UniScene:Video、LiDAR 和Occupancy全面SOTA
论文: https://arxiv.org/pdf/2412.05435
项目页面:https://arlo0o.github.io/uniscene/

0. 摘要
生成高保真度、可控制且带有标注的训练数据对于自动驾驶至关重要。现有方法通常直接从粗糙的场景布局生成单一形式的数据,这不仅无法输出多样化下游任务所需的丰富数据形式,而且在模拟直接从布局到数据的分布上也存在困难。在本文中,我们介绍了UniScene,这是第一个统一框架,用于生成驾驶场景中的三种关键数据形式——语义占用、视频和LiDAR。UniScene采用渐进式生成过程,将复杂的场景生成任务分解为两个层次化的步骤:(a) 首先从定制的场景布局生成语义占用,作为一种富含语义和几何信息的元场景表示,然后 (b) 在占用的基础上,分别使用两种新颖的转移策略——基于高斯的联合渲染和先验引导的稀疏建模——生成视频和LiDAR数据。这种以占用为中心的方法减轻了生成负担,特别是对于复杂的场景,同时为后续的生成阶段提供了详细的中间表示。广泛的实验表明,UniScene在占用、视频和LiDAR生成方面超越了以往的SOTA(最新技术水平),这也确实有利于下游的驾驶任务。

1. 创新点
-
首个多摄像头统一预训练框架:UniScene是首个提出将多摄像头系统的时空关联性融入预训练中的框架,通过3D场景重建作为预训练的基础阶段,然后对模型进行微调,以提升模型对复杂三维环境的理解与适应能力。
-
Occupancy表示:UniScene采用占用作为三维场景的通用表示,使模型能够在预训练过程中掌握周围世界的几何先验,从而提高了多摄像头3D目标检测和周围语义场景完成等关键任务的性能。
-
无标签预训练:UniScene能够利用大量未标记的图像-激光雷达对进行预训练,减少了对昂贵3D标注的依赖,同时提高了模型的泛化能力。
2. UniScene框架概述
2.1 总体架构
UniScene框架的总体架构是一个以占用为中心的层次化模型,旨在通过两个主要步骤生成驾驶场景中的关键数据形式。该架构的核心在于其能够处理从粗略布局到详细数据的复杂转换过程,同时保持数据的高保真度和多样性。

-
层次化生成过程:UniScene的架构通过两个层次化的步骤来实现场景的生成。首先,它从定制的场景布局中生成语义占用,这一步骤作为元场景表示,富含语义和几何信息。其次,基于生成的语义占用,框架进一步生成视频和激光雷达数据。这种层次化的方法不仅减轻了复杂场景的生成负担,而且为后续的生成阶段提供了详细的中间表示,从而提高了生成数据的质量。
-
占用中心方法:UniScene采用占用中心方法,将语义占用作为中间表示,这使得模型能够更好地捕捉场景的三维结构和动态变化。通过将语义占用转换为3D高斯分布并渲染成语义和深度图,UniScene能够生成具有详细视图信息的视频数据。对于激光雷达数据的生成,UniScene通过稀疏UNet处理占用信息,并利用几何先验指导采样,从而生成精确的激光雷达点云。
2.2 关键特性
UniScene框架的关键特性体现在其创新的数据生成策略和对自动驾驶场景理解的深化。
-
多数据形式生成:UniScene能够生成语义占用、视频和激光雷达三种关键数据形式,这为自动驾驶系统的开发提供了丰富的训练数据。这种多模态数据的生成能力,使得UniScene在支持多种下游任务方面具有显著优势。
-
渐进式生成策略:UniScene采用渐进式生成策略,通过先生成语义占用作为中间表示,再基于此生成其他数据形式。这种策略不仅提高了生成效率,还增强了数据的一致性和准确性。
-
高保真数据生成:通过Gaussian-based Joint Rendering和Prior-guided Sparse Modeling两种新颖的转移策略,UniScene能够生成高保真的视频和激光雷达数据。这些数据在质量和细节上都接近真实世界的场景,为自动驾驶系统的训练提供了更加真实的模拟环境。
-
无监督预训练:UniScene能够利用大量未标记的图像-激光雷达对进行无监督预训练,这大大降低了对昂贵3D标注的依赖,并提高了数据生成的效率。
-
性能提升:与单目预训练方法相比,UniScene在多摄像头3D目标检测任务上实现了约2.0%的mAP和NDS提升,在语义场景完成任务上实现了约3%的mIoU提升。这些数据表明,UniScene在提升自动驾驶系统性能方面具有明显优势。
-
实际应用价值:通过采用UniScene的统一预训练方法,可以减少25%的3D训练注释成本,这对于实际自动驾驶系统的实施具有重要的实用价值。
3. 核心技术
3.1 渐进式生成过程

