案例分享|企查查的数据降本增效之路
分享嘉宾
任何强
企查查科技股份有限公司
大数据架构负责人
关于企查查
“企查查”是企查查科技股份有限公司旗下的一款企业信用查询工具。2023年5月20日,企查查正式发布全球首款商查大模型——“知彼阿尔法”,该模型基于企查查覆盖的全球企业信用数据进行训练,相较于当前 AIGC(生成式人工智能)领域其它模型,“知彼阿尔法”大模型的亮点在于用垂直领域的海量数据进行训练,保证信息的精准度,基于“知彼阿尔法”大模型相关产品上线后可为司法、金融、风控、政务等人士提供多维度数据服务。
导读
在当今快速发展的数字化时代,数据已成为企业和组织最宝贵的资产之一。然而,随着数据量的激增,如何有效管理和利用这些数据,同时降低成本、提高效率,成为了一个重要议题。本次分享将围绕“数据的降本增效之路”这一主题,探讨数据管理与分析的最佳实践,以及如何通过技术创新实现数据的优化利用。
分享提纲
- 企查查数据架构;
- 混合“云”架构形成;
- 多云下的统一架构;
- 扩展内容。
企查查数据结构
首先分享的是企查查的数据架构
基础数据架构:Hadoop 的三驾马车

我们的大数据是从 Hadoop 的三驾马车(存储、计算和调度)一个很经典的数据架构开始的。Hadoop 大数据架构,是一个独立的生态。有了这个生态之后,我们要和现有的一些生态进行联合,所以进行了一些数据同步,包括原始数据、业务数据、日志数据等。
数据仓库架构

我们的数仓采用了常规的四层架构,包括 ODS 原始层、DWD 轻度解析层、DW 汇总层,以及最上面的应用层。最初是使用云服务进行数据查询,但是企查查所需数据与业界一般数据有所不同,不仅整体数据量大,单条数据有时也很大,可能达到几十兆,这导致云上跑一条 SQL 可能要花费几百块。所以我们自己搭建了线下的大数据,以实现 SQL 自由。
数据仓库架构升级

由上图中可以看到,升级后的架构与之前的结构相比,多了 Hive2、Kyuubi 和 Trino 这几个计算组件,这些组件能大幅提升计算效能,但也会带来一些问题。以 Hive2 为例,我已有一个 Hive,再搭建一个 Hive2 相当于两个独立的数据库了,那么在 Hive1 建的库和表该如何在 Hive2 上读取呢,反过来,在 Hive2 上建的表,又该如何在 Hive1 上读取?这是升级带来的困扰。
Hive 的升级姿势

Hive 的升级有两种方式。第一种是直接升级,风险很大,面临的问题是有可能无法回退,毕竟测试无法覆盖全部。还有一种方式,是摩托和跑车同时跑,即 Hive1 和 Hive2 同时存在,为了保证底层数据的统一,可以利用 MySQL 的一些双组机制互相同步。这种方式的好处是很稳定,升级后数据的准确性完全可控,但它带来了复杂性,从架构角度来说,不太能接受,因为多了一个 MySQL 及其 schema 元数据(我们 Hive 的元数据使用的是 MySQL,也可以是 PostgreSQL),还多了一套数据同步方式。经过进一步考虑,是否能够把这些整合到一起,有待进一步探索。
Hive1 与 Hive2 架构对比

基于这种想法,将 Hive1 的元数据 schema 架构与 Hive2 的 schema 元数据架构进行了对比。之后发现,Hive2 的 schema 元数据总体上比 Hive1 的元数据多了几张表,部分表也多了几个字段。如果得出这样的结果,我们是否可以采用如图右侧这样的架构呢?Hive1 和 Hive2 这两个计算组件使用的是同一个元数据,从而解决了上述问题。
统一元数据底层

