数据分析类论文通过stata进行数据预处理(一)
一:导入数据
打开Stata命令窗口,输入以下命令:
use "文件路径\数据文件名.dta", clear
其中,.dta是Stata的数据文件格式。clear选项用于在打开新数据文件前关闭当前数据集。
以下是一些导入不同格式数据的方法:
import excel "path_to_file.xlsx", firstrow clear
firstrow选项表示数据的第一行包含变量名。
二:删除和保留变量
删除多个变量:
drop 变量名1 变量名2 变量名3
删除变量列表:
drop 变量名1-变量名N
删除除指定变量外的所有变量(即保留指定变量):
keep 变量名1 变量名2三:重命名变量
重命名单个变量:
rename 旧变量名 新变量名四:生成新变量
使用generate命令(gen)
generate 命令(通常简写为 gen)是最常用的方法来创建一个新变量。
gen 新变量名 = 表达式
例如,如果想根据变量 age 生成一个表示年龄是否大于30的新变量 age_gt_30,可以这样写:
gen age_gt_30 = (age > 30)
这将创建一个虚拟变量(0或1),其中1表示年龄大于30,0表示不大于30。
五:标签变量和值
在Stata中,为变量和它们的值添加标签可以使数据集更易于理解和分析。以下是如何在Stata中给变量和值添加标签的方法:
要给变量添加标签,可以使用 label variable 命令:
label variable 变量名 "标签文本"
例如,如果有一个名为 age 的变量,你可以这样给它添加标签:
label variable age "年龄"
要给变量的特定值添加标签,可以使用 label define 和 label values 命令。
首先,使用 label define 命令创建一个标签定义:
label define 标签名 value1 "标签文本1" value2 "标签文本2" ...
例如,如果有一个名为 gender 的变量,其值为1和2,分别代表男性和女性,可以这样定义标签:
label define gender_lbl 1 "男性" 2 "女性"
然后,使用 label values 命令将标签定义应用到变量上:
label values 变量名 标签名
继续上面的例子:
label values gender gender_lbl
现在,变量 gender 的值1和2将分别显示为“男性”和“女性”。
以下是一个完整的例子,展示了如何给一个变量及其值添加标签:
* 创建一个新变量
gen gender = 1 if sex == "male"
replace gender = 2 if sex == "female"* 给变量添加标签
label variable gender "性别"* 定义值的标签
label define gender_lbl 1 "男性" 2 "女性"* 将标签应用到变量
label values gender gender_lbl
通过给变量和值添加标签,你可以使Stata输出结果更加清晰,特别是在生成表格和图表时。
六:数据类型转换
在Stata中,数据类型转换是一个常见的操作,因为它确保了数据以正确的格式存储,这对于后续的分析至关重要。以下是在Stata中进行数据类型转换的方法:
如果有一个字符串变量,但需要将其转换为数值型变量,可以使用 generate (gen) 命令结合 real() 或 float() 函数:
gen newvar = real(oldvar)
或者,如果数据是浮点数,可以使用:
gen newvar = float(oldvar)
如果转换过程中遇到非数值字符,Stata会将那些观测值设置为缺失值(.)。
将数值型变量转换为字符串变量,可以使用 generate (gen) 命令结合 string() 函数:
gen newvar = string(oldvar)
可以指定转换后的字符串长度:
gen newvar = string(oldvar, "%10.2f")
destring 命令用于将字符串变量转换为数值型变量,它比 real() 或 float() 函数提供了更多的选项来处理转换过程中可能遇到的错误:
destring oldvar, generate(newvar) [options]
选项包括:
replace:替换原有变量而不是生成新变量。force:即使遇到无法转换的字符也继续转换其他值。ignore("string"):忽略指定的字符串,将其视为缺失值。
在转换数据类型时,确保目标数据类型能够容纳原始数据,以避免数据丢失。如果字符串变量包含非数值字符,转换可能会导致数据丢失或转换为缺失值。
七:排序数据
在Stata中,排序数据是一个基本的数据管理操作,它可以帮助你按照特定的变量顺序排列数据集。以下是在Stata中排序数据的方法:
sort 命令是Stata中最常用的排序命令。允许按照一个或多个变量的升序(默认)或降序来排列数据。
要按照单个变量升序排序,可以使用以下命令:
sort variable_name
如果要按降序排序,可以在变量名后添加 desc:
sort variable_name desc
也可以按照多个变量进行排序。首先按照第一个变量排序,然后在第一个变量值相同的情况下,按照第二个变量排序,依此类推。
sort variable1 [variable2 [variable3 ...]] [desc]
例如,如果想先按age升序排序,然后在age相同的情况下按income降序排序,可以使用:
sort age income desc
八:合并数据集
在Stata中,合并数据集是一个常见的操作,它允许用户将两个或多个数据集合并成一个。
merge 命令用于根据一个或多个键变量(key variables)将两个数据集合并。
merge [merge_options] [keyvarlist] using filename [if] [in] [, options]
merge_options可以是1:1,m:1, 或1:m,指定合并的类型。keyvarlist是在两个数据集中都存在的变量,用于匹配记录。filename是要合并的第二个数据集的文件名。[if]和[in]是可选的条件语句,用于限制合并的范围。options是其他可选参数,如update或replace。
一对一合并两个数据集,假设它们都有名为id的键变量:
merge 1:1 id using another_dataset.dta
多对一合并,其中第一个数据集的每条记录可以与第二个数据集的多条记录匹配:
merge m:1 id using another_dataset.dta
- 在合并之前,两个数据集应该根据键变量进行排序。
- 合并后,Stata会在结果数据集中添加一个名为
_merge的变量,它指示每条记录的合并状态(3个可能的值:1表示只在第一个数据集中,2表示只在第二个数据集中,3表示在两个数据集中都存在)。
九:数据检查
在Stata中进行数据检查是确保数据质量的重要步骤。以下是一些常用的方法来检查数据:
describe 命令提供数据集的基本信息,包括变量名称、类型、标签和观测值数量。
describe
summarize 命令:提供变量的统计概要,包括均值、标准差、最小值、最大值、中位数等。
summarize
list 命令:可以列出数据集中的特定观测值,特别是缺失值。
list varname if varname == .misstable 命令:提供详细的缺失值报告。
misstable summarize
tabulate 命令用于分类变量,可以检查分类变量的分布。
tabulate varname
histogram 命令:绘制变量的直方图,帮助识别异常值。
histogram varname
graph box 命令:绘制箱线图,用于识别异常值。
graph box varname
assert 命令:用于检查数据是否满足特定的逻辑条件。如果不满足,会显示错误。
assert varname > 0
codebook 命令:提供变量的详细信息,包括值标签和缺失值的数量。
codebook varname
十:处理缺失值
在Stata中处理缺失值是数据分析前的重要步骤。以下是一些处理缺失值的常用方法:
删除含有缺失值的观测:
drop if varname == .
删除所有含有缺失值的变量:
drop varname if missing(varname)
使用固定值替换缺失值:
replace varname = value if varname == .
使用变量的均值、中位数、众数等统计量替换缺失值:
summarize varname, detail
replace varname = r(mean) if varname == .
使用线性插值(适用于时间序列数据):
ipolate varname timevar, generate(newvarname)
使用多重插补(Multiple Imputation)
Stata提供了mi命令集来进行多重插补,这是一个更高级的处理缺失值的方法。
mi set mlong
mi register imputed varname
mi impute chained (regress) varname = othervars, add(5)
mi estimate: regress dependentvar varname othervars
如果数据是面板数据(panel data),可以使用其他时间点的观测值来填充缺失值:
bysort id: egen varname_fill = mean(varname)
replace varname = varname_fill if varname == .
drop varname_fill
使用统计模型预测缺失值,并将预测值填充到缺失的位置:
regress varname othervars
predict varname_pred
replace varname = varname_pred if varname == .
drop varname_pred
- 在处理缺失值之前,了解缺失数据的机制(完全随机缺失、随机缺失、非随机缺失)是非常重要的,因为这会影响处理方法的选择。
- 删除缺失值可能会导致样本量减少,从而影响分析结果的可靠性。
- 替换缺失值可能会引入偏差,特别是如果缺失不是完全随机的。
- 多重插补是一个相对复杂的过程,但它可以提供更稳健的估计,因为它考虑了缺失值的不确定性。
相关文章:
)
数据分析类论文通过stata进行数据预处理(一)
一:导入数据 打开Stata命令窗口,输入以下命令: use "文件路径\数据文件名.dta", clear其中,.dta是Stata的数据文件格式。clear选项用于在打开新数据文件前关闭当前数据集。 以下是一些导入不同格式数据的方法&#x…...

