Linux - MySQL迁移至一主一从
Linux - MySQL迁移至一主一从
- 迁移准备
- 安装MySQL
- ibd文件迁移
- 原服务器操作
- 目标服务器操作
- 一主一从
- 增量同步
- 异常解决
- 结尾
首先部分单独安装MySQL,请参考Linux - MySQL安装,迁移数据量比较大约400G左右且网络不通故使用文件迁移,需开启一段时间只读和锁表。
迁移准备
| 测试机 | 作用 |
|---|---|
| 172.17.7.9 | 原MySQL |
| 10.3.69.6 | 目标主库 |
| 10.3.69.7 | 目标从库 |
原服务器与目标服务器不在同一局域网内而且无外网。
思路
先检测原MySQL健康的表进行记录,设置原MySQL为只读以及锁表,防止迁移过程中继续写入,记录时间点用作迁移后增量同步,导出所有表结构和ibd文件,解锁恢复读写,将表结构和ibd文件转至目标主库以及从库,都先进行恢复ibd文件,然后进行主从连接,使用binlog导出原MySQL时间点开始的sql日志,并增量同步至目标主库。
安装MySQL
先在目标2台服务器上面安装MySQL,请参考Linux - MySQL安装,其中my.cnf配置参考以下,其中server_id主库与从库不一致 主库6 从库7,其他配置都一致,具体参数值参考自己MySQL需求大小进行配置。
[mysqld]
basedir=/usr/local/mysql/mysql8
datadir=/home/mysql/data
log-error=/home/mysql/log/mysql.logserver_id=6
gtid_mode=on
enforce_gtid_consistency=on
binlog_format=row
log-slave-updates=on
log-bin=mysqlbin-log
binlog_row_image = minimalmax_connections=2000
lower_case_table_names=1
character-set-server=utf8mb4
default_authentication_plugin=mysql_native_password
max_binlog_size=1G
max_binlog_cache_size=4G
log_timestamps=system
配置好后就初始化MySQL,然后重置密码操作什么的,先不进行主从连接。
ibd文件迁移
原服务器操作
注:其中有些打通ssh免密也进行了记录(假设原服务器和目标服务器可以互通),本次迁移未使用到ssh免密
ssh免密
ssh-keygen -t rsa
ssh-copy-id root@10.3.69.6
ssh-copy-id root@10.3.69.7
ssh root@10.3.69.6 # 测试是否免密登录
ssh root@10.3.69.7
创建一个export.sh脚本
找一个磁盘够大的位置(看数据量),创建一个transfer文件夹,在这个文件夹里面创建脚本
我们要一次一个库的去迁移(数据量有点大没磁盘了)当然也可以一次全部迁移全部的库(自行加一个循环),先查询某个库的所有表名,然后导出这个库所有的表结构,然后把ibd文件复制压缩即可
此处我自己写了一个py每过10s向数据库orders表中新增一条数据,模拟真实写入
#!/bin/bash# 数据库连接信息 变量 - 需要更改的
DB_USER="root" # 替换为你的数据库用户名
DB_PASSWORD="123456" # 替换为你的数据库密码
DB_HOST="172.17.7.9" # 主机地址
DB_NAME="dw" # 数据库名称,想迁移整个MySQL所有库可以写个大循环
MYSQLDUMP_PATH="/usr/local/mysql/mysql8/bin/mysqldump" # mysqldump 路径
MYSQL_DATA_DIR="/home/weekeight/mysql/data/${DB_NAME}" # MySQL 数据目录路径# 注:下面的所有值都不需要修改
# 输出文件路径
TABLES_FILE="${DB_NAME}_table_name.txt"
SCHEMA_FILE="${DB_NAME}_schema.sql"
# 创建 dw 文件夹(如果不存在)
DW_DIR="./${DB_NAME}"
mkdir -p "$DW_DIR"
# 查询所有表名并保存到文件,移除标题行
mysql -u "$DB_USER" -p"$DB_PASSWORD" -h "$DB_HOST" -D "$DB_NAME" -e "SHOW TABLES;" | sed '1d' > "$TABLES_FILE"
if [ $? -ne 0 ]; thenecho "导出表名时发生错误"exit 1
fi
echo "表名已成功导出到 $TABLES_FILE"
# 使用 mysqldump 导出表结构到文件
$MYSQLDUMP_PATH -u "$DB_USER" -p"$DB_PASSWORD" -h "$DB_HOST" --no-data --single-transaction --routines --triggers --events "$DB_NAME" > "$SCHEMA_FILE"
if [ $? -ne 0 ]; thenecho "导出表结构时发生错误"exit 1
elseecho "表结构已成功导出到 $SCHEMA_FILE"
fi
# 复制 IBD 文件到 dw 文件夹
while IFS= read -r table; doibd_file="${MYSQL_DATA_DIR}/${table}.ibd"if [ -f "$ibd_file" ]; thencp "$ibd_file" "$DW_DIR/"echo "复制了 $ibd_file 到 $DW_DIR/"elseecho "警告: $ibd_file 不存在"fi
done < "$TABLES_FILE"
# 压缩打包 dw 文件夹
TAR_FILE="${DB_NAME}_ibd_files.tar.gz"
tar -czvf "$TAR_FILE" "$DW_DIR"
if [ $? -eq 0 ]; thenecho "dw 文件夹已成功压缩打包为 $TAR_FILE"
elseecho "压缩打包时发生错误"exit 1
fi
# 清理临时文件夹
rm -rf "$DW_DIR"上面的脚本写好记得添加权限
chmod +x export.sh
搞好sh脚本后先不用管他,接下来我们进入MySQL进行设置只读和锁表,然后执行脚本,恢复MySQL
SET GLOBAL read_only = ON; # 设置全局只读模式
FLUSH TABLES WITH READ LOCK; # 锁表
SHOW ENGINE INNODB STATUS\G # 检查当前是否还有事务正在执行
# 记录一下当前时间(16:26:00,order结尾11),用作后续的增量同步,order结尾11验证后面的增量同步order.ibd中只存在11条数据
# 然后去执行上面的./export.sh脚本,脚本执行完毕后继续在MySQL中执行以下命令恢复MySQL
UNLOCK TABLES; # 解除锁表
SET GLOBAL read_only = OFF; # 恢复读写模式,恢复后order表记录到38,上面sh脚本保存的ibd文件中不包含12-38
现在的我们已经生成了三个文件了,一个ibd数据文件、一个dw库所有表名文件、一个dw库表结构文件,可以把export.sh文件删除了,已经没用了

