Python蒙特卡罗MCMC:优化Metropolis-Hastings采样策略Fisher矩阵计算参数推断应用—模拟与真实数据...
全文链接:https://tecdat.cn/?p=38397
本文介绍了其在过去几年中的最新开发成果,特别阐述了两种有助于提升 Metropolis - Hastings 采样性能的新要素:跳跃因子的自适应算法以及逆 Fisher 矩阵的计算,该逆 Fisher 矩阵可用作提议密度(点击文末“阅读原文”获取完整代码数据)。
通过多个示例展示,这些特性可加快收敛速度,在协方差矩阵先验知识不足的复杂运行情况下,能节省数百 CPU 小时。
Metropolis-Hastings 采样策略
蒙特卡罗 Python 可以在不同的参数空间探索方式之间切换,包括 Metropolis - Hastings、嵌套采样、Cosmo Hammer 以及描述的一种新的 Fisher 采样方法。这些不同的算法在代码中被称为方法,相同的方法列表还包括后处理算法,如重要性采样或添加派生参数。
(一)快速采样
在蒙特卡罗 Python 中,Metropolis - Hastings 从高斯提议密度在参数空间中进行随机跳跃。后者被编码在一个矩阵 CC 中,描述了参数相关性和彼此相对的标准差,以及一个整体跳跃参数 c,使得参数跳跃 Δp从概率分布 P=Nexp(−12cΔpTC−1Δp)中随机生成。因此,提议密度的实际协方差矩阵为 cC。
在没有快速采样的情况下,跳跃可以每次独立地从 PP 中随机生成(全局方法),或者沿着 CC 的 NN 个特征向量中的每一个进行 NN 次抽取的循环(顺序方法)。这些方法在蒙特卡罗 Python 中仍然可以激活,但在存在带有干扰参数的似然函数时,它们并非最优。快速采样用于 MCMC 参数估计。对于这种采样方法,我们将快速干扰参数和慢速参数的采样分开,以在处理大量快速干扰参数 Nfast时优化性能。沿着特征向量生成位移会混合慢速和快速参数,并且不允许仅对快速参数空间进行高速探索。但是引入特征向量并不是转换到提议密度正交的参数基的唯一方法。特别是,可以对协方差矩阵进行 Cholesky 分解为 C=LLT,其中 LL 是下三角矩阵。在通过 Δp0=L−1Δp 与物理参数相关的向量 Δp0 的空间中,提议密度是正交的,因此可以通过为 Δp0的每个分量绘制方差为 c 的一维高斯概率分布的随机数,并投影回 Δp=LΔp0 来轻松生成跳跃。与之前基于特征向量的方案相比,其巨大优势在于当 Δp0仅在给定索引之上具有非零分量时,对于 Δp也是如此。因此可以生成一些不会改变慢速参数的跳跃。我们首先根据计算时间将输入参数按块排序。
在实践中,这可以通过在输入参数文件中以正确的顺序编写它们来简单实现。第一个块是需要对玻尔兹曼代码进行新调用的参数。接下来的块是给定似然函数的干扰参数,如果参数保持固定,则可以在不要求对玻尔兹曼代码进行评估的情况下更改这些参数。干扰参数块应从最慢到最快的似然函数排序。当一个干扰参数在多个似然函数中通用时,应仅在最慢的块中声明。我们称 MM 为块的数量,djdj 为第 jj 个块中的参数数量,其中 d1=Nslow 是参数的数量。蒙特卡罗 Python 将自动检测块的数量 MM,并期望用户传递一个 MM 维的过采样向量 FF。F1F1 是参数的过采样因子,通常固定为 1。其他条目是其他每个块所需的冗余采样数量。在运行链时,对于 j=1,⋯,M,我们在与第 jj 个块对应的 Δp0的 dj 个组件中生成 Fjdj个随机跳跃序列。换句话说,在 Fjdj步期间,我们为 Δp0的每个相关组件生成 djdj 个随机数,这些随机数从标准方差为 c=j2/dj的高斯分布中抽取。因此,每个完整周期由 ∑jFjdj个随机跳跃组成,其中只有 F1d1=Ns 个需要调用玻尔兹曼代码。稍后我们将这个数字称为快速参数乘数(FPM)。
# 以下是示例代码,用于展示相关计算过程(非完整代码)
# 假设已经有了协方差矩阵 C 和其他相关参数定义
import numpy as np
# 进行 Cholesky 分解
L = np.linalg.cholesky(C)
# 生成随机数(这里简化示意,实际可能更复杂)
delta_p0 = np.random.normal(0, j**2 / dj, (dj,))
# 投影回原始参数空间
delta\_p = np.dot(L, delta\_p0)
没有精确的规则来确定过采样因子 F2,⋯,FN。对于更快的似然函数和/或块中更多的干扰参数,应增加这些因子。如果数量过低,则无法享受快慢参数分解的优势。如果数量过高,则在快速参数的(∑jFjdj−Ns)次迭代中花费的时间可能与在慢速参数的 Ns次迭代中花费的时间相比显著增加,并且参数结果的收敛将被延迟。
(二)更新和超级更新
虽然 Metropolis - Hastings 算法原则上需要马尔可夫链,即具有随时间恒定的提议密度的链,但非常希望实现一些自动更新算法,以便即使从高斯提议密度的不良猜测开始也能获得收敛结果。我们回顾一下,提议密度被参数化为 P=Nexp(−12cΔpTC−1Δp),因此取决于两个量,协方差矩阵 CC 和与跳跃因子 jj 相关的跳跃参数 cc。蒙特卡罗 Python 有两个互补选项来加速 Metropolis - Hastings 运行的收敛:
--update U:每 UU 个周期更新协方差矩阵 CC [默认:U=50]--superupdate SU:此外,在每次协方差矩阵更新后开始 SUSU 个周期更新跳跃因子 jj [默认:SU=0,表示“未激活”;推荐:20]
一旦满足某些标准,协方差矩阵将定期更新,并且跳跃因子将在每一步进行调整。这会显著改善运行时间,特别是对于在先验知识较少(例如适当的起始步长或良好的初始提议分布)的情况下的运行。在接下来的两节中,我们将描述这两种方案所选择的策略。
1. 更新策略
蒙特卡罗 Python 和 CosmoMC 对该功能的实现非常相似。例如,在两个代码中,启动或停止更新机制的决定取决于 Gelman - Rubin 统计量 R 的值,对于收敛最差的参数。当从每个链的后半部分计算的最大(R−1)低于 3 时开始更新,当低于 0.4 时停止更新。两个实现之间的差异仅在于两个方面:
非 MPI 用户友好性。启动多个链的最直接方法是使用 MPI 运行蒙特卡罗 Python,例如对于 8 个链:
mpirun -np 8 python montepython/MontePython.py run...。另一种选择是手动启动 8 个链,或者在带有 for 循环的小 shell 脚本中启动。对于 CosmoMC,第二种选择与协方差矩阵更新不兼容。在蒙特卡罗 Python 中,由于安装 MPI 有时可能很麻烦,我们选择以这样一种方式编码--update机制,使其在有或没有 MPI 的情况下都能正常工作。在后一种情况下,用户只需多次运行python montepython/MontePython.py run...,更新机制仍将启动并使用在同一目录中运行的所有链的信息。在最终结果中仅保留马尔可夫步骤。严格来说,用户希望基于真正的马尔可夫链获得最终结果和绘图。这是蒙特卡罗 Python 的默认行为。实际上,每次协方差矩阵更新时,代码都会在所有链文件中写入以
# After accepted steps: update proposal...开头的注释行,其中还包含有关当前收敛的信息(因此这些注释也可用于仔细检查运行情况)。当使用 info 模式分析链时,默认情况下,代码将仅考虑最后一次更新后的链部分,即马尔可夫部分。如果用户想要停用此行为以在链中获得更多点,可以使用--keep - non - markovian标志。
最后,更新周期由 UU 输入参数控制(默认:U=50),以周期为单位。鉴于一个周期由 FPM 步组成(见公式(1)),更新每 U×FPMU×FPM 步发生一次。
