Spring AI 框架介绍
Spring AI是一个面向人工智能工程的应用框架。它的目标是将Spring生态系统的设计原则(如可移植性和模块化设计)应用于AI领域,并推广使用pojo作为AI领域应用的构建模块。
概述
Spring AI 现在(2024/12)已经支持语言,图像,语音类的生成式AI模型。
GPT类的模型特点是预训练,这种预训练将AI转变为一个通用的开发工具,而不需要广泛的机器学习或模型训练背景。
Prompts
提示词是基于语言的输入的基础,指导人工智能模型产生特定的输出。
制定高效的提示词既是一门艺术,也是一门科学。ChatGPT设计出来是为了与人类对话的。这与使用SQL之类的东西来“问问题”有很大的不同。人们必须像与人交流一样来与AI模型交流。由于这种交互是如此的重要,现在已经出现了“提示词工程”这种术语,专门描述在提示词方面的研究。高效的提示词可以极大提高输出结果的准确性。
分享提示已经变成了公共实践,当前学术界正在积极地研究这个问题。很多提示词是反直觉的,比如最近的一篇研究论文显示,一个非常高效的提示词短语是: “深呼吸,循序渐进地来解决这个问题”。到目前为止,我们还不完全了解如何最有效地利用该技术的前几次迭代,例如ChatGPT 3.5,更不用说最新的版本了。
提示词模版
创建有效的提示涉及建立请求上下文,并用特定于用户输入的值替换请求的部分内容。
在Spring AI中,提示框模板可以比作Spring MVC架构中的“视图”。模型对象,通常是java.util.Map,用于填充模板中的占位符。“渲染”后的字符串成为提供给AI模型的提示的内容。
发送给模型的提示的特定数据格式有很大的变化。提示符最初是简单的字符串,现在已经发展到包括多个消息,其中每个消息中的每个字符串表示模型的一个不同角色。
发送给模型的提示的特定数据格式有很大的变化。提示符最初是简单的字符串,现在已经发展到包括多个消息,其中每个消息中的每个字符串表示模型的一个不同角色。
嵌入
嵌入(Embedding)是一种将文本(如单词、短语、句子或文档)转换为数字向量表示的方法。这种向量化表示捕捉了文本的语义信息,使得模型能够以数学形式理解和操作自然语言。
嵌入的工作原理是将文本、图像和视频转换为称为向量的浮点数数组。嵌入后的向量通常是实数值(如 [0.1, -0.3, 0.7]),这些向量能够反映文本在语义空间中的相对位置。
嵌入的核心目的是捕捉文本的语义关系和上下文信息,从而支持各种NLP任务,例如:
- 语义相似度:两个语义上相近的单词或句子,其嵌入向量在空间中的距离较小。
- 分类和聚类:嵌入向量可以作为特征,用于分类或聚类任务。
- 搜索和推荐:通过计算嵌入之间的距离或相似度,找到相关内容。
在ChatGPT中,嵌入用于以下方面:
- 语言理解:模型将用户输入转化为嵌入,理解语义信息以生成相关回答。
- 知识存储:嵌入帮助模型在回答时调用相关的上下文或知识点。
- 搜索增强:通过嵌入匹配用户输入和知识库中的相关内容,提高生成回答的准确性。
举个例子, 假设模型生成了以下嵌入:
- “猫”:[0.21, -0.19, 0.37, …]
- “狗”:[0.20, -0.18, 0.36, …]
- “桌子”:[0.05, 0.33, -0.15, …]
通过计算余弦相似度或欧几里得距离,可以发现"猫"和"狗"的向量更加相似,而与"桌子"差异较大。
作为探索AI的Java开发人员,没有必要理解这些向量表示背后复杂的数学理论或特定的实现。对它们在AI系统中的角色和功能的基本了解就足够了,特别是当您将AI功能集成到应用程序中时。
Tokens
Tokens是AI模型工作的基石。在输入时,模型将单词转换为tokens,然后在输出时又将tokens转换成单词。
在英语中,一个token大约相当于一个单词的75%。作为参考,莎士比亚全集约90万字,可以翻译成约120万个tokens。
也许更为重要的是,Tokens = Money。在受托管的AI模型的上下文中,你的花费取决于使用的tokens的数量。不管是输入还是输出,都计入token的数量。
另外,模型也有token限制,具体来说就是一次API调用会限制处理的文本的数量。这就是所谓的上下文窗口。如果文本超过这个限制,将不会被模型处理。
举例来说,ChatCPT3 的token限制为4K,GPT4则有多个选择,可以是8K,16K或32K。Anthropic的Claude AI模型具有100K token限制,而Meta最近的研究创建了一个1M token限制的模型。
结构化输出
通常情况下,即使你要求 AI 模型输出JSON格式,但实际上它还是字符串。另外,要求“输出JSON”本身也不是一个准确的提示词。
这种复杂性导致了一个专门领域的出现,包括创建提示以产生预期的输出,然后将生成的简单字符串转换为用于应用程序集成的可用数据结构,如下图所示:

结构化输出转换采用精心设计的提示,通常需要与模型进行多次交互才能实现所需的格式。
训练你的AI模型
如何让AI模型拥有它没有被培训过的知识呢?
GPT3.5/4.0 知识库更新到2021年9月。
定制AI模型主要有三种技术手段。
- 微调(Fine Tuning)
在现有大模型的基础上,使用特定领域的数据进行二次训练,以调整模型的权重,提升其在特定任务上的表现。如构建医疗、法律行业的问答系统。但这种方式不适用于GPT这种规模太大的模型。
- 提示填充(Prompt Stuffing)
另外一种比较实际的方案是在提示词中填充你的数据。具体来说,就是将额外信息嵌入到提示中,以改进模型的回答或引导其生成目标输出,比如扩展上下文范围、提供更多相关背景,甚至注入具体的任务指令。
Spring AI 中的提示填充即所谓的RAG(Retrieval Augmented Generation,检索增强生成)
- 函数调用
通过AI模型解释用户的意图并将其映射到与定义的函数接口上,从而触发响应的逻辑或操作。
检索增强生成
Spring AI 中使用了Retrieval Augmented Generation 来实现提示填充。RAG主要包括两个阶段,一是检索阶段,在用户提出问题时,系统会通过搜索引擎、数据库查询或向量检索等技术,从外部知识库(如文档集合、数据库、网页等)中提取相关信息。二是生成阶段,使用生成式AI模型接收用户输入和检索到的信息,并根据二者生成答案。如下图所示:

其中offline部分是离线生成外部知识库的过程,runtime部分就是将用户问题与检索到的信息传入模型并返回生成结果的过程。
函数调用
大型语言模型在训练后是冻结的,这会导致知识陈旧,并且无法访问或修改外部数据。
函数调用机制可以解决这些缺点。它允许您注册自己的函数,以将大型语言模型连接到外部系统的api。这些系统可以为llm提供实时数据并代表它们执行数据处理操作。
Spring AI 极大简化了为支持函数调用而需要编写的代码。它为你处理函数调用的对话,你可以通过@Bean的形式提供函数,然后在提示选项中提供函数的bean名来激活该函数。此外,你也可以在单个提示符中定义和引用多个函数。如下所示:

结果评价
高效评价 AI 模型的输出结果对问题的准确性和有效性是非常重要的。这个评估过程包括分析生成的响应是否与用户的意图和查询的上下文一致。可以用来衡量响应质量的指标包括:相关性、连贯性和事实正确性。
其中一种方法是同时呈现用户的请求和 AI 模型的响应,查询该响应是否与提供的数据一致。进一步地,引入向量数据库存储的补充信息,提供额外上下文来支持评估过程。
Spring AI 提供了一个名为Evaluator API 的工具,用于自动化模型响应的评估过程。当然,目前只提供了一些基础评估策略。
开启你的 Spring AI 之旅
你可以通过 Spring Initializr 来创建你的 Spring AI 项目,也可以手动创建。
或者直接从github上下载demo:
- OpenAI:github.com/rd-1-2022/ai-openai-helloworld
- Azure OpenAI:github.com/rd-1-2022/ai-azure-openai-helloworld 或者 github.com/Azure-Samples/spring-ai-azure-workshop
下面以ai-azure-openai-helloworld为例,下载到本地后,配置好的你的api-key和endpoint。有的模型还需要额外设置一下temperature: 1。
temperature是一个用来控制生成式AI模型输出内容随机性的重要参数。数值越小,随机性越低。数值越大,随机性越高。
运行项目,访问curl localhost:8080/ai/simple即可。
Chat Client
ChatClient为与AI模型通信提供了流畅的API,它同时支持同步和流式编程模型。
创建ChatClient
下面是一个例子:
@RestController
class MyController {private final ChatClient chatClient;public MyController(ChatClient.Builder chatClientBuilder) {this.chatClient = chatClientBuilder.build();}@GetMapping("/ai")String generation(String userInput) {return this.chatClient.prompt().user(userInput).call().content();}
}
ChatClient.Builder是自动装配的bean,直接注入使用即可。
也可以禁用ChatClient.Builder 的自动装配:spring.ai.chat.client.enabled=false。这在联合使用多种对话模型时是很有用的。此时可以通过编程式生成:
ChatModel myChatModel = ... // usually autowiredChatClient.Builder builder = ChatClient.builder(this.myChatModel);// or create a ChatClient with the default builder settings:ChatClient chatClient = ChatClient.create(this.myChatModel);
流式 API 和 Response
你可以通过三种方式来创建链式API:prompt(),prompt(Prompt prompt) 和 prompt(String content)。
AI模型的返回类型是ChatResponse定义的,其中包括response的元数据,如该response所使用的tokens数量:
ChatResponse chatResponse = chatClient.prompt().user("Tell me a joke").call().chatResponse();
返回Entity
可以通过entity方法将返回的内容映射成对象实体,如下所示:
record ActorFilms(String actor, List<String> movies) {}ActorFilms actorFilms = chatClient.prompt().user("Generate the filmography for a random actor.").call() // send request to AI model.entity(ActorFilms.class);
流式响应
stream() 方法可以让结果异步返回:
Flux<String> output = chatClient.prompt().user("Tell me a joke").stream().content(); // string content response
当然,也可以直接通过异步的Flux<ChatResponse> chatResponse()来获得异步返回。
根据以上介绍可知,对AI 模型的调用分为同步和异步两种方式,前者使用call方法,后者使用stream方法。原始的返回内容应该是ChatResponse类型,其中包括了各种元数据。可以通过content方法仅仅只返回字符串类型,也可以通过entity方法来返回对象实体。
默认设置
如果通过默认设置的方式来创建ChatClient,那使用起来就比较简单了。
首先在配置类中创建chatClient:
@Configuration
class Config {@BeanChatClient chatClient(ChatClient.Builder builder) {return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a Pirate").build();}}
然后调用这个chatClient:
@RestController
class AIController {private final ChatClient chatClient;AIController(ChatClient chatClient) {this.chatClient = chatClient;}@GetMapping("/ai/simple")public Map<String, String> completion(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {return Map.of("completion", this.chatClient.prompt().user(message).call().content());}
}
在 SpringAI 中,默认的系统文本指的是在与 AI 模型交互时,发送给模型的初始说明或上下文信息。系统文本通常用于指导模型的行为,例如确定其回答的风格、角色或语气。这是通过设定一个隐式的“系统消息”来完成的,类似于在 OpenAI 的 Function Calling 中使用的 System Role Messages。
带参数的默认系统文本
修改默认的系统文本如下:
@Configuration
class Config {@BeanChatClient chatClient(ChatClient.Builder builder) {return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}").build();}}
调用:
@RestController