力扣——1.返回字符串中第一个唯一的字符;2.把字符串转换成整数(C++)
1.返回字符串中第一个唯一的字符 1.1题目描述 给定一个字符串s ,找到它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。 示例: 1.2思路 这里提供两种思路:第一种是利用哈希表,先遍历一…...
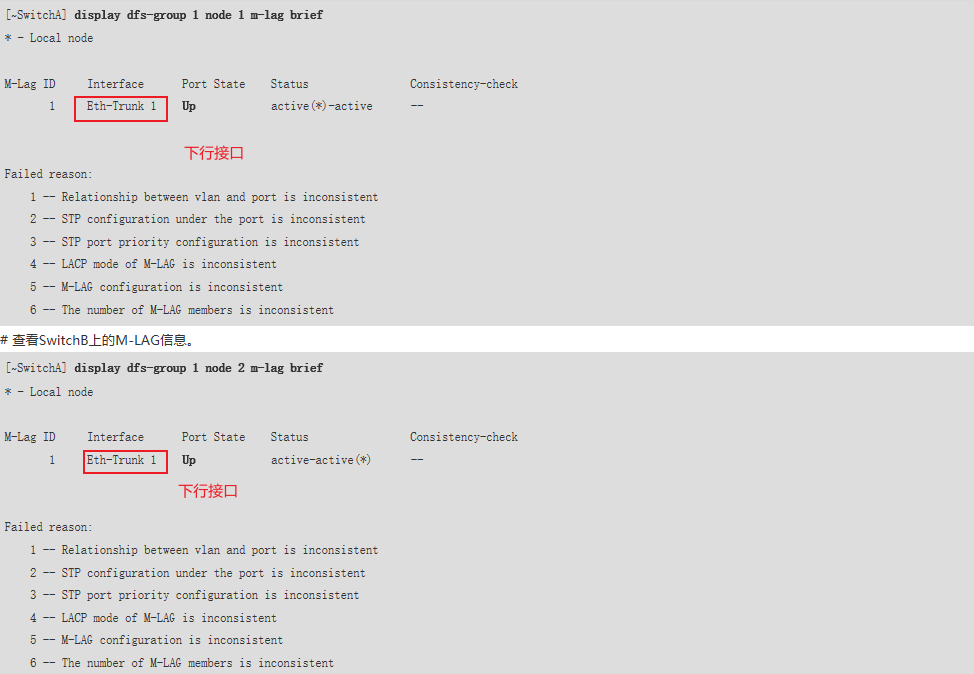
M-LAG【根桥方式】
1.M-LAG不是有单向隔离机制天然防环吗,为什么还要使用STP? 答:因为M-LAG设备下面不是只接服务器,也不是和所有下联设备组成M-LAG,和没有组成M-LAG的设备可能会造成环路。 2.为什么要关闭peer-link接口的生成树计算&a…...

