图数据库 | 12、图数据库架构设计——高性能计算架构
在传统类型的数据库架构设计中,通常不会单独介绍计算架构,一切都围绕存储引擎展开,毕竟存储架构是基础,尤其是在传统的基于磁盘存储的数据库架构设计中。
类似地,在图数据库架构设计中,项目就围绕存储的方式来展开,例如开源的Titan项目(已停滞)及其后续延展形成的开源的JanusGraph项目都是基于第三方NoSQL数据库的存储引擎而构建的,可以说这些图数据库项目本身是在调用底层存储提供的接口来完成图计算请求。
老夫认为,图数据库所要解决的核心问题并非存储而是计算。换句话说,传统数据库(包含NoSQL类数据库)不能完成业务与技术挑战的主要原因是在面向关联数据的深度穿透与分析时的计算效率问题。尽管这些挑战与存储也相关,但更多的是计算效率问题,参考下图所示的存储与计算的分层加速逻辑。

1、实时图计算系统架构
关于数据库计算架构的设计,没有所谓的唯一正确答案。
但是,在众多可选方案中,笔者认为最为重要的是常识,有时候也包含一些逆向思维。
(1)常识
·内存比外存快得多。
·CPU的三级缓存比内存快得多。
·数据缓存在内存中要比在外存上快得多。
·Java的内存管理很糟糕。
·链表数据结构的搜索时间复杂度是O(N),树状数据结构(索引)的搜索时间复杂度是O(log N),哈希数据结构的复杂度是O(1)。
(2)逆向思维
·SQL和RDBMS是世界上最好的组合——在过去30年中大抵如此,但是业务场景的不断推陈出新决定了需要有新的架构来满足业务需求。互联网业务中通过大量的多实例并发来满足海量用户请求(例如秒杀场景),这些高并发的场景中,处理模式都属于短链条交易模式,和以金融行业为首的长链交易模式非常不同——两者之间的主要区别在于,长链条交易的计算复杂度成倍增加,对于分布式系统的设计挑战更大,而短链交易中分布式系统的各节点间的通信或同步量小且逻辑简单(故称短链条)。
·庞大有如BAT类的大企业一定是图技术最强大的提供商——如果按照这个思路,BAT恐怕不会在过去20年中从小不点成长到今天的巨无霸。每一次新的巨大的IT升级换代机遇出现时都会有一些小公司跑赢大盘。图2是一种实时图数据库的总体架构设计思路。

实时图数据库的核心部件(纵向)具体如下:
·图存储引擎:数据持久化层;
·图计算引擎:实时图计算与分析层;
·内部工作流、算法流管理及优化组件;
·数据库、数据仓库对接组件(数据导入、导出);
·图查询语言解析器及优化器组件;
·图谱管理、可视化及其他上层管理组件。
图数据库的内部结构示意图如下图3所示:

上图中,我们用了三种颜色来标识图数据库中三种工作流:
数据工作流(橙色)、管理工作流(蓝色)和计算工作流(绿色)。
数据工作流与管理工作流对于设计实现过软件定义的存储系统的读者应该感到不陌生,在逻辑上它们代表数据传输与系统管理指令的分离,可以看作是在两个分离的通道上传输图数据与管理指令。
而计算工作流则可以看作是一种特殊的图数据工作流,它是与图计算引擎之间流转的数据与指令流。我们用具体的例子来说明计算工作流与数据工作流之间的差异。
图4与图5分别是两条实时路径查询指令返回结果的可视化呈现。它们之间的差异在于是否有点(实体)、边(关系)的属性被返回。在图4中是无点、边属性返回;在图5中是全部属性被返回。图3-16的查询指令如下:

上图的查询指令如下:
// 五环路路径查询,返回结果无属性字段
ab().src(12).dest(21).depth(5).limit(5).no_circle()

