大数据技术架构(组件)35——Spark:Spark Streaming(1)
2.3、Spark Streaming
2.3.0、Overview
Spark Streaming 是核心 Spark API 的扩展,它支持实时数据流的可扩展、高吞吐量、容错流处理。数据可以从许多来源(如 Kafka、Kinesis 或 TCP 套接字)获取,并且可以使用复杂的算法进行处理,这些算法由 map、reduce、join 和 window 等高级函数表示。最后,可以将处理后的数据推送到文件系统、数据库和实时仪表板。当然也可以在数据流上应用机器学习和图处理。
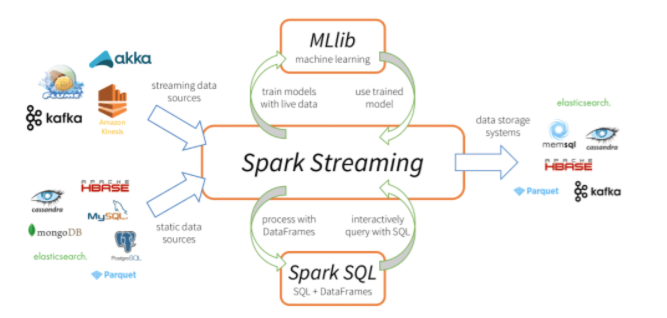
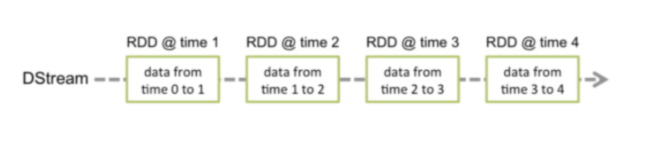
工作原理如下:Spark Streaming 接收实时输入的数据流,并将数据分成批处理,然后由 Spark 引擎处理以批处理生成最终的结果流。其中SparkStreaming提供了一种离散流或DStream的高级抽象来代表一个连续的数据流,底层就是由一系列RDD来表示。