接下来就是把这三个文件移动到目标服务器了,下面使用scp,
scp -r ./transfer/ root@10.3.69.6:/home/weekeight/
scp -r ./transfer/ root@10.3.69.7:/home/weekeight/
目标服务器操作
下面的操作在目标服务器的两台上面同步执行命令
cd /home/weekeight/transfer/ # 进入移动过来的文件夹里面
创建一个import.sh脚本
#!/bin/bash# 变量 - 需要更改的
DB_USER="root" # 替换为你的数据库用户名
DB_PASSWORD="123456" # 替换为你的数据库密码
DB_NAME="dw" # 迁移数据库名
MYSQL_DATA_DIR="/home/mysql/data/${DB_NAME}" # MySQL 数据目录路径
TRANSFER_DIR="/home/weekeight/transfer" # 资源目录,就是从原服务器移动过来的# 注:下面的所有值都不需要修改
IBD_TAR_FILE="${TRANSFER_DIR}/${DB_NAME}_ibd_files.tar.gz"
SCHEMA_FILE="${TRANSFER_DIR}/${DB_NAME}_schema.sql"
TABLES_NAME="${TRANSFER_DIR}/${DB_NAME}_table_name.txt"
log_file="all.log"
# 清空日志文件
> "$log_file"
# 检查数据库是否存在
check_db_exists() {mysql -u "$DB_USER" -p"$DB_PASSWORD" -e "SHOW DATABASES LIKE '$DB_NAME';" | grep -w "$DB_NAME" > /dev/null
}
# 检查数据库是否存在
if check_db_exists; thenecho "数据库 $DB_NAME 已存在。" | tee -a "$log_file"
else# 创建数据库echo "正在创建数据库 $DB_NAME..." | tee -a "$log_file"mysql -u "$DB_USER" -p"$DB_PASSWORD" -e "CREATE DATABASE IF NOT EXISTS $DB_NAME;"if [ $? -ne 0 ]; thenecho "创建数据库 $DB_NAME 失败,请检查数据库连接信息和权限。" | tee -a "$log_file"exit 1elseecho "数据库 $DB_NAME 创建成功。" | tee -a "$log_file"fi
fi
# 导入表结构
echo "正在导入表结构..." | tee -a "$log_file"
mysql -u "$DB_USER" -p"$DB_PASSWORD" "$DB_NAME" < "$SCHEMA_FILE"
if [ $? -eq 0 ]; thenecho "表结构已成功导入到数据库 $DB_NAME 中。" | tee -a "$log_file"
elseecho "导入表结构失败,请检查 $SCHEMA_FILE 是否存在且格式正确。" | tee -a "$log_file"exit 1
fi
# 解压 IBD 文件压缩包
echo "解压 IBD 文件..." | tee -a "$log_file"
tar -xzvf "$IBD_TAR_FILE" -C "$TRANSFER_DIR"
if [ $? -ne 0 ]; thenecho "解压失败,请检查 $IBD_TAR_FILE 是否存在且无损坏。" | tee -a "$log_file"exit 1
elseecho "解压成功,文件已放置在 $TRANSFER_DIR 中。" | tee -a "$log_file"
fi
# 循环读取表名
while IFS= read -r table_name; doecho "开始处理表 $table_name..." | tee -a "$log_file"# 设置源和目标路径source_path="${TRANSFER_DIR}/${DB_NAME}/${table_name}.ibd"destination_path="${MYSQL_DATA_DIR}/${table_name}.ibd"# 清除表空间mysql -u "$DB_USER" -p"$DB_PASSWORD" -e "ALTER TABLE $DB_NAME.$table_name DISCARD TABLESPACE;"if [ $? -ne 0 ]; thenecho "表 $table_name: DISCARD TABLESPACE 失败,跳过" | tee -a "$log_file"continuefi# 复制 .ibd 文件cp "$source_path" "$destination_path"if [ $? -ne 0 ]; thenecho "表 $table_name: 文件复制失败,跳过" | tee -a "$log_file"continuefi# 修改文件拥有者为 mysqlchown mysql:mysql "$destination_path"if [ $? -ne 0 ]; thenecho "表 $table_name: 更改文件拥有者失败,跳过" | tee -a "$log_file"continuefi# 导入表空间mysql -u "$DB_USER" -p"$DB_PASSWORD" -e "ALTER TABLE $DB_NAME.$table_name IMPORT TABLESPACE;"if [ $? -ne 0 ]; thenecho "表 $table_name: IMPORT TABLESPACE 失败,跳过" | tee -a "$log_file"continuefiecho "表 $table_name 迁移成功" | tee -a "$log_file"
done < "$TABLES_NAME"
echo "所有表处理完成,详情见 $log_file" | tee -a "$log_file"
创建import.sh后执行下面操作
chmod +x import.sh # 修改权限
./import.sh # 执行,执行完毕后检查一下打印是否正确,可以查看all.log日志
cd ..
