每日一刷——二叉树的构建——12.12
第一题:最大二叉树
题目描述:654. 最大二叉树 - 力扣(LeetCode)



我的想法:
我感觉这个题目最开始大家都能想到的暴力做法就是遍历找到数组中的最大值,然后再遍历一遍,把在它左边的依次找到最大值,但是emmm,感觉效率很低,时间上肯定过不了
然后其实我会觉得这个题目跟大根堆和小根堆有一点像,,,就是先建立一个树来,然后如果大就上去,如果小就下来,但是有一点,怎么保证顺序??因为这样先建立一棵树来,再上移,好像不能保证??我浅浅画个图

那这样,是让6之后的全部向上移动吗,移动到6的右边?
题目分析:
嗯,看了一圈,好像没有人用小根堆,大根堆写哈,有用单调栈写的,有用DFS写,然后其实我那个初始想法版本也行,因为我的题解给我的就是这样写的,但是有一点不一样的是:它分割了数组+递归,我就是憨憨的非要把每一步写出来哈,,其实每一个节点做的事情一样,就一定一定抽象出来然后递归
就是相当于先找到数组中的最大值,然后左右两边分别交给左右儿子再去做分割
其实这样我们可以总结一个思想就是:
其实每一个节点,都是首先把自己构造出来,然后想办法构造自己的左右子树,就相当于每一个人都有当孩子和当父亲的一天,你要在孩子时期规定此时要做的事,要在父亲时期规定要做的事,然后每一个人的框架都是如此,只不过最后做出来的成果可能不一样
我的错误题解:
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public TreeNode constructMaximumBinaryTree(int[] nums) {// 只要不断地传递就可以了,天哪噜return build(nums, 0, nums.length - 1);}TreeNode build(int[] nums ,int lo,int hi){if(lo>hi)return null;int max=nums[lo];int index=lo;//找到数组中地最大值,然后构建这个节点,再分配左右儿子的数组for(int i=lo+1;i<=hi;i++){if(nums[i]>max){max=nums[i];index=i;}}//一般,数组,====>传递下标,而不是非得要找到这个数是多少//创建这个节点TreeNode root =new TreeNode(max);root.left=build(nums,lo,index-1);root.left=build(nums,index+1,hi);return root;}
}
其实这个错误原因很好分析,一看,我去,右边的好像都没进去,所以直接检查代码,发现root.right写错了,写成了root.left
题解:
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public TreeNode constructMaximumBinaryTree(int[] nums) {// 只要不断地传递就可以了,天哪噜return build(nums, 0, nums.length - 1);}TreeNode build(int[] nums ,int lo,int hi){if(lo>hi)return null;int max=nums[lo];int index=lo;//找到数组中地最大值,然后构建这个节点,再分配左右儿子的数组for(int i=lo+1;i<=hi;i++){if(nums[i]>max){max=nums[i];index=i;}}//一般,数组,====>传递下标,而不是非得要找到这个数是多少//创建这个节点TreeNode root =new TreeNode(max);root.left=build(nums,lo,index-1);root.right=build(nums,index+1,hi);return root;}
}这个题目想清楚了之后,代码写起来和思维都不是很难的
第二题:从前序与中序遍历序列构造二叉树
题目描述:105. 从前序与中序遍历序列构造二叉树 - 力扣(LeetCode)


我的想法:
soga,这个!用前序和中序构建树,这个题目老师原来讲过,挺经典的题的
而且无论是前序还是后序,都必须要知道中序序列,才有唯一的二叉树确定
应该思路是这样的:
先从preorder里边开始,最开始是3 然后在inorder里边找3,3就把inorder分成了两半,左边是左子树里边的,右边就是右子树里边的,然后一直一直这样下去,最后这棵树就建好了(这里的思路有点小问题,看到后面就知道了)
我的题解:
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public TreeNode buildTree(int[] preorder, int[] inorder) {//1.建立头节点//拿到头节点在inorder中的位置,然后分割左右//左边就是新的inorder 右边也是新的inorder//2.建立左右子节点//3.什么时候结束?int index=0;return build(index,preorder,inorder,0,inorder.length-1);}public static TreeNode build(int index,int[] preorder, int[] inorder,int lf,int lr){if(lf<lr)return null;int findplace=0; TreeNode root =new TreeNode(preorder[index-1]);index++;for(int i=0;i<inorder.length;i++){if(inorder[i]==root.val){findplace=i;break;}}//突然感觉index传的不对啊??? 这个index是互通的吗??root.left=build(index,preorder,inorder,lf,findplace-1);root.right=build(index,preorder,inorder,findplace+1,lr);return root;}
}为啥越界了???

