Hive 窗口函数与分析函数深度解析:开启大数据分析的新维度
Hive 窗口函数与分析函数深度解析:开启大数据分析的新维度
在当今大数据蓬勃发展的时代,Hive 作为一款强大的数据仓库工具,其窗口函数和分析函数犹如一把把精巧的手术刀,助力数据分析师们精准地剖析海量数据,挖掘出深藏其中的价值宝藏。本文将带领大家深入探索 Hive QL 中这些神奇函数的奥秘,从版本演进、功能特性到丰富多样的实际应用示例,全方位地呈现它们在大数据处理领域的卓越魅力。
一、版本回溯与知识宝库指引
Hive 窗口函数和分析函数的辉煌篇章始于 Hive 版本 0.11 的历史性登场。这一里程碑式的升级为数据处理带来了全新的范式转变。若您渴望深入探究其技术细节与设计精髓,“Windowing Specifications in HQL”(紧密依附于 HIVE - 4197)犹如一座知识的金矿,蕴含着无尽的智慧结晶。与此同时,HIVE - 896 则像一位贴心的向导,不仅提供了丰富的示例资源,其初始评论区中的早期文档链接更是为我们打开了一扇追溯历史的窗口,让我们得以见证这些函数从孕育到诞生的全过程,深刻理解其发展脉络与设计初衷。
二、函数家族大揭秘:功能特性全解析
(一)窗口函数:数据洞察的多面手
- LEAD 函数:前瞻数据的导航仪
LEAD 函数宛如一位目光长远的数据探险家,它赋予我们窥视未来数据行的神奇能力。在实际业务场景中,想象一下我们正在分析电商平台的用户购买行为数据。以订单时间为序,通过 LEAD 函数,我们能够轻松查看用户下一次购买商品的类别,从而精准预测用户的消费趋势,提前布局个性化推荐策略,为用户提供贴心的购物体验,同时也为商家挖掘潜在的销售增长点。当我们未明确指定领先行数时,它默认仅向前眺望一行,恰似在时间长河中迈出一小步,却能为我们带回珍贵的未来信息。然而,当它的探索之旅超出了窗口的边界,如同勇敢的航海家驶入未知的深海,便会返回null值,提醒我们数据的尽头已近。 - LAG 函数:回溯数据的时光机
与 LEAD 函数遥相呼应,LAG 函数则是一台能够带我们穿越回过去的时光机。在金融领域的数据分析中,比如分析股票价格走势时,借助 LAG 函数,我们可以获取前一交易日的股价信息,通过对比相邻交易日的股价波动,计算涨跌幅、移动平均线等关键指标,进而洞察股价变化的趋势与规律,为投资者提供科学的决策依据。若未指定滞后行数,它也会贴心地为我们带回前一行的数据,让我们在数据的时光隧道中稳步回溯。一旦超出窗口的起始范围,同样会以null值警示我们已抵达数据的源头。 - FIRST_VALUE 函数:分组数据的先锋旗手
FIRST_VALUE 函数犹如在分组数据海洋中竖起的一面先锋旗帜,标识出每组数据的起始特征。在日志数据分析中,假设我们按照用户会话 ID 对日志进行分组,想要获取每个会话的首次访问页面,FIRST_VALUE 函数便能精准地完成这一使命。通过设置第二个可选参数为true,它还能巧妙地跳过null值,确保我们获取到的首个有效数据点,为后续的数据分析奠定坚实的基础,如同在茫茫数据海洋中找到了可靠的灯塔。 - LAST_VALUE 函数:分组数据的收官之笔
LAST_VALUE 函数则是为分组数据画上完美句号的艺术家。在销售数据分析中,若按照销售区域对销售订单进行分组,我们可以利用 LAST_VALUE 函数获取每个区域最后一笔订单的金额、时间等关键信息,从而分析不同区域销售活动的收尾情况,评估销售策略在不同区域的长期效果,为下一轮销售计划的制定提供有力的参考依据,如同在一场盛大的商业演出中,捕捉到最后一个精彩的落幕瞬间。
(二)OVER 子句:数据聚合的魔法舞台
- 标准聚合函数与 OVER 子句的梦幻联动
COUNT、SUM、MIN、MAX、AVG这些耳熟能详的标准聚合函数,在与OVER子句携手之后,仿佛被赋予了全新的生命力,摇身一变成为数据聚合的魔法大师。以电商订单数据为例,我们可以使用SUM函数结合OVER子句,按照用户 ID 进行分区,轻松计算出每个用户的历史订单总金额,为用户价值评估提供直观的量化指标;或者运用AVG函数,在按照产品类别分区的基础上,计算出各类产品的平均销售价格,帮助商家精准把握市场价格定位,制定合理的价格策略。 - PARTITION BY 与 ORDER BY:构建有序的数据分区世界
PARTITION BY语句如同一位严谨的建筑师,精心构建起数据的分区大厦,而ORDER BY则是大厦内的导航系统,为数据赋予了明确的顺序。在社交媒体数据分析中,我们可以依据用户的注册时间进行分区,并按照用户的活跃度(如发布内容数量、点赞评论数量等)进行排序,这样一来,在每个分区内,数据都按照活跃度有序排列。借助OVER子句,我们能够在这个有序的分区世界中,针对不同活跃度层次的用户群体进行深入分析,例如计算每个分区内活跃度前 10% 的用户的平均互动率,为精准营销和用户运营提供极具价值的洞察。 - 窗口规范:定制化的数据视野窗口
窗口规范则像是为我们的数据视野量身定制的一扇扇窗户,通过不同的格式设置,我们可以灵活地调整看到的数据范围。例如,在物流配送数据分析中,对于订单配送时间数据,我们可以设定(ROWS | RANGE) BETWEEN 3 PRECEDING AND CURRENT ROW的窗口规范,这样就能聚焦于当前订单及其前三个订单的配送时间信息,计算平均配送时长的滚动变化趋势,及时发现配送效率的波动情况并采取相应的优化措施。当指定了ORDER BY但缺少WINDOW子句时,默认的RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW窗口规范就像开启了一扇全景天窗,让我们能够纵览从数据起始点到当前行的所有数据信息;而若ORDER BY和WINDOW子句都缺失,ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING则为我们呈现出一幅无边界的数据画卷,涵盖了整个数据集的全貌。