上图的查询指令如下:
//返回结果包含全部点、边的五环路路径搜索
ab().src(12),dest(21).depth(5).limit(5).no_circle().select(*)以上两个路径查询语句都是查询两个顶点间深度为5的无环路径,且限定找到5条路径即可返回,区别在于后者要求返回全部顶点及边上的属性。这一语义层面对于底层的图计算与存储引擎的区别在于,如果无属性返回,那么图计算引擎可以完全以序列化ID来进行查询与计算,这样做显然最节省内存,也是性能最优的一种方案;如果需要返回属性,这个工作可以分给存储引擎来完成,在存储持久层找到每个点、边的属性并返回。
因此,在需要返回属性的查询语句中,计算与存储引擎都被调动了,而无属性返回的场景中,存储引擎无须介入计算过程中。
当然,存储引擎通过优化,特别是缓存等功能的实现,也可以在毫秒级至秒级时间内返回大量的属性数据(尤其是多次查询时的加速效果明显)。
然而问题的关键在于,像上面这种深度的路径查询,基于内存加速的计算引擎的效率会是传统存储引擎的成百上千倍(微秒级),并且随着查询深度的递增而产生的性能落差指数级增大。
2、图数据库模型与数据模型
图数据库普遍被认为采用的是模式自由(schema-free或无模式schemaless)的方式来处理数据,也因此具备了更高的灵活性和应对动态变化数据的能力。这也是图数据库区别于传统关系型数据库的一个重要之处。
关系型数据库的模式描述并定义了数据库对象及对象相互间的关系,起到了一种提纲挈领的作用,下图6显示了19张表及其数据类型,表之间通过主外键所形成的关联关系。
不过,不同厂家的数据库对于模式的具体定义存在很大差异,在MySQL中schema可以等同于数据库本身,Oracle则把schema作为数据库的一部分,甚至从属于每个用户,而在SQL Server中创建模式后,用户与对象等信息可以依附在其下。

关于关系型数据库和图数据库语言之间的区别,详细可以参见这篇:嬴图 | 微距观察从“表数据”到“图数据”的建模过程CSDN博客
关系型数据库中的模式的创建是前置的,一旦创建并且数据库已经运行,做出动态、灵活的改变是非常困难的。然而,在图数据库中,如何能提纲挈领地定义图数据对象及对象间关系的骨架,这一挑战有两种不用思路的解方案:一是无模式方案;二是动态模式方案。
事实上,还有第三种方案就是延续传统数据库的静态模式方案,但这个和构建较传统数据库更为灵活的图数据库的目标相悖,不过超出不在本篇文章中讨论了。
无模式,顾名思义,无须明确定义数据库对象间关系的模式,或者说对象间的模式是不言而喻的或隐含但明确的。例如社交网络图谱中顶点间的关联关系,默认都是关注或被关注关系,这种简单图关系中并不需要模式定义介入。即便在更为复杂的关系网络中,例如金融交易网络,两个账户(顶点)间可能存在多笔转账关系(多交易等于多边),这种图属于多边图,在同类型(同构)顶点间的多笔同类型边的存在,也不需要定义模式来加以区分。
动态模式是相对静态模式而言的,显然,在上面的例子中,如果有多种类型的顶点(账户、商户、POS机、借记卡、信用卡等)、多种类型的边(转账、汇款、刷卡、还款等),那么定义模式可以更清晰地描述对象及对象间的关系。如果图数据还是动态改变的,例如新的类型的数据(点、边)出现后,那么就需要动态定义新的模式或改变原有的模式来更灵活地描述和处理数据,而不需要像传统数据库的静态模式定义一样,需要停机、重启数据库等一系列复杂的操作。
图数据库因为不存在表、主键、外键等概念,可以很大程度被简化为只包含以下组件:
·节点:也称为顶点(对应的复数为nodes和vertices)。
·边:通常称为关系,每条边通常连接一对顶点(也有复杂的边模式会连接大于2个节点,但非常罕见且混乱。为避免复杂化,本书不处理此类情况)。
·边的方向:对于由边连接在一起的每对节点来说,方向是有意义的。例如:A→父亲(是)→B;用户A→(拥有)账户→账号A。
·节点的属性:每个节点相关的属性,每个属性用一个键值对来表达,例如:参考书-与神对话,符号前是主键的名称,符号后是数值字符串。
·边的属性:边的属性可能包括很多内容,如关系类型、时间跨度、地理位置数据、描述信息,以及装饰边的键值对等。
·模式:在图数据库中,模式的定义可以在图数据库对象创建后发生,并且可以动态地调整每个模式所包含的对象。点、边可以分别定义各自的多组模式。
·索引及计算加速数据结构:磁盘索引部分与传统数据库无二,计算加速则是图数据库特有的创新,这一部分与内存数据库有一些相似之处。
·标签:标签可以被看作是一种特殊的属性,某些图数据库采用标签的方式来模拟模式的效果,但是两者之间存在较大的区别,标签只能算作一种简化但功能不完整的类模式实现,无法替代模式。
图数据库的数据源中所对应的数据类型如表1所示:

3、核心引擎如何处理不同的数据类型
需要记住的一点是,某些类型的数据对内存不友好,以字符类型或唯一标识码(UUID)为例,这些数据类型往往会在内存中膨胀,如果不做处理(数据蒸馏)很快就会有内存不足的问题。
举个例子,一张图有10亿个顶点、50亿条边,每条边用最简单的形式记录包含2个顶点(起点和终点),如果使用唯一标识码(UUID)来代表每个顶点,每个UUID是64B的字符串,那么这张图最少占用内存的计算公式如下:
64×2×5 000 000 000=640 Billion Bytes=640GB RAM
如果以无向图或双向图存储(允许反向遍历),那么就需要将每条边反转(图遍历中的一种常见技术),则使用UUID的内存消耗倍增为1 280GB,而且这不包括任何边ID、点-边属性数据,不考虑任何缓存、运行时动态内存需要等。
为了减少内存占用和提高性能,我们需要做如下几件事。
·序列化:把UUID类型的主键类数据转换为整型存储,并在源数据与序列化数据间建立对照表(例如Unordered Map或某种哈希映射表),对照表的建立相当于为10亿顶点逐一分配整型ID,即便使用8B长整型,低至100G~200GB的连续内存。数据结构就有可能覆盖全部UUID-ID的映射关系。
·近邻无索引:使用适合的数据结构来实现最低算法复杂度的点-边-点遍历。读者可以参考前面介绍的近邻无索引数据结构设计来构建自己的高效、低延时图计算数据结构。
·想办法使CPU饱和并让它们全速运行是每个高性能系统的终极目标,因为内存仍然比CPU慢1000倍。当然,这也与多线程代码如何组织和操作工作线程以尽可能高效地生产有关。这与所使用的数据结构密切相关——如果你在Java中使用过堆(heap),它一定不像映射或矢量那样的类型有效率,列表和数组等也是一样。
另外一方面,并非所有数据都应该直接加载到图核心计算引擎中,这里要特别注意的是,点、边属性的数量分别乘以点、边的个数,结果可能远远大于点和边的数量。很多人喜欢用传统数据库的字段数量来统计图数据库的规模,如10亿的点、50亿的边,假设的点有20个属性字段,边有10个属性字段,它的(字段)规模=10×20+50×10=700亿,相当于千亿规模。很多所谓的千亿或万亿规模的图实际上可能远远小于真实的情况。
图计算的本质是对图的拓扑结构(图的骨骼、骨架)以及对必要的、有限的点、边属性进行查询、计算与分析。因此在大多数的图计算和查询过程中,大量的点、边及属性与当前查询的内容无关。这也意味着它们在实时图计算的过程中没有必要占用宝贵的计算引擎资源,也不需要在实时处理的路径之中。
为了更好地说明这些特点,下面列举一些例子:
·为了计算一个人朋友的朋友的朋友,等同于图计算中的3跳(3-Hop)操作,是一个典型的广度优先(BFS)查询操作。
·要了解2个人之间的所有4度以内关系,是一种典型的AB路径查询(BFS或DFS或两者兼而有之),中间涉及非常多的节点,可能是人、账户、地址、电话、社保号、IP地址、公司等。
·监管机构查看某企业高管的电话记录,比如近30天内的来电与呼出电话,以及这些来电者和接听者如何进一步打电话,了解他们延展5步之内的通话网络并查询他们之间的通话关系网络。
这三个例子是典型的网络分析或反欺诈的场景,并且查询深度以及复杂度逐级升高。不同的图系统会采用不同的方法来解决这一问题,但关键是:
·如何进行数据建模?数据建模的优劣会影响作业的完成效率以及存储与计算资源的消耗程度,甚至会制造出大量噪声,这些噪声不仅会降低查询作业的完成速度,还会使作业准确性难以保证。例如同构图、异构图、简单图、多边图,不同的建模逻辑都可能会影响最终的查询效率。
逻辑都可能会影响最终的查询效率。
·如何尽可能快地完成工作?只要成本可以接受,实时返回结果总是更好的。
·性价比一直是考虑的因素,如果相同的操作总要一遍又一遍运行,那么为它创建一个专用的图表是有意义的。另外,在数据并没有频繁更新的条件下,缓存结果也可以达到同样的效果。
·如何优化查询?这个工作是由图遍历优化器(graph traversal optimizer)来完成的。图遍历优化器有两种工作方式:一是遍历所有的边后再进行过滤;二是遍历的同时进行过滤。这两种遍历优化的核心区别如下:
·在第一种方法中,遍历是通过一个高度并发的多线程图引擎完成的,先获得一张子图,然后再根据过滤规则筛选并保留可能的路径集合。
·在第二种方法中,过滤规则在图遍历过程中以动态剪枝的方式来实现,一边遍历,一边筛选。
·这两种方法在真实的业务场景中可能有很大的不同,因为它会影响属性(对于节点/边)的处理方式。第二种方法要求属性与每个节点/边共存,而第一种方法则可以允许属性单独存储。不同的图数据模型建模机制和不同的查询逻辑可能会让一种方法比另一种方法运行得更快。同时支持两种方法并同时运行两个实例,通过比较可以帮助优化并找到图数据建模(和模式)的最合适方法。
不同的图数据模型建模机制和不同的查询逻辑可能会让一种方法比另一种方法运行得更快。同时支持两种方法并同时运行两个实例,通过比较可以帮助优化并找到图数据建模(和模式)的最合适方法。
4、图计算引擎中的数据结构
在图数据库的存储引擎中,可以按照行存储、列存储、KV存储三大类方式划分持久化存储方案。在图计算引擎层,尽管我们渴望高维的计算模式,但是数据结构层面依然分为两大类:顶点数据结构和边数据结构。
注:在一些图计算框架中,因为点、边都没有属性,可以只存在边数据结构,而不需要顶点数据结构,因为每条边都是由起点与终点构成的有序的一对整数,已经隐含了顶点。
当然,以上两种数据结构还分别包含点属性、边的方向、边的属性等字段。显而易见,可能的数据结构方案有如下几种。
·点、边分开存储:点、边及各自属性字段采用两套数据结构分别表达。
·点、边合并存储:顶点数据结构包含边,或边数据结构包含顶点。
·点、边及各自的属性字段分开存储:可能用4套或更多的数据结构来表达。
下图给出的图数据结构是点、边及属性的“一体化”数据结构设计方案,第一竖行是顶点,而后面部分是起始顶点的属性,以及边和边对应的属性。
这一数据存储模型非常类似谷歌的分布式存储系统big table。这类数据模型设计的优点如下:

·对图遍历来说,这是一种边优先(edge-first)的数据模型,遍历速度高。
·数据模型可以用最合适的数据结构进行优化,以获得最佳的遍历性能。
·它将使分区(或分片)更加容易。·这种数据结构对于持久化存储层也同样适用(行存储模式)。
缺点如下:
·使用连续存储(内存)空间的数据结构,无法快速地更新(删除)数据。
·如果使用对齐的字段边界,不可避免地会导致空间浪费(所谓空间换时间)。
按照上图的思路延展开来,大家可以自由发挥来设计更为高效的图计算数据结构。
未完结,明天继续再聊。
相关文章:
图数据库 | 12、图数据库架构设计——高性能计算架构
在传统类型的数据库架构设计中,通常不会单独介绍计算架构,一切都围绕存储引擎展开,毕竟存储架构是基础,尤其是在传统的基于磁盘存储的数据库架构设计中。 类似地,在图数据库架构设计中,项目就围绕存储的方…...

Unity 利用Button 组件辅助Scroll View 滚动
实现 创建枚举类ScrollDir 以区分滚动方向。每组两个按钮负责同方向上左右/上下滚动。 Update 中实时获取Scroll View 滚动条当前位置。 if (dir.Equals(ScrollDir.vertical)) {posCurrent scroll.verticalNormalizedPosition; } else if (dir.Equals(ScrollDir.horizontal)…...

Ubuntu 安装Ansible ansible.cfg配置文件生成
安装后的ansible.cfg后的默认内容如下: rootlocalhost:/etc/ansible# cat ansible.cfg # Since Ansible 2.12 (core): # To generate an example config file (a "disabled" one with all default settings, commented out): # $ ansible-…...