2. 超级更新策略
协方差矩阵更新并不能完全自动实现达到最佳收敛条件的任务。提议密度的另一部分是与跳跃因子 jj 相关的跳跃参数 cc。如果 jj 太大,接受率(a.r.)太小,接受的模型数量不足以提取统计信息。如果 jj 太小,a.r. 可能接近 1。在这种情况下,链会迅速增长,但相邻点将高度相关,并且链不一定会对整个后验分布进行采样。因此,应该寻求接受率的折衷值。虽然对于多元高斯后验,f=2.4符合此目标,但许多运行针对非高斯后验,例如由于参数的非平凡先验(如要求中微子质量为正)或干扰参数的强烈非高斯后验(如普朗克高 似然函数的那些)。当前的做法是进行一些尝试并手动尝试不同的 $f$ 值,直到接受率正确。例如,人们很快就会知道,例如,特定版本的普朗克似然函数通常需要特定的 $f$ 值才能实现 a.r. $\approx 0.25$。当然,最好让代码为模型和数据集的每种组合自动找到此值。
自动跳跃因子自适应还将使代码在从非常差的提议密度开始时更强大(例如,当向先前的运行添加许多新的自由参数时,或者当仅在约束性差得多的集合的协方差矩阵可用时研究一组非常有约束性的似然函数时)。超级更新的基本原理是根据递归关系在每一步调整跳跃因子:
# 示例代码示意(非完整代码)
# 假设相关参数已定义
k_update = 0 # 第一个序列的起始步编号
for k in range(1, total_steps + 1):if k >= k_update + SU * FPM:# 计算跳跃因子更新(这里简化示意,实际有更多逻辑)j\_new = j * (target\_a.r. / a.r.) ** (1.0 / (k - k_update))其中 kk 是当前步编号,而 kupdate 是每个新“更新序列”的第一步编号。对于第一个序列,kupdate=0。此递归关系导致在每个新序列开始时更快地更新,并在一段时间后具有更慢的更新和安全的收敛特性。
开始跳跃因子更新:当满足两个条件时,代码开始应用递归关系(3):
我们不想过早更新提议分布,因为它可能基于仍处于燃烧阶段的链。因此,我们等待链达到一定的收敛水平:从每个链的后半部分计算的(R−1R−1)对于所有参数应低于 10。
我们等待自新“更新序列”开始以来已经完成了 SU 个周期,或者如果我们仍处于第一个序列,则从一开始就等待:(k−kupdate)≥SU×FPM。由于平均接受率 a.r. 是在最后 SU 个周期上计算的,因此递归将仅考虑来自相同“更新序列”的一些步骤。选择 SU≥20 可确保平均接受率不会在过小的样本上计算,在这种情况下,散粒噪声可能导致接受率与目标值显著不同(即由于接受率的随机波动导致过早停止跳跃因子的适应)。我们建议使用 SU=20,因为我们发现这是效率和精度之间的良好折衷,但也可以考虑更高的值,以减少超级更新的影响(跳跃因子将稍后开始演变并进行较小的偏移)或进一步减少散粒噪声对跳跃因子确定的影响。请注意,当 SU>U时,超级更新有时仅在协方差矩阵的最后一次更新之后才会在运行的最后阶段激活,此时收敛已经良好(或者可能在链尚未充分收敛以开始更新协方差矩阵之前)。因此,通常应仅考虑 20≤SU<U 的范围。当协方差矩阵更新时的重新缩放:由于高斯提议密度的真实协方差矩阵实际上由乘积 cC 给出,因此在每个新“更新周期”开始时更新矩阵 CC 时,将 cc 保持不变将是次优的。例如,假设在第 n 个“更新周期”中,已经找到了与协方差矩阵 CnCn 相结合的良好跳跃因子 cn(这意味着接受率具有正确的数量级)。如果在下一个周期开始时,矩阵适应为小得多的 Cn+1,而 cn+1 从相同的值 cn 重新开始,那么显然整个提议密度将缩小并且接受率将增加太多。我们可以通过分析要求在每次协方差矩阵更新时,整个提议密度所探测的体积保持恒定来限制这种影响,这可以简单地通过施加:
# 示例代码示意(非完整代码)
# 假设相关参数已定义
N = total_parameters # 自由(慢 + 快)参数的数量
c\_n1 = c\_n * (np.linalg.det(C\_n) / np.linalg.det(C\_n1)) ** (1.0 / N)其中 N 是自由(慢 + 快)参数的数量。当协方差矩阵的演变仅来自一个或几个参数时,这种重新缩放可能不是非常有效,但总的来说,这是可以做出的最佳简单猜测。就跳跃因子而言,这给出:
# 示例代码示意(非完整代码)
# 假设相关参数已定义
j\_n1 = j\_n * (np.linalg.det(C\_n) / np.linalg.det(C\_n1)) ** (1.0 / (2 * N))请注意,对于协方差矩阵的第一次更新,这种重新缩放背后的逻辑不成立。实际上,如果我们从较差的输入协方差矩阵开始,跳跃因子的第一次重新缩放可能完全不切实际。为了安全起见,在第一次更新时,我们将跳跃因子重置为输入值(通过 --f 提供 [默认:2.4])。
停止跳跃因子更新:我们调整跳跃参数,直到满足三个条件:
接受率应收敛到 26%,容差为 1 个百分点(在许多情况下,接受率开始较低并增加到最佳值,然后当代码达到 25% 时适应将停止):
# 示例代码示意(非完整代码)
# 假设相关参数已定义
if abs(a.r. - 0.26) <= 0.01:stop\_jump\_factor_update = True除了接受率标准之外,为了停止跳跃参数的适应,我们还要求它是稳定的:
# 示例代码示意(非完整代码)
# 假设相关参数已定义
if abs(c - c_mean) <= tolerance: # tolerance 为设定的稳定阈值stop\_jump\_factor_update = True其中 c¯是最后 SU×FPM 步的跳跃参数的平均值。此外,我们不希望允许跳跃参数收敛到任意低的值,因为链陷入局部最小值的风险会增加。因此,我们引入跳跃因子的最小值,对应于初始跳跃因子的 10%。如果需要较小的跳跃参数,建议使用 --f 输入较低的值。
最后,我们要求从链的后半部分计算的最大(R−1)对于所有参数低于 0.4:这与停止协方差矩阵更新的条件相同。因此,超级更新机制将仅在最终的“更新序列”中停止其活动,在此期间可以积累大量真正的马尔可夫步骤(使用恒定的提议密度生成)。
非 MPI 用户友好性:我们在蒙特卡罗 Python 中以与更新机制相同的编码原则实现了超级更新机制。因此,由于链之间的通信通过文件而不是 MPI 命令进行,它也可以在有或没有 MPI 的情况下使用。在运行目录中,文件jumping_factors.txt存储了所有已使用的跳跃因子序列,而文件jumping_factor.txt仅包含最终的跳跃因子,可在下一次运行中用作输入值。当使用--restart命令在同一目录中重新启动链时,这将自动完成。
在最终结果中仅保留马尔可夫步骤:当--superupdate被激活时,代码仍会在每个新“更新周期”开始时在链中写入一些注释行,其中包含有关当前最大(R−1R−1)、jj 和 a.r. 值的信息。此外,当跳跃因子更新停止时,它会写入一行额外的注释。当在 info 模式下分析链时,除非用户传递选项--keep - non - markovian,否则之前的所有行都将被丢弃,最终的数字和绘图将基于纯粹的马尔可夫链。
单链运行的替代实现:超级更新机制原则上需要多个链,因为它使用基于 Gelman - Rubin 统计量的收敛测试。对于单链运行,代码将链拆分为三个单独的链以计算 Gelman - Rubin 统计量,这种做法可能比运行多个链不太可靠。此其他机制由标志--adaptive而不是--superupdate激活。它不使用 Gelman - Rubin 统计量。
Fisher 矩阵
