Hadoop生态圈框架部署(八)- Hadoop高可用(HA)集群部署
文章目录
- 前言
- 一、部署规划
- 二、Hadoop HA集群部署(手动部署)
- 1. 下载hadoop
- 2. 上传安装包
- 2. 解压hadoop安装包
- 3. 配置hadoop配置文件
- 3.1 虚拟机hadoop1修改hadoop配置文件
- 3.1.1 修改 hadoop-env.sh 配置文件
- 3.3.2 修改 core-site.xml 配置文件
- 3.3.3 修改 hdfs-site.xml 配置文件
- 3.3.4 修改 mapred-site.xml 配置文件
- 3.3.5 修改 yarn-site.xml 配置文件
- 3.3.6 修改 workers 配置文件
- 3.2 虚拟机hadoop2安装并配置hadoop
- 3.3 虚拟机hadoop3安装并配置hadoop
- 4. 配置hadoop环境变量
- 4.1 配置虚拟机hadoop1的hadoop环境变量
- 4.2 配置虚拟机hadoop2的hadoop环境变量
- 4.3 配置虚拟机hadoop3的hadoop环境变量
- 三、启动过程
- 1. 启动zookeeper
- 2. 启动JournalNode
- 3. 格式化HDFS(Hadoop分布式文件系统)
- 4. FSImage文件同步
- 5. 格式化ZKFC
- 6. hadoop集群启动和停止
- 6.1 启动 hadoop HA 集群
- 6.2 停止 hadoop HA 集群
- 四、测试NameNode和ResourceManager的主备切换
- 1. 启动 hadoop HA 集群
- 2. 通过服务ID查看NameNode和ResourceManager的状态
- 2.1 查看NameNode的状态
- 2.2 查看ResourceManager的状态
- 3. 测试主备切换
- 3.1 查看NameNode的状态
- 3.2 查看ResourceManager的状态
- 注意
前言
在当今大数据时代,Hadoop作为一种强大的分布式计算框架,广泛应用于海量数据的存储与处理。为了确保系统的高可用性和可靠性,Hadoop引入了高可用性(HA)架构,通过部署多个NameNode和ResourceManager,实现故障转移和负载均衡。本篇文章将详细介绍如何在虚拟机环境中手动部署Hadoop高可用集群,包括环境准备、配置文件修改、服务启动与测试等步骤。通过本指南,读者将能够掌握Hadoop HA集群的搭建过程,为后续的大数据应用打下坚实的基础。
一、部署规划
| 虚拟机 | Name Node | Data Node | Resource Manager | Node Manager | Journal Node | QuorumPeer Main | ZKFC |
|---|---|---|---|---|---|---|---|
| hadoop1 | √ | √ | √ | √ | √ | √ | √ |
| hadoop2 | √ | √ | √ | √ | √ | √ | √ |
| hadoop3 | √ | √ | √ | √ |
二、Hadoop HA集群部署(手动部署)
1. 下载hadoop
点击下载hadoop3.3.0安装包:https://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
2. 上传安装包
通过拖移的方式将下载的hadoop安装包hadoop-3.3.0.tar.gz上传至虚拟机hadoop1的/export/software目录。

2. 解压hadoop安装包
在虚拟机hadoop1创建Hadoop HA的安装目录。
mkdir -p /export/servers/hadoop-HA

在虚拟机hadoop1上传完成后将hadoop安装包通过解压方式安装至/export/servers/hadoop-HA目录。
tar -zxvf /export/software/hadoop-3.3.0.tar.gz -C /export/servers/hadoop-HA/
解压完成如下图所示。

3. 配置hadoop配置文件
3.1 虚拟机hadoop1修改hadoop配置文件
3.1.1 修改 hadoop-env.sh 配置文件
在虚拟机hadoop1修改hadoop运行时环境变量配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh,使用echo命令向hadoop-env.sh文件追加如下内容。
echo >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export JAVA_HOME=/export/servers/jdk1.8.0_421' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_NAMENODE_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_DATANODE_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_SECONDARYNAMENODE_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export YARN_RESOURCEMANAGER_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export YARN_NODEMANAGER_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_JOURNALNODE_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_ZKFC_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh

查看文件内容是否添加成功。
cat /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh

3.3.2 修改 core-site.xml 配置文件
在虚拟机hadoop1修改hadoop核心配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/core-site.xml,使用echo命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/core-site.xml 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/core-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定HDFS的通信地址 --><property><name>fs.defaultFS</name><value>hdfs://ns1</value></property><!-- 指定Hadoop临时数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/export/data/hadoop-HA/hadoop/</value></property><!-- 配置ZooKeeper集群的地址列表,用于Hadoop高可用性(HA) --><property><name>ha.zookeeper.quorum</name><value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value></property><!-- 设置访问Hadoop Web界面时使用的静态用户名 --><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- 允许root用户代理任何主机上的请求,指定了哪些主机可以作为代理用户来提交作业 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!-- 允许root用户代理任何组的用户 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
</configuration>
EOF

3.3.3 修改 hdfs-site.xml 配置文件
在虚拟机hadoop1修改hdfs的配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hdfs-site.xml,使用cat命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hdfs-site.xml 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hdfs-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 设置HDFS的副本数 --><property><name>dfs.replication</name><value>3</value></property><!-- NameNode的元数据存储目录 --><property><name>dfs.namenode.name.dir</name><value>/export/data/hadoop/namenode</value></property><!-- DataNode的数据存储目录 --><property><name>dfs.datanode.data.dir</name><value>/export/data/hadoop/datanode</value></property><!-- 设置命名服务的名称,在 HDFS 中,nameservices 是一个逻辑名称,用于标识一组 NameNode 实例。它允许客户端和其他 HDFS 组件通过一个统一的名称来访问多个 NameNode,从而实现高可用性。 --><property><name>dfs.nameservices</name><value>ns1</value></property><!-- 配置高可用性NameNode --><property><name>dfs.ha.namenodes.ns1</name><value>nn1,nn2</value></property><!-- NameNode nn1 的 RPC 地址 --><property><name>dfs.namenode.rpc-address.ns1.nn1</name><value>hadoop1:9000</value></property><!-- NameNode nn1 的 HTTP 地址 --><property><name>dfs.namenode.http-address.ns1.nn1</name><value>hadoop1:9870</value></property><!-- NameNode nn2 的 RPC 地址 --><property><name>dfs.namenode.rpc-address.ns1.nn2</name><value>hadoop2:9000</value></property><!-- NameNode nn2 的 HTTP 地址 --><property><name>dfs.namenode.http-address.ns1.nn2</name><value>hadoop2:9870</value></property><!-- 共享edits日志的目录,在 HA 配置中,多个 NameNode 需要访问同一组edits日志,以确保它们之间的数据一致性。 --><!-- qjournal 是一种用于存储edits日志的机制。它允许多个 NameNode 通过一个共享的、可靠的日志系统来记录对文件系统的修改。qjournal 由多个 JournalNode 组成,这些 JournalNode 负责接收和存储来自 NameNode 的编辑日志。 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1</value></property><!-- JournalNode的edits日志存储目录 --><property><name>dfs.journalnode.edits.dir</name><value>/export/data/journaldata</value></property><!-- 启用自动故障转移 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置客户端故障转移代理提供者 --><property><name>dfs.client.failover.proxy.provider.ns1</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 禁用权限检查 --><property><name>dfs.permissions.enable</name><value>false</value></property><!-- 配置高可用性隔离方法 --><property><name>dfs.ha.fencing.methods</name><value>sshfenceshell(/bin/true)</value></property><!-- SSH围栏使用的私钥文件 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- SSH连接超时时间 --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property>
</configuration>
EOF




3.3.4 修改 mapred-site.xml 配置文件
在虚拟机hadoop1修改mapreduce的配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/mapred-site.xml,使用cat命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/mapred-site.xml 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/mapred-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定MapReduce框架使用的资源管理器名称,这里设置为YARN --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 设置MapReduce JobHistory服务的地址,用于存储已完成作业的历史信息 --><property><name>mapreduce.jobhistory.address</name><value>hadoop1:10020</value></property><!-- 设置MapReduce JobHistory Web应用程序的地址,可以通过浏览器访问来查看作业历史记录 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop1:19888</value></property><!-- 为MapReduce Application Master设置环境变量,指定HADOOP_MAPRED_HOME路径 --><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=\${HADOOP_HOME}</value></property><!-- 为Map任务设置环境变量,指定HADOOP_MAPRED_HOME路径 --><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=\${HADOOP_HOME}</value></property><!-- 为Reduce任务设置环境变量,指定HADOOP_MAPRED_HOME路径 --><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=\${HADOOP_HOME}</value></property>
</configuration>
EOF