class AIController {private final ChatClient chatClient;AIController(ChatClient chatClient) {this.chatClient = chatClient;}@GetMapping("/ai")Map<String, String> completion(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message, String voice) {return Map.of("completion",this.chatClient.prompt().system(sp -> sp.param("voice", voice)).user(message).call().content());}}
其他默认配置项
在ChatClient级别,你可以指定默认的提示词配置,如
defaultOptioons(ChatOptions chatOptions): 可以传入通用ChatOptions的配置,也可以传入特定模型,如OpenAiChatOptions配置。defaultFunction(String name, String description, java.util.function.Function<I, O> function):三个参数分别表示函数名,函数描述和模型要调用的函数本身。defaultFunctions(String… functionNames):在应用上下文中定义的函数bean的名称。defaultUser(String text),defaultUser(Resource text),defaultUser(Consumer<UserSpec> userSpecConsumer): 用于定义用户文本。Consumer<UserSpec>允许你用lambda表达式来指定用户文本和其他默认参数。defaultAdvisors(Advisor… advisor):在与 AI 模型交互的过程中拦截请求或响应,修改相应的数据。QuestionAnswerAdvisor实现通过在提示词里附加与用户文本相关的上下文信息来支持检索增强生成(RAG)模式。
这些方法去掉default前缀,就是相应的自定义方法了,可以用来覆盖默认值。
Advisors
在Spring AI 中,Advisors 是用于拦截和增强AI 操作行为的组件。可以将其看作是一种中间件机制,允许开发者在 AI 请求的处理流程中插入自定义逻辑,以调整默认行为或实现特定需求。
ChatClient的流式API提供了AdvisorSpec接口用来配置advisors。如下所示:
interface AdvisorSpec {AdvisorSpec param(String k, Object v);AdvisorSpec params(Map<String, Object> p);AdvisorSpec advisors(Advisor... advisors);AdvisorSpec advisors(List<Advisor> advisors);
}
advisors根据添加的先后顺序执行。
检索增强生成(Retrieval Augmented Generation)
向量数据库中存储了AI模型不知道的数据。当用户发送一个请求时,QuestionAnswerAdvisor 会从向量数据库中查询与用户问题相关的信息,然后将其附加到用户文本中,供 AI 模型来生成响应。如下所示:
ChatResponse response = ChatClient.builder(chatModel).build().prompt().advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults())).user(userText).call().chatResponse();
动态过滤表达式
在运行时更新过滤表达式如下:
ChatClient chatClient = ChatClient.builder(chatModel).defaultAdvisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults())).build();// Update filter expression at runtime
String content = this.chatClient.prompt().user("Please answer my question XYZ").advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'Spring'")).call().content();
FILTER_EXPRESSION 参数可以让你动态过滤搜索结果。
对话记忆
接口ChatMemory表示对话历史记录的存储。其中包含添加会话消息,获取会话消息和删除会话记录等方法。
该接口有两个实现,分别是 InMeomoryChatMemory和CassandraChatMemory,前者是内存存储,后者是持久化存储。
ChatMemory典型的使用场景:
- 用户多次提问,需要 AI 基于历史记录给出精准回答。
- 用户在一个会话中完成一个多步骤任务,需要 AI 模型保存中间步骤数据。
- 跨会话记忆,将用户的偏好和历史交互持久化,以便在后续会话中为用户提供个性化体验。
- 调试与分析,开发者可以通过ChatMemory 检查对话历史,分析AI 的生成为行为是否符合预期。
很多advisor实现均使用了ChatMemory接口来将会话历史添加到提示词中,只不是细节不通而已。如MessageChatMemoryAdvisor , PromptChatMemoryAdvisor ,VectorStoreChatMemoryAdvisor 。
日志
SimpleLoggerAdvisor 是一个记录request和response的日志advisor,开启如下:
ChatResponse response = ChatClient.create(chatModel).prompt().advisors(new SimpleLoggerAdvisor()).user("Tell me a joke?").call().chatResponse();// set up the log level
loggging.level.org.springframework.ai.chat.client.advisor=DEBUG
你可以定制日志格式:
SimpleLoggerAdvisor(Function<AdvisedRequest, String> requestToString,Function<ChatResponse, String> responseToString
)SimpleLoggerAdvisor customLogger = new SimpleLoggerAdvisor(request -> "Custom request: " + request.userText,response -> "Custom response: " + response.getResult()
);
参考资料
[1]. https://docs.spring.io/spring-ai/reference/concepts.html
相关文章:
Spring AI 框架介绍
Spring AI是一个面向人工智能工程的应用框架。它的目标是将Spring生态系统的设计原则(如可移植性和模块化设计)应用于AI领域,并推广使用pojo作为AI领域应用的构建模块。 概述 Spring AI 现在(2024/12)已经支持语言,图像…...

