【论文复现】分割万物-SAM

📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


❀ 分割万物-SAM
- 介绍
- 原理
- 分割任务
- 任务
- 预训练
- zero-shot transfer
- 相关任务
- 模型
- Image Encoder
- Prompt Encoder
- Mask Eecoder
- 消除歧义
- 高效
- Loss 和训练细节
- 推理与部署
- 读取图片
- 选择模型
- 加载模型
- prompt
- 推理
- WebUI
介绍
Segment Anything(SAM)是 Meta/FAIR 提出的以 data-centric AI 理念搭建的机器视觉分割模型,堪称图像分割领域的 GPT!SAM 在 1100w 张图片上镜像训练,拥有分割万物的能力。无论是庞然大物、还是精细入微,都可以准确区分。
可以点击此处体验模型demo。
论文地址见此。
原理
分割任务
任务
任务(Task)是由 NLP 领域带来的灵感。在 NLP 中通过预测 next token 作为预训练的任务,在下游任务中使用 prompt engineering 作为应用。出于图像分割的需要,SAM 将prompt 分为以下几种类型:
- point
- box
- mask
- 文本
本文所涉及的所有资源的获取方式:这里
预训练
可提示的分割任务提出一种自然的预训练算法,模拟多种 sequence 的 prompt,并且每一次训练都与 ground truth 进行比较。
zero-shot transfer
预训练任务赋予了模型在推理时对任何提示做出适当反应的能力,因此下游任务可以通过设计合适的提示来解决。例如在实例分割中,可以提供一个检测得到的 box, SAN 就可以利用该 promp 进行实例分割。
相关任务
分割可以细分出很多领域:交互式分割、边缘检测、超像素化、目标提案生成、前景分割、语义分割、实例分割、全景分割等。而SAM时一个具有广泛适用性的模型,通过 prompt 可以适应许多现有的和新的分割任务。
模型
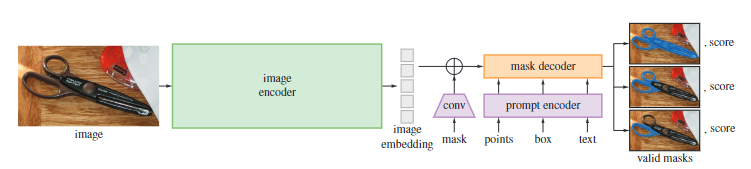
上图展示了 SAM 的结构。SAM 由以下三个部分组成。
Image Encoder
使用 MAE 预训练 ViT 模型处理高解析输入。Image Encoder 对每张图像运行,并用于提示模型。
Prompt Encoder
模型设计了两种 prompt:稀疏(points,boxes,text)、密集(masks)。点和框使用位置编码表示,与每种 prompt 的 learned embedding 相加。而文本使用来自 CLIP 的现成文本 encoder。密集型提示使用卷积进行 embedded, 与图像 embedding 相加。
Mask Eecoder
该部分有效地将 image embedding、 prompt embedding、 和输出 token 映射到一个 mask 上。修改 transformer decoder 块,将 image embedding 和prompt embedding 做双向的 cross-attention。
消除歧义
只有一个输出的情况下,如果给了一个模棱两可的提示,模型会对多个有效的 mask 进行平均处理。为了解决这个问题,模型被修改为对单个提示预测多个输出。而且可以发现,三个输出就可以解决大多数常见情况。
