2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析
2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析
完整代码请私聊 博主
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df1_1 = pd.read_excel('./数据/附件1.xlsx')
df1_1
df1_1.info()
df1_1['产品通用名称'].unique()
set(df1_1["产品通用名称"])
def grade(x):if ('复混' in x[:2]) or ('掺混' in x):return '复混肥料'elif '无机' in x:return '有机-无机复混肥料'elif '有机肥料' in x:return '有机肥料'elif '调酸剂' in x:return '床土调酸剂'
df1_1['产品通用名称'] = df1_1['产品通用名称'].apply(grade)
df1_1.reset_index(inplace=True,drop=True)
df1_1.to_excel('result1_1.xlsx',index=None)
序号 企业名称 产品通用名称 产品形态 总氮百分比 P2O5百分比 K2O百分比 含氯情况 有机质百分比 正式登记证号 发证日期 有效期
0 1 安徽中元化肥股份有限公司 复混肥料 颗粒 0.1300 0.1700 0.2000 低氯 0.00 皖农肥(2016)准字4255号 2016-01-08 2021-01
1 2 安徽中元化肥股份有限公司 复混肥料 颗粒 0.1300 0.1700 0.2000 中氯 0.00 皖农肥(2016)准字4256号 2016-01-08 2021-01
2 3 安徽中元化肥股份有限公司 复混肥料 颗粒 0.2000 0.1500 0.1600 低氯 0.00 皖农肥(2016)准字4257号 2016-01-08 2021-01
3 4 安徽中元化肥股份有限公司 复混肥料 颗粒 0.2600 0.1300 0.1200 低氯 0.00 皖农肥(2016)准字4258号 2016-01-08 2021-01
4 5 安徽中元化肥股份有限公司 复混肥料 颗粒 0.2600 0.1300 0.1200 中氯 0.00 皖农肥(2016)准字4259号 2016-01-08 2021-01
... ... ... ... ... ... ... ... ... ... ... ... ...
2920 2921 安徽泰又丰有机肥科技有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7174号 2021-3-8 5年
2921 2922 滁州市塔山生物有机肥料有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7175号 2021-3-8 5年
2922 2923 利辛县鑫圣农业科技有限责任公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7176号 2021-3-8 5年
2923 2924 利辛县鑫圣农业科技有限责任公司 有机肥料 颗粒 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7177号 2021-3-8 5年
2924 2925 六安亿牛生物科技有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7178号 2021-3-17 5年
2925 rows × 12 columns
任务 1.2
计算附件 1 中各肥料产品的氮、磷、钾养分百分比之和,称为总无机养分百分比。请在报告中给出处理思路、过程及必要的结果,同时将完整的结果保存到文件“result1_2.xlsx”中,结果保留 3 位小数(例如 1.0%,即 0.010)。
df1_2 = pd.read_excel('./数据/附件1.xlsx')
df1_2.head()
res = df1_2[['总氮百分比','P2O5百分比','K2O百分比']].sum(axis=1)
res = round(res*100,1).astype(str)+'%'
df1_2['总无机养分百分比'] = res
df1_2[['序号','正式登记证号','总无机养分百分比']].to_excel('result1_2.xlsx',index=None) 序号 企业名称 产品通用名称 产品形态 总氮百分比 P2O5百分比 K2O百分比 含氯情况 有机质百分比 正式登记证号 发证日期 有效期 总无机养分百分比
0 1 安徽中元化肥股份有限公司 复混肥料 颗粒 0.1300 0.1700 0.2000 低氯 0.00 皖农肥(2016)准字4255号 2016-01-08 2021-01 50.0%
1 2 安徽中元化肥股份有限公司 复混肥料 颗粒 0.1300 0.1700 0.2000 中氯 0.00 皖农肥(2016)准字4256号 2016-01-08 2021-01 50.0%
2 3 安徽中元化肥股份有限公司 复混肥料 颗粒 0.2000 0.1500 0.1600 低氯 0.00 皖农肥(2016)准字4257号 2016-01-08 2021-01 51.0%
3 4 安徽中元化肥股份有限公司 复混肥料 颗粒 0.2600 0.1300 0.1200 低氯 0.00 皖农肥(2016)准字4258号 2016-01-08 2021-01 51.0%
4 5 安徽中元化肥股份有限公司 复混肥料 颗粒 0.2600 0.1300 0.1200 中氯 0.00 皖农肥(2016)准字4259号 2016-01-08 2021-01 51.0%
... ... ... ... ... ... ... ... ... ... ... ... ... ...
