241207_MindNLP中的大模型微调
241207_基于MindNLP的大模型高效微调
现在的大模型体量非常庞大,全量微调所需要的算力也特别庞大,个人开发者没有条件微调。参数量达到7B的模型才刚刚有涌现能力,但是我们要微调7B的模型的话,就需要3×28G的显存,至少需要2张A100的卡,更何况我们连一张也没有。
近年来研究者提出了各种各样的参数高效微调方法,即固定住预训练模型的大部分参数,仅调整模型的一小部分参数实现微调。
为什么使用高效微调
大模型在下游任务泛化性不够好
高效参数微调相比全量微调训练参数更少
高效参数微调忘得少,相比全量微调不容易过拟合
更适合online training
Additive PEFT(加性微调):在模型的特定位置添加可学习的模块或参数。
Selective PEFT(选择性微调):在微调过程中只更新模型中的一部分参数,而保持其余参数固定。
Reparameterization PEFT(重参数化微调):通过构建原始模型参数的低秩表示,在训练中增加可学习参数,以实现参数高效微调。

Additive PEFT
Prompt Tuning
Prompt Tuning的本质是往模型添加一些额外的信息,使得模型在生成预测值y的时候能获得一些条件(提示),一般是在我们的输入层面解决的,Prompt Tuning并不改变模型参数,相当于就是一个提示文本。
比如:
输入:这部电影真是太好看了
我们单纯给这样的输入模型并不知道我们要干啥,此时我们就要拼接一个提示的prompt
提示:我感觉很
这个时候模型才知道他的任务可能是续写或者情绪分类,这样他才会预测“很”字后面的情绪。
在这个过程中,模型的所有参数都是冻结的,只有embedding得到了学习。
Prefix Tuning
传统的微调是利用预训练模型针对不同的下游任务进行微调,微调完成之后每个下游任务都要去保存一份模型权重,此时修改整个模型的权重,训练耗时长,同时整个模型的权重保存下来所占据的存储空间也大。
Prefix Tuning是为大模型添加可训练任务的特定前缀,他不是训练整个模型,只是训练一个前缀,就解决了训练耗时以及存储空间的问题。

针对不同的模型结构需要构造不同的Prefix。prefix需要加在每一个transformer结构前面。
在仅有解码器的GPT中(decoder-only),prefix只加在句首,模型的输入表示为:
z = [ P R E F I X ; x ; y ] z=[PREFIX;x;y] z=[PREFIX;x;y]
在编解码器的结构中(encoder-decoder),编码器和解码器前面都需要添加prefix

在MindSpore NLP里面的实现步骤:
1.为防止直接更新Prefix参数导致训练不稳定,在Prefix层前面加上MLP结果,训练完成只保留Prefix参数。
2.得到past_key_values
3.在每一层的transformer block的key value前面,拼接past_key_value

Selective PEFT
BitFit
BitFit在微调的时候仅仅调整预训练模型的bias项,训练时冻结除bias外的所有参数,只更新bias参数。
在mindnlp中的实现:
# creating modelmodel = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)all_param = sum(param.numel() for param in model.parameters())trainable_params = 0
for name, param in model.named_parameters():if "bias" not in name:param.requires_grad = False else:print(name)trainable_params += param.numel() print(f"trainable params: {trainable_params:,d} || all params: {all_param:,d} || trainable%: {100 * trainable_params / all_param}")

Reparameterization PEFT
LoRA

LoRA同样不修改PLM(Pretrained Language Model),是在预训练的权重旁边搭建一个旁路,添加可训练的参数,具体是搭建两个低秩矩阵,相乘后做生维,在和原来的预训练模型的权重相叠加
假设模型有一个具有 1,000 行和 2,000 列的矩阵。这就是要在模型文件中存储的 2,000,000 个数字(1,000 x 2,000)。LoRA 将该矩阵分解为一个 1,000x2 的矩阵和一个 2x2,000 的矩阵。这只需要 6,000 个数字(1,000 x 2 + 2 x 2,000),是原始矩阵大小的 333 倍。这就是 LoRA 参数数量小的原因。
针对transformer的mutil-head attention中的一些矩阵做调整。比如mutil-head attention中的Q,K做了旁路调整。