使用PaddlePaddle实现线性回归模型
目录 编辑 引言 PaddlePaddle简介 线性回归模型的构建 1. 准备数据 2. 定义模型 3. 准备数据加载器 4. 定义损失函数和优化器 5. 训练模型 6. 评估模型 7. 预测 结论 引言 线性回归是统计学和机器学习中一个经典的算法,用于预测一个因变量࿰…...

MongoDB集群的介绍与搭建
MongoDB集群的介绍与搭建 一.MongoDB集群的介绍 注意:Mongodb是一个比较流行的NoSQL数据库,它的存储方式是文档式存储,并不是Key-Value形式; 1.1集群的优势和特性 MongoDB集群的优势主要体现在以下几个方面: (1)高…...

PhpStorm配置Laravel
本文是2024最新的通过phpstorm创建laravel项目 1.下载phpstorm 2.检查本电脑的环境phpcomposer 显示图标就是安装成功了,不会安装的百度自行安装 3.安装完后,自行创建一个空目录不要有中文,然后运行cmd 输入以下命令,即可创建…...

Solving the Makefile Missing Separator Stop Error in VSCode
1. 打开 Makefile 并转换缩进 步骤 1: 在 VSCode 中打开 Makefile 打开 VSCode。使用文件浏览器或 Ctrl O(在 Mac 上是 Cmd O)打开你的 Makefile。 步骤 2: 打开命令面板 按 Ctrl Shift P(在 Mac 上是 Cmd Shift P)&…...

MySQL大小写敏感、MySQL设置字段大小写敏感
文章目录 一、MySQL大小写敏感规则二、设置数据库及表名大小写敏感 2.1、查询库名及表名是否大小写敏感2.2、修改库名及表名大小写敏感 三、MySQL列名大小写不敏感四、lower_case_table_name与校对规则 4.1、验证校对规则影响大小写敏感4.1、验证校对规则影响排序 五、设置字段…...

项目搭建:guice,jdbc,maven
当然,以下是一个使用Guice、JDBC和Maven实现接口项目的具体例子。这个项目将展示如何创建一个简单的用户管理应用,包括用户信息的增删改查(CRUD)操作。 ### 1. Maven pom.xml 文件 首先确保你的pom.xml文件包含必要的依赖&#…...
)
第四届新生程序设计竞赛正式赛(C语言)
A: HNUCM的学习达人 SQ同学是HNUCM的学习达人,据说他每七天就能够看完一本书,每天看七分之一本书,而且他喜欢看完一本书之后再看另外一本。 现在请你编写一个程序,统计在指定天数中,SQ同学看完了多少本完整的书&#x…...

【分布式知识】Redis6.x新特性了解
文章目录 Redis6.x新特性1. 多线程I/O处理2. 改进的过期算法3. SSL/TLS支持4. ACL(访问控制列表)5. RESP3协议6. 客户端缓存7. 副本的无盘复制8. 其他改进 Redis配置详解1. 基础配置2. 安全配置3. 持久化配置4. 客户端与连接5. 性能与资源限制6. 其他配置…...

程序员需要具备哪些知识?
程序员需要掌握的知识广泛而深厚,这主要取决于具体从事的领域和技术方向。不过,有些核心知识是共通的,就像建房子的地基一样,下面来讲讲这些关键领域: 1. 编程语言: 无论你是搞前端、后端、移动开发还是嵌…...

实验四:MyBatis 的关联映射
目录: 一 、实验目的: 熟练掌握实体之间的各种映射关系。 二 、预习要求: 预习数据库原理中所讲过的一对一、一对多和多对多关系 三、实验内容: 1. 查询所有订单信息,关联查询下单用户信息(注意:因为一…...

【Leetcode】189.轮转数组
题目链接: 189.轮转数组 题目描述: 解题思路: 要想实现数组元素向右轮转k个位置,可是将数组三次反转来实现 以 nums [1,2,3,4,5,6,7], k 3 为例,最终要得到[5,6,7,1,2,3,4]: 第一次反转:将整个数组反转…...