2920 2921 安徽泰又丰有机肥科技有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7174号 2021-3-8 5年 5.0%
2921 2922 滁州市塔山生物有机肥料有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7175号 2021-3-8 5年 5.0%
2922 2923 利辛县鑫圣农业科技有限责任公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7176号 2021-3-8 5年 5.0%
2923 2924 利辛县鑫圣农业科技有限责任公司 有机肥料 颗粒 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7177号 2021-3-8 5年 5.0%
2924 2925 六安亿牛生物科技有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 皖农肥(2021)准字7178号 2021-3-17 5年 5.0%
2925 rows × 13 columns
任务 2 肥料产品的数据分析
任务 2.1
从附件 2 中筛选出复混肥料的产品,将所有复混肥料按照总无机养分百分比的取值等距分为 10 组。根据每个产品所在的分组,为其打上分组标签(标签用 1~10 表示),将完整的结果保存到文件“result2_1.xlsx”中。分析复混肥料产品的分布特点,在报告中绘制产品登记数量的直方图,给出处理思路及过程,并按登记数量从大到小列出登记数量最大的前 3 个分组及相应的产品登记数量。
df2_1 = pd.read_excel('./数据/附件2.xlsx')
df2_1 = df2_1.loc[df2_1['产品通用名称']=='复混肥料']
df2_1
df2_1['分组标签'] = pd.cut(df2_1['总无机养分百分比'],bins=10,include_lowest=True,labels=list(range(1,11)))
df2_1.to_excel('result2_1.xlsx',index=None)
序号 企业名称 产品通用名称 产品形态 总氮百分比 P2O5百分比 K2O百分比 含氯情况 有机质百分比 正式登记证号 发证日期 有效期 产品商品名称 适用作物 总无机养分百分比 分组标签
1 2 嘉施利(应城)化肥有限公司 复混肥料 粒状 0.17 0.17 0.07 低氯 0.0 鄂农肥(2009)准字0004号 2014-08-15 2019-08 NaN NaN 0.41 6
2 3 嘉施利(应城)化肥有限公司 复混肥料 粒状 0.20 0.05 0.15 无氯 0.0 鄂农肥(2009)准字0005号 2014-08-15 2019-08 NaN NaN 0.40 6
3 4 嘉施利(应城)化肥有限公司 复混肥料 粒状 0.26 0.08 0.10 中氯 0.0 鄂农肥(2009)准字0006号 2014-08-15 2019-08 NaN NaN 0.44 7
4 5 湖北澳特尔化工有限公司 复混肥料 粒状 0.15 0.15 0.15 无氯 0.0 鄂农肥(2009)准字00079号 2014-10-25 2019-10 NaN NaN 0.45 7
5 6 嘉施利(应城)化肥有限公司 复混肥料 粒状 0.20 0.05 0.11 无氯 0.0 鄂农肥(2009)准字0007号 2014-08-15 2019-08 NaN NaN 0.36 5
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
7597 2214 广西洁源动物无害化处理有限公司 复混肥料 粒状 0.16 0.05 0.09 高氯 0.0 桂农肥(2020)准字3873号 2020-10-09 2025-10 复混肥料 NaN 0.30 5
7598 2215 广西洁源动物无害化处理有限公司 复混肥料 粒状 0.14 0.04 0.09 中氯 0.0 桂农肥(2020)准字3874号 2020-10-09 2025-10 复混肥料 NaN 0.27 4
7604 2221 广西崇左弗恩生物科技有限公司 复混肥料 粒状 0.16 0.08 0.16 无氯 0.0 桂农肥(2020)准字3880号 2020-10-09 2025-10 桔丰 NaN 0.40 6
7609 2226 玉林市绿芬威化肥有限公司 复混肥料 粒状 0.17 0.06 0.07 高氯 0.0 桂农肥(2020)准字3885号 2020-10-09 2025-10 复混肥料 NaN 0.30 5
7610 2227 玉林市绿芬威化肥有限公司 复混肥料 粒状 0.15 0.05 0.05 高氯 0.0 桂农肥(2020)准字3886号 2020-10-09 2025-10 复混肥料 NaN 0.25 4
5954 rows × 16 columns

任务 2.2
从附件 2 中筛选出有机肥料的产品,将产品按照总无机养分百分比和有机质百分比分别等距分为 10 组,并为每个产品打上分组标签 (1,1), (1,2),⋯, (10,10),将完整的结果保存到文件“result2_2.xlsx”中。请在报告中给出处理思路及过程,并根据分组情况绘制有机肥料产品的分布热力图,其中横轴代表总无机养分分组,纵轴代表有机质分组。在此基础上,分析有机肥料产品的分布特点,并按登记数量从大到小列出登记数量最大的前 3 个分组及相应的产品登记数量。
df2_2 = pd.read_excel('./数据//附件2.xlsx')
df2_2 = df2_2[df2_2['产品通用名称']=='有机肥料']
df2_2['总无机养分分组'] = pd.cut(df2_2['总无机养分百分比'],bins=10,include_lowest=True,labels=list(range(1,11)))