3.3.5 修改 yarn-site.xml 配置文件
在虚拟机hadoop1修改yarn的配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/yarn-site.xml,使用cat命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/yarn-site.xml 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/yarn-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 启用YARN ResourceManager的高可用性(HA) --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 设置YARN集群的唯一标识符,自定义YARN高可用集群的标识符 --><property><name>yarn.resourcemanager.cluster-id</name><value>jyarn</value></property><!-- 列出所有ResourceManager实例的ID,指定YARN高可用集群中每个ResourceManager的唯一标识符 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- 指定第一个ResourceManager实例(rm1)的主机名 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>hadoop1</value></property><!-- 指定第二个ResourceManager实例(rm2)的主机名 --><property><name>yarn.resourcemanager.hostname.rm2</name><value>hadoop2</value></property><!-- 指定ZooKeeper服务器地址,用于存储ResourceManager的状态信息 --><property><name>yarn.resourcemanager.zk-address</name><value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value></property><!-- 配置NodeManager上的辅助服务,这里设置为MapReduce shuffle服务 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 启用日志聚合功能,将容器日志收集到HDFS中 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志保留时间(秒),这里是1天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value></property><!-- 启用ResourceManager的恢复功能 --><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!-- 指定ResourceManager状态存储的实现类,这里使用ZooKeeper作为存储 --><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><!-- 指定第一个ResourceManager实例(rm1)Web应用程序的地址 --><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>hadoop1:8188</value></property><!-- 指定第一个ResourceManager实例(rm1)调度器的地址 --><property><name>yarn.resourcemanager.scheduler.address.rm1</name><value>hadoop1:8130</value></property><!-- 指定第二个ResourceManager实例(rm2)Web应用程序的地址 --><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>hadoop2:8188</value></property><!-- 指定第二个ResourceManager实例(rm2)调度器的地址 --><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>hadoop2:8130</value></property>
</configuration>
EOF


3.3.6 修改 workers 配置文件
在虚拟机hadoop1修改hadoop的从节点服务器配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/workers,使用cat命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/workers 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/workers <<EOF
hadoop1
hadoop2
hadoop3
EOF

3.2 虚拟机hadoop2安装并配置hadoop
在虚拟机hadoop1远程登录到hadoop2创建hadoop高可用的安装目录,使用scp命令把虚拟机hadoop1的hadoop的安装目录复制到虚拟机hadoop2的相同目录下,就相当于在hadoop2安装并配置了hadoop。
ssh hadoop2 'mkdir -p /export/servers/hadoop-HA exit'
scp -r /export/servers/hadoop-HA/hadoop-3.3.0 hadoop2:/export/servers/hadoop-HA

3.3 虚拟机hadoop3安装并配置hadoop
在虚拟机hadoop1远程登录到hadoop3创建hadoop高可用的安装目录,使用scp命令把虚拟机hadoop1的hadoop的安装目录复制到虚拟机hadoop3的相同目录下,就相当于在hadoop3安装并配置了hadoop。
ssh hadoop3 'mkdir -p /export/servers/hadoop-HA exit'
scp -r /export/servers/hadoop-HA/hadoop-3.3.0 hadoop3:/export/servers/hadoop-HA

4. 配置hadoop环境变量
4.1 配置虚拟机hadoop1的hadoop环境变量
在虚拟机hadoop1使用echo命令向环境变量配置文件/etc/profile追加环境变量内容,使用source命令加载环境变量配置文件,然后使用echo命令打印环境变量,查看环境变量是否生效。
echo >> /etc/profile
echo 'export HADOOP_HOME=/export/servers/hadoop-HA/hadoop-3.3.0' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
echo $HADOOP_HOME

4.2 配置虚拟机hadoop2的hadoop环境变量
在虚拟机hadoop2使用echo命令向环境变量配置文件/etc/profile追加环境变量内容,使用source命令加载环境变量配置文件,然后使用echo命令打印环境变量,查看环境变量是否生效。
echo >> /etc/profile
echo 'export HADOOP_HOME=/export/servers/hadoop-HA/hadoop-3.3.0' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
echo $HADOOP_HOME

