【论文复现】隐式神经网络实现低光照图像增强

📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


❀ 隐式神经网络实现低光照图像增强
- 引言
- 那么目前低光照图像增强还面临哪些挑战呢?
- 挑战1. 不可预测的亮度降低和噪声
- 挑战2.度量友好版本和视觉友好版本之间的差异
- 挑战3. 有限的配对训练数据
- 1.论文概述(原文摘要、引言部分)
- 2.核心创新点(原文方法部分)
- 2.1 归一化的神经表示
- 什么是归一化的神经表示?
- 为什么归一化的神经表示能够奏效?
- 2.2 文本驱动的外观识别器
- 文本驱动的判别表示
- 外观驱动的判别表示
- 2.3 整体框架
- 3.实验部分
- 5.复现过程(重要)
- 5.1 数据准备
- 5.2 环境搭建
- 下载
- 快速运行
- 训练
- 5.3 取消SSL证书验证(重要)
- 5.4 生成增强图像
- 5.5 模型调优
2023年人工智能顶会ICCV会议论文复现
Implicit Neural Representation for Cooperative Low-light Image Enhancement
引言
本文涉及到低光照图像增强、图像的神经表示以及多模态学习等领域,下面将简单介绍下相关知识。
本文所涉及的所有资源的获取方式:这里
1.低光照图像增强
低光图像增强是图像处理领域的一个重要研究方向,旨在改善在低照度条件下拍摄的图像质量。低光条件下的图像往往具有低对比度、噪点增加和细节丢失等问题。低光图像增强方法通过调整图像的亮度、对比度、色彩平衡等方面来提高图像的质量和视觉感知效果。