SparkSQL 本身可以直接使用 Hive 的 catalog,相当于 Spark on Hive。然后再往下,Trino 实际上也可以使用 Hive 的 Catalog。我们现在使用的是 Kyuubi,可以简单理解为是 SparkSQL 的一个服务,底层实际上直接用的是 SparkSQL 的一个 catalog。所以到目前这个阶段,是基于多个计算引擎的架构,包括 Hive1、Hive2、Kyuubi 和 Trino,但元数据是统一实现的。
整体数据架构

即便使用不同的计算引擎,最终所需得到的表却是一致的。基于这样的架构逻辑,搭建了一套完整的数据架构。数据源层包括 FTP、RDS、ES、ODPS 和 Kafka 等技术。数据同步层,离线同步使用 Sqoop、Flink;实时同步方面则有 Kafka、Flume、Canal 和 CDC。再往上是计算存储层,目前使用了四个离线计算引擎,实时计算由 Flink 和 Spark 完成,实际上是 Spark Streaming。中间层湖仓一体是采用的 Iceberg,但是 Iceberg 存在一些问题,我们中间是用 amoro 来解决其元数据问题。然后是存储层。这样整体形成了一套标准数据架构。
混合“云”架构形成
下面分享混合云的形成。
离线集群与实时集群

以前的集群全部是一套的,带来的问题是离线和集群在一起,离线的资源使用方式是有多少用多少。一条 SQL 有可能把整个集群的资源全部用满。另外一个问题就是 Hadoop 的一些调优参数比较复杂,不同场景的调优参数是不一样的,如果不拆分开来就没办法把集群性能拉到最大,所以进行了拆分的架构设计。但是拆分面临的问题就是混合云,这两个云实际上都是我们的私有云。
实时数仓架构

实时流程较为简单,中间有实时数据存储,底层是计算资源,后面则是属于业务应用的实时数仓,采用的是 TiDB 和 MongoDB。在数据湖出现之前,大部分企业选择的是 HBase,但目前很少有企业使用这个。比较早期的时候选择了 TiDB 和 MongoDB 作为实时数仓。现在来看,很多数据湖也可以作为数仓,比如 Iceberg,所以采用这一套架构,走了两行架构,性能有所提升。
存储问题与元数据问题

接着面临的是存储问题,因为以前所有的集群实际上盘是插满的,我们的实时数仓又选择了 TiDB 和 MongoDB,实时集群上面的存储成了一个需要解决的问题。另外,如果部署到 Hive,又出现元数据如何统一的问题。
为了解决这个问题,我们只是想用实时集群的一个存储功能,所以把问题演变一下,只要把 HDFS 之间的一个集群互通就可以解决。因为 Hive 的存储本来就可以 locate 到不同的存储上面去。然而,Hadoop 集群分为安全集群和非安全集群。第一,如果两个集群都是非安全集群的话,不存在互通,本身都有 HDFS 的客户端,配置好 dfs.namenode 的识别,是可以随意访问另外一个 Hadoop 上面的数据的,像客户端命令 Hadoop fs 或者 Hive 直接 location 到另一个 Hadoop 地址是完全支持的。第二个是安全集群和非安全集群的打通,实际上安全集群也是可以直接访问非安全集群的,非安全集群是没办法访问安全集群的。

第三,Kerberos 之间即安全集群之间可不可以相互打通?这是可以的。本身官网有一些配置方式,在系统中是可以直接配置的,可以访问两个 Kerberos,且 Kerberos 是一致的。

除了 HDFS,很多公司还会采有对象存储。常用的对象存储有云对象 OBS、OSS、COS,还有开源对象存储 CEPH 和 MinIO。
Hadoop 集成对象

目前业界主流的做法一般是使用中间件,中间件有两个选择,一个选择是 Alluxio,可以做一个中间缓存层;另一个选择是 JuiceFS,这两个选择都可以实现同样的一些功能。

在 Alluxio 官网介绍的架构中,中间层是 Alluxio,底层是 S3、GC、Azure、HDFS、CEPH 等。从官网上可以看到,Alluxio 支持对接各种存储,上层可以提供各种协议,比如 HDFS interface、Java File API、POSIX interface 等。