使用LoRA时会对主干模型做int8甚至int4的量化,使得主干模型的前向传播和反向传播耗时减少。
多卡训练(数据并行)时,卡间通信只需要同步LoRA模型部分的梯度,大大减小通信的压力,也会使总训练速度变快。
秩的选取,对于一般的任务,rank=1,2,4,8就够了,对于领域差距比较大的任务,需要更大的rank。
因为旁路的两个矩阵计算完成后会和主干的权重做叠加,所以不会增加推理成本
在MindNLP中的步骤:
(1)初始化低秩矩阵
(2)计算原始矩阵结果
(3)计算低秩矩阵结果
(4)汇总得到LoRA的结果

在MindNLP中的使用:
# creating model
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()

( I A ) 3 (IA)^3 (IA)3
IA3是给每个激活层学习一个系数向量,训练和推断时,激活单元与向量中对应的分量相乘,参数量更少。
就是通过点乘一个向量的形式对模型的一部分参数进行加权。

和其他PEFT的使用方法差不多,使用步骤如下:
实例化基本模型。
创建一个配置 (IA3Config),在其中定义 IA3 特定的参数。
使用 get_peft_model() 包装基础模型以获得可训练的 PeftModel。
像平常训练基础模型一样训练 PeftModel。
在MindNLP中的实现:
# creating model
peft_config = IA3Config(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
IA3实战
本次实验环境
mindspore=2.3.0,mindnlp=0.4.1,python=3.9.10,cann=8.0
首先我们来捋一下MRPC和GLUE的关系。
GLUE是一个多任务的自然语言理解基准和分析平台,他有九大任务,其中有一个任务就是MRPC(语义相似任务),他即可以说是一个任务,又可以说是数据集。
接下来我们要使用IA3对Roberta-Large模型进行微调训练
使用roberta-large模型,数据集使用mrpc
MRPC数据集是一个用于文本相似分析的数据集,用于自动识别两个句子是否表达相同的意思
我们加载该数据集并进行可视化。
from mindnlp.dataset import load_dataset
task="mrpc"
datasets=load_dataset("glue",task)
datasets

这里我们就可以发现,每组数据中有两个英文句子,label意思是是否相似,idx是索引
既然我们要使用IA3微调,那就先把IA3加载进来(配置一个用于序列分类任务的IA3模型),任务类型选的SEQ_CLS是序列分类任务。
from mindnlp.peft import get_peft_model,PeftType,IA3Config
peft_config = IA3Config(task_type="SEQ_CLS", inference_mode=False)
lr = 1e-3
然后配置我们一些参数
batch_size=32 # 批次数
model_name="roberta-large" # 模型
task="mrpc" # 任务类型
peft_type=PeftType.IA3 # 微调类型
num_epochs=20 # 训练epoch
不同的预训练模型在处理输入时要求不同,例如GPT、OPT、Bloom等模型通常是基于自回归架构,需要在左侧填充,以便在生成过程中保持上下文一致。其他模型如 RoBERTa、BERT 等通常是基于双向编码器,通常需要右侧填充(right),以确保上下文信息的对称性。
if any(k in model_name for k in ("gpt", "opt", "bloom")):padding_side = "left"
else:padding_side = "right"
然后我们再定义一个分词器并进行检查
from mindnlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None:tokenizer.pad_token_id = tokenizer.eos_token_id
为了适配mindnlp输入,我们需要做一些转换。
from mindnlp.dataset import BaseMapFunctionclass MapFunc(BaseMapFunction):"""自定义映射函数类,继承自BaseMapFunction。该类用于处理数据集中的每一项,将文本句子转换为模型所需的输入格式。调用时,它会使用传入的tokenizer对两个句子进行编码,并保持标签不变。参数:sentence1 -- 第一个输入句子sentence2 -- 第二个输入句子label -- 句子对的标签idx -- 数据项的索引返回:input_ids -- 编码后的输入ID序列attention_mask -- 注意力掩码序列label -- 原始标签"""def __call__(self, sentence1, sentence2, label, idx):# 使用tokenizer对句子对进行编码,启用truncation以确保不超过最大长度outputs = tokenizer(sentence1, sentence2, truncation=True, max_length=None)# 返回编码后的input_ids和attention_mask,以及原始标签return outputs['input_ids'], outputs['attention_mask'], labeldef get_dataset(dataset, tokenizer):"""获取经过处理的数据集。该函数将输入的数据集与tokenizer作为参数,使用MapFunc处理每个数据项,然后将处理后的数据项批处理,并对不足批次大小的数据进行填充。参数:dataset -- 输入的数据集tokenizer -- 用于编码文本的tokenizer返回:dataset -- 经过映射和批处理的数据集"""# 定义输入和输出列名input_colums=['sentence1', 'sentence2', 'label', 'idx']output_columns=['input_ids', 'attention_mask', 'labels']# 使用MapFunc处理数据集的每一项dataset = dataset.map(MapFunc(input_colums, output_columns),input_colums, output_columns)# 对处理后的数据集进行批处理和填充dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),'attention_mask': (None, 0)})# 返回处理后的数据集return dataset# 使用训练数据集和tokenizer获取经过处理的训练数据集
train_dataset = get_dataset(datasets['train'], tokenizer)
# 使用验证数据集和tokenizer获取经过处理的验证数据集
eval_dataset = get_dataset(datasets['validation'], tokenizer)从 evaluate 库中加载指定任务的 GLUE评估指标
metric = evaluate.load("glue", task)
然后加载预训练的序列分类模型,并把我们刚才配置的ia3模型应用到模型上,使其支持参数高效微调。
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
然后我们就可以打印可以训练的参数数量
model.print_trainable_parameters()
这里可以看到ia3微调的参数量非常小,只占总参数量的0.3%

