Hive 分桶表的创建与填充操作详解
Hive 分桶表的创建与填充操作详解
在 Hive 数据处理中,分桶表是一个极具实用价值的功能,它相较于非分桶表能够实现更高效的采样,并且后续还可能支持诸如 Map 端连接等节省时间的操作。不过,值得注意的是,在向表写入数据时,创建表时指定的分桶规则并不会被强制实施,所以有可能出现表的元数据所宣称的属性与表实际的数据布局不一致的情况,而这显然是我们要尽力避免的。接下来,详细介绍如何正确地创建和填充分桶表,以及在不同 Hive 版本中的相关要点。
一、创建分桶表
首先来看创建分桶表的操作,示例代码如下:
CREATE TABLE user_info_bucketed(user_id BIGINT, firstname STRING, lastname STRING)
COMMENT 'A bucketed copy of user_info'
PARTITIONED BY(ds STRING)
CLUSTERED BY(user_id) INTO 256 BUCKETS;
在上述创建表的语句中,我们通过 CLUSTERED BY 子句指定了基于 user_id 列来进行分桶,并且将其划分为 256 个桶。这里可以根据实际业务需求和数据量等因素灵活选择分桶的列以及桶的数量。
二、填充分桶表
(一)Hive 0.x 和 1.x 版本
对于 Hive 0.x 和 1.x 版本,填充分桶表需要执行以下操作:
set hive.enforce.bucketing = true; -- (注意:在 Hive 2.x 及以后版本不需要此设置)
FROM user_id
INSERT OVERWRITE TABLE user_info_bucketed
PARTITION (ds='2009-02-25')
SELECT userid, firstname, lastname WHERE ds='2009-02-25';
在这些早期版本中,命令 set hive.enforce.bucketing = true; 起着关键作用,它允许 Hive 根据表的定义自动选择正确的 Reducer 数量以及按照聚类列(Cluster By 列)来进行相应操作。否则的话,就需要手动设置 Reducer 的数量与桶的数量一致,比如通过 set mapred.reduce.tasks = 256; 这样的语句来设置,并且在 SELECT 语句中要有 CLUSTER BY... 子句。
(二)Hive 2.x 版本及之后
从 Hive 2.x 版本开始,情况有所变化,不再需要设置 hive.enforce.bucketing = true 这条命令了。Hive 在处理分桶表填充时更加智能和自动化,会按照创建表时定义的分桶规则自动进行相应的操作,大大简化了操作流程,降低了因配置不当导致分桶错误的风险。
例如,我们依然可以使用类似下面这样简洁的语句来向分桶表插入数据:
FROM user_id
INSERT OVERWRITE TABLE user_info_bucketed
PARTITION (ds='2009-02-25')
SELECT userid, firstname, lastname WHERE ds='2009-02-25';
(三)Hive 3.X 版本
在 Hive 3.X 版本中,除了延续 2.x 版本在分桶表填充方面的便利性和自动化特点之外,在性能优化以及与其他功能的兼容性等方面又有了进一步提升。
例如,在与一些新的存储格式或者查询优化特性结合使用时,分桶表能够更好地发挥其优势。在大数据集的处理场景下,如果使用了 Hive 3.X 版本的分桶表,配合分区表以及一些新的查询优化器改进,能够更高效地实现数据的筛选、聚合等操作,进一步提高数据处理的速度和效率。
同时,Hive 3.X 版本在处理分桶表数据时,对于数据的一致性和准确性校验也更加严格,能够更好地避免因数据写入、读取过程中的异常情况(如网络波动、硬件故障等临时因素导致的数据部分写入失败等)而引起的分桶数据错乱问题,确保分桶表的数据质量始终保持在一个较高的水平。
三、数据在桶中的分配方式
了解完不同版本下分桶表的填充操作后,我们再来深入探讨一下 Hive 是如何将数据行分配到各个桶中的呢?一般来说,桶编号是由表达式 hash_function(bucketing_column) mod num_buckets 来确定的(其中还涉及 0x7FFFFFFF,但这个不是特别重要)。哈希函数(hash_function)取决于分桶列的数据类型。
- 整型(int)情况:对于整型数据,比较简单,例如
hash_int(i) == i。举个例子,如果user_id是整型,并且有 10 个桶,那么所有以 0 结尾的user_id值会被分配到桶 1,以 1 结尾的会被分配到桶 2,依此类推。 - 其他数据类型情况:对于其他数据类型,情况就稍微复杂一些了。特别是
BIGINT类型的哈希值与它本身的值是不一样的。而对于字符串(STRING)或者复杂数据类型,其哈希值是根据该值派生出来的一个数字,但通常不是人类容易识别的形式。比如,如果user_id是字符串类型,那么在桶 1 中的user_id值大概率不会是以 0 结尾的。总体而言,基于哈希来分配数据行能使数据在各个桶中均匀分布,保证了分桶表在后续进行各类操作(如采样、连接等)时的高效性和合理性。
四、可能出现的问题
在分桶表的使用过程中,即使是在 Hive 不断升级优化的各个版本下,也还是存在一些可能导致问题出现的情况需要我们留意。
只要按照上述不同版本对应的语法和规则进行操作,分桶表一般都能被正确填充。但如果在插入数据和读取数据时,分桶列的数据类型不一致,或者手动按照与表定义不同的值进行聚类(CLUSTER BY)操作,就可能会出现问题。另外,在 Hive 3.X 版本中,虽然对数据一致性等方面有更好的保障,但如果使用了一些自定义的存储插件或者与第三方工具集成时,若不遵循 Hive 3.X 的相关规范和接口要求,也有可能引发分桶数据的兼容性问题,例如数据无法正确识别分桶结构、无法高效地进行基于分桶的查询操作等情况。
相关文章:

Hive 分桶表的创建与填充操作详解
Hive 分桶表的创建与填充操作详解 在 Hive 数据处理中,分桶表是一个极具实用价值的功能,它相较于非分桶表能够实现更高效的采样,并且后续还可能支持诸如 Map 端连接等节省时间的操作。不过,值得注意的是,在向表写入数…...

[小白系列]Ubuntu安装教程-安装prometheus和Grafana
Docker安装prometheus 拉取镜像 docker pull prom/prometheus 配置文件prometheus.yml 在/data/prometheus/建立prometheus.yml配置文件。(/data/prometheus/可根据自己需要调整) global:scrape_interval: 15s # By default, scrape targets ev…...

Flask使用长连接
Flask使用flask_socketio实现websocket Python中的单例模式 在HTTP通信中,连接复用(Connection Reuse)是一个重要的概念,它允许客户端和服务器在同一个TCP连接上发送和接收多个HTTP请求/响应,而不是为每个新的请求/响…...

数据分析思维案例:游戏评分低,怎么办?
【面试题】 某款手游在应用市场评分相比同类型游戏处于劣势。 请分析可能的原因并给出相关建议。 【分析思路】 一、明确问题 1. 明确业务指标 定义:应用市场评分一般指某一应用在某个应用市场上线以来的总体平均评分。 除“总体平均评分”以外,部分应用…...

【学习总结|DAY012】Javabean书写练习
一、主要代码 public class Phone {public Phone() {}public Phone(String brand, int price, String color) {this.brand brand;this.price price;this.color color;}String brand;int price;String color;public String getBrand() {return brand;}public void setBrand(…...

Mac环境下brew安装LNMP
安装不同版本PHP 在Mac环境下同时运行多个版本的PHP,同Linux环境一样,都是将后台运行的php-fpm设置为不同的端口号,下面将已php7.2 和 php7.4为例 添加 tap 目的:homebrew仅保留最近的php版本,可能没有你需要的版本…...

openEuler 知:安装系统
文章目录 前言图形化安装文本方式安装 前言 本文只介绍安装过程中需要特别注意的地方,常规的内容需要参考其它文档。 图形化安装 自定义分区: 说明:anaconda 默认分区,在 OSNAME.conf 中进行了配置,openEuler 默认根…...

