使用PaddlePaddle实现线性回归模型
目录
编辑
引言
PaddlePaddle简介
线性回归模型的构建
1. 准备数据
2. 定义模型
3. 准备数据加载器
4. 定义损失函数和优化器
5. 训练模型
6. 评估模型
7. 预测
结论
引言
线性回归是统计学和机器学习中一个经典的算法,用于预测一个因变量(响应变量)和多个自变量(解释变量)之间的关系。它基于一个简单的假设:因变量Y和自变量X之间存在线性关系,即Y可以表示为X的线性组合加上一个随机误差项。这种关系可以用数学公式表示为 Y = β0 + β1X + ε,其中β0是截距,β1是斜率,ε是误差项。线性回归的目标是找到最佳的β0和β1,使得模型对于给定数据集的预测值和实际值之间的差异最小。在深度学习领域,线性回归模型可以被视为神经网络的一个特例,其中网络只有一个线性层。PaddlePaddle作为一个强大的深度学习框架,提供了简单易用的接口来实现线性回归模型。本文将详细介绍如何使用PaddlePaddle来构建和训练一个线性回归模型,包括数据准备、模型构建、训练、评估和预测等步骤。
PaddlePaddle简介
PaddlePaddle是由百度开源的深度学习平台,它支持多种深度学习模型,包括图像识别、自然语言处理等多种应用。PaddlePaddle以其易用性、灵活性和高效性而受到开发者的欢迎。它提供了丰富的API,使得构建和训练深度学习模型变得更加简单。PaddlePaddle的设计哲学是降低深度学习的研发门槛,使得更多的研究人员和开发者能够快速地实现和部署深度学习模型。此外,PaddlePaddle还提供了一系列的工具和库,如PaddleHub、PaddleSlim等,用于模型的压缩、加速和部署,进一步扩展了其在工业界的应用。
为了确保安装成功,你可以运行以下代码来测试PaddlePaddle是否正确安装:
import paddle# 打印PaddlePaddle版本
print(paddle.__version__)这行代码将输出你当前安装的PaddlePaddle版本号,确保你使用的是最新版本或者符合项目要求的版本。
线性回归模型的构建
1. 准备数据
数据是机器学习项目的基础。对于线性回归模型,我们需要一组特征(X)和对应的标签(y)。以下是生成一些模拟数据的示例:
import numpy as np
import paddle
import matplotlib.pyplot as plt# 设置随机种子以确保结果的可重复性
np.random.seed(0)# 生成模拟数据
X = 2 * np.random.rand(100, 1) # 生成100个0到2之间的随机数
y = 4 + 3 * X + np.random.randn(100, 1).flatten() # 线性关系y = 4 + 3x + noise# 将numpy数组转换为PaddlePaddle Tensor
X_tensor = paddle.to_tensor(X, dtype='float32')
y_tensor = paddle.to_tensor(y, dtype='float32')# 可视化数据
plt.scatter(X, y)
plt.xlabel('X')
plt.ylabel('y')
plt.title('Scatter Plot of X and y')
plt.show()在实际应用中,这些数据可能来自于实验测量、调查问卷或任何其他形式的数据收集。数据预处理是机器学习中非常重要的一步,它包括清洗数据、处理缺失值、特征缩放等步骤。在这个例子中,我们生成了一些简单的线性关系数据,并添加了一些随机噪声。通过可视化数据,我们可以直观地看到数据的分布情况,这对于理解数据特征和模型性能至关重要。数据可视化是一个强大的工具,它可以帮助我们识别数据中的模式、趋势和异常值,从而更好地理解数据集的特点。
2. 定义模型
使用PaddlePaddle定义线性回归模型非常简单。我们只需要定义一个包含单个线性层的网络:
import paddle.nn as nnclass LinearRegressionModel(nn.Layer):def __init__(self):super(LinearRegressionModel, self).__init__()# 定义一个线性层,输入特征为1,输出特征也为1self.linear = nn.Linear(in_features=1, out_features=1)def forward(self, x):# 前向传播,通过线性层得到预测结果return self.linear(x)# 实例化模型
model = LinearRegressionModel()# 打印模型结构
print(model)在这个模型中,Linear层是核心,它接受输入特征并输出预测结果。in_features和out_features参数定义了输入和输出的维度。在这个简单的例子中,我们假设输入和输出都是一维的。通过打印模型结构,我们可以清晰地看到模型的架构,这对于调试和优化模型非常有帮助。模型结构的清晰表示有助于我们理解模型的工作方式,以及如何通过改变模型的架构来提高性能。
3. 准备数据加载器
为了训练模型,我们需要将数据转换为PaddlePaddle的Tensor格式,并使用DataLoader来加载数据:
from paddle.io import DataLoader, TensorDataset# 创建TensorDataset,它将X_tensor和y_tensor包装成一个数据集
dataset = TensorDataset(X_tensor, y_tensor)# 创建DataLoader,它将数据集分批次加载,batch_size指定每个批次的大小
train_loader = DataLoader(dataset, batch_size=10, shuffle=True)# 遍历DataLoader,打印每个批次的数据
