【AIGC】大模型面试高频考点-位置编码篇
【AIGC】大模型面试高频考点-位置编码篇
- (一)手撕 绝对位置编码 算法
- (二)手撕 可学习位置编码 算法
- (三)手撕 相对位置编码 算法
- (四)手撕 Rope 算法(旋转位置编码)
(一)手撕 绝对位置编码 算法
class SinPositionEncoding(nn.Module):def __init__(self, max_sequence_length, d_model, base=10000):super().__init__()self.max_sequence_length = max_sequence_lengthself.d_model = d_modelself.base = basedef forward(self):pe = torch.zeros(self.max_sequence_length, self.d_model, dtype=torch.float) # size(max_sequence_length, d_model)exp_1 = torch.arange(self.d_model // 2, dtype=torch.float) # 初始化一半维度,sin位置编码的维度被分为了两部分exp_value = exp_1 / (self.d_model / 2)alpha = 1 / (self.base ** exp_value) # size(dmodel/2)out = torch.arange(self.max_sequence_length, dtype=torch.float)[:, None] @ alpha[None, :] # size(max_sequence_length, d_model/2)embedding_sin = torch.sin(out)embedding_cos = torch.cos(out)pe[:, 0::2] = embedding_sin # 奇数位置设置为sinpe[:, 1::2] = embedding_cos # 偶数位置设置为cosreturn peSinPositionEncoding(d_model=4, max_sequence_length=10, base=10000).forward()
(二)手撕 可学习位置编码 算法
class TrainablePositionEncoding(nn.Module):def __init__(self, max_sequence_length, d_model):super().__init__()self.max_sequence_length = max_sequence_lengthself.d_model = d_modeldef forward(self):pe = nn.Embedding(self.max_sequence_length, self.d_model)nn.init.constant(pe.weight, 0.)return pe
(三)手撕 相对位置编码 算法
class RelativePosition(nn.Module):def __init__(self, num_units, max_relative_position):super().__init__()self.num_units = num_unitsself.max_relative_position = max_relative_positionself.embeddings_table = nn.Parameter(torch.Tensor(max_relative_position * 2 + 1, num_units))nn.init.xavier_uniform_(self.embeddings_table)def forward(self, length_q, length_k):range_vec_q = torch.arange(length_q)range_vec_k = torch.arange(length_k)distance_mat = range_vec_k[None, :] - range_vec_q[:, None]distance_mat_clipped = torch.clamp(distance_mat, -self.max_relative_position, self.max_relative_position)final_mat = distance_mat_clipped + self.max_relative_positionfinal_mat = torch.LongTensor(final_mat).cuda()embeddings = self.embeddings_table[final_mat].cuda()return embeddingsclass RelativeMultiHeadAttention(nn.Module):def __init__(self, d_model, n_heads, dropout=0.1, batch_size=6):"Take in model size and number of heads."super(RelativeMultiHeadAttention, self).__init__()self.d_model = d_modelself.n_heads = n_headsself.batch_size = batch_sizeassert d_model % n_heads == 0self.head_dim = d_model // n_headsself.linears = _get_clones(nn.Linear(d_model, d_model), 4)self.dropout = nn.Dropout(p=dropout)self.relative_position_k = RelativePosition(self.head_dim, max_relative_position=16)self.relative_position_v = RelativePosition(self.head_dim, max_relative_position=16)self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).cuda()def forward(self, query, key, value):# embedding# query, key, value = [batch_size, len, hid_dim]query, key, value = [l(x).view(self.batch_size, -1, self.d_model) for l, x inzip(self.linears, (query, key, value))]len_k = query.shape[1]len_q = query.shape[1]len_v = value.shape[1]# Self-Attention# r_q1, r_k1 = [batch_size, len, n_heads, head_dim]r_q1 = query.view(self.batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)r_k1 = key.view(self.batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)attn1 = torch.matmul(r_q1, r_k1.permute(0, 1, 3, 2))r_q2 = query.permute(1, 0, 2).contiguous().view(len_q, self.batch_size * self.n_heads, self.head_dim)r_k2 = self.relative_position_k(len_q, len_k)attn2 = torch.matmul(r_q2, r_k2.transpose(1, 2)).transpose(0, 1)attn2 = attn2.contiguous().view(self.batch_size, self.n_heads, len_q, len_k)attn = (attn1 + attn2) / self.scaleattn = self.dropout(torch.softmax(attn, dim=-1))# attn = [batch_size, n_heads, len, len]r_v1 = value.view(self.batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)weight1 = torch.matmul(attn, r_v1)r_v2 = self.relative_position_v(len_q, len_v)weight2 = attn.permute(2, 0, 1, 3).contiguous().view(len_q, self.batch_size * self.n_heads, len_k)weight2 = torch.matmul(weight2, r_v2)weight2 = weight2.transpose(0, 1).contiguous().view(self.batch_size, self.n_heads, len_q, self.head_dim)x = weight1 + weight2# x = [batch size, n heads, query len, head dim]x = x.permute(0, 2, 1, 3).contiguous()# x = [batch size, query len, n heads, head dim]x = x.view(self.batch_size * len_q, self.d_model)# x = [batch size * query len, hid dim]return self.linears[-1](x)
(四)手撕 Rope 算法(旋转位置编码)
import torch
import torch.nn as nn
import torch.nn.functional as F
import math# %%def sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, device):# (max_len, 1)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(-1)# (output_dim//2)ids = torch.arange(0, output_dim // 2, dtype=torch.float) # 即公式里的i, i的范围是 [0,d/2]theta = torch.pow(10000, -2 * ids / output_dim)# (max_len, output_dim//2)embeddings = position * theta # 即公式里的:pos / (10000^(2i/d))# (max_len, output_dim//2, 2)embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)# (bs, head, max_len, output_dim//2, 2)embeddings = embeddings.repeat((batch_size, nums_head, *([1] * len(embeddings.shape)))) # 在bs维度重复,其他维度都是1不重复# (bs, head, max_len, output_dim)# reshape后就是:偶数sin, 奇数cos了embeddings = torch.reshape(embeddings, (batch_size, nums_head, max_len, output_dim))embeddings = embeddings.to(device)return embeddings# %%
def RoPE(q, k):# q,k: (bs, head, max_len, output_dim)batch_size = q.shape[0]nums_head = q.shape[1]max_len = q.shape[2]output_dim = q.shape[-1]# (bs, head, max_len, output_dim)pos_emb = sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, q.device)# cos_pos,sin_pos: (bs, head, max_len, output_dim)# 看rope公式可知,相邻cos,sin之间是相同的,所以复制一遍。如(1,2,3)变成(1,1,2,2,3,3)cos_pos = pos_emb[..., 1::2].repeat_interleave(2, dim=-1) # 将奇数列信息抽取出来也就是cos 拿出来并复制sin_pos = pos_emb[..., ::2].repeat_interleave(2, dim=-1) # 将偶数列信息抽取出来也就是sin 拿出来并复制# q,k: (bs, head, max_len, output_dim)q2 = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1)q2 = q2.reshape(q.shape) # reshape后就是正负交替了# 更新qw, *对应位置相乘q = q * cos_pos + q2 * sin_posk2 = torch.stack([-k[..., 1::2], k[..., ::2]], dim=-1)k2 = k2.reshape(k.shape)# 更新kw, *对应位置相乘k = k * cos_pos + k2 * sin_posreturn q, k# %%
def attention(q, k, v, mask=None, dropout=None, use_RoPE=True):# q.shape: (bs, head, seq_len, dk)# k.shape: (bs, head, seq_len, dk)# v.shape: (bs, head, seq_len, dk)if use_RoPE:q, k = RoPE(q, k)d_k = k.size()[-1]att_logits = torch.matmul(q, k.transpose(-2, -1)) # (bs, head, seq_len, seq_len)att_logits /= math.sqrt(d_k)if mask is not None:att_logits = att_logits.masked_fill(mask == 0, -1e9) # mask掉为0的部分,设为无穷大att_scores = F.softmax(att_logits, dim=-1) # (bs, head, seq_len, seq_len)if dropout is not None:att_scores = dropout(att_scores)# (bs, head, seq_len, seq_len) * (bs, head, seq_len, dk) = (bs, head, seq_len, dk)return torch.matmul(att_scores, v), att_scoresif __name__ == '__main__':# (bs, head, seq_len, dk)q = torch.randn((8, 12, 10, 32))k = torch.randn((8, 12, 10, 32))v = torch.randn((8, 12, 10, 32))res, att_scores = attention(q, k, v, mask=None, dropout=None, use_RoPE=True)# (bs, head, seq_len, dk), (bs, head, seq_len, seq_len)print(res.shape, att_scores.shape)
相关文章:

【AIGC】大模型面试高频考点-位置编码篇
【AIGC】大模型面试高频考点-位置编码篇 (一)手撕 绝对位置编码 算法(二)手撕 可学习位置编码 算法(三)手撕 相对位置编码 算法(四)手撕 Rope 算法(旋转位置编码…...

如何使用 SQL 语句创建一个 MySQL 数据库的表,以及对应的 XML 文件和 Mapper 文件
文章目录 1、SQL 脚本语句2、XML 文件3、Mapper 文件4、启动 ServiceInit 文件5、DataService 文件6、ComplianceDBConfig 配置文件 这个方式通常是放在项目代码中,使用配置在项目的启动时创建表格,SQL 语句放到一个 XML 文件中。在Spring 项目启动时&am…...

Unity性能优化---动态网格组合(二)
在上一篇中,组合的是同一个材质球的网格,如果其中有不一样的材质球会发生什么?如下图: 将场景中的一个物体替换为不同的材质球 运行之后,就变成了相同的材质。 要实现组合不同材质的网格步骤如下: 在父物体…...

JVM学习《垃圾回收算法和垃圾回收器》
目录 1.垃圾回收算法 1.1 标记-清除算法 1.2 复制算法 1.3 标记-整理算法 1.4 分代收集算法 2.垃圾回收器 2.1 熟悉一下垃圾回收的一些名词 2.2 垃圾回收器有哪些? 2.3 Serial收集器 2.4 Parallel Scavenge收集器 2.5 ParNew收集器 2.6 CMS收集器 1.垃圾…...

GPS模块/SATES-ST91Z8LR:电路搭建;直接用电脑的USB转串口进行通讯;模组上报定位数据转换地图识别的坐标手动查询地图位置
从事嵌入式单片机的工作算是符合我个人兴趣爱好的,当面对一个新的芯片我即想把芯片尽快搞懂完成项目赚钱,也想着能够把自己遇到的坑和注意事项记录下来,即方便自己后面查阅也可以分享给大家,这是一种冲动,但是这个或许并不是原厂希望的,尽管这样有可能会牺牲一些时间也有哪天原…...

什么是TCP的三次握手
TCP(传输控制协议)的三次握手是一个用于在两个网络通信的计算机之间建立连接的过程。这个过程确保了双方都有能力接收和发送数据,并且初始化双方的序列号。以下是三次握手的详细步骤: 第一次握手(SYN)&…...

《Clustering Propagation for Universal Medical Image Segmentation》CVPR2024
摘要 这篇论文介绍了S2VNet,这是一个用于医学图像分割的通用框架,它通过切片到体积的传播(Slice-to-Volume propagation)来统一自动(AMIS)和交互式(IMIS)医学图像分割任务。S2VNet利…...

Linux ifconfig ip 命令详解
简介 ifconfig 和 ip 命令用于配置和显示 Linux 上的网络接口。虽然 ifconfig 是传统工具,但现在已被弃用并被提供更多功能的 ip 命令取代。 ifconfig 安装 sudo apt install net-toolssudo yum install net-tools查看所有活动的网络接口 ifconfig启动/激活网络…...