4.3 配置虚拟机hadoop3的hadoop环境变量
在虚拟机hadoop3使用echo命令向环境变量配置文件/etc/profile追加环境变量内容,使用source命令加载环境变量配置文件,然后使用echo命令打印环境变量,查看环境变量是否生效。
echo >> /etc/profile
echo 'export HADOOP_HOME=/export/servers/hadoop-HA/hadoop-3.3.0' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
echo $HADOOP_HOME

三、启动过程
1. 启动zookeeper
由于 Hadoop 的高可用性依赖于 ZooKeeper 来实现 HDFS 和 YARN 的高可用性,因此在启动 Hadoop 之前,必须确保 ZooKeeper 正常运行。
依次在虚拟机 hadoop1、hadoop2 和 hadoop3 启动 ZooKeeper,并检查其状态是否正常。
zkServer.sh start

zkServer.sh status

2. 启动JournalNode
在格式化 Hadoop 高可用集群的 HDFS 文件系统时,系统会向 Quorum Journal Manager 写入 EditLog。在首次启动之前,需要在虚拟机 Hadoop1、Hadoop2 和 Hadoop3 上分别执行以下命令以启动 JournalNode。
hdfs --daemon start journalnode



3. 格式化HDFS(Hadoop分布式文件系统)
在虚拟机hadoop1执行如下命令格式化Hadoop分布式文件系统HDFS。
hdfs namenode -format
格式化成功如下图所示,会提示我们存储目录 /export/data/hadoop/namenode 已经成功格式化。

4. FSImage文件同步
为了确保HDFS初次启动时两个NameNode节点上的FSImage文件保持一致,在虚拟机hadoop1上完成HDFS格式化后(此操作仅初始化虚拟机hadoop1的NameNode并生成FSImage文件),需要将生成的FSImage文件从hadoop1复制到hadoop2对应的目录中。
在虚拟机hadoop1执行如下命令把hadoop1生成的FSImage文件复制到hadoop2对应的目录。
ssh hadoop2 'mkdir -p /export/data/hadoop'
scp -r /export/data/hadoop/namenode hadoop2:/export/data/hadoop

5. 格式化ZKFC
ZKFC(ZooKeeper Failover Controller)是Hadoop高可用性(HA)架构中的一个关键组件,主要用于NameNode的故障转移管理。在HDFS HA配置中,通常会部署两个NameNode节点来提供服务冗余,其中一个处于Active状态负责处理客户端请求,另一个则处于Standby状态作为备份。ZKFC的作用就是在主NameNode发生故障时自动切换到备用NameNode,从而保证系统的连续性和数据的一致性。
在虚拟机hadoop1执行如下命令格式化ZKFC。
hdfs zkfc -formatZK

6. hadoop集群启动和停止
6.1 启动 hadoop HA 集群
在虚拟机hadoop1执行如下命令同时启动 hdfs 高可用集群和 yarn 高可用集群。
start-all.sh

hadoop 高可用集群启动之后使用如下命名分别在虚拟机hadoop1、虚拟机hadoop2和虚拟机hadoop3执行如下命令查看对应进程是否正常。
jps正常如下图所示。

访问 HDFS(NameNode)的 Web UI 页面
在启动 hadoop 高可用集群后,在浏览器输入http://192.168.121.160:9870进行访问,如下图,可以看到处于active(活跃)状态的NameNode。
在浏览器输入
http://192.168.121.161:9870进行访问,如下图,可以看到处于standby(备用)状态的NameNode。
检查DataNode是否正常,正常如下图所示。



访问 YARN 的 Web UI 页面
在启动hadoop集群后,在浏览器输入http://192.168.121.161:8188进行访问,如下图,可以看到处于active(活跃)状态的ResourceManager。
在浏览器输入http://192.168.121.160:8188进行访问,如下图,可以看到处于standby(备用)状态的ResourceManager。


6.2 停止 hadoop HA 集群
如果需要停止 hadoop HA 集群运行,在虚拟机hadoop1执行如下命令同时停止 hdfs 高可用集群和 yarn高可用集群。
stop-all.sh