for batch_id, (x_data, y_data) in enumerate(train_loader):print(f"Batch {batch_id}: x_data shape - {x_data.shape}, y_data shape - {y_data.shape}")if batch_id == 0:breakDataLoader是PaddlePaddle中用于加载数据的类,它允许我们以批次的方式迭代数据集。batch_size参数定义了每个批次的大小,shuffle=True表示在每个epoch开始时随机打乱数据,这有助于模型学习到数据的一般规律,而不是仅仅记住训练数据的顺序。通过遍历DataLoader,我们可以查看每个批次的数据形状,这对于确保数据正确加载和处理非常重要。正确地加载和预处理数据是机器学习项目成功的关键,它直接影响到模型的训练效果和最终性能。
4. 定义损失函数和优化器
线性回归通常使用均方误差(MSE)作为损失函数,并使用SGD(随机梯度下降)作为优化器:
# 定义均方误差损失函数
loss_fn = nn.MSELoss()# 定义随机梯度下降优化器,学习率设置为0.01
optimizer = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())# 打印优化器参数
print(optimizer)损失函数衡量的是模型预测值和真实值之间的差异。优化器则负责根据损失函数的结果更新模型的参数,以最小化损失。在这个例子中,我们选择了SGD作为优化器,它是一种常用的优化算法,适用于多种不同的优化问题。通过打印优化器参数,我们可以查看优化器的配置,这对于调整学习率和其他优化器参数非常有帮助。选择合适的损失函数和优化器对于模型的训练效果至关重要,它们直接影响到模型的收敛速度和最终性能。
5. 训练模型
通过迭代数据集,计算损失,反向传播,更新模型参数:
model = LinearRegressionModel()
num_epochs = 100 # 设置训练的轮数for epoch in range(num_epochs):for batch_id, (x_data, y_data) in enumerate(train_loader):# 前向传播,计算预测值pred = model(x_data)# 计算损失loss = loss_fn(pred, y_data)# 反向传播,计算梯度loss.backward()# 更新模型参数optimizer.step()# 清除梯度,为下一次迭代做准备optimizer.clear_grad()# 每10个批次打印一次损失值,观察训练过程if batch_id % 10 == 0:print(f"Epoch [{epoch}], Batch [{batch_id}], Loss: {loss.numpy()[0]}")在训练过程中,我们通过backward()方法计算梯度,并通过step()方法更新模型参数。clear_grad()方法用于清除梯度信息,为下一次迭代做准备。这个过程会重复进行,直到模型在训练数据上的表现达到满意的水平。通过打印损失值,我们可以监控模型的训练进度,这对于调整训练策略和优化模型性能非常重要。训练是机器学习项目中最核心的步骤之一,它决定了模型能否从数据中学习到有用的模式和规律。
6. 评估模型
评估模型是机器学习工作流程中的关键步骤,它帮助我们验证模型的性能,并确保模型能够在新的、未见过的数据上做出准确的预测。在模型评估阶段,我们通常将数据集分为训练集和测试集。训练集用于训练模型,而测试集则用于评估模型的泛化能力。以下是如何使用测试集来评估线性回归模型的性能:
# 假设test_loader是测试数据的DataLoader
test_loss = 0
num_batches = 0for x_data, y_data in test_loader:# 前向传播,计算预测值pred = model(x_data)# 计算损失loss = loss_fn(pred, y_data)# 累加损失test_loss += loss.numpy()[0]num_batches += 1# 计算平均损失
avg_test_loss = test_loss / num_batches
print(f"Average Test Loss: {avg_test_loss}")在这段代码中,我们遍历测试集的每个批次,使用模型进行预测,并计算损失。然后,我们将所有批次的损失累加起来,并计算平均损失。这个平均损失值是评估模型性能的重要指标,它告诉我们模型在测试集上的平均预测误差。一个低的平均测试损失表明模型在测试集上有很好的性能,而一个高的平均测试损失则表明模型可能过拟合或欠拟合。
7. 预测
一旦模型被训练和评估,我们就可以使用它来对新数据进行预测。这是机器学习项目的最终目标,即利用模型来解决实际问题。以下是如何使用训练好的线性回归模型进行预测:
# 假设new_X是新的输入数据
new_X = paddle.to_tensor(np.array([[1.5]]), dtype='float32')
new_pred = model(new_X)
print("Prediction:", new_pred)在这个例子中,我们创建了一个新的输入数据new_X,并使用训练好的模型来进行预测。模型的输出new_pred是对应于新输入数据的预测结果。这个预测结果可以用于各种应用,比如金融领域的风险评估、医疗领域的疾病预测、商业领域的销售预测等。
结论
通过本文的介绍,我们了解了如何使用PaddlePaddle来构建和训练一个线性回归模型。从数据准备到模型训练,再到评估和预测,PaddlePaddle提供了一套完整的工具和API,使得整个流程变得简单而高效。线性回归作为一个基础的机器学习模型,在许多领域都有广泛的应用。掌握如何使用PaddlePaddle实现线性回归,将为你在深度学习和机器学习领域的进一步探索打下坚实的基础。
随着技术的不断进步,深度学习和机器学习正在变得越来越重要,它们正在改变我们生活和工作的方式。通过学习和掌握这些技术,我们可以更好地适应未来的挑战,并在各自的领域中取得成功。线性回归模型虽然简单,但它是理解和学习更复杂机器学习算法的基石。通过实践线性回归项目,你可以积累宝贵的经验,为将来处理更复杂的数据和问题做好准备。
相关文章:

使用PaddlePaddle实现线性回归模型
目录 编辑 引言 PaddlePaddle简介 线性回归模型的构建 1. 准备数据 2. 定义模型 3. 准备数据加载器 4. 定义损失函数和优化器 5. 训练模型 6. 评估模型 7. 预测 结论 引言 线性回归是统计学和机器学习中一个经典的算法,用于预测一个因变量࿰…...

MongoDB集群的介绍与搭建
MongoDB集群的介绍与搭建 一.MongoDB集群的介绍 注意:Mongodb是一个比较流行的NoSQL数据库,它的存储方式是文档式存储,并不是Key-Value形式; 1.1集群的优势和特性 MongoDB集群的优势主要体现在以下几个方面: (1)高…...

PhpStorm配置Laravel
本文是2024最新的通过phpstorm创建laravel项目 1.下载phpstorm 2.检查本电脑的环境phpcomposer 显示图标就是安装成功了,不会安装的百度自行安装 3.安装完后,自行创建一个空目录不要有中文,然后运行cmd 输入以下命令,即可创建…...

Solving the Makefile Missing Separator Stop Error in VSCode
1. 打开 Makefile 并转换缩进 步骤 1: 在 VSCode 中打开 Makefile 打开 VSCode。使用文件浏览器或 Ctrl O(在 Mac 上是 Cmd O)打开你的 Makefile。 步骤 2: 打开命令面板 按 Ctrl Shift P(在 Mac 上是 Cmd Shift P)&…...