Vue3 对于echarts使用 v-show,导致显示不全,宽度仅100px,无法重新渲染的问题
参考链接:解决Echarts图表使用v-show,显示不全,宽度仅100px的问题_echarts v-show图表不全-CSDN博客 Vue3 echarts v-show无法重新渲染的问题_v-show echarts不渲染-CSDN博客 原因不多赘述了,大概就是v-show 本身是结构已经存在,当数据发生…...
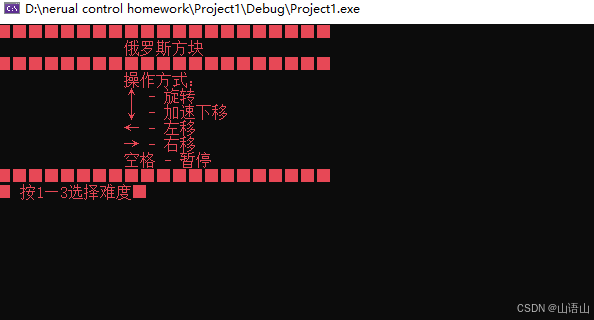
C++实现俄罗斯方块
俄罗斯方块 还记得俄罗斯方块吗?相信这是小时候我们每个人都喜欢玩的一个小游戏。顾名思义,俄罗斯方块自然是俄罗斯人发明的。这人叫阿列克谢帕基特诺夫。他设置这个游戏的规则是:由小方块组成的不同形状的板块陆续从屏幕上方落下来…...

鸿蒙分享:添加模块,修改app名称图标
新建公共模块common 在entry的oh-package.json5添加dependencies,引入common模块 "dependencies": {"common": "file:../common" } 修改app名称: common--src--resources--string.json 新增: {"name&q…...

扫描IP段内的使用的IP
扫描IP段内的使用的IP 方法一:命令行 命令行进入 for /L %i IN (1,1,254) DO ping -w 1 -n 1 192.168.3.%iarp -a方法二:python from scapy.all import ARP, Ether, srp import keyboarddef scan_network(ip_range):# 创建一个ARP请求包arp ARP(pds…...

【专题】虚拟存储器
前文提到的存储器管理方式有一个共同的特点,即它们都要求将一个作业全部装入内存后方能运行。 但有两种特殊情况: 有的作业很大,其所要求的内存空间超过了内存总容量,作业不能全部被装入内存,致使该作业无法运行&#…...

Python之爬虫入门--示例(2)
一、Requests库安装 可以使用命令提示符指令直接安装requests库使用 pip install requests 二、爬取JSON数据 (1)、点击网络 (2)、刷新网页 (3)、这里有一些数据类型,选择全部 (…...
)
5G CPE终端功能及性能评测(四)
5G CPE 功能性能评测 本文选取了几款在工业应用领域应用较多的5G CPE,对其功能和性能进行了对比评测。功能方面主要对比了网络接口数量,VPN功能 支持情况。以下测试为空口测试,测试结果受环境影响较大,性能仅供参考。总体看,高通X55芯片下行最优,速率稳定。 功能 对比CPE…...

人工智能驱动的骗局会模仿熟悉的声音
由于人工智能技术的进步,各种现代骗局变得越来越复杂。 这些骗局现在包括人工智能驱动的网络钓鱼技术,即使用人工智能模仿家人或朋友的声音和视频。 诈骗者使用来自社交媒体的内容来制作深度伪造内容,要求提供金钱或个人信息。个人应该通过…...

电子病历静态数据脱敏路径探索
一、引言 数据脱敏(Data Masking),屏蔽敏感数据,对某些敏感信息(比如patient_name、ip_no、ad、no、icd11、drug等等 )通过脱敏规则进行数据的变形,实现隐私数据的可靠保护。电子病历作为医疗领…...

混合云策略在安全领域受到青睐
Genetec 发布了《2025 年物理安全状况报告》,该报告根据超过 5,600 名该领域领导者(其中包括 100 多名来自澳大利亚和新西兰的领导者)的回应,揭示了物理安全运营的趋势。 报告发现,澳大利亚和新西兰的组织采用混合云策…...