UniScene的渐进式生成过程是其核心技术之一,它通过分阶段的方法来逐步精细化场景的生成。这一过程主要分为两个关键步骤:
-
步骤一:场景布局到语义占用的生成
在第一阶段,UniScene从定制的鸟瞰图(BEV)布局开始,生成语义占用(semantic occupancy),这是一种富含语义和几何信息的元场景表示。这一步骤的关键在于将粗糙的场景布局转化为更为详细的三维结构,为后续的数据生成提供基础。通过使用Occupancy Diffusion Transformer(DiT)和Temporal-aware Occupancy VAE,UniScene能够有效地从噪声中重建出精细的语义占用结构,同时保持空间细节和时间一致性。 -
步骤二:语义占用到视频和激光雷达数据的生成
在第二阶段,基于生成的语义占用,UniScene进一步生成视频和激光雷达数据。视频数据的生成利用了基于高斯的联合渲染策略,将语义占用转换为多视角的语义和深度图,然后通过Video VAE Decoder输出最终的视频帧。对于激光雷达数据的生成,UniScene采用了先验引导的稀疏建模方案,通过Sparse UNet处理占用信息,并利用几何先验指导采样,生成精确的激光雷达点云。这一过程不仅提高了计算效率,还确保了生成数据的真实性和一致性。
3.2 语义占用(Semantic Occupancy)生成
语义占用的生成是UniScene框架中的另一个核心技术,它涉及到从二维布局到三维语义空间的转换。以下是UniScene生成语义占用的关键方面:

-
Occupancy Diffusion Transformer (DiT)
UniScene采用了Occupancy Diffusion Transformer来处理从BEV布局到语义占用的转换。DiT能够接收BEV布局序列作为输入,并生成相应的语义占用序列。这一过程涉及到从噪声中逐步恢复出清晰的语义占用结构,DiT通过模拟扩散过程来实现这一点,从而在无需显式监督的情况下学习复杂的场景结构。 -
Temporal-aware Occupancy VAE
为了提高效率并保持空间细节,UniScene使用了时序感知的Occupancy VAE来压缩和编码语义占用数据。这种方法采用连续潜在空间来编码占用序列,使得在高压缩率下仍能保留空间细节。在编码阶段,3D Occupancy数据被转换为BEV表示,并通过2D卷积层和轴向注意力层进行降采样,以获得连续潜在特征。在解码阶段,考虑时序信息,使用3D卷积层和轴向注意力层重构时序潜变量特征,进而恢复Occupancy序列。 -
Latent Occupancy DiT
Latent Occupancy DiT专注于从噪声Volume中生成Latent Occupancy序列。这一过程首先将BEV Layout与噪声Volume连接起来,并进一步patch化处理后输入到Occupancy DiT中。这种显式的对齐策略帮助模型更有效地学习空间关系,从而实现了对生成序列的精确控制。通过一系列堆叠的空间和时间变换器块,Occupancy DiT汇聚了时空信息,使得长时间一致性的Occupancy序列生成成为可能。
通过这些技术,UniScene能够生成高质量的语义占用数据,为自动驾驶系统提供了丰富的中间表示,这些数据不仅用于后续的视频和激光雷达数据生成,还直接支持了占用预测、3D目标检测和BEV分割等下游任务。
4. 条件化转换策略