MySQL大小写敏感、MySQL设置字段大小写敏感
文章目录 一、MySQL大小写敏感规则二、设置数据库及表名大小写敏感 2.1、查询库名及表名是否大小写敏感2.2、修改库名及表名大小写敏感 三、MySQL列名大小写不敏感四、lower_case_table_name与校对规则 4.1、验证校对规则影响大小写敏感4.1、验证校对规则影响排序 五、设置字段…...

项目搭建:guice,jdbc,maven
当然,以下是一个使用Guice、JDBC和Maven实现接口项目的具体例子。这个项目将展示如何创建一个简单的用户管理应用,包括用户信息的增删改查(CRUD)操作。 ### 1. Maven pom.xml 文件 首先确保你的pom.xml文件包含必要的依赖&#…...
)
第四届新生程序设计竞赛正式赛(C语言)
A: HNUCM的学习达人 SQ同学是HNUCM的学习达人,据说他每七天就能够看完一本书,每天看七分之一本书,而且他喜欢看完一本书之后再看另外一本。 现在请你编写一个程序,统计在指定天数中,SQ同学看完了多少本完整的书&#x…...

【分布式知识】Redis6.x新特性了解
文章目录 Redis6.x新特性1. 多线程I/O处理2. 改进的过期算法3. SSL/TLS支持4. ACL(访问控制列表)5. RESP3协议6. 客户端缓存7. 副本的无盘复制8. 其他改进 Redis配置详解1. 基础配置2. 安全配置3. 持久化配置4. 客户端与连接5. 性能与资源限制6. 其他配置…...

程序员需要具备哪些知识?
程序员需要掌握的知识广泛而深厚,这主要取决于具体从事的领域和技术方向。不过,有些核心知识是共通的,就像建房子的地基一样,下面来讲讲这些关键领域: 1. 编程语言: 无论你是搞前端、后端、移动开发还是嵌…...

实验四:MyBatis 的关联映射
目录: 一 、实验目的: 熟练掌握实体之间的各种映射关系。 二 、预习要求: 预习数据库原理中所讲过的一对一、一对多和多对多关系 三、实验内容: 1. 查询所有订单信息,关联查询下单用户信息(注意:因为一…...

【Leetcode】189.轮转数组
题目链接: 189.轮转数组 题目描述: 解题思路: 要想实现数组元素向右轮转k个位置,可是将数组三次反转来实现 以 nums [1,2,3,4,5,6,7], k 3 为例,最终要得到[5,6,7,1,2,3,4]: 第一次反转:将整个数组反转…...