题目分析:

for循环遍历确定index效率不高,可以考虑进一步优化:
因为题目说二叉树结点的值不重复,所以我们可以使用一个hashmap存储元素到索引的映射,这样就可以直接通过hashMap查到rootVal对应的index!!
我天!!!我知道了我的有一点的错误了!!
就是在preorder里边遍历,其实是不需要一个一个遍历,怎么说呢,因为你一直把index传给左右两颗子树,但是其实左右两颗子树里边需要的index并不相同,因为它们的元素就不相同,所以这样干,没有考虑周到,笑死我了,根据下面这张图应该能很明显的看到:preorder其实把它分成了这样两个部分

也就是说现在想指向某个值在数组里边对应的下标的时候,可以不需要遍历,直接用hashmap映射就可以了,它的值就是它的下标
题解:
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public static HashMap<Integer,Integer> valToIndex =new HashMap<>();public TreeNode buildTree(int[] preorder, int[] inorder) {//1.建立头节点//拿到头节点在inorder中的位置,然后分割左右//左边就是新的inorder 右边也是新的inorder//2.建立左右子节点//3.什么时候结束?//HashMap优化for(int i=0;i<preorder.length;i++){valToIndex.put(inorder[i],i);}return build(0,preorder.length-1,preorder,inorder,0,inorder.length-1);}public static TreeNode build(int preFirst,int preLast,int[] preorder, int[] inorder,int lf,int lr){if(preFirst>preLast)return null;//分步完善 rootVal index leftSizeint rootVal =preorder[preFirst];int index=valToIndex.get(rootVal);int leftSize=index-lf;//构造父结点TreeNode root =new TreeNode(rootVal);/*有了hashmap这一步可以简化了for(int i=0;i<inorder.length;i++){if(inorder[i]==root.val){findplace=i;break;}} */root.left=build(preFirst+1 , preFirst+leftSize , preorder , inorder , lf , index-1);root.right=build(preFirst+leftSize+1 , preLast , preorder , inorder , index+1 , lr);return root;}
}第三题:根据前序和后序遍历构造二叉树
题目描述:889. 根据前序和后序遍历构造二叉树 - 力扣(LeetCode)