然后定义我们的优化器、学习率调度器
optimizer = AdamW(params=model.parameters(), lr=lr)# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0.06 * (len(train_dataset) * num_epochs),num_training_steps=(len(train_dataset) * num_epochs),
)
开始前向训练
from mindnlp.core import value_and_grad
def forward_fn(**batch):outputs = model(**batch)loss = outputs.lossreturn lossgrad_fn = value_and_grad(forward_fn, tuple(model.parameters()))for epoch in range(num_epochs):model.set_train()train_total_size = train_dataset.get_dataset_size()for step, batch in enumerate(tqdm(train_dataset.create_dict_iterator(), total=train_total_size)):optimizer.zero_grad()loss = grad_fn(**batch)optimizer.step()lr_scheduler.step()model.set_train(False)eval_total_size = eval_dataset.get_dataset_size()for step, batch in enumerate(tqdm(eval_dataset.create_dict_iterator(), total=eval_total_size)):outputs = model(**batch)predictions = outputs.logits.argmax(axis=-1)predictions, references = predictions, batch["labels"]metric.add_batch(predictions=predictions,references=references,)eval_metric = metric.compute()print(f"epoch {epoch}:", eval_metric)
如果有没有导入的包,直接用以下代码
import mindspore
from tqdm import tqdm
from mindnlp import evaluate
from mindnlp.dataset import load_dataset
from mindnlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
from mindnlp.core.optim import AdamW
from mindnlp.common.optimization import get_linear_schedule_with_warmup
from mindnlp.peft import (get_peft_model,PeftType,IA3Config,
)
相关文章:
241207_MindNLP中的大模型微调
241207_基于MindNLP的大模型高效微调 现在的大模型体量非常庞大,全量微调所需要的算力也特别庞大,个人开发者没有条件微调。参数量达到7B的模型才刚刚有涌现能力,但是我们要微调7B的模型的话,就需要328G的显存,至少需…...

MongoDB、Mongoose使用教程
文章目录 一:MongoDB 简介1.1 什么是 MongoDB1.2 特点1.3 与关系数据库的区别:1.4 资源链接: 二:安装 MongoDB2.1 安装前的准备2.2 安装、启动 MongoDB2.3 创建用户 MongoDB 三、连接四:MongoDB 基础操作4.1 库操作&am…...
)
单片机:实现控制步进电机正反转(附带源码)
1. 步进电机概述 步进电机(Step Motor)是一种能够将电能转换为机械能的电动机。其独特之处在于能够精确地控制转动角度,因此被广泛应用于需要精确控制的场合,如打印机、机器人、数控机床、自动化设备等。 步进电机的转动是以“步…...