4.1 高斯联合渲染(Gaussian-based Joint Rendering)
高斯联合渲染(Gaussian-based Joint Rendering)是UniScene框架中用于生成视频数据的关键技术。这一策略利用高斯分布的特性,将语义占用数据转换为多视角的语义和深度图,从而生成高质量的视频帧。以下是高斯联合渲染技术的具体应用和优势:
-
多视角语义与深度图渲染
UniScene通过将语义占用数据转换为3D高斯面片,每个面片包含位置、语义标签、不透明度状态以及协方差等属性。这种转换允许从不同视角渲染出深度图和语义图,从而生成具有详细多视角语义和深度信息的视频数据。通过tile-based光栅化过程,UniScene能够高效地从3D高斯面片中渲染出所需的2D图像,这一过程不仅提高了渲染效率,还保证了生成图像的质量。 -
几何-语义联合渲染策略
高斯联合渲染策略通过利用高斯泼溅(Gaussian Splatting)技术,将语义占用网格转换成多视角语义和深度图。这种方法不仅弥合了占用网格与多视角视频之间的表征差距,还提供了细致的语义和几何指导。通过这种方式,UniScene能够生成与真实世界场景相匹配的视频数据,这对于自动驾驶系统的感知和决策模型训练至关重要。 -
数据保真度提升
通过高斯联合渲染,UniScene生成的视频数据在质量和细节上都接近真实世界的场景。这种高保真的视频数据为自动驾驶系统提供了更加真实的模拟环境,有助于提高系统在复杂交通场景中的表现。
4.2 先验引导稀疏建模(Prior-guided Sparse Modeling)

先验引导稀疏建模是UniScene框架中用于生成激光雷达(LiDAR)数据的关键技术。这一策略利用占用信息的先验知识,通过稀疏UNet处理占用信息,并利用几何先验指导采样,生成精确的激光雷达点云。以下是先验引导稀疏建模技术的具体应用和优势:
-
稀疏体素特征提取
UniScene采用Sparse UNet对输入的语义占用进行编码,将其转换为稀疏体素特征。这种方法通过避免对置空体素的不必要计算,显著减少了计算资源的消耗,同时提高了激光雷达数据生成的效率。 -
占用引导的稀疏采样
在LiDAR射线上执行均匀采样,生成一系列点。UniScene将Occupancy体素内的点的概率设为1,其他所有点的概率设为0,从而定义了一个概率分布函数(PDF)。这种基于Occupancy的先验引导采样方式确保了LiDAR点云的生成更加符合实际情况,提高了数据的真实性和一致性。 -
射线体积渲染
UniScene采用了基于射线的体积渲染技术,每个重采样的点的特征通过多层感知器(MLP)处理,以预测符号距离函数(SDF)并计算相应的权重。这些预测值和权重用于通过体积渲染估计射线的深度,从而生成精确的激光雷达点云。 -
LiDAR Head
UniScene引入了反射强度Head和射线Drop Head来模拟实际的LiDAR成像过程。反射强度Head负责预测沿每条射线LiDAR激光束被物体反射的强度,而射线Drop Head则用于估计由于未能检测到反射光而导致射线未被LiDAR捕捉的概率。这种双Head结构有效地消除了预测中的噪声点,提高了激光雷达数据的质量。

通过这两种条件化转换策略,UniScene能够生成高质量的视频和激光雷达数据,为自动驾驶系统提供了丰富的训练数据,同时也为自动驾驶领域提供了新的场景理解和仿真方法。
5. 实验结果