JuiceFS 是一款高性能的分布式文件系统。JuiceFS 具有出色的扩展性和灵活性,能够轻松应对海量数据的存储和管理需求。它支持多种存储后端,例如对象存储服务,这使得用户可以根据自身的业务规模和成本要求进行灵活选择。举例来说,在大数据处理场景中,JuiceFS 可以高效地存储和访问大量的文件,提升数据处理的效率。在云计算环境下,JuiceFS 能与各种云服务无缝集成,为用户提供稳定可靠的数据存储解决方案。
跨集群下的元数据统一

基于刚刚介绍的这套流程。第一阶段实现的是一个 HDFS,上面有多个计算引擎,但元数据是统一的。在第二阶段我们实现了多个 HDFS,中间元数据仍然是统一的,因为利用第二套集群,实际上只用了它的存储,Hive 和元数据实际上还是一套。只不过利用 Hive 本身的 location 直接指向另外一套存储上面。所以第二集群已经实现了多个 HDFS,多个计算引擎的元数据统一。
多云下的统一架构
下面分享多云下的统一架构。

基于上面的一些架构,现在两只小象已经可以快乐的玩耍了。目前都已经是多套架构了,实际上把一套部署在 A 云上面,另外一套部署在 B 云上面,已经实现了多云下面的统一架构。一些安全要求高的数据放在私有云上面,一些日志数据或者不太重要的数据则放在公有云上面。但我们还发现另外一些问题,有些云上面的版本和公司本身的版本是不一样的。
版本兼容

不同版本间如何做到架构上的统一呢?Hadoop 不是一个组件,而是一个生态,它本身的服务有很多。第二个问题是版本之间的兼容,在 Hadoop 刚推出时,如果再部署一套 Hadoop 集群是非常复杂的,所以后面有了 Ambari、ClouderaManage 这种企业,一键直接部署,不用再考虑版本之间的兼容问题。第三个问题是跨版本下面的元数据该如何统一。还有第四个问题是涉及自研,在 Hive 上面做了一些改造,也需要考虑该如何处理。
中间件解决方案

中间件解决方案,首先要思考一个组件能不能支撑 Hadoop 不同版本的兼容。

通过调研发现 Alluxio 官网有很重要的一句话,序号 4.5.3 这一行写着 Alluxio 是支持 Hadoop 2.2-3.3 版本以及 1.0 和 1.2 版本。

其次,JuiceFS 也同时兼容 Hadoop 2.0-3.0 版本,以及 Hadoop 中的各种主流组件。
数据架构 V1

基于对中间件的调研和实践,最终我们形成了一套完整的架构,左边是一套集群,右边是另一套集群,两个集群可以是不同的版本。比如左边是 Hadoop2,右边是 Hadoop3,在上面加一层 Alluxio,或者 JuiceFS,这样 Hadoop2 接收到的请求,使用 Hadoop2 集群的算力,但是可以同时读 Hadoop2 和 Hadoop3 上的数据,而且可以互相读写。相反,使用 Hadoop3 的算力也是一样。这样做的好处就是有时候可以使用云上面的一些资源,利用云上的算力把云下的数据和云上的数据结合进行计算,同样也可以利用云下的算力把云下云上的数据结合计算。完美适配是针对安全级别较高的数据放在线下,如何利用云上算力的场景。
数据架构 V2

虽然上面的架构已经解决了问题,但是需要把所有的 HDFS 都架上一层中间件,所以我们又继续迭代出了 V2 版本,做了这样的改造。把 Alluxio 作为跨版本之间的一个中间过渡,但是它本身集群是没有的。如何实现跨集群,因为 Alluxio 写入的是原生文件,它的好处是通过 Haddop3,然后通过 Alluxio 写入的 Hadoop2 的数据。在 Hadoop2 上面直接读 Alluxio 的数据也是支持的。这种方式的耦合性较低,所以架构相对比较简单。另外,两个 Hadoop 集群跨版本兼容性问题,通过 Alluxio 就可以全部解决。而且这套架构不需要任何二次开发,直接基于开源实现,代价非常低。
实现成果

