嵌入式系统中的并行编程模型:汇总解析与应用

概述:随着嵌入式系统处理能力的不断提升,并行编程在其中的应用愈发广泛。本文深入探讨了多种专门为嵌入式设计的并行编程模型,包括任务队列模型、消息传递模型、数据并行模型、异构多核并行模型、实时任务调度模型以及函数式并行模型。详细阐述了各模型的原理、优缺点、适用场景,并提供了相应的 C++ 源代码示例及典型开源库介绍,旨在为嵌入式系统开发人员在选择和应用并行编程模型时提供全面的参考与指导,助力其更高效地开发嵌入式并行应用程序。
一、任务队列模型
任务队列模型将需要执行的任务放入一个队列中,由多个线程从队列中获取任务并执行。这种模型可以有效地管理任务的分配和执行顺序,避免了线程之间的直接依赖和复杂的同步问题。
(一)优点
能灵活地分配任务,可根据系统的负载动态调整任务的执行顺序和分配方式。当有新任务加入队列时,空闲线程可以及时获取并执行,提高了系统的资源利用率和响应速度。
(二)缺点
需要额外的内存来存储任务队列和任务的相关信息,增加了一定的内存开销。如果任务之间存在依赖关系,需要在任务的设计和调度中进行额外的处理,以确保任务的正确执行顺序。
(三)适用场景
适用于处理多个相对独立的任务,如传感器数据的采集和处理。不同的传感器数据采集任务可以作为独立的任务放入队列,由多个线程并行处理,提高数据采集和处理的效率。
(四)C++ 源代码示例
#include <iostream>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>std::queue<int> task_queue;
std::mutex mutex_queue;
std::condition_variable cond_var;void fibonacci_task(int n) {if (n == 0) {std::cout << "0 ";return;} else if (n == 1) {std::cout << "1 ";return;} else {int a = 0, b = 1, temp;for (int i = 0; i < n; i++) {std::cout << a << " ";temp = a + b;a = b;b = temp;}std::cout << std::endl;}
}void worker_thread() {while (true) {std::unique_lock<std::mutex> lock(mutex_queue);cond_var.wait(lock, []{ return!task_queue.empty(); });int task = task_queue.front();task_queue.pop();lock.unlock();fibonacci_task(task);}
}int main() {const int num_tasks = 10;std::thread threads[num_tasks];// 创建并启动工作线程for (int i = 0; i < num_tasks; ++i) {threads[i] = std::thread(worker_thread);}// 将任务放入队列for (int i = 0; i < num_tasks; ++i) {std::unique_lock<std::mutex> lock(mutex_queue);task_queue.push(i);lock.unlock();cond_var.notify_one();}// 等待所有线程完成任务for (int i = 0; i < num_tasks; ++i) {threads[i].join();}return 0;
}
(五)典型开源库
cppq 是一个简单、可靠且高效的 C++17 分布式任务队列库,它提供了方便的任务调度和执行功能,适用于各种需要异步处理任务的场景。
二、消息传递模型
消息传递模型中线程之间通过传递消息来进行通信和协调,而不是直接共享内存。每个线程都有自己的消息队列,用于接收和发送消息。
(一)优点
避免了共享内存带来的并发访问问题,如数据竞争和死锁等,提高了系统的稳定性和可靠性。线程之间的通信更加明确和可控,便于进行系统的调试和维护。
(二)缺点
消息传递的开销相对较大,包括消息的复制和传递过程中的系统调用等,可能会影响系统的性能。如果消息的处理不及时,可能会导致消息队列的积压,影响系统的实时性。
(三)适用场景
适用于对可靠性要求较高的嵌入式系统,如航空航天、工业控制等领域。在这些系统中,线程之间的通信需要严格的控制和管理,以确保系统的安全和稳定运行。
(四)C++ 源代码示例
#include <cstdlib>
#include <iostream>
#include <mpl/mpl.hpp>int main() {// 获取通信器 "world" 的引用const mpl::communicator& comm_world{mpl::environment::comm_world()};// 每个进程打印包含处理器名称、在通信器中的 rank 以及通信器大小的消息std::cout << "Hello World! I am running on \"" << mpl::environment::processor_name()<< "\". My rank is " << comm_world.rank() << " out of " << comm_world.size()<< " processes.\n";// 如果有两个或更多进程,则从进程 0 向进程 1 发送消息if (comm_world.size() >= 2) {if (comm_world.rank() == 0) {std::string message{"Hello World!"};comm_world.send(message, 1); // 向 rank 1 发送消息} else if (comm_world.rank() == 1) {std::string message;comm_world.recv(message, 0); // 从 rank 0 接收消息std::cout << "Got: \"" << message << "\"\n";}}return EXIT_SUCCESS;