高效
模型设计得非常高效,在 web 浏览器上 CPU 计算只需要约 50 ms。、
Loss 和训练细节
主要使用 focal loss 和 dice loss。对于每个 mask 模型会随机产生 11 种 prompt 进行配对。
推理与部署
大部分可以使用的推理场景在文件中的 notebook 中,打开后可以根据自己的需要运行任何一个部分。
此处介绍模型的推理方法。
首先确保安装对应的依赖
pip install git+https://github.com/facebookresearch/segment-anything.git
pip install opencv-python pycocotools matplotlib onnxruntime onnx gradio
读取图片
需要使用 opencv 读取图片,使用以下代码读取一张图像:
import cv2
image = cv2.imread('imgs/example.jpg')
选择模型
SAM有三种模型可以选择,分别为sam_vit_l_0b3195、sam_vit_b_01ec64、sam_vit_h_4b8939。规模、效果以及需要的算力依次增加。
sam_checkpoint = "checkpoint/sam_vit_h_4b8939.pth"
model_type = "vit_h"device = "cuda"
加载模型
使用sam_model_registry 加载指定的模型并得到预测器。将图片作为预测器的输入即可。
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)predictor = SamPredictor(sam)predictor.set_image(image)
prompt
SAM 可以接受多种形式的prompt。例如多个点和一个方框。同时也需要提供对应的标签。
import numpy as np
input_point = np.array([[300, 300], [350, 350]])
input_label = np.array([1, 1])
input_box = np.array([150, 100, 320, 500])
推理
推理只需要使用预测器的 predict 函数,该函数接受多个点输入,最多一个方框的输入,与对应的标签。multimask_output 表示是否输出多个预测。masks 即为模型的预测结果。
masks, _, _ = predictor.predict(point_coords=input_point,point_labels=input_label,box=input_box[None, :],multimask_output=False,
)
WebUI
为了方便大家操作,制作了一个可以输入提示的网站。使用python webui.py即可启动网站。
在 Point 一栏输入点的横纵坐标,SAM 就可以去识别点所标记的物体。支持多个点输入,例如(100,150)(250,300)就输入 “100 150 250 300” 即可。点击右侧的 Add 将点添加进 prompt 中。点击 Preview 可以预览点所在的位置。没有任何输入时点击预览可以查看图片的坐标轴。点击底部的 Run 即可根据输入的 prompt 分割图像,分给结果展示在下方。
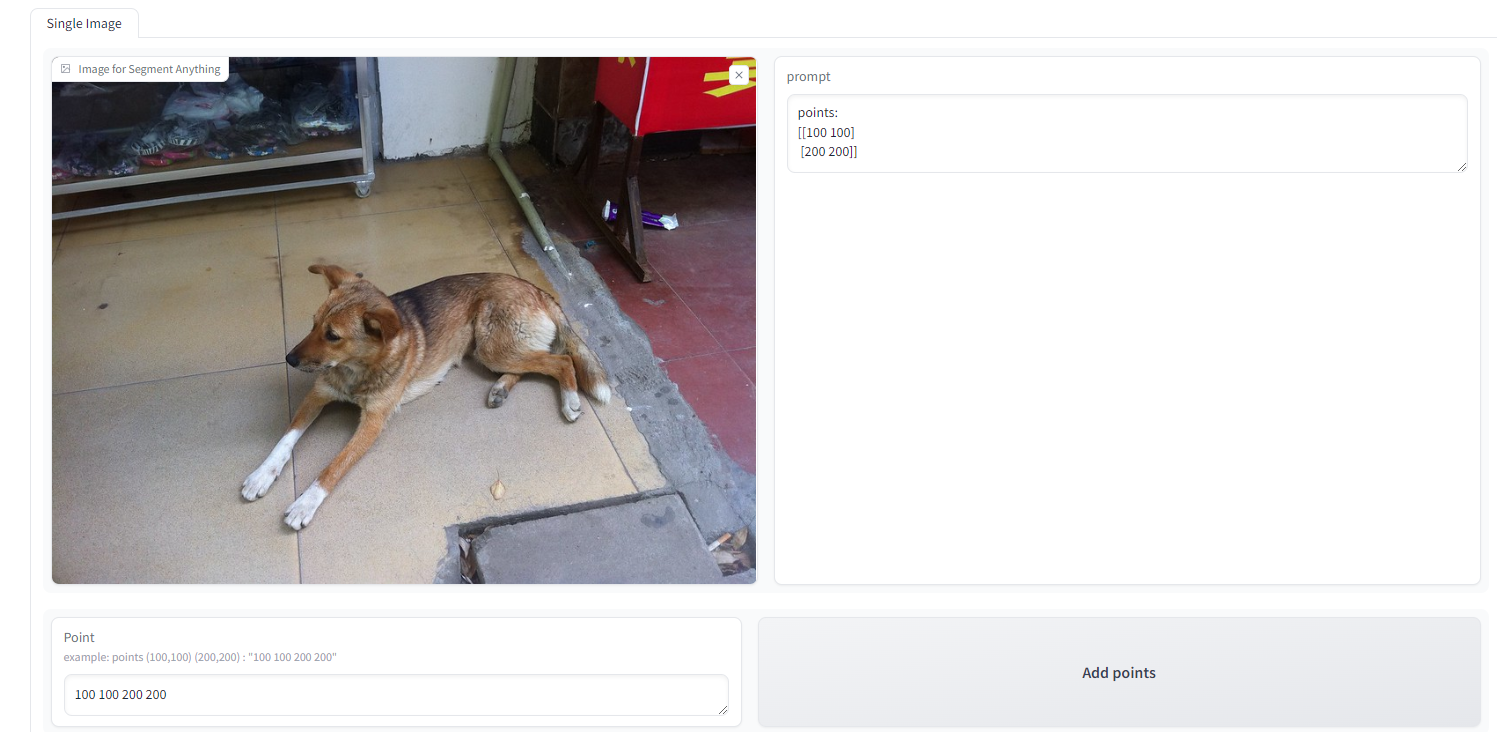