新书速览|循序渐进Node.js企业级开发实践
《循序渐进Node.js企业级开发实践》 1 本书内容 《循序渐进Node.js企业级开发实践》结合作者多年一线开发实践,系统地介绍了Node.js技术栈及其在企业级开发中的应用。全书共分5部分,第1部分基础知识(第1~3章)…...

Xlsxwriter生成Excel文件时TypeError异常处理
在使用 XlsxWriter 生成 Excel 文件时,如果遇到 TypeError,通常是因为尝试写入的值或格式与 XlsxWriter 的限制或要求不兼容。 1、问题背景 在使用 Xlsxwriter 库生成 Excel 文件时,出现 TypeError: “expected string or buffer” 异常。此…...

【NLP高频面题 - LLM架构篇】大模型使用SwiGLU相对于ReLU有什么好处?
【NLP高频面题 - LLM架构篇】大模型使用SwiGLU相对于ReLU有什么好处? 重要性:★★★ 💯 NLP Github 项目: NLP 项目实践:fasterai/nlp-project-practice 介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化…...

2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析
2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析 完整代码请私聊 博主 # 一、背景 肥料是农业生产中一种重要的生产资料,其生产销售必须遵循《肥料登记管理办法》,依法在农业行政管理部门进行登记。各省、自治区、直辖市人民政府农业行政主管部门主…...

网络原理之 IP 协议
目录 1. IP 协议报文格式 2. 网段划分 3. 地址管理 1) 动态分配 2) NAT 机制 (网络地址转换) 3) IPv6 4. 路由选择 1. IP 协议报文格式 IP 协议是网络层的重点协议。 网络层要做的事情,主要就是两方面: 1) 地址管理 制定一系列的规则ÿ…...
来在开发过程中更快速地看到页面的变化。)
在 Spring Boot 项目中使用 Thymeleaf 时,通常情况下,你需要配置热加载(Hot Reload)来在开发过程中更快速地看到页面的变化。
配置步骤: 1. 添加 DevTools 依赖 在 pom.xml 中添加 spring-boot-devtools 依赖。DevTools 提供了自动重启、LiveReload、模板热加载等功能。 <dependencies><!-- Spring Boot DevTools (用于热加载) --><dependency><groupId>org.spri…...

arm-linux GPIO控制-脚本及shell格式
以下是针对BCM编号27, 28, 29, 30, 31的shell命令 shell方式 导出GPIO引脚 echo 27 > /sys/class/gpio/export echo 28 > /sys/class/gpio/export echo 29 > /sys/class/gpio/export echo 30 > /sys/class/gpio/export echo 31 > /sys/class/gpio/export 设…...