【JavaSE】常见面试问题
1. 什么是 Java 中的多态? 多态是 Java 中面向对象的核心特性之一,指的是同一操作作用于不同类型的对象时表现出不同的行为。通过方法重载和方法重写实现。方法重载是同一方法名,根据参数不同做不同处理,属于编译时多态ÿ…...
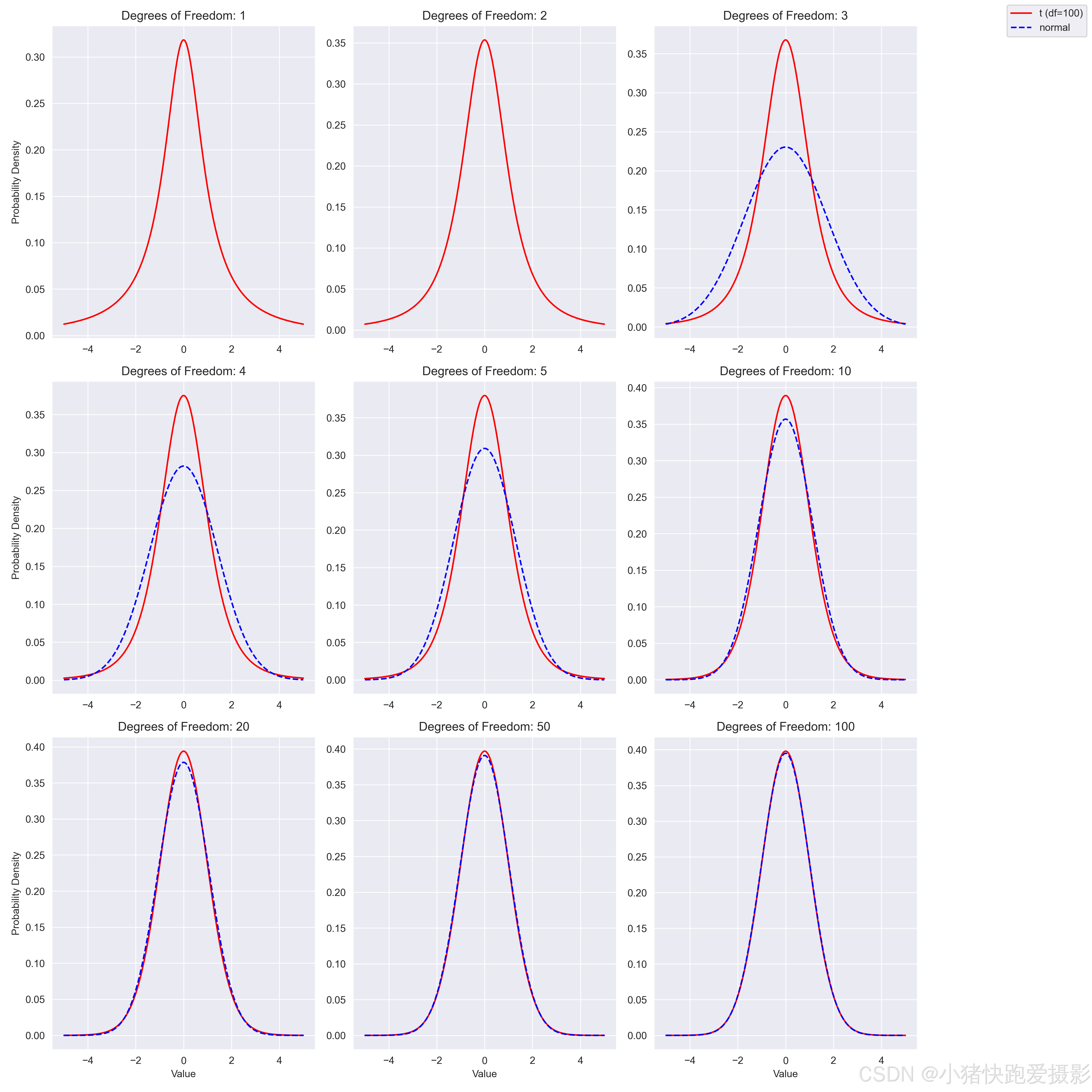
【超详图文】多少样本量用 t分布 OR 正态分布
文章目录 相关教程相关文献预备知识Lindeberg-Lvy中心极限定理 t分布的来历实验不同分布不同抽样次数的总体分布不同自由度相同参数的t分布&正态分布 作者:小猪快跑 基础数学&计算数学,从事优化领域7年,主要研究方向:MIP求…...

leetcode hot100【Leetcode 416.分割等和子集】java实现
Leetcode 416.分割等和子集 题目描述 给定一个非负整数的数组 nums ,你需要将该数组分割成两个子集,使得两个子集的元素和相等。如果可以分割,返回 true ,否则返回 false。 示例 1: 输入:nums [1,5,11,…...

《算法导论》英文版前言To the teacher第4段研习录:有答案不让用
【英文版】 Departing from our practice in previous editions of this book, we have made publicly available solutions to some, but by no means all, of the problems and exercises. Our Web site, http://mitpress.mit.edu/algorithms/, links to these solutions. Y…...

Laravel关联模型查询
一,多表关联 文章表articles 和user_id,category_id关联 //with()方法是渴求式加载,缓解了1N的查询问题,仅需11次查询就能解决问题,可以提升查询速度。with部分没有就以null输出,所以可以理解为 多表 left join 查…...

Clickhouse 数据类型
文章目录 字符串类型数值类型日期时间类型枚举类型数组类型元组类型映射类型其它类型 字符串类型 数据类型描述备注String可变长度字符串无长度限制,适用于存储任意字符FixedString固定长度字符串定长字符串,长度在创建时指定,如 FixedStrin…...