}
(五)典型开源库
MPL 是一个基于 MPI 标准的 C++17 消息传递库,它为高性能计算提供了现代 C++ 接口,具有类型安全、易于使用等特点,适用于大规模模拟、并行算法研究等高性能计算场景。
三、数据并行模型
数据并行模型将数据分成多个部分,每个部分由一个独立的处理单元进行处理,处理单元之间可以并行执行,从而提高数据处理的效率。
(一)优点
能充分利用硬件的并行处理能力,大大提高数据处理的速度。对于处理大规模数据的嵌入式系统,如视频监控、图像处理等,数据并行模型可以显著提高系统的性能。
(二)缺点
对数据的划分和分配要求较高,如果数据划分不合理,可能会导致处理单元之间的负载不均衡,影响系统的性能。同时,数据并行模型需要处理单元之间进行一定的同步和通信,以确保数据处理的正确性。
(三)适用场景
适用于需要对大量数据进行相同或相似处理的嵌入式系统,如智能交通系统中的车牌识别、医疗设备中的图像诊断等。
(四)C++ 源代码示例
#include <iostream>
#include <CL/sycl.hpp>int main() {const int size = 1024;int a[size], b[size], c[size];// 初始化数组for (int i = 0; i < size; i++) {a[i] = i;b[i] = i * 2;}{// 创建 SYCL 队列cl::sycl::queue q(cl::sycl::default_selector{});// 在设备上分配内存cl::sycl::buffer<int, 1> buffer_a(a, cl::sycl::range<1>(size));cl::sycl::buffer<int, 1> buffer_b(b, cl::sycl::range<1>(size));cl::sycl::buffer<int, 1> buffer_c(c, cl::sycl::range<1>(size));// 提交并行任务q.submit([&](cl::sycl::handler& h) {auto accessor_a = buffer_a.get_access<cl::sycl::access::mode::read>(h);auto accessor_b = buffer_b.get_access<cl::sycl::access::mode::read>(h);auto accessor_c = buffer_c.get_access<cl::sycl::access::mode::write>(h);h.parallel_for<class add_vectors>(cl::sycl::range<1>(size), [=](cl::sycl::id<1> idx) {accessor_c[idx] = accessor_a[idx] + accessor_b[idx];});});// 等待任务完成q.wait();}// 检查结果for (int i = 0; i < size; i++) {if (c[i]!= a[i] + b[i]) {std::cerr << "Error at index " << i << std::endl;return -1;}}std::cout << "Arrays added successfully." << std::endl;return 0;
}
(五)典型开源库
DPC++ 是一个基于 C++ 和 SYCL 的异构并行编程模型,它允许开发者使用标准 C++ 编写跨不同架构的并行代码,包括 CPU、GPU 和 FPGA 等,适用于需要在异构硬件平台上进行高性能计算的场景。
四、异构多核并行模型
异构多核并行模型针对嵌入式异构多核处理器设计,充分发挥不同类型处理器核心的优势,实现并行计算。
(一)优点
能根据不同核心的特点进行任务分配,提高系统的整体性能和能效比。可以在不增加太多硬件成本的情况下,通过合理利用异构多核处理器的资源,满足嵌入式系统对高性能计算的需求。
(二)缺点
需要对异构多核处理器的架构和编程接口有深入的了解,开发难度相对较大。同时,异构多核之间的通信和协同工作也需要进行精心的设计和优化,以确保系统的稳定性和性能。
(三)适用场景
适用于对性能和功耗有严格要求的嵌入式系统,如智能手机、平板电脑、智能机器人等。
(四)C++ 源代码示例
#include <iostream>
#include <CL/cl.hpp>const int matrix_size = 1024;void matrix_multiply(cl::CommandQueue& queue, cl::Buffer& matrix_a, cl::Buffer& matrix_b, cl::Buffer& result_matrix) {// 定义内核函数const char* kernel_source = "__kernel void matrix_multiply_kernel(__global const float* matrix_a, ""__global const float* matrix_b, __global float* result_matrix, ""const int matrix_size) {""int row = get_global_id(0);""int col = get_global_id(1);""float sum = 0.0f;""for (int k = 0; k < matrix_size; k++) {""sum += matrix_a[row * matrix_size + k] * matrix_b[k * matrix_size + col];""}""result_matrix[row * matrix_size + col] = sum;""}";// 创建程序对象cl::Program::Sources sources;sources.push_back({kernel_source, strlen(kernel_source)});cl::Program program(queue.getInfo<CL_QUEUE_CONTEXT>(), sources);// 构建程序program.build("-cl-std=CL1.2");// 创建内核对象cl::Kernel kernel(program, "matrix_multiply_kernel");// 设置内核参数kernel.setArg(0, matrix_a);kernel.setArg(1, matrix_b);kernel.setArg(2, result_matrix);kernel.setArg(3, matrix_size);// 定义全局工作项大小cl::NDRange global_work_size(matrix_size, matrix_size);// 执行内核queue.enqueueNDRangeKernel(kernel, cl::NullRange, global_work_size);
