【学习笔记】深入浅出详解Pytorch中的View, reshape, unfold,flatten等方法。
文章目录
- 一、写在前面
- 二、Reshape
- (一)用法
- (二)代码展示
- 三、Unfold
- (一)torch.unfold 的基本概念
- (二)torch.unfold 的工作原理
- (三) 示例代码
- (四)torch.unfold 的应用场景
- (五)注意事项
- (六)总结
- 四、View
- (一)用法
- (二)注意事项
- (三)其他方法
- 五、Flatten
- (一)torch.flatten 的基本概念
- (二)torch.flatten 的工作原理
- (三)示例代码
- 六、Permute
- (一)torch.permute 的基本概念
- (二)torch.permute 的工作原理
- (三) 示例代码
- (四) torch.permute 的应用场景
- 七、总结
一、写在前面
最近在解析transformer源码的时候突然看到了unfold?我在想unfold是什么意思?为什么不用reshape,他们的底层逻辑有什么区别呢?于是便相对比一下他们之间的区别,便有了本篇博客,希望对大家有帮助!
二、Reshape
(一)用法
1. torch.reshape(input, shape)
输入是tensor和shape,其中原始shape和目标shape的元素数量要一致。
2. Tensor.reshape(shape) → Tensor
与上述用法一致,只不过这个是直接在tensor的基础上进行reshape。
reshpe是按照顺序进行重新排列组合的。
[16,2] 其实与 [4,2,2,2] 是一样的,只要最后一维的数字是一样,其实结果都是一样的。
(二)代码展示
三、Unfold
(一)torch.unfold 的基本概念
torch.unfold 的作用是将输入张量的某个维度展开为多个滑动窗口。每个窗口包含一个局部区域,这些区域可以用于后续的计算。
- 语法:
torch.Tensor.unfold(dimension, size, step)
- 参数:
- dimension:要展开的维度(整数)。
- size:滑动窗口的大小(整数)。
- step:滑动窗口的步长(整数)。
- 返回值:返回一个新的张量,其中指定维度的每个元素被展开为多个滑动窗口。
(二)torch.unfold 的工作原理
假设我们有一个形状为 (N, C, H, W) 的张量(例如图像数据),我们希望在高度维度(H)上提取滑动窗口。
- 输入张量:(N, C, H, W)
- 展开维度:dimension=2(即高度维度 H)
- 窗口大小:size=k(例如 k=3)
- 步长:step=s(例如 s=1)
torch.unfold 会将高度维度 H 展开为多个大小为 k 的滑动窗口,每个窗口之间间隔 s。
(三) 示例代码
- 示例 1:一维张量的展开
import torch
# 创建一个一维张量
x = torch.arange(10)
print("原始张量:", x)# 使用 unfold 展开
unfolded = x.unfold(dimension=0, size=3, step=1)
print("展开后的张量:\n", unfolded)
- 输出:
原始张量: tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
展开后的张量:tensor([[0, 1, 2],[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6],[5, 6, 7],[6, 7, 8],[7, 8, 9]])
- 示例 2:二维张量的展开(图像处理)
import torch
# 创建一个二维张量(模拟图像)x = torch.arange(16).reshape(1, 1, 4, 4) # 形状为 (1, 1, 4, 4)print("原始张量:\n", x)# 使用 unfold 展开unfolded_1 = x.unfold(dimension=2, size=3, step=1)unfolded_2 = unfolded_1.unfold(dimension=3, size=3, step=1)print("展开后的张量形状:", unfolded_1.shape)print("展开后的张量:\n", unfolded_1)print("展开后的张量形状:", unfolded_2.shape)print("展开后的张量:\n", unfolded_2)
- 输出:
原始张量:tensor([[[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]]]])
展开后的张量形状: torch.Size([1, 1, 2, 4, 3])
展开后的张量:tensor([[[[[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]],[[ 4, 8, 12],[ 5, 9, 13],[ 6, 10, 14],[ 7, 11, 15]]]]])