DStream 中的每个 RDD 都包含来自某个区间的数据,如下图:
2.3.0.1、Example
import org.apache.spark._
import org.apache .spark.streaming._
import org.apache.spark.streaming.StreamingContext_ // not necessary since Spark 1.3
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new streamingContext(conf, Seconds(1))
// Create a Dstream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextstream("localhost", 9999)
// Split each line into words
val words = lines.flatMap(_.split(”"))
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this Dstream to the console
wordCounts.print()
ssc.start() // start the computation
ssc.awaitTermination() // Wait for the computation to terminate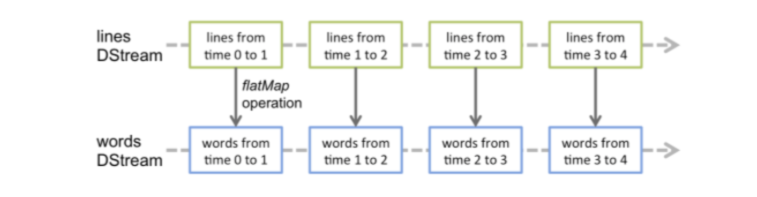
如上面的demo所示,每个输入流都会和一个Receiver对象相关联,该对象用来接收数据并将其存储在Spark内存中进行下一步的处理。因此如果你想要在流应用程序中并行接收多个数据流的话,那么就得需要创建多个Receiver对象用来接收数据。同时也需要记住的是SparkStreaming应用程序是属于常驻的,而且也是Spark程序,那么Worker/Executor也会占用一部分资源,所以为了能够保障运行Receiver以及正常处理数据,那么就需要申请到足够的资源,所以其分配的核数一定要大于receivers的个数。
2.3.0.2、Points To Remember
1、一旦Context启动之后,就不能增加或者设置新的流计算
2、一旦Context停止后,就无法重新启动。这里说的是容错方面。
3、同一时间一个JVM内只能有一个StreamingContext。
4、在StreamingContext上调用stop()方法,同时也会把SparkContext给停止;如果只是想停止StreamingContext,那么可以在调用stop()方法的时候指定stopSparkContext=false。
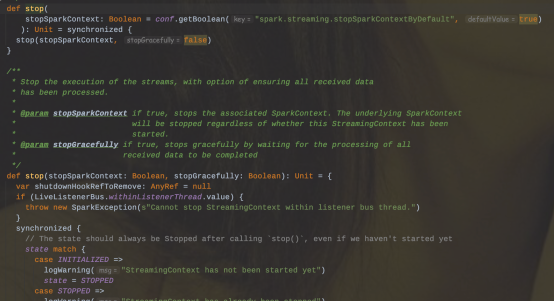
5、一个SparkContext可以被复用创建多个StreamingContext(即在下一个StreamingContext被创建之前停止上一个StreamingContext,且不停止SparkContext)
2.3.1、Receiver
SparkStreaming可以从任意的数据源来接收数据并处理,目前内置的数据源包括Kafka、File、Socket等等。当然目前Spark内置支持的数据源可以满足日常大部分的场景,但有些时候仍然需要自定义Receiver来定制接收数据源。这小节将来讲述如何实现一个自定义的Receiver。首先要继承Receiver,然后重写onStart和onStop方法。onStart()方法会在启动的时候负责接收数据;onStop()方法将停止这些接收数据的线程,当然还可以使用isStopped()方法来检查它们是否停止接收数据。
在 Spark Streaming 中,当一个 Receiver 启动时,每隔 spark.streaming.blockInterval 毫秒就会产生一个新的块,每个块都会变成 RDD 的一个分区,最终由 DStream 创建。例如,由 KafkaInputDStream 创建的 RDD 中的分区数由 batchInterval / spark.streaming.blockInterval 确定,其中 batchInterval 是将流数据分成批次的时间间隔(通过 StreamingContext 的构造函数参数设置)。例如,如果批处理间隔为 2 秒(默认),块间隔为 200 毫秒(默认),则RDD 将包含 10 个分区,还有一个流程路径涉及从迭代器接收数据,由 ReceivedBlockHandler 表示。创建 RDD 后,驱动程序的 JobScheduler 可以将其处理安排为作业。在 Spark Streaming 的当前实现和默认配置下,任何时间点只有一个作业处于活动状态(即正在执行)。因此,如果一个批次的处理时间比批次间隔长,那么下一个批次的作业将保持排队,将其设置为 1 的原因是并发作业可能会导致奇怪的资源共享,并且可能难以调试系统中是否有足够的资源来足够快地处理摄取的数据,当然可以通过实验性 Spark 属性 spark.streaming.concurrentJobs 进行更改,默认情况下设置为 1。一次只运行一个作业,不难看出,如果批处理时间小于批处理间隔,那么系统将是稳定的。
Receiver一旦接收到数据后,那么就会调用store(data)方法进行存储,这里有两种处理方式来保障Receiver是否可靠:
1、来一条存储一条,这种可靠性较差
2、存储整个对象/序列化集合。(阻塞的方式存储)
其自定义实现store()方法会影响到整体的容错和可靠。当应用程序发生了异常时应该要有捕获机制,并要有重试机制。
如果应用程序发生重启的时候,那么会调用Receiver类中的restart()方法,其内部会异步调用onStop方法并隔一定延迟后调用onStart()方法完成重启动作。
public class JavaCustomReceiver extends Receiver<String> {String host = null;int port = -1;public JavaCustomReceiver(String host_ , int port_) {super(storageLevel.MEMORY_AND_DISK_2());host = host_;port = port_;}@Overridepublic void onstart() {// Start the thread that receives data over a connectionnew Thread(this::receive).start();}@overridepublic void onstop() {// There is nothing much to do as the thread calling receive()// is designed to stop by itself if isStopped() returns false}/** Create a socket connection and receive data until receiver is stopped */private void receive() {Socket socket = nul1;String userInput = null;try {// connect to the serversocket = new Socket(host, port);BufferedReader reader = new BufferedReader(new InputstreamReader(socket.getInputstream(), StandardCharsets.UTF 8))// Until stopped or connection broken continue readingwhile (!isStopped() && (userInput = reader.readLine()) != null) {System.out.println("Received data "" + userInput + "");store(userInput);}reader.close();socket.close();// Restart in an attempt to connect again when server is active againrestart("Trying to connect again");} catch(ConnectException ce) {// restart if could not connect to serverrestart("Could not connect", ce);} catch(Throwable t) f// restart if there is any other errorrestart("Error receiving data", t);}}
}// 调用自定义Receiver:
// Assuming ssc is the JavastreamingContext
JavaDStream<String> customReceiverstream = ssc.receiverstream(new JavaCustomReceiver(host, port));
JavaDstream<String> words = customReceiverstream.flatMap(s -> ...);
...相关文章:
大数据技术架构(组件)35——Spark:Spark Streaming(1)
2.3、Spark Streaming2.3.0、OverviewSpark Streaming 是核心 Spark API 的扩展,它支持实时数据流的可扩展、高吞吐量、容错流处理。数据可以从许多来源(如 Kafka、Kinesis 或 TCP 套接字)获取,并且可以使用复杂的算法进行处理&am…...