}int main() {// 初始化矩阵数据float matrix_a_data[matrix_size * matrix_size];float matrix_b_data[matrix_size * matrix_size];float result_matrix_data[matrix_size * matrix_size];for (int i = 0; i < matrix_size * matrix_size; i++) {matrix_a_data[i] = static_cast<float>(rand()) / RAND_MAX;matrix_b_data[i] = static_cast<float>(rand()) / RAND_MAX;}try {// 获取平台和设备信息std::vector<cl::Platform> platforms;cl::Platform::get(&platforms);cl::Device device;for (const auto& platform : platforms) {std::vector<cl::Device> devices;platform.getDevices(CL_DEVICE_TYPE_ALL, &devices);for (const auto& dev : devices) {if (dev.getInfo<CL_DEVICE_TYPE>() == CL_DEVICE_TYPE_GPU ||dev.getInfo<CL_DEVICE_TYPE>() == CL_DEVICE_TYPE_CPU) {device = dev;break;}}if (device()!= 0) {break;}}// 创建上下文和命令队列cl::Context context({device});cl::CommandQueue queue(context, device);// 在设备上创建缓冲区cl::Buffer matrix_a(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * matrix_size * matrix_size, matrix_a_data);cl::Buffer matrix_b(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * matrix_size * matrix_size, matrix_b_data);cl::Buffer result_matrix(context, CL_MEM_WRITE_ONLY, sizeof(float) * matrix_size * matrix_size);// 执行矩阵乘法matrix_multiply(queue, matrix_a, matrix_b, result_matrix);// 将结果从设备读回主机queue.enqueueReadBuffer(result_matrix, CL_TRUE, 0, sizeof(float) * matrix_size * matrix_size, result_matrix_data);// 输出结果的一部分for (int i = 0; i < 10; i++) {for (int j = 0; j < 10; j++) {std::cout << result_matrix_data[i * matrix_size + j] << " ";}std::cout << std::endl;}} catch (cl::Error& e) {std::cerr << "OpenCL error: " << e.what() << " (" << e.err() << ")" << std::endl;return -1;}return 0;
}
(五)典型开源库
OpenCL 是一个用于异构并行计算的开放标准和编程框架,它允许开发者使用 C、C++ 等语言在不同的异构硬件平台上进行并行编程,包括 CPU、GPU、FPGA 等,适用于各种需要利用异构硬件加速计算的场景。
五、实时任务调度模型
实时任务调度模型根据任务的实时性要求和优先级,对任务进行调度和分配,确保关键任务能够在规定的时间内完成。
(一)优点
能保证系统的实时性,对于一些对时间敏感的嵌入式应用,如汽车电子控制系统、工业自动化控制系统等,实时任务调度模型可以确保系统的可靠运行。
(二)缺点
需要对任务的实时性要求和优先级进行准确的评估和设置,否则可能会导致系统的性能下降或任务错过截止时间。同时,抢占式调度可能会引入一定的上下文切换开销,影响系统的效率。
(三)适用场景
适用于对实时性要求极高的嵌入式系统,特别是那些涉及到人身安全和关键任务控制的领域。
(四)C++ 源代码示例
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <ctime>
#include <ratio>
#include <chrono>std::mutex mutex_task;
std::condition_variable cond_var;
bool high_priority_task_ready = false;
bool medium_priority_task_ready = false;