安装指南|OpenCSG Starship上架GitHub Marketplace
在代码开发的日常中,你是否常常被以下问题困扰? 代码审查耗时太长,拖慢项目进度? 审查质量参差不齐,一些关键问题被遗漏? 复杂代码变更看不懂,审查者需要大量时间理解意图? 别担…...
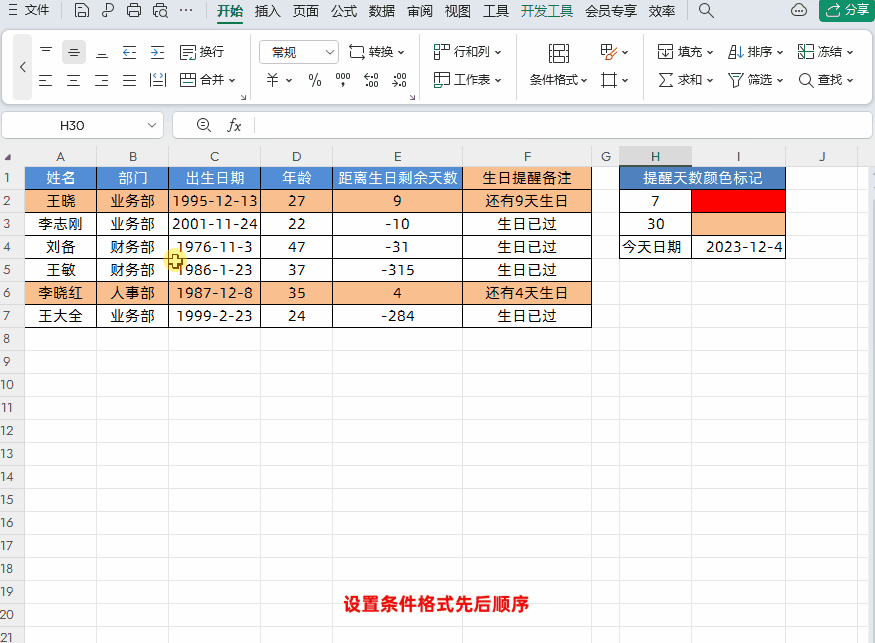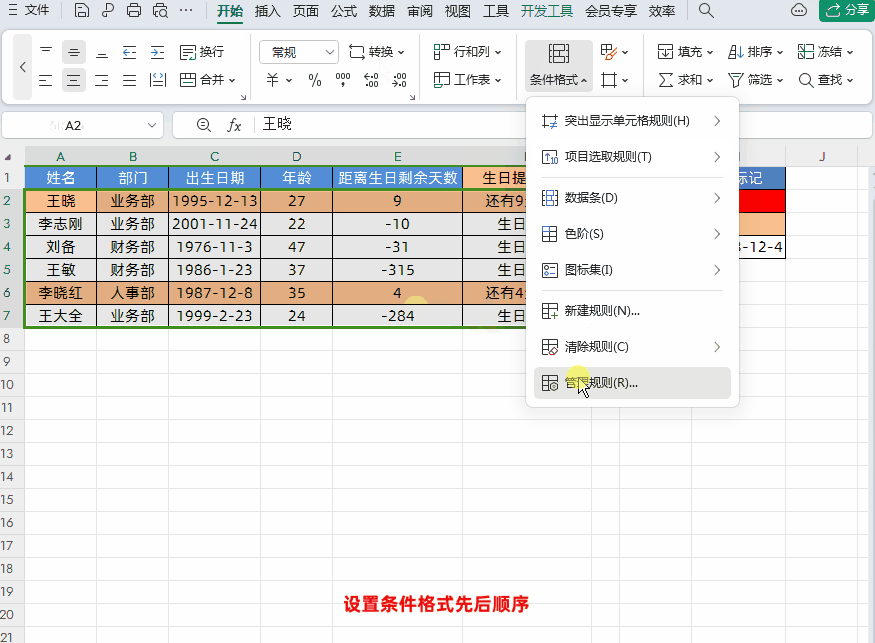