rm -rf ./transfer # 删除移动过来的文件夹即可,已无用
一主一从
下面是在目标服务器的MySQL上的操作,是进行一主一从的连接
首先在主库上面查看gtid值
mysql> SHOW VARIABLES LIKE 'gtid_executed';
+---------------+-------------------------------------------+
| Variable_name | Value |
+---------------+-------------------------------------------+
| gtid_executed | 36513eed-b6bd-11ef-843c-6c92bfcb11f0:1-76 |
+---------------+-------------------------------------------+
1 row in set (0.01 sec)
然后在从库上面进行绑定连接
SET @@GLOBAL.GTID_PURGED='36513eed-b6bd-11ef-843c-6c92bfcb11f0:1-76'; # 把主库的gtid添加到这里
change master to master_host='10.3.69.6',master_port=3306,master_user='root',master_password='123456',master_auto_position=1 for channel 'master1'; # 连接主库创建管道名为msater1
start slave for channel 'master1'; # 单独启动master1进行复制,可使用start slave;
show slave status\G # 查看从库的状态,状态中Slave_IO_Running与Slave_SQL_Running同为yes时正常,不然就是异常
下面的几个命令不需要执行,如果主从连接出现了问题,那么我们就要停止连接,清除配置,重新连接时使用的
stop slave; # 停止主从
reset master; # 重置主库配置
reset slave all; # 重置从库配置
下面就是去主库上面进行创建一个数据库,或者写入数据,查看从库是否变化了
增量同步
上方已经记录了时间以及order参数(16:26:00),目标数据库的参数为11,原数据库的参数是38
先在原mysql上面进行查看binlog的file,然后导出binlog信息
mysql> SHOW MASTER STATUS;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000014 | 33034659 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
- –skip-gtids:跳过GTID事件,必填项,不加的话导出的数据用不了,GTID冲突
- –database:指定数据库
- –start-datetime:指定开始时间,此时间即锁表后的时间,上面已经记录了
- –stop-datetime:指定结束时间,最好指定此时间,导出的数据包头不包尾,这样的话如果有需要,下次的增量同步这个就是开始时间
- binlog的文件在MySQL数据目录中,上面已经有文件名称了
/usr/local/mysql/mysql8/bin/mysqlbinlog --skip-gtids --database=dw --start-datetime="2024-12-12 16:26:00" --stop-datetime="2024-12-13 10:00:00" /home/weekeight/mysql/data/binlog.000014 > ./dw20241213100000.sql
把dw20241213100000.sql文件发送到目标服务器主库上面,从库不需要。
scp -r ./dw20241213100000.sql root@10.3.69.6:/usr/local/
下面在主库上导入sql
mysql -u root -p dw < dw20241213100000.sql
然后查看主库以及从库orders参数是否增加。
异常解决
@@SESSION.GTID_NEXT cannot be set to ANONYMOUS when @@GLOBAL.GTID_MODE = ON.
主库执行增量的sql文件时报错
binlog导出sql信息时使用–skip-gtids跳过GTID事件
Multiple channels exist on the slave. Please provide channel name as an argument
需要将从机的master清空(本机连接的有master的也要清空)
stop slave; reset slave all; reset master;
@@GLOBAL.GTID_PURGED cannot be changed: the added gtid set must not overlap with @@GLOBAL.GTID_EXECUTED
reset master;
@@GLOBAL.GTID_PURGED cannot be changed: the new value must be a superset of the old value
之前已经存在gtid了想再需要配置一个多个的
SET @@GLOBAL.GTID_PURGED=‘以前的gtid…,新的gtid’;
结尾
至此MySQL迁移至一主一从已经全部搞定,如果有问题或者有其他好的方案望提议,共同学习。
相关文章:
Linux - MySQL迁移至一主一从
Linux - MySQL迁移至一主一从 迁移准备安装MySQL ibd文件迁移原服务器操作目标服务器操作 一主一从增量同步异常解决结尾 首先部分单独安装MySQL,请参考Linux - MySQL安装,迁移数据量比较大约400G左右且网络不通故使用文件迁移,需开启一段时间…...
《变形金刚:赛博坦的陨落》游戏启动难题:‘buddha.dll’缺失的七大修复策略
《变形金刚:赛博坦的陨落》游戏启动时提示buddha.dll缺失:原因与解决方案 作为一名软件开发从业者,我在日常工作中经常遇到电脑游戏运行时出现的各种问题,如文件丢失、文件损坏和系统报错等。今天,我们就来探讨一下《…...