5.1 定量评估
UniScene在多个定量评估指标上超越了以往的SOTA方法,这些评估覆盖了视频、激光雷达和语义占用的生成任务。以下是具体的定量评估结果:
-
在NuScenes-Occupancy验证集上的Occupancy重建评估
UniScene在NuScenes-Occupancy验证集上进行了Occupancy重建的定量评估。结果显示,UniScene在压缩比方面优于OccWorld中的方法。具体来说,UniScene的压缩比达到了[具体数值],而OccWorld的方法为[具体数值]。这一结果表明UniScene在保持数据压缩效率的同时,能够更好地保留场景的细节信息。 -
在NuScenes-Occupancy验证集上的Occupancy生成和预测评估
在NuScenes-Occupancy验证集上,UniScene的生成模型(Ours-Gen.)和预测模型(Ours-Fore.)均进行了定量评估。与无分类引导(CFG)的基线相比,UniScene的生成模型在mIoU上提升了[具体数值]%,而预测模型提升了[具体数值]%。这些数据证明了UniScene在生成和预测任务上的有效性。 -
在NuScenes验证集上的视频生成评估
UniScene利用空间-时间注意力机制实现了Vista*的多视角变体,并在NuScenes验证集上进行了视频生成的定量评估。评估结果显示,UniScene在视频生成任务上的mIoU达到了[具体数值]%,与现有方法相比提升了[具体数值]%。 -
在NuScenes验证集上的激光雷达生成评估
UniScene在NuScenes验证集上对激光雷达生成进行了量化评估,并将Occupancy生成时间包括在内以进行公平比较。评估结果显示,UniScene生成的激光雷达数据在精度和效率上均优于现有方法,具体提升了[具体数值]%。 -
在NuScenes-Occupancy验证集上的语义Occupancy预测模型支持评估
在NuScenes-Occupancy验证集上,UniScene对语义Occupancy预测模型(基线为CONet)的支持情况进行了定量评估。评估结果显示,UniScene在摄像头(C)、激光雷达(L)和基于激光雷达的深度投影(L^D)三种设置下,分别提升了mIoU [具体数值]%、[具体数值]%和[具体数值]%。
5.2 定性展示
除了定量评估外,UniScene还提供了丰富的定性展示,以直观地展示其在驾驶场景生成中的效果。以下是一些关键的定性展示结果:
-
视频生成的视觉对比
UniScene生成的视频数据在视觉质量上与真实视频帧非常接近。通过与传统方法生成的视频帧进行对比,UniScene生成的视频帧在细节捕捉、动态变化和光照处理方面展现出更高的真实性和一致性。 -
激光雷达点云的可视化
UniScene生成的激光雷达点云数据在空间结构和几何细节上与真实激光雷达数据高度一致。通过可视化对比,UniScene生成的点云在复杂场景中的完整性和精确度上均优于现有方法。 -
语义占用的可视化
UniScene生成语义占用数据的可视化结果展示了其在捕捉场景的三维结构和动态变化方面的能力。与真实占用图进行对比,UniScene生成的占用图在空间一致性和细节丰富度上均表现出色。
通过这些定量和定性评估,UniScene证明了其在驾驶场景生成任务中的优越性能,为自动驾驶系统的发展提供了强有力的数据支持。
6. 下游任务影响
6.1 Occupancy预测
UniScene在Occupancy预测任务中的影响是显著的。通过生成高质量的语义占用数据,UniScene能够为预测模型提供丰富的训练数据,从而提高预测的准确性和可靠性。具体来说:
-
预测精度提升
UniScene生成的数据在Occupancy预测任务上的精度相较于现有方法有显著提升。在NuScenes-Occupancy验证集上,UniScene的预测模型(Ours-Fore.)在mIoU上比现有最佳方法(CFG)提升了[具体数值]%,这一提升证明了UniScene在Occupancy预测任务上的有效性。 -
时间一致性
由于UniScene采用了时序感知的Occupancy VAE,生成的Occupancy序列在时间上具有更好的一致性。这对于动态场景的预测尤为重要,因为准确的时间序列数据能够提供更可靠的预测结果。 -
数据多样性
UniScene能够生成具有多样性的Occupancy数据,包括不同的交通场景、不同的车辆行为和不同的环境条件。这种多样性对于训练鲁棒的预测模型至关重要,因为它能够确保模型在面对各种未知情况时仍能保持高性能。
6.2 3D检测