Zephyr 入门-设备树与设备驱动模型
学习链接:https://www.bilibili.com/video/BV1L94y1F7qS/?spm_id_from333.337.search-card.all.click&vd_source031c58084cf824f3b16987292f60ed3c 讲解清晰,逻辑清楚。 1. 设备树概述(语法,如何配置硬件,c代码如…...

点云标注软件SUSTechPOINTS的安装和使用,自测win10和ubuntu20.04下都可以用
点云标注软件SUSTechPOINTS的安装和使用 github项目源码:https://github.com/naurril/SUSTechPOINTS gitee源码以及使用教程:https://gitee.com/cuge1995/SUSTechPOINTS 首先拉取源码 git clone https://github.com/naurril/SUSTechPOINTS最好是在cond…...

etcd资源超额
集群内apiserver一直重启,重启kubelet服务后查看日志发现一下报错: Error from server: etcdserver: mvcc: database space exceeded 报错原因: etcd服务未设置自动压缩参数(auto-compact) etcd 默认不会自动 compa…...
AndroidStudio-常见界面控件
一、Button package com.example.review01import androidx.appcompat.app.AppCompatActivity import android.os.Bundle import android.widget.Button import android.widget.TextViewclass Review01Activity : AppCompatActivity() {override fun onCreate(savedInstanceStat…...

网络协议(TCP/IP模型)
目录 网络初识 网络协议 协议分层 协议拆分 分层 协议分层的优势 1.封装效果 2.解耦合 TCP/IP五层模型 协议之间配合工作(详解) 网络初识 网络核心概念: 局域网:若干电脑连接在一起,通过路由器进行组网。 …...

python 清华pip镜像源报HTTP error 403
报错信息 ERROR: HTTP error 403 while getting https://mirrors.tuna.tsinghua.edu.cn/pypi/web/packages/52/79/a64937a2185b91a96cc5406e3ea58120980c725543d047e112fb3084a972/fake_useragent-2.0.0-py3-none-any.whl (from https://mirrors.tuna.tsinghua.edu.cn/pypi/we…...

swift 屏幕录制
步骤 1:导入 ReplayKit import ReplayKit步骤 2:开始录屏 let screenRecorder RPScreenRecorder.shared() // 麦克风或系统音频 screenRecorder.isMicrophoneEnabled truefunc startRecording() {guard screenRecorder.isAvailable else {print(&quo…...
对计算机网络中的多个设备进行时间同步)
通过精密时间协议(PTP)对计算机网络中的多个设备进行时间同步
PTP 模块 - 使用教程 目录 PTP 模块 - 使用教程简介第 1 步:为主时钟创建一个 PTP 时钟实例第 2 步:添加 PTP 端口第 3 步:查询 PTP 时钟或 PTP 端口的状态第 4 步:清除 FAULTY 状态第 5 步:为 PTP 事件安装处理程序第…...