51c嵌入式~单片机~合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/12362395 一、不同的电平信号的MCU怎么通信? 下面这个“电平转换”电路,理解后令人心情愉快。电路设计其实也可以很有趣。 先说一说这个电路的用途:当两个MCU在不同的工作电压下工作&a…...

java Resource 记录
Java 注解 Resource 是一个标准的 Java 注解,用于注入资源。它可以用于注入任何资源,如文件、数据库连接、用户定义的资源等。它可以通过名称或类型进行注入。 当你想要注入一个bean到你的类中时,你可以使用Resource注解。 解决方案1&#…...

Avalonia 开发环境准备
总目录 前言 介绍如何搭建 Avalonia 开发环境。 一、在线开发环境搭建 请先安装您选择的受支持的IDE。Avalonia 支持 Visual Studio、Rider 和 Visual Studio Code。 详见:https://docs.avaloniaui.net/zh-Hans/docs/get-started/install 1. 使用 Visual Studio 20…...
; win 和 docker容器输出不同)
C# 中 Console.WriteLine($“{DateTime.Now.Date}“); win 和 docker容器输出不同
Console.WriteLine($"{DateTime.Now.Date}"); //windowns输出:2024/12/10 0:00:00 //docker容器输出:12/10/2024 00:00:00 这是由于 不同的文化区域(CultureInfo)设置 导致的时间格式差异。在 Windows 系统…...

回型矩阵:JAVA
解题思路: 通过定义四条边界;top,left,right,bottom,来循环,当top>bottom&&left>right的时候循环终止 循环结束的条件: 链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述…...

从零开始学习 sg200x 多核开发之 sophpi 编译生成 fip.bin 流程梳理
本文主要介绍 sophpi 编译生成 fip.bin 流程。 1、编译前准备 sophpi 的基本编译流程如下: $ source build/cvisetup.sh $ defconfig sg2002_wevb_riscv64_sd $ clean_all $ build_all $ pack_burn_image注: 需要在 bash 下运行clean_all 非必要可以不…...

python--在服务器上面创建conda环境
今天刚开始使用服务器的时候使用上面的公共环境发现老师缺少模块, [guoyupingcins195 ~]$ conda --version Traceback (most recent call last): File "/home/miniconda3/bin/conda", line 12, in <module> from conda.cli import main Fil…...

day15 python(3)——python基础(完结!!)
【没有所谓的运气🍬,只有绝对的努力✊】 目录 1、函数 1.1 函数传参中的拆包 1.2 匿名函数的定义 1.3 匿名函数练习 1.4 匿名函数应用——列表中的字典排序 2、面向对象 OOP 2.1 面向对象介绍 2.2 类和对象 2.3 类的构成和设计 2.4 面向对象代码…...

/:087启动游戏时提示丢失”d3dx···.dll””VCOMP···.dll”
/:087启动游戏时提示丢失”d3dx.dll””VCOMP.dll”或遇到应用程序无法正常启动(0xc000007b)和游戏有图像没有声音等情况。 主要是因为系统缺少大型游戏/软件运行的必备组件,这些组件有DirectX,Visual C2010,2012&…...

利用PHP和phpSpider进行图片爬取及下载
利用PHP和phpSpider进行图片爬取及下载,可以遵循以下步骤。phpSpider是一个开源的PHP爬虫框架,它可以帮助你轻松地抓取网页内容。以下是一个基本的步骤指南: 1. 安装phpSpider 首先,你需要确保你已经安装了Composer(…...

企业架构划分探讨:业务架构与IT架构的利与弊
在企业架构(EA)的江湖里,大家一直致力于如何把企业的复杂性简化成有条有理的架构蓝图。有人选择把企业架构分成业务架构和IT架构,而IT架构又进一步细分为应用架构、数据架构和技术架构。但一提到这种划分方式,总有人跳…...

Java设计模式 —— 【结构型模式】桥接模式详解
前言 现在有一个需求,需要创建不同的图形,并且每个图形都有可能会有不同的颜色。 首先我们看看用继承来实现: 我们可以发现有很多的类,假如我们再增加一个形状或再增加一种颜色,就需要创建更多的类。 试想…...

