【Python爬虫五十个小案例】爬取猫眼电影Top100

博客主页:小馒头学python
本文专栏: Python爬虫五十个小案例
专栏简介:分享五十个Python爬虫小案例

🐍引言
猫眼电影是国内知名的电影票务与资讯平台,其中Top100榜单是影迷和电影产业观察者关注的重点。通过爬取猫眼电影Top100的数据,我们可以分析当前最受欢迎的电影,了解电影市场的变化趋势。在本文中,我们将介绍如何使用Python实现爬取猫眼电影Top100榜单的过程,并通过简单的数据分析展示电影的评分分布及其它相关信息。
🐍准备工作
在开始爬虫之前,我们需要做一些准备工作:
🐍安装必要的库:
首先,我们需要安装几个常用的Python库:
pip install requests beautifulsoup4 pandas matplotlib seaborn
🐍了解页面结构:
使用浏览器的开发者工具打开猫眼电影Top100的网页,观察页面的DOM结构,找到包含电影信息的元素
下面是页面的大概结构
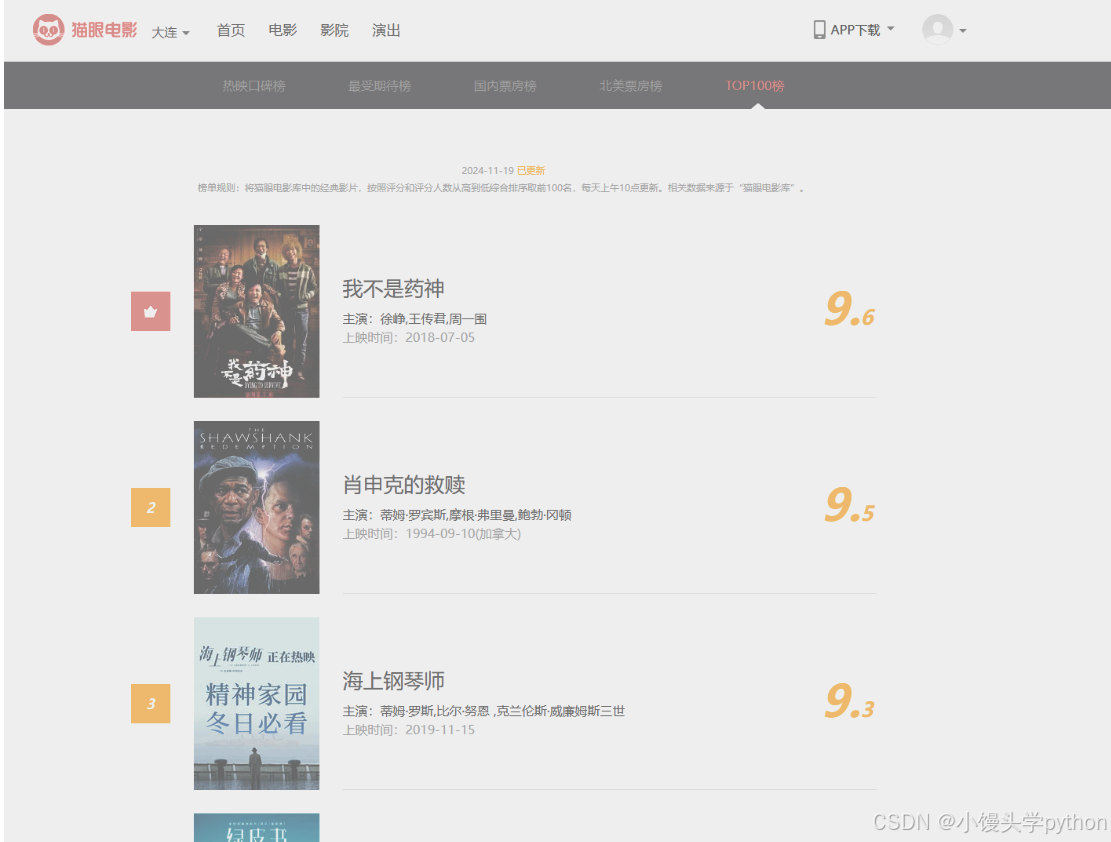
🐍分析猫眼电影Top100页面结构
猫眼电影Top100的URL通常是类似于 https://maoyan.com/board/4。我们可以通过浏览器开发者工具(F12)来查看HTML结构,识别出电影的名称、评分、上映时间等数据。通过<li class="board-item">标签,每个电影的信息都包含在这个标签下。我们需要提取出其中的子标签来获取所需的数据。
🐍 编写爬虫代码
接下来,我们编写爬虫代码,来抓取页面中的电影信息。爬虫的主要任务是获取电影的名称、评分、上映时间等数据,并处理分页逻辑,直到抓取完Top100。
import requests
from bs4 import BeautifulSoup
import pandas as pd# 设置目标URL
url = 'https://maoyan.com/board/4'# 发送请求
response = requests.get(url)
response.encoding = 'utf-8'# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')# 存储电影信息的列表
movies = []# 提取电影列表
for item in soup.find_all('dd'):movie = {}movie['name'] = item.find('a').text.strip() # 电影名称movie['score'] = item.find('p', class_='score').text.strip() # 电影评分movie['release_time'] = item.find('p', class_='releasetime').text.strip() # 上映时间movies.append(movie)# 将数据保存到DataFrame
df = pd.DataFrame(movies)# 输出前5行数据
print(df.head())# 保存到CSV文件
df.to_csv('maoyan_top100.csv', index=False)
🐍数据清洗与存储
在爬取数据之后,我们需要进行数据清洗,确保抓取的数据是准确和完整的。例如:
- 清理电影名称中的空格和特殊字符
- 处理评分字段中缺失或非数字的情况
- 上映时间可能需要转换为标准日期格式
使用pandas可以方便地进行数据清洗:
# 清洗数据:去除空值
df.dropna(inplace=True)# 转换上映时间为标准格式
df['release_time'] = pd.to_datetime(df['release_time'], errors='coerce')# 处理评分数据,将评分转换为浮动类型
df['score'] = pd.to_numeric(df['score'], errors='coerce')
🐍数据分析与可视化
通过简单的数据分析,我们可以查看电影评分的分布、上映年份的趋势等:
import matplotlib.pyplot as plt
import seaborn as sns# 绘制评分分布图
plt.figure(figsize=(8, 6))
sns.histplot(df['score'], bins=20, kde=True)
plt.title('电影评分分布')
plt.xlabel('评分')
plt.ylabel('数量')
plt.show()# 电影上映年份分布
df['release_year'] = df['release_time'].dt.year
plt.figure(figsize=(10, 6))
sns.countplot(x='release_year', data=df)
plt.title('电影上映年份分布')
plt.xticks(rotation=45)
plt.show()
🐍反爬虫机制与应对策略
猫眼电影网站有一定的反爬虫机制,比如限制频繁的请求。因此,在编写爬虫时,我们需要注意以下几个问题:
- 使用User-Agent:模拟浏览器请求头,避免被识别为爬虫
- 设置请求间隔:通过
time.sleep()设置请求的间隔,防止过于频繁的请求 - 使用代理:避免IP封禁
import time
import randomheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}# 模拟延时,避免频繁请求