bool low_priority_task_ready = false;void high_priority_task() {std::this_thread::sleep_for(std::chrono::seconds(1));{std::lock_guard<std::mutex> lock(mutex_task);high_priority_task_ready = true;}cond_var.notify_one();
}void medium_priority_task() {std::this_thread::sleep_for(std::chrono::seconds(2));{std::lock_guard<std::mutex> lock(mutex_task);medium_priority_task_ready = true;}cond_var.notify_one();
}void low_priority_task() {std::this_thread::sleep_for(std::chrono::seconds(3));{std::lock_guard<std::mutex> lock(mutex_task);low_priority_task_ready = true;}cond_var.notify_one();
}void scheduler() {std::unique_lock<std::mutex> lock(mutex_task);while (!high_priority_task_ready ||!medium_priority_task_ready ||!low_priority_task_ready) {if (high_priority_task_ready) {std::cout << "Executing high priority task." << std::endl;high_priority_task_ready = false;} else if (medium_priority_task_ready) {std::cout << "Executing medium priority task." << std::endl;medium_priority_task_ready = false;} else if (low_priority_task_ready) {std::cout << "Executing low priority task." << std::endl;low_priority_task_ready = false;} else {cond_var.wait(lock);}}lock.unlock();
}int main() {std::thread high_thread(high_priority_task);std::thread medium_thread(medium_priority_task);std::thread low_thread(low_priority_task);std::thread scheduler_thread(scheduler);high_thread.join();medium_thread.join();low_thread.join();scheduler_thread.join();return 0;
}
(五)典型开源库
RTEMS 是一个开源的实时操作系统,它提供了丰富的实时任务调度和管理功能,包括优先级调度、时间片轮转调度等,适用于各种对实时性要求较高的嵌入式系统,如航空航天、工业控制等领域 。
六、函数式并行模型
函数式并行模型将程序表示为一系列不可变数据和纯函数的组合,函数之间可以并行执行,因为它们没有副作用,不会相互干扰。
(一)优点
代码简洁、易于理解和维护,函数的并行执行可以提高系统的性能,特别是对于处理大规模数据和复杂计算的嵌入式系统。由于函数没有副作用,不会出现数据竞争和并发访问问题,提高了系统的可靠性。
(二)缺点
对开发人员的编程习惯和思维方式有一定的要求,需要熟悉函数式编程的概念和技巧。同时,函数式并行模型可能会引入一定的额外开销,如函数的调用和数据的复制等,影响系统的性能。
(三)适用场景
适用于对代码简洁性和可靠性要求较高的嵌入式系统,如金融交易系统、智能家居控制系统等。
(四)C++ 源代码示例
#include <iostream>
#include <future>int fibonacci(int n) {if (n == 0) {return 0;} else if (n == 1) {return 1;} else {return fibonacci(n - 1) + fibonacci(n - 2);}
}int main() {int n = 10;std::future<int> future_result = std::async(std::launch::async, fibonacci, n);std::cout << "Calculating Fibonacci(" << n << ")..." << std::endl;int result = future_result.get();std::cout << "Fibonacci(" << n << ") = " << result << std::endl;return 0;
}
(五)典型开源库
range-v3 是一个 C++ 函数式编程库,它提供了类似于 Haskell 中的 range 概念和相关的函数式操作,如 map、filter、reduce 等,可以方便地进行数据处理和并行计算,适用于需要简洁、高效地处理数据的场景 。
综上所述,不同的并行编程模型在嵌入式系统中各有优劣和适用场景。开发人员在选择时,需要综合考虑系统的资源限制、实时性要求、任务特性以及自身的开发能力等因素,以确定最适合的并行编程模型,从而实现高效、可靠的嵌入式系统开发。
相关文章:
嵌入式系统中的并行编程模型:汇总解析与应用
概述:随着嵌入式系统处理能力的不断提升,并行编程在其中的应用愈发广泛。本文深入探讨了多种专门为嵌入式设计的并行编程模型,包括任务队列模型、消息传递模型、数据并行模型、异构多核并行模型、实时任务调度模型以及函数式并行模型。详细阐…...