MySQL学习之DDL操作
目录 数据库的操作 创建 查看 选择 删除 修改 数据类型 表的创建 表的修改 表的约束 主键 PRIMARY KEY 唯一性约束 UNIQUE 非空约束 NOT NULL 外键约束 约束小结 索引 索引分类 常规索引 主键索引 唯一索引 外键索引 优点 缺点 视图 创建 删除 修改…...
游戏AI实现-寻路算法(A*)
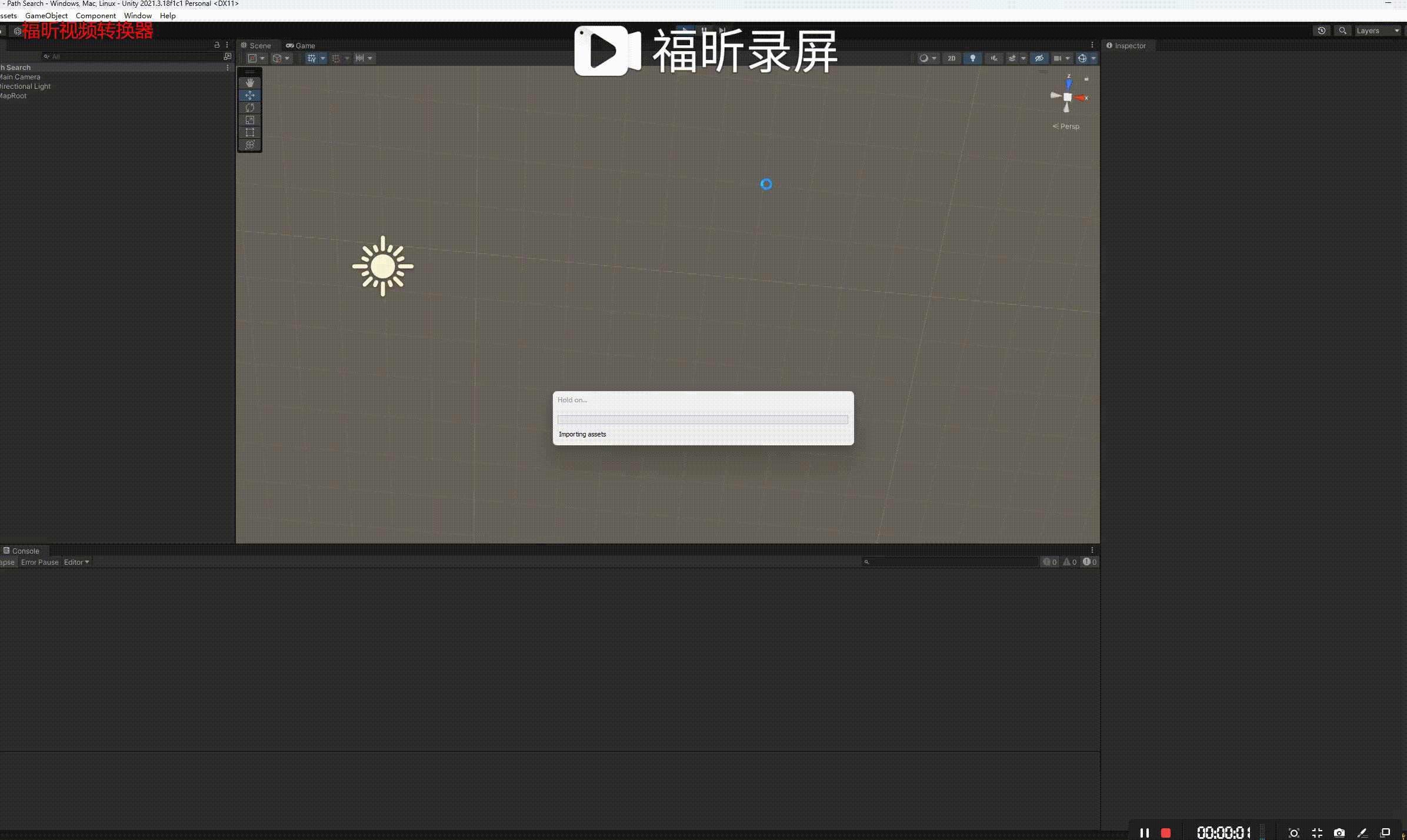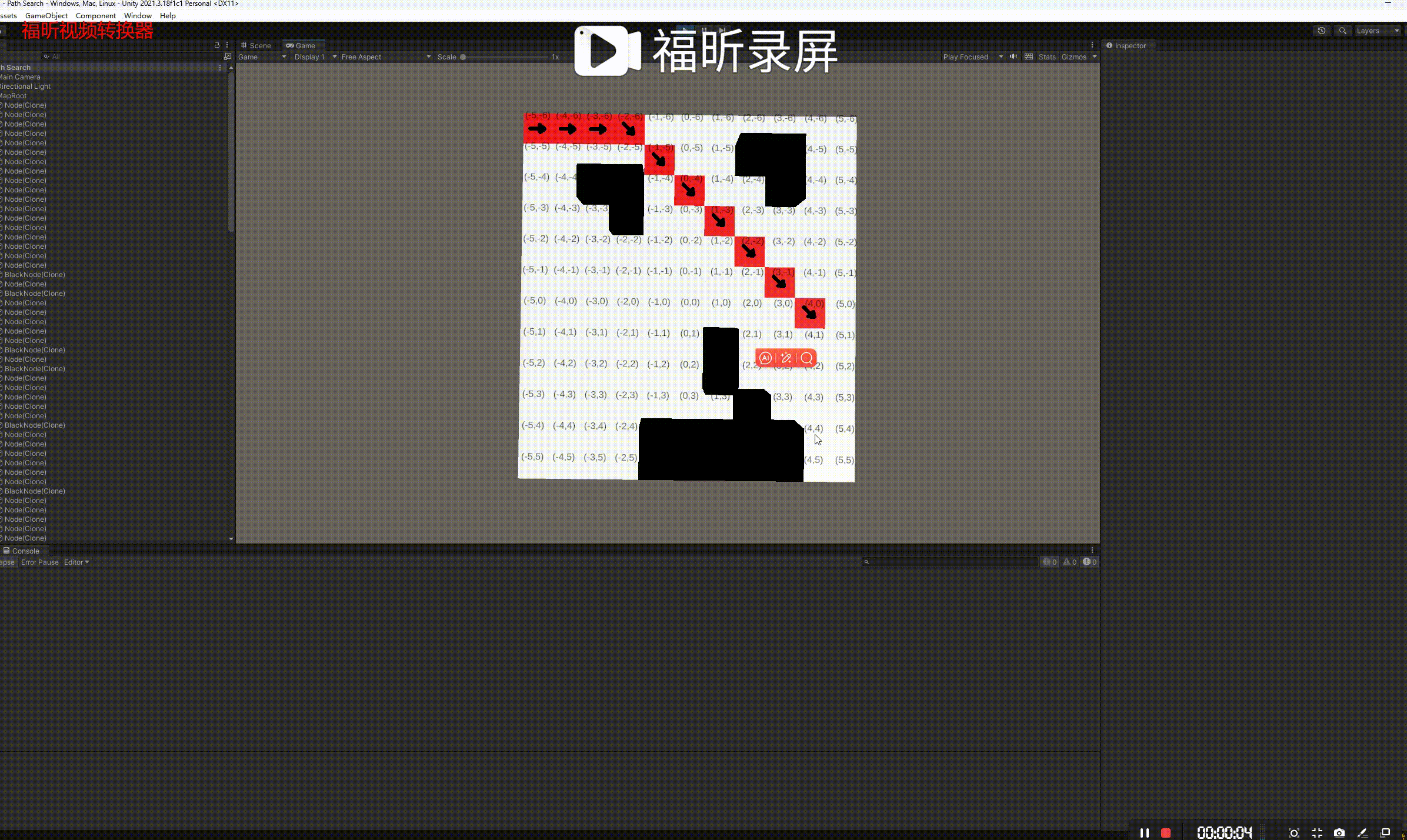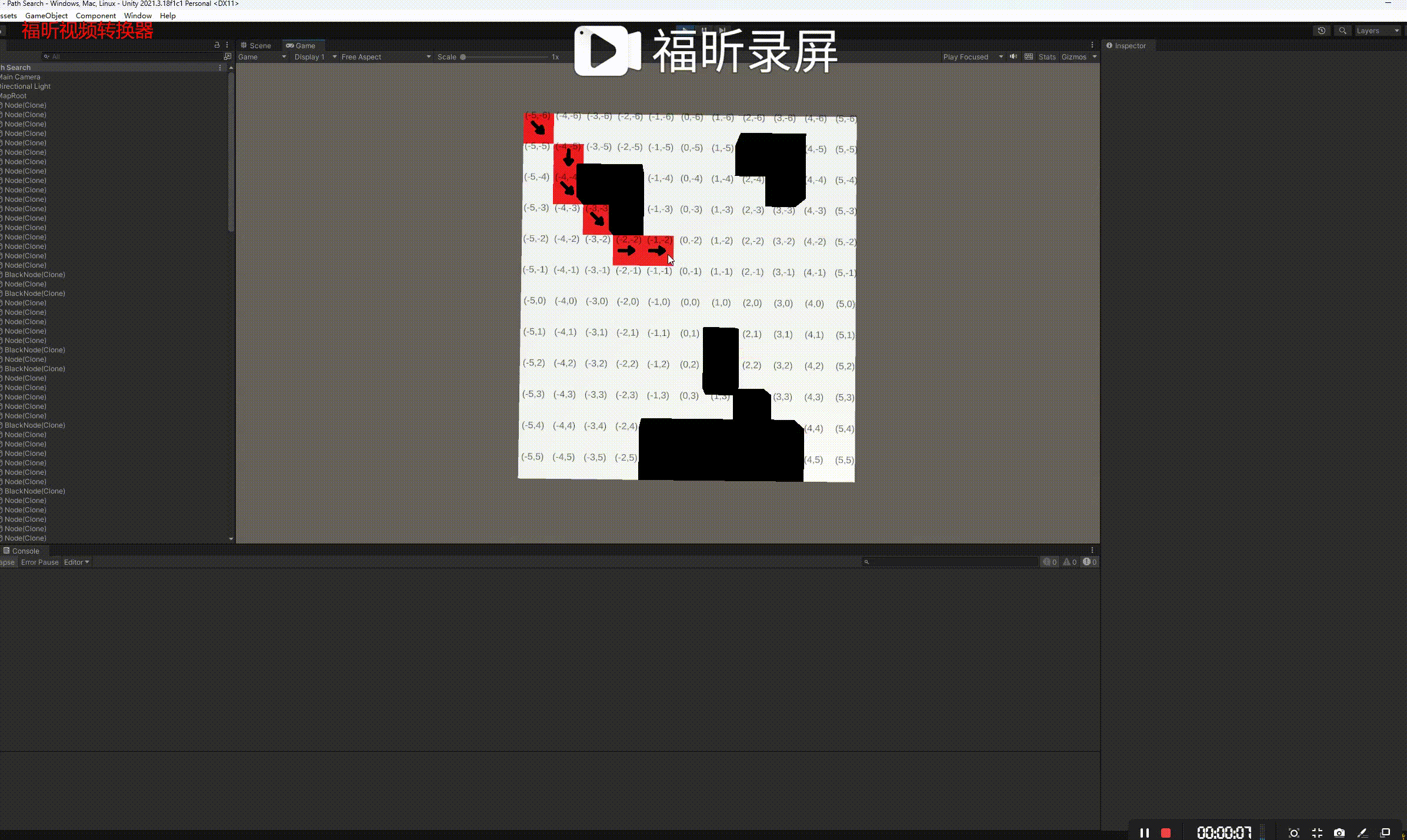