df2_2['有机质分组'] = pd.cut(df2_2['有机质百分比'],bins=10,include_lowest=True,labels=list(range(1,11)))
df2_2['总无机养分-有机质分组'] = list(zip(df2_2['总无机养分分组'],df2_2['有机质分组']))
df2_2 = df2_2.reset_index(drop=True)
df2_2
df2_2.to_excel('result2_2.xlsx',index=None)
序号 企业名称 产品通用名称 产品形态 总氮百分比 P2O5百分比 K2O百分比 含氯情况 有机质百分比 正式登记证号 发证日期 有效期 产品商品名称 适用作物 总无机养分百分比 总无机养分分组 有机质分组 总无机养分-有机质分组
0 231 湖北中化东方肥料有限公司 有机肥料 粉状 0.0267 0.0267 0.0267 无氯 0.60 鄂农肥(2009)准字0348号 2015-01-20 2020-01 NaN NaN 0.0801 1 7 (1, 7)
1 320 武汉市沃农肥业有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 鄂农肥(2010)准字0595号 2015-01-20 2020-01 NaN NaN 0.0501 1 6 (1, 6)
2 425 湖北太阳雨三农科技有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 鄂农肥(2010)准字0915号 2015/11/10 2020-11 NaN NaN 0.0501 1 6 (1, 6)
3 474 武汉裕龙生物科技有限责任公司 有机肥料 粒状 0.0167 0.0167 0.0167 无氯 0.45 鄂农肥(2010)准字1116号 2015/11/20 2020-11 NaN NaN 0.0501 1 6 (1, 6)
4 539 湖北地利奥生物科技有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 鄂农肥(2011)准字0038号 2016/03/22 2021-03 NaN NaN 0.0501 1 6 (1, 6)
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1040 2230 北海浦联生态科技有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 桂农肥(2020)准字3889号 2020-11-04 2025-11 浦联精制有机肥 NaN 0.0501 1 6 (1, 6)
1041 2232 广西佳旺生物科技有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 桂农肥(2015)准字2257号 2020-11-16 2025-11 精制有机肥 NaN 0.0501 1 6 (1, 6)
1042 2233 广西海源生态农业开发有限公司 有机肥料 粉、粒状 0.0167 0.0167 0.0167 无氯 0.45 桂农肥(2015)准字2304号 2020-11-30 2025-11 精制有机肥 NaN 0.0501 1 6 (1, 6)
1043 2234 广西亿裕发生态肥业有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 桂农肥(2016)准字2591号 2020-12-14 2022-01 莫老爷有机肥 NaN 0.0501 1 6 (1, 6)
1044 2235 广西群星肥业有限公司 有机肥料 粉状 0.0167 0.0167 0.0167 无氯 0.45 桂农肥(2019)准字3446号 2020-12-16 2024-02 精制有机肥 NaN 0.0501 1 6 (1, 6)
1045 rows × 18 columns

任务 2.3
从附件 2 中筛选出复混肥料的产品,按照氮、磷、钾养分的百分比,使用聚类算法将这些产品分为 4 类。根据聚类结果为每个产品打上聚类标签(标签用 1~4 表示),并将完整的结果保存到文件“result2_3.xlsx”中。请在报告中给出处理思路及过程,根据聚类标签绘制肥料产品的三维散点图和散点图矩阵,并通过绘制聚类结果的雷达图分析每个聚类的特征。

#散点图矩阵

cluster = km.cluster_centers_#获取聚类中心
print(cluster.max())#聚类中心中的最大值
0.25918935643564356
雷达图

任务 3 肥料产品的多维度对比分析
任务 3.1
从文件“result2_1.xlsx”中提取发证日期中的年份,分析比较复混肥料中各组别不同年份产品登记数量的变化趋势。请在报告中给出处理思路及分析过程,使用合适的图表对结果进行可视化。
df3_1 = pd.read_excel('result2_1.xlsx')
df3_1['发证日期'] = pd.to_datetime(df3_1['发证日期'], format="%Y-%m-%d")
df3_1['年份'] = df3_1['发证日期'].dt.year
data = df3_1.pivot_table(index='年份',columns='分组标签',values='序号',aggfunc='count',fill_value=0)
import pyecharts.options as opts
from pyecharts.charts import Line

任务 3.2
从文件“result2_2.xlsx”中提取 2021 年 9 月 30 日仍有效的有机肥料产品,将完整的结果保存到文件“result3_2.xlsx”中。从有效产品中分别筛选出广西和湖北(根据正式登记证号区分)产品登记数量在前 5 的组别,分析两个省份上述组别的分布差异。请在报告中给出处理过程及分析结果。