【Oracle11g SQL详解】UPDATE 和 DELETE 操作的正确使用
UPDATE 和 DELETE 操作的正确使用 UPDATE 和 DELETE 是 Oracle 11g 中用于修改和删除表中数据的重要 SQL 语句。在操作时,需特别注意数据筛选条件的准确性,以避免意外更改或删除数据。本文将详细介绍这两种语句的用法、注意事项及相关案例。 一、UPDATE…...

Advanced Macro Techniques in C/C++: `#`, `##`, and Variadic Macros
Advanced Macro Techniques in C/C: #, ##, and Variadic Macros 文章目录 Advanced Macro Techniques in C/C: #, ##, and Variadic MacrosIllustrative Examples of Macros Using # and ##Stringification ExampleToken Concatenation ExampleNested Macros Example Key Conc…...

Maven、JAVAWeb、Servlet
知识点目标 1、MavenMaven是什么Maven项目的目录结构Maven的Pom文件Maven的命令Maven依赖管理Maven仓库JavaWeb项目 2.网络基础知识 3、ServletMaven Maven是什么 Maven是Java的项目管理工具,可以构建,打包,部署项目,还可以管理…...

分布式资源调度——yarn 概述(资源调度基本架构和高可用的实现)
此文章是学习笔记,图片均来源于B站:哈喽鹏程 yarn详细介绍 1、yarn 简介1.1 yarn的简介1.2 yarn 的基本架构1.3. yarn 的高可用 2、yarn 调度策略、运维、监控2.1 yarn 的调度策略2.1.1 FIFO scheduler(先进先出)2.1.2 容量调度2.1.3 公平调度 2.2 yarn…...

网页开发的http基础知识
请求方式-GET:请求参数在请求行中,没有请求体,如:/brand/findAll?nameoPPo&status1。GET请求大小在浏览器中是有限制的请求方式-POST:请求参数在请求体中,POST请求大小是没有限制的 HTTP请求…...

学习方法的进一步迭代————4
今天又在怀疑第二大脑的可靠程度 为什么呢? 还是因为自己没记住东西,感觉没学到东西。 其实自己知道大脑本就不应该用来存放知识而是用来思考知识,但是自己还是陷在里面了,我觉得其本质不是因为认知还不够,也不是因为还有点不适…...

数据科学家创建识别假图像的工具
Pixelator v2 是一款用于识别假图像的工具。它采用了全新的图像真实性技术组合,其能力超出了人眼所能看到的范围。 它能够以比传统方法更高的准确度识别图像中的细微差异,并且已被证明能够检测到小至 1 个像素的交替。 使用 SSIM 和 Pixelator v2 突出显…...

使用 GORM 与 MySQL 数据库进行交互来实现增删改查(CRUD)操作
1、安装 GORM 和 MySQL 驱动 新版本库是gorm.io/gorm go get -u gorm.io/gormgo get -u gorm.io/driver/mysql2、连接 MySQL 数据库 package mainimport ("gorm.io/driver/mysql""gorm.io/gorm""log" )func main() {// 数据源名称 (DSN) 格式&a…...