time.sleep(random.uniform(1, 3))
🐍完整源码
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
import matplotlib.pyplot as plt
from matplotlib import rcParams
import seaborn as sns
import re# 设置Matplotlib使用的字体为SimHei(黑体),以支持中文显示
rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题# 设置目标URL
url = 'https://maoyan.com/board/4'# 请求头,模拟浏览器访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}# 发送请求
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')# 存储电影信息的列表
movies = []# 提取电影列表
for item in soup.find_all('dd'):movie = {}# 获取电影名称,从a标签的title属性中提取movie['name'] = item.find('a')['title'].strip() if item.find('a') else 'N/A'# 获取评分,确保评分字段存在score_tag = item.find('p', class_='score')movie['score'] = score_tag.text.strip() if score_tag else 'N/A'# 获取上映时间,确保上映时间字段存在release_time_tag = item.find('p', class_='releasetime')release_time = release_time_tag.text.strip() if release_time_tag else 'N/A'# 使用正则表达式清洗数据,提取年份部分movie['release_time'] = re.findall(r'\d{4}', release_time) # 匹配年份if movie['release_time']:movie['release_time'] = movie['release_time'][0] # 只取第一个年份else:movie['release_time'] = 'N/A' # 如果没有找到年份,设置为'N/A'# 将电影信息添加到列表中movies.append(movie)# 将数据存储到pandas DataFrame
df = pd.DataFrame(movies)# 输出前5行数据
print("爬取的数据:")
print(df.head())# 数据清洗:去除空值并处理评分数据
df.dropna(subset=['score', 'release_time'], inplace=True) # 删除评分和上映时间为空的行# 将评分转换为数值类型,无法转换的设置为NaN
df['score'] = pd.to_numeric(df['score'], errors='coerce')# 删除评分为空的行
df.dropna(subset=['score'], inplace=True)# 将release_time列转换为数值类型的年份
df['release_year'] = pd.to_numeric(df['release_time'], errors='coerce')# 输出清洗后的数据
print("清洗后的数据:")
print(df.head())# 保存数据为CSV文件
df.to_csv('maoyan_top100.csv', index=False)# 数据分析:电影评分分布
plt.figure(figsize=(8, 6))
sns.histplot(df['score'], bins=20, kde=True)
plt.title('电影评分分布')
plt.xlabel('评分')
plt.ylabel('数量')
plt.show()# 数据分析:电影上映年份分布
plt.figure(figsize=(10, 6))
sns.countplot(x='release_year', data=df)
plt.title('电影上映年份分布')
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('电影数量')
plt.show()# 结束
print("爬取和分析完成!数据已保存至 maoyan_top100.csv")
🐍翻页功能
我们完成了基本的功能,接下来我们为了爬取前100个电影(即10页数据),你需要构造爬虫来遍历每一页并合并数据。每一页的URL格式为https://www.maoyan.com/board/4?offset=n,其中n是每页的偏移量,分别为0、10、20、30等,
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
import matplotlib.pyplot as plt
from matplotlib import rcParams
import seaborn as sns
import re# 设置Matplotlib使用的字体为SimHei(黑体),以支持中文显示
rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题# 设置目标URL基础部分
base_url = 'https://www.maoyan.com/board/4?offset={}'# 请求头,模拟浏览器访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}# 存储所有电影信息的列表
movies = []# 爬取10页数据,每页偏移量为0, 10, 20, ..., 90
for offset in range(0, 100, 10):url = base_url.format(offset) # 构造每一页的URLresponse = requests.get(url, headers=headers)response.encoding = 'utf-8'# 使用BeautifulSoup解析HTMLsoup = BeautifulSoup(response.text, 'html.parser')# 提取电影列表for item in soup.find_all('dd'):movie = {}# 获取电影名称,从a标签的title属性中提取movie['name'] = item.find('a')['title'].strip() if item.find('a') else 'N/A'# 获取评分,确保评分字段存在score_tag = item.find('p', class_='score')movie['score'] = score_tag.text.strip() if score_tag else 'N/A'# 获取上映时间,确保上映时间字段存在release_time_tag = item.find('p', class_='releasetime')release_time = release_time_tag.text.strip() if release_time_tag else 'N/A'# 使用正则表达式清洗数据,提取年份部分movie['release_time'] = re.findall(r'\d{4}', release_time) # 匹配年份if movie['release_time']:movie['release_time'] = movie['release_time'][0] # 只取第一个年份else:movie['release_time'] = 'N/A' # 如果没有找到年份,设置为'N/A'# 将电影信息添加到列表中movies.append(movie)# 随机延迟,避免频繁请求被封禁time.sleep(random.uniform(1, 3))# 将数据存储到pandas DataFrame
df = pd.DataFrame(movies)# 输出前5行数据
print("爬取的数据:")
print(df.head())# 数据清洗:去除空值并处理评分数据
df.dropna(subset=['score', 'release_time'], inplace=True) # 删除评分和上映时间为空的行# 将评分转换为数值类型,无法转换的设置为NaN
df['score'] = pd.to_numeric(df['score'], errors='coerce')# 删除评分为空的行
df.dropna(subset=['score'], inplace=True)# 将release_time列转换为数值类型的年份
df['release_year'] = pd.to_numeric(df['release_time'], errors='coerce')# 输出清洗后的数据
print("清洗后的数据:")
print(df.head())# 保存数据为CSV文件
df.to_csv('maoyan_top100.csv',encoding='utf-8-sig' ,index=False)# 数据分析:电影评分分布
plt.figure(figsize=(8, 6))
sns.histplot(df['score'], bins=20, kde=True)
plt.title('电影评分分布')
plt.xlabel('评分')
plt.ylabel('数量')
plt.show()# 数据分析:电影上映年份分布
plt.figure(figsize=(10, 6))
sns.countplot(x='release_year', data=df)
plt.title('电影上映年份分布')
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('电影数量')
plt.show()# 结束
print("爬取和分析完成!数据已保存至 maoyan_top100.csv")
遍历10页:
- 我们使用
range(0, 100, 10)来设置偏移量,依次爬取从offset=0到offset=90的URL - 每一页的URL由
base_url.format(offset)生成。
随机延迟:
- 为了避免频繁请求导致被封禁,爬虫请求每一页后,加入了
time.sleep(random.uniform(1, 3)),模拟随机延迟
爬取并合并数据:
- 所有电影信息都会存储到
movies列表中,最后通过pandas的DataFrame进行数据整合
运行结果