实现超大文件上传逻辑
引言 文件上传功能是我们开发中经常会遇到的功能点,当日常开发中遇到小文件(比如:头像),可以直接将文件转为字节流直接上传到服务器上即可。但是当遇到大文件这种(比如:一部电影至少1个G)该怎么…...

JavaScript HTML DOM EventListener
JavaScript HTML DOM EventListener 是一个非常重要的概念,在前端开发中被广泛使用。它是用来监听 HTML DOM 上的事件,并执行特定的代码块。 EventListener 的语法非常简单,下面是一个示例代码: element.addEventListener("…...

构建RFID系统的重要组成部分
RFID读写设备,通常被用来扫描读取安装了RFID电子标签的目标物品,能实现快速批量无接触读写,是构建RFID系统的重要组成部分。RFID读写设备,通常有固定式读写设备和可移动读写设备两种。下面来了解一下RFID的特点,RFID系…...
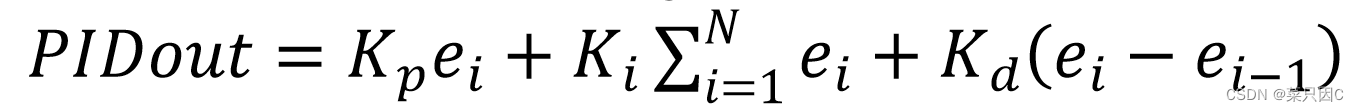
PID控制算法简介
目录 1 简介 2 比例Proportional 3 积分Integral 4 微分Differential 5 公式 6 积分限幅 7 积分限行 8 相关代码 1 简介 PID控制中有P、I、D三个参数,PID即:Proportional(比例)、Integral(积分&#…...
【王道数据结构】第八章 | 排序
目录 8.1. 排序的基本概念 8.2. 插入排序 8.2.1. 直接插入排序 8.2.2. 折半插入排序 8.2.3. 希尔排序 8.3. 交换排序 8.3.1. 冒泡排序 8.3.2. 快速排序 8.4. 选择排序 8.4.1. 简单选择排序 8.4.2. 堆排序 8.5. 归并排序和基数排序 8.5.2. 基数排序 8.1. 排序的基本概念 排…...
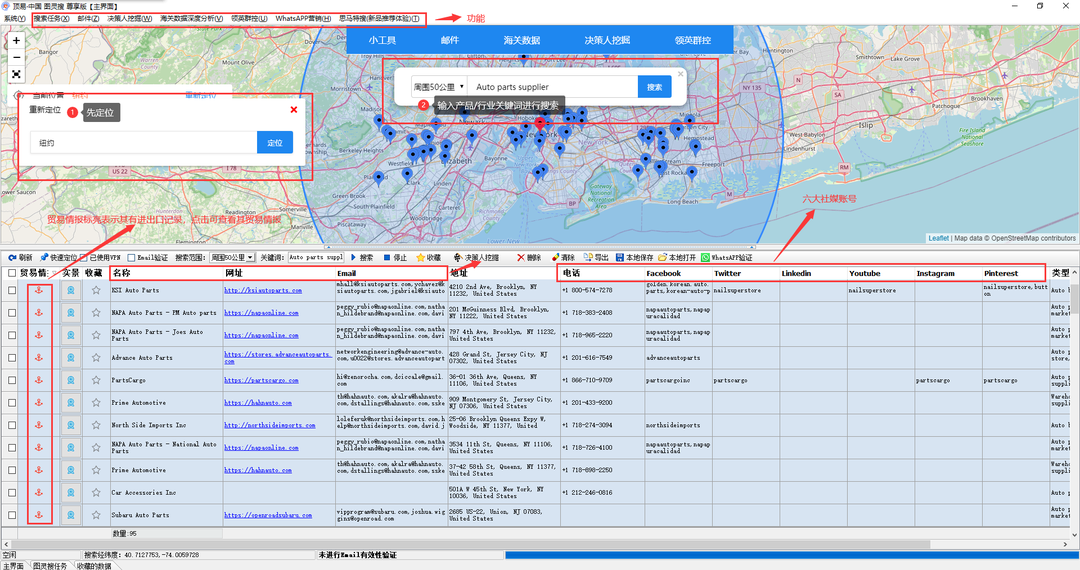
95后外贸SOHO,年入7位数,他究竟是怎么做的?
外贸SOHO,一年到底能挣多少钱?有人说:“勤勤恳恳,年薪也就十来万吧”;也有人说:“100万而已我早就已经挣到了”;还有人说:“谁说新手难出头?我做跨境半年赚200万…...
2023年全国最新消防设施操作员精选真题及答案
百分百题库提供消防设施操作员考试试题、消防设施操作员考试预测题、消防设施操作员考试真题、消防设施操作员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、多选题 15、以下符合电气火灾监控系统监控设备的安装要求的有:( ) A、…...