我的想法:
我没有想法,惹惹惹,我在想这两个题有啥区别
我的题解:
题目分析:
前两道题:可以通过前序或者后序遍历找到根节点,然后根据中序遍历结果确定左右子树
但这一道题,可以确定根节点,但是无法确切的知道左右子树有哪些节点
比如:
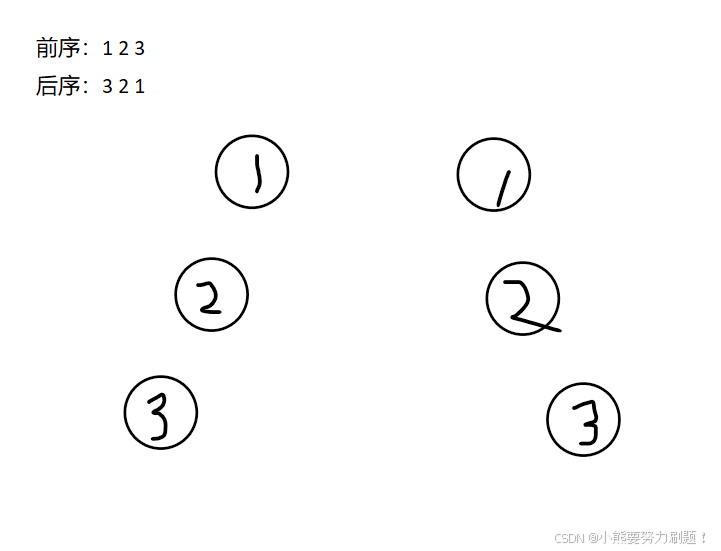
但是解法还是和前两道题差别不大,通过控制左右子树的索引来构建
1.首先把前序遍历结果的第一个元素或者后序遍历结果的最后一个元素作为根节点的值
2.然后把前序遍历结果的第二个元素作为左子树的根节点的值
3.在后序遍历结果中寻找左子树跟节点的值,从而确定了左子树的索引边界,进而确定右子树的索引边界,然后递归构造左右子树即可
题解:
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {//依然是下标到数的hash映射HashMap<Integer,Integer> valToIndex =new HashMap<>();public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {for(int i=0;i<postorder.length;i++){valToIndex.put(postorder[i],i);}return build(preorder,0,preorder.length-1,postorder,0,postorder.length-1);}TreeNode build(int[] preorder,int preStart ,int preEnd,int[] postorder,int postStart,int postEnd){if(preStart > preEnd)return null;if(preStart==preEnd)return new TreeNode(preorder[preStart]);//root节点对应的值就是前序遍历数组的第一个元素int rootVal =preorder[preStart];//root.left 的值是前序遍历元素第二个元素//通过前序和后序遍历构造二叉树的关键在于通过左子树的根节点//确定preorder 和postorder 中左右子树的元素区间int leftRootVal =preorder[preStart+1]; //leftRootVal 在后序遍历数组中的索引int index =valToIndex.get(leftRootVal);//左子树的元素个数int leftSize =index-postStart +1;//先构造出当前根节点TreeNode root =new TreeNode(rootVal);//递归构造左右子树//根据左子树的根节点索引和元素个数推导左右子树的索引边界root.left =build(preorder,preStart+1,preStart+leftSize,postorder,postStart,index);root.right =build(preorder,preStart+leftSize+1,preEnd,postorder,index+1,preEnd-1); //是因为左闭右开吗?? //好像因为要用到两个,preorder里边,一次性用两个,第一个为头节点,第二个为左孩子节点return root;}
}我要背题目!!阿巴
相关文章:
每日一刷——二叉树的构建——12.12
第一题:最大二叉树 题目描述:654. 最大二叉树 - 力扣(LeetCode) 我的想法: 我感觉这个题目最开始大家都能想到的暴力做法就是遍历找到数组中的最大值,然后再遍历一遍,把在它左边的依次找到最大…...
Redis配置文件中 supervised指令
什么是Supervised? supervised模式允许Redis被外部进程管理器监控。通过这个选项,Redis能够在崩溃后自动重启,确保服务的高可用性。常见的进程管理器包括systemd和upstart。 开启方法 vim修改: sudo vi /etc/redis/redis.conf…...
根据基础矩阵(Fundamental Matrix)校正两组匹配点函数correctMatches()的使用)
OpenCV相机标定与3D重建(18)根据基础矩阵(Fundamental Matrix)校正两组匹配点函数correctMatches()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 优化对应点的坐标。 cv::correctMatches 是 OpenCV 库中的一个函数,用于根据基础矩阵(Fundamental Matrix)校…...
python脚本:向kafka数据库中插入测试数据
# coding:utf-8 import datetime import json import random import timefrom kafka import KafkaProducer生产者demo向branch-event主题中循环写入10条json数据注意事项:要写入json数据需加上value_serializer参数,如下代码producer KafkaProducer(val…...
10. 高效利用Excel导入报警信息
高效利用Excel导入报警信息 1.添加报警服务器2.导出报警EXCEL3.报警控件使用1.添加报警服务器 右键项目名称——Add New Sever——Tag Alarm and Event Sever 给报警服务器命名Alarm 给报警服务器分配优先级。如果想要使能历史的话需要和SQL sever配合使用,之前写过。记住这…...

k8s service 配置AWS nlb load_balancing.cross_zone.enabled
在Kubernetes中配置NLB(Network Load Balancer)的跨区域负载均衡(cross-zone load balancing),需要使用服务注解(service annotations)来实现。根据AWS官方文档,以下是配置NLB跨区域…...