展开后的张量形状: torch.Size([1, 1, 2, 2, 3, 3])
展开后的张量:tensor([[[[[[ 0, 1, 2],[ 4, 5, 6],[ 8, 9, 10]],[[ 1, 2, 3],[ 5, 6, 7],[ 9, 10, 11]]],[[[ 4, 5, 6],[ 8, 9, 10],[12, 13, 14]],[[ 5, 6, 7],[ 9, 10, 11],[13, 14, 15]]]]]])
数组的运算主要看最后两维,倒数第二维代表行,倒数第一维代表列。
(四)torch.unfold 的应用场景
- 卷积操作
在卷积神经网络(CNN)中,卷积核通过滑动窗口的方式提取图像的局部特征。torch.unfold 可以用于手动实现卷积操作。
- 图像处理
在图像处理中,torch.unfold 可以用于提取图像的局部区域(例如提取图像的滑动窗口)。
- 时间序列分析
在时间序列分析中,torch.unfold 可以用于提取时间序列的滑动窗口,用于特征提取或模型训练。
(五)注意事项
- 维度选择:需要明确指定要展开的维度(dimension)。
- 窗口大小和步长:窗口大小(size)和步长(step)的选择会影响展开后的张量形状。
- 内存消耗:torch.unfold 可能会生成较大的张量,尤其是在高维数据上使用时,需要注意内存消耗。
(六)总结
- torch.unfold 的作用:从张量的某个维度提取滑动窗口。
- 常用参数:dimension(展开维度)、size(窗口大小)、step(步长)。
- 应用场景:卷积操作、图像处理、时间序列分析等。
- 注意事项:选择合适的维度、窗口大小和步长,避免内存消耗过大。
四、View
torch.view 用于返回一个与原始张量共享相同数据存储的新张量,但具有不同的形状。换句话说,view 只是改变了张量的视图(view),而不会复制数据。
(一)用法
- Tensor.view(*shape):
- 参数:
*shape:新的形状(可以是整数或元组)。
- 返回值:
返回一个新的张量,具有指定的形状,并与原始张量共享相同的数据存储。
(二)注意事项
- view 返回的张量与原始张量共享相同的数据存储。
- 如果原始张量的数据发生变化,view 返回的张量也会随之变化。
- view 要求张量的内存必须是连续的(即张量在内存中是连续存储的)。如果内存不连续,view 会抛出错误。
(三)其他方法
- view_as
- 作用:将当前张量转换为与另一个张量相同的形状。
- 语法:
torch.Tensor.view_as(other)
- 参数:
other:目标张量,当前张量的形状将被转换为与 other 相同的形状。
- 返回值:
返回一个新的张量,具有与 other 相同的形状,并与原始张量共享数据存储。
- 示例:
import torch
# 创建一个张量
x = torch.arange(12)
print("原始张量:", x)
# 创建目标张量
other = torch.empty(3, 4)
# 使用 view_as 改变形状
y = x.view_as(other)
print("改变形状后的张量:\n", y)
- 输出:
原始张量: tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
改变形状后的张量:tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
- view_as_real
- 作用:将复数张量转换为实数张量。
- 语法:
torch.Tensor.view_as_real()
- 返回值:
返回一个新的实数张量,形状为 (…, 2),其中最后一个维度包含复数的实部和虚部。
- 示例:
import torch
# 创建一个复数张量
x = torch.tensor([1 + 2j, 3 + 4j])
print("原始张量:", x)
# 使用 view_as_real 转换为实数张量
y = x.view_as_real()
print("转换后的张量:\n", y)
- 输出:
原始张量: tensor([1.+2.j, 3.+4.j])
转换后的张量:tensor([[1., 2.],[3., 4.]])
- view_as_complex
- 作用:将实数张量转换为复数张量。
- 语法:
torch.Tensor.view_as_complex()
- 返回值:
返回一个新的复数张量,形状为 (…,),其中最后一个维度被解释为复数的实部和虚部。
- 示例:
import torch
# 创建一个实数张量
x = torch.tensor([[1., 2.], [3., 4.]])
print("原始张量:\n", x)
# 使用 view_as_complex 转换为复数张量
y = x.view_as_complex()
print("转换后的张量:", y)
- 输出:
原始张量:tensor([[1., 2.],[3., 4.]])