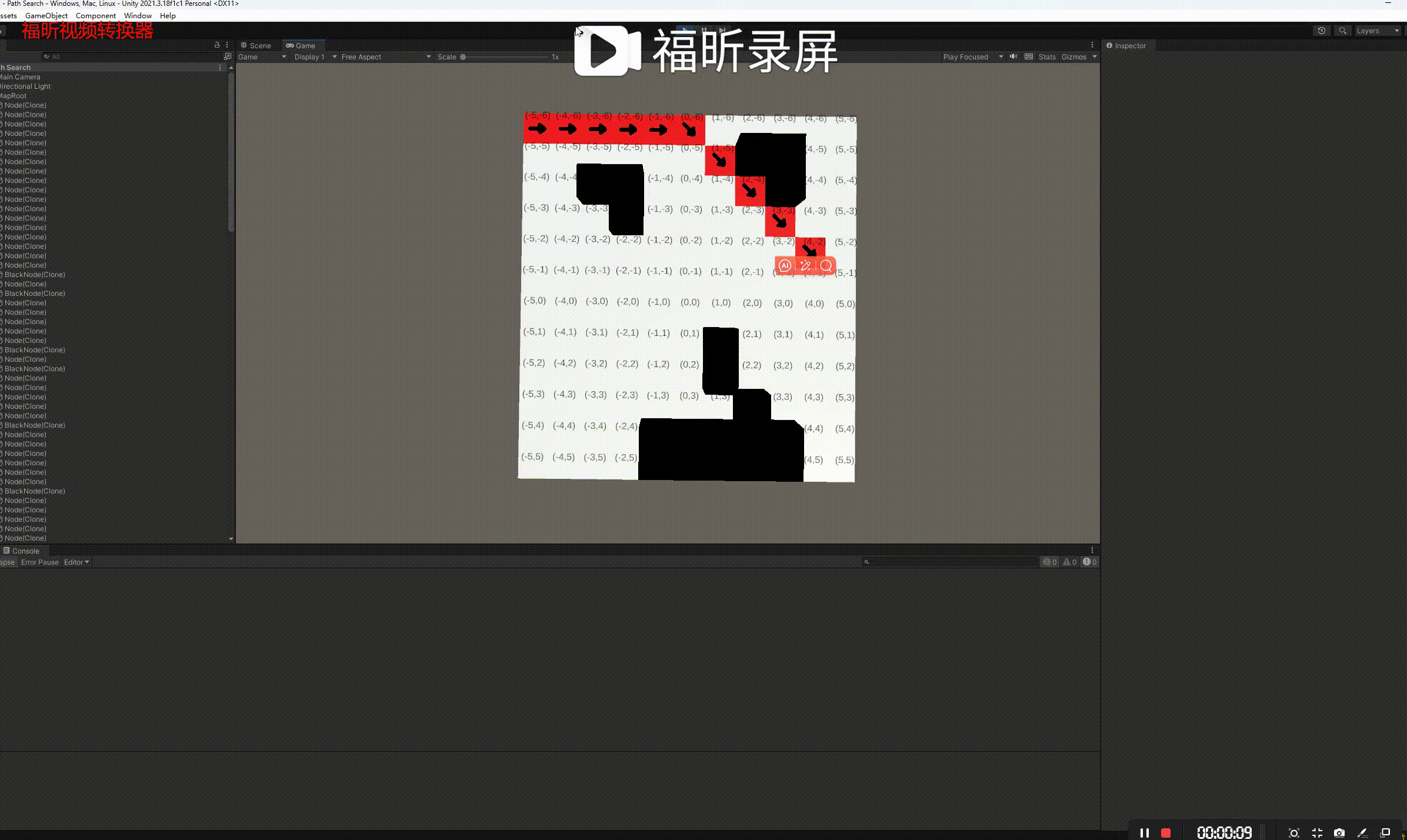
A*(A-star)是一种图遍历和寻路算法,由于其完整性、最优性和最佳效率,它被用于计算机科学的许多领域。给定一个加权图、一个源节点和一个目标节点,该算法将找到从源到目标的最短路径(相对于给定的权重&#…...