有了这套架构,实现了多云下的统一元数据,做到了统一存储,即底层可以是不同版本的一些存储,也可以是不同云上的存储,但上层是统一的。
另外,可以做到跨版本联邦,Hadoop 架构本身有两个 NameNode,它所有的计算都要用 NameNode 来进行交互,算力是在 DataNode 上的,但是数据量如果太多会被 NameNode 限制,所以有了联邦机制可以部署多套 NameNode,管理不同的 DataNode,但是它的限制是在同一个版本上面,所以基于这套架构,实现了跨版本的联邦。
基于该架构,还可以实现 Hadoop 的丝滑升级。以前的升级比较粗暴,就是高版本再部署一套。但这种方式需要对齐大量数据,导致大量繁琐复杂的工作,而且规模越大成本越高。但基于该架构可以将数据直接写入 Hadoop3 中,而算力可以采用更灵活的方式。
那么,基于以上架构会带来怎样的效果呢?因为 Hadoop3 拥有 EC 机制,而之前的 Hadoop2 是三副本。基于实测,Hadoop3EC 机制能实现 1.67 倍的存储,却能达到三副本的效果,这就是 EC 的能力。所以,走 Hadoop3 这条路,从理论上讲能够降低存储的成本,这是第一版的成本降低。第二版的成本降低就是可以大规模部署一套 DAS 存储集群,在硬件成本方面实现降低。底层也能够往上进行分配,然后对于数据上方基于数据的治理,比如热数据、温数据、冷数据如何存储,大家可以根据自身的业务来制定策略,并指定到不同的数据存储位置。同时,如刚才所讲,这套架构本身是多计算引擎的。如果有新的计算引擎,能否纳管进来?答案是可以的。因为多个版本在不断推进,比如在 Hadoop3 上,我们搭建了 Hive3,Hive3 上面还搭建了 Kyuubi。但元数据仍然是统一的一套。
扩展内容
统一引擎
前面讲到实现了统一存储,那么能否统一当前架构中的 Hive1、Hive2、SparkSQL 和 Kyuubi 等计算引擎呢?基于这一想法,我们做了相关调研,发现有两种方式。
第一种方式是选择其中一个计算引擎。因为现在有很多强大的引擎,选择一个就能够兼容其他计算引擎,例如 Kyuubi、Trino、StarRocks。
第二种方式是实现不同计算引擎之间的互相翻译,在上层设置一个智能引擎。所谓智能引擎,就是可以基于 SQL 的语法、成本,或者不同计算引擎的使用状态来选择不同的引擎。这方面已有相关方案,我们使用的是开源组件 Coral,它能够实现不同计算引擎的语法转换。进而扩展一下,既然已经能够实现不同引擎之间的语法转化,再根据每个集群目前的自行使用状态来选择不同的引擎就相对简单了。
我们之所以会采取这一举措,是因为业务的推动。业务方面认为,频繁上新引擎,对于他们而言是痛苦的,增加了学习成本。所以从去年上线智能引擎后,这个问题得到了解决。后续再扩展引擎对用户是无感知的,甚至可以做到灰度发布,比如让部分资深用户或者内部人员使用新的计算引擎,以观察真实效果。
统一集群
更进一步,思考历史的发展规律,读过《三国》的人都知道天下之事分久必合,合久必分。起初我们采用的是一套集群,之后因各种问题进行了拆分。而如今集群数量过多,那么我们是否能够将其整合呢?对于小工程而言,我们会有这样的想法。因为 K8S 在云原生方面相对出色,能够涵盖所有机器。而且 Hadoop 也注意到了这方面的诸多改变,内部的一些组件,例如 Spark 等各个组件,也都能够直接在 K8S 上运行。然而,若底层直接进行调度切换,会引发另一个问题,即众多任务是否需要进行改造?毕竟有时任务量庞大,这一过程较为痛苦。之后我们思考,既然 K8S 能够纳管机器,那能否将 Hadoop 纳管进来?目前,我们已将此应用于内部的一些测试,效果甚佳,即将整个 Yarn 直接安装至 K8S 上。实际上,底层完全统一为一套 K8S,上方存在各类集群,这块是基于 Koordinator 组件实现。
这样做的一个扩展的好处是解决超卖问题,这是业界的一个痛点,实时资源通常是预申请的资源。以 Flink 为例,若开始数据量大申请 20 核,后续增量变小,资源不会减少,不像 Hive。这是因为它会判断机器本身的资源使用情况。比如在 Core 上申请 20 核,而实际只使用物理机的 10 核,Koordinator 组件能将剩余的 10 核重新分配给可用的 Core 的 Hadoop,增加可用的 Core。现阶段,我们已将 Hadooop3 整个集群放置于此,冷数据也已全部放上,目前取得的效果是实时资源有显著提升,约在 50% 以上。
总结
最后总结一下,架构上我们要大胆创新,实践上面我们谨慎落地。就像企查查一样,模式上我们大胆的创新,但数据上我们小心谨慎。另外架构上常说的是没有最好的架构,只有最适合架构,“生命不息,迭代不止”。
以上就是本次分享的内容,谢谢大家。
相关文章:
案例分享|企查查的数据降本增效之路
分享嘉宾 任何强 企查查科技股份有限公司 大数据架构负责人 关于企查查 “企查查”是企查查科技股份有限公司旗下的一款企业信用查询工具。2023年5月20日,企查查正式发布全球首款商查大模型——“知彼阿尔法”,该模型基于企查查覆盖的全球企业信用数据进…...