df3_2 = pd.read_excel('result2_2.xlsx')
df3_2 = df3_2[df3_2['有效期'] >= '2021-9-30']
df3_2.reset_index(drop=True,inplace=True)
df3_2.to_excel('result3_2.xlsx',index=None)
df3_2[df3_2['正式登记证号'].apply(lambda x:'鄂'in x)]['总无机养分-有机质分组'].value_counts()[:5]
(1, 6) 373
(1, 7) 11
(1, 8) 5
(2, 6) 3
(2, 7) 2
Name: 总无机养分-有机质分组, dtype: int64
df3_2[df3_2['正式登记证号'].apply(lambda x:'桂'in x)]['总无机养分-有机质分组'].value_counts()[:5]
(1, 6) 340
(1, 7) 55
(2, 6) 48
(2, 7) 23
(1, 8) 9
Name: 总无机养分-有机质分组, dtype: int64
任务 3.3
从附件 3 中提取产品登记数量大于 10 的肥料企业,给出这些企业所用到的原料集合(发酵菌剂除外)。以各企业用到的原料作为特征,计算企业之间的杰卡德相似系数矩阵,并将结果(保留4位小数)保存到文件“result3_3.xlsx”中(不提供模板文件,格式见表 1)。请在报告中给出处理思路、过程及相似系数矩阵。
注 集合 𝐴 与 𝐵 的杰卡德相似系数定义为 𝐽(𝐴, 𝐵) =|𝐴∩𝐵|/𝐴∪𝐵| ,其中 |S| 表示集合 𝑆 中元素的个数。

df3_3 = pd.read_excel('./数据/附件3.xlsx')
df3_3.head()
a = df3_3['企业名称'].value_counts()>10
a = a[a].index
a
Index(['ID1', 'ID2', 'ID3', 'ID5', 'ID4', 'ID6', 'ID7', 'ID12', 'ID10', 'ID9'], dtype='object')
…
```bash
jiedeka_list=[]
for i in a:jiedeka_row = []for j in a:jiaoji_nums = len(qiye_dict[i].intersection(qiye_dict[j]))bingji_nums = len(qiye_dict[i].union(qiye_dict[j]))jiedeka = jiaoji_nums/bingji_numsjiedeka = '%.4f'%jiedekajiedeka_row.append(jiedeka)jiedeka_list.append(jiedeka_row)
data = pd.DataFrame(np.array(jiedeka_list),index=a.values,columns=a.values)
data.to_excel('result3_3.xlsx')
data
ID1 ID2 ID3 ID5 ID4 ID6 ID7 ID12 ID10 ID9
ID1 1.0000 0.2692 0.3000 0.2143 0.3333 0.3000 0.3333 0.2381 0.2273 0.1538
ID2 0.2692 1.0000 0.3500 0.2069 0.3182 0.3500 0.3889 0.2857 0.2727 0.1923
ID3 0.3000 0.3500 1.0000 0.3333 0.4667 0.5385 0.6364 0.4286 0.3125 0.3333
ID5 0.2143 0.2069 0.3333 1.0000 0.3043 0.2727 0.3000 0.2174 0.2083 0.2800
ID4 0.3333 0.3182 0.4667 0.3043 1.0000 0.3750 0.4286 0.2941 0.2778 0.2381
ID6 0.3000 0.3500 0.5385 0.2727 0.3750 1.0000 0.8000 0.4286 0.4000 0.2632
ID7 0.3333 0.3889 0.6364 0.3000 0.4286 0.8000 1.0000 0.5000 0.3571 0.2941
ID12 0.2381 0.2857 0.4286 0.2174 0.2941 0.4286 0.5000 1.0000 0.3125 0.2632
ID10 0.2273 0.2727 0.3125 0.2083 0.2778 0.4000 0.3571 0.3125 1.0000 0.1905
ID9 0.1538 0.1923 0.3333 0.2800 0.2381 0.2632 0.2941 0.2632 0.1905 1.0000任务 4 肥料产品的多维度对比分析
任务 4.1
设计算法或处理流程,从附件 4 技术指标中提取出氮、磷、钾养分和有机质的百分比,以及肥料含氯的程度。请在报告中给出处理思路及过程,并将结果保存到文件“result4_1.xlsx”中。
注 如果技术指标中只给出总养分百分比(“≥”按照“=”处理)而无明细数据,则氮、磷、钾养分的百分比按照总百分比的 1/3 来计算,结果保留 3 位小数(例如 1.0%,即 0.010)。复混肥料属于无机肥料,它的有机质百分比设定为 0。含氯情况分为“无氯”、“低氯”、“中氯”和“高氯”4 种。如果肥料产品的技术指标中没有给出含氯情况,则视为“无氯”;如果注明“含氯”,则视为“低氯”。
df4_1 = pd.read_excel('./数据/附件4.xlsx')
df4_1.head()
df4_1[['总氮百分比','P205百分比','K20百分比','有机质百分比','含氯的程度']]=np.nan
.............................................................................................