四、测试NameNode和ResourceManager的主备切换
1. 启动 hadoop HA 集群
在虚拟机hadoop1执行如下命令同时启动 hdfs 高可用集群和 yarn 高可用集群。
start-all.sh

2. 通过服务ID查看NameNode和ResourceManager的状态
下图所示是设置的NameNode服务的ID。

2.1 查看NameNode的状态
hadoop配置中设置的nn1在hadoop1,nn2在hadoop2。
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2

可以看出hadoop1上的NameNode是active状态。
2.2 查看ResourceManager的状态
hadoop配置中设置的rm1在hadoop1,rm2在hadoop2。
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2

可以看出hadoop2上的ResourceManager是active状态。
3. 测试主备切换
根据上面得到的处于active状态的NameNode和ResourceManager的虚拟机,分别在对应的虚拟机停止处于active状态的服务,测试主备切换。
在虚拟机hadoop1执行如下命令停止虚拟机hadoop1的NameNode。
hdfs --daemon stop namenode
在虚拟机hadoop2执行如下命令停止虚拟机hadoop2的ResourceManager。
yarn --daemon stop resourcemanager
再次通过服务ID查看NameNode和ResourceManager的状态。
3.1 查看NameNode的状态
hadoop配置中设置的nn1在hadoop1,nn2在hadoop2。
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2

可以看出hadoop1上的NameNode已经由active状态变为不正常,hadoop2上的NameNode已经由standby转为active。
3.2 查看ResourceManager的状态
hadoop配置中设置的rm1在hadoop1,rm2在hadoop2。
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
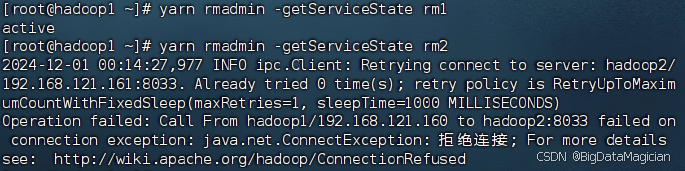
可以看出hadoop2上的ResourceManager已经由active状态变为不正常,hadoop1上的ResourceManager已经由standby转为active。
注意
若启动过程中出现问题,需要重新执行启动过程,需要删除生成的对应目录或文件。
rm -rf /export/data/hadoop-HA
rm -rf /export/data/hadoop
rm -rf /export/data/journaldata
zkCli.sh
deleteall /hadoop-ha
deleteall /rmstore
deleteall /yarn-leader-election
quit
相关文章:
Hadoop生态圈框架部署(八)- Hadoop高可用(HA)集群部署
文章目录 前言一、部署规划二、Hadoop HA集群部署(手动部署)1. 下载hadoop2. 上传安装包2. 解压hadoop安装包3. 配置hadoop配置文件3.1 虚拟机hadoop1修改hadoop配置文件3.1.1 修改 hadoop-env.sh 配置文件3.3.2 修改 core-site.xml 配置文件3.3.3 修改 …...
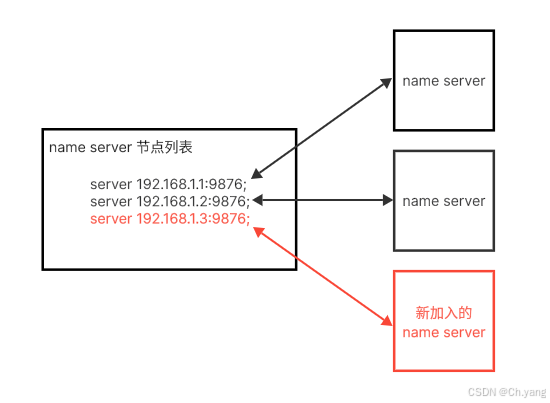
【RocketMQ】Name Server 无状态特点及如何让 Broker Consumer Producer 感知新节点
文章目录 前言1. Name Server 无状态特点2. Name Server 地址服务3. Name Server 手动配置后记 前言 看了 《RocketMQ 消息中间件实战派(上册)》前面一点,书中代码太多容易陷入细节。 这里简单描述下 RocketMQ Name Server 无状态表现在什么…...
蓝牙定位的MATLAB程序,四个锚点、三维空间
这段代码通过RSSI信号强度实现了在三维空间中的蓝牙定位,展示了如何使用锚点位置和测量的信号强度来估计未知点的位置。代码涉及信号衰减模型、距离计算和最小二乘法估计等基本概念,并通过三维可视化展示了真实位置与估计位置的关系。 目录 程序描述 运…...