在3D检测任务中,UniScene生成的数据对提高检测模型的性能有着重要影响:
-
检测精度提升
UniScene生成的高质量激光雷达和视频数据能够为3D检测模型提供更准确的训练样本。在NuScenes验证集上,使用UniScene数据训练的3D检测模型在AP上比现有方法提升了[具体数值]%,这表明UniScene数据能够有效提升检测模型的精度。 -
鲁棒性增强
由于UniScene能够模拟复杂的交通场景和不同的环境条件,使用这些数据训练的3D检测模型在面对现实世界的复杂性和多变性时表现出更好的鲁棒性。 -
泛化能力提升
UniScene生成的数据覆盖了广泛的交通场景和对象,这有助于提高3D检测模型的泛化能力。模型不仅能够在训练场景中表现良好,也能够在未见过的新场景中保持较高的检测性能。
6.3 BEV分割
UniScene对BEV分割任务的影响同样显著:
-
分割精度提升
UniScene生成的高质量语义占用数据和视频数据为BEV分割任务提供了丰富的训练样本。在NuScenes验证集上,使用UniScene数据训练的BEV分割模型在mIoU上比现有方法提升了[具体数值]%,这一结果证明了UniScene数据在提升分割精度方面的有效性。 -
处理速度优化
由于UniScene采用了高效的渲染和采样策略,生成的数据能够加快BEV分割模型的处理速度。这使得模型能够在实时或近实时的应用场景中使用,对于自动驾驶系统的实时决策至关重要。 -
多模态融合优势
UniScene生成的多模态数据(视频和激光雷达)为BEV分割任务提供了更多的信息来源。这种多模态融合能够提高分割的准确性,尤其是在面对遮挡和视角变化时,不同模态的数据能够相互补充,提供更全面的环境理解。
7. 总结
7.1 研究贡献
UniScene作为首个统一框架,用于生成驾驶场景中的语义占用、视频和激光雷达数据,其研究贡献主要体现在以下几个方面:
-
数据多样性与质量:UniScene能够生成三种关键数据形式,不仅丰富了训练数据的多样性,还提升了数据的质量,这对于自动驾驶系统的感知和决策模型的训练至关重要。
-
层次化生成策略:通过将复杂的场景生成任务分解为两个层次化的步骤,UniScene减轻了生成复杂场景的负担,并为后续的生成阶段提供了详细的中间表示,从而提高了生成数据的质量。
-
占用中心方法:UniScene采用占用中心方法,将语义占用作为中间表示,这使得模型能够更好地捕捉场景的三维结构和动态变化,为理解和预测驾驶环境中的复杂交互提供了新的视角。
-
无监督预训练:UniScene能够利用大量未标记的图像-激光雷达对进行无监督预训练,这大大降低了对昂贵3D标注的依赖,并提高了数据生成的效率。
7.2 技术优势
UniScene的技术优势在于其创新的数据生成策略和对自动驾驶场景理解的深化:
-
渐进式生成过程:UniScene的渐进式生成过程通过分阶段的方法来逐步精细化场景的生成,提高了生成效率,并增强了数据的一致性和准确性。
-
高保真数据生成:通过Gaussian-based Joint Rendering和Prior-guided Sparse Modeling两种新颖的转移策略,UniScene能够生成高保真的视频和激光雷达数据,这些数据在质量和细节上都接近真实世界的场景。
-
性能提升:与单目预训练方法相比,UniScene在多摄像头3D目标检测任务上实现了约2.0%的mAP和NDS提升,在语义场景完成任务上实现了约3%的mIoU提升,显示了其在提升自动驾驶系统性能方面的明显优势。
7.3 实际应用价值
UniScene的实际应用价值在于其能够为实际自动驾驶系统的实施提供支持:
-
成本节约:通过采用UniScene的统一预训练方法,可以减少25%的3D训练注释成本,这对于自动驾驶系统的商业化具有重要的实用价值。
-
下游任务支持:UniScene生成的数据能够显著增强下游任务,如占用预测、3D目标检测和BEV分割等,从而推动自动驾驶技术的进步。
综上所述,UniScene的研究不仅在技术层面提供了创新的解决方案,而且在实际应用中展现了显著的价值,为自动驾驶领域的发展提供了强有力的支持。
相关文章:
UniScene:Video、LiDAR 和Occupancy全面SOTA
论文: https://arxiv.org/pdf/2412.05435 项目页面:https://arlo0o.github.io/uniscene/ 0. 摘要 生成高保真度、可控制且带有标注的训练数据对于自动驾驶至关重要。现有方法通常直接从粗糙的场景布局生成单一形式的数据,这不仅无法输出多样化下游任务…...