2.图像的神经表示
图像的神经表示指的是通过神经网络模型对图像进行编码和表示的方法。传统的图像表示方法通常使用手工设计的特征提取器,如SIFT、HOG等。而神经表示方法则通过深度学习模型,如卷积神经网络(CNN)、自编码器等,学习到图像的高级特征表示。这些神经表示能够捕捉图像的语义信息和结构信息,对于图像分类、目标检测、图像生成等任务具有重要作用。
3.多模态学习
多模态学习是指利用不同的感知模态(如图像、文本、语音等)之间的关联性进行联合学习和信息融合的方法。Radford提出从语言监督中学习视觉模型,称为CLIP。经过4亿对图像-文本对的训练,它可以用自然语言描述任何视觉概念,并且无需任何特定的训练就可以转移到其他任务中。CLIP模型的核心思想是通过对图像和文本进行对比学习,使得它们在嵌入空间中的表示能够相互匹配。这意味着,在嵌入空间中,相关的图像和文本将被映射到相近的位置,从而使得模型能够理解图像和文本之间的语义关系,如下图。
CLIP模型通过一个共享的编码器来处理图像和文本输入。对于图像,它使用卷积神经网络(CNN)对图像进行编码;对于文本,它使用Transformer模型对文本进行编码。编码器的输出表示图像和文本在嵌入空间中的表示。CLIP模型的优点是不需要大量的标注数据,可以使用大规模的无标注图像和文本数据进行预训练。预训练后的CLIP模型可以用于多种任务,如图像分类、图像生成、图像检索等。它在许多视觉和语言相关的任务中取得了出色的性能,并展现了强大的泛化能力。
那么目前低光照图像增强还面临哪些挑战呢?
挑战1. 不可预测的亮度降低和噪声
在低光条件下,图像往往会出现亮度降低和噪声增加的问题。然而,这些退化因素的具体程度和方式往往是不可预测的,因为它们受到多种因素的影响,如光照条件、相机设置等。现有的低光图像增强方法难以准确地对这些退化因素进行建模和处理,导致增强结果可能不够鲁棒并且无法满足视觉感知的要求。
挑战2.度量友好版本和视觉友好版本之间的差异
低光图像增强方法通常会追求在度量上有所改善,例如增加对比度、减少噪声等。然而,这些度量友好的改善并不总是与人眼感知的视觉友好相一致。在一些情况下,虽然度量上的改善较大,但图像质量却被认为是不自然或不真实的。因此,现有方法在度量友好版本和视觉友好版本之间存在固有的差距,无法很好地平衡二者之间的关系。
挑战3. 有限的配对训练数据
有限的配对训练数据:低光图像增强方法通常需要使用配对的训练数据,即低光图像和对应的高质量图像。然而,获取大规模配对数据是一项耗时且昂贵的任务。由于配对数据的限制,现有方法在模型的泛化能力和适应性方面存在一定的局限性。此外,配对数据可能无法涵盖所有的场景和退化情况,导致模型的性能受到限制。
1.论文概述(原文摘要、引言部分)
NeRCo(Implicit Neural Representation for Cooperative Low-light Image Enhancement)提出了一种名为NeRCo的隐式神经表示方法,用于合作式低光图像增强。现有的低光图像增强方法存在以下三个限制:不可预测的亮度降低和噪声、度量友好版本和视觉友好版本之间的固有差距,以及有限的配对训练数据。为了解决这些限制,论文提出了NeRCo方法,它以无监督的方式稳健地恢复感知友好的结果。
具体而言,NeRCo通过一个可控的拟合函数统一了现实场景中多样的退化因素,从而提高了鲁棒性。对于输出结果,论文引入了来自预训练视觉-语言模型的先验信息,采用语义导向的监督方法。它不仅仅追随参考图像,还鼓励结果符合主观期望,寻找更加视觉友好的解决方案。此外,为了减少对配对数据的依赖并减少解决空间,论文开发了一个双闭环约束增强模块,它以自监督的方式与其他相关模块合作进行训练。
最后,广泛的实验证明了我们提出的NeRCo方法的鲁棒性和优越性能。
2.核心创新点(原文方法部分)
2.1 归一化的神经表示
什么是归一化的神经表示?
归一化的神经表示(Neural Representation Normalization)是一种在神经网络中对特征表示进行标准化的技术。它的目的是通过对神经表示进行归一化处理,使得不同样本的特征表示在统计上具有相似的分布,从而提高模型的鲁棒性和泛化能力。在神经网络中,每个神经元的输出表示了输入数据的某种特征。这些特征往往具有不同的尺度和范围,可能会对模型的训练和表征能力产生不利影响。神经表示归一化的目的是通过对特征进行调整,使得它们具有相似的均值和方差,从而减少特征之间的差异。本文是利用余弦相似性对输入进行重构,在与encoder进行编码后的特征concat,而后经过多层感知机得到归一化后的图像,如下图:

为什么归一化的神经表示能够奏效?
- 学习丰富的特征表示:神经网络模型能够通过多层非线性变换和映射来学习丰富的特征表示。在低光照条件下,图像往往存在低对比度、噪点增加和细节丢失等问题。通过神经网络的层次结构,可以逐渐提取出更高级别、更抽象的特征,从而更好地捕捉图像中的语义信息和结构信息。
- 鲁棒性和泛化能力:神经表示能够从大量的标记数据中学习到数据的潜在表示,具有较强的鲁棒性和泛化能力。在低光照图像增强任务中,由于光照条件的变化和图像退化的多样性,很难通过手工设计的规则和特征提取器来准确地恢复图像质量。神经表示方法可以通过大规模数据的训练来学习到低光照图像的共性特征,从而更好地适应各种退化情况,提高增强效果的鲁棒性和泛化能力。
- 感知导向的引导:在低光照图像增强任务中,仅仅恢复图像的亮度和对比度等低级特征可能不足以获得视觉上友好的结果。神经表示方法可以结合感知导向的引导,利用预训练的视觉模型的先验知识来指导增强结果的生成,使得增强后的图像更加自然和具有良好的视觉感知效果。

2.2 文本驱动的外观识别器
本文提出的文本驱动的外观鉴别器(在左侧区域)和我协同关注力模块(在右侧区域)的细节。前者用文本和图像模态监督输入,并关注高频成分。后者将注意力调整到不同的渠道并输出注意图。