转换后的张量: tensor([1.+2.j, 3.+4.j])
- view_as_strided
- 作用:返回一个具有指定步长和内存布局的张量视图。
- 语法:
torch.Tensor.view_as_strided(size, stride)
- 参数:
size:新的形状(元组)。
stride:新的步长(元组)。
- 返回值:
返回一个新的张量,具有指定的形状和步长,并与原始张量共享数据存储。
- 示例:
import torch
# 创建一个张量
x = torch.arange(9).view(3, 3)
print("原始张量:\n", x)
# 使用 view_as_strided 改变形状和步长
y = x.view_as_strided((2, 2), (1, 2))
print("改变形状和步长后的张量:\n", y)
- 输出:
原始张量:tensor([[0, 1, 2],[3, 4, 5],[6, 7, 8]])
改变形状和步长后的张量:tensor([[0, 2],[1, 3]])
- view_as_real 和 view_as_complex 的应用场景
- 复数计算:
在涉及复数计算的任务中,view_as_real 和 view_as_complex 可以用于在复数和实数之间进行转换。
- 信号处理:
在信号处理中,复数张量常用于表示频域信号,view_as_real 和 view_as_complex 可以用于频域和时域之间的转换。
- view_as_strided 的应用场景
- 自定义内存布局:
在需要自定义内存布局的场景中,view_as_strided 可以用于创建具有特定步长和形状的张量视图。
- 高效内存访问:
在需要高效访问内存的场景中,view_as_strided 可以用于优化内存访问模式。
五、Flatten
(一)torch.flatten 的基本概念
torch.flatten 的作用是将输入张量的指定维度展平为一维。它可以展平整个张量,也可以只展平部分维度。
- 语法:
torch.flatten(input, start_dim=0, end_dim=-1)
-
参数:
- input:输入张量。
- start_dim:开始展平的维度(整数),默认为 0。
- end_dim:结束展平的维度(整数),默认为 -1。
- 返回值:返回一个新的张量,具有展平后的形状。
(二)torch.flatten 的工作原理
- torch.flatten 会将指定范围内的维度展平为一维。
- 如果 start_dim=0 且 end_dim=-1,则整个张量会被展平为一维。
- 如果只展平部分维度,则其他维度保持不变。
(三)示例代码
- 示例 1:展平整个张量
import torch
# 创建一个二维张量
x = torch.arange(12).view(3, 4)
print("原始张量:\n", x)
# 使用 flatten 展平整个张量
y = torch.flatten(x)
print("展平后的张量:", y)
- 输出:
原始张量:tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
展平后的张量: tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])- 示例 2:展平部分维度
import torch
# 创建一个三维张量
x = torch.arange(24).view(2, 3, 4)
print("原始张量:\n", x)
# 使用 flatten 展平第二个维度到第三个维度
y = torch.flatten(x, start_dim=1, end_dim=2)
print("展平后的张量:\n", y)
- 输出:
原始张量:tensor([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])
展平后的张量:tensor([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],[12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]])
- 示例 3:展平特定维度
import torch
# 创建一个四维张量
x = torch.arange(24).view(2, 2, 3, 2)
print("原始张量:\n", x)
# 使用 flatten 展平第三个维度
y = torch.flatten(x, start_dim=2, end_dim=2)
print("展平后的张量:\n", y)
- 输出:
原始张量:tensor([[[[ 0, 1],[ 2, 3],[ 4, 5]],[[ 6, 7],[ 8, 9],[10, 11]]],[[[12, 13],[14, 15],[16, 17]],[[18, 19],[20, 21],[22, 23]]]])
展平后的张量:tensor([[[ 0, 1, 2, 3, 4, 5],[ 6, 7, 8, 9, 10, 11]],[[12, 13, 14, 15, 16, 17],[18, 19, 20, 21, 22, 23]]])