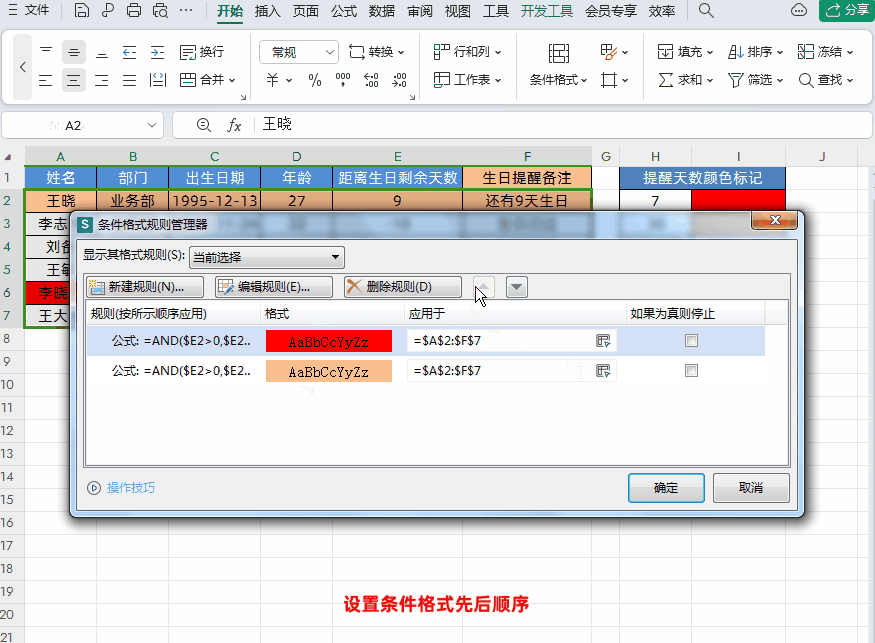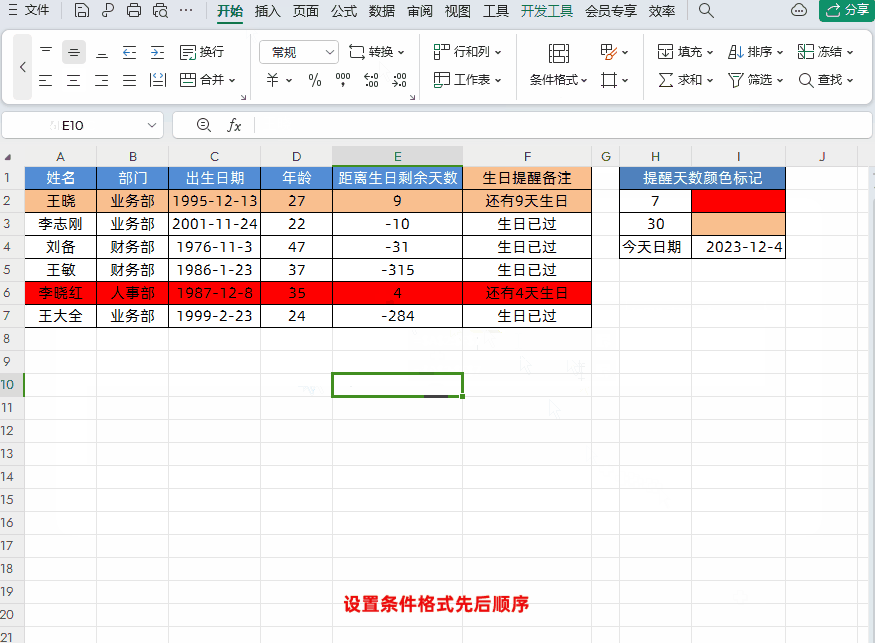
Excel设置生日自动智能提醒,公式可直接套用!
大家好,我是小鱼。 今天跟大家分享一个WPS表格中根据出生日期,设置生日提醒,并且根据距离生日天数自动标记数据颜色。简单又实用,一个公式轻松搞定! 接下来我们先学习一下需要使用到的函数,然后再根据实例让…...