df4_1['总氮百分比'] = df4_1[['产品通用名称', '技术指标']].apply(npk_youji, axis=1).str[0]
df4_1['P2O5百分比'] = df4_1[['产品通用名称', '技术指标']].apply(npk_youji, axis=1).str[1]
df4_1['K2O百分比'] = df4_1[['产品通用名称', '技术指标']].apply(npk_youji, axis=1).str[2]
df4_1['有机质百分比'] = df4_1[['产品通用名称', '技术指标']].apply(npk_youji, axis=1).str[3]
# 保存结果
df4_1.to_excel('result4_1.xlsx')
序号 产品通用名称 技术指标 原料与占比 总氮百分比 P205百分比 K20百分比 有机质百分比 含氯的程度 P2O5百分比 K2O百分比
0 1 复混肥料 总养分(N+P2O5+K2O)≥35%(14-8-13) 硫酸钾型 尿素 (占15%),高岭土 (占15.5%),硫酸铵 (占28.16%),磷酸一铵 (占16... 0.140 NaN NaN 0.00 无氯 0.080 0.130
1 2 复混肥料 总养分(N+P2O5+K2O)≥30%(15-6-9) 中氯 尿素 (占15%),高岭土 (占30.23%),氯化铵 (占28%),磷酸一铵 (占12.2... 0.150 NaN NaN 0.00 中氯 0.060 0.090
2 3 有机肥料 N+P2O5+K2O≥5% ,有机质≥45% 木薯渣(干基) (占84.9%),菌种 (占0.1%),黄豆渣 (占15%) 0.017 NaN NaN 0.45 无氯 0.017 0.017
3 4 复混肥料 总养分(N+P2O5+K2O)≥43% (10―18―15)含氯(低氯) 尿素 (占15%),高岭土 (占20%),粉状磷酸一铵 (占40%),氯化钾 (占25%) 0.100 NaN NaN 0.00 低氯 0.180 0.150
4 5 有机肥料 总养分(N+P2O5+K2O)≥5.0% 有机质≥45% 酸碱度(PH) 5.5∽8.5 畜禽粪便 (占50%),菌种 (占2%),桐 麸 (占30%),滤 泥 (占18%) 0.017 NaN NaN 0.45 无氯 0.017 0.017
... ... ... ... ... ... ... ... ... ... ... ...
195 196 有机-无机复混肥料 有机-无机肥复混肥料(Ⅰ型)6-8-6(含氯 )总含量:N+P2O5+K2O≥20%,有机质... 尿素 (占5%),膨润土 (占25%),氯化铵 (占10%),氯化钾 (占10%),磷酸一铵... 0.060 NaN NaN 0.20 低氯 0.080 0.060
196 197 有机-无机复混肥料 总养份≥29%(9-7-13) 有机质≥20% 含氯 尿素 (占16.5%),酒糟 (占13%),滤泥 (占33.2%),磷酸一铵 (占15.6%... 0.090 NaN NaN 0.20 低氯 0.070 0.130
197 198 有机肥料 总养分(N+P2O5+K2O)≥5.0% 有机质≥45% 酸碱度(PH) 5.5∽8.5 畜禽粪便 (占50%),菌种 (占2%),桐 麸 (占30%),滤泥 (占18%) 0.017 NaN NaN 0.45 无氯 0.017 0.017
198 199 有机肥料 总养分(N+P2O5+K2O)≥5.0%有机质≥45% 牛粪 (占85%),发酵剂 (占0.03%),鸡粪 (占10%), (占0%), (占0%)... 0.017 NaN NaN 0.45 无氯 0.017 0.017
199 200 有机-无机复混肥料 总养分≥25%(N+P2O5+K2O) 有机质 ≥15% 含氯 II型 尿素 (占26%),高岭土 (占10%),55磷酸一铵 (占12%),氯化钾 (占12%),... 0.083 NaN NaN 0.15 低氯 0.083 0.083
200 rows × 11 columns
任务 4.2
设计算法或处理流程,从附件 4 原料与百分比中提取各种原料的名称及其百分比。请在报告中给出处理思路及过程,并将结果保存到文件“result4_2.xlsx”中(参见表 2)

data4_2 = pd.DataFrame(columns=['序号', '原料名称', '百分比'])
# 记录未成功提取的的数据的序号
xuhaos = []
........................................................................................
if xuhaos == []:print('全部数据提取成功')
# 保存数据
data4_2.to_excel('result4_2.xlsx')
序号 原料名称 百分比
0 001 尿素 15%
1 001 高岭土 15.5%
2 001 硫酸铵 28.16%
3 001 磷酸一铵 16.34%
4 001 硫酸钾 25%
... ... ... ...