VulkanSamples编译记录
按照BUILD.md说明,先安装依赖项 sudo apt-get install git build-essential libx11-xcb-dev \libxkbcommon-dev libwayland-dev libxrandr-dev 然后创建一个新文件夹build,在该目录下更新依赖项 cd VulkanSamples mkdir build cd build python ../scr…...
)
使用FabricJS对大图像应用滤镜(巨坑)
背景:我司在canvas的渲染模板的宽高都大于2048px 都几乎接近4000px,就导致使用FabricJS的滤镜功能图片显示异常 新知识:滤镜是对图片纹理的处理 FabricJS所能支持的最大图片纹理是2048的 一但图片超出2048的纹理尺寸 当应用滤镜时,图像会被剪切或者是缩…...

网页502 Bad Gateway nginx1.20.1报错与解决方法
目录 网页报错的原理 查到的502 Bad Gateway报错的原因 出现的问题和尝试解决 问题 解决 网页报错的原理 网页显示502 Bad Gateway 报错原理是用户访问服务器时,nginx代理服务器接收用户信息,但无法反馈给服务器,而出现的报错。 查到…...

Spring基础分析02-BeanFactory与ApplicationContext
大家好,今天和大家一起学习整理一下Spring 的BeanFactory和ApplicationContext内容和区别~ BeanFactory和ApplicationContext是Spring IoC容器的核心组件,负责管理应用程序中的Bean生命周期和配置。我们深入分析一下这两个接口的区别、使用场景及其提供…...

Rerender A Video 技术浅析(五):对象移除与自动配色
Rerender A Video 是一种基于深度学习和计算机视觉技术的视频处理工具,旨在通过智能算法对视频进行重新渲染和优化。 一、对象移除模块 1. 目标检测 1.1 概述 目标检测是对象移除的第一步,旨在识别视频中需要移除的对象并生成相应的掩码(m…...

Java项目实战II基于微信小程序的小区租拼车管理信息系统 (开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、核心代码 五、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。 一、前言 随着城市化进程的加速,小区居民对于出行方…...
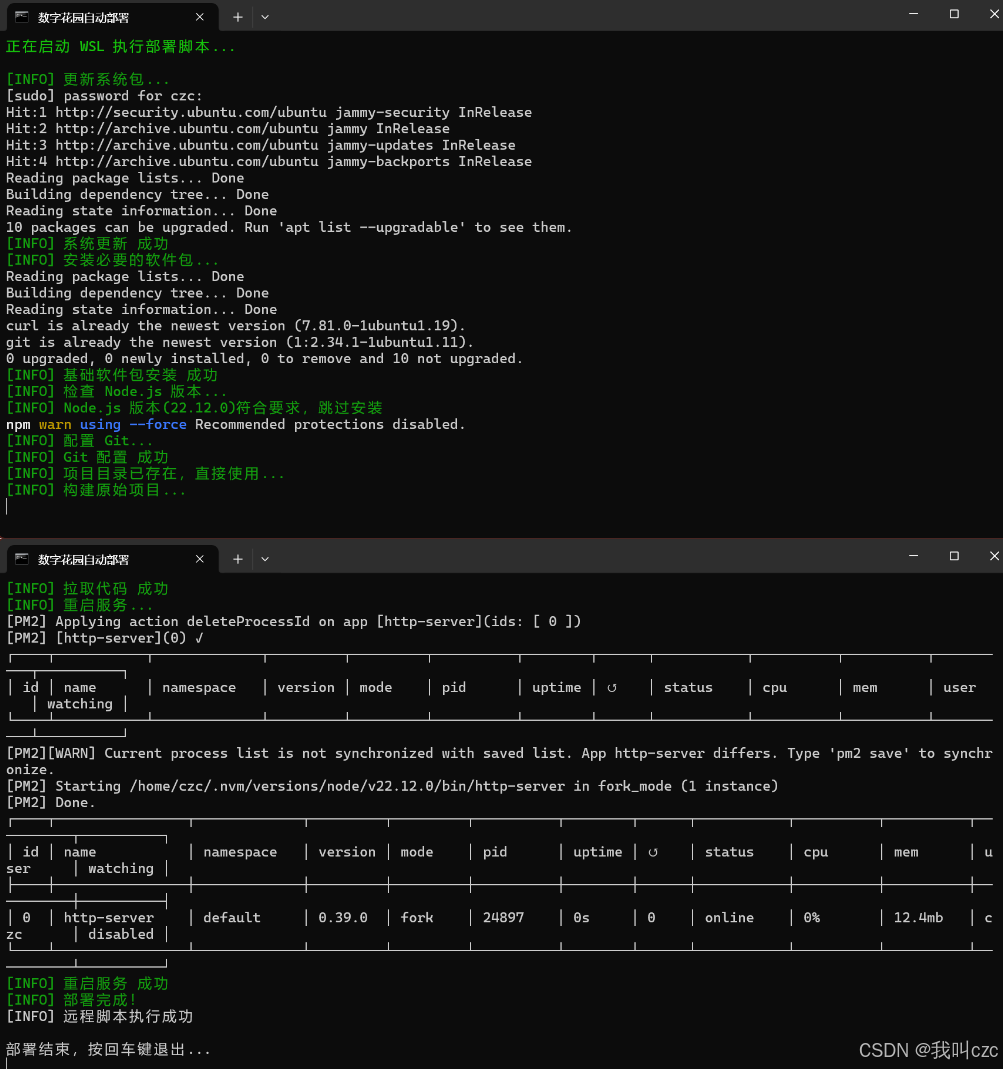
【数字花园】数字花园(个人网站、博客)搭建经历汇总教程
目录 写在最最前面第一章:netlify免费搭建数字花园相关教程使用的平台步骤信息管理 第二章:本地部署数字花园数字花园网站本地手动部署方案1. 获取网站源码2.2 安装 Node.js 3. 项目部署3.1 安装项目依赖3.2 构建项目3.3 启动http服务器 4. 本地预览5. 在…...