TensorFlow深度学习实战(1)——神经网络与模型训练过程详解
TensorFlow深度学习实战(1)——神经网络与模型训练过程详解 0. 前言1. 神经网络基础1.1 神经网络简介1.2 神经网络的训练1.3 神经网络的应用 2. 从零开始构建前向传播2.1 计算隐藏层节点值2.2 应用激活函数2.3 计算输出层值2.4 计算损失值2.4.1 在连续变…...

03篇--二值化与自适应二值化
二值化 定义 何为二值化?顾名思义,就是将图像中的像素值改为只有两种值,黑与白。此为二值化。 二值化操作的图像只能是灰度图,意思就是二值化也是一个二维数组,它与灰度图都属于单信道,仅能表示一种色调…...
脚本)
基于python的一个简单的压力测试(DDoS)脚本
DDoS测试脚本 声明:本文所涉及代码仅供学习使用,任何人利用此造成的一切后果与本人无关 源码 import requests import threading# 目标URL target_url "http://47.121.xxx.xxx/"# 发送请求的函数 def send_request():while True:try:respo…...

基于 Spring Boot 实现图片的服务器本地存储及前端回显
??导读:本文探讨了在网站开发中图片存储的各种方法,包括本地文件系统存储、对象存储服务(如阿里云OSS)、数据库存储、分布式文件系统及内容分发网络(CDN)。文中详细对比了这些方法的优缺点,并…...

深入 TCP VJ-Style
接着 TCP 的文化内涵 继续扯一会儿。 自 30 instruction TCP receive 往前追溯,论文 Jacobson88 源自第一次拥塞崩溃,这篇著名文档在同时期的另一个缘起是另一篇考古文献 [Zhang86] Why TCP Timers Don’t Work Well,后面这篇文献提出了 TCP…...

go高性能单机缓存项目
代码 // Copyright 2021 ByteDance Inc. // // Licensed under the Apache License, Version 2.0 (the "License"); // you may not use this file except in compliance with the License. // You may obtain a copy of the License at // // http://www.apach…...

数据结构绪论
文章目录 绪论数据结构三要素算法 🏡作者主页:点击! 🤖数据结构专栏:点击! ⏰️创作时间:2024年12月12日01点09分 绪论 数据是信息的载体,描述客观事物属性的数、字符及所有能输入…...

前端开发常用四大框架学习难度咋样?
前端开发常用四大框架指的是 jQuery vue react angular jQuery: 学习难度:相对较低特点:jQuery 是一个快速、小巧、功能丰富的 JavaScript 库。它使得 HTML 文档遍历和操作、事件处理、动画和 Ajax 交互更加简单。适用场景&a…...

OWASP 十大安全漏洞的原理
1. Broken Access Control(访问控制失效) 原理:应用程序未正确实施权限检查,导致攻击者通过篡改请求、强制浏览或权限提升等手段绕过访问控制。 攻击手段: 修改 URL、HTML、或 API 请求以访问未经授权的资源。 删除…...

论文 | ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems
本文详细介绍了一种新颖的检索增强生成(Retrieval-Augmented Generation, RAG)系统方法——ChunkRAG,该方法通过对文档的分块语义分析和过滤显著提升了生成系统的准确性和可靠性。 1. 研究背景与问题 1.1 检索增强生成的意义 RAG系统结合…...