943 199 鸽子粪 4.97%
944 200 尿素 26%
945 200 高岭土 10%
946 200 氯化钾 12%
947 200 有机肥料 40%
948 rows × 3 columns
四、数据说明
附件 1~附件 4 的数据收集自农业部门官方网站,部分数据细节与实际有差别,仅供比赛使用。
附件 1 为安徽肥料登记数据,附件 2 为广西、湖北肥料登记数据。这两个附件中表的主要字段有企业名称、产品通用名称、正式登记证编号、发证日期、有效时间、产品形态、营养成分百分比、含氯情况等。其中产品通用名称实际上是肥料产品的类型,需要在省级农业行政主管部门登记的肥料有复混肥料(包括掺混肥料)、有机-无机复混肥料、有机肥料和床土调酸剂这 4 类。肥料的营养成分百分比指标,通常标记出属于无机成分的氮、磷、钾的含量,以及有机质的含量。我国规定,氮肥成分以总氮的质量来计算含量,磷肥成分按磷元素的量折算
成五氧化二磷(P2O5)的质量来计算含量,钾肥成分按钾元素的量折算成氧化钾(K2O)的质量来计算含量。注意,肥料正式登记证有效期为 5 年,可以续期,会出现有效期距发证日期大于 5 年的情况。
附件 3 给出了某省登记肥料的产品配方,相比附件 1 和附件 2 增加了关于肥料原料的信息。
附件 4 给出了某省肥料登记数据中营养成分及原料构成的原始数据。字段技术指标以字符串的形式给出了肥料的营养成分的百分比。例如某复混肥料的技术指标字段取值为“N+P2O5+K2O≥20%(7-10-3) 有机质≥20% 含氯”,表示肥料中氮磷钾三大元素的总养分含量不小于 20%;“(7-10-3)”指的是氮磷钾的配比,氮含量为 7%,磷肥成分(折算为 P2O5)含量为 10%,钾肥成分(折算为K2O)含量为 3%;“有机质≥20%”表示肥料中有机质的含量不小于 20%;“含氯”表示肥料中含有氯元素。有机肥料由于不含无机养分或含量较少,有些产品
只在技术指标中标明“总养分≥…%”,没有给出氮、磷、钾 3 大元素的具体含量。字段原料与百分比以字符串的形式给出了肥料的原料构成及质量百分比,例如某有机肥料的原料与百分比字段取值为“糖蜜酒精废液 (占 25%),发酵菌种(占 1%),木糠 (占 25%),滤泥 (占 49%)”,表明了该有机肥料由蜜糖酒精废液、发酵菌种、木糠和滤泥四种原料构成,质量百分比分别是 25%、1%、25%及 49%。
注 本赛题中,不同的正式登记证号代表不同的产品。
相关文章:
2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析
2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析 完整代码请私聊 博主 # 一、背景 肥料是农业生产中一种重要的生产资料,其生产销售必须遵循《肥料登记管理办法》,依法在农业行政管理部门进行登记。各省、自治区、直辖市人民政府农业行政主管部门主…...

网络原理之 IP 协议
目录 1. IP 协议报文格式 2. 网段划分 3. 地址管理 1) 动态分配 2) NAT 机制 (网络地址转换) 3) IPv6 4. 路由选择 1. IP 协议报文格式 IP 协议是网络层的重点协议。 网络层要做的事情,主要就是两方面: 1) 地址管理 制定一系列的规则ÿ…...
来在开发过程中更快速地看到页面的变化。)
在 Spring Boot 项目中使用 Thymeleaf 时,通常情况下,你需要配置热加载(Hot Reload)来在开发过程中更快速地看到页面的变化。
配置步骤: 1. 添加 DevTools 依赖 在 pom.xml 中添加 spring-boot-devtools 依赖。DevTools 提供了自动重启、LiveReload、模板热加载等功能。 <dependencies><!-- Spring Boot DevTools (用于热加载) --><dependency><groupId>org.spri…...

arm-linux GPIO控制-脚本及shell格式
以下是针对BCM编号27, 28, 29, 30, 31的shell命令 shell方式 导出GPIO引脚 echo 27 > /sys/class/gpio/export echo 28 > /sys/class/gpio/export echo 29 > /sys/class/gpio/export echo 30 > /sys/class/gpio/export echo 31 > /sys/class/gpio/export 设…...

Go 语言基础知识语法
很早听人说过一句话:“每年学习(接触)一门新的编程语言”,这听起来可能有点不太现实,但是其实很多种语言都是相通的。掌握新的编程语言不仅仅是增加职业工具箱中的工具,更是一种扩展我们思维方式、解决问题…...

贪心算法part05
文章参考来源代码随想录 (programmercarl.com) 56. 合并区间 本题和前几题类似,都是判断上一个元素的右边界与当前元素的左边界大小关系 但是需要注意是:本题需要更新结果数组元素的右边界,因此比较的是数组最后一个元素右边界与当前元素左…...
)
02、SpringMVC核心(上)
一、RequestMapping注解 @Target({ElementType.TYPE, ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented @Mapping @Reflective({ControllerMappingReflectiveProcessor.class}) public @interface RequestMapping {String name() default "";…...

EasyPlayerPro的同一个组件实例根据url不同展示视频流
效果 学习 url的组成 webrtc://192.168.1.225:8101/index/api/webrtc?applive&stream001&typeplay 协议部分 webrtc://: 这表示使用 WebRTC 协议来进行实时通信。WebRTC 允许浏览器之间直接交换音频、视频和其他数据,而不需要通过中间服务器 主机和端口部分…...