著名的 Fisher 矩阵由有效 χ2相对于模型参数在 χ2 最小值(即似然最大值)处的二阶导数构建而成:
# 示例代码示意(非完整代码)
# 假设相关函数和参数已定义
def fisher_matrix(parameters):# 计算二阶导数(这里简化示意,实际计算可能更复杂)second\_derivatives = calculate\_second_derivatives(parameters)return second_derivatives根据最大似然点的定义,Fisher 矩阵必须是正定且可逆的。其逆矩阵是似然在最佳拟合点附近的高斯近似的协方差矩阵。如果二阶导数矩阵不是在该点计算的,则它可能不可逆。
(一)计算 Fisher 矩阵的动机
我们在Python v3.0.0 中使用有限差分法直接从似然和公式(8)计算 Fisher 矩阵,我们将在下一节详细介绍。此计算背后有两个动机:
1. 加速 MCMC 运行
逆 Fisher 矩阵可用作 MCMC 运行(例如 Metropolis - Hastings)的输入协方差矩阵。在这种情况下,我们不需要对该矩阵进行高精度计算,因为任何近似结果都可能是一个足够好的猜测,Metropolis - Hastings“更新”机制无论如何都会迅速改进。这种方法在大多数情况下会显著加速,因为很少有人在开始 MCMC 运行时就已经有一个非常好的包括所有参数对的协方差矩阵。不过,该方法只有在代码首先找到可逆的 Fisher 矩阵时才有效,而这仅在精确的最大似然点处得到保证。根据运行类型,实现这一条件可能容易或困难:
对于使用模拟数据的参数预测,我们通常使用基准光谱作为观测光谱,而不生成随机实现。因此,最大似然恰好与基准模型重合,用户事先知道该模型。然后,新的 Fisher 方法效果特别好。
对于从真实数据中提取参数,我们最多知道最佳拟合点的近似值。然后,人们可能希望,如果真实和近似最佳拟合点之间的距离与有限差分法中使用的步长相比很小,则在后一点计算的近似 Fisher 矩阵仍将是正定且可逆的。然而,我们发现这种情况并不经常发生,因此将这种新方法用于真实数据的可能性仍然有些不确定。为了增加机会,我们在蒙特卡罗 Python 中纳入了一些来自
optimizePython 库的最小化算法,这至少可以帮助在尝试 Fisher 矩阵计算之前更接近真实的最佳拟合点。然而,我们的测试表明,目前实现的最小化算法不是非常稳健,特别是在存在许多干扰参数的情况下。
总之,新的 Fisher 计算肯定会改善所有 MCMC 预测并且它也可能改善使用真实数据的 MCMC 运行,除非最终得到的似然形状对于找到最小值和/或运行 Fisher 算法来说过于复杂。
2. 替代 MCMC 运行
当知道给定运行的后验应该接近高斯分布,或者当对后验的细节不感兴趣(例如具有一些偏度、峰度、香蕉形状等的非平凡参数相关性)时,很想用简单的 Fisher 矩阵计算来替代整个 MCMC 参数提取运行。然后,逆 Fisher 矩阵将给出一些近似的一维置信区域和二维椭圆轮廓。这对于灵敏度预测尤其直接,因为在那种情况下,最大似然点事先已知。如果最大似然点已知到良好的近似值,例如在使用蒙特卡罗 Python 的新 --minimize 选项运行之后(其成功并非保证),也可以设想用于真实数据。
在文献中,绝大多数参数预测基于 Fisher 矩阵计算。这些通常由特定代码执行,利用在几步解析计算之后,FijFij 可以重新表示为可观测量相对于参数的导数的函数(例如 ∂C‘/∂pi 或 ∂P(k)/∂pi)。相反,蒙特卡罗 Python 执行的 Fisher 矩阵计算是基于直接似然评估,因为我们计算 ∂lnL/∂pi。这两种方法在数学上是等价的,但后者可能提供一些实际优势。实际上,主要用于模拟给定实验的量是似然。跳过导致像 ∂C‘/∂pi或 ∂P(k)/∂pi这样的导数的解析步骤有时可以避免复杂的表达式、引入近似的需要以及进一步出错的风险。
在这两种方法中,都必须使用给定的步长计算一些数值导数。对于纯高斯似然,步长应该无关紧要,只要它不是太小以至于数值误差(来自玻尔兹曼代码或似然代码)开始占主导地位。通常,玻尔兹曼代码经过优化,以便为最具约束性的实验(通常是现在的普朗克实验)提供 χ2eff 的精度约为 δχ2∼O(10−1),因为实现更好的精度不会改变置信区间的结果,因此将是浪费计算时间。因此,使用使得:
# 示例代码示意(非完整代码)
# 假设相关参数已定义
if step\_size < 0.1 / some\_factor: # some_factor 根据具体情况确定step\_size = 0.1 / some\_factor显著小于 0.1 的步长 Δpi是危险的。这大致提供了 ΔpiΔpi 的下限。上限的问题更加微妙,特别是当似然不是高斯分布时:不同的选择可能会返回显著不同的 Fisher 矩阵和置信限。在这个问题上,社区存在不同的方法。一种观点建议使用尽可能小的步长,直到数值噪声起作用,以便尽可能接近二阶导数的数学定义。另一种观点更喜欢选择步长,使得如果最终目标是为参数提供 68%(或 95%)置信限的预测,则 Δχ2≈1(或 4),因为在那种情况下,Fisher 矩阵给出的似然的高斯近似恰好在与参数界限相关的区域内有效。许多 Fisher 代码甚至没有针对 Δχ2 的任何特定给定数量级,并且任意选择步长 Δpi。在 Python v3.0.0 中,我们通过让用户选择 ΔlnL=2Δχ2的目标值来解决这个问题。默认情况下,代码将首先尝试使用 ΔlnL∼0.1 获得可逆的 Fisher 矩阵,并在结果不可逆的情况下迭代增加该值,如下一节所述。然而,用户可以选择 ΔlnL的第一个值,例如可以将其设置为 0.5 或 2(使用标志 --fisher - delta)。
(二)从逆 Fisher 矩阵绘制似然轮廓
拥有 Fisher 矩阵及其逆矩阵后,用户可以轻松编写一个小脚本,绘制对应于参数空间中二维置信水平的椭圆。蒙特卡罗 Python 本身无法做到这一点,它只能在存在一些 MCMC 链时进行绘图。然而,蒙特卡罗 Python 的绘图工具对于比较 MCMC 运行结果与逆 Fisher 矩阵给出的高斯后验近似很有用。为此,可以使用通常的 info 模式分析蒙特卡罗 Python 结果,只需添加一个输入标志:--plot - fisher。然后代码将检查是否在用户尝试绘制的链所在的同一目录中计算并存储了 Fisher 矩阵。如果是这种情况,Fisher 椭圆将绘制在 MCMC 轮廓之上,如图 所示。
y2 = info.extent\[3\]ax2dsub.fill_between(x95,y1,y2,facecolor=contour_color\[0\],edgecolor=contour_color\[1\],linewidth=1,alpha=contour_alpha)ax2dsub.fill_between(x68,y1,y2,color=contour_color\[1\],alpha=contour_alpha)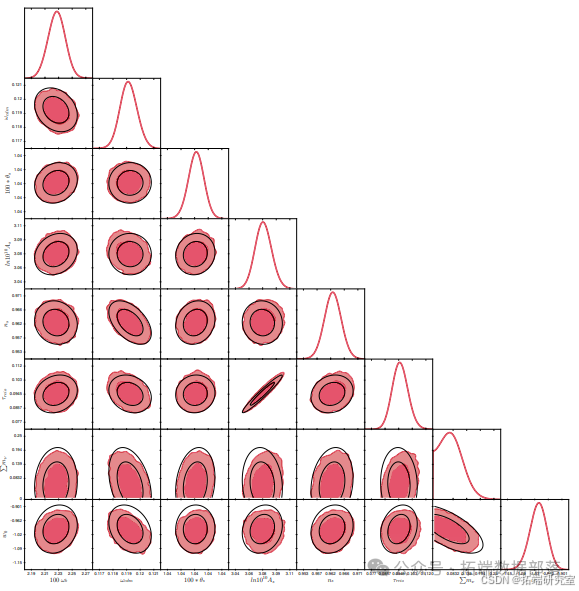
此图显示了基于来自 DESI 调查的模拟 BAO 数据与普朗克数据相结合的灵敏度预测,用于具有大质量中微子和动态暗能量的模型(νwCDM,8 个自由参数)。实际上,Fisher 矩阵在启动链之前计算,其逆矩阵用作输入协方差矩阵。最终的 MCMC 轮廓证明在这种情况下,Fisher 近似非常出色。这个逆 Fisher 矩阵不仅为 MCMC 运行提供了良好的提议密度,还给出了参数界限的出色估计,并且可以替代整个 MCMC 结果。可能会出现这样的情况:首先在最佳拟合点的猜测周围计算 Fisher 矩阵,然后使用它来启动将以真实最佳拟合点为中心的 MCMC 链(在高斯后验的情况下)。
点击标题查阅往期内容