图书馆管理系统(四)基于jquery、ajax--完结篇
任务3.6 后端代码编写 任务描述 这个部分主要想实现图书馆管理系统的后端,使用 Express 框架来处理 HTTP 请求,并将书籍数据存储在一个文本文件 books.txt 中。 任务实施 3.6.1 引入模块及创建 Express 应用 const express require(express); cons…...

什么是Modbus协议网关?
在工业自动化领域,设备间的通信与数据交换是实现高效、智能控制的关键。Modbus协议作为一种广泛应用的通信协议,自1971年由Modicon公司首次推出以来,便以其标准、开放、支持多种电气接口等特点,在工业控制系统中占据了重要地位。然…...

Docker 容器中启用 SSH 服务
在 Docker 容器中运行 SSH 服务需要一些调整,因为 Docker 容器通常使用 init 系统而不是完整的 systemd。以下是配置 SSH 服务在 Docker Ubuntu 容器中运行的步骤: 1. 安装 SSH 服务 如果还未安装 OpenSSH,请先安装: apt update…...

Linux系统—利用systemd管控系统以及服务详解(十四)
本文为Ubuntu Linux操作系统- 第十四弹~~ 新的一周开始了,时间过得真快,这星期就要冬至啦!! 今天继续Linux系统高级管理板块,主要讲述使用systemd管控系统和服务~ 上期回顾:“Linux系统—进程管理详解” 更…...

人工智能 AI 大模型研究设计与实践应用技术毕业论文
标题:人工智能 AI 大模型研究设计与实践应用技术 内容:1.摘要 人工智能 AI 大模型是当前人工智能领域的研究热点之一,它具有高度的通用性、灵活性和智能性,可以应用于多种领域,如自然语言处理、计算机视觉、语音识别等。本文旨在探讨人工智能…...

已有 containerd 的情况下部署二进制 docker 共存
文章目录 [toc]学习目的开始学习dockerd启动 containerd准备配置文件启动 containerd 启动 docker准备配置文件启动 docker 环境验证停止 docker 和 containerd 学习目的 使用容器的方式做一些部署的交付,相对方便很多,不需要担心别人的环境缺少需要的依…...