Go 语言基础知识语法
很早听人说过一句话:“每年学习(接触)一门新的编程语言”,这听起来可能有点不太现实,但是其实很多种语言都是相通的。掌握新的编程语言不仅仅是增加职业工具箱中的工具,更是一种扩展我们思维方式、解决问题…...

贪心算法part05
文章参考来源代码随想录 (programmercarl.com) 56. 合并区间 本题和前几题类似,都是判断上一个元素的右边界与当前元素的左边界大小关系 但是需要注意是:本题需要更新结果数组元素的右边界,因此比较的是数组最后一个元素右边界与当前元素左…...
)
02、SpringMVC核心(上)
一、RequestMapping注解 @Target({ElementType.TYPE, ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented @Mapping @Reflective({ControllerMappingReflectiveProcessor.class}) public @interface RequestMapping {String name() default "";…...

EasyPlayerPro的同一个组件实例根据url不同展示视频流
效果 学习 url的组成 webrtc://192.168.1.225:8101/index/api/webrtc?applive&stream001&typeplay 协议部分 webrtc://: 这表示使用 WebRTC 协议来进行实时通信。WebRTC 允许浏览器之间直接交换音频、视频和其他数据,而不需要通过中间服务器 主机和端口部分…...
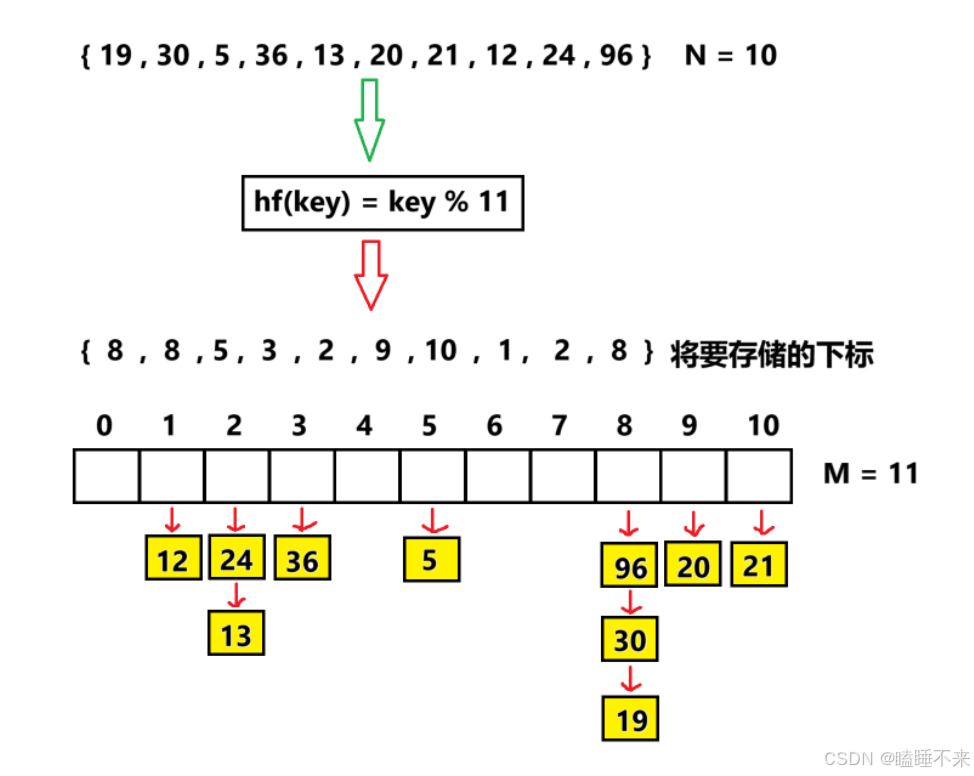
哈希表介绍、实现与封装
哈希表介绍、实现与封装 一、哈希概念二、哈希表实现直接定址法其他映射方法介绍1. 哈希冲突2. 负载因子3. 将关键字转为整数4. 设计哈希函数除法散列法 / 除留余数法乘法散列法全域散列法其他方法 将关键字转为整数处理哈希冲突开放定址法线性探测二次探测双重散列 开放定址法…...