课程视频|R语言bnlearn包:贝叶斯网络的构造及参数学习的原理和实例

左右滑动查看更多
01
02
03
04
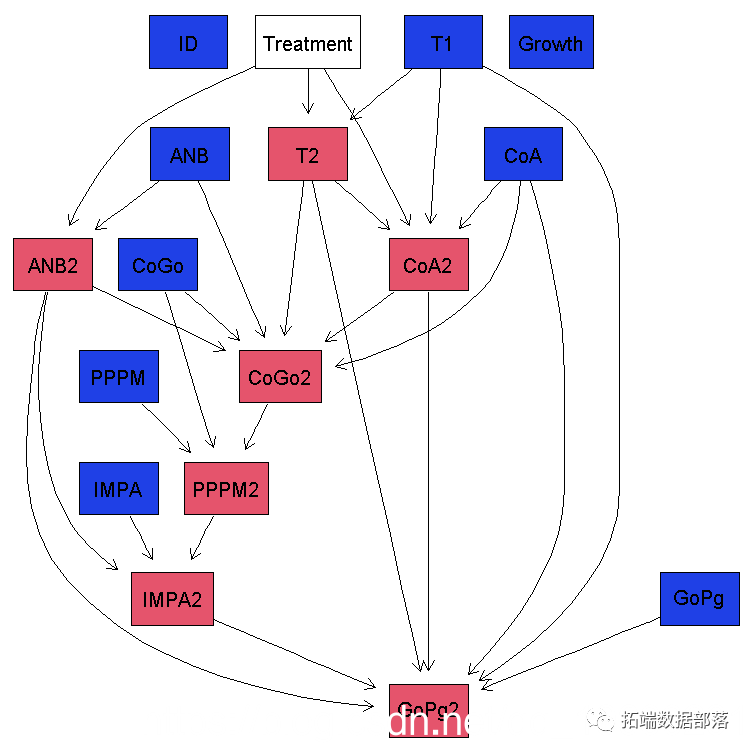
在比较图中,可能会发现 Fisher 椭圆形状正确,但相对于真实最佳拟合点有偏移。为了获得更好的图,蒙特卡罗 Python 用户可以使用输入标志 --center - fisher。这将自动将 Fisher 椭圆中心定位在从 MCMC 链中提取的最大似然点上,而不是使用在 log.param 文件中读取的中心值,即使 Fisher 矩阵实际上是在该点计算的。
性能示例
为了说明超级更新的性能以及使用逆 Fisher 矩阵作为输入协方差矩阵的影响,我们选择了一些数据集和模型,并在使用或不使用这些不同选项的情况下进行了一些拟合。在最困难的情况下进行比较特别有趣:大量自由参数、先验知识少(即对输入协方差矩阵的猜测不佳)等。
(一)先验知识少的预测
我们首先对来自 DESI 调查的模拟 BAO 数据和普朗克数据的组合进行一些 MCMC 预测。我们使用名为 fake_desi_vol 的模拟 DESI 似然函数(在附录 D 中有文档记录)。对于预测,我们不需要使用真实的普朗克数据。相反,我们使用一种大致模拟普朗克卫星近似情况的似然函数,但使用与普朗克最佳拟合模型对应的一些合成数据。这个似然函数称为 fake_planck_realistic。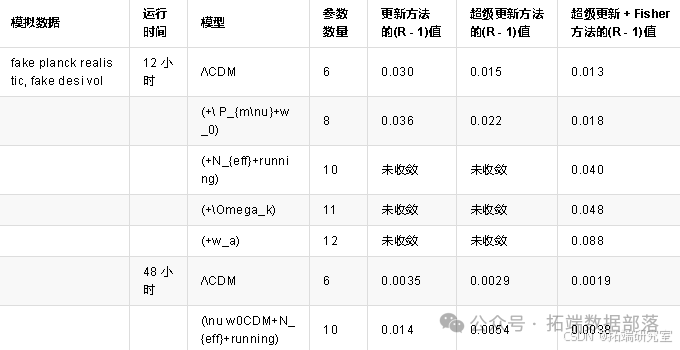
表 1:对于模拟数据和几个模型,使用 Gelman - Rubin 收敛准则比较三种采样选项。
我们使用最小的 6参数 ΛCDM模型以及几个具有多达 12 个自由参数的扩展模型来拟合这些数据集。这些扩展列在表 1 的第一列中,包括大质量中微子、具有恒定状态方程的动态暗能量、额外的相对论自由度、原始谱指数的跑动、空间曲率,以及最后具有 CPL 参数化的动态暗能量。我们在这些不同情况下使用 Metropolis - Hastings 算法和三种不同方法运行蒙特卡罗 Python:
update [--update]:协方差矩阵的定期更新,superupdate [--superupdate]:跳跃因子的额外自适应,superupdate + Fisher [首先 --method Fisher;然后 --superupdate]:相同,但从蒙特卡罗 Python 计算的逆 Fisher 矩阵开始。
对于更新和超级更新运行,提议密度初始化为“普朗克 2015 协方差矩阵”,即作为蒙特卡罗 Python 包公开分发的协方差矩阵,该矩阵源自基于普朗克 2015 似然函数的良好收敛运行的分析,并假设 6 参数 ΛCDM 模型。此外,在这两次运行中,跳跃因子最初设置为 2.4(因此在更新方法中它保持等于此值)。对于 Fisher 矩阵计算,我们将用于生成模拟数据的精确最佳拟合模型传递给代码。对于每个模型和方法,我们使用 8 个链启动代码,其中每个链在 6 个核心上运行,总共使用 48 个核心。在 12 或 48 小时后,我们计算所有参数上的较差收敛准则(R−1),去除每个链的初始 10 - 20%(取决于燃烧阶段的持续时间,但对于给定的模型和实验组合始终相同)。
这些运行的困难在于对输入协方差矩阵的不良猜测。在六参数运行中,输入协方差矩阵仅来自普朗克数据,而 DESI BAO 数据非常具有约束性。这意味着提议密度最初太宽,需要收缩到 DESI 数据允许的小区域。当添加额外参数时,情况更糟。对于额外参数,代码不依赖于输入协方差矩阵,而是依赖于输入文件中写入的标准偏差(对于这些我们插入普朗克误差条)。因此,提议密度需要学习这些新方向上跳跃的正确数量级以及涉及额外参数的参数相关性。
我们发现,对于最简单的模型(6 和 8 个参数),所有三种方法都成功地至少获得了 R−1=0.03的收敛,尽管超级更新和超级更新 + Fisher 表现更好,获得的 R−1小达 2 倍。对于更复杂的模型(10、11 和 12 个参数),从 Fisher 矩阵开始并使用超级更新产生了很大的差异,因为只有从 Fisher 矩阵开始的运行在限制我们仅运行 12 小时的情况下设法获得了任何收敛水平。然而,如果我们允许更长的运行时间(48 小时),更新和超级更新方法也设法收敛,这得益于协方差矩阵的定期更新,超级更新和超级更新 + Fisher 运行显示出比单独更新好 2.6 到 3.7 倍的收敛性。图 2 明确显示了为什么跳跃因子自适应和 Fisher 矩阵计算会导致此运行收敛速度显著加快。
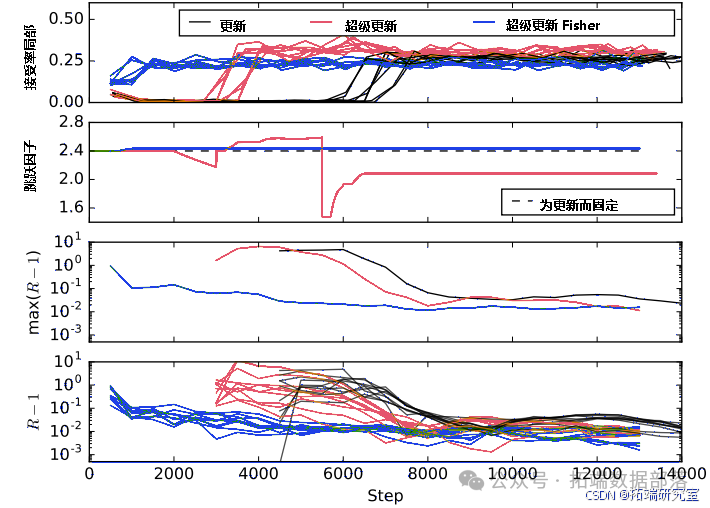
图 2:表 1 中最后一次运行(10 参数模型,模拟普朗克 + DESI,48 小时)的接受率、跳跃因子和收敛估计量的演变,使用 U=50,SU=20,FPM=10,因此 Nupdate=500。跳跃因子信息在每一步更新,而关于(R−1)的信息每 Nupdate步更新(在链的最后 50% 上计算)。此信息始终可以从代码输出中提取。相反,上图中的局部接受率是为了绘制此图而对链进行后处理计算的,并且通过在大约 500 步上平均来定义(因此这与超级更新算法使用的量 a.r. 略有不同,后者仅在 SU×FPM=200 步上平均)。“Fisher”运行从一开始就基本上捕获了正确的协方差矩阵、跳跃因子和接受率。“超级更新”运行减小其跳跃因子以快速积累许多点并获得良好的协方差矩阵估计;一旦完成,它会增加跳跃因子以避免接受率过大。最后,“更新”运行在进入具有良好协方差矩阵和接受率的有效采样制度之前需要大约 3500 多个步,这在我们的 48 个核上对应于大约 12 小时:因此我们可以说在这个特定示例中,“超级更新”为单次运行节省了大约 600 小时。
(二)当前数据
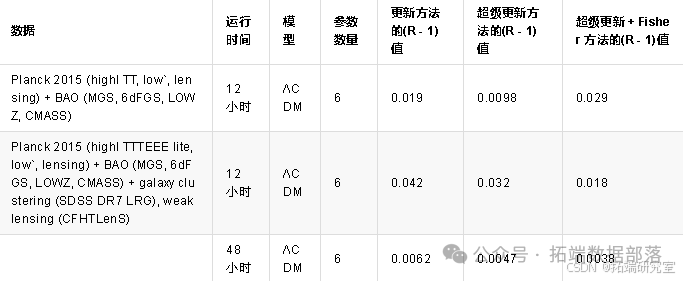