机器学习--绪论
开启这一系列文章的初衷,是希望搭建一座通向机器学习世界的桥梁,为有志于探索这一领域的读者提供系统性指引和实践经验分享。随着人工智能和大数据技术的迅猛发展,机器学习已成为推动技术创新和社会变革的重要驱动力。从智能推荐系统到自然语…...
详解)
Unity 设计模式-命令模式(Command Pattern)详解
命令模式(Command Pattern)是一种行为型设计模式,它将请求封装成对象,从而使得可以使用不同的请求、队列或日志请求,以及支持可撤销的操作。命令模式通常包含四个主要角色:命令(Command…...

线程信号量 Linux环境 C语言实现
既可以解决多个同类共享资源的互斥问题,也可以解决简易的同步问题 头文件:#include <semaphore.h> 类型:sem_t 初始化:int sem_init(sem_t *sem, int pshared, unsigned int value); //程序中第一次对指定信号量调用p、v操…...
karmada-descheduler
descheduler规则 karmada-descheduler 定期检测所有部署,通常是每2分钟一次,并确定目标调度集群中无法调度的副本数量。它通过调用 karmada-scheduler-estimator 来完成这个过程。如果发现无法调度的副本,它将通过减少 spec.clusters 的配…...

【热门主题】000075 探索嵌入式硬件设计的奥秘
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 【热…...

Android okhttp请求
下面是一个用 OkHttp 封装的 GET 请求方法,适用于 Android 项目。该方法包括基本的网络请求、错误处理,并支持通过回调返回结果。 封装 GET 请求的工具类 添加依赖 在你的 build.gradle 文件中,确保添加了 OkHttp 的依赖: imple…...

嵌入式蓝桥杯学习4 lcd移植
cubemx配置 复制前面配置过的文件 打开cubemx,将PB8,PB9配置为GPIO-Output。 点击GENERATE CODE. 文件移植 1.打开比赛提供的文件包,点击Inc文件夹 2.点击Inc文件夹。复制fonts.h和lcd.h,粘贴到我们自己的工程文件夹的bsp中(…...

电子应用设计方案-38:智能语音系统方案设计
智能语音系统方案设计 一、引言 智能语音系统作为一种便捷、自然的人机交互方式,正逐渐在各个领域得到广泛应用。本方案旨在设计一个高效、准确、功能丰富的智能语音系统。 二、系统概述 1. 系统目标 - 实现高准确率的语音识别和自然流畅的语音合成。 - 支持多种语…...

渗透测试:网络安全的深度探索
一、引言 在当今数字化时代,网络安全问题日益凸显。企业和组织面临着来自各种恶意攻击者的威胁,他们试图窃取敏感信息、破坏系统或进行其他恶意活动。渗透测试作为一种主动的安全评估方法,能够帮助企业发现潜在的安全漏洞,提高网…...
基于SpringBoot的“小区物业管理系统”的设计与实现(源码+数据库+文档+PPT)
基于SpringBoot的“小区物业管理系统”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:SpringBoot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统功能结构图 个人信息界面图 费用信息管理…...

调试android 指纹遇到的坑
Android8以后版本 一、指纹服务不能自动 指纹服务fingerprintd(biometrics fingerprintservice),可以手动起来,但是在init.rc中无法启动。 解决办法: 1.抓取开机时kernel log ,确认我们的启动指纹服务的init.rc 文件有被init.c…...
剑指offer(专项突破)---字符串
总目录:剑指offer(专项突破)---目录-CSDN博客 1.字符串的基本知识 C语言中: 函数名功能描述strcpy(s1, s2)将字符串s2复制到字符串s1中,包括结束符\0,要求s1有足够空间容纳s2的内容。strncpy(s1, s2, n)…...