国标GB28181网页直播平台EasyGBS国标GB28181-2016协议解读:媒体流保活机制
GB28181-2016在为视频监控系统提供统一的网络视频传输协议。这项标准主要用于公共安全视频监控系统,支持视频监控设备间的互联互通。其主要应用场景包括城市公共安全监控、交通监控、消防监控等。 GB28181-2016标准中的媒体流保活机制,主要是在确保视频…...

面试经验分享 | 杭州某安全大厂渗透测试岗
目录: 所面试的公司:某安全大厂 所在城市:杭州 面试职位:渗透测试工程师 面试过程: 面试官的问题: 1、面试官开始就问了我,为什么要学网络安全? …...
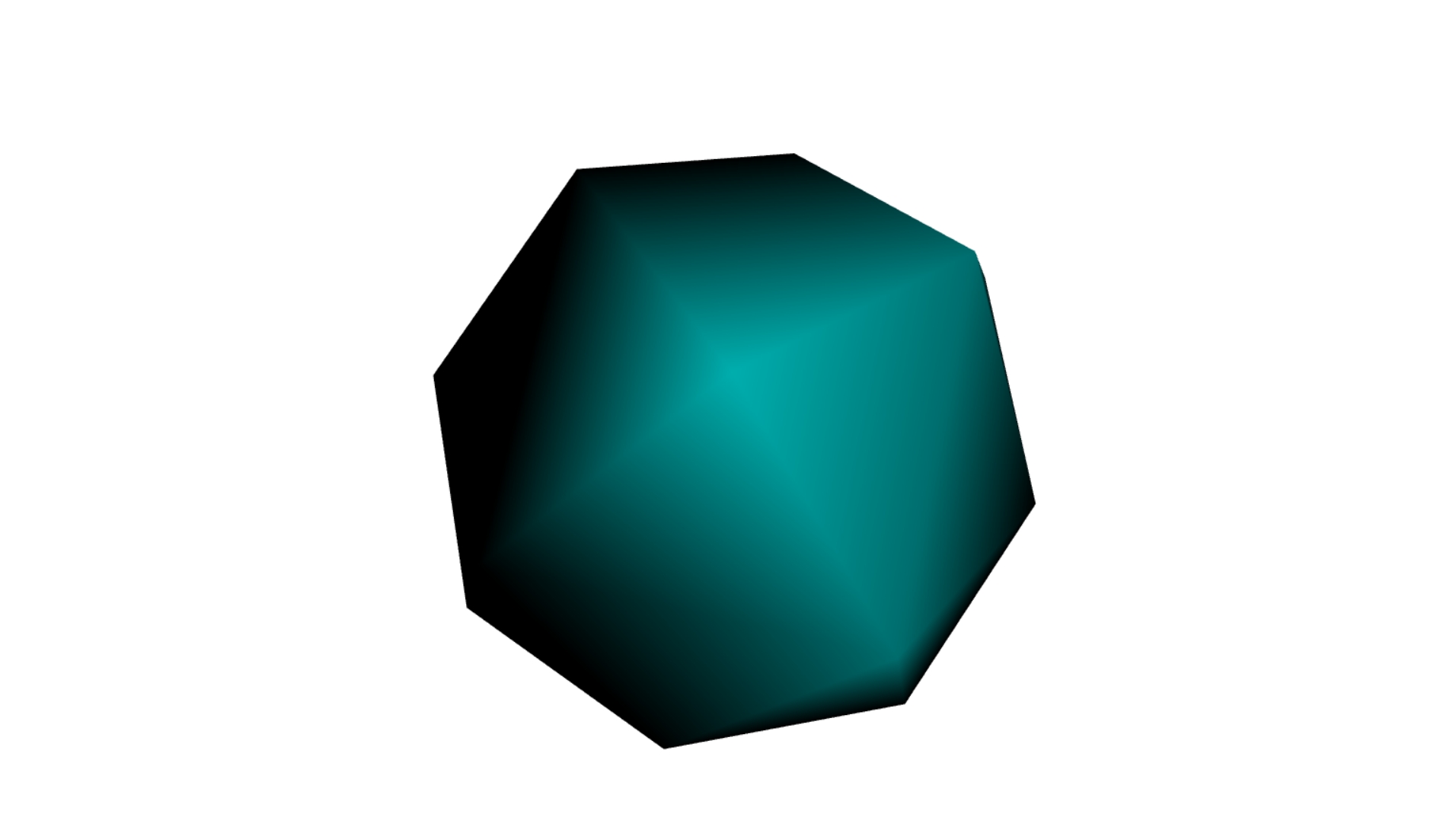
26. Three.js案例-自定义多面体
26. Three.js案例-自定义多面体 实现效果 知识点 WebGLRenderer WebGLRenderer 是 Three.js 中用于渲染场景的主要类。它支持 WebGL 渲染,并提供了多种配置选项。 构造器 new THREE.WebGLRenderer(parameters) 参数类型描述parametersObject可选参数对象&…...