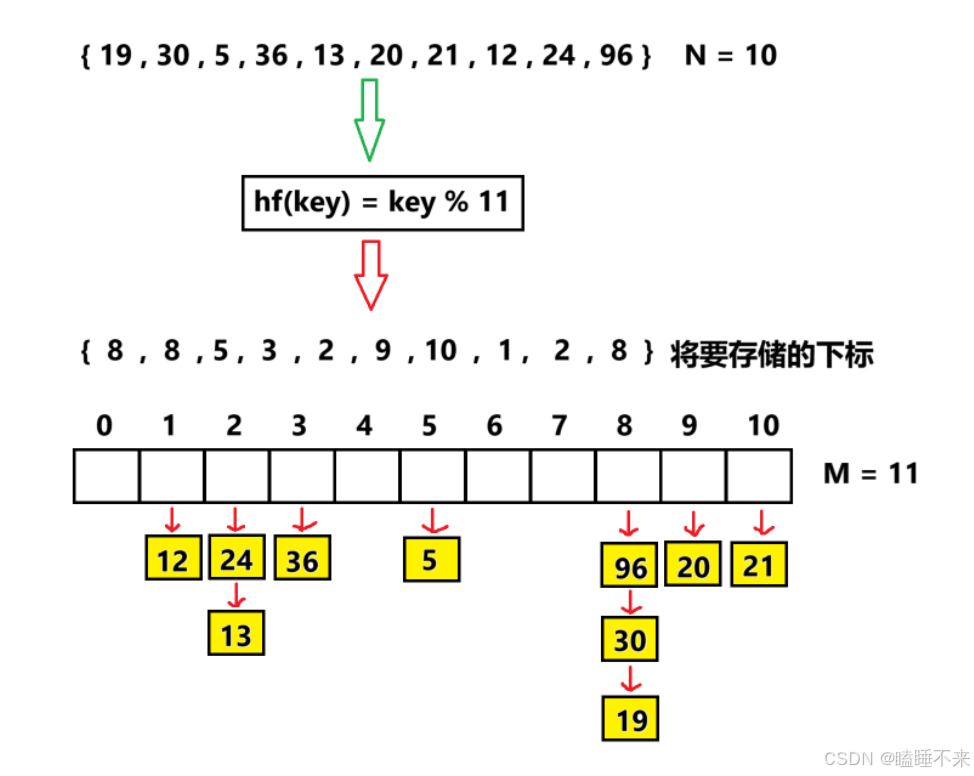
哈希表介绍、实现与封装
哈希表介绍、实现与封装 一、哈希概念二、哈希表实现直接定址法其他映射方法介绍1. 哈希冲突2. 负载因子3. 将关键字转为整数4. 设计哈希函数除法散列法 / 除留余数法乘法散列法全域散列法其他方法 将关键字转为整数处理哈希冲突开放定址法线性探测二次探测双重散列 开放定址法…...

使用vm配置网络
查看本地ip 配置vm网络 配置固定ip vi /etc/sysconfig/network-script/ifcfg-ens33参考 vm使用nat模式,导致vm中docker部署的服务,无法通过局域网中其他机器连接 https://www.cnblogs.com/junwind/p/14345385.html 三张图看懂vm中,三种网…...

OpenStack介绍
OpenStack概述 OpenStack是一个开源的云计算管理平台软件,主要用于构建和管理云计算环境。它允许企业或组织通过数据中心的物理服务器创建和管理虚拟机、存储资源和网络等云计算服务。其核心组件包括计算(Nova)、网络(Neutron)、存储(Cinder、Swift)等。这些组件相互协作…...

力扣93题:复原 IP 地址
力扣93题:复原 IP 地址(C语言实现详解) 题目描述 给定一个只包含数字的字符串 s,复原它并返回所有可能的 IP 地址格式。 有效的 IP 地址需满足以下条件: IP 地址由四个整数(每个整数位于 0 到 255 之间…...

mock.js介绍
mock.js http://mockjs.com/ 1、mock的介绍 *** 生成随机数据,拦截 Ajax 请求。** 通过随机数据,模拟各种场景;不需要修改既有代码,就可以拦截 Ajax 请求,返回模拟的响应数据;支持生成随机的文本、数字…...

React开发 - 技术细节汇总一
React简介 React 是一个声明式,高效且灵活的用于构建用户界面的 JavaScript 库。使用 React 可以将一些简短、独立的代码片段组合成复杂的 UI 界面,这些代码片段被称作“组件”。 ui render (data) -> 单向数据流 MVC // model var myapp {}; // …...

【论文复现】分割万物-SAM
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ 分割万物-SAM 介绍原理分割任务任务预训练zero-shot transfer相关任务 模型Image EncoderPrompt EncoderMask Eecoder消除歧义高效Loss 和训…...