VSCode 搭建Python编程环境 2024新版图文安装教程(Python环境搭建+VSCode安装+运行测试+背景图设置)
名人说:一点浩然气,千里快哉风。—— 苏轼《水调歌头》 创作者:Code_流苏(CSDN) 目录 一、Python环境安装二、VScode下载及安装三、VSCode配置Python环境四、运行测试五、背景图设置 很高兴你打开了这篇博客,更多详细的安装教程&…...

vue+springboot+cas配置及cookie传递问题
cookie的注意事项 前边的文章已经介绍过cookie的基本信息,这里再次说明一点:cookie是无法进行跨域传递的,很多时候cookie无法设置和传递都是因为跨域问题,ip/端口不一致。 主要就是:被设置cookie和要传递cookie的地址…...
0009.基于springboot+layui的ERP企业进销存管理系统
一、系统说明 基于springbootlayui的ERP企业进销存管理系统,系统功能齐全, 代码简洁易懂,适合小白学编程,课程设计,毕业设计。 二、系统架构 前端:html| layui 后端:springboot | mybatis| thymeleaf 环境:jdk1.8 |…...
ZYNQ初识2(zynq_7010)基于vivado,从PL端调用PS端的时钟
由于需要进行一些FPGA的简单开发,但板载PL端没有焊接晶振,所以需要从PS端借用时钟到PL端使用。 首先新建项目,根据自己的板载选择芯片,我的板载芯片是zynq_7010。 一路next,在自己的vivado的工作文档新建文件夹并给自…...

Android详解——ConstraintLayout约束布局
目录 一、ConstraintLayout概述 二、ConstraintLayout属性介绍 1. 相对位置 2. 边距 3. 中心和偏移位置 中心位置 偏移位置 4. 圆形位置 5. 可见性 6. 尺寸约束 最小尺寸 WRAP_CONTENT :强制约束 MATCH_CONSTRAINT Min和Max 百分比尺寸 比率 7. 链式布局 创建…...