【JavaSE】常见面试问题
1. 什么是 Java 中的多态? 多态是 Java 中面向对象的核心特性之一,指的是同一操作作用于不同类型的对象时表现出不同的行为。通过方法重载和方法重写实现。方法重载是同一方法名,根据参数不同做不同处理,属于编译时多态ÿ…...
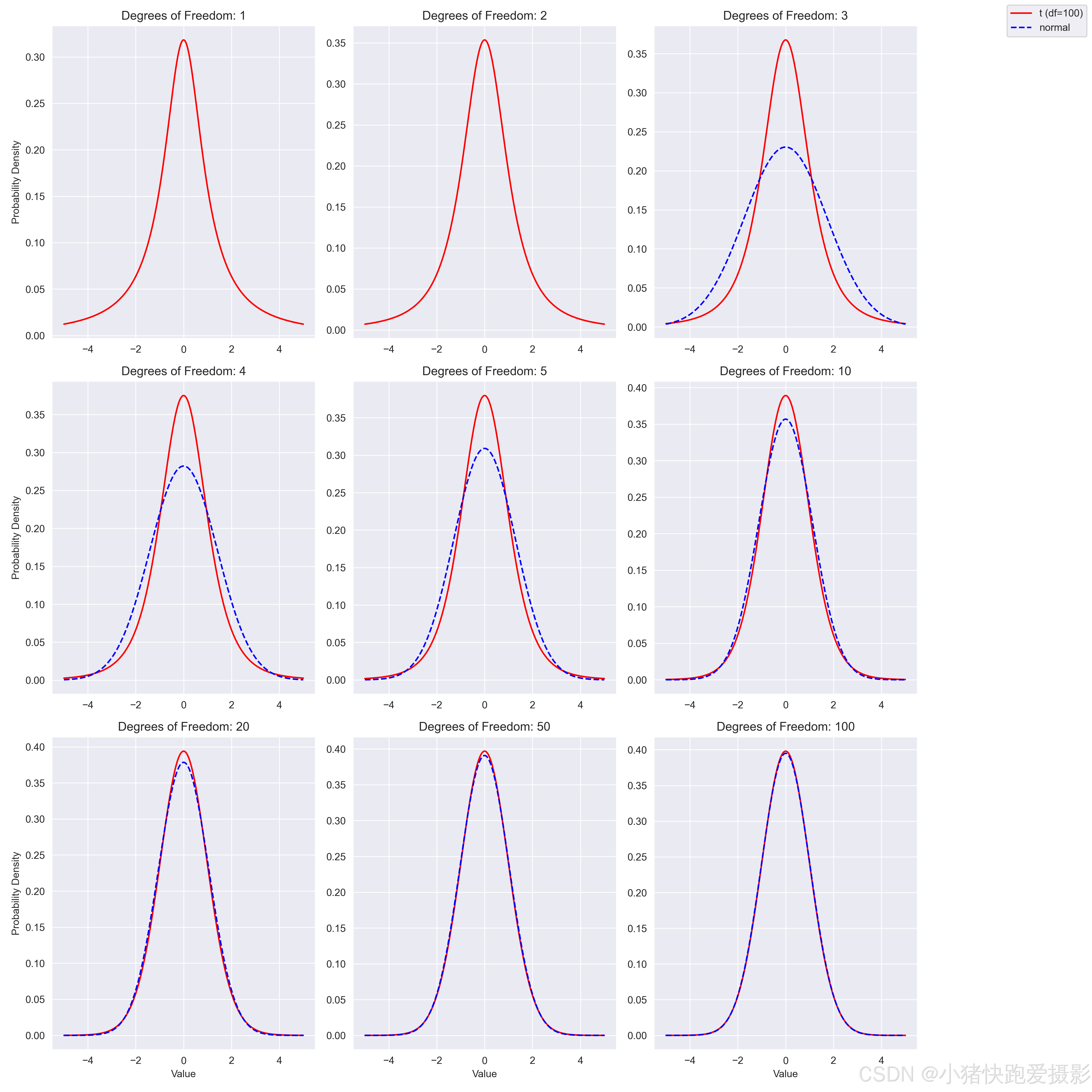
【超详图文】多少样本量用 t分布 OR 正态分布
文章目录 相关教程相关文献预备知识Lindeberg-Lvy中心极限定理 t分布的来历实验不同分布不同抽样次数的总体分布不同自由度相同参数的t分布&正态分布 作者:小猪快跑 基础数学&计算数学,从事优化领域7年,主要研究方向:MIP求…...

leetcode hot100【Leetcode 416.分割等和子集】java实现
Leetcode 416.分割等和子集 题目描述 给定一个非负整数的数组 nums ,你需要将该数组分割成两个子集,使得两个子集的元素和相等。如果可以分割,返回 true ,否则返回 false。 示例 1: 输入:nums [1,5,11,…...