spring学习(spring的IoC思想、spring容器、spring配置文件、依赖注入(DI)、BeanProxy机制(AOP))
目录 一、spring-IoC。 (1)spring框架。(诞生原因及核心思想) 1、为什么叫框架? 2、spring框架诞生的技术背景。 (2)控制反转(IoC)。 (3)spring的Bean工厂和IoC容器。 &a…...

谁说C比C++快?
看到这个问题,我我得说:这事儿没有那么简单。 1. 先把最大的误区打破 "C永远比C快" —— 某位1990年代的程序员 这种说法就像"自行车永远比汽车省油"一样荒谬。我们来看个例子: // C风格 char* str (char*)malloc(100…...

GEE+本地XGboot分类
GEE本地XGboot分类 我想做提取耕地提取,想到了一篇董金玮老师的一篇论文,这个论文是先提取的耕地,再做作物分类,耕地的提取代码是开源的。 但这个代码直接在云端上进行分类,GEE会爆内存,因此我准备把数据下…...
计算两个二维点集之间的最佳仿射变换矩阵(2x3)函数estimateAffine2D()的使用)
OpenCV相机标定与3D重建(24)计算两个二维点集之间的最佳仿射变换矩阵(2x3)函数estimateAffine2D()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 计算两个二维点集之间的最优仿射变换,它计算 [ x y ] [ a 11 a 12 a 21 a 22 ] [ X Y ] [ b 1 b 2 ] \begin{bmatrix} x\\ y\\ \en…...

HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁
HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是专为《Honey Select 2》…...

Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题!
Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统越用越慢而烦恼吗&…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

ARM Neoverse-V3架构解析与性能优化实战
1. ARM Neoverse-V3架构概览作为Arm公司面向基础设施领域的最新处理器IP,Neoverse-V3代表了当前服务器级处理器的顶尖设计水平。我在实际芯片开发中多次接触该架构,其设计哲学可概括为:通过精细化微架构控制实现性能与能效的完美平衡。1.1 指…...
)
用STM32+LoRa+阿里云IoT Studio,我DIY了一个低成本畜牧电子围栏(附完整代码)
基于STM32与LoRa的智能畜牧围栏系统开发实战 在广袤的牧区,牲畜走失一直是困扰牧民的核心问题。传统物理围栏不仅成本高昂,在草原这类开放地形中实施难度也很大。本文将详细介绍如何利用STM32微控制器、LoRa远距离通信模块和阿里云IoT Studio平台&#x…...

Claude-Code-Board:构建AI编程工作台,提升开发效率与协作
1. 项目概述与核心价值最近在GitHub上看到一个名为“Claude-Code-Board”的项目,作者是cablate。这个项目标题直译过来就是“Claude代码板”,听起来像是一个与AI编程助手Claude相关的工具。作为一名长期在开发一线摸爬滚打的程序员,我对这类能…...

PromptCraft-Robotics:基于LLM的机器人任务规划与安全控制实践
1. 项目概述与核心价值最近在机器人编程和AI应用领域,一个名为“PromptCraft-Robotics”的项目在开发者社区里引起了不小的讨论。这个项目由微软开源,其核心目标直指一个困扰许多开发者和研究者的痛点:如何让大型语言模型(LLM&…...

Mod Engine 2完全指南:告别游戏模组安装烦恼的终极解决方案
Mod Engine 2完全指南:告别游戏模组安装烦恼的终极解决方案 【免费下载链接】ModEngine2 Runtime injection library for modding Souls games. WIP 项目地址: https://gitcode.com/gh_mirrors/mo/ModEngine2 还在为传统游戏模组安装的繁琐流程而烦恼吗&…...

RL78/G13单片机实现流水呼吸灯:软件PWM与状态机编程实践
1. 项目概述与核心思路最近在整理手头的瑞萨RL78/G13开发板,想着做点有意思的小项目来熟悉一下这款MCU的GPIO操作和定时器资源。呼吸灯和流水灯算是嵌入式开发的“Hello World”了,但把两者结合起来,做成一个“流水呼吸灯”,既有动…...

Spring Kafka监听多个Topic时,如何避免消费者‘摸鱼’?聊聊Range和RoundRobin分配策略的选择
Spring Kafka多Topic监听场景下消费者分配策略深度优化 1. 问题背景:当消费者开始"摸鱼" 在分布式消息系统中,Kafka凭借其高吞吐、低延迟的特性成为众多企业的首选。然而在实际开发中,不少团队遇到过这样的尴尬场景:明明…...