docker简单命令
docker images 查看镜像文件 docker ps -a 查看容器文件 docker rm 0b2 删除容器文件,id取前三位即可 docker rmi e64 删除镜像文件(先删容器才能删镜像),id取前三位即可 在包含Dockerfile文件的目录…...
-文件操作)
【linux】shell(36)-文件操作
1. 文件创建 1.1 使用 touch 命令创建空文件 touch filename创建一个名为 filename 的空文件。如果文件已存在,touch 会更新该文件的时间戳。 示例: touch file1.txt1.2 使用重定向符创建文件 > filename使用 > 符号创建一个空文件。如果文件…...
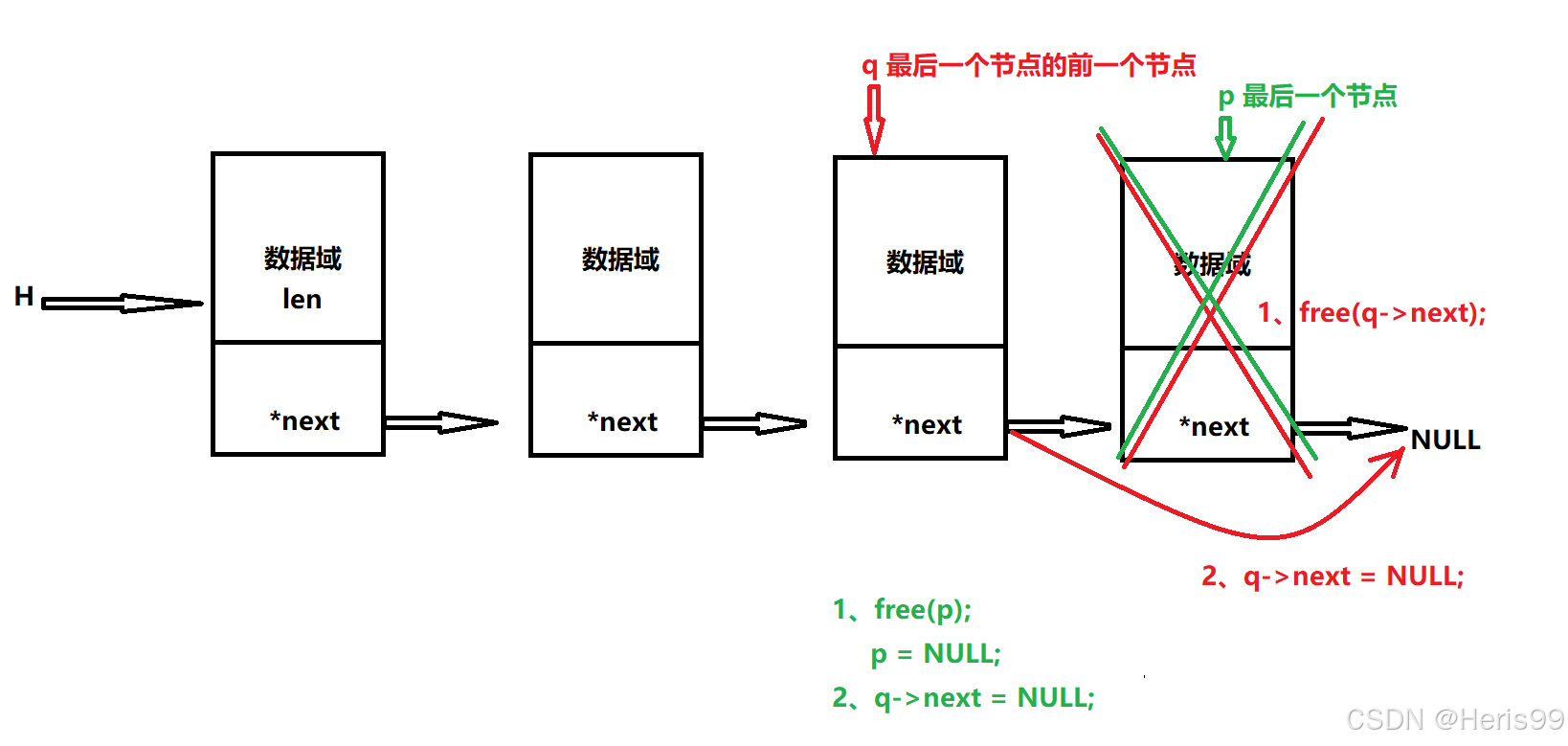
c语言——数据结构【链表:单向链表】
上篇→快速掌握C语言——数据结构【创建顺序表】多文件编译-CSDN博客 一、链表 二、单向链表 2.1 概念 2.2 单向链表的组成 2.3 单向链表节点的结构体原型 //类型重定义,表示存放的数据类型 typedef int DataType;//定义节点的结构体类型 typedef struct node {union{int l…...

Python 标识符是啥?
Python 的标识符就是我们写代码时用来给变量、函数、类等取名字的东西。 你写的 my_variable 是个标识符, 定义的 add_numbers 函数名也是个标识符, 甚至你写的 Cat 类名,也是标识符。 一句话总结:标识符就是代码里给“东西”起…...

视频及JSON数据的导出并压缩
npm下载安装 jszip 和 file-saver 这两个库来实现文件的压缩和保存功能: npm install jszip npm install file-saver 导入依赖库: import JSZip from jszip; import { saveAs } from file-saver; 方法实现: batchDownload() {const zip…...
VScode使用教程(菜鸟版)
目录 1.VScode是什么? 2.VScode的下载和安装? 2.1下载和安装 下载路径: 安装流程: 一、点击【Download for Windows】 二、等一小会儿的下载,找到并双击你下载好的.exe文件,开始进入安装进程 三、点…...
)
【漏洞复现】Grafana 安全漏洞(CVE-2024-9264)
🏘️个人主页: 点燃银河尽头的篝火(●’◡’●) 如果文章有帮到你的话记得点赞👍+收藏💗支持一下哦 一、漏洞概述 1.1漏洞简介 漏洞名称:Grafana 安全漏洞 (CVE-2024-9264)漏洞编号:CVE-2024-9264 | CNNVD-202410-1891漏洞类型:命令注入、本地文件包含漏洞威胁等级:…...