需要特别注意的是,OVER 子句在支持一些函数时存在着特定的限制与微妙之处。排名函数(Rank、NTile、DenseRank、CumeDist、PercentRank)以及 Lead 和 Lag 函数本身在与窗口搭配使用时,就像在复杂的舞蹈中遵循着特定的舞步规则,需要我们深入理解并谨慎运用,以免在数据处理的舞台上出现意外的失误(参考 HIVE - 4797)。
(三)分析函数:数据排名与分布的智慧导师
RANK、ROW_NUMBER、DENSE_RANK、CUME_DIST、PERCENT_RANK、NTILE 这些分析函数宛如一群智慧的导师,从不同的角度为我们解读数据的排名与分布奥秘。在学生成绩数据分析中,RANK 函数能够清晰地为每个学生在班级中的成绩排名定位,让我们一目了然地看出学生的相对位置;DENSE_RANK 函数则在排名时避免了名次的跳跃,为成绩相近的学生提供更合理的排名呈现,有助于更细致地评估学生的学业水平层次;CUME_DIST 函数可以计算出每个学生成绩在班级中的累积分布比例,帮助教师了解成绩的整体分布情况,判断教学效果是否呈现正态分布;PERCENT_RANK 函数进一步将排名转换为百分比形式,为跨班级、跨年级的成绩比较提供了统一的标准尺度;NTILE 函数则像一位公平的分配者,将数据按照指定的份数进行分桶,例如将学生按照成绩均匀地划分到高、中、低三个能力组,为分层教学和个性化辅导提供了有力的支持。
(四)Distinct 支持:数据去重的精准利器
在 Hive 2.1.0 及之后版本(参考 HIVE - 9534),聚合函数中的 DISTINCT 操作如同一把精准的手术刀,在数据的海洋中精准地剔除重复元素。以电商用户行为分析为例,我们可能想要统计每个用户在一段时间内访问过的不同商品类别数量。通过 COUNT(DISTINCT a) OVER (PARTITION BY c) 语句,我们可以按照用户 ID(列 c)进行分区,然后对每个用户访问的商品类别(列 a)进行去重计数,从而清晰地了解每个用户的兴趣广度和多样性。在早期实现中,出于对性能这一数据处理高速公路通行效率的考量,分区子句里暂时无法容纳 ORDER BY 或窗口规范这位“旅伴”。然而,随着 Hive 技术的不断演进,到了 Hive 2.2.0 版本(参考 HIVE - 13453),ORDER BY 和窗口规范终于可以与 DISTINCT 操作携手同行,为我们提供更强大、更灵活的去重计数功能,例如 COUNT(DISTINCT a) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING),让我们能够在一个动态变化的窗口范围内对去重数据进行精细的统计分析,满足日益复杂的业务需求。
此外,自 Hive 2.1.0 及后续版本(参考 HIVE - 13475),OVER 子句内引用聚合函数的功能如同一座新搭建的桥梁,连接起了更多数据处理的可能性。例如,在企业销售数据分析中,我们可以通过 SELECT rank() OVER (ORDER BY sum(b)) FROM T GROUP BY a; 语句,先按照产品类别(列 a)进行分组,然后在每个分组内计算销售金额(列 b)的总和,并基于这些总和进行排名。这一功能为我们在多维度数据综合分析的复杂迷宫中开辟了一条新的通道,让我们能够更深入地挖掘数据之间的内在联系和潜在规律。
三、实战演练:示例代码全解析
(一)PARTITION BY 实战场景
- 单分区列无 ORDER BY 和窗口规范:基础分区统计
SELECT a, COUNT(b) OVER (PARTITION BY c)
FROM T;
在这个简洁而强大的示例中,我们以列 c 为分区依据,对表 T 中的数据进行划分。就如同将一个庞大的数据集按照某种特定的属性(例如地区、部门等)切割成多个相对独立的子集,然后在每个子集中统计列 b 的数量。在实际业务中,假设 T 是一张员工信息表,c 表示部门,b 表示员工的项目经验数量,那么这个查询就能快速告诉我们每个部门内员工项目经验数量的总和,为部门之间的人才资源对比提供了直观的数据支持。
2. 双分区列无 ORDER BY 和窗口规范:多维度分区细化
SELECT a, COUNT(b) OVER (PARTITION BY c, d)
FROM T;
此示例进一步拓展了分区的维度,通过列 c 和 d 两个维度对数据进行更为精细的划分。例如,在电商订单数据中,如果 c 表示订单的发货城市,d 表示订单的收货城市,那么这个查询就可以统计出从每个发货城市到每个收货城市的订单数量,帮助电商企业深入了解物流配送的地域流向和需求分布,优化物流网络布局和资源分配。
3. 单分区列单 ORDER BY 无窗口规范:有序分区聚合起步
SELECT a, SUM(b) OVER (PARTITION BY c ORDER BY d)
FROM T;
这里在分区的基础上引入了排序机制,按照列 c 分区后,再依据列 d 的顺序对数据进行组织。以在线教育课程学习数据为例,如果 c 表示课程类别,d 表示学生的学习时间顺序,那么这个查询可以计算出每个课程类别下,按照学习时间顺序累计的学习时长总和,有助于课程开发者分析不同课程的学习进度和学生参与度变化趋势,为课程优化和教学策略调整提供依据。
4. 双分区列双 ORDER BY 无窗口规范:复杂有序分区聚合
SELECT a, SUM(b) OVER (PARTITION BY c, d ORDER BY e, f)
FROM T;