为了比较我们的新方法在使用当前数据时的效率,我们仅考虑 6 参数 ΛCDM 模型,我们将其拟合到两个数据集:一个仅包含普朗克和 BAO 似然函数的小数据集,以及一个更大的数据集,包括大尺度结构(LSS)似然函数(来自 SDSS 的星系团和来自 CFHTLenS 的弱引力透镜)。更多详细信息在表 2 中给出。我们再次以三种不同方式(更新、超级更新、超级更新 + Fisher)进行拟合,与上一节完全相同(即从代码分发的“普朗克 2015 协方差矩阵”开始更新和超级更新,并从跳跃因子 2.4 开始)。我们使用与预测相同数量的链和核心,并允许链运行 12 或 48 小时。
这些运行说明了从提议密度的不良猜测开始的情况,因为输入协方差矩阵仅考虑普朗克,并且需要收缩到与 BAO 和 LSS 数据兼容的较小区域。与上一节的运行相比,还有其他显著差异。
首先,当我们使用“小”数据集时,我们拥有普朗克高 TT 似然函数的所有干扰参数,这些参数具有强烈的非高斯后验并且彼此相关。这意味着最佳跳跃因子与 2.4 显著不同(实际上更接近 1.9)。这也意味着由于参数数量众多、相对于某些参数的似然函数的非高斯性以及我们在参数空间中仅具有最佳拟合点的不良近似(我们仅从普朗克数据的早期运行的链中提取的近似最佳拟合点计算 Fisher 矩阵),Fisher 矩阵计算很困难。对于扩展数据集,代码实际上无法使用完整的普朗克 TTTEEE + BAO + LSS 数据获得可逆的 Fisher 矩阵,因此我们不得不切换到普朗克 - 精简 TTTEEE 似然函数以摆脱干扰参数。
使用小数据集的运行显示了自动跳跃因子更新的影响:使用超级更新,代码迅速将跳跃因子调整到约 1.9,而使用更新时它保持在 2.4,导致接受率较低。表 2 显示使用超级更新时(R−1)提高了两倍。然而,这次运行也表明,在当前数据和许多非高斯参数的情况下,使用逆 Fisher 矩阵并不总是一个好主意,因为 Fisher 矩阵可能是似然函数的如此差的近似(特别是在非高斯干扰参数的方向上),以至于它实际上是比从先前仅普朗克运行的链推断出的协方差矩阵更差的输入协方差矩阵。因此,初步的 Fisher 计算使性能比超级更新 + “普朗克 2015 协方差矩阵”差三倍。
使用大数据集(但使用普朗克 - 精简 TTTEEE 似然函数)的运行显示出与预测相同的趋势:超级更新和 Fisher 都带来了显著的改进,(R−1)提高了多达两倍。
这些不同的情况使我们得出以下结论,这与我们进行的其他一些未在此处包含的测试相符:
使用超级更新基本上总是一个好主意。唯一可以考虑坚持使用更新的情况是最简单的情况,即当新运行涉及与先前运行非常相似的数据集和模型,以至于我们已经对协方差矩阵和最佳跳跃因子有了出色的了解。在那种情况下,更新和超级更新几乎等效,但在最不幸的情况下,超级更新可能会有一个过渡阶段,在此期间跳跃因子会偏离最佳值,然后渐近地回到最佳值,并且会在效率上略有损失。这通常是微不足道的,我们可以安全地建议在所有情况下使用超级更新:然后,根据运行的“难度”,改进范围将从可忽略不计到很大。
当存在许多非高斯参数,例如普朗克干扰参数时,Fisher 矩阵计算经常失败,即使它没有失败,逆 Fisher 矩阵通常也是提议密度的不良近似,与从具有相同干扰参数的链推断出的任何输入协方差矩阵相比。例如,这意味着当使用完整的普朗克高
似然函数时,应该使用分布式的“普朗克 2015 协方差矩阵”,或者自己从先前运行中获得的协方差矩阵,而不是 Fisher 选项。在几乎所有其他情况下,我们发现计算并从逆 Fisher 矩阵开始是加速收敛的非常强大的方法。
综上所述,蒙特卡罗 Python 通过超级更新策略和 Fisher 矩阵计算的引入,在参数推断方面取得了显著的进展。超级更新在处理不同复杂度模型和数据集时展现出良好的适应性,能够有效提升收敛速度并减少计算资源的消耗。尤其是在面对先验知识匮乏的情况,如在处理模拟数据与实际数据结合的复杂场景中,其优势更为突出。
然而,Fisher 矩阵计算虽然在多数 MCMC 预测场景中表现卓越,但在面对大量非高斯参数以及真实数据且似然形状复杂的情况下,可能会面临挑战,甚至可能导致性能下降。因此,在实际应用中,需要根据具体的数据特征和模型需求,灵活选择是否采用 Fisher 矩阵计算以及如何结合超级更新策略,以达到最佳的参数推断效果。
未来,蒙特卡罗 Python 的发展可以进一步聚焦于提升 Fisher 矩阵计算在复杂情况下的稳定性和准确性,例如优化最小化算法以更好地处理非高斯似然函数和众多干扰参数的情况。同时,对于超级更新策略,可以探索更加智能的跳跃因子调整机制,进一步提高其在各种场景下的效率,从而为研究提供更加强有力的工具支持,助力科学家们更深入地探索宇宙的奥秘,揭示参数背后隐藏的物理规律。
参考文献
[1] B. Audren, J. Lesgourgues, K. Benabed, S. Prunet, Conservative Constraints on Early Cosmology: an illustration of the Monte Python cosmological parameter inference code, JCAP 1302 (2013) 001.
[2] A. Lewis, S. Bridle, Cosmological parameters from CMB and other data: A Monte Carlo approach, Phys. Rev. D66 (2002) 103511. arXiv:astro-ph/0205436, doi:10.1103/PhysRevD.66.103511.
[3] A. Lewis, Efficient sampling of fast and slow cosmological parameters, Phys. Rev. D87 (10) (2013) 103529.