在 Box 一栏输入方框左上角的横纵坐标与右下角的横纵坐标。方框(100,100,200,200)和(300,300,500,500)就输入为"100 100 200 200 300 300 500 500 "点击右侧的 Add 将方框添加进 prompt 中。点击 Run 运行,现在不支持点和方框的混合输出。


编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里
相关文章:
【论文复现】分割万物-SAM
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ 分割万物-SAM 介绍原理分割任务任务预训练zero-shot transfer相关任务 模型Image EncoderPrompt EncoderMask Eecoder消除歧义高效Loss 和训…...

实现RAGFlow-0.14.1的输入框多行输入和消息框的多行显示
一、Chat页面输入框的修改 1. macOS配置 我使用MacBook Pro,chip 是 Apple M3 Pro,Memory是18GB,macOS是 Sonoma 14.6.1。 2. 修改chat输入框代码 目前RAGFlow前端的chat功能,输入的内容是单行的,不能主动使用Shift…...

Pointnet++改进71:添加LFE模块|高效长距离注意力网络
简介:1.该教程提供大量的首发改进的方式,降低上手难度,多种结构改进,助力寻找创新点!2.本篇文章对Pointnet++特征提取模块进行改进,加入LFE模块,提升性能。3.专栏持续更新,紧随最新的研究内容。 目录 1.理论介绍 2.修改步骤 2.1 步骤一 2.2 步骤二 2.3 步骤三 1.理…...

C++STL容器vector容器大小相关函数
目录 前言 主要参考 vector::size vector::max_size vector::resize vector::capacity vector::empty vector::reserve vector::shrink_to_fit 共勉 前言 本文将讨论STL容器vector中与迭代器相关的函数,模板参数T为int类型。 主要参考 cpluscplus.com 侯…...

阿里云CPU超载解决记录
现象:阿里云CPU使用率超90%连续5分钟告警,项目日志error.log中存在heap/gc/limit等内存耗尽等信息,阿里云慢查询日志每日有查询时间很长的参数一直不变的慢sql,linux服务器使用top命令并按c可以看到cpu过大是哪个命令行造成的 分…...

【工具变量】上市公司企业商业信用融资数据(2003-2022年)
一、测算方式:参考《会计研究》张新民老师的做法 净商业信用NTC(应付账款应付票据预收账款)-(应收账款应收票据预付账款),用总资产标准化; 应付账款AP应付账款应付票据预收账款,用总资产标准化 一年以上应付账款比例LAP是企业一年以上(包括一…...

2024数字科技生态大会 | 紫光展锐携手中国电信助力数字科技高质量发展
2024年12月3日至5日,中国电信2024数字科技生态大会在广州举行,通过主题峰会、多场分论坛、重要签约及合作发布等环节,与合作伙伴共绘数字科技发展新愿景。紫光展锐作为中国电信的战略合作伙伴受邀参会,全面呈现了技术、产品创新进…...
概括)
ES语法(一)概括
一、语法 1、请求方式 Elasticsearch(ES)使用基于 JSON 的查询 DSL(领域特定语言)来与数据交互。 一个 ElasticSearch 请求和任何 HTTP 请求一样由若干相同的部件组成: curl -X<VERB> <PROTOCOL>://&l…...

(vue)el-cascader多选级联选择器,值取最后一级的数据
(vue)el-cascader多选级联选择器,取值取最后一级的数据 获取到:[“养殖区”,“鸡棚”,“E5001”] 期望:[“E5001”] 问题: 解决方法 增加change事件方法,处理选中的value值 1.单选 <el-cascaderv-model"tags2":o…...

友思特方案 | 精密制程的光影贴合:半导体制造中的高功率紫外光源
导读 为新能源锂电行业赋能第四站:半导体制造中的高功率紫外光源!稳定输出、灵活控制的曝光设备是新能源/半导体行业高端生产中减少误差、提高效率的核心技术,友思特 ALE 系列 UV LED 紫外光源集合6大优势,为精密制造的健康发展提…...

README写作技巧
做一个项目,首先第一眼看上去要美观,这样才有看下去的动力。做项目亦是如此,如果每一步应付做的话,我想动力也不会太大,最终很大概率会放弃或者进度缓慢。 1.README组成 README是对项目的一个说明,它对观看…...

【密码学】分组密码的工作模式
1.电码本模式(ECB) 优点: 每个数据块独立加密,可并行加密,实现简单。 缺点: 相同明文会产生相同密文,不具备数据完整保护性。 适用于短消息的加密传输 (如一个加密密钥)。 工作流程:用相同的密钥分别对…...

SQL 和 NoSQL 有什么区别?
SQL(Structured Query Language,结构化查询语言)和NoSQL数据库是两种不同类型的数据库管理系统,它们在多个方面存在显著的区别。以下是对SQL和NoSQL主要区别的详细分析: 一、数据存储与模型 SQL数据库 使用关系模型来…...