使用vm配置网络
查看本地ip 配置vm网络 配置固定ip vi /etc/sysconfig/network-script/ifcfg-ens33参考 vm使用nat模式,导致vm中docker部署的服务,无法通过局域网中其他机器连接 https://www.cnblogs.com/junwind/p/14345385.html 三张图看懂vm中,三种网…...

OpenStack介绍
OpenStack概述 OpenStack是一个开源的云计算管理平台软件,主要用于构建和管理云计算环境。它允许企业或组织通过数据中心的物理服务器创建和管理虚拟机、存储资源和网络等云计算服务。其核心组件包括计算(Nova)、网络(Neutron)、存储(Cinder、Swift)等。这些组件相互协作…...

力扣93题:复原 IP 地址
力扣93题:复原 IP 地址(C语言实现详解) 题目描述 给定一个只包含数字的字符串 s,复原它并返回所有可能的 IP 地址格式。 有效的 IP 地址需满足以下条件: IP 地址由四个整数(每个整数位于 0 到 255 之间…...

mock.js介绍
mock.js http://mockjs.com/ 1、mock的介绍 *** 生成随机数据,拦截 Ajax 请求。** 通过随机数据,模拟各种场景;不需要修改既有代码,就可以拦截 Ajax 请求,返回模拟的响应数据;支持生成随机的文本、数字…...

React开发 - 技术细节汇总一
React简介 React 是一个声明式,高效且灵活的用于构建用户界面的 JavaScript 库。使用 React 可以将一些简短、独立的代码片段组合成复杂的 UI 界面,这些代码片段被称作“组件”。 ui render (data) -> 单向数据流 MVC // model var myapp {}; // …...

Photoshop快速导出图层终极指南:如何高效批量处理设计文件
Photoshop快速导出图层终极指南:如何高效批量处理设计文件 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目地址:…...

Windows用户的救星:APK Installer让你在电脑上轻松运行Android应用
Windows用户的救星:APK Installer让你在电脑上轻松运行Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上体验Androi…...

3个高级功能解锁NIPAP企业级IP地址管理潜力
3个高级功能解锁NIPAP企业级IP地址管理潜力 【免费下载链接】NIPAP Neat IP Address Planner - NIPAP is the best open source IPAM in the known universe, challenging classical IP address management (IPAM) systems in many areas. 项目地址: https://gitcode.com/gh_…...

命令行故障自动修复工具 fix-my-claw:原理、插件架构与实战指南
1. 项目概述:一个修复“爪子”的实用工具最近在GitHub上看到一个挺有意思的项目,叫caopulan/fix-my-claw。光看名字,你可能会有点摸不着头脑——“爪子”是什么?需要修复什么?这其实是一个典型的、由开发者社区需求催生…...

CST 2023 GPU加速实战:从硬件选型到性能验证,一份给仿真工程师的避坑清单
CST 2023 GPU加速实战:从硬件选型到性能验证,一份给仿真工程师的避坑清单 当电磁仿真项目规模从实验室级别扩展到工业级应用时,计算资源的需求往往呈指数级增长。我曾见证过一个汽车雷达天线阵列的仿真案例:采用传统CPU计算需要72…...

VIO实战:从理论到代码,详解相机与IMU时间戳软同步的两种核心算法
1. 时间戳同步:VIO系统的隐形守护者 第一次接触VIO系统时,我被一个看似简单的问题困扰了很久:为什么明明IMU和相机数据都对,但融合结果总是出现微妙的偏差?直到某天深夜调试代码时,突然发现两个传感器的时…...

西门子PLC通信必备:手把手教你用SCL编写Modbus RTU CRC校验功能块
西门子PLC通信实战:SCL实现Modbus RTU CRC校验的工程化解决方案 在工业自动化领域,可靠的数据通信如同设备的神经系统。当两台PLC需要通过RS485接口交换温度传感器读数时,Modbus RTU协议因其简洁高效成为首选。但许多工程师在调试阶段都会遇到…...
)
手把手教你给STM32MP157开发板接上HDMI显示器(基于Sii9022A芯片与设备树配置)
STM32MP157开发板HDMI显示实战:从硬件连接到设备树配置全解析 引言 当你第一次拿到STM32MP157开发板时,最令人兴奋的莫过于看到图形界面在屏幕上亮起的那一刻。但现实往往很骨感——手头可能没有配套的LCD屏幕,而HDMI显示器却是大多数开发者桌…...

UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界
UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA UABEA(Unity Asset Bundle Extractor Avalonia&#…...

Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间
Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的Windows电脑是否经常提示C盘空间不足ÿ…...