[4] J. Zuntz, M. Paterno, E. Jennings, D. Rudd, A. Manzotti, S. Dodelson, S. Bridle, S. Sehrish, J. Kowalkowski, CosmoSIS: Modular Cosmological Parameter Estimation, Astron. Comput. 12 (2015) 45–59. arXiv:1409.3409, doi:10.1016/j.ascom.2015.05.005.
[5] J. Lesgourgues, The Cosmic Linear Anisotropy Solving System (CLASS) I: Overview. arXiv:1104.2932.
[6] D. Blas, J. Lesgourgues, T. Tram, The Cosmic Linear Anisotropy Solving System (CLASS) II: Approximation schemes, JCAP 1107 (2011) 034.
[7] J. Lesgourgues, The Cosmic Linear Anisotropy Solving System (CLASS) III: Comparision with CAMB for ΛCDM. arXiv:1104.2934.
[8] J. Lesgourgues, T. Tram, The Cosmic Linear Anisotropy Solving System (CLASS) IV: efficient implementation of non-cold relics, JCAP 1109 (2011) 032.
[9] M. Zumalacarregui, E. Bellini, I. Sawicki, J. Lesgourgues, hi´class: Horndeski in the Cosmic Linear Anisotropy Solving System. arXiv:1605.06102.
[10] G. W. Pettinari, C. Fidler, R. Crittenden, K. Koyama, D. Wands, The intrinsic bispectrum of the cosmic microwave background, J. Cosmology Astropart. Phys. 4 (2013) 3. arXiv:1302.0832, doi:10.1088/1475-7516/2013/04/003.
[11] P. Stocker, M. Krämer, J. Lesgourgues, V. Poulin, Exotic energy injection with ExoCLASS: Application to the Higgs portal model and evaporating black holes. arXiv:1801.01871.
[12] B. Bolliet, B. Comis, E. Komatsu, J. F. Mac´ías-Perez, Dark Energy from the Thermal Sunyaev Zeldovich Power Spectrum. arXiv:1712.00788.
[13] E. Di Dio, F. Montanari, J. Lesgourgues, R. Durrer, The CLASSgal code for Relativistic Cosmological Large Scale Structure, JCAP 1311 (2013) 044. arXiv:1307.1459, doi:10.1088/1475-7516/2013/11/044.
[14] Y. Dirian, S. Foffa, M. Kunz, M. Maggiore, V. Pettorino, Non-local gravity and comparison with observational datasets. II. Updated results and Bayesian model comparison with ΛCDM, JCAP 1605 (05) (2016) 068. arXiv:1602.03558, doi:10.1088/1475-7516/2016/05/068.
[15] A. Lewis, A. Challinor, A. Lasenby, Efficient computation of CMB anisotropies in closed FRW models, Astrophys. J. 538 (2000) 473–476. arXiv:astro-ph/9911177, doi:10.1086/309179.
[16] C. Howlett, A. Lewis, A. Hall, A. Challinor, CMB power spectrum parameter degeneracies in the era of precision cosmology, JCAP 1204 (2012) 027. arXiv:1201.3654, doi:10.1088/1475-7516/2012/04/027.
[17] A. Refregier, L. Gamper, A. Amara, L. Heisenberg, PyCosmo: An Integrated Cosmological Boltzmann Solver. arXiv:1708.05177.
[18] J. Dunkley, M. Bucher, P. G. Ferreira, K. Moodley, C. Skordis, Fast and reliable MCMC for cosmological parameter estimation, Mon. Not. Roy. Astron. Soc. 356 (2005) 925–936. arXiv:astro-ph/0405462, doi:10.1111/j.1365-2966.2004.08464.x.