Day2 生信新手笔记: Linux基础
一、基础知识 1.1 服务器 super computer 或 server 1.2 组学数据分析 组学数据:如基因组学、转录组学、蛋白质组学等; 上游分析:主要涉及原始数据的获取和初步处理,计算量大,消耗的资源较多,在服务器完…...
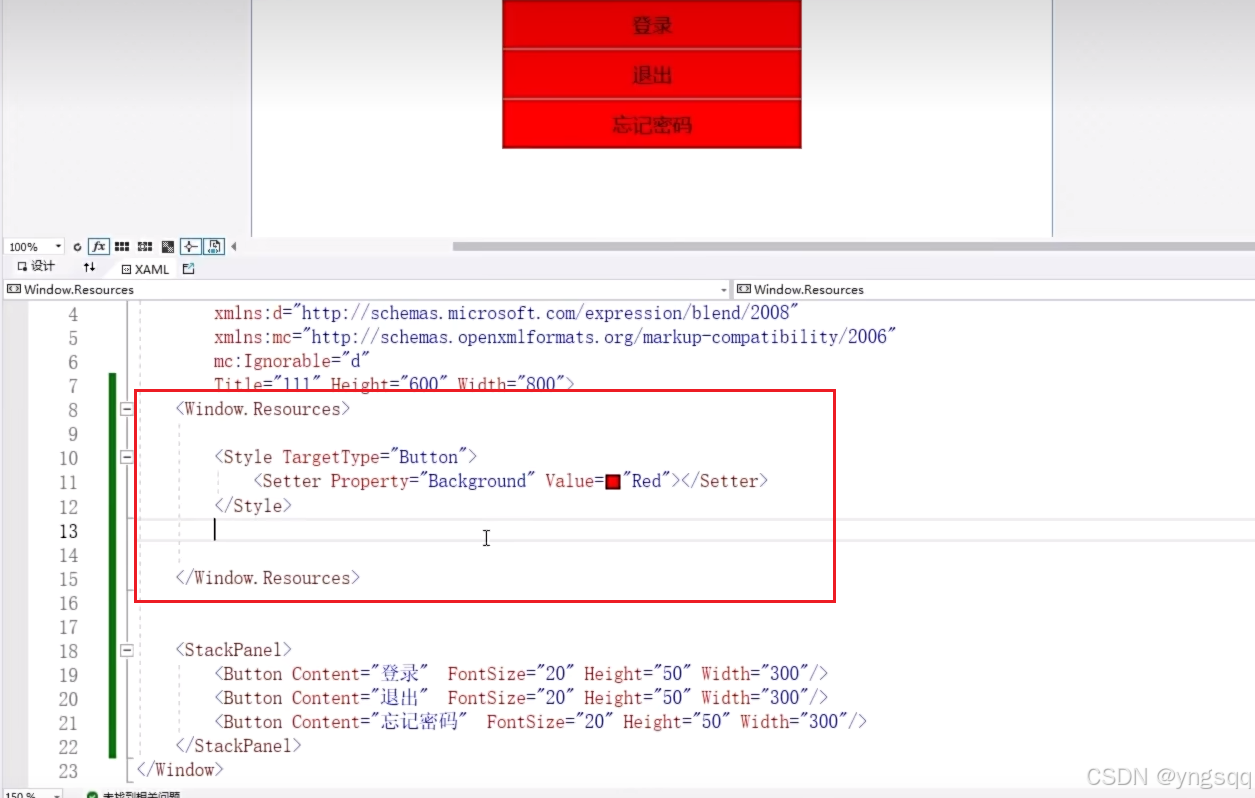
001集—— 创建一个WPF项目 ——WPF应用程序入门 C#
本例为一个WPF应用(.NET FrameWork)。 首先创建一个项目 双击xaml文件 双击xaml文件进入如下界面,开始编写代码。 效果如下: 付代码: <Window x:Class"WpfDemoFW.MainWindow"xmlns"http://schema…...

【C++】1___引用
一、基本语法 数据类型 &别名 原名 #include<iostream> using namespace std; int main(){int a 10;int &b a;cout<<"a"<<a<<endl; // a10cout<<"b"<<b<<endl;// a10b 20;cout<<"a…...

如何通过 JWT 来解决登录认证问题
1. 问题引入 在登录功能的实现中 传统思路: 登录页面时把用户名和密码提交给服务器服务器验证用户名和密码,并把检验结果返回给后端如果密码正确,则在服务器端创建 session,通过 cookie 把 session id 返回给浏览器 但是正常情…...

高效集成:将聚水潭数据导入MySQL的实战案例
聚水潭数据集成到MySQL:店铺信息查询案例分享 在数据驱动的业务环境中,如何高效、准确地实现跨平台的数据集成是每个企业面临的重要挑战。本文将聚焦于一个具体的系统对接集成案例——将聚水潭的店铺信息查询结果集成到MySQL数据库中,以供BI…...

Jenkins-基于 JNLP协议的 Java Web 启动代理
在上一篇的基础配置上进行以下步骤 工作流程: 通过 JNLP 启动代理,客户端从 Jenkins 服务器上下载一个 agent.jar 文件。该文件启动时,代理程序通过 JNLP 协议连接到 Jenkins 主节点。一旦连接成功,代理节点就可以执行从主节点分…...

Qt数据库操作-QSqlQueryModel 的使用
QSqlQueryModel 功能概述 QSqlQueryModel 是 QSqlTableModel 的父类。QSqlQueryModel 封装了执行 SELECT 语句从数据库查询数据的功能,但是 QSqlQueryModel 只能作为只读数据源使用,不可以编辑数据。QSqlQueryModel 类的主要函数如下: 接口…...