mysql 无需修改配置文件,即可改变表数据存储位置
由于Linux系统的mysql 默认数据存储在/var/lib/mysql路径下,而该路径装系统时默认大小仅50G,当我们的数据稍微大一点时就会把该空间占满,无法再插入数据。 针对该问题有两种解决办法: 1、修改/etc/my.cnf配置文件,重启…...

轻松解决Session-Cookie 鉴权(含坑)附代码
Session-Cookie 鉴权 cookie介绍 Cookie 存储在客户端,可随意篡改,不安全有大小限制,最大为 4kb有数量限制,一般一个浏览器对于一个网站只能存不超过 20 个 Cookie,浏览器一般只允许存放 300个 CookieCookie 是不可跨…...

pyinstaller使用详细
目录常用命令spec文件配置报错常用命令 pyinstaller -D xxx.py //打包生成目录(director)pyinstaller -F xxx.py//打包生成单个exe文件pyinstaller xxx.spec //根据现有的spec文件进行打包运行以上命令之一后会生成build、dist文件夹以及xxx.spec文件&a…...
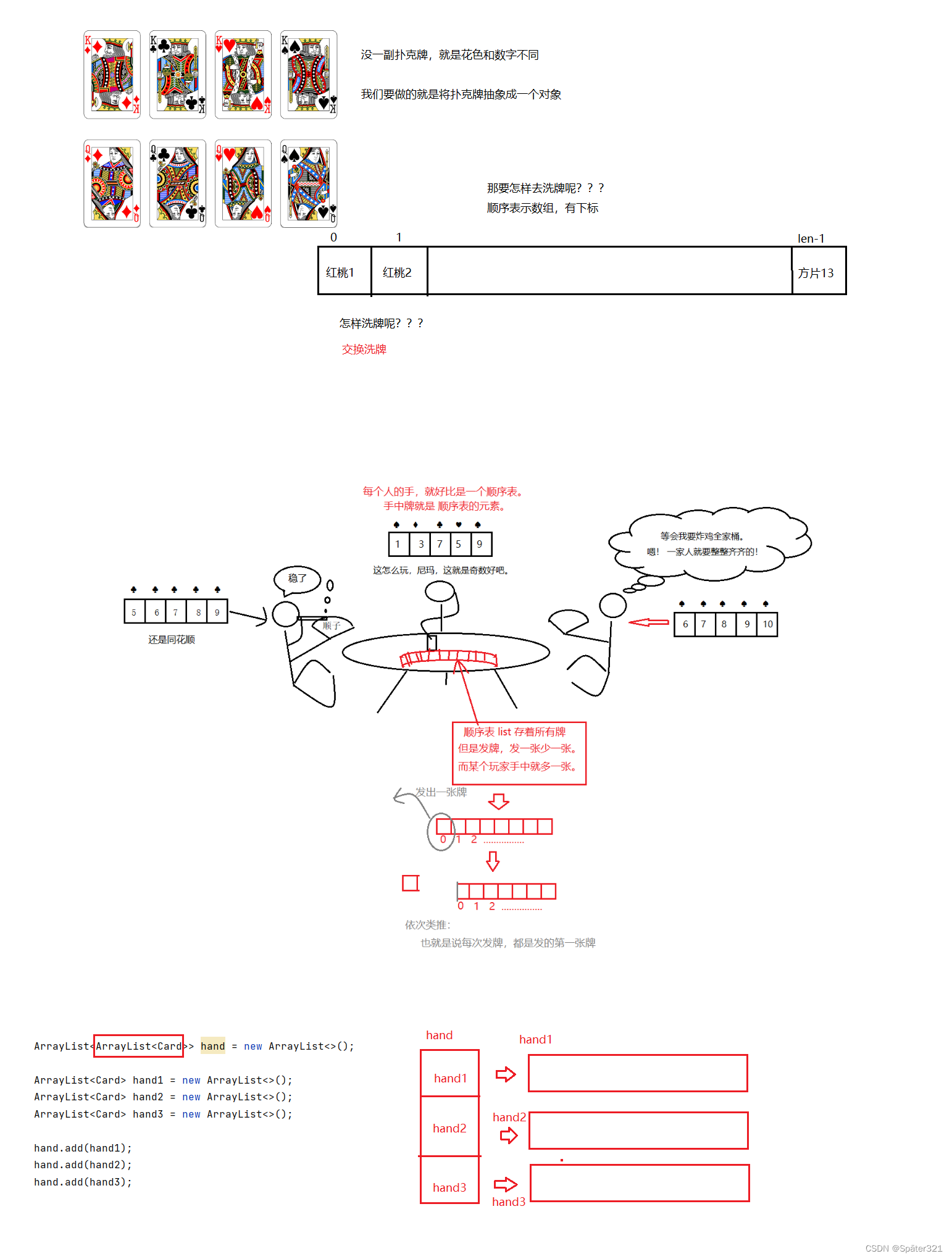
java -数据结构,List相关基础知识,ArrayList的基本使用,泛型的简单、包装类介绍
一、 预备知识-泛型(Generic) 1.1、泛型的引入 比如:我们实现一个简单的顺序表 class MyArrayList{public int[] elem;public int usedSize;public MyArrayList(){this.elem new int[10];}public void add(int key){this.elem[usedSize] key;usedSize;}public …...
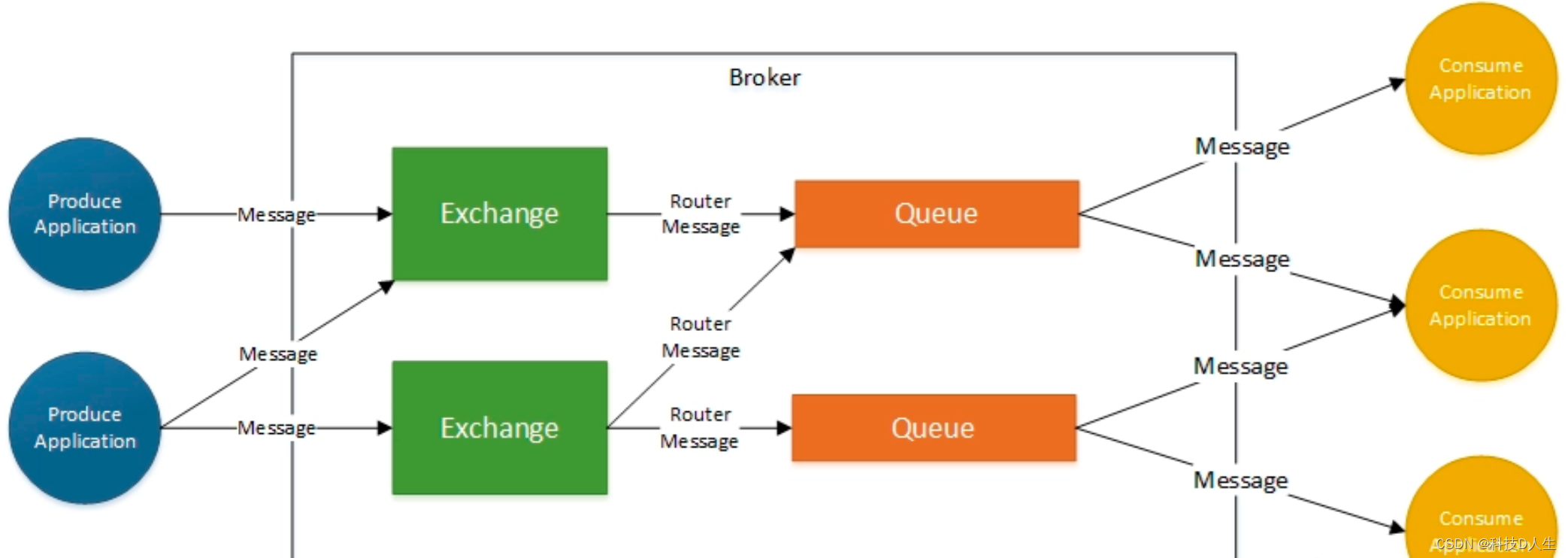
RabbitMQ学习总结(10)—— RabbitMQ如何保证消息的可靠性
一、丢失场景 RabbitMQ丢失的以下3种情况: (1)生产者:生产者发送消息至MQ的数据丢失...