Android AOSP 源码中批量替换“phone“为“tablet“的命令详解
我来帮你写一篇关于这条命令的分析博客。 Android 项目中批量替换"phone"为"tablet"的命令详解 前言 在 Android 开发中,有时我们需要批量修改资源文件中的某些文本内容。今天我们来分析一条结合了 grep 和 sed 的强大命令,该命令用于将项目中的 “ph…...

免费跨平台绘图神器:draw.io桌面版终极使用指南
免费跨平台绘图神器:draw.io桌面版终极使用指南 【免费下载链接】drawio-desktop Official electron build of draw.io 项目地址: https://gitcode.com/GitHub_Trending/dr/drawio-desktop 还在为不同系统间的图表文件兼容性而烦恼吗?ᾑ…...

告别风扇噪音烦恼!Fan Control:Windows上最智能的免费风扇控制软件完全指南
告别风扇噪音烦恼!Fan Control:Windows上最智能的免费风扇控制软件完全指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https:/…...

告别Keil!用STM32CubeIDE给STM32F103C8T6做双路ADC采样,DMA+中断实战避坑
从Keil到STM32CubeIDE:双路ADC采样与DMA中断实战全解析 当传统嵌入式开发遇上现代化工具链,迁移过程中的技术决策往往比想象中更复杂。对于长期使用Keil MDK的开发者而言,转向STM32CubeIDE不仅意味着开发环境的改变,更涉及从寄存器…...
)
Midjourney V6树胶重铬酸盐输出崩溃?紧急修复指南(含--sref自定义光敏响应曲线参数实测数据)
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6树胶重铬酸盐输出崩溃现象与本质溯源 现象复现与触发条件 Midjourney V6 在启用 --style raw 且 prompt 中包含化学术语(如“重铬酸盐”、“树胶”、“potassium dichromate”…...

终极指南:使用Tinke轻松探索和修改NDS游戏资源
终极指南:使用Tinke轻松探索和修改NDS游戏资源 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾经好奇任天堂DS游戏内部是如何组织的?想要提取游戏中的精美图片、动…...

数据中心网络卡顿?可能是你的链路聚合负载均衡没配对!详解华为交换机src-dst-ip哈希算法
数据中心网络卡顿?华为交换机src-dst-ip哈希算法深度调优指南 在数据中心网络运维中,链路聚合(Link Aggregation)技术早已成为提升带宽和可靠性的标配方案。但许多工程师在完成基础配置后,常常遇到一个令人头疼的现象&…...

Windows热键冲突终极排查指南:5分钟快速定位占用进程
Windows热键冲突终极排查指南:5分钟快速定位占用进程 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经…...

ComfyUI-Manager插件不显示问题终极指南:从原理到实战的完整解决方案
ComfyUI-Manager插件不显示问题终极指南:从原理到实战的完整解决方案 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable…...

C语言字符串处理算法:反转、回文检测等实用技巧终极指南
C语言字符串处理算法:反转、回文检测等实用技巧终极指南 【免费下载链接】c Implementation of All ▲lgorithms in C Programming Language 项目地址: https://gitcode.com/gh_mirrors/c3/c 你是否在寻找C语言字符串处理的高效方法?🤔…...

AI智能体协作命令行工具squads-cli:多智能体编排与自动化实战
1. 项目概述:一个面向AI智能体协作的命令行工具如果你最近在关注AI智能体(Agent)的开发,尤其是多智能体协作(Multi-Agent Collaboration)这个方向,那你很可能已经听说过或接触过一些相关的框架。…...