文本驱动的判别表示
本文将弱光域表示为L,高光域表示为h。如图上图所示,本文引入多模态学习来同时监督图像和文本模态的图像。具体而言,采用了最近广为人知的CLIP模型来获得高效先验。它由两个预训练的编码器组成,即文本的Enct和图像的Enci,具体代码如下:
# clip模型核心代码class CLIP(nn.Module):def __init__(self,embed_dim: int,# visionimage_resolution: int,vision_layers: Union[Tuple[int, int, int, int], int],vision_width: int,vision_patch_size: int,# textcontext_length: int,vocab_size: int,transformer_width: int,transformer_heads: int,transformer_layers: int):super().__init__()self.context_length = context_lengthif isinstance(vision_layers, (tuple, list)):vision_heads = vision_width * 32 // 64self.visual = ModifiedResNet(layers=vision_layers,output_dim=embed_dim,heads=vision_heads,input_resolution=image_resolution,width=vision_width)else:vision_heads = vision_width // 64self.visual = VisionTransformer(input_resolution=image_resolution,patch_size=vision_patch_size,width=vision_width,layers=vision_layers,heads=vision_heads,output_dim=embed_dim)self.transformer = Transformer(width=transformer_width,layers=transformer_layers,heads=transformer_heads,attn_mask=self.build_attention_mask())self.vocab_size = vocab_sizeself.token_embedding = nn.Embedding(vocab_size, transformer_width)self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))self.ln_final = LayerNorm(transformer_width)self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
外观驱动的判别表示
为了生成可靠的内容,图像监督是必要的。如中文本驱动器框架图紫色区域(框架图)所示,本文叠加了一个判别器来区分预测结果和真实图像,从而提高了图像级的真实性(例如颜色、纹理和结构)。考虑到图像处理中的细节失真,本文嵌入了一个由高通滤波器和相同结构的鉴别器组成的高频路径。滤波器提取高频分量,鉴别器在边缘级对高频分量进行监督。基于这种双路色边判别结构,实现了色彩与细节的权衡。
在训练过程中,TAD在学习L和H之间的双向映射关系中起对抗作用,利用的是sobel算子实现图像的高通滤波,代码如下。
# -*- coding: utf-8 -*-
from re import I
import torch
import torch.nn as nn
import torch.nn.functional as F
from PIL import Image
from torchvision import transforms
import os
trans = transforms.Compose([transforms.ToTensor()])class GradLayer(nn.Module):def __init__(self):super(GradLayer, self).__init__()kernel_v = [[0, -1, 0],[0, 0, 0],[0, 1, 0]]kernel_h = [[0, 0, 0],[-1, 0, 1],[0, 0, 0]]kernel_h = torch.FloatTensor(kernel_h).unsqueeze(0).unsqueeze(0)kernel_v = torch.FloatTensor(kernel_v).unsqueeze(0).unsqueeze(0)self.weight_h = nn.Parameter(data=kernel_h, requires_grad=False)self.weight_v = nn.Parameter(data=kernel_v, requires_grad=False)self.gray2RGB = torch.nn.Conv2d(1, 3, kernel_size=1, stride=1, padding=0)def get_gray(self,x):''' Convert image to its gray one.'''gray_coeffs = [65.738, 129.057, 25.064]convert = x.new_tensor(gray_coeffs).view(1, 3, 1, 1) / 256x_gray = x.mul(convert).sum(dim=1)return x_gray.unsqueeze(1)def forward(self, x):if x.shape[1] == 3:x = self.get_gray(x)x_v = F.conv2d(x, self.weight_v, padding=1)x_h = F.conv2d(x, self.weight_h, padding=1)x = torch.sqrt(torch.pow(x_v, 2) + torch.pow(x_h, 2) + 1e-6)x = self.gray2RGB(x)return xclass GradLoss(nn.Module):def __init__(self):super(GradLoss, self).__init__()self.loss = nn.L1Loss()self.grad_layer = GradLayer()def forward(self, output, gt_img):output_grad = self.grad_layer(output)gt_grad = self.grad_layer(gt_img)return self.loss(output_grad, gt_grad)def tran(img):net = GradLayer().to(torch.device('cuda:0'))img = net(img) # input img: data range [0, 1]; data type torch.float32; data shape [1, 3, 256, 256]image = img * 4.return image
2.3 整体框架
- 如图所示,给定一个弱光图像IL,我们首先通过神经表示(NRN,第3.2节)对其进行归一化,以提高模型对不同退化条件的鲁棒性。