同步异步日志系统:前置知识
一、日志项目的介绍 1.1 为什么要有日志系统 1、⽣产环境的产品为了保证其稳定性及安全性是不允许开发⼈员附加调试器去排查问题,可以借助日志系统来打印⼀些⽇志帮助开发⼈员解决问题 为什么不直接printf打印在屏幕上呢??因为现实中没有…...

微服务设计原则——功能设计
文章目录 1.ID生成2.数值精度3.DB操作4.性能测试5.版本兼容5.1 向旧兼容5.2 向新兼容 6.异步时序问题7.并发问题7.1 并发时序7.2 并发数据竞争 参考文献 1.ID生成 在分布式系统中,生成全局唯一ID是非常重要的需求,因为需要确保不同节点、服务或实例在并…...

低代码软件搭建自学的第一天——熟悉PyQt
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 学习计划第 1 步:环境搭建1.1 安装 Python1.2 安装 PyQt安装命令:验证安装: 第 2 步:PyQt 基础知识2.1 创建第一个窗…...

基于Python3编写的Golang程序多平台交叉编译自动化脚本
import argparse import os import shutil import sys from shutil import copy2from loguru import loggerclass GoBuild:"""一个用于构建跨平台执行文件的类。初始化函数,设置构建的主文件、生成的执行文件名称以及目标平台。:param f: 需要构建的…...

远程桌面连接
电脑A:使用机 电脑B:被控制的另一个 方法1: 在电脑B上操作 ①winr输入cmd进入命令行窗口,输入ipconfig查询本机地址 ②我的电脑/此电脑 右键点击“属性” ③选择屏幕右边“远程桌面” ④打开“启用远程桌面” ⑤打开设置&am…...

网络地址转换NAT
NAT(Network Address Translation) 方法于1994年提出。需要在专用网连接到因特网的路由器上安装NAT软件。装有NAT软件的路由器叫做NAT路由器,它至少有一个有效的外部全球地址IPG。 所有使用本地地址的主机在和外界通信时都要在NAT路由器上将其本地地址转换成外部全球…...

什么是CRM管理软件?CRM的基本概念、功能、选择标准、应用场景
什么是CRM管理软件? 嘿,大家好!今天咱们聊聊一个在现代企业管理中非常重要的工具——CRM管理软件。CRM是Customer Relationship Management(客户关系管理)的缩写,简单来说,它就是一个帮助企业和…...

Python编程常用的19个经典案例
Python 的简洁和强大使其成为许多开发者的首选语言。本文将介绍36个常用的Python经典代码案例。这些示例覆盖了基础语法、常见任务、以及一些高级功能。 1. 列表推导式 fizz_buzz_list ["FizzBuzz" if i % 15 0 else "Fizz" if i % 3 0 else "Buzz…...

【Unity基础】AudioSource 常用方法总结
在 Unity 中,AudioSource 组件用于控制音频的播放和管理。以下是常用的 AudioSource 控制方法及其说明。 1. 播放和暂停音频 Play():开始播放音频,如果是从暂停的地方继续播放,可以直接调用。Pause():暂停当前播放的…...
-- 滚动优化详解)
CSS系列(25)-- 滚动优化详解
前端技术探索系列:CSS 滚动优化详解 📜 致读者:探索流畅滚动的艺术 👋 前端开发者们, 今天我们将深入探讨 CSS 滚动优化,学习如何创建流畅、高性能的滚动体验。 平滑滚动 🚀 基础设置 /* …...

CST天线设计的六大核心特点:为天线分析提供完整解决方案!
CST Studio Suite 为天线设计提供了从最初的概念评估到最终的合规性测试所需的所有功能,确保天线设计在各种环境下实现稳定通信。这一套工具覆盖了所有重要的设计阶段,帮助设计师顺利完成从概念到成品的全过程。 下面我们来看一看CST电磁仿真中天线设计…...

Ubuntu下C语言操作kafka示例
目录 安装kafka: 安装librdkafka consumer Producer 测试运行 安装kafka: Ubuntu下Kafka安装及使用_ubuntu安装kafka-CSDN博客 安装librdkafka github地址:GitHub - confluentinc/librdkafka: The Apache Kafka C/C library $ apt in…...
怎么将pdf中的某一个提取出来?介绍几种提取PDF中页面的方法
怎么将pdf中的某一个提取出来?传统上,我们可能通过手动截取屏幕或使用PDF阅读器的复制功能来提取信息,但这种方法往往不够精确,且无法保留原文档的排版和格式。此外,很多时候我们需要提取的内容可能涉及多个页面、多个…...