实现RAGFlow-0.14.1的输入框多行输入和消息框的多行显示
一、Chat页面输入框的修改 1. macOS配置 我使用MacBook Pro,chip 是 Apple M3 Pro,Memory是18GB,macOS是 Sonoma 14.6.1。 2. 修改chat输入框代码 目前RAGFlow前端的chat功能,输入的内容是单行的,不能主动使用Shift…...

Pointnet++改进71:添加LFE模块|高效长距离注意力网络
简介:1.该教程提供大量的首发改进的方式,降低上手难度,多种结构改进,助力寻找创新点!2.本篇文章对Pointnet++特征提取模块进行改进,加入LFE模块,提升性能。3.专栏持续更新,紧随最新的研究内容。 目录 1.理论介绍 2.修改步骤 2.1 步骤一 2.2 步骤二 2.3 步骤三 1.理…...

C++STL容器vector容器大小相关函数
目录 前言 主要参考 vector::size vector::max_size vector::resize vector::capacity vector::empty vector::reserve vector::shrink_to_fit 共勉 前言 本文将讨论STL容器vector中与迭代器相关的函数,模板参数T为int类型。 主要参考 cpluscplus.com 侯…...

阿里云CPU超载解决记录
现象:阿里云CPU使用率超90%连续5分钟告警,项目日志error.log中存在heap/gc/limit等内存耗尽等信息,阿里云慢查询日志每日有查询时间很长的参数一直不变的慢sql,linux服务器使用top命令并按c可以看到cpu过大是哪个命令行造成的 分…...

【工具变量】上市公司企业商业信用融资数据(2003-2022年)
一、测算方式:参考《会计研究》张新民老师的做法 净商业信用NTC(应付账款应付票据预收账款)-(应收账款应收票据预付账款),用总资产标准化; 应付账款AP应付账款应付票据预收账款,用总资产标准化 一年以上应付账款比例LAP是企业一年以上(包括一…...

英雄联盟LCU自动化工具:3步打造你的专属智能游戏伴侣
英雄联盟LCU自动化工具:3步打造你的专属智能游戏伴侣 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中重复繁琐的操…...

3D打印操作辅助工具:自制安全高效的“过来放大器”
1. 项目概述:当3D打印遇上“过来”放大器在3D打印这个行当里折腾了这么多年,我见过各种稀奇古怪的“魔改”和“土法炼钢”,但最近一个朋友工作室里出现的一个小玩意儿,还是让我眼前一亮。他管它叫“3D打印设备专用过来放大器”。初…...

基于Node.js与Socket.IO构建开源实时聊天应用:从架构到部署
1. 项目概述:一个为纯净对话而生的开源聊天应用在信息过载的今天,我们每天被各种应用的通知、广告和复杂功能所包围。对于即时通讯这类高频使用的工具,这种“臃肿感”尤为明显。你是否也怀念过早期聊天软件那种简洁、纯粹、专注于信息交换本身…...

基于本地大模型的字幕翻译:LM Studio集成方案与实战优化
1. 项目概述:当本地大模型遇上字幕翻译最近在折腾本地大模型应用时,发现了一个挺有意思的场景:字幕翻译。很多朋友喜欢看海外影视剧或学习资料,但苦于没有高质量的中文字幕。在线翻译工具要么有字数限制,要么担心隐私泄…...

基于规则与启发式的Claude对话内容自动Markdown格式化工具实现
1. 项目概述与核心价值最近在折腾文档自动化生成工具时,发现了一个挺有意思的项目,叫looseleaf-acrylic560/claude-md-generator。乍一看这个名字,你可能觉得它就是个普通的Markdown生成器,但实际用下来,我发现它远不止…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...

GEO优化实操框架:GEO优化的正确姿势是“带着答案去找客户”
如果你是B2B企业的老板或市场负责人,你一定听过这句话: “我们网上曝光是不少,但来的询盘都不对——问价格的比问方案的还多,还有不少是学生做调研的。” 这不是你一个人遇到的问题。这是传统SEO和竞价广告的天然缺陷——你只能“…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

多智能体的协作成本:沟通开销、上下文膨胀与优化手段
多智能体的协作成本:沟通开销、上下文膨胀与优化手段 1. 标题 (Title) 多智能体系统的协作困境:解析沟通开销与上下文膨胀 从理论到实践:优化多智能体协作成本的完整指南 协作的代价:多智能体系统中的沟通、上下文与优化策略 打破协作壁垒:如何有效降低多智能体系统的运行…...

Switch便携投影底座DIY:3D打印与硬件改造实战指南
1. 项目概述:当Switch遇上投影,一场桌面上的大屏革命作为一个折腾过不少游戏机外设的玩家,我一直在想,有没有办法让Switch的“便携”属性再进化一步?官方底座接电视固然爽,但总被一根线缆束缚在客厅。直到我…...