- 然后,Mask Extractor 模块从图像中提取注意掩模,以指导不同区域的增强。之后,增强模块GH(以ResNet为代表)生成高光图像eIH。为了保证图像的质量,设计了一个文本驱动的外观判别器来监督图像的生成,其中文本驱动的监督保证了语义的可靠性,外观监督保证了视觉的可靠性。然后,eIH通过退化模块GL转换回低光域eeIL,并计算与原始低光图像IL的一致性损失。
- 在训练过程中,我们运行了整个过程,如图1所示。我们输入两幅图像(即弱光IL和高光IH)。IL被增强为eIH,然后再转化回弱光eeIL。IH反之亦然。注意到IH仅用于训练目的,即以无监督的方式训练模型以获得更好的增强而不是退化。因此,我们只使用NRN来增强IL而不降低IH。对于推理,直接将IL增强为eIH,不做任何其他操作,
- NeRco整体架构如下所示:NeRCo的工作流程。提出了一种包含双闭环分支的合作对抗增强过程,每个分支包含一个增强操作和一个退化操作。我们嵌入了一个掩模提取器(ME)来描绘退化分布,并嵌入了一个神经表示归一化(NRN)模块来归一化输入弱光图像的退化情况。所有这些都被一起训练以相互约束,锁定到一个更精确的目标域。红色表示注意力图的转移。

3.实验部分
本文在三个主流的低光照图像数据集上做了消融实验,在不同度量、不同的模型、自监督方法、无监督方法做了测试,本文提出的方法达到了新sota,如下图:
从实际的图像增强效果也可以看出,本文提出的方法优于先前的方法:

4.结论
总结而言,该论文提出了一种名为NeRCo的隐式神经表示方法,用于协同弱光图像增强。具体而言,该方法通过以下几个方面来实现:
- 利用神经表示来归一化输入退化图像的水平,包括暗亮度和自然噪声,从而增强方法对不同退化因素的鲁棒性。
- 引入高频路径和预训练的视觉语言模型的先验信息作为感知导向的引导,以确保输出增强图像在视觉上更加友好和自然。
- 开发双闭环合作约束来训练增强模块,以减轻对配对数据的依赖,并以自监督的方式增强弱光场景。这种合作约束促使所有组件相互约束,进一步减少解决方案的空间。
通过大量的实验证明,该方法在弱光图像增强任务上表现出优越性能,与其他性能最好的方法相比具有明显的优势。此外,该方法的组件还为其他低级任务,如图像去雾、压缩感知和高光谱成像等,提供了宝贵的灵感和参考。
总体而言,该论文提出的NeRCo方法通过引入隐式神经表示、感知导向引导和双闭环合作约束等创新的方法,有效地解决了弱光图像增强中存在的挑战,为该领域的研究和应用提供了有价值的贡献。成具有更合理笔画连接的更高质量的书法字体,并且在常规字体上也有令人满意的表现
5.复现过程(重要)
5.1 数据准备
- Linux or macOS
- Python 3.8
- NVIDIA GPU + CUDA CuDNN
提示
这里的python版本无需固定3.8,经实测,python 3.6、python 3.9代码均可运行。
5.2 环境搭建
键入命令:
pip install -r requirements.txt
提示
这里实测,requirements.txt的一些依赖库版本过高,清华源无法安装,只需要安装到清华源目前现有最高的版本即可。
例如,我们在安装依赖库的时候键入命令pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple

警告
ERROR: Could not find a version that satisfies the requirement torch>=1.12.0
这里会报错找不到满足torch>=1.12.0的错误,我们只需要从上图中找到清华源中关于torch的最新版本1.10.2,我们在requirements.txt中将torch>=1.12.0替换为torch>=1.10.2即可,若遇到其他依赖库版本找不到的问题,同样使用此种解决方式。