HarmonyOS-高级(四)
文章目录 应用开发安全应用DFX能力介绍HiLog使用指导HiAppEvent 🏡作者主页:点击! 🤖HarmonyOS专栏:点击! ⏰️创作时间:2024年12月11日11点18分 应用开发安全 应用隐私保护 隐私声明弹窗的作…...

Qt-chart 画折线图(以时间为x轴)
上图 代码 #include <iostream> #include <random> #include <qcategoryaxis.h>void MainWindow::testLine() {//1、创建图表视图QChartView* view new QChartView(this);//2.创建图表QChart* chart new QChart();//3.将图表设置给图表视图view->setCh…...

【入门】晶晶的补习班
描述 晶晶上初中了。妈妈认为晶晶应该更加用功学习,所以晶晶除了上学之外,还要参加妈妈为她报名的各科补习班。晶晶的妈妈给了晶晶的下周每天上补习班的小时数,晶晶同学想知道,下周平均一天要上多少小时的补习班(结果…...

c#动态更新替换json节点
需求项目json作为主模板,会应用到多个子模版,当后续项目变更只需要修改主模板中节点,并且能够动态更新到原来的子模版中去。 主模板示例: {"A": {"A1": "","A2": false,"A3"…...
cf补题日记
听退役选手建议,补40道C、D题。 (又又又开新专题。。。 进度:2/40 原题1: You are given a string ss, consisting of digits from 00 to 99. In one operation, you can pick any digit in this string, except for 00 or the…...

