LinkedList与链表 和 链表面试题
目录
一. ArrayList 与 LinkedList 的优缺点:
二. LinkedList 的分类
三.链表的十道面试题:
1. 删除链表中等于给定值 val 的所有节点。题目链接
2. 反转⼀个单链表。题目链接
3. 输⼊⼀个链表,输出该链表中倒数第k个结点。题目链接
4.给定⼀个带有头结点 head 的非空单链表,返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。题目链接
5.将两个有序链表合并为⼀个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。题目链接
6.编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结点之前。题目链接
7.链表的回文结构。题目链接
8.输⼊两个链表,找出它们的第一个公共结点。题目链接
9.给定⼀个链表,判断链表中是否有环。题目链接
10.给定⼀个链表,返回链表开始入环的第⼀个节点。如果链表无环,则返回 NULL 。题目链接
四. 模拟实现 LinkedList 的一些方法。
具体什么是 “反C” 方法,看图:
五. LindedList 的构造:
六. LinkedList 常用方法:
一. ArrayList 与 LinkedList 的优缺点:
ArrayList 在任意位置删除或插入元素时,就需要把后面的所有元素整体往前或者往后移动,时间复杂度为O(n),效率较低,但是适合需要频繁访问元素的情况。空间不够会涉及到自动扩容,容易浪费空间。
LinkedList 链表 可以理解为 一个长长的火车,每一个 "车厢" 为一个对象元素,也叫做节点,每一个对象元素有两个或三个变量,两个变量的是 单向链表,三个变量的是双向链表,其中链表其中一个变量一般是存放数据,其余的变量存放的是其他对象的引用,可以通过这个对象引用访问其他 "车厢"也就是节点。 LinkedList 适合 需要频繁修改节点数据时使用。
另外,ArrayList 和 LinkedList 在内存存储上也有不同。ArrayList 它在内存中存储是连续的,而 LinkedList 存储逻辑是连续的,但是在内存不一定连续,因为 LinkedList 可以通过 其节点其中的变量 来找到 下一个 节点。
二. LinkedList 的分类
LinkedList 分为一下几种结构:
1.单向 或者 双向 。
2.带头 或者 不带头。
3.循环 或者 非循环。
其中 一 一 组合一共有八种结构,但是我们只需要掌握两种结构就行了:
1. 无头单向非循环链表 :
这种一般在面试笔试出现会比较多。
结构如图:

val 代表的是存储的数据,next 代表存储的是下一个节点的对象引用(可以理解为下一个节点的地址),可以通过 next 找到下一个节点 。
2.无头双向链表:
在Java的集合框架库中LinkedList底层实现就是无头双向循环链表。
结构如图:

val 代表的是存储的数据,next 和 prev 分别代表存储的是 下一个节点 和上一个节点 的对象引用(可以理解为下一个节点的地址),可以通过 next 找到下一个节点 。也可以通过 prev 找到上一个节点。
三.链表的十道面试题:
1. 删除链表中等于给定值 val 的所有节点。题目链接
题解思路:
1.首先,要判断传过来的链表是否为空,若为空则返回 null ,否则进入下一步。
2. 其次,定义两个节点指向,一个在前,一个在后。
若后面的节点存储的值为val,则要对节点重链接,然后后节点往前走一步,前节点不动。
如果后面的节点存储的值不为val,则前节点走一步,后节点走一步。
3.最后,因为上述的过程 无法判断 最开始节点的 值,所以再判断 最开始节点的值。
题解代码:
if(head == null) {return null;}ListNode cur = head.next;ListNode curL = head;while( cur != null) {if(cur.val == val) {curL.next = cur.next;}else {curL = cur;;}cur = cur.next;}if(head.val == val) {head = head.next;}return head;2. 反转⼀个单链表。题目链接
题解代码:
if(head == null) {return null;}if(head.next == null) {return head;}ListNode cur = head;ListNode curN = head.next;head.next = null;while(curN != null) {ListNode curNN = curN.next;curN.next = cur;cur = curN;curN = curNN;}return cur;题解思路:
1.首先,判断是否为空链表或者只有一个节点的链表的情况。
2.定义两个指向 cur 和 curN ,一个在前,一个在后,再把头节点置为null
3.在循环里定义个 curNN ,记录之后节点反转两个节点后 curN 所要在的地方。
注意:循环里不用 cur.next != null 作为条件,是因为cur.next当前所指向的是前一个节点,那么cur.next是访问前一个节点了。这也是什么要定义 curNN 的原因。
4.最后,返回完成后的链表的头节点。
3. 输⼊⼀个链表,输出该链表中倒数第k个结点。题目链接
题解代码:
ListNode fast = head;ListNode slow = head;int count = k-1;while(count != 0) {fast = fast.next;count--;}while(fast.next != null) {fast = fast.next;slow = slow.next;}return slow.val;
题解思路:
1.首先,定义两个指向 fast 和 slow
2.因为返回的是倒数第几个节点的值,那么可以通过让fast 先走 k-1步,再让slow 和 fast 一起走直到 fast 走到最后一个节点为止。那么slow 少走的几步就是 当前 的所需节点。
4.给定⼀个带有头结点 head 的非空单链表,返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。题目链接
题解代码:
if(head == null) {return null;}if(head.next == null) {return head;}ListNode fast = head;ListNode slow = head;while(fast != null && fast.next != null) {fast = fast.next.next;slow = slow.next;}return slow;
题解思路:
1.首先,判断链表是否为空,或者只有一个节点。
2.定义一个快指针,一个慢指针。
3.每次循环让快指针走两步,慢指针走一步,当快指针遇到链表结尾,当前的慢指针就是中间节点。特别要注意循环条件。
5.将两个有序链表合并为⼀个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。题目链接
题解代码:
if(list1 == null && list2 == null) {return null;}ListNode curA = list1;ListNode curB = list2;ListNode curN = new ListNode(1);ListNode cur = curN;while(curA != null && curB != null) {if(curA.val < curB.val) {cur.next = curA;cur = curA;curA = curA.next;}else {cur.next = curB;cur = curB;curB = curB.next;}}if(curA == null) {cur.next = curB;}if(curB == null) {cur.next = curA;}return curN.next;题解思路:
1.首先,判断两个链表是否为空。
2.分别给两个不同的链表定义一个头节点,curA 和 curB ,再定义一个 “傀儡” 节点curN,最后再定义一个 节点 cur 从 “傀儡” 节点开始,cur用来帮助我们重新建立链表的大小链接。
3.比较 curA 和 curB 的大小,小的节点 被作为 cur 重新建立顺序的一方,再让 cur 走到 小节点的位置,小节点再往后走一步,直到某个链表走到尾部了。
4.最后,把走到尾部的一方链接上 没走到尾部链表的curA 或者 curB 位置 。最后返回 “傀儡” 节点后一个节点作为新链表的起始位置。
6.编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结点之前。题目链接
题解代码:
ListNode bs = null;ListNode be = null;ListNode as = null;ListNode ae = null;ListNode cur = pHead;while(cur != null) {if(cur.val < x) {//第一次if(bs == null) {bs = cur;be = cur; }else {be.next = cur;be = cur;}}else {//第一次if(as == null) {as = ae = cur;}else {ae.next = cur;ae = cur;}}cur = cur.next;}if(bs == null) {return as;}if(as == null) {return bs;}ae.next = null;be.next =as;return bs;题解思路:
1.首先,定义空引用 bs 和 be 作为 小于x 的节点存放处;定义空引用 as 和 ae 作为 大于或等于 x 的节点存放处。
2.定义 引用 cur ,遍历链表,若 空引用 bs 和 be 或者 as 和 ae 第一次 接收节点,那么把他们都赋值 为 第一次传过来的节点引用,后续就只让 be 或者 ae 往后走。
3.遍历完成后,分三种情况:
一是没有小于x 的部分 节点,bs 和 be 还是空引用,那么直接返回 as ,也就是原链表。
二是没有大于x 的部分 节点,as 和 ae 还是空引用,那么直接返回 bs, 也就是原链表。
三是双方都有节点,而要把 ae 当前的节点的next置为null ;因为cur 遍历完链表的最后一个节点不知道是放在 be 还是 ae ,所以要手动把 ae 的next 置为null ,再将其两部分链接起来返回 bs
7.链表的回文结构。题目链接
题解代码:
if(A == null) {return false;} if(A.next == null) {return true;}ListNode fast = A;ListNode slow = A;while(fast != null && fast.next != null) {fast = fast.next.next;slow = slow.next;}ListNode cur = slow.next;while(cur != null) {ListNode curN = cur.next;cur.next = slow;slow = cur;cur = curN;}while(A != slow) {if(A.val != slow.val) {return false;}if( A.next == slow) {return true;}A = A.next;slow = slow.next;}return true;题解思路:
1.首先,判断链表是否为空 或者 链表只有一个节点的情况。
2.大体思路是将后一半的链表反转过来,再通过起始节点往后遍历 与 结尾节点往前遍历 对比val。
3.有个特殊情况,就是链表节点个数如果为偶数的话,就需要 A.next == slow 的判断情况,,因为前面已经判断过这两个节点的val了,是相等才能走到 A.next == slow 的判断,若是这种情况,说明到中间了,直接返回 true
8.输⼊两个链表,找出它们的第一个公共结点。题目链接
题解代码:
ListNode curL = headA;ListNode curS = headB;int pl = 0;int ps = 0;while(curL != null) {pl++;curL =curL.next;}while(curS != null) {ps++;curS =curS.next;}int len = pl - ps;curL = headA;curS = headB;if(len < 0) {len = ps - pl;curL = headB;curS = headA;}while(len != 0) {curL = curL.next;len--;}while(curL != curS) {curL = curL.next;curS = curS.next;}if(curL == null) {return null;}return curS;题解思路:
1.首先,我们假设 长节点是headA,短节点 是headB,再求出他们各自的链表长度,再减去得到长度差。
2.得到的长度差如果是小于零的,那么 长链表是 headB,短链表是headA
3.先让长链表走 len 布,再让两个链表同时一起走,那么循环到相同节点就是他们的链表的相交节点,还要通过 curL == null 判断有没有相交,如果没相交返回null 。
9.给定⼀个链表,判断链表中是否有环。题目链接
题解代码:
ListNode fast = head;ListNode slow = head;while(fast != null && fast.next != null) {fast = fast.next.next;slow = slow.next;if(fast == slow) {return true;}}return false;
题解思路:
1. 先定义一个快指针,一个慢指针。
2.每次循环,快指针走两步,慢指针走一步。
3.每次循环判断一次 两个引用是否相等,如果相等说明链表存在环,若循环结束了 ,说明fast 走到链表尾部 ,该链表没有形成环。
10.给定⼀个链表,返回链表开始入环的第⼀个节点。如果链表无环,则返回 NULL 。题目链接
题解代码:
ListNode fast = head;ListNode slow = head;while(fast != null && fast.next != null) {fast = fast.next.next;slow = slow.next;if(fast == slow) {while(head != slow) {head = head.next;slow = slow.next;}return slow;}}return null;题解思路:
1. 先定义一个快指针,一个慢指针。
2.每次循环,快指针走两步,慢指针走一步。
3.每次循环判断一次 两个引用是否相等,如果相等说明链表存在环,若循环结束了 ,说明fast 走到链表尾部 ,该链表没有形成环,返回null 。
4.存在环的情况下,看下图:

c 代表是圆环的周长,所以 head 离 入环点 等于 y ,所以通过上述 head 和 slow 一起走 的代码即可找到入环点。
四. 模拟实现 LinkedList 的一些方法。
注意:
在Java的中LinkedList底层实现的是双向链表。
代码实现:
//任意位置插入public void addIndex(int index,int data) {int len = size();if(index < 0 || index > size()) {throw new IndexOutOfBoundsException("双向链表index位置不合法: "+index);}if(index == 0) {addFirst(data);return;}if(index == size()) {addLast(data);return;}ListNode node = new ListNode(data);ListNode cur = Findindex(index);node.next = cur;cur.prev.next = node;node.prev = cur.prev;cur.prev = node;}//寻找插入节点的后一个节点public ListNode findindex(int index) {ListNode cur = head;while(index != 0) {cur = cur.next;index--;}return cur;}//头插法public void addFirst(int data) {ListNode node = new ListNode(data);if(head == null) {head = node;last = node;}else {node.next = head;head.prev = node;head = node;}}//尾插法public void addLast(int data) {ListNode node = new ListNode(data);if(head == null) {head = node;last = node;}else {last.next = node;node.prev = last;last = node;}}注意:
prev 是指向前一个节点,next 是指向下一个节点。
代码分析:
这里我们实现了头插法,尾插法,任意下标插入的方法。
1.头插法:
首先定义一个要插入的新节点 node ,再判断当前是不是空链表,如果是空链表,说明此时要插入的是第一个元素;如果不是空链表,再通过先绑定后面,再绑定前面的操作进行插入元素。
2.尾插法:
首先定义一个要插入的新节点 node ,再判断当前是不是空链表,如果是空链表,说明此时要插入的是第一个元素;如果不是空链表,再通过先绑定后面,再绑定前面的操作进行插入元素。
3.任意下标插入法:
首先,要判断准备要插入的下标是否合法,通过 size()方法,得到链表的节点个数,如果下标不合法就抛出个异常。
其次,如果下标是 0 或者 是 size(),证明是头插法或者是尾插法,调用其对应的方法就行了。
最后,findindex 方法找到 准备插入新节点的后一个节点,再通过 “反C” 方法 绑定。
具体什么是 “反C” 方法,看图:

按照重新链接起来的节点,序号1,2,,3,4代表先后顺序, 因为酷似 “C”,顺序像从C的底部开始往上走,所以被我称作 “反C”方法。
五. LindedList 的构造:
LinkedList 有两种构造方法:

上面的是无参的构造方法;
下面的构造方法是这样的:
先看图:


这样的构造方法是可行的,为什么?
因为 list 实现了 Collection 接口,并且当前的 list 是 list2 的同类型,(list 是 list2 的子类也行 ),所以是没问题的。
但是这样就不行了:

虽然 list 实现了 Collection 接口,但是 String 并不是 Integer 的子类。
所以必须要满足两个条件才可以实现带参数构造LinkedList。
六. LinkedList 常用方法:

相关文章:
LinkedList与链表 和 链表面试题
目录 一. ArrayList 与 LinkedList 的优缺点: 二. LinkedList 的分类 三.链表的十道面试题: 1. 删除链表中等于给定值 val 的所有节点。题目链接 2. 反转⼀个单链表。题目链接 3. 输⼊⼀个链表,输出该链表中倒数第k个结点。题目链接 4.给定…...

ansible自动化运维(一)简介及清单,模块
相关文章ansible自动化运维(二)playbook模式详解-CSDN博客ansible自动化运维(三)jinja2模板&&roles角色管理-CSDN博客ansible自动化运维(四)运维实战-CSDN博客 ansible自动化运维工具 1.什么是自…...

利用代理IP爬取Zillow房产数据用于数据分析
引言 最近数据分析的热度在编程社区不断攀升,有很多小伙伴都开始学习或从事数据采集相关的工作。然而,网站数据已经成为网站的核心资产,许多网站都会设置一系列很复杂的防范措施,阻止外部人员随意采集其数据。为了解决这个问题&a…...

大屏开源项目go-view二次开发1----环境搭建(C#)
最近公司要求做一个大屏的程序用于展示公司的产品,我以前也没有相关的经验,最糟糕的是公司没有UI设计的人员,领导就一句话要展示公司的产品,具体展示的内容细节也不知道,全凭借自己发挥。刚开始做时是用wpf做的&#x…...

【含开题报告+文档+PPT+源码】基于微信小程序的点餐系统的设计与实现
开题报告 随着互联网技术的日益成熟和消费者生活水平与需求层次的显著提升,外卖点餐平台在中国市场上迅速兴起并深深植根于民众日常生活的各个角落。这类平台的核心在于构建了一个基于互联网的强大订餐服务系统,它无缝整合了餐饮商户资源与广大消费者的…...

k8s中用filebeat文件如何收集不同service的日志
以下是一个详细的从在 Kubernetes 集群中部署 Filebeat,到实现按web-oper、web-api微服务分离日志并存储到不同索引的完整方案: 理解需求:按服务分离日志索引 在 Kubernetes 集群中,有web-oper和web-api两种微服务,希…...

Mysql数据库中,什么情况下设置了索引但无法使用?
在MySQL数据库中,即使已经正确设置了索引,但在某些情况下索引可能无法被使用。 以下是一些常见的情况: 1. 数据分布不均匀 当某个列的数据分布非常不均匀时,索引可能无法有效地过滤掉大部分的数据,导致索引失效。 …...

QT6学习第十一天 Qt Quick控件 Control
QT6学习第十一天 Qt Quick控件控件基类 Control按钮类控件指示器类控件输入类控件日期类控件 Qt Quick控件 Qt Quick本身是为了移动触摸界面而生的,但Qt的跨平台性也决定了它需要支持多种系统。为了支持桌面平台开发,从Qt 5.1开始,增加了新的…...

【唐叔学算法】第16天:枚举-探索所有可能性的艺术
大家好,我是唐叔。今天我们要探讨的是一个看似简单却非常实用的概念——枚举(Enumeration)。它不仅仅是一种数据类型,在算法设计中也是一种解决问题的策略。通过系统地遍历所有可能的情况,我们可以找到满足特定条件的答…...