下载
你需要创建目录 ./saves/[YOUR-MODEL] (例如 ./saves/LSRW).
下载经过预训练的模型并将其放入 ./saves/[YOUR-MODEL].
在这里,已经发布了预训练模型的两个版本,它们是在[LSRW]上训练的 LSRW数据集 和 LOL 数据集的下载链接如下:
NeRCo trained on LSRW
NeRCo trained on LOL
最终关于预训练模型的目录应该如下:

快速运行
- 创建目录 ./dataset/testA and ./dataset/testB.
- 将测试图像放入/dataset/testA(这里应该保留./dataset/testB中的任何一个图像,以确保程序可以启动,具体放置方法可以看下图)
- 使用预先训练的权重测试模型:
CUDA_VISIBLE_DEVICES=0 python test.py --dataroot ./dataset --name [YOUR-MODEL] --preprocess=none
- 测试结果将保存到以下目录中: ./results/[YOUR-MODEL]/test_latest/images, 将显示在此处的html文件中: ./results/[YOUR-MODEL]/test_latest/index.html.

训练
- 下载训练低光数据并将其放入 ./dataset/trainA.
- 随机采用数百个普通光图像,并将它们放在 ./dataset/trainB.
- 训练模型代码如下:
cd NeRCo-main
mkdir loss
CUDA_VISIBLE_DEVICES=0 python train.py --dataroot ./dataset --name [YOUR-MODEL]
- 损失曲线保存在目录 ./loss.
- 要查看更多中间结果,请查看 ./saves/[YOUR-MODEL]/web/index.html.
5.3 取消SSL证书验证(重要)
在运行CUDA_VISIBLE_DEVICES=0 python test.py代码的过程中,需要在clip.py文件里要添加取消证书验证代码,否则会报错如下:
警告
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED]
取消证书验证代码:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
添加位置如下:

5.4 生成增强图像
- 一切准备就绪后,运行以下命令即可得到增强后的图像。
CUDA_VISIBLE_DEVICES=0 python test.py --dataroot ./dataset --name [YOUR-MODEL] --preprocess=none
- 增强后的图像默认路径在 results/LSRW/test_latset/images 路径下,如下图所示:

- 增强后的图片与原始图片,增强效果非常好,大家在这里也可以换成自己的数据集测试。

5.5 模型调优
本文所使用的高斯滤波算子为sobel算子,可以将滤波算子替换为拉普拉斯算子,Laplace算子是一种基于二阶导数的边缘检测算子,用于检测图像中的边缘和纹理。与Sobel算子不同,Laplace算子直接计算图像像素的二阶导数。它通过计算像素值周围邻域的梯度变化来识别边缘。Laplace算子对边缘进行二次微分,可以检测到边缘的更高阶特征,这里给出拉普拉斯算子的示例代码以供参考:
import cv2
import numpy as np
from matplotlib import pyplot as pltdef correl2d(img, window):m = window.shape[0]n = window.shape[1]# 图像边界填0扩展img_border = np.zeros((img.shape[0] + m - 1, img.shape[1] + n - 1))img_border[(m - 1) // 2:img.shape[0] + (m - 1) // 2, (n - 1) // 2:img.shape[1] + (n - 1) // 2] = imgimg_result = np.zeros(img.shape)for i in range(img.shape[0]):for j in range(img.shape[1]):temp = img_border[i:i + m, j:j + n]img_result[i, j] = np.sum(np.multiply(temp, window))return img_resultimg = cv2.imread('Fig0338.tif', 0)img_list = [img]
# 拉普拉斯滤波器模板
window1 = np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]])
# 带有对角项的拉普拉斯滤波器模板
window2 = np.array([[1, 1, 1], [1, -8, 1], [1, 1, 1]])img_result = correl2d(img, window1)# # 对拉普拉斯的结果做标定
img_lap = 255*(img_result-img_result.min())/(img_result.max()-img_result.min())
img_list.append(img_lap)# 将原图加上拉普拉斯滤波的结果图得到最终的锐化结果
img_sharpened = img - img_result
img_list.append(img_sharpened)# 对window2再执行一遍锐化操作
img_result = correl2d(img, window2)
img_sharpened = img - img_result
img_list.append(img_sharpened)_, axs = plt.subplots(2, 2)for i in range(2):for j in range(2):axs[i, j].imshow(img_list[i * 2 + j], vmin=0, vmax=255, cmap='gray')axs[i, j].axis('off')plt.savefig('sharpen.jpg')
plt.show()
提示
完整代码见附件。
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里
相关文章:
【论文复现】隐式神经网络实现低光照图像增强
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ 隐式神经网络实现低光照图像增强 引言那么目前低光照图像增强还面临哪些挑战呢? 挑战1. 不可预测的亮度降低和噪声挑战2.度量友好…...