下图展示了电影评分分布情况还有电影上映年份的分布


🐍结语
通过本篇博客,我们展示了如何使用Python爬虫技术抓取猫眼电影Top100的数据,并进行简单的数据清洗与分析。除了数据抓取和分析,我们还学习了如何应对反爬虫机制。通过这些知识,我们可以很好的进行后续的数据分析,或者可以查看自己喜欢哪个电影,当然本节主要还是为了练手,为了后续我们进行其他项目任务
若感兴趣可以访问并订阅我的专栏:Python爬虫五十个小案例:https://blog.csdn.net/null18/category_12840403.html?fromshare=blogcolumn&sharetype=blogcolumn&sharerId=12840403&sharerefer=PC&sharesource=null18&sharefrom=from_link
相关文章:
【Python爬虫五十个小案例】爬取猫眼电影Top100
博客主页:小馒头学python 本文专栏: Python爬虫五十个小案例 专栏简介:分享五十个Python爬虫小案例 🐍引言 猫眼电影是国内知名的电影票务与资讯平台,其中Top100榜单是影迷和电影产业观察者关注的重点。通过爬取猫眼电影Top10…...

等保测评和 ISO27001 都是信息保护,区别是什么?
ISO27001 和等级保护(等保)都是信息安全领域重要的标准和制度,但它们在多个方面存在区别: 定义和性质 ISO27001 它是国际标准化组织(ISO)发布的信息安全管理体系标准,其目的是帮助组织建立、实…...

Linux系统编程之进程创建
概述 在Linux系统中,通过创建新的进程,我们可以实现多任务处理、并发执行和资源隔离等功能。创建进程的主要方法为:fork、vfork、clone。下面,我们将分别进行介绍。 fork fork是最常用的创建新进程的方法。当一个进程调用fork时&a…...

JAVA-IO
目录 IO流 一 字节流 1 FileOutStream 1 书写: 2 换行书写与续写: 2 FileInputStream 1 读取数据 2 循环读取: 二 字符流 1 FileReader 1 空参的read()方法读取数据: 2 有参的read()方法读取数据: 3 指定字…...

动态系统特征分析:特征向量、特征值、频率与阻尼比、参与因子计算方法
特征值和特征向量在动态系统分析中是核心工具,广泛用于电力系统小信号稳定性、机械系统模态分析等领域。以下详细介绍计算方法及应用。 1. 求解特征值与特征向量 对于一个 n n n\times n nn的系统矩阵 A A A: 右特征向量与特征值 特征值( λ \lambd…...

乐鑫发布 esp-iot-solution v2.0 版本
今天,乐鑫很高兴地宣布,esp-iot-solution v2.0 版本已经发布,release/v2.0 分支下的正式版本组件将为用户提供为期两年的 Bugfix 维护(直到 2027.01.25 ESP-IDF v5.3 EOL)。该版本将物联网开发中常用的功能进行了分类整…...