购物车案例【版本为vue3】
前言: 首先我们要明白整个购物车的组成。它是由一个主页面加两个组件组合成的。本章主要运用父子之间的通讯: 父传子 子传父 首先新建一个vue3项目,这里有俩种创建方式: vue-cli : ● 输入安装指令 npm init vuelates…...

Multisim14 安装包及安装教程
Multisim14 安装教程 Multisim14下载地址:Kevin的学习站–安装包下载地址 Multisim14 简介: Multisim 14 是美国国家仪器有限公司(National Instrument,NI)推出的以 Windows 为基础、符合工业标准的、具有 SPICE 最佳仿…...

Java实现简单的图书管理系统源码+论文
简单图书管理系统设计(文末附带源码论文) 为图书管理人员编写一个图书管理系统,图书管理系统的设计主要是实现对图书的管理和相关操作,包括3个表: 图书信息表——存储图书的基本信息,包括书号、书名、作者…...
前端调试2
一、用chrome调试(node.js)例:const fs require(fs/promises);(async function() {const fileContent await fs.readFile(./package.json, {encoding: utf-8});await fs.writeFile(./package2.json, fileContent); })();1.先 node index.js 跑一下:2.然…...

AlphaFold 2 处理蛋白质折叠问题
蛋白质是一个较长的氨基酸序列,比如100个氨基酸的规模,如此长的氨基酸序列连在一起是不稳定的,它们会卷在一起,形成一个独特的3D结构,这个3D结构的形状决定了蛋白质的功能。 蛋白质结构预测(蛋白质折叠问题…...