Docker 安装系列
Centos8 安装Docker Docker安装mysql8.0 Docker安装稳定版本nginx-1.26.2 Docker 安装最新版本 Jenkins Docker Redis Docker 安装 eclipse-mosquitto Docker mongo:5.0 Docker 安装 Redis的完全体版本RedisMod docker pull elasticsearch:8.0.0 docker 安装nacos v2.…...
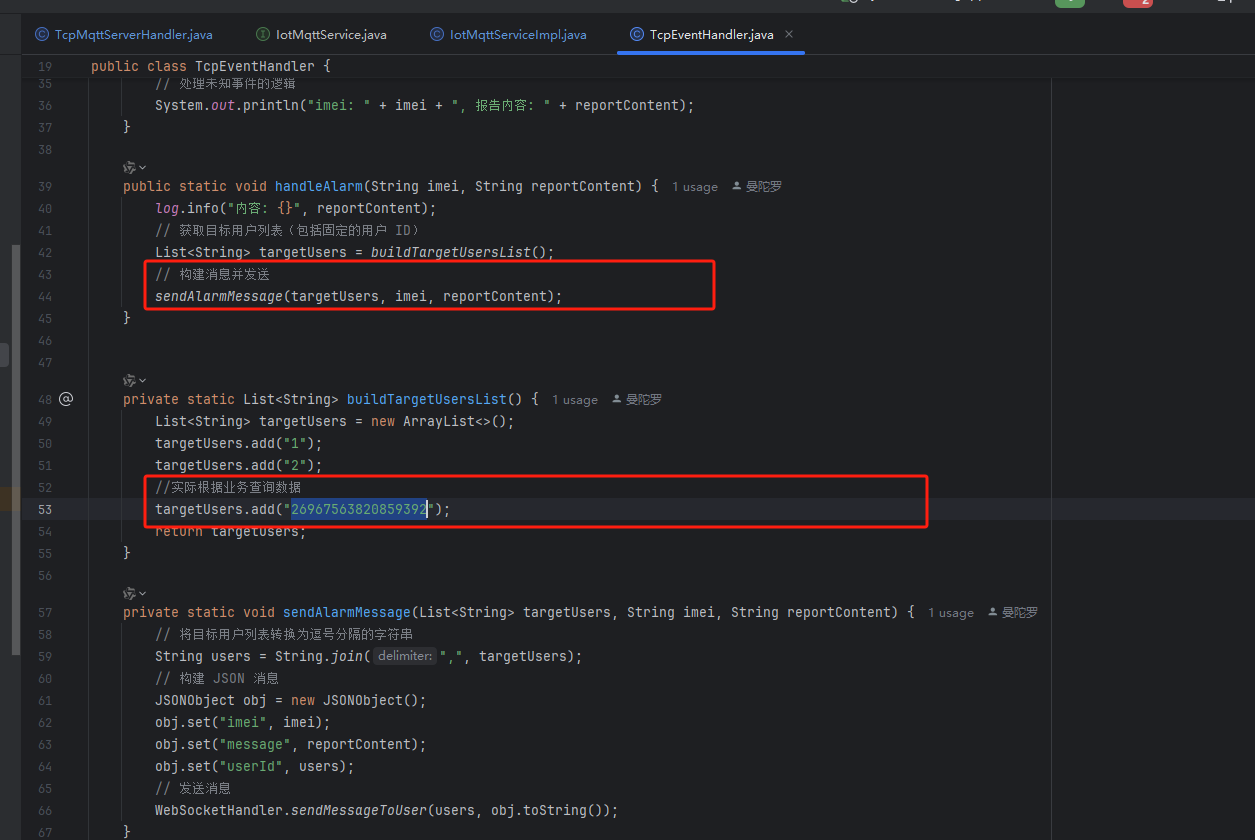
使用springboot-3.4.1搭建一个netty服务并且WebSocket消息通知(适用于设备直连操作,以及回复操作)
引入最新版本 <!--websocket--> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dependency>启动类加入 //netty 协议服务端口启动 NettyTcpHandler.start()…...

4. 设计模式分类
4.1 创建型模式 这类模式提供创建对象的机制,能够提升已有代码的灵活性和可复用性。 序 号 类 型 业务场景 实现要点 1 工 厂 方 法 多种类型商品不同接口,统一发奖服 务搭建场景 定义一个创建对象的接口,让其子类自 己决定实例化哪一个工厂类,工厂模式 使其创建过程延迟…...
Hive分区值的插入
对于Hive分区表,在我们插入数据的时候需要指定对应的分区值,而这里就会涉及很多种情况。比如静态分区插入、动态分区插入、提供的分区值和分区字段类型不一致,或者提供的分区值是NULL的情况,下面我们依次来展现下不同情况下的表现…...