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!

资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python蒙特卡罗MCMC:优化Metropolis-Hastings采样策略Fisher矩阵计算参数推断应用》。
点击标题查阅往期内容
MATLAB贝叶斯优化混合Bayes-CNN-RNN分析股票市场数据与浅层网络超参数优化
R语言贝叶斯分析:INLA 、MCMC混合模型、生存分析肿瘤临床试验、间歇泉喷发时间数据应用|附数据代码
课程视频|R语言bnlearn包:贝叶斯网络的构造及参数学习的原理和实例
R语言贝叶斯分层、层次(Hierarchical Bayesian)模型房价数据空间分析
R语言Gibbs抽样的贝叶斯简单线性回归仿真分析
python贝叶斯随机过程:马尔可夫链Markov-Chain,MC和Metropolis-Hastings,MH采样算法可视化
Python贝叶斯推断Metropolis-Hastings(M-H)MCMC采样算法的实现
Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
Matlab用BUGS马尔可夫区制转换Markov switching随机波动率模型、序列蒙特卡罗SMC、M H采样分析时间序列
R语言RSTAN MCMC:NUTS采样算法用LASSO 构建贝叶斯线性回归模型分析职业声望数据
R语言BUGS序列蒙特卡罗SMC、马尔可夫转换随机波动率SV模型、粒子滤波、Metropolis Hasting采样时间序列分析
R语言Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
R语言贝叶斯MCMC:用rstan建立线性回归模型分析汽车数据和可视化诊断
R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例
R语言贝叶斯Poisson泊松-正态分布模型分析职业足球比赛进球数
R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言中贝叶斯网络(BN)、动态贝叶斯网络、线性模型分析错颌畸形数据
R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
Python贝叶斯回归分析住房负担能力数据集
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
Python用PyMC3实现贝叶斯线性回归模型
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言Gibbs抽样的贝叶斯简单线性回归仿真分析
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言贝叶斯线性回归和多元线性回归构建工资预测模型
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言stan进行基于贝叶斯推断的回归模型
R语言中RStan贝叶斯层次模型分析示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
WinBUGS对多元随机波动率模型:贝叶斯估计与模型比较
R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
视频:R语言中的Stan概率编程MCMC采样的贝叶斯模型
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计



![]()

相关文章:
Python蒙特卡罗MCMC:优化Metropolis-Hastings采样策略Fisher矩阵计算参数推断应用—模拟与真实数据...
全文链接:https://tecdat.cn/?p38397 本文介绍了其在过去几年中的最新开发成果,特别阐述了两种有助于提升 Metropolis - Hastings 采样性能的新要素:跳跃因子的自适应算法以及逆 Fisher 矩阵的计算,该逆 Fisher 矩阵可用作提议密…...

成绩排序
成绩排序 C语言代码C 代码Java代码Python代码 💐The Begin💐点点关注,收藏不迷路💐 给出班里某门课程的成绩单,请你按成绩从高到低对成绩单排序输出,如果有相同分数则名字字典序小的在前。 输入 第一行为…...

MySQL底层概述—7.优化原则及慢查询
大纲 1.Explain概述 2.Explain详解 3.索引优化数据准备 4.索引优化原则详解 5.慢查询设置与测试 6.慢查询SQL优化思路 1.Explain概述 使用Explain关键字可以模拟查询优化器来执行SQL查询语句,从而知道MySQL是如何处理SQL语句的,从而分析出查询语句…...

R““有什么作用在C++中,举例说明
在C中,R""(双引号前加R)表示一个原始字符串字面量(Raw String Literal),其主要作用是让字符串中的反斜杠\和其他特殊字符不被当作转义字符处理,而是保留其原始字面意义。这在处理包含…...

linux中top 命令返回数据解释
当您在 Linux 终端中运行 top 命令时,它会显示一个动态更新的系统状态视图,其中包括许多有关系统性能的数据。下面是对 top 命令返回数据的详细解释: 标题栏 top - 22:46:12 up 2 days, 3:14, 1 user, load average: 0.05, 0.07, 0.09 22:46:12:当前时间。up 2 days, 3:14…...

深入理解二叉树及其变体:平衡二叉树、红黑树、B-树和B+树
一、二叉树简介 二叉树是一种非常常见的数据结构,它具有以下特点: 每个节点最多有两个子节点,分别称为左子节点和右子节点。每个节点的左子树和右子树都是二叉树。 二叉树的常见操作包括:创建、插入、删除、查找、遍历等。下面…...
)
C++ 编程技巧之StrongType(1)
最近看到一个NamedType的开源库,被里面的Strong Type这个概念和里面的模版实现给秀了一脸,特此总结学习一下 GitHub - joboccara/NamedType: Implementation of strong types in C C本身是一种强类型语言,类型包括int、double等这些build i…...

芯片测试-smith圆图
smith圆图 💢smith圆图的故事💢💢smith圆图中的各部分来历💢💢公式推导💢💢等电阻圆特点💢💢等电抗圆💢💢等电抗圆特点💢 Ὂ…...