此查询在多维度分区的基础上,结合了多列排序,构建了一个更为复杂而精细的数据处理场景。在金融交易数据分析中,如果 c 表示交易的市场板块,d 表示交易的账户类型,e 表示交易时间,f 表示交易金额大小顺序,那么这个查询能够计算出在每个市场板块和账户类型的组合下,按照交易时间和金额顺序累计的交易总量,为金融机构深入分析不同市场和客户群体的交易行为模式提供了强大的工具。
5. 带分区、ORDER BY 和窗口规范:灵活窗口分区聚合
SELECT a, SUM(b) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM T;
SELECT a, AVG(b) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
FROM T;
SELECT a, AVG(b) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN 3 PRECEDING AND 3 FOLLOWING)
FROM T;
SELECT a, AVG(b) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
FROM T;
这些示例展示了如何通过灵活调整窗口规范,在分区和排序的基础上实现多样化的聚合计算。以社交媒体用户互动数据为例,如果 c 表示用户所在的社交群组,d 表示用户的注册时间顺序,第一个查询可以计算出每个社交群组内,从最早注册的用户到当前用户的互动总量(如点赞、评论数量总和);第二个查询能够计算出当前用户及其前三个注册用户的平均互动频率;第三个查询则聚焦于当前用户及其前后三个注册用户的互动频率平均值,用于分析局部用户群体的互动活跃度;第四个查询可以获取从当前用户到最新注册用户的平均互动情况,为评估社交群组的互动发展趋势提供了多维度的视角。
6. 单查询多 OVER 子句:多元聚合并行出击
SELECT a,COUNT(b) OVER (PARTITION BY c),SUM(b) OVER (PARTITION BY c)
FROM T;
在这个查询中,我们同时运用了两个 OVER 子句,分别进行计数和求和操作。这就好比在一次数据探索之旅中,派遣了两支不同任务的探险队,一支负责统计每个分区内的元素数量,另一支负责计算分区内数据的总和。例如在企业库存管理数据分析中,如果 c 表示仓库地点,a 表示库存商品类别,b 表示库存商品数量,这个查询可以一次性获取每个仓库地点的商品类别数量以及库存总量,为库存调配和管理决策提供全面的数据支持。
7. 别名使用:数据结果清晰标识
SELECT a,COUNT(b) OVER (PARTITION BY c) AS b_count,SUM(b) OVER (PARTITION BY c) b_sum
FROM T;
通过使用别名,我们为基于窗口计算的结果列赋予了清晰易懂的名称。这就像在复杂的数据迷宫中为每个出口都贴上了明确的标识牌,方便我们在后续的数据处理和分析中快速定位和理解这些结果。无论是在生成报表还是在与其他数据处理步骤进行对接时,别名都能极大地提高数据的可读性和可操作性。
(二)WINDOW 子句实战应用
SELECT a, SUM(b) OVER w
FROM T
WINDOW w AS (PARTITION BY c ORDER BY d ROWS UNBOUNDED PRECEDING);
在这个示例中,WINDOW 子句将窗口规范单独定义,然后在 OVER 子句中引用。这就像是将数据处理的规则和流程进行了模块化封装,提高了代码的可维护性和复用性。在大型数据处理项目中,如果多个查询都需要使用相同的窗口规范,通过这种方式,我们只需定义一次 WINDOW 子句,然后在各个查询中直接引用即可,避免了重复编写相同的窗口定义代码,减少了出错的可能性,同时也使得代码结构更加清晰简洁,易于理解和优化。
(三)LEAD 和 LAG 函数实战演练
- LEAD 默认用法:未来数据初探
SELECT a, LEAD(a) OVER (PARTITION BY b ORDER BY C)
FROM T;
以电信用户通话记录数据为例,如果 b 表示用户电话号码,C 表示通话时间顺序,a 表示通话时长,这个查询可以查看每个用户下一次通话的时长情况。通过分析这些数据,电信运营商可以洞察用户的通话行为模式,例如是否存在长时间通话后短时间内再次通话的规律,为套餐设计和网络资源优化提供参考依据。
2. LAG 指定滞后:回溯历史数据洞察
SELECT a, LAG(a, 3, 0) OVER (PARTITION BY b ORDER BY C)
FROM T;
同样在电信用户通话记录数据中,这个查询可以获取每个用户前三次通话的时长信息(若不足三次则以 0 填充)。通过对比当前通话时长与前三次通话时长,能够分析用户通话时长的变化趋势,比如是否存在通话时长逐渐增加或减少的情况,进而为精准营销提供支持。例如,对于通话时长持续增加的用户,可以推荐更适合长时间通话的套餐;对于通话时长明显减少的用户,可以推送一些优惠活动以刺激其通话需求。
(四)分区内去重计数实战示例
SELECT a, COUNT(distinct a) OVER (PARTITION BY b)
FROM T;
假设 T 是一张用户访问网站页面的日志表,b 表示用户 ID,a 表示用户访问的页面 URL。此查询能够统计出每个用户访问过的不同页面数量,从而了解用户的兴趣广度和多样性。对于互联网公司来说,可以根据用户的兴趣多样性来进行个性化推荐。例如,对于访问页面种类丰富的用户,可以推荐更多元化的内容,包括新闻、娱乐、科技等不同领域的信息;而对于访问页面较为单一的用户,则可以集中推荐其感兴趣领域的深度内容或相关产品,提高用户的参与度和转化率。
相关文章:

Hive 窗口函数与分析函数深度解析:开启大数据分析的新维度
Hive 窗口函数与分析函数深度解析:开启大数据分析的新维度 在当今大数据蓬勃发展的时代,Hive 作为一款强大的数据仓库工具,其窗口函数和分析函数犹如一把把精巧的手术刀,助力数据分析师们精准地剖析海量数据,挖掘出深…...

前端工程 Node 版本如何选择
1. Node 与 Npm 版本对应 这是一个必知必会的问题,尤其是对于维护那些老掉牙、一坨坨、非常大的有着长期历史的老破大工程。 1.1. package-lock.json 版本 首先你要会看项目的 package-lock.json 文件中的 lockfileVersion 版本号,这对于 NPM 安装来说…...
推荐在线Sql运行
SQL Fiddle 1、网址:SQL Fiddle - Online SQL Compiler for learning & practiceDiscover our free online SQL editor enhanced with AI to chat, explain, and generate code. Support SQL Server, MySQL, MariaDB, PostgreSQL, and SQLite.http://www.sqlfi…...

【数据结构】【线性表】特殊的线性表-字符串
目录 字符串的基本概念 字符串的三要素 字符串的基本概念 串的编码 串的实现及基本运算 顺序串的实现 串的静态数组实现 串的动态数组的实现 顺序存储的四种方案 链式串的实现 基本运算 方案三 方案一 字符串的基本概念 数据结构千千万,…...