六、Permute
(一)torch.permute 的基本概念
torch.permute 的作用是将输入张量的维度按照指定的顺序重新排列。它类似于 NumPy 中的 transpose,但更加灵活,可以同时对多个维度进行排列。
- 语法:
torch.Tensor.permute(*dims)
- 参数:
- *dims:新的维度顺序(元组或多个整数)。
- 返回值:返回一个新的张量,具有重新排列后的维度顺序,并与原始张量共享数据存储。
(二)torch.permute 的工作原理
torch.permute 会将输入张量的维度按照指定的顺序重新排列。
新的维度顺序必须与原始张量的维度数量相同,并且每个维度索引只能出现一次。
(三) 示例代码
- 示例 1:二维张量的转置
import torch
# 创建一个二维张量
x = torch.arange(12).view(3, 4)
print("原始张量:\n", x)# 使用 permute 转置
y = x.permute(1, 0) # 将维度 0 和 1 交换
print("转置后的张量:\n", y)
- 输出:
原始张量:tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
转置后的张量:tensor([[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]])
- 示例 2:三维张量的维度重排
import torch
# 创建一个三维张量
x = torch.arange(24).view(2, 3, 4)
print("原始张量:\n", x)# 使用 permute 重排维度
y = x.permute(2, 0, 1) # 将维度 0, 1, 2 重排为 2, 0, 1
print("重排后的张量形状:", y.shape)
print("重排后的张量:\n", y)
- 输出:
原始张量:tensor([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])
重排后的张量形状: torch.Size([4, 2, 3])
重排后的张量:tensor([[[ 0, 4, 8],[12, 16, 20]],[[ 1, 5, 9],[13, 17, 21]],[[ 2, 6, 10],[14, 18, 22]],[[ 3, 7, 11],[15, 19, 23]]])
- 示例 3:四维张量的维度重排
import torch
# 创建一个四维张量
x = torch.arange(24).view(2, 2, 3, 2)
print("原始张量:\n", x)# 使用 permute 重排维度
y = x.permute(3, 1, 2, 0) # 将维度 0, 1, 2, 3 重排为 3, 1, 2, 0
print("重排后的张量形状:", y.shape)
print("重排后的张量:\n", y)
- 输出:
原始张量:tensor([[[[ 0, 1],[ 2, 3],[ 4, 5]],[[ 6, 7],[ 8, 9],[10, 11]]],[[[12, 13],[14, 15],[16, 17]],[[18, 19],[20, 21],[22, 23]]]])
重排后的张量形状: torch.Size([2, 2, 3, 2])
重排后的张量:tensor([[[[ 0, 12],[ 2, 14],[ 4, 16]],[[ 6, 18],[ 8, 20],[10, 22]]],[[[ 1, 13],[ 3, 15],[ 5, 17]],[[ 7, 19],[ 9, 21],[11, 23]]]])
(四) torch.permute 的应用场景
- 图像处理
在图像处理中,torch.permute 可以用于调整图像的通道顺序。例如,将 (C, H, W) 的图像张量转换为 (H, W, C)。
- 深度学习模型输入
在深度学习中,模型的输入张量通常需要特定的维度顺序。torch.permute 可以用于调整输入张量的维度顺序。
- 数据预处理
在数据预处理中,torch.permute 可以用于调整数据的维度顺序,以便进行后续的计算或操作。
如果每一维度都有特定的含义,此时想改变维度的时候用permute。
七、总结
- reshape 与 view 几乎一致, 甚至可以说reshape可以代替view;
- reshape 与 permute 的区别在于,reshape是按照顺序重新进行排列组合,permute是按照维度进行重新排列组合,如果各个维度都有特定的意义,那么permute会更合适。
- unfold是按照某一维度滑动选取数据,新增加一维,新增加的维度的大小为滑动窗口的大小,原始维度会根据滑动窗口和step的大小而变化。
- flatten也是按照顺序进行展开,且展开的是某个范围的维度,不是特定的维度。
- 不管是几维数组,主要看最后两维,倒数第二维代表行,倒数第一维代表列。
相关文章:

【学习笔记】深入浅出详解Pytorch中的View, reshape, unfold,flatten等方法。
文章目录 一、写在前面二、Reshape(一)用法(二)代码展示 三、Unfold(一)torch.unfold 的基本概念(二)torch.unfold 的工作原理(三) 示例代码(四&a…...

CTFHUB-web(SSRF)
内网访问 点击进入环境,输入 http://127.0.0.1/flag.php 伪协议读取文件 /?urlfile:///var/www/html/flag.php 右击查看页面源代码 端口扫描 1.根据题目提示我们知道端口号在8000-9000之间,使用bp抓包并进行爆破 POST请求 点击环境,访问flag.php 查看页…...

分解质因数
给定 n个正整数 ,将每个数分解质因数,并按照质因数从小到大的顺序输出每个质因数的底数和指数。 输入格式 第一行包含整数 n 接下来 n行,每行包含一个正整数 。 输出格式 对于每个正整数 ,按照从小到大的顺序输出其分解质因数后&…...

前景物体提取
参考:精选课:C完整的实现双目摄像头图像采集、双目摄像头畸变矫正、前景物体提取、生成视差图、深度图、PCL点云图 前景物体提取是计算机视觉中的一个重要技术,可以用于视频监控、虚拟现实和计算机视觉等领域。 1.前景物体提取的原理 前景…...

Kotlin复习
一、Kotlin类型 1.整数 2.浮点 显示转换: 所有数字类型都支持转换为其他类型,但是转换前会检测长度。 toByte(): Byte toShort(): Short toInt(): Int toLong(): Long toFloat(): Float toDouble(): Double 不同进制的数字表示方法(为了提高…...

【AI日记】24.12.17 kaggle 比赛 2-6 | 把做饭看成一种游戏 | 咖喱牛肉
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】 工作 参加:kaggle 比赛 Regression with an Insurance Dataset时间:9 小时睡得好很重要 读书 书名:富兰克林自传时间:0.5 小时阅读原因:100 美元纸…...

操作系统(14)请求分页
前言 操作系统中的请求分页,也称为页式虚拟存储管理,是建立在基本分页基础上,为了支持虚拟存储器功能而增加了请求调页功能和页面置换功能的一种内存管理技术。 一、基本概念 分页:将进程的逻辑地址空间分成若干个大小相等的页&am…...

uniapp navigateTo、redirectTo、reLaunch等页面路由跳转方法的区别
uni.switchTab 跳转到 tabBar 页面,并关闭其他所有非 tabBar 页面 // app.json {"tabBar": {"list": [{"pagePath": "index","text": "首页"},{"pagePath": "other","text&…...
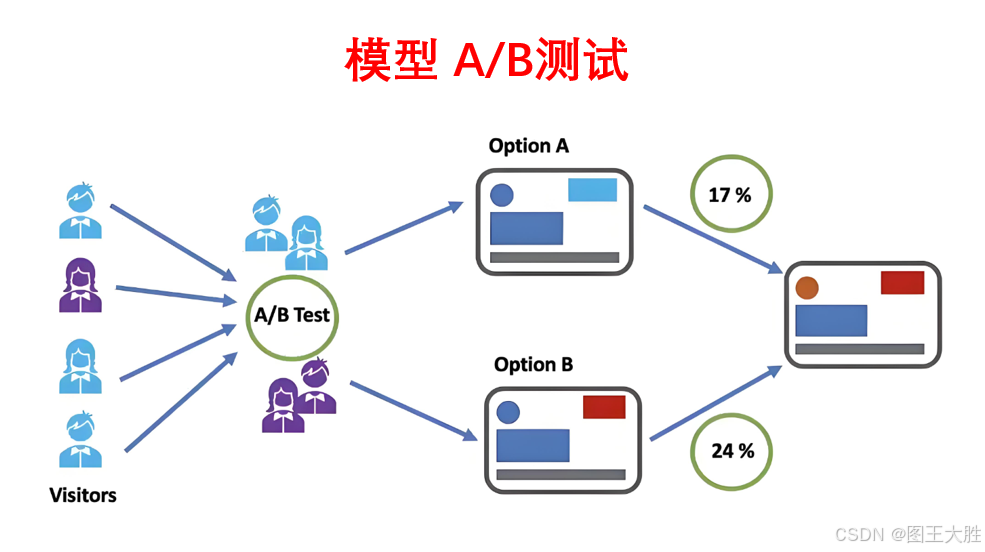
模型 A/B测试(科学验证)
系列文章 分享 模型,了解更多👉 模型_思维模型目录。控制变量法。 1 A/B测试的应用 1.1 Electronic Arts(EA)《模拟城市》5游戏网站A/B测试 定义目标: Electronic Arts(EA)在发布新版《模拟城…...
谷歌发布升级版AI视频生成器Veo 2与图像生成器Imagen 3
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
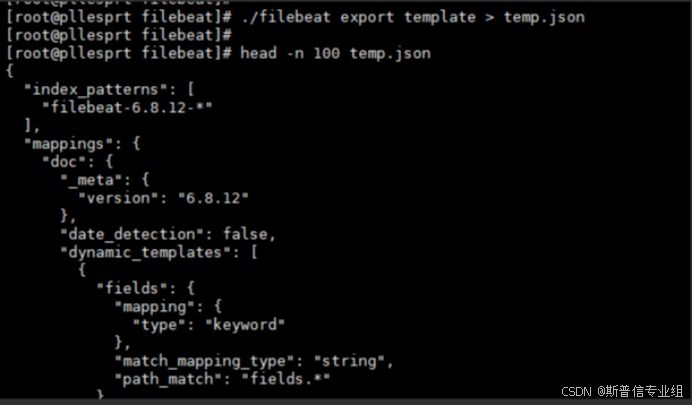
快速掌握源码部署Filebeat
文章目录 1. 裸金属安装1.1 压缩包方式安装1.2 yum方式安装 2. docker安装3. K8s安装 项目使用了Filebeat,现在需要运行在ARM架构的服务器上,但是Filebeat官方没有提供,需要自己编译一份 filebeat等组件的源码地址 https://github.com/elasti…...