动态代理如何加强安全性
在当今这个信息爆炸、网络无孔不入的时代,我们的每一次点击、每一次浏览都可能留下痕迹,成为潜在的安全隐患。如何在享受网络便利的同时,有效保护自己的隐私和信息安全,成为了每位网络使用者必须面对的重要课题。动态代理服务器&a…...

Flutter 之 InheritedWidget
InheritedWidget 是 Flutter 框架中的一个重要类,用于在 Widget 树中共享数据。它是 Flutter 中数据传递和状态管理的基础之一。通过 InheritedWidget,你可以让子 Widget 在不需要显式传递数据的情况下,访问祖先 Widget 中的数据。这种机制对…...

AI 助力开发新篇章:云开发 Copilot 深度体验与技术解析
本文 一、引言:技术浪潮中的个人视角1.1 AI 和低代码的崛起1.2 为什么选择云开发 Copilot? 二、云开发 Copilot 的核心功能解析2.1 自然语言驱动的低代码开发2.1.1 自然语言输入示例2.1.2 代码生成的模块化支持 2.2 实时预览与调整2.2.1 实时预览窗口功能…...

MyBatis-Plus介绍及基本使用
文章目录 概述介绍MyBatis-Plus 常用配置分页插件配置类注解配置 快速入门maven 依赖编写配置文件编写启动类编写 MybatisPlus 配置类 代码生成器:MybatisPlusGeneratormaven依赖代码生成器核心类 概述 介绍 MyBatis-Plus(简称 MP)是一个 M…...

SpringBoot 整合 Avro 与 Kafka
优质博文:IT-BLOG-CN 【需求】:生产者发送数据至 kafka 序列化使用 Avro,消费者通过 Avro 进行反序列化,并将数据通过 MyBatisPlus 存入数据库。 一、环境介绍 【1】Apache Avro 1.8;【2】Spring Kafka 1.2…...

支持JT1078和GB28181的流媒体服务器-LKM启动配置文件参数说明
流媒体服务器地址:https://github.com/lkmio/lkm GB28181信令,模拟多个国标设备工具:https://github.com/lkmio/gb-cms 文章目录 gop_cachegop_buffer_sizeprobe_timeoutwrite_timeoutmw_latencylisten_ippublic_ipidle_timeoutreceive_timeo…...
有哪些风险?)
什么是隐式类型转换?隐式类型转换可能带来哪些问题? 显式类型转换(如强制类型转换)有哪些风险?
C 中的隐式类型转换 定义:在 C 中,隐式类型转换是指由编译器自动执行的类型转换,不需要程序员显式地进行操作。这种转换在很多情况下会自动发生,比如在表达式求值、函数调用传参等过程中。常见场景 算术运算中的转换:…...
——金融研究者的得力助手)
量化交易新利器:阿布量化(AbuQuant)——金融研究者的得力助手
🚀 量化交易新利器:阿布量化(AbuQuant)——金融研究者的得力助手 🚀 文章目录 🚀 量化交易新利器:阿布量化(AbuQuant)——金融研究者的得力助手 🚀dz…...

UI设计从入门到进阶,全能实战课
课程内容: ├── 【宣导片】从入门到进阶!你的第一门UI必修课!.mp4 ├── 第0课:UI知识体系梳理 学习路径.mp4 ├── 第1课:IOS设计规范——基础规范与切图.mp4 ├── 第2课:IOS新趋势解析——模块规范与设计原则(上).mp4…...

Uniapp自动调整元素高度
获取设备的像素 如果你想让元素的高度相对于整个屏幕的高度占用一定的比例,可以通过获取屏幕的高度,然后计算出你想要的比例来设置元素的高度。以下是如何实现的示例: <script setup> import { ref, onMounted } from vue;// 定义一个…...

软考高项经验分享:我的备考之路与实战心得
软考,尤其是信息系统项目管理师(高项)考试,对于众多追求职业提升与专业认可的人士来说,是一场充满挑战与机遇的征程。我在当年参加软考高项的经历,可谓是一波三折,其中既有成功的喜悦࿰…...