WebRTC服务质量(03)- RTCP协议
一、前言: RTCP(RTP Control Protocol)是一种控制协议,与RTP(Real-time Transport Protocol)一起用于实时通信中的控制和反馈。RTCP负责监控和调节实时媒体流。通过不断交换RTCP信息,WebRTC应用…...
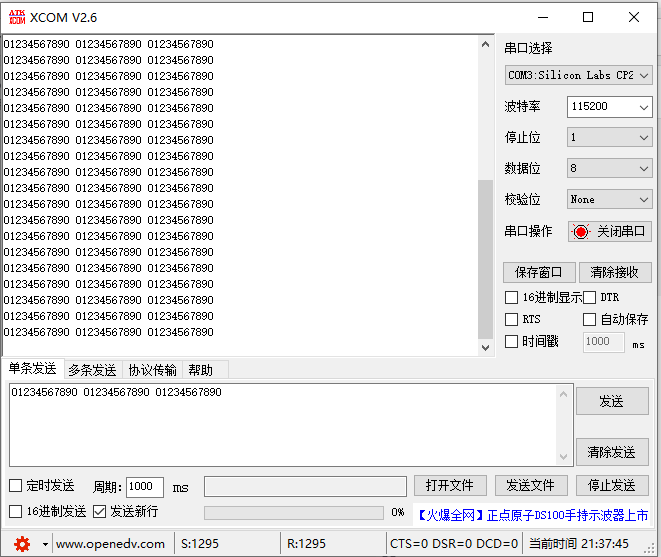
STM32F103单片机HAL库串口通信卡死问题解决方法
在上篇文章 STM32F103单片机使用STM32CubeMX创建IAR串口工程 中分享了使用cubeMX直接生成串口代码的方法,在测试的过程中无意间发现,串口会出现卡死的问题。 当串口一次性发送十几个数据的时候,串口感觉像卡死了一样,不再接收数据…...