【OpenCV】基于GrabCut算法的交互式前景提取
介绍 GrabCut 算法是一种用于图像分割的交互式前景提取技术,它结合了图割(Graph Cut)方法和迭代优化过程。该算法最初由 Rother, Kolmogorov 和 Blake 在 2004 年提出,并因其高效性和准确性而被广泛应用于计算机视觉领域。OpenCV…...

【Flask+OpenAI】利用Flask+OpenAI Key实现GPT4-智能AI对话接口demo - 从0到1手把手全教程(附源码)
文章目录 前言环境准备安装必要的库 生成OpenAI API代码实现详解导入必要的模块创建Flask应用实例配置OpenAI API完整代码如下(demo源码)代码解析 利用Postman调用接口 了解更多AI内容结尾 前言 Flask作为一个轻量级的Python Web框架,凭借其…...

最短路----Dijkstra算法详解
简介 迪杰斯特拉(Dijkstra)算法是一种用于在加权图中找到单个源点到所有其他顶点的最短路径的算法。它是由荷兰计算机科学家艾兹格迪科斯彻(Edsger Dijkstra)在1956年提出的。Dijkstra算法适用于处理带有非负权重的图。迪杰斯特拉…...

ORB-SLAM3源码学习:G2oTypes.cc: void EdgeInertial::computeError 计算预积分残差
前言 这部分函数涉及了g2o的内容以及IMU相关的推导内容,需要你先去进行这部分的学习。 1.函数声明 void EdgeInertial::computeError() 2.函数定义 涉及到的IMU的公式: {// TODO Maybe Reintegrate inertial measurments when difference between …...

Unity协程机制详解
Unity的协程(Coroutine)是一种异步编程的机制,允许在多个帧之间分割代码的执行,而不阻塞主线程。与传统的多线程不同,Unity的协程在主线程中运行,并不会开启新的线程。 什么是协程? 协程是一种…...

2024年【高压电工】最新解析及高压电工考试总结
高压电工考试是电力行业从业人员必须通过的资格考试之一,它不仅检验了考生对高压电技术的掌握程度,还考验了考生在实际操作中的安全意识和应急处理能力。为了帮助广大考生更好地备考,本文整理了10道2024年高压电工考试的最新解析及总结试题&a…...

OELOVE 6.0城市列表模板
研究了好久OELOVE6.0源码,一直想将城市列表给单独整出来,做地区排名,但是PHP程序都是加密的,非常难搞,做二开都是要命的处理不了,在这里有一个简单方法可以处理城市列表,并且可以自定义TDK&…...

如何将你的 Ruby 应用程序从 OpenSearch 迁移到 Elasticsearch
作者:来自 Elastic Fernando Briano 将 Ruby 代码库从 OpenSearch 客户端迁移到 Elasticsearch 客户端的指南。 OpenSearch Ruby 客户端是从 7.x 版 Elasticsearch Ruby 客户端分叉而来的,因此代码库相对相似。这意味着当将 Ruby 代码库从 OpenSearch 迁…...

day1数据结构,关键字,内存空间存储与动态分区,释放
小练习 在堆区空间连续申请5个int类型大小空间,用来存放从终端输入的5个学生成绩,然后显示5个学生成绩,再将学生成绩升序排序,排序后,再次显示学生成绩。显示和排序分别用函数完成(两种排序方法࿰…...
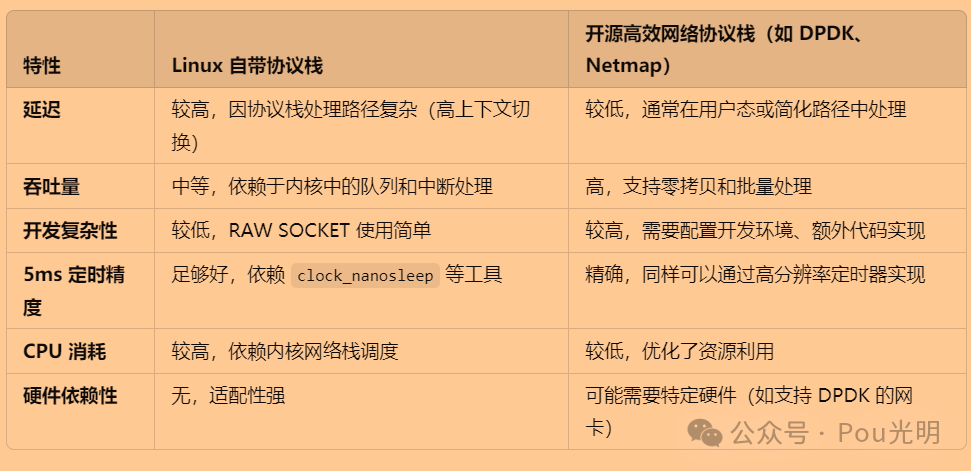
1_linux系统网络性能如何优化——几种开源网络协议栈比较
之前合集《计算机网络从入门到放弃》第一阶段算是已经完成了。都是理论,没有实操,让“程序猿”很难受,操作性不如 Modbus发送的报文何时等到应答和 tcp通信测试报告单1——connect和send。开始是想看linux内核网络协议栈的源码,然…...