物联网智能项目如何实现设备高效互联与数据处理?
一、硬件(Hardware) 设备互联的基础,涵盖传感器、执行器、网关和边缘计算设备。 传感器与执行器 功能: 采集环境数据(如温度、湿度、运动等)并执行控制命令。优化方向: 低功耗、高精度传感器以…...

【云服务器】搭建博客服务
未完待续 一、云服务器二、1panel安装及其容器三、Halo博客 一、云服务器 选择了狗云服务器:狗云-高性价比的服务器 安装系统:Ubuntu22.04 前期配置: 修改ssh端口: 二、1panel安装及其容器 三、Halo博客 主题:butt…...

如何抽象策略模式
策略模式是什么 策略设计模式(Strategy Pattern)是一种面向对象设计模式,它定义了一系列算法,并将每个算法封装起来,使它们可以相互替换。这种模式使得算法可以独立于使用它们的客户端而变化。 策略设计模式包含三个主…...

PowerToys汉化指南:3步让英文效率工具变成你的中文助手
PowerToys汉化指南:3步让英文效率工具变成你的中文助手 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是不是曾经因为PowerToys的英文界面…...

我用AI一周做了个口播视频平台,现在开源了
做独立开发这两年,我一直在想一个问题:一个人到底能做到什么程度? 上周我给出了自己的答案——我用 DeepSeek 定义需求 CodeBuddy 辅助编码,一个人从零搞了一个 AI 口播视频生成平台,取名智播坊。输入文案࿰…...

如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南
如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南 【免费下载链接】ColabFold Making Protein folding accessible to all! 项目地址: https://gitcode.com/gh_mirrors/co/ColabFold ColabFold蛋白质结构预测是生物信息学领域的一项革命性技术&a…...

SAP 和 Legacy 系统之间的平面文件集成,GUI_DOWNLOAD 的实战设计
很多 SAP 项目里,系统集成并不总是从 API、RFC、OData 或 Event Mesh 开始。相当多的老系统仍然依赖一个最朴素的接口形态,固定格式的文本文件。财务共享平台要一份物料清单,仓储系统要一份当天新增物料,历史的生产执行系统只认 .txt 或 .csv,这时 ABAP 报表把 SAP 表里的…...

别再死记硬背了!用Spark实战电影评分分析,手把手教你搞定Join操作与数据清洗
用Spark实战电影评分分析:从数据清洗到Join操作的完整指南 每次看到电影评分网站上的"Top 100"榜单,你有没有好奇过背后的数据处理逻辑?作为Spark初学者,你可能已经啃了不少官方文档,但面对真实数据集时依然…...

LeetCode 409:最长回文串 | 哈希表统计字符频率
LeetCode 409:最长回文串 | 哈希表统计字符频率 引言 最长回文串(Longest Palindrome)是 LeetCode 第 409 题,难度为 Easy。题目要求在给定字符串中构造最长的回文串,返回其长度。这道题虽然简单,但蕴含了回…...

CANN/pypto填充操作API
pypto.pad 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/Atla…...

uView 2.0插件开发指南:如何扩展自定义组件与工具函数
uView 2.0插件开发指南:如何扩展自定义组件与工具函数 【免费下载链接】uView2.0 uView UI,是全面兼容nvue的uni-app生态框架,全面的组件和便捷的工具会让您信手拈来,如鱼得水 项目地址: https://gitcode.com/gh_mirrors/uv/uVi…...
)
Navicat密码忘了别慌!手把手教你用Java小工具找回(支持15/16版本)
Navicat密码找回实战指南:零基础也能操作的Java解密方案 上周五凌晨两点,李工程师在部署紧急热修复时突然发现——Navicat里保存的生产数据库密码居然记不清了。这个场景对于经常需要管理多个数据库连接的开发者来说并不陌生。本文将详细介绍一套经过验证…...

Lemur性能优化:10个提升证书管理平台响应速度的技巧
Lemur性能优化:10个提升证书管理平台响应速度的技巧 【免费下载链接】lemur Repository for the Lemur Certificate Manager 项目地址: https://gitcode.com/gh_mirrors/le/lemur Lemur作为一款开源证书管理平台,能够帮助用户轻松管理SSL/TLS证书…...