Golang学习笔记_01——包
文章目录 包(package)1. 定义2. 导入3. 初始化4. 可见性4. 注意4.1 包声明4.2 main包4.3 包的导入4.4标识符的可见性4.5 包的初始化4.6 避免命名冲突4.7 包的路径和名称4.8 匿名导入4.9 使用Go Modules 包(package) 在Golang&…...
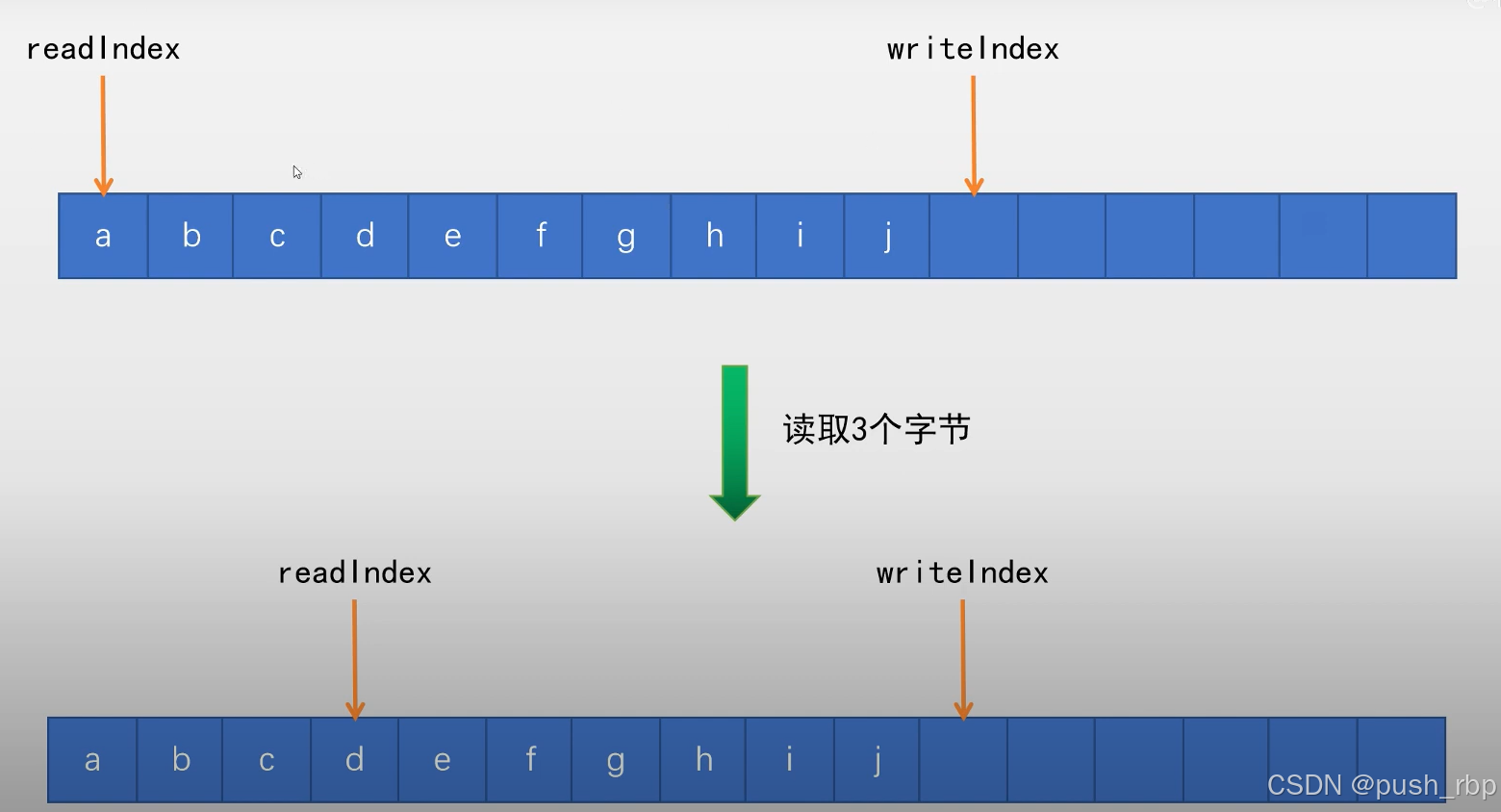
RPC设计--应用层缓冲区,TcpBuffer
为什么需要应用层的buffer 为了方便数据处理,从fd上直接读写然后做包的组装、拆解不够方便方便异步发送,将数据写到应用层buffer后即可返回,让epoll即event_loop去异步发送。提高发送效率,多个小包可合并发送 buffer 设计 可以…...