app-1 App 逆向环境准备(mumu模拟器+magisk+LSPosed+算法助手+抓包(socksDroid+charles)+Frida环境搭建
一、前言 本篇是基于 mumu模拟器 进行环境配置记录。(真机的后面博客记录) 二、mumu模拟器magiskLSPosed算法助手 2.1、mumu模拟器 选择 mumu 模拟器,下载地址:https://mumu.163.com 安装完成后打开,找到设置中心进…...

在米尔FPGA开发板上实现Tiny YOLO V4,助力AIoT应用
学习如何在 MYIR 的 ZU3EG FPGA 开发板上部署 Tiny YOLO v4,对比 FPGA、GPU、CPU 的性能,助力 AIoT 边缘计算应用。 一、 为什么选择 FPGA:应对 7nm 制程与 AI 限制 在全球半导体制程限制和高端 GPU 受限的大环境下,FPGA 成为了中…...
)
【IT】测试用例模版(含示例)
这里写目录标题 一、测试用例模版二、怎么用模版示例如何使用这个模板 一、测试用例模版 一个相对标准的测试用例模板通常包含以下部分: 测试用例ID:唯一标识符,用于追踪测试用例。测试用例标题:简短描述测试用例的目的。测试用…...

react dnd——一个拖拽组件
React DnD是一个流行的库,用于在React应用程序中实现拖放功能。以下是对React DnD的详细解释,包括示例和API说明: 基本概念 在开始使用React DnD之前,了解以下几个基本概念是很重要的: Drag Source(拖动…...

3GPP R18 LTM(L1/L2 Triggered Mobility)是什么鬼?(三) RACH-less LTM cell switch
这篇看下RACH-less LTM cell switch。 相比于RACH-based LTM,RACH-less LTM在进行LTM cell switch之前就要先知道target cell的TA信息,进而才能进行RACH-less过程,这里一般可以通过UE自行测量或者通过RA过程获取,而这里的RA一般是通过PDCCH order过程触发。根据38.300中的描…...

Flutter解压文件并解析数据
Flutter解压文件并解析数据 前言 在 Flutter 开发中,我们经常需要处理文件的读取和解压。 这在处理应用数据更新、安装包、存档文件等场景中尤为常见。 本文将介绍如何在Flutter中使用archive插件来解压文件并解析数据。 准备 在开始之前,我们需要…...

21、结构体成员分布
结构体中的成员并不是紧挨着分布的,内存分布遵循字节对齐的原则。 按照成员定义的顺序,遵循字节对齐的原则存储。 字节对齐的原则: 找成员中占据字节数最大的成员,以它为单位进行空间空配 --- 遇到数组看元素的类型 每一个成员距离…...

TSWIKI知识库软件
TSWIKI 知识库软件介绍 推荐一个适合本地化部署、自托管的知识库软件 TSWIKI介绍 tswiki 是一个适合小团队、个人的知识库、资料管理的软件,所有数据均本地化存储。可以本地化、私有云部署,安装简单。在线预览。 主要功能说明 1、简化的软件依赖和安…...