问卷调查会遇到哪些问题?怎么解决?
提到问卷调查我们并不陌生,它经常被用作调查市场、观察某类群体的行为特征等多种调查中。通过问卷调查得出的数据能够非常真实反映出是市场的现状和变化趋势,所以大家经常使用这个方法进行调查研究。不过,很多人在进行问卷调查的时候也会遇到…...
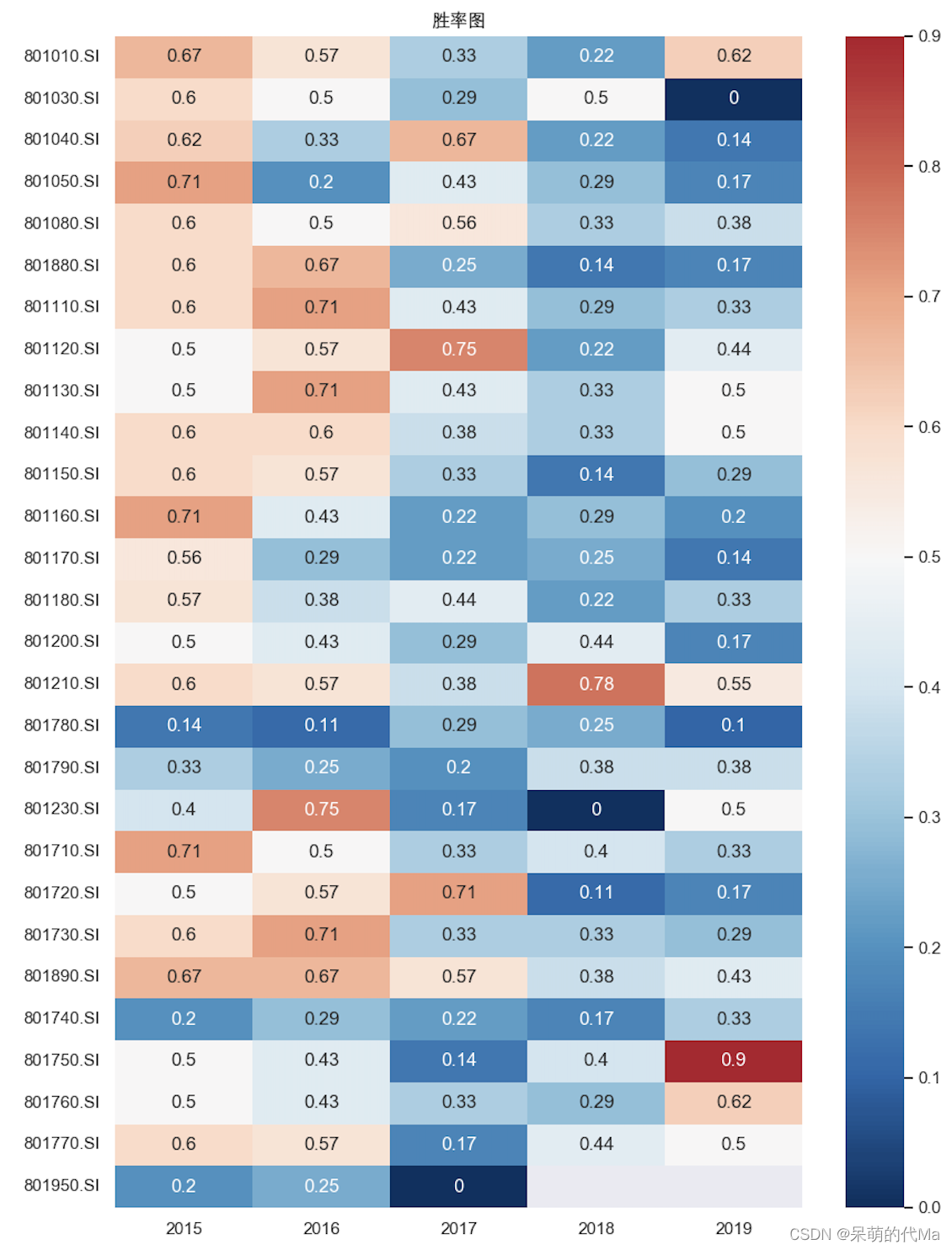
量化选股——基于动量因子的行业风格轮动策略(第1部分—因子测算)
文章目录动量因子与行业轮动概述动量因子的理解投资视角下的行业轮动现象投资者视角与奈特不确定性动量因子在行业风格上的效果测算动量因子效果测算流程概述1. 行业选择:申万一级行业2. 动量因子选择:阿隆指标(Aroon)3. 测算方法…...