C++ 哈希表封装unordered_map 和 unordered_set
1.源码框架 SGI-STL30版本源代码中没有unordered_map和unordered_set,SGI-STL30版本是C11之前的STL 版本,这两个容器是C11之后才更新的。但是SGI-STL30实现了哈希表,只容器的名字是hash_map 和hash_set,他是作为⾮标准的容器出现…...

pymysql 入门
发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。 1. 什么是 PyMySQL? PyMySQL 是一个纯 Python 编写的 MySQL 客户端库,可以通过它轻松地在 Python 中连…...

Leecode刷题C++之形成目标字符串需要的最少字符串数①
执行结果:通过 执行用时和内存消耗如下: 代码如下: class Solution { public:int minValidStrings(vector<string>& words, string target) {auto prefix_function [](const string& word, const string& target) -> vector<…...

Linux应用开发————mysql数据库
数据库概述 什么是数据库(database)? 数据库是一种数据管理的管理软件,它的作用是为了有效管理数据,形成一个尽可能无几余的数据集合,并能提供接口,方便用户使用。 数据库能用来干什么? 顾名思义,仓库就是用来保存东…...

4_使用 HTML5 Canvas API (3) --[HTML5 API 学习之旅]
4_使用 HTML5 Canvas API (3) --[HTML5 API 学习之旅] 1.缩放 canvas 对象 在 <canvas> 中缩放对象可以通过 scale 方法来实现。这个方法会根据提供的参数对之后绘制的所有内容进行缩放。下面是两个具体的示例,展示如何使用 scale 方法来缩放 canvas 上的对…...

docker build次数过多,导致磁盘内存不足:ERROR: no space left on device
在使用 docker build 构建镜像时,Docker 会创建一个临时的构建上下文,生成镜像的过程中会产生多个中间层。这些文件和层会占用磁盘空间。构建完成后,如果你没有清理这些不再使用的中间层和临时文件,可能会导致磁盘空间不足。 常见…...

LDO和DC-DC的区别、DCDC和LDO主要指标
LDO和DC-DC的区别 LDO外围器件少,电路简单,成本低;DC-DC外围器件多,电路复杂,成本高; LDO负载响应快,输出纹波小;DC-DC负载响应比LDO慢,输出纹波大; LDO效…...

LeetCode hot100-81
https://leetcode.cn/problems/climbing-stairs/description/?envTypestudy-plan-v2&envIdtop-100-liked 70. 爬楼梯 已解答 简单 相关标签 相关企业 提示 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢&…...