深度学习安装环境笔记
1、输出cuda版本 torch.version.cuda 返回的是 PyTorch 在编译时所使用的 CUDA 版本,而不是运行时实际调用的 CUDA 版本。PyTorch 在运行时实际调用的 CUDA 版本取决于系统上安装的 CUDA 驱动和库。 import torch from torch.utils.cpp_extension import CUDA_HOME…...
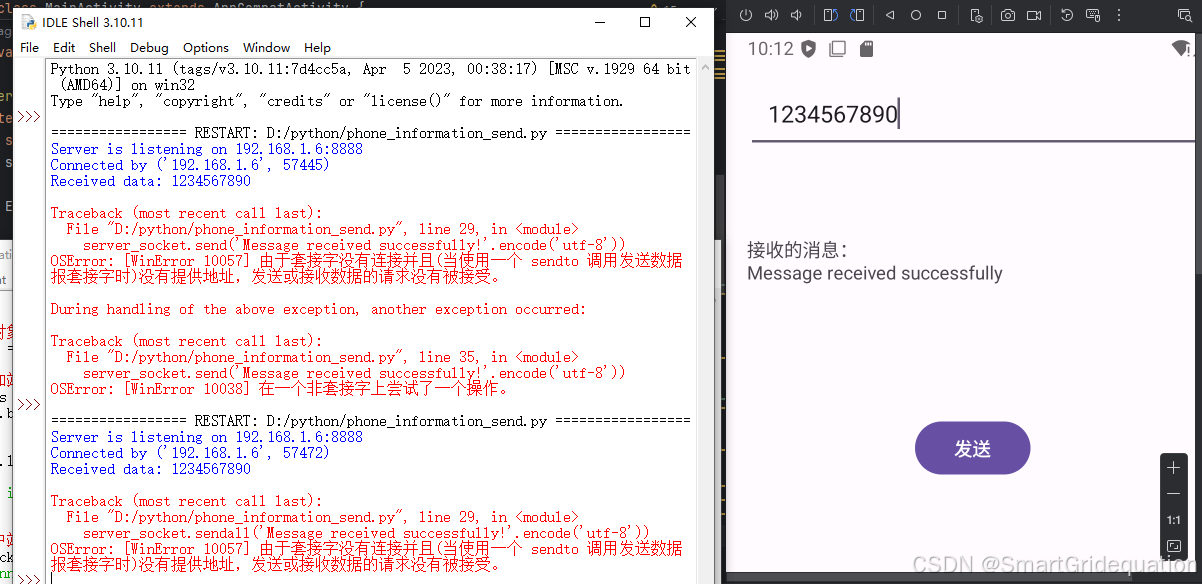
使用android studio写一个Android的远程通信软件(APP),有通讯的发送和接收消息界面
以下是使用 Android Studio 基于 Java 语言编写一个简单的 Android APP 实现远程通信(这里以 TCP 通信为例)的代码示例,包含基本的通信界面以及发送和接收消息功能。 1. 创建项目 打开 Android Studio,新建一个 Empty Activity …...

学习Python的笔记14--迭代器和生成器
1.迭代器(Iterator) 概念: 迭代意味着重复多次,就像循环一样。 迭代器是一个可以记住遍历的位置的对象。 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。 迭代器只能往前不会后退。 1.iter…...

车机端同步outlook日历
最近在开发一个车机上的日历助手,其中一个需求就是要实现手机端日历和车机端日历数据的同步。然而这种需求似乎没办法实现,毕竟手机日历是手机厂商自己带的系统应用,根本不能和车机端实现数据同步的。 那么只能去其他公共的平台寻求一些机会&…...

教学案例:k相同的一次函数的图像关系
【题目】 请在同一个平面直角坐标系中画出一次函数y2x, y2x4的图象,并观察图象,你发现这两个图形有什么位置关系?为什么? 【答案】 图象是相互平行的两条直线 【解析】 一、教学活动形式 这里设计的教学活动形式是“画图 →…...
EmoAva:首个大规模、高质量的文本到3D表情映射数据集。
2024-12-03,由哈尔滨工业大学(深圳)的计算机科学系联合澳门大学、新加坡南洋理工大学等机构创建了EmoAva数据集,这是首个大规模、高质量的文本到3D表情映射数据集,对于推动情感丰富的3D头像生成技术的发展具有重要意义…...