提升网站流量的关键:AI在SEO关键词优化中的应用
内容概要 在当今数字时代,提升网站流量已成为每个网站管理员的首要任务。而人工智能的技术进步,为搜索引擎优化(SEO)提供了强有力的支持,尤其是在关键词优化方面。关键词是连接用户需求与网站内容的桥梁,其…...

Harnessing Large Language Models for Training-free Video Anomaly Detection
标题:利用大型语言模型实现无训练的视频异常检测 原文链接:https://openaccess.thecvf.com/content/CVPR2024/papers/Zanella_Harnessing_Large_Language_Models_for_Training-free_Video_Anomaly_Detection_CVPR_2024_paper.pdf 源码链接:ht…...

如何通过自学成长为一名后端开发工程师?
大家好,我是袁庭新。最近,有星友向我提出了一个很好的问题:如何通过自学成为一名后端开发工程师? 为了解答这个疑问,我特意制作了一个视频来详细分享我的看法和建议。 戳链接:如何通过自学成长为一名后端开…...

HDR视频技术之六:色调映射
图像显示技术的最终目的就是使得显示的图像效果尽量接近人们在自然界中观察到的对应的场景。 HDR 图像与视频有着更高的亮度、更深的位深、更广的色域,因此它无法在常见的普通显示器上显示。 入门级的显示器与播放设备(例如普通人家使用的电视࿰…...
P11060 【MX-X4-T0】「Jason-1」x!)
(洛谷题目)P11060 【MX-X4-T0】「Jason-1」x!
思路: 理解问题:首先,我们要理解题目的要求,即判断一个非负整数n的阶乘n!是否是n1的倍数。 阶乘的定义:根据阶乘的定义,n!是所有小于等于n的正整数的乘积。特别地,0!被定义为1。 特殊情况处理…...

TEXT2SQL工具vanna本地化安装和应用
TEXT2SQL工具vanna本地化安装和应用 Vanna和Text2SQL环境安装和数据准备 conda虚拟环境安装数据准备ollama环境准备 ollama安装和运行ollama下载模型测试下API方式正常使用 chromaDB的默认的embedding模型准备 vanna脚本跑起来 Vanna和Text2SQL TEXT2SQL即文本转SQL…...

Bloom 效果
1、Bloom 效果是什么 Bloom效果(中文也可以叫做高光溢出效果),是一种使画面中亮度较高的区域产生一种光晕或发光效果的图像处理技术,Bloom效果的主要目的是模拟现实世界中强光源在相机镜头或人眼中造成的散射和反射现象ÿ…...

终极指南:FigmaCN中文插件让设计师告别英文障碍
终极指南:FigmaCN中文插件让设计师告别英文障碍 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的全英文界面而烦恼吗?Figma中文插件FigmaCN正是为你…...

HoRain云--Skills 工作原理
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...
)
py每日spider案例之某guangdong省人mingzhengfu登录接口(难度高 )
加密入口: 逆向接口: sm2密钥接口: js逆向代码: const fs = require("fs"); const path = re...

AI智能体容器化开发实践:基于AgentBox构建安全可复现的沙盒环境
1. 项目概述:AgentBox,一个为AI智能体打造的“沙盒”开发环境最近在折腾AI智能体(Agent)的开发,发现一个挺有意思的现象:很多开发者,包括我自己在内,在初期搭建智能体应用时…...

FastbootEnhance:面向Windows用户的终极Fastboot工具箱与Payload提取器指南
FastbootEnhance:面向Windows用户的终极Fastboot工具箱与Payload提取器指南 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance FastbootE…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

【HarmonyOS 6.1 全场景实战】《灵犀厨房》之【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑”
【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑” 摘要:从“爱吃什么”到“该吃什么”,是《灵犀厨房》进化的关键一步。上一篇我们刚打通了 Health Kit 数据,今天,我们就要基于 Mifflin-St Jeor …...

3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍
3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过这样的情况࿱…...

线程化笔记工具:重塑深度思考与知识管理的技术实践
1. 项目概述:一个为线程化思考而生的笔记工具最近在折腾个人知识管理工具时,发现了一个挺有意思的开源项目:alishobeiri/thread-notebook。乍一看名字,可能会以为是又一个普通的Markdown笔记本应用。但深入使用后,我发…...

紧急更新!Midjourney 6.2.1已悄然修复碳素印相的硫化银衰减模拟缺陷——但97%用户仍在用旧参数,立即校准你的工作流
更多请点击: https://intelliparadigm.com 第一章:碳素印相的视觉本质与Midjourney 6.2.1修复的底层动因 碳素印相的物质性光感逻辑 碳素印相并非数字渲染的模拟,而是一种基于明胶-碳黑颗粒物理沉积的连续调成像工艺。其高密度阴影区呈现哑…...