Scala正则表达式
一、定义:正则表达式是一种用于匹配、查找和替换文本中特定模式的字符串。 使用方式:①定义一个正则 正则表达式应用场景:查找、验证、替换。 Ⅰ、查找 在目标字符串中,找到符合正则表达式规则要求的 子串。 方括号ÿ…...
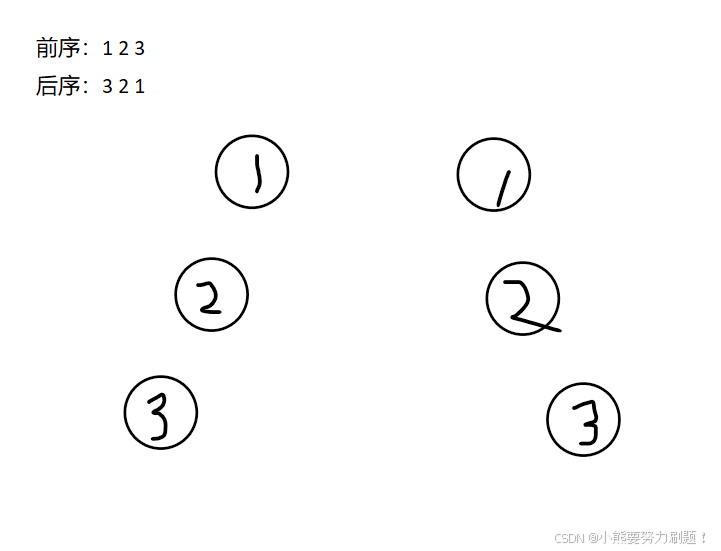
每日一刷——二叉树的构建——12.12
第一题:最大二叉树 题目描述:654. 最大二叉树 - 力扣(LeetCode) 我的想法: 我感觉这个题目最开始大家都能想到的暴力做法就是遍历找到数组中的最大值,然后再遍历一遍,把在它左边的依次找到最大…...
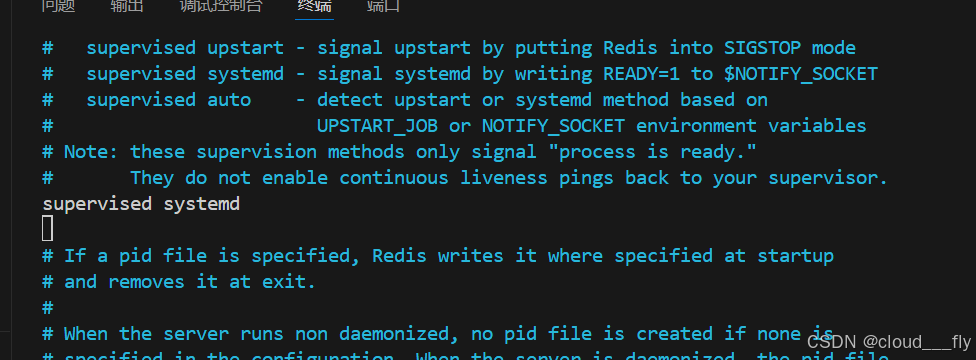
Redis配置文件中 supervised指令
什么是Supervised? supervised模式允许Redis被外部进程管理器监控。通过这个选项,Redis能够在崩溃后自动重启,确保服务的高可用性。常见的进程管理器包括systemd和upstart。 开启方法 vim修改: sudo vi /etc/redis/redis.conf…...
根据基础矩阵(Fundamental Matrix)校正两组匹配点函数correctMatches()的使用)
OpenCV相机标定与3D重建(18)根据基础矩阵(Fundamental Matrix)校正两组匹配点函数correctMatches()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 优化对应点的坐标。 cv::correctMatches 是 OpenCV 库中的一个函数,用于根据基础矩阵(Fundamental Matrix)校…...
python脚本:向kafka数据库中插入测试数据
# coding:utf-8 import datetime import json import random import timefrom kafka import KafkaProducer生产者demo向branch-event主题中循环写入10条json数据注意事项:要写入json数据需加上value_serializer参数,如下代码producer KafkaProducer(val…...
10. 高效利用Excel导入报警信息
高效利用Excel导入报警信息 1.添加报警服务器2.导出报警EXCEL3.报警控件使用1.添加报警服务器 右键项目名称——Add New Sever——Tag Alarm and Event Sever 给报警服务器命名Alarm 给报警服务器分配优先级。如果想要使能历史的话需要和SQL sever配合使用,之前写过。记住这…...

k8s service 配置AWS nlb load_balancing.cross_zone.enabled
在Kubernetes中配置NLB(Network Load Balancer)的跨区域负载均衡(cross-zone load balancing),需要使用服务注解(service annotations)来实现。根据AWS官方文档,以下是配置NLB跨区域…...