Python知识分享第十九天-网络编程
网络编程 概述用来实现 网络互联 不同计算机上运行的程序间可以进行数据交互也叫Socket编程 套接字编程 三要素IP地址概述设备在网络中的唯一标识分类IPV4城域网13广域网22局域网31IPV6八字节 十六进制相关dos命令查看ipwindows: ipconfigmac和linux: ifconfig测试网络ping 域…...

C# 绘制GDI红绿灯控件
C# 绘制GDI红绿灯控件 using System; using System.Windows.Forms; using System.Drawing;public class TrafficLightControl : Control {protected override void OnPaint(PaintEventArgs e){base.OnPaint(e);Graphics g e.Graphics;g.SmoothingMode System.Drawing.Drawin…...

Centos 8 服务器时间校正
Centos 8 服务器时间校正 使用chrony服务自动同步时间: 1.安装chrony: sudo dnf install chrony 2.启动并使chrony服务自动启动: sudo systemctl start chronyd sudo systemctl enable chronyd 3.添加配置置文件/etc/chrony.conf指向了可靠…...
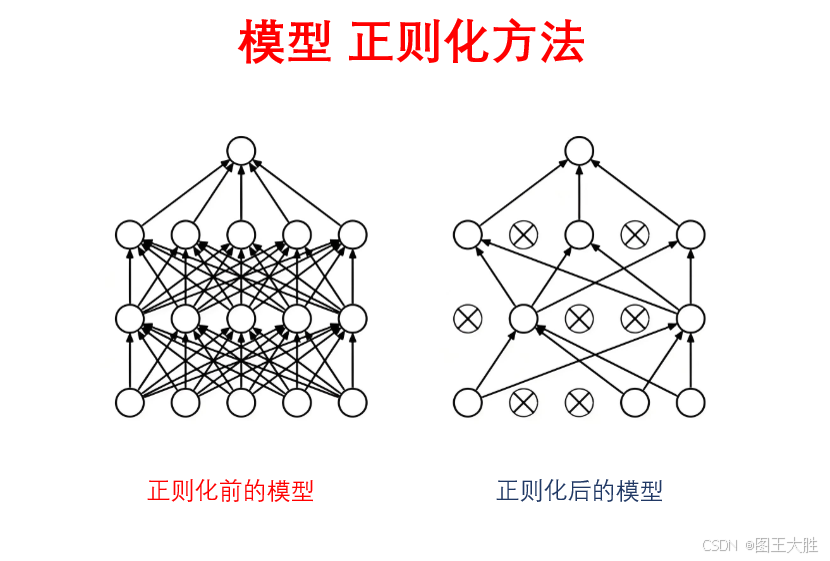
模型 正则化方法(通俗解读)
系列文章 分享 模型,了解更多👉 模型_思维模型目录。控制模型复杂度,防过拟合。 1 正则化方法的应用 1.1 正则化方法在教育领域的应用案例 - 重塑教学模式 背景: 在教育领域,正则化方法可以被理解为对教学模式和学习…...

ffmpeg命令
ffmpeg是专门处理多媒体文件(包括音频、视频)的命令; ffplay 是 ffmpeg 软件包中的一个命令行多媒体播放器,它主要用于播放音视频文件; # fmpeg命令转换格式,将mp3格式转换为wav格式 ffmpeg -i input.mp3…...