【问题记录】07 MAC电脑,使用FileZilla(SFTP)连接堡垒机不成功
项目场景: 使用MAC电脑,以子账号(非root)的形式登录,连接堡垒机CLB(传统型负载均衡),使用FileZilla(SFTP)进行FTP文件传输。 问题描述: MAC电脑…...

NVIDIA Profile Inspector:解锁显卡700+隐藏设置的终极优化指南
NVIDIA Profile Inspector:解锁显卡700隐藏设置的终极优化指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾疑惑,为什么同一款显卡在不同游戏中表现天差地别…...

甲骨文免费服务器到手后,用Xshell连接不上?这份SSH密钥配置避坑指南请收好
甲骨文云SSH连接全攻略:从密钥解析到Xshell实战配置 密钥管理的核心逻辑与常见误区 初次接触甲骨文云免费实例的用户,90%的SSH连接问题都源于密钥处理不当。与常规密码登录不同,甲骨文云强制采用密钥对认证机制,这种设计虽然提升了…...

神经网络概念解码:从物理直觉到工程权衡的思维地图
1. 项目概述:这不是又一本“手把手写反向传播”的书,而是一张神经网络的思维地图“NN#2 — Neural Networks Decoded: Concepts Over Code”这个标题里,“NN#2”不是版本号,而是刻意设计的编号——它暗示这是一场持续进行的认知迭…...

3步快速上手:gmpublisher帮你轻松发布Garry‘s Mod工坊内容
3步快速上手:gmpublisher帮你轻松发布Garrys Mod工坊内容 【免费下载链接】gmpublisher ⚙️ Workshop Publishing Utility for Garrys Mod, written in Rust & Svelte and powered by Tauri 项目地址: https://gitcode.com/gh_mirrors/gm/gmpublisher 还…...
FlashAttention 在昇腾NPU上到底快在哪?一次拆透 ops-transformer 的核心算子
这是一篇关于昇腾NPU上FlashAttention技术深度解析的CSDN博客文章。文章结合了您提供的网页信息(特别是ops-transformer仓库的上下文)以及深度学习算子优化的专业知识,旨在帮助开发者理解其原理、优势及在昇腾生态中的应用。 FlashAttention …...

如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案
如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...

作业5:案例挑战
文章目录1、密码锁设计 P110,2、基于PWM的可调光台灯设计 P131,3、动态密码获取系统设计 P210,效果(1) 密码模式说明(2) 测试密码输入(3) 测试修改密码(4) 测试修改密码模式4、数码管时钟系统设计 P228,7.5.2 数码管时钟系统设计&…...

Seraphine终极指南:英雄联盟免费智能助手,5分钟提升排位胜率15%
Seraphine终极指南:英雄联盟免费智能助手,5分钟提升排位胜率15% 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 还在为英雄联盟排位赛中的战绩查询和BP决策烦恼吗?Seraphin…...

我的日常开发工具迭代|MonkeyCode实测存档
做开发日常,其实大部分编码需求都很琐碎,根本用不上繁杂的专业工具。但市面上的AI编程软件,要么收费贵、额度抠搜,要么功能臃肿、操作繁琐,用起来处处受限。我一直在找一款适配个人日常使用、不折腾、无套路的轻量化编…...

机器学习赋能多共振生物传感:从多维光学数据中挖掘精准检测新范式
1. 项目概述与核心思路在生物传感和医疗诊断领域,我们一直在追求更高的检测精度和更低的检测限。传统的光学折射率传感器,比如基于表面等离子体共振(SPR)或法布里-珀罗腔的传感器,其工作原理大多依赖于监测单个光学共振…...