国标GB28181网页直播平台EasyGBS国标GB28181-2016协议解读:媒体流保活机制
GB28181-2016在为视频监控系统提供统一的网络视频传输协议。这项标准主要用于公共安全视频监控系统,支持视频监控设备间的互联互通。其主要应用场景包括城市公共安全监控、交通监控、消防监控等。 GB28181-2016标准中的媒体流保活机制,主要是在确保视频…...

面试经验分享 | 杭州某安全大厂渗透测试岗
目录: 所面试的公司:某安全大厂 所在城市:杭州 面试职位:渗透测试工程师 面试过程: 面试官的问题: 1、面试官开始就问了我,为什么要学网络安全? …...
26. Three.js案例-自定义多面体
26. Three.js案例-自定义多面体 实现效果 知识点 WebGLRenderer WebGLRenderer 是 Three.js 中用于渲染场景的主要类。它支持 WebGL 渲染,并提供了多种配置选项。 构造器 new THREE.WebGLRenderer(parameters) 参数类型描述parametersObject可选参数对象&…...

命令行控制中心:提升开发效率的聚合与自动化工具
1. 项目概述:一个面向开发者的命令行控制中心最近在GitHub上看到一个挺有意思的项目,叫jendrypto/command-center。光看名字,你可能会联想到科幻电影里那种布满屏幕、控制一切的舰桥。但在开发者的世界里,它其实是一个更接地气、更…...

思源宋体CN终极指南:7种字重免费商用中文字体快速上手完整教程
思源宋体CN终极指南:7种字重免费商用中文字体快速上手完整教程 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目中文字体版权问题而烦恼吗?思源宋…...

数据可视化:使用D3.js创建交互式图表
数据可视化:使用D3.js创建交互式图表 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊数据可视化这个话题。作为一个全栈开发者,我经常需要将复杂的数据以直观的方式展示给用户。D3.js是一个功能强大的数据可视化库&am…...

Nornir网络自动化监控插件:集成Sentry实现异常告警与上下文追踪
1. 项目概述:一个为Nornir网络自动化框架量身定制的告警与监控插件 如果你和我一样,长期使用Nornir框架来管理成百上千的网络设备,那你一定遇到过这样的场景:一个精心编写的自动化任务在测试环境跑得飞快,一旦放到生产…...

BilibiliDown:专业级B站视频下载工具,高效构建个人媒体库
BilibiliDown:专业级B站视频下载工具,高效构建个人媒体库 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.co…...

基于BLE与CircuitPython的无线8-bit音乐合成器DIY全攻略
1. 项目概述与核心思路想不想亲手做一个能揣在口袋里,随时随地弹奏出复古8-bit音乐的小玩意儿?不是那种手机App模拟的,而是实实在在的、有物理按键、能无线连接、还会发光的小合成器。今天分享的这个项目,就是基于两块小巧但功能强…...

NoFences:如何用开源方案解决Windows桌面管理难题
NoFences:如何用开源方案解决Windows桌面管理难题 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences Windows桌面图标管理长期困扰着用户,NoFences作为开…...

Wwise音频工具完全指南:3步轻松解包和修改游戏音频文件
Wwise音频工具完全指南:3步轻松解包和修改游戏音频文件 【免费下载链接】wwiseutil Tools for unpacking and modifying Wwise SoundBank and File Package files. 项目地址: https://gitcode.com/gh_mirrors/ww/wwiseutil 还在为无法编辑游戏音频文件而烦恼…...

基于SpringBoot+Vue的CRM客户管理系统毕设
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的CRM客户管理系统以解决传统客户关系管理中存在的信息孤岛现象与业务流程低效问题。当前企业客户管理普遍面临数据…...

远程办公总掉线?四大远控软件横测:谁才是“不断连之王”?
远程办公总掉线?四大远控软件横测:谁才是“不断连之王”? 远程办公最怕 “关键时刻掉链子”:写方案写到一半断连、远程运维突然掉线、跨城开会画面卡死…… 连接稳定性早已成为远控软件的核心生命线。本次横测聚焦ToDesk、向日葵、…...