使用 EasyExcel 实现高效的 Excel 读写操作
在日常开发中,Excel 文件的读写操作是一个常见的需求。EasyExcel 是阿里巴巴开源的一个高性能、易用的 Excel 读写库,可以大幅提高处理 Excel 文件的效率。它通过事件驱动模型优化了大数据量 Excel 的读写性能,非常适合处理大文件或高并发场景…...

数据结构(栈Stack)
1.前言: 在计算机科学中,栈(Stack)是一种基础而存在的数据结构,它的核心特性是后进先出(LIFO,Last In, First Out)。想象一下,在现实生活中我们如何处理一堆托盘——我们…...

Windows 11 环境下 条码阅读器输入到记事本的内容不完整
使用Windows11时,为什么记事本应用程序中的扫描数据被截断或不完整?为什么sdo 特殊字符的显示与Windows 10 记事本应用程序不同? 很多人认为和中文输入法有关,其实主要问题出在这个windows11下的记事本程序上,大家知道这个就可以了&#x…...

【串口助手开发】visual studio 使用C#开发串口助手,生成在其他电脑上可执行文件,可运行的程序
1、改成Release,生成解决方案 串口助手调试成功后,将Debug改为Release,点击生成解决方案 2、运行exe文件 生成解决方案后,在bin文件夹下, Release文件夹下,生成相关文件 复制一整个Release文件夹…...

Redis设计与实现读书笔记
Redis设计与实现读书笔记 Redis设计与实现[^1]简单动态字符串SDS的基础定义与C字符串的差别常数获取长度杜绝缓冲区溢出减少修改字符串时带来的内存重分配次数二进制安全函数兼容 链表链表和链表节点的实现 字典字典的实现哈希表定义哈希表节点定义字典定义 哈希算法解决键冲突…...

UE5 Do Once 节点
在 Unreal Engine 5 (UE5) 中,Do Once 节点是一个蓝图节点,用于确保某个操作或代码只执行一次,直到某些条件被重置。它通常用于处理需要执行一次的逻辑,例如初始化、事件触发、或防止重复执行某些操作。 如何使用 Do Once 节点&a…...
作为客户端端通过grpc与cpp(服务端)交互)
javascript(前端)作为客户端端通过grpc与cpp(服务端)交互
参考文章 https://blog.csdn.net/pathfinder1987/article/details/129188540 https://blog.csdn.net/qq_45634989/article/details/128151766 前言 临时让我写前端, 一些配置不太懂, 可能文章有多余的步骤但是好歹能跑起来吧 你需要提前准备 公司有自带的这些, 但是版本大都…...

前端常用缓存技术深度剖析
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
)
Asp.net Mvc在VSCore中如何将增删改查的增改添加数据传输到页面(需配合上一篇Mvc的增删改查一起)
Linq集成查询(关联Lambda) First FirstOrDefault 找到第一个符合条件的元素 First(x >x.Id id) 返回第一个Id等于id的元素,如果都没有符合的,报错FirstOrDefault(x >x.Id id) 返回第一个Id等于id的元素,如果…...

Android显示系统(04)- OpenGL ES - Shader绘制三角形
一、前言: OpenGL 1.0采用固定管线,OpenGL 2.0以上版本重要的改变就是采用了可编程管线,Shader 编程是指使用着色器(Shader)编写代码来控制图形渲染管线中特定阶段的处理过程。在图形渲染中,着色器是在 GP…...

微信 创建小程序码-有数量限制
获取小程序码:小程序码为圆图,有数量限制。 目录 文档 接口地址 功能描述 注意事项 请求参数 对接 获取小程序码 调用获取 小程序码示例 总结 文档 接口地址 https://api.weixin.qq.com/wxa/getwxacode?access_tokenaccess_token 功能描述 …...

