的语言特性与鸭子类型
Golang的语言特性与鸭子类型 前言 什么是鸭子类型? Suppose you see a bird walking around in a farm yard. This bird has no label that says ‘duck’. But the bird certainly looks like a duck. Also, he goes to the pond and you notice that he swims l…...

如何在Linux系统中排查GPU上运行的程序
如何在Linux系统中排查GPU上运行的程序 在Linux系统中,随着深度学习和高性能计算的普及,GPU资源的管理和监控变得越来越重要。当您遇到GPU资源不足或性能下降的问题时,需要能够快速定位并解决这些问题。本文将介绍几种常用的方法来帮助您排查…...

VSCode 新建 Python 包/模块 Pylance 无法解析
问题描述: 利用 VSCode 写代码,在项目里新建一个 Python 包或者模块,然后在其他文件里正常导入这个包或者模块时出现: Import “xxxx” could not be resolved Pylance (reportMissingImports) 也就是说 Pylance 此时无法解析我们…...

Unet++改进44:添加MogaBlock(2024最新改进模块)|在纯基于卷积神经网络的模型中进行判别视觉表示学习,具有良好的复杂性和性能权衡。
本文内容:添加MogaBlock 目录 论文简介 1.步骤一 2.步骤二 3.步骤三 4.步骤四 论文简介 通过将内核尽可能全局化,现代卷积神经网络在计算机视觉任务中显示出巨大的潜力。然而,最近在深度神经网络(dnn)内的多阶博弈论相互作用方面的进展揭示了现代卷积神经网络的表示瓶…...

计算机网络(14)ip地址超详解
先看图: 注意看第三列蓝色标注的点不会改变,A类地址第一个比特只会是0,B类是10,C类是110,D类是1110,E类是1111. IPv4地址根据其用途和网络规模的不同,分为五个主要类别(A、B、C、D、…...

【C语言】野指针问题详解及防范方法
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C语言 文章目录 💯前言💯什么是野指针?💯未初始化的指针代码示例问题分析解决方法 💯指针越界访问代码示例问题分析解决方法 💯指向已释放内存的…...

【SVN和GIT】版本控制系统详细下载使用教程
文章目录 ** 参考文章一、什么是SVN和GIT二、软件使用介绍1 SVN安装1.1 服务端SVN下载地址1.2 客户端SVN下载地址2 SVN使用2.1 服务端SVN基础使用2.1.1 创建存储库和用户成员2.1.2 为存储库添加访问人员2.2 客户端SVN基础使用2.2.1 在本地下载库中的内容2.2.2 版本文件操作--更…...

Debian挂载NFS远程硬盘踩坑实录:权限拒绝、连接超时问题一站式解决
Debian挂载NFS远程硬盘踩坑实录:权限拒绝、连接超时问题一站式解决在Linux环境下使用NFS(Network File System)挂载远程存储是常见的跨服务器文件共享方案,但实际操作中常会遇到各种"拦路虎"。本文将以Debian系统为例&a…...

别再让auditd拖慢你的麒麟系统!手把手教你排查并关闭这个审计服务
麒麟系统性能优化实战:auditd服务深度排查与替代方案 在麒麟系统的日常运维中,auditd这个默默运行的后台服务常常成为系统性能的"隐形杀手"。许多开发者突然发现系统响应变慢、内存占用飙升时,往往不会第一时间联想到这个看似无害的…...

1. NLP课程大纲
NLP 学习大纲: 自然语言处理入门 文本预处理 RNN及其变体 Transformer 迁移学习 1. 自然语言处理入门 1.1 什么是自然语言处理 计算机科学与语言学中 关注于计算机与人类语言间转换的领域 1.2 AI 的几个时间点 1️⃣ CV领域 2012年分水岭:2012年 al…...

AI Agent Harness Engineering 在房地产中的应用:智能推荐与价值评估
AI Agent Harness Engineering 在房地产中的应用:智能推荐与价值评估 引言:房地产数字化转型的「最后一公里」——智能决策的人机协同闭环 痛点引入:千亿级赛道下的三大决策「卡脖子」难题 房地产作为全球规模最大的实体产业之一(据CBRE世邦魏理仕2024年全球房地产市场报…...

Oracle EBS COA 嵌入 SAP 利润中心段:设计逻辑、哲学、思路、用途、优缺点深度分析
Oracle EBS COA 嵌入 SAP 利润中心段:设计逻辑、哲学、思路、用途、优缺点深度分析先明确核心前提: 你当前场景是集团双系统架构(SAPOracle EBS),或Oracle EBS 承接 SAP 迁移 / 数据映射,计划在 EBS 会计科…...

企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任
企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任 引言 各位正在关注 AI Agent 落地企业生产环境的技术负责人、CTO、架构师、开发者们: 去年我在国内某头部 SaaS 公司做内部 Hackathon 的评委时,看到了一支由 3 个应届毕业的计算机科学博士和 2 个资深后…...

AI检测率太高论文过不了?这4个降AI率平台2026年别再错过了
随着AI技术在学术领域的广泛应用,论文中的AI痕迹越来越容易被检测系统识别。如何有效降低AIGC率、去除AI痕迹,已成为众多学者和学生关注的焦点。依托权威检测平台数据、高校实测结果及用户真实反馈,本文将深入解析当前最值得尝试的降AI率工具…...

KNN工程落地:从距离度量到FAISS索引的生产级实践
1. 这不是“调个sklearn参数”就能糊弄过去的事:KNN背后被严重低估的工程现实“K近邻算法(K-nearest Neighbors)”,四个字,教科书里三行公式就讲完,面试官常问“它是不是懒惰学习?有没有训练过程…...

UABEA跨平台Unity资源编辑器:安全修改AssetBundle实战指南
1. 这不是又一个AssetBundle查看器,而是Unity资源编辑的“手术刀”你有没有在调试一个Unity游戏时,突然发现某个UI按钮的贴图颜色不对,或者NPC对话框的字体大小被改得离谱,但手头只有打包后的APK或EXE文件?更糟的是&am…...

Triton+KServe构建高可用ML模型服务的七道关卡
1. 项目概述:这不是一次“部署”,而是一场从实验室到产线的系统性迁移“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题里藏着太多被轻描淡写却重若千钧的词。“Notebook”不是指纸质本子,而是Jupyter里…...