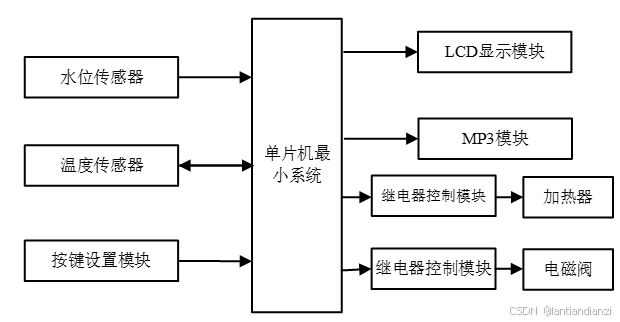
基于单片机智能控制的饮水机控制系统
基于单片机智能控制的饮水机控制系统,以STC89C52单片机为核心,利用防水型DS18B20温度传感器对饮水机内的水温做出检测,其次利用水位传感器对饮水机内的水量做出检测,并显示在OLED液晶显示屏上。用户在使用饮水机时,通过…...
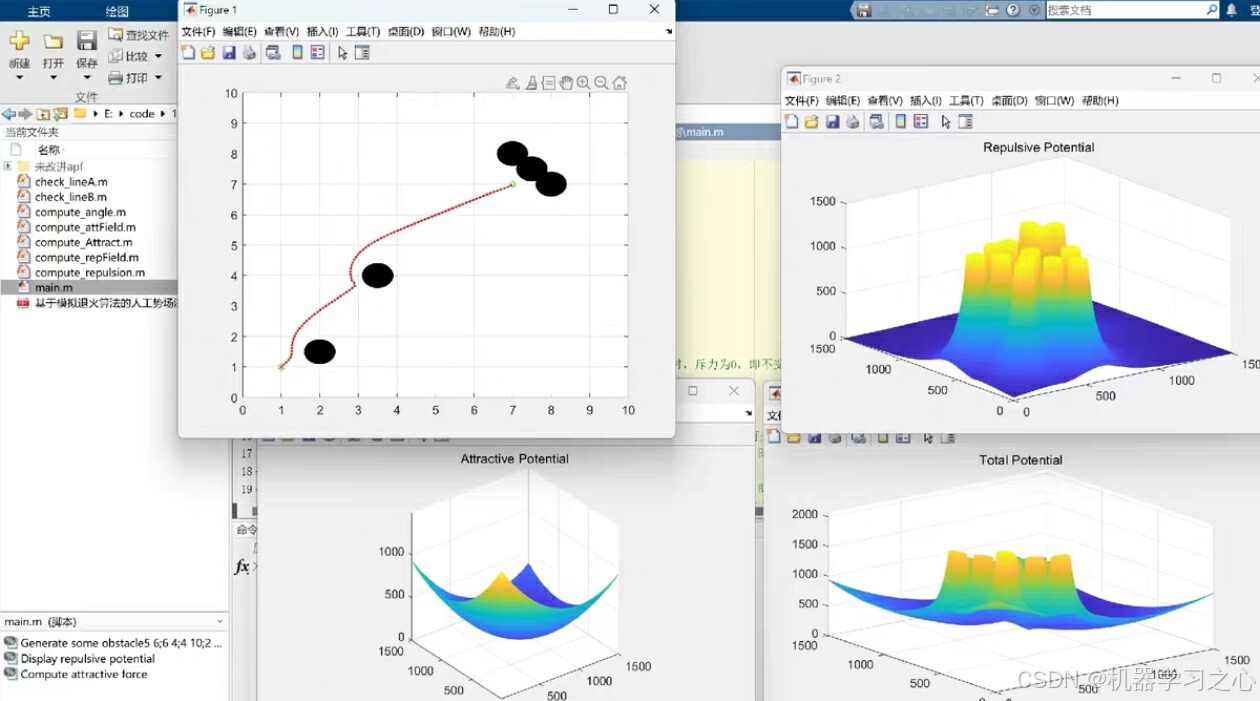
路径规划 | 改进的人工势场法APF算法进行路径规划(Matlab)
目录 效果一览基本介绍程序设计参考文献 效果一览 基本介绍 改进的人工势场法(APF)路径规划算法 在路径规划中,人工势场法(APF)是一种常见的方法,但传统的APF算法容易陷入局部极小值,导致路径规…...