安全关系型数据库查询新选择:Rust 语言的 rust-query 库深度解析
在当今这个数据驱动的时代,数据库作为信息存储和检索的核心组件,其重要性不言而喻。然而,对于开发者而言,如何在保证数据安全的前提下,高效地进行数据库操作却是一项挑战。传统的 SQL 查询虽然强大,但存在诸…...

《C++ 模型训练之早停法:有效预防过拟合的关键策略》
在 C 模型开发的复杂世界里,过拟合犹如一个潜藏的陷阱,常常使我们精心构建的模型在实际应用中表现大打折扣。而早停法(Early Stopping)作为一种行之有效的策略,能够帮助我们及时察觉模型训练过程中的异常,避…...

5.11【数据库】第一次实验
民宿预定,至少有不同的民宿,民宿下面有不同的房间(面积,房间编号) 房间类型,单价, 可预订以及不可预订 游客信息 订单信息 公司有很多课程, 学生,课程 每位学生每期…...

终极指南:BetterNCM插件管理器一键安装,让网易云音乐焕然新生
终极指南:BetterNCM插件管理器一键安装,让网易云音乐焕然新生 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼?Bett…...

AI答案优化效果可以靠哪些第三方数据验证?
先给结论:AI答案优化效果要做三层交叉验证AI 答案优化、GEO 服务的效果,不应只听服务商自述,也不适合只靠单张 AI 回答截图判断。更稳妥的做法,是用三层数据交叉验证:AI回答层数据:看品牌是否被提及、位置是…...

抖音内容下载终极指南:5分钟搞定批量下载与去水印
抖音内容下载终极指南:5分钟搞定批量下载与去水印 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

大模型概念遗忘:SCUGP梯度投影实现精准神经外科手术
1. 项目概述:这不是“删除记忆”,而是给大模型做一次精准的神经外科手术“Who is Harry Potter?”——这个看似简单的问答,恰恰成了检验大模型“概念遗忘”能力的黄金测试题。微软研究院这篇论文标题里藏着一个反直觉的事实:他们…...

C# WebAssembly构建高性能Web3D引擎实战
1. 这不是“把C#搬到浏览器”,而是重构Web图形开发的底层契约 你有没有试过在浏览器里跑一个带物理模拟、动态光照和实时骨骼动画的3D场景,结果发现JavaScript主线程卡成PPT,WebGL状态管理像在解九连环?我去年接手一个工业数字孪生…...

告别断电重启就丢程序:深入聊聊紫光同创FPGA的Flash固化与CPLD内置eFlash配置差异
紫光同创FPGA与CPLD配置存储机制深度解析:从瞬态下载到永久固化的技术实现 在数字电路设计领域,FPGA和CPLD的可重构特性为硬件开发带来了极大灵活性。然而,这种灵活性背后需要可靠的配置存储机制作为支撑——断电后程序能否自动恢复…...

边缘AI落地实战:模型轻量化、硬件加速与端侧部署全链路解析
1. 项目概述:为什么“把AI带到边缘设备”不是一句口号,而是正在发生的产业迁移 “Bringing AI To Edge Devices”——这个标题乍看像科技发布会的PPT副标题,但在我过去十年跑遍深圳华强北模组厂、杭州海康产线、苏州工业视觉集成商和北京智能…...

为Claude Code配置Taotoken备用API解决封号与Token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken备用API解决封号与Token不足问题 许多开发者在日常使用Claude Code时,可能会遇到服务暂时不…...

GEO工具红黑榜:有的在“监测“,有的在“收智商税“
2026年,AI搜索已承接超过40%的传统搜索查询量,品牌面临的不再是"百度一下"的竞价排名,而是AI助手直接给出的"默认答案"。当用户问ChatGPT"推荐一款面霜"或向豆包询问"哪个在线教育平台更好"时&#…...

SCI论文重复率一般得控制在多少合格?
SCI论文这个问题,先说结论:没有一个“全球统一合格线”。SCI期刊不像本科毕业论文那样,很多学校会明确卡 10%、15%、20%。SCI更看目标期刊要求。但实际经验里,大致可以这么理解:常见参考区间<10%࿱…...