HTTP接口报错详解与解决 200,500,403,408,404
前言: 仅做学习记录,侵删 背景 当后端编写接口时,经常需要对接口使用ApiFox或者PostMan进行测试,此时就会出现各种各样的报错,一般都会包括报错编码:200,400,401等。这个状态码一般是服务器所返回的包含…...

监控IP频繁登录服务器脚本
该脚本的作用是监控IP登录失败次数,如果某个IP的登录失败次数超过设定的最大次数,则阻止该IP的进一步登录尝试。通过iptables防火墙阻止连接,当一个IP尝试登录次数超过5次时,iptables会阻止来自该IP的所有连接 #!/bin/bashfuncti…...

大语言模型智能体长期记忆解决方案:LightMem架构解析与LangChain实战
1. 项目概述:轻量化记忆增强的智能体新范式最近在探索大语言模型智能体应用时,一个核心痛点始终绕不开:如何让智能体在长对话或多轮任务中,记住关键信息,并做出连贯、精准的决策?传统的做法要么是将整个对话…...

水凝膜、钢化膜、护景贴大对决:一张表看懂该买谁
水凝膜、钢化膜、护景贴大对决:一张表看懂该买谁手机屏幕保护膜主要有三种:水凝膜、普通钢化膜和护景贴(悟赫德为代表)。很多人不知道它们到底有什么区别,我们从六个维度给你讲清楚。材料结构。水凝膜是单层软塑料&…...
)
考古现场数据智能治理新范式(NotebookLM+地层学语义建模深度解析)
更多请点击: https://intelliparadigm.com 第一章:考古现场数据智能治理新范式(NotebookLM地层学语义建模深度解析) 在田野考古数字化进程中,传统地层记录存在碎片化、非结构化与语义断层三大瓶颈。NotebookLM 作为基…...

Vercel反向代理实战:基于Serverless Functions构建安全API网关
1. 项目概述:一个反向代理的轻量级解决方案最近在折腾个人项目部署时,遇到了一个挺典型的问题:前端应用托管在 Vercel 上,但需要安全地调用一些部署在其他地方(比如家里的 NAS,或者某个有严格 IP 白名单限制…...

MPLAB Harmony 2.0固件框架:从MISRA-C合规到图形化开发的嵌入式开发新范式
1. 项目概述:为什么我们需要一个“全功能”的固件框架?如果你和我一样,在PIC32单片机的世界里摸爬滚打过几年,肯定经历过这样的场景:项目启动,面对Microchip提供的海量外设库、驱动代码和中间件,…...

t-io HTTP服务器实现:如何替代Tomcat和Jetty的完整指南
t-io HTTP服务器实现:如何替代Tomcat和Jetty的完整指南 【免费下载链接】t-io T-io is a network programming framework developed based on Java AIO. From the collected cases, t-io is widely used for IoT, IM, and customer service, making it a top-notch …...

综合能源系统多级环式一体化设计【附代码】
✨ 长期致力于综合能源系统、环式一体化设计、混合求解算法、软件开发应用研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多级环式一体化设计模型与嵌…...

架构设计实战指南:在约束中做取舍的工程智慧
架构设计实战指南:在约束中做取舍的工程智慧 版本:V1.0 适合人群:开发工程师、架构师、技术负责人、CTO、技术出身的创业者写在前面:你是不是也遇到过这些问题? 如果你是开发工程师: 刚写完的代码ÿ…...

基于Claude的代码库感知工具:智能编程助手的设计与实战
1. 项目概述:当Claude遇上代码库,一个智能编程助手的诞生最近在GitHub上看到一个挺有意思的项目,叫openclaw-claude-code。光看名字,你可能会觉得这又是一个基于某个大语言模型的代码生成工具,但实际深入了解后&#x…...

零中频接收机技术演进与动态范围优化方案
1. 零中频接收机技术演进与核心挑战零中频架构(Zero-IF)在移动通信领域已发展超过二十年,最早可追溯至1990年代的GSM手机设计。这种直接将射频信号下变频至基带的技术,相比传统超外差架构省去了中频处理环节,理论上具有…...