【云原生知识】Kubernets实践-前端服务如何访问后端服务
文章目录 概述步骤1:部署后端服务步骤2:配置Nginx步骤3:创建Nginx服务总结 如何确保 Nginx 能持续访问后端服务?相关文献 概述 假设你正在使用Kubernetes作为容器云平台,以下是如何配置Nginx以及相关服务,…...
【ubuntu18.04】ubuntu18.04安装EasyCwmp操作说明
参考链接 Tutorial – EasyCwmphttps://easycwmp.org/tutorial/ EasyCwmp 介绍 EasyCwmp 设计包括 2 个部分: EasyCwmp 核心:它包括 TR069 CWMP 引擎,负责与 ACS 服务器的通信。它是用 C 语言开发的。EasyCwmp DataModel:它包…...

Cursor AI 规则引擎:自动化编码规范与项目约束实践指南
1. 项目概述:一个为 Cursor 编辑器量身定制的规则引擎如果你和我一样,深度依赖 Cursor 这款 AI 驱动的代码编辑器,那你一定经历过这样的时刻:面对 AI 生成的代码,既惊叹于它的效率,又时常为它不遵守团队规范…...

Java 枚举类型:3个经典应用场景与实战案例
Java 枚举类型:3个经典应用场景与实战案例枚举( enum )是 Java 中一种特殊的类,它通过固定的常量集合来表示有限且离散的状态,不仅能提升代码可读性,还能避免魔法值、减少错误,是后端开发中非常…...

基于CPX与LSM303的电子罗盘制作:从I2C通信到传感器校准全解析
1. 项目概述与核心价值如果你玩过嵌入式开发,尤其是涉及姿态感知或导航的项目,大概率会碰到一个经典问题:如何让设备“知道”自己面朝哪个方向?加速度计能告诉你设备是平放还是倾斜,陀螺仪能告诉你转得多快,…...

在职场上,别人对你的态度,都是你允许的:“他为什么敢这样对我?”“他为什么不怕得罪我?”“我有什么好怕的?”
当有人在公司凶你时:别问"他为什么凶我",要问"他为什么敢" 目录 当有人在公司凶你时:别问"他为什么凶我",要问"他为什么敢" 别人敢在公司得罪你,是因为他早已算清了这笔账 他不怕得罪你,说明在他眼里你"没有威胁性" …...
)
NotebookLM畜牧业研究辅助落地手册(2024畜牧AI工具箱首发版)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM畜牧业研究辅助落地手册(2024畜牧AI工具箱首发版)概述 NotebookLM 是 Google 推出的基于用户上传文档构建可信问答与推理能力的 AI 助手,其“引用溯源”与…...

《魔兽世界》怀旧服:纳克萨玛斯教官拉苏维奥斯战术详解与实战心得
1. 教官拉苏维奥斯战斗机制解析 教官拉苏维奥斯作为纳克萨玛斯军事区的守门BOSS,其战斗核心在于学员控制循环与仇恨管理的双重考验。这个BOSS战最特别的地方在于,你需要同时应对教官本体的高伤害和四名学员的协同作战。很多团队第一次开荒时容易忽略学员…...

对话式AI智能中继与编排框架:构建高可用AI应用的核心架构
1. 项目概述:一个面向对话式AI的智能中继与编排框架最近在折腾一个挺有意思的开源项目,叫ChatAgentRelay。乍一看这个名字,可能觉得它又是一个聊天机器人框架,但深入把玩之后,我发现它的定位其实更精准,也更…...

AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控
AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://git…...

弃ReID跨镜,选镜像无感定位——打破跨镜追踪断链困局,实现全域精准无感感知
弃ReID跨镜,选镜像无感定位——打破跨镜追踪断链困局,实现全域精准无感感知在安防监控、智慧园区、商业综合体、交通枢纽等场景中,跨摄像头目标追踪是核心需求之一——无论是人员轨迹追溯、异常行为预警,还是资产安全管控、流量数…...

PPTTimer终极指南:Windows演示时间管理的免费开源解决方案
PPTTimer终极指南:Windows演示时间管理的免费开源解决方案 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 在重要的演示、会议或培训中,时间控制往往成为成功的关键。你是否曾在演讲时频…...