《算法导论》英文版前言To the teacher第4段研习录:有答案不让用
【英文版】 Departing from our practice in previous editions of this book, we have made publicly available solutions to some, but by no means all, of the problems and exercises. Our Web site, http://mitpress.mit.edu/algorithms/, links to these solutions. Y…...

Laravel关联模型查询
一,多表关联 文章表articles 和user_id,category_id关联 //with()方法是渴求式加载,缓解了1N的查询问题,仅需11次查询就能解决问题,可以提升查询速度。with部分没有就以null输出,所以可以理解为 多表 left join 查…...

Clickhouse 数据类型
文章目录 字符串类型数值类型日期时间类型枚举类型数组类型元组类型映射类型其它类型 字符串类型 数据类型描述备注String可变长度字符串无长度限制,适用于存储任意字符FixedString固定长度字符串定长字符串,长度在创建时指定,如 FixedStrin…...

多模型选型实验场景下Taotoken模型广场的价值与应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型选型实验场景下Taotoken模型广场的价值与应用 在模型技术快速迭代的今天,无论是学术研究还是产品开发࿰…...

3步解锁百度网盘全速下载:baidu-wangpan-parse技术解析与应用实践
3步解锁百度网盘全速下载:baidu-wangpan-parse技术解析与应用实践 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾面对百度网盘那令人绝望的下载速度而束手…...

UPS、EPS蓄电池更换周期及更换判定标准详解
在机房后备供电、工业不间断供电、消防应急供电体系中,UPS不间断电源与EPS应急电源的核心储能载体均为蓄电池。蓄电池的健康状态,直接决定整套应急供电系统的可靠性,是电气运维、机房维保、消防设施巡检的重点工作内容。在实际运维工作中&…...
)
别再手动拼图了!用Godot4的TileMap快速搭建2D游戏场景(附图层与相机跟随技巧)
别再手动拼图了!用Godot4的TileMap快速搭建2D游戏场景(附图层与相机跟随技巧) 在独立游戏开发中,场景搭建往往是耗时最长的环节之一。许多新手开发者习惯用Sprite节点逐个摆放场景元素,这不仅效率低下,后期…...

企业级应用如何通过Taotoken聚合API管理多个大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken聚合API管理多个大模型调用 在构建企业级AI应用时,一个常见的需求是同时接入多个不同厂商的…...

抖音内容高效管理方案:批量下载与智能文件组织
抖音内容高效管理方案:批量下载与智能文件组织 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音…...

数据可视化库对比:选择最适合你的工具
数据可视化库对比:选择最适合你的工具 前言 大家好,我是前端老炮儿。今天咱们来聊聊数据可视化库的选择! 在前端开发中,数据可视化是一个非常重要的领域。市面上有很多优秀的可视化库,比如ECharts、D3.js、Chart.js、T…...

深入理解Istio架构:控制平面与数据平面核心组件全解析
深入理解Istio架构:控制平面与数据平面核心组件全解析 【免费下载链接】istio-handbook Istio服务网格进阶实战 项目地址: https://gitcode.com/gh_mirrors/is/istio-handbook Istio作为新一代服务网格(Service Mesh)的领航者…...

如何选择最佳身份验证技能:Awesome Agent Skills中Auth0、Firebase Auth与Better Auth全面指南
如何选择最佳身份验证技能:Awesome Agent Skills中Auth0、Firebase Auth与Better Auth全面指南 【免费下载链接】awesome-agent-skills A curated collection of 1000 agent skills from official dev teams and the community, compatible with Claude Code, Codex…...

科研绘图革命:3步让Matplotlib图表达到期刊发表标准
科研绘图革命:3步让Matplotlib图表达到期刊发表标准 【免费下载链接】SciencePlots Matplotlib styles for scientific plotting 项目地址: https://gitcode.com/gh_mirrors/sc/SciencePlots 想象一下这样的场景:你花了数周时间收集数据、编写分析…...