【springboot】 多数据源实现
文章目录 1. 引言:多数据源的必要性和应用场景**为什么需要多数据源?****应用场景** 2. Spring Boot中的数据源配置2.1 默认数据源配置简介2.2 如何在Spring Boot中配置多个数据源 3. 整合MyBatis与多数据源**配置MyBatis使用多数据源****Mapper接口的数…...

多模态COGMEN详解
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...
)
django 实战(python 3.x/django 3/sqlite)
要在 Python 3.x 环境中使用 Django 3.2 和 SQLite 创建一个新的 Django 项目,你可以按照以下步骤进行操作。这些步骤假设你已经安装了 Python 3.x 和 pip。 1. 设置虚拟环境 首先,建议为你的 Django 项目创建一个虚拟环境,以便隔离项目的依…...

图数据库 | 12、图数据库架构设计——高性能计算架构
在传统类型的数据库架构设计中,通常不会单独介绍计算架构,一切都围绕存储引擎展开,毕竟存储架构是基础,尤其是在传统的基于磁盘存储的数据库架构设计中。 类似地,在图数据库架构设计中,项目就围绕存储的方…...

Unity 利用Button 组件辅助Scroll View 滚动
实现 创建枚举类ScrollDir 以区分滚动方向。每组两个按钮负责同方向上左右/上下滚动。 Update 中实时获取Scroll View 滚动条当前位置。 if (dir.Equals(ScrollDir.vertical)) {posCurrent scroll.verticalNormalizedPosition; } else if (dir.Equals(ScrollDir.horizontal)…...

惠普tank 2606屏幕显示 er-08 ,加了粉还是报错er08,黄灯闪烁成像鼓接近寿命期限?亲测完美修复。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1J7PN4m4fbIzku9DqBFg_nw?pwd0000...

企业AI知识库搭建实战:从文件管理到智能检索的完整方案
2025年我们团队做过一个调研,找了37家用了AI知识库的企业,发现一个有意思的规律:真正用起来的不到1/3,剩下2/3基本都卡在同一个地方——知识库和文件管理系统是割裂的。 你让员工把文件再上传一遍到知识库?没人干。你让…...

喜马拉雅音频下载神器:3步搞定VIP付费专辑的终极完整指南
喜马拉雅音频下载神器:3步搞定VIP付费专辑的终极完整指南 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 想要轻松下载…...

3分钟解决iPhone网络共享驱动问题:Windows用户终极指南
3分钟解决iPhone网络共享驱动问题:Windows用户终极指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mi…...
)
别再手动调图了!用LaTeX的subcaption包搞定论文子图排版(附完整代码)
LaTeX子图排版终极指南:告别手动调整的5个高效技巧 写论文时最让人抓狂的莫过于图片排版——尤其是当需要排列多个子图时。每次编译后总有几个图片位置不对齐,标题错位,或者直接跑到了下一页。这种反复调试的过程不仅浪费时间,还…...

星露谷物语SMAPI模组加载器:终极安装与使用完整指南
星露谷物语SMAPI模组加载器:终极安装与使用完整指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否想在星露谷物语中体验数百个模组带来的无限可能,却又担心安装复杂和…...

Awesome Video终极指南:从零开始掌握流媒体视频技术栈
Awesome Video终极指南:从零开始掌握流媒体视频技术栈 【免费下载链接】awesome-video A curated list of awesome streaming video tools, frameworks, libraries, and learning resources. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-video 流媒…...

鸣潮自动化助手:5步轻松实现后台智能战斗与资源收集
鸣潮自动化助手:5步轻松实现后台智能战斗与资源收集 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves 还在为每天重复刷声…...

PTFE材料在多领域的创新应用与发展分析
PTFE材料在生活领域的独特贡献不粘锅技术的演变与PTFE应用不粘锅的问世大大推动了厨房烹饪的便利性,而PTFE材料在其中扮演了关键角色。随着科技的发展,我们见证了PTFE涂层技术的不断创新,早期的传统不粘锅被更为耐磨、不易脱落的新型PTFE涂层…...

AI驱动数字孪生:从静态镜像到自主决策的工业智能体
1. 项目概述:当物理世界有了“数字分身”,它就开始自己思考了我第一次在德国一家汽车厂的控制中心看到那个画面时,手里的咖啡差点洒出来——大屏幕上,整条总装线正以毫秒级延迟同步运转:机械臂的关节扭矩、焊点温度曲线…...