LED照明技术演进中的杰文斯悖论:从节能到光污染的双刃剑效应
1. 从“省电”到“光污染”:LED照明技术的双刃剑效应作为一名在电子工程和消费电子领域摸爬滚打了十几年的从业者,我见证了一波又一波的技术浪潮。从CRT到LCD,从机械硬盘到固态硬盘,每一次技术迭代都伴随着“更高效、更节能、更便…...

中国移联AI元宇宙产业委调研阿尔特汽车科技园 构建高精尖产业的“技术-场景-商业”融合生态
(央链知播 北京讯) 5月7日,中国移动通信联合会人工智能与元宇宙产业工作委员会(简称“中国移联AI与元宇宙产业委”)、中国移动通信联合会数字文化与智慧教育分会、中国通信工业协会区块链专业委员会等机构秘书长何超带…...

别再手动下载了!用Chocolatey在Windows上一键安装Zookeeper 3.8.0
告别繁琐配置:用Chocolatey在Windows上极速部署Zookeeper 每次在Windows环境下部署Zookeeper,你是否还在重复下载压缩包、配置环境变量、修改配置文件的传统流程?对于追求效率的开发者而言,这种手动操作不仅耗时耗力,还…...

AI自主报告正常胸片:技术原理、临床价值与英国NHS实践挑战
1. 项目概述:当AI开始“读”胸片作为一名在医学影像和人工智能交叉领域摸爬滚打了十多年的从业者,我亲眼见证了AI从实验室里的新奇玩具,逐渐成长为临床医生案头一个值得信赖的“第二双眼睛”。最近,一个特别的应用场景正在全球范围…...

AI代理治理零风险上线:asqav观察模式与渐进式集成实践
1. 项目概述:在AI代理上线后,如何安全地引入治理机制你花了好几周时间,终于把那个AI代理流水线给搭起来了。从LangChain的链式调用,到精心设计的工具函数,再到与外部API的集成,每一个环节都调试得服服帖帖。…...

10x-bench-eval:量化开发效率的基准测试框架设计与实践
1. 项目概述:当“10倍速”遇上“基准测试”在软件工程领域,“10倍速工程师”是一个充满争议又令人神往的概念。它描述的是一种理想状态:一位工程师凭借其卓越的工具链、深刻的问题洞察力以及高效的自动化能力,其产出效率能达到普通…...

JSON数据高效处理:命令行工具jsoncut的查询、过滤与投影实战
1. 项目概述:一个专为JSON数据“瘦身”的利器在前后端开发、API接口调试、数据迁移或者日志分析的日常工作中,JSON格式的数据几乎无处不在。它结构清晰、易于阅读和解析,是现代数据交换的绝对主力。但随之而来的一个常见痛点就是:…...

蒙特卡洛方法赋能智能体决策:原理、实现与工程实践
1. 项目概述:一个为智能体注入“蒙特卡洛”思想的工具箱最近在探索智能体(Agent)开发时,我一直在思考一个问题:如何让智能体的决策过程不那么“一根筋”?我们常见的基于规则或简单LLM调用的智能体ÿ…...
)
Sora 2生成素材在AE中频繁掉帧?20年合成老炮儿用CUDA Graph重构图层管线,性能提升3.8倍(含Profile对比图)
更多请点击: https://intelliparadigm.com 第一章:Sora 2生成素材在AE中频繁掉帧?20年合成老炮儿用CUDA Graph重构图层管线,性能提升3.8倍(含Profile对比图) 当Sora 2输出的4K/60fps高动态范围视频序列导入…...

硅应变计与Σ-Δ ADC协同设计及温度补偿技术
1. 硅应变计与Σ-Δ ADC的协同优势解析硅基应变计在现代传感器领域占据重要地位,其核心原理基于压阻效应——当硅材料发生机械形变时,晶格结构变化导致载流子迁移率改变,从而引起电阻值变化。与传统金属箔应变计相比,硅应变计的灵…...