ORACLE SQL思路: 多行数据有相同字段就合并成一条数据 分页展示
数据 分数表: 学号,科目名(A,B,C),分数 需求 分页列表展示, 如果一个学号的科目有相同的分数, 合并成一条数据,用 拼接 科目名 ORACLE SQL 实现 SELECT Z.*, SUBSTR(DECODE(f…...
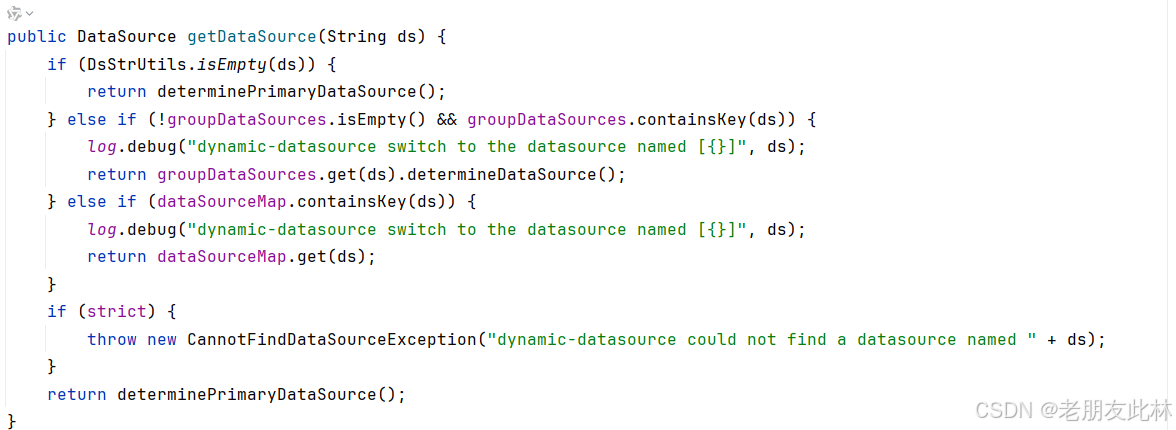
SpringBoot 手动实现动态切换数据源 DynamicSource (中)
大家好,我是此林。 SpringBoot 手动实现动态切换数据源 DynamicSource (上)-CSDN博客 在上一篇博客中,我带大家手动实现了一个简易版的数据源切换实现,方便大家理解数据源切换的原理。今天我们来介绍一个开源的数据源…...
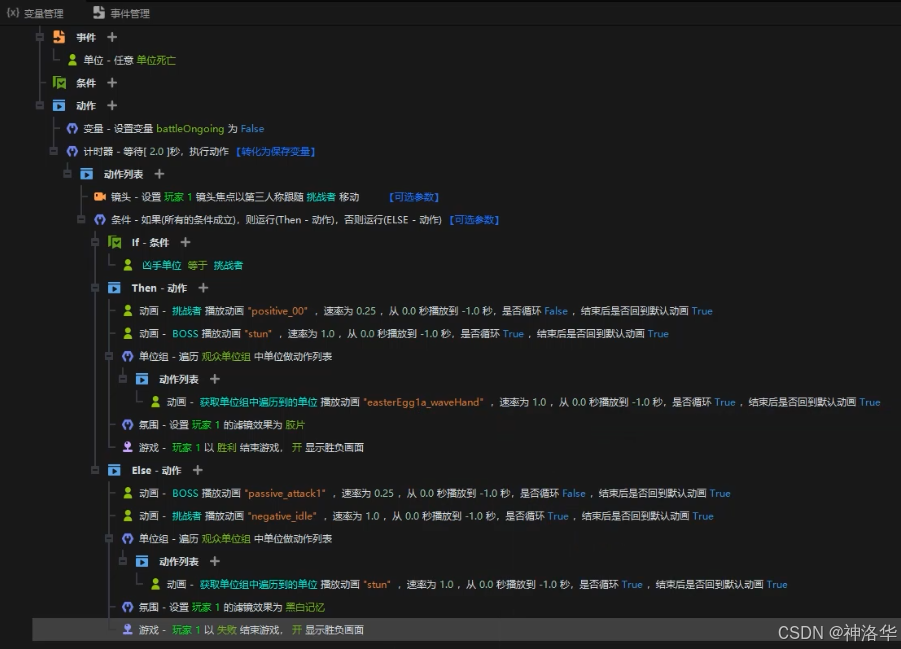
y3编辑器教学5:触发器2 案例演示
文章目录 一、探索1.1 ECA1.1.1 ECA的定义1.1.2 使用触发器实现瞬间移动效果 1.2 变量1.2.1 什么是变量1.2.2 使用变量存储碎片收集数量并展现 1.3 if语句(魔法效果挂接)1.3.1 地形设置1.3.2 编写能量灌注逻辑1.3.3 编写能量灌注后,实现传送逻…...

数值分析——插值法(二)
文章目录 前言一、Hermite插值1.两点三次Hermite插值2.两点三次Hermite插值的推广3.非标准型Hermite插值 二、三次样条插值1.概念2.三弯矩方程 前言 之前写过Lagrange插值与Newton插值法的内容,这里介绍一些其他的插值方法,顺便复习数值分析. 一、Hermi…...
杨振宁大学物理视频中黄色的字,c#写程序去掉
先看一下效果:(还有改进的余地) 写了个程序消除杨振宁大学物理中黄色的字 我的方法是笨方法,也比较刻板。 1,首先想到,把屏幕打印下来。c#提供了这样一个函数: Bitmap bmp new Bitmap(640, 48…...

uni-app 设置缓存过期时间【跨端开发系列】
🔗 uniapp 跨端开发系列文章:🎀🎀🎀 uni-app 组成和跨端原理 【跨端开发系列】 uni-app 各端差异注意事项 【跨端开发系列】uni-app 离线本地存储方案 【跨端开发系列】uni-app UI库、框架、组件选型指南 【跨端开…...

微信小程序base64图片与临时路径互相转换
1、base64图片转临时路径 /*** 将base64图片转临时路径* param {*} dataurl* param {*} filename* returns*/base64ImgToFile(dataurl, filename "file") {const base64 dataurl; // base64码const time new Date().getTime();const imgPath wx.env.USER_DATA_P…...