Elasticsearch vs 向量数据库:寻找最佳混合检索方案
图片来自Shutterstock上的Bakhtiar Zein 多年来,以Elasticsearch为代表的基于全文检索的搜索方案,一直是搜索和推荐引擎等信息检索系统的默认选择。但传统的全文搜索只能提供基于关键字匹配的精确结果,例如找到包含特殊名词“Python3.9”的文…...

【Flink-scala】DataStream编程模型之水位线
DataStream API编程模型 1.【Flink-Scala】DataStream编程模型之 数据源、数据转换、数据输出 2.【Flink-scala】DataStream编程模型之 窗口的划分-时间概念-窗口计算程序 3.【Flink-scala】DataStream编程模型之 窗口计算-触发器-驱逐器 文章目录 DataStream API编程模型前言…...

在 Taotoken 控制台中如何管理多个 API Key 并设置访问控制与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Taotoken 控制台中如何管理多个 API Key 并设置访问控制与审计 对于需要接入多个大模型应用的团队或开发者而言,集中…...

CFS调度器:从公平算法到内核实现全景解析
1. CFS调度器的设计哲学与公平性实现 Linux内核的CFS(Completely Fair Scheduler)调度器诞生于2007年,取代了之前的O(1)调度器。它的核心设计理念可以用一个简单的比喻理解:想象CPU时间是一块披萨,CFS要确保每个进程都…...

NotebookLM思维导图生成已进入「语义拓扑时代」:2024Q2最新Benchmark显示其节点关联准确率超越MindNode Pro 41.6%
更多请点击: https://intelliparadigm.com 第一章:NotebookLM思维导图生成已进入「语义拓扑时代」 传统基于关键词共现或规则模板的思维导图生成方式,正被 NotebookLM 的语义理解能力彻底重构。其底层 LLM 模型不再仅识别显式术语关系&#…...
)
数字视频发送器(SDI编码器)
这是一款数字视频发送器(SDI编码器),功能对标Genum公司的GV7600和Semtech的GS2972。该芯片主要用于将并行数字视频信号(如BT.1120)转换为串行SDI信号,通过75欧姆同轴线缆进行传输。特征:传输速率…...

Borderless Gaming终极指南:如何轻松实现无边框游戏窗口管理
Borderless Gaming终极指南:如何轻松实现无边框游戏窗口管理 【免费下载链接】Borderless-Gaming Play your favorite games in a borderless window; no more time consuming alt-tabs. 项目地址: https://gitcode.com/gh_mirrors/bo/Borderless-Gaming 你…...

Manus开源框架:高效探索与开发灵巧手抓取技能
1. 项目概述与核心价值最近在机器人抓取领域,一个名为“Manus Open Claw Skill Hunter and Developer”的项目引起了我的注意。这个项目由Simplio Labs开源,它不是一个具体的硬件爪子,也不是一个单一的算法,而是一个专门用于发现、…...

整合ssm框架,详细讲解
今天针对 SSM(SpringSpringMVCMyBatis)框架整合展开了学习,学习内容如下:我们在进行 JavaEE 开发时,为了实现解耦和提高开发效率,通常会采用 SSM(SpringSpringMVCMyBatis)框架整合的…...
)
别再手动敲空格了!用LaTeX的\parskip命令一键搞定论文段落间距(附局部调整技巧)
LaTeX段落间距精修指南:从全局配置到章节级微调 在学术写作的世界里,格式规范往往比内容本身更容易引发焦虑。当你在凌晨三点盯着屏幕,发现第17次调整的段落间距仍然不符合期刊要求时,那种绝望感足以让任何研究者崩溃。传统的手动…...

GCC __builtin函数避坑指南:让你的跨平台C代码在ARM和x86上都跑得稳
GCC __builtin函数跨平台避坑实战:ARM与x86兼容性深度解析 在嵌入式开发与高性能计算领域,GCC编译器的__builtin函数集一直是开发者提升性能的利器。但当代码需要同时运行在ARM架构的嵌入式设备和x86架构的服务器上时,这些看似美妙的"魔…...

蓝桥杯单片机备赛:AT24C02 EEPROM存储整型数据的完整流程与常见错误分析
蓝桥杯单片机备赛:AT24C02 EEPROM存储整型数据的完整流程与常见错误分析 在蓝桥杯单片机竞赛中,AT24C02 EEPROM模块是必考内容之一。许多选手已经掌握了基本字符型数据的读写操作,但当面对整型数据时,往往会遇到各种问题。本文将深…...