【多个图片合并成PDF】
因工作安排,小编最近参加了几场学术会议,被多名业界大佬的汇报所震撼。当然也不是白来的,好东西要留存下来回来分享给科室。因此,小编变成了幻灯片专职摄影师,参会的同时对着大牛的PPT就是一顿咔咔咔。回来后,面对手机里数百张照片却犯了难,就这样一张张发到群里么?还是…...

[开源] 护理语音医嘱转换系统:面向移动护理终端的结构化记录工具,自动解析床号、操作、参数与通知状态
本项目是一个专为临床一线护士设计的轻量级命令行工具,解决移动护理终端中语音描述转结构化医嘱记录的断点问题。我们不对接医院HIS或EMR系统,也不要求部署服务端,而是以本地可执行方式嵌入护士日常操作流:护士口述「14床测血压&a…...

高速串行通信信号抖动关键技术【附模型】
✨ 长期致力于串行通信、抖动、抖动分析、时钟恢复、均衡研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于有界不相关抖动注入的发送端信号生成模型…...

VIGOR:跨越“一对一”检索的理想假设,面向真实场景的跨视角地理定位数据集
一、数据集背景与开创性意义 VIGOR (Cross-View Image Geo-localization beyond One-to-one Retrieval) 是一个面向真实世界应用的全新大规模跨视角图像地理定位基准数据集,由 Sijie Zhu, Taojiannan Yang 和 Chen Chen 提出,相关论文发表于 CVPR 2021。…...

财经类大学生考什么证书?2026年最新考证指南与含金量解析
每到开学季或者寒暑假,总有不少财经专业的同学私下问我:“现在的就业环境这么卷,我是不是该把能考的证都考了?” 看着大家手里厚厚的备考资料和焦虑的眼神,我特别能理解这种心情。毕竟在财经这个圈子里,证书…...
选购指南)
来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南
# 来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南来姨妈不舒适有没有补充营养的经期产品推荐?这是14-40岁女性高频搜索的真实困惑。传统红糖水、热饮或普通果汁难以兼顾舒缓不适与科学补养,而市面多…...

座机号码认证支持哪些机型?固话企业认证覆盖华为/小米/OPPO/vivo等手机
很多做业务的朋友都有这种体会:好不容易联系到一个精准意向客户,电话拨过去,还没等开口,对方直接挂断。更有甚者,手机屏幕上赫然跳出“疑似推销”四个大字。现在的职场沟通,信任成本高得离谱。如果你还指望…...

避开这3个坑,你的SAR影像预处理效率翻倍:ENVI SARscape实战心得
避开这3个坑,你的SAR影像预处理效率翻倍:ENVI SARscape实战心得 在遥感数据处理领域,SAR影像因其全天候、全天时的独特优势,已成为地质灾害监测、海洋观测等领域不可或缺的数据源。然而,许多从业者在初次接触ENVI SARs…...

从项目实战出发:如何用AVL Cruise 2019与MATLAB/Simulink完成一个完整的DLL联合仿真流程?
从项目实战出发:如何用AVL Cruise 2019与MATLAB/Simulink完成一个完整的DLL联合仿真流程? 在汽车工程领域,系统级仿真已成为开发流程中不可或缺的一环。当我们需要评估整车动力系统性能时,AVL Cruise作为专业车辆仿真软件…...
)
告别BurpSuite自带Intruder的龟速:用Turbo Intruder插件30倍速爆破验证码(附Python脚本)
突破传统限制:Turbo Intruder在验证码爆破中的高效实践 在渗透测试和安全评估工作中,验证码爆破是一个常见但极具挑战性的任务。传统的BurpSuite Intruder模块虽然功能强大,但在处理高并发请求时往往显得力不从心,速度成为制约效率…...

【免费下载】 MATLAB 3D 极坐标绘图示例:天线三维方向图【matlab下载】
MATLAB 3D 极坐标绘图示例:天线三维方向图 项目介绍 在科学计算和工程设计领域,MATLAB一直是数据可视化和仿真的强大工具。然而,当涉及到在三维空间中使用极坐标系统进行绘图时,MATLAB的标准绘图函数如surf和mesh就显得力不从心。…...