Echarts使用平面方法绘制三维立体柱状图表
目录 一、准备工作 1.下载引入ECharts库 2.创建容器 二、绘制基本柱状 三、绘制立体柱状方法一 1.定义立方体形状 2.注册立方体形状 3.配置custom系列 4.设置数据 5.渲染图表 四、绘制立体柱状方法二 1.画前知识 2.计算坐标renderItem 函数 (1&#x…...
java-判断语句
题目一:选择练习1 657. 选择练习1 - AcWing题库 代码 import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner sc new Scanner(System.in);int a sc.nextInt(), b sc.nextInt();int c sc.nextInt(), d sc.nextInt();…...
)
保姆级教程:搞定EVE-NG客户端与SecureCRT/Wireshark的完美关联(附常见问题修复)
EVE-NG高阶工具链集成:SecureCRT与Wireshark深度调优指南 当网络工程师从基础实验迈入复杂拓扑模拟时,EVE-NG与专业工具链的协同工作能力直接决定实验效率。本文将深入解析SecureCRT会话管理与Wireshark抓包分析两大核心组件的集成优化方案,涵…...

chatgpt-web-midjourney-proxy的TypeScript类型系统:类型安全的AI应用开发
chatgpt-web-midjourney-proxy的TypeScript类型系统:类型安全的AI应用开发 在当今AI技术快速发展的时代,如何构建稳定可靠的AI应用成为开发者面临的重要挑战。chatgpt-web-midjourney-proxy项目通过精心设计的TypeScript类型系统,为开发者提供…...

从模型文件到孪生场景:一个Three.js三维模型管理系统的完整产品化思考
从技术原型到商业产品:构建Three.js数字孪生系统的全栈实践 在数字孪生技术快速渗透工业制造、智慧城市等领域的今天,如何将一个基于Three.js的模型展示Demo转化为真正具备商业价值的企业级管理系统?这个问题困扰着许多掌握前端3D技术的开发者…...

一键找回青春记忆:GetQzonehistory让QQ空间历史说说永久保存
一键找回青春记忆:GetQzonehistory让QQ空间历史说说永久保存 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 还在为那些年发过的QQ空间说说可能丢失而担忧吗?Get…...

HDR 图像的双层结构——元数据生成与 hdrDecompose/hdrCompose 完整解析
文章目录HDR 图到底怎么存的?三个核心操作的关系元数据生成代码详解HDR 分解与合成代码详解HdrMetadataType 四种类型对比像素格式与 HDR 类型对应关系StorageLink 串联四个页面的设计思路踩坑记录写在最后一直以来我以为 HDR 图就是"更亮的图"࿰…...

Ccursor安装使用
首先进入官文 https://cursor.com/下载,然后按照步骤进行安装,一般都是直接默认安装(修改软件位置的话可以修改下去,默认是在c盘,可能会后面用的多了造成卡顿),直到安装完成, 点击使…...

Seraphine:英雄联盟玩家的终极智能助手,5分钟快速上手教程
Seraphine:英雄联盟玩家的终极智能助手,5分钟快速上手教程 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾在英雄联盟对局中因为不了解队友对手的实力而输掉比赛?是…...

汽车质量管理体系的核心要素与持续改进之道
在当今竞争激烈的汽车制造业中,质量管理体系不仅是确保产品品质的基石,更是引领行业迈向智能制造未来的关键。作为制造业的核心,质量管理体系能够帮助企业在产品研发、生产制造和售后服务等环节发现并解决问题,提升产品质量和用户…...

别再只用labelme了!用ENVI 5.3的ROI工具给遥感影像打深度学习标签,保姆级避坑指南
遥感影像标注革命:ENVI ROI工具在深度学习标签制作中的专业实践 引言 在遥感影像分析与深度学习模型训练的工作流中,数据标注环节往往成为制约效率提升的关键瓶颈。传统标注工具如labelme虽然在小尺寸自然图像处理中表现出色,但当面对动辄数G…...
)
别再只会用vi了!openEuler 20.03 LTS下保姆级安装vim教程(附yum源配置)
从零配置到高效编辑:openEuler系统vim全攻略 刚接触openEuler系统的开发者常会遇到一个尴尬场景:习惯性输入vim命令后,终端却冷冷地回应"command not found"。这个看似简单的问题背后,其实涉及Linux发行版的软件管理机制…...