HTML技术深度解析:构建现代网页的基石
引言 HTML(HyperText Markup Language,超文本标记语言)是构建网页和网上应用的标准标记语言。随着互联网技术的飞速发展,HTML已经成为前端开发中不可或缺的核心技术之一。本文将深入探讨HTML的基本概念、核心元素、最新发展以及在…...

Leecode刷题C语言之判断是否可以赢得数字游戏
执行结果:通过 执行用时和内存消耗如下: bool canAliceWin(int* nums, int numsSize) {int single_digit_sum 0;int double_digit_sum 0;for (int i 0; i < numsSize; i) {if (nums[i] < 10) {single_digit_sum nums[i];} else {double_digit_sum nums[…...

Ubuntu 关机命令
在 Ubuntu 系统中,有几种方法可以关机。以下是常用的关机命令及其说明: 1. 使用 shutdown 命令 shutdown 命令是最常用和最灵活的关机方式。它可以设置定时关机,并且可以发送警告消息给所有登录用户。 立即关机 sudo shutdown now定时关机…...

数据采集中,除了IP池的IP被封,还有哪些常见问题?
在数据采集的过程中,代理IP池的使用无疑为我们打开了一扇通往信息宝库的大门。然而,除了IP被封禁这一常见问题外,还有许多其他问题可能影响数据采集的效果。本文将探讨在数据采集中,除了IP被封之外,还可能遇到的一些常…...

【Anaconda】 创建环境报错:CondaHTTPError: HTTP 000 CONNECTION FAILED for url
问题描述 使用 Anaconda 创建环境时报错: CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.com/pkgs/free/noarch/repodata.json.bz2> Elapsed: -An HTTP error occurred when trying to retrieve this URL. HTTP errors are o…...

社交电商破局之“2+1 链动模式 O2O 商城小程序源码”赋能流量困境突围
摘要:本文聚焦于当下商家在流量困境中挣扎的现状,剖析传统电商高流量成本、平台流量获取难等痛点,阐述私域流量池兴起的缘由与价值。重点探究“21 链动模式 O2O 商城小程序源码”如何融入社交电商架构,通过创新机制与线上线下融合…...

【ArcGIS Pro微课1000例】0062:ArcGIS Pro3.3.1中文版安装教程(附安装包下载)
本文讲述ArcGIS Pro3.3.1中文版安装教程(附安装包下载)。 文章目录 一、ArcGIS Pro3.3.1中文版下载二、ArcGIS Pro3.3.1中文版安装一、ArcGIS Pro3.3.1中文版下载 【订阅专栏】,获取完整安装包及专栏配套实验数据。下载后解压,如下图所示: 二、ArcGIS Pro3.3.1中文版安装…...

Linux - web服务器
四、web服务器 1、基础知识 URL:Uniform Resource Locator,统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。 网址格式:<协议>://<主机或主机名&g…...

设计模式-适配器模式-注册器模式
设计模式-适配器模式-注册器模式 适配器模式 如果开发一个搜索中台,需要适配或接入不同的数据源,可能提供的方法参数和平台调用的方法参数不一致,可以使用适配器模式 适配器模式通过封装对象将复杂的转换过程隐藏于幕后。 被封装的对象甚至…...

减速机润滑油更换的最佳周期是多久?
减速机是工业设备中的重要组成部分,润滑油的使用对于其正常运转和寿命具有至关重要的作用。那么,减速机多久更换一次润滑油呢?实际上,减速机润滑油的更换周期受多种因素影响,以下是一些具体的更换周期建议:…...

程序执行堆栈执行模拟
所有的文件都是在硬盘(磁盘)上,调用时先调用javac指令的jdk编译成.class然后被java指令的jre送到内存中,java在内存中有自己的一片区域叫JVM,编译进来的文件首先进入方法区。 staitc的属性就是在进入内存的时候开辟了一…...

《Python基础》之数据加密模块hashlib的用法
目录 一、简介 二、用法 步骤一、导入hashlib库 步骤二、创建哈希对象 步骤三、往哈希对象中传值 1、可以在创建对象的时候传值 2、使用updata传值 步骤四、获取经过哈希对象加密后的值 三、注意事项 1、编码问题 2、安全性 3、多次传值 四、总结 一、简介 hashli…...

当电脑风扇遇上智能管家:FanControl让散热控制变得简单有趣
当电脑风扇遇上智能管家:FanControl让散热控制变得简单有趣 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendi…...

英雄联盟玩家的智能工具箱:League Akari 如何提升你的游戏体验
英雄联盟玩家的智能工具箱:League Akari 如何提升你的游戏体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 想象一下这样的场景…...

ARM-MPU实战:从寄存器配置到内存安全防护
1. ARM-MPU基础概念与核心价值 第一次接触ARM-MPU时,我盯着开发板反复确认了三遍接线——明明程序逻辑完全正确,却总是莫名其妙进入HardFault中断。后来才发现是某个野指针改写了关键数据区,这种隐蔽的错误让我意识到内存保护的重要性。ARM-M…...

归并排序:分治思想的经典应用
归并排序一、核心原理分治思想分:把数组不断从中间拆成左右两半,直到每个子数组只剩 1 个元素(天然有序);治:把两个有序子数组 合并 成一个大的有序数组;递归向上合并,最终整个数组有…...

终极指南:3分钟掌握Typora插件,让写作效率提升300%
终极指南:3分钟掌握Typora插件,让写作效率提升300% 【免费下载链接】typora_plugin Typora plugin. Feature enhancement tool | Typora 插件,功能增强工具 项目地址: https://gitcode.com/gh_mirrors/ty/typora_plugin Typora是一款广…...

iOS激活锁终极绕过指南:开源工具applera1n的完整解决方案
iOS激活锁终极绕过指南:开源工具applera1n的完整解决方案 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 面对iOS设备激活锁的困扰,你是否曾为无法使用二手iPhone而烦恼&#x…...

ARM TRCCNTCTLR寄存器详解与调试技巧
1. ARM Trace Counter控制寄存器TRCCNTCTLR深度解析在嵌入式系统调试和性能分析领域,硬件计数器是不可或缺的关键工具。作为ARM架构调试系统的重要组成部分,Trace Counter Control Register(TRCCNTCTLR)系列寄存器为开发者提供了精…...

英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南
英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否厌倦了在英雄联盟排位赛中手忙脚乱地查询对手战绩?是否希望有一个智能助…...

Hypha框架深度解析:现代Python异步Web开发与API构建实践
1. 项目概述:Hypha,一个被低估的轻量级Web框架 如果你和我一样,长期在Web后端开发领域摸爬滚打,那么对Flask、FastAPI、Express这些名字一定耳熟能详。它们各有千秋,也各有其“甜蜜点”和“痛点”。最近在GitHub上闲逛…...

rCore-Tutorial-v3:从零开始用Rust编写RISC-V操作系统的终极指南
rCore-Tutorial-v3:从零开始用Rust编写RISC-V操作系统的终极指南 【免费下载链接】rCore-Tutorial-v3 Lets write an OS which can run on RISC-V in Rust from scratch! 项目地址: https://gitcode.com/gh_mirrors/rc/rCore-Tutorial-v3 你是否曾梦想过亲手…...