C语言编程1.21波兰国旗问题
题目描述 桌上有 n ( 1 < n < 10000 ) 面小旗,一部分是白旗,一部分是红旗(波兰国旗由白色和红色组成)。唯一允许的操作是交换两面小旗位置。请你设计一个算法,用最少的交换操作将所有的白旗都置于红旗的之前。 输入格式 第一行为一个…...

如何利用微型5G网关为智慧无人矿车提供精确定位
随着5G、AI、物联网技术的发展和普及,越来越多行业正在加快生产、运营、管理的无人化、数字化与智能化,以适应当前我国“智慧、绿色、低碳”的新型发展模式需要。其中矿产业就是典型场景之一。针对矿山场景的智慧化、无人化转型,佰马提供基于…...
使用docker-compese部署SFTPGo详解
官网:SFTP & FTP as a Managed Service (SaaS) and On-premise 一、SFTPGo简介 SFTPGo 是一款功能强大的文件传输服务器软件。它支持多种协议(SFTP、SCP、FTP/S、WebDAV、HTTP/S)和多个存储后端。 借助 SFTPGo,您可以利用本地…...

Ajax基础总结(思维导图+二维表)
一些话 刚开始学习Ajax的时候,感觉很模糊,但是好像学什么都是这样的,很正常,但是当你学习的时候要持续性敲代码,边敲代码其实就可以理解很多了。然后在最后的总结,其实做二维表之后,就可以区分…...

Triton模型服务化实战:从Notebook到高可用推理API
1. 项目概述:这不是一次模型训练,而是一场工程交付“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题里藏着一个被太多人轻描淡写、却让无数团队在临门一脚时彻底卡死的真相:Notebook 是思考的草稿纸&…...

5分钟快速上手gInk:Windows上最轻量级的免费屏幕画笔工具完整指南
5分钟快速上手gInk:Windows上最轻量级的免费屏幕画笔工具完整指南 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk gInk是一款专为Windows设计的屏幕画笔工具…...

微信小程序161~200
收货地址实现删除收货地址删除滑块SwipeCell自动收起调用之前的swipeCell商品管理配置商品管理分包-封装商品模块接口import http from "../utils/http"/*** description 获取商品列表数据* param {Object} param {page,limit,categoryId,category2Id}* returns Prom…...

终极指南:如何用Edgar-Unity打造无限变化的2D地牢世界
终极指南:如何用Edgar-Unity打造无限变化的2D地牢世界 【免费下载链接】Edgar-Unity Unity Procedural Level Generator 项目地址: https://gitcode.com/gh_mirrors/ed/Edgar-Unity 还在为每个关卡的手工设计而烦恼吗?是否梦想着让你的游戏地图能…...

如何解决跨平台资源下载难题:res-downloader的完整使用指南
如何解决跨平台资源下载难题:res-downloader的完整使用指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否…...

构建AI模型实时反馈回路:从概念漂移到持续进化
1. 项目概述:当AI模型不再“一锤定音”,而是持续呼吸、自我校准你有没有遇到过这样的情况:一个花了三个月调优的推荐模型,上线首周点击率提升12%,第二周开始缓慢下滑,到第四周几乎回到基线水平?…...

UABEA:跨平台Unity游戏资源编辑神器,解锁游戏模组制作新境界
UABEA:跨平台Unity游戏资源编辑神器,解锁游戏模组制作新境界 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 你是否曾想修改游戏中的角色皮肤、替换背景音乐,或是深…...

UE5.6低延迟视频推流实战:从采集编码到RTMP传输全链路解析
1. 这不是“加个插件就能播”的事:UE5.6视频流推送的真实战场 很多人看到“UE5.6推送视频流”这个标题,第一反应是:“哦,用Media Player播放本地MP4?或者接个RTMP推流插件?”——我试过,也踩过坑…...

5分钟快速上手:TegraRcmGUI Switch注入图形化工具终极指南
5分钟快速上手:TegraRcmGUI Switch注入图形化工具终极指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款专为Nintendo Switc…...

spring源码bean生命周期篇 五 如何解决循环依赖
一.spring循环依赖 1. 什么是循环依赖? bean的生命周期前面的章节我们有讲解过大量的源码,我们粗略的分为这几步 spring扫描class获取BeanDefintionspring根据BeanDefintion实例化bean创建bean之前需要实例化对象,实例化后填充原始对象中的属…...