重生之我在异世界学编程之C语言:操作符篇
大家好,这里是小编的博客频道 小编的博客:就爱学编程 很高兴在CSDN这个大家庭与大家相识,希望能在这里与大家共同进步,共同收获更好的自己!!! 本文目录 引言正文1. 算术操作符2. 关系࿰…...
365天深度学习训练营-第P7周:马铃薯病害识别(VGG-16复现)
文为「365天深度学习训练营」内部文章 参考本文所写记录性文章,请在文章开头带上「👉声明」 🍺 要求: 自己搭建VGG-16网络框架【达成√】调用官方的VGG-16网络框架【达成√】如何查看模型的参数量以及相关指标【达成√】 &#…...

解密时序数据库的未来:TDengine Open Day技术沙龙精彩回顾
在数字化时代,开源已成为推动技术创新和知识共享的核心力量,尤其在数据领域,开源技术的涌现不仅促进了行业的快速发展,也让更多的开发者和技术爱好者得以参与其中。随着物联网、工业互联网等技术的广泛应用,时序数据库…...

肺部X光AI诊断系统:五分类模型实战与临床可解释性
1. 项目概述:当X光片遇上深度学习——一个肺部疾病AI诊断系统的实操手记 我做医疗影像AI项目快七年了,从最早在医院信息科帮放射科老师写脚本批量重命名DICOM文件,到后来带着学生团队在基层医院部署轻量级肺炎筛查工具,踩过的坑比…...

5分钟快速激活Cursor Pro:突破AI编程助手的终极破解方案
5分钟快速激活Cursor Pro:突破AI编程助手的终极破解方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

Irony Mod Manager:终极Paradox游戏模组冲突解决方案完全指南
Irony Mod Manager:终极Paradox游戏模组冲突解决方案完全指南 【免费下载链接】IronyModManager Mod Manager for Paradox Games. Official Discord: https://discord.gg/t9JmY8KFrV 项目地址: https://gitcode.com/gh_mirrors/ir/IronyModManager 你是否曾经…...

甲骨文免费服务器到手后,用Xshell连接不上?这份SSH密钥配置避坑指南请收好
甲骨文云SSH连接全攻略:从密钥解析到Xshell实战配置 密钥管理的核心逻辑与常见误区 初次接触甲骨文云免费实例的用户,90%的SSH连接问题都源于密钥处理不当。与常规密码登录不同,甲骨文云强制采用密钥对认证机制,这种设计虽然提升了…...

米哈游游戏字体库终极指南:轻松获取11款精美架空文字字体资源
米哈游游戏字体库终极指南:轻松获取11款精美架空文字字体资源 【免费下载链接】HoYo-Glyphs Constructed scripts by HoYoverse 米哈游的架空文字 项目地址: https://gitcode.com/gh_mirrors/ho/HoYo-Glyphs 想要为你的设计作品注入《原神》、《崩坏…...

使用TaotokenCLI工具一键配置开发环境与模型密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境与模型密钥 在接入大模型进行开发时,手动配置API密钥、Base URL和模型ID是常见的…...

新手入门使用 Python 快速接入 Taotoken 调用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门使用 Python 快速接入 Taotoken 调用大模型 对于刚开始接触大模型 API 调用的开发者而言,如何快速、正确地接入…...

别再装ModelSim了!用HDLBits网页版5分钟搞定Verilog仿真和波形图
5分钟极速验证:用HDLBits网页版替代传统Verilog仿真工具 在图书馆公用电脑上突然有了个FPGA设计灵感,却发现自己没装ModelSim?公司电脑没有管理员权限,无法安装Vivado Simulator?别急着放弃——打开浏览器,…...
)
从零开发游戏需要学习的c#模块,第十九章(在游戏画面里显示文字 —— FontStashSharp)
本节课我们要学习的内容是安装字体渲染库加载系统字体文件在游戏画面里直接显示分数、金币数等信息第一步:安装 NuGet 包在 Visual Studio 右侧“解决方案资源管理器”里,右键你的项目名(不是解决方案)选择 “管理 NuGet 程序包”…...

性价比高的国产PLM软件公司
在制造业领域,不少企业都面临着研发效率低下、协同困难等问题。比如某电子制造企业,研发部门与生产部门之间信息沟通不畅,图纸版本管理混乱,导致产品研发周期延长,生产成本增加,新品上市时间比预期晚了近30…...