RTMP、RTSP、RTP、HLS、MPEG-DASH协议的简介,以及应用场景
实时视频传输协议 1. RTMP(Real Time Messaging Protocol) 简介:RTMP是由Adobe公司开发的实时消息传输协议,主要用于流媒体数据的传输。它基于TCP传输,具有低延迟、高可靠性的特点。特点:RTMP支持多种视…...

Hotkey Detective:3分钟快速定位Windows热键冲突的终极指南
Hotkey Detective:3分钟快速定位Windows热键冲突的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...

手机号查QQ号终极指南:3分钟快速找回遗忘的QQ号码
手机号查QQ号终极指南:3分钟快速找回遗忘的QQ号码 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 你是否曾因忘记QQ号而无法登录?是否因为更换手机需要重新绑定QQ却找不到账号信息?手机号查QQ号工…...

惊心动魄!从“卡脖子”到“心脏搭桥”,6台路由器带你亲历IPv6平滑迁移
摘要:从IPv4地址耗尽,到DNS根域服务器“卡脖子”风险,再到中国部署IPv6根服务器,网络协议的演进不仅关乎技术,更关乎国家战略。本文带你穿越互联网发展史,并通过eNSP搭建6台路由器的复杂拓扑,手把手演示如何在不重启设备、不影响业务的前提下,将网络从IPv4平滑迁移至IP…...

Local AI MusicGen创意展示:由‘neon lights vibe’触发的都市夜景音乐
Local AI MusicGen创意展示:由‘neon lights vibe’触发的都市夜景音乐 1. 引言:当AI遇见音乐创作 你有没有想过,用一段简单的文字描述就能生成一段专属的背景音乐?Local AI MusicGen让这个想法变成了现实。这是一个基于Meta Mu…...
)
ISOLAR-B系统配置实战:如何将DBC文件信号正确映射到SWC Port(CAN网络示例)
ISOLAR-B系统配置实战:DBC信号与SWC Port的精准映射指南 当你在AUTOSAR开发中完成应用层SWC设计后,最令人头疼的莫过于如何让这些精心设计的组件与真实的ECU网络信号"对话"。ISOLAR-B作为BSW配置的核心工具,其系统级配置能力直接决…...

快速验证模型服务:AutoGen Studio中连接vLLM部署的Qwen3-4B
快速验证模型服务:AutoGen Studio中连接vLLM部署的Qwen3-4B 1. 环境准备与快速部署 1.1 镜像启动与基础检查 首先确保已成功启动AutoGen Studio镜像,该镜像已预置vLLM部署的Qwen3-4B-Instruct-2507模型服务。验证模型服务是否正常运行: c…...

OpenClaw技能扩展:千问3.5-35B-A3B-FP8驱动的内容生成与发布
OpenClaw技能扩展:千问3.5-35B-A3B-FP8驱动的内容生成与发布 1. 为什么选择OpenClaw千问3.5做内容自动化 去年冬天,当我第一次尝试用AI自动化完成公众号内容生产时,经历了典型的"缝合怪"工作流:ChatGPT生成初稿→Midj…...

OpenClaw替代方案:当Qwen3-4B不可用时降级策略
OpenClaw替代方案:当Qwen3-4B不可用时降级策略 1. 为什么需要降级策略 上周三凌晨3点,我的OpenClaw自动化脚本突然停止了工作。原本定时执行的周报生成任务卡在了模型调用环节——Qwen3-4B服务因网络波动暂时不可用。这次意外让我意识到:依…...

OpenClaw安全方案:百川2-13B-4bits量化模型的本地化数据边界
OpenClaw安全方案:百川2-13B-4bits量化模型的本地化数据边界 1. 为什么我们需要本地化数据边界 去年我在帮一家初创公司做财务自动化方案时,遇到一个棘手问题:他们需要分析包含客户银行账号的Excel报表,但公司严格禁止数据上传到…...

Beyond Compare许可证获取与激活全攻略
1. Beyond Compare简介与许可证类型解析 Beyond Compare作为一款老牌文件对比工具,已经陪伴开发者走过了20多个年头。我第一次接触它是在2015年做代码合并时,当时就被它直观的三栏式对比界面惊艳到了——左右两侧显示对比内容,中间实时标注差…...