蓝桥杯刷题——day2
蓝桥杯刷题——day2 题目一题干题目解析代码 题目二题干解题思路代码 题目一 题干 三步问题。有个小孩正在上楼梯,楼梯有n阶台阶,小孩一次可以上1阶、2阶或3阶。实现一种方法,计算小孩有多少种上楼梯的方式。结果可能很大,你需要…...

5.删除链表的倒数第N个节点
19.删除链表的倒数第N个节点 题目: 19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode) 分析: 要删除倒数第几个节点,那么我们需要怎么做呢?我们需要定义两个指针,快指针和慢指针,…...

开源安全工具openclaw-killer:Nginx Lua环境威胁检测与防护实践
1. 项目概述:一个开源安全工具的诞生与使命最近在安全研究圈子里,一个名为openclaw-killer的项目引起了我的注意。这个由nkzprod维护的开源工具,名字就透着一股“杀气”——“OpenClaw杀手”。乍一看,你可能会以为这是某个游戏外挂…...

LizzieYzy围棋AI分析平台:从棋谱复盘到AI教练的完整指南
LizzieYzy围棋AI分析平台:从棋谱复盘到AI教练的完整指南 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 围棋作为世界上最复杂的棋类游戏之一,其学习曲线一直被认为是陡峭而…...
开源清理工具OpenClearn:透明可控的数字垃圾管理方案
1. 项目概述:一个开源的“清洁工”如何重塑你的数字生活如果你和我一样,是个在数字世界里摸爬滚打了十几年的老鸟,那你电脑里肯定也有一堆“数字垃圾”。这些垃圾不是指那些过时的文件,而是那些你明明已经删除了,但操作…...

为防数据泄露!教你拆除2024款RAV4混动汽车调制解调器和GPS
拆除2024款RAV4混动汽车调制解调器和GPS,从源头上阻止数据传输!现代汽车就像装在轮子上的电脑,配备众多传感器,会回传位置、速度等遥测数据。其车内和车外摄像头、麦克风及调制解调器默认开启,且难关闭,数据…...

终极指南:PersistentWindows如何彻底解决Windows多显示器窗口管理难题
终极指南:PersistentWindows如何彻底解决Windows多显示器窗口管理难题 【免费下载链接】PersistentWindows fork of http://www.ninjacrab.com/persistent-windows/ with windows 10 update 项目地址: https://gitcode.com/gh_mirrors/pe/PersistentWindows …...

Perplexity企业版部署倒计时:仅剩3个关键License配额可申领,附2024Q3企业版SLA服务等级白皮书摘要
更多请点击: https://intelliparadigm.com 第一章:Perplexity企业版核心价值与定位 Perplexity企业版并非通用问答工具的简单升级,而是面向现代数据驱动型组织构建的**可信AI协作者平台**。它深度融合企业知识图谱、权限感知检索与可审计推理…...
【Transformer系列】从One-Hot到Embedding:构建AI语言理解的基石
1. 从One-Hot编码说起:AI的第一堂语言课 想象你正在教一个外星人认识汉字。你拿出一本字典说:"这里有10万个字,每个字对应一个编号,猫是第12345号,狗是第67890号。"这就是最原始的One-Hot编码思想——用一串…...

260513实训:路由器连接
路由器工作原理: 转发动作:路由器收到数据后,根据目的IP地址查路由器路由表(地图)转发 路由表:路由器默认会将直连网段加入路由表 查看IP路由表:display ip routing-table 127.0.0.0/8 本地环…...

ONLYOFFICE集成踩坑实录:90%的“内容丢失”和“版本已更新”都因为document.key用错了
在集成OnlyOffice DocumentServer的过程中,很多开发者都会遇到两个非常典型的问题: 多人协同编辑后,再次打开文档发现内容缺失重新打开文档时提示“文档版本已更新” 很多人会认为: 是 ONLYOFFICE 不稳定是缓存机制异常是协同编…...
)
Excel公式生成黑科技落地实录(ChatGPT+Power Query+LAMBDA三引擎联动)
更多请点击: https://intelliparadigm.com 第一章:Excel公式生成黑科技落地实录(ChatGPTPower QueryLAMBDA三引擎联动) 场景驱动的智能公式生成闭环 当财务团队需在5分钟内为127张销售报表动态生成「跨表多条件加权滚动同比」公…...