javase-15、正则表达式
一、初识正则表达式
1、概念
正则表达式是对字符串操作的一种逻辑公式,它会将事先定义好的一些特定字符,以及这些特定字符的组合,组成一个规则字符串,并且通过这个规则字符串表达对给定字符串的过滤逻辑。
一条正则表达式也称为一个模式,使用每个模式可以匹配指定文本中与表达式模式相同的字符串。正则表达式由普通字符、元字符或预定义字符集组成,其中普通字符包括大小写字母和数字。
常见用途
-
数据验证:比如电话号码、邮箱等
-
替换文本:快速找到特定文本,用于替换
-
快速提取字符串:基于匹配规则,快速从文档中查找或提取子字符串
3、正则的用途举例
案例1
以下哪些是四大名著?
A.西游记
B.三国演义
C.水浒传
D.红楼梦
你喜欢哪些课程?
A.python
B.java
C.hadoop
D.爬虫
执行3/2后的结果正确的是
A、1
B、1.0
B、1.5
B、0
以上排版比较浪费空间,将其变为一行
请将选项后面的.换成、
案例2
Zhangsan like orange or apple
将or替换为and
二、基本语法
1、普通字符
正则表达式中的普通字符,由没有显示的指定为元字符的打印和非打印的字符组成,普通字符没有其它含义,表示它本身。
举例
hello world
匹配hello
hello
2、元字符
使用简单的元字符表达某一类字符,下面列出常用的匹配方式:
预定义字符类
| 元字符 | 描述 |
|---|---|
. | **默认模式:**匹配任何1个字符但换行除外;**DOTALL模式:**匹配任意字符 |
\d | 一个数字:[0-9] |
\D | 非数字:[^0-9] |
\h | 水平空白字符:[ \t\xA0\u1680\u180e\u2000-\u200a\u202f\u205f\u3000] |
\H | 非水平空白字符:[^\h] |
\s | 空白字符:[ \t\n\x0B\f\r] |
\S | 非空白字符:[^\s] |
\v | 垂直空白字符:[\n\x0B\f\r\x85\u2028\u2029] |
\V | 非垂直空白字符:[^\v] |
\w | 单词字符:[a-z,A-Z,_,0-9] |
\W | 非单词字符:[^\w] |
POSIX 字符类(仅限 US-ASCII)
| 元字符 | 描述 |
|---|---|
\p{Lower} | 小写字母字符:[a-z] |
\p{Upper} | 大写字母字符:[A-Z] |
\p{ASCII} | 所有 ASCII:[\x00-\x7F] |
\p{Alpha} | 字母字符:[\p{Lower}\p{Upper}] |
\p{Digit} | 十进制数:[0-9] |
\p{Alnum} | 字母数字字符:[\p{Alpha}\p{Digit}] |
\p{Punct} | 标点符号:!"#$%&'()*+,-./:;<=>?@[\]^_{ |
\p{Graph} | 可见字符:[\p{Alnum}\p{Punct}] |
\p{Print} | 可打印字符:[\p{Graph}\x20] |
\p{Blank} | 空格或制表符:[ \t] |
\p{Cntrl} | 控制字符:[\x00-\x1F\x7F] |
\p{XDigit} | 十六进制数字:[0-9a-fA-F] |
\p{Space} | 空白字符:[ \t\n\x0B\f\r] |
举例
重庆大学 张三,ZhangSan 8000元 重庆万州
重庆大学 李四,Lisiq 8800元 重庆万州
重庆大学 王五,Wangwu 9800元 四川成都
思考,匹配工资信息
\d\d\d\d
思考,匹配中文姓名
\s\s,
其中,用于辅助定位
思考,匹配英文姓名
3、 转义字符
我们已经学了部分元字符,比如. ? + *等,那如果我们想要查找元字符本身,比如要查找. 或者 * ,就出现了问题:没办法指定它们,因为它们会被解释成别的意思。这时就得使用 \来取消这些字符的特殊意义,从而表示字符字面量。
| 元字符 | 转义字符 |
|---|---|
| $ | \$ |
| . | \. |
| + | \+ |
| * | \* |
| ? | \? |
| ^ | \^ |
| / | \/ |
| \ | \\ |
| ( | \( |
| ) | \) |
| [ | \[ |
| ] | \] |
| { | \{ |
| } | \} |
举例
<script src="student.js"></script>
<script src="score.xml"></script>
取出文件名
\w+\.\w+
说明:\w+:中的【+】表示,\w重复1次或多次。说人话,能匹配1个或多个字母\.:表示【.】的转义字符,因为【.】在正则表达式中,有特殊的含义
举例
apple's price is $10.01 per kg.
apple's price is $10.02 per kg.
取出价格
\d+\.\d+
4、字符集
在正则表达式语法中,方括号表示字符范围,也称字符集(或者叫字符组)。
| 字符类 | 说明 |
|---|---|
[abc] | a、b、c |
[^abc] | ^ 表示取反,除 a、b、c 以外的其它字符 |
[a-zA-Z] | - 表示连续,匹配所有字母字符 |
[0-9] | - 表示连续,匹配所有数字字符 |
[a-c[x-z]] | a到c,或 x 到 z,等价于 [a-cx-z],(并) |
[a-z&&[def]] | &&表示and,等价于 [def],(交) |
[a-z&&[^bc]] | a到z,但bc除外,等价于[ad-z],(差) |
举例
124 156 111 1337
92 20 999 666
匹配所有的偶数数字
[02468]
匹配所有的偶数
\d*[02468]
说明:
\d*:【*】匹配\d 0次或多次,说人话:匹配0个或多个数字
[02468]:匹配1个偶数数数字
5、量词
上面我们学会的是单个字符的匹配,如果要表达多个类似的字符,只能通过复制多次的方式,比如我们要查找5个连在一起的数字,要写成\d\d\d\d\d,按程序员的思维,显然不合理,比如我们要表示1000个数字、任意多个数字、…
接下来介绍如何通过量词来表示上面的情形,下面列出了几种量词的写法:
| 量词 | 含义 | 举例 |
|---|---|---|
| X? | X出现 0次 或 1次 | \d? 0个或1个数字 |
| X+ | X出现 1次 或 多次 | \d+1个或多个数字 |
| X* | X出现 0次 或 n次 | \d* 0个或多个数字 |
| X{m} | X出现 m次 | \d{3} 3个数字 |
| X{m,} | X出现 至少m次 | \d{2,} 至少3个数字 |
| X{m,n} | X出现 m~n次 | 0\d{2,3} 0后面根2-3个数字 |
举例
ggle gogle google gooogle goooogle gooooogle goooooogle gooooooogle goooooooogle
匹配上面所有的字符串
go*gle
说明:
o*:o可以出现0次或多次
举例
重庆大学 张三,ZhangSan 80000元 重庆万州
重庆大学 李四,Lisiq 8800元 重庆万州
重庆大学 王五,Wangwu 9800元 四川成都
思考,匹配工资信息
\d+
思考,匹配中文姓名
(\s+),
说明:【,】用于定位,()表示分组,方便后续通过分组编号取出这部分数据
思考,匹配英文姓名
,(\w+)
说明:【,】用于定位,()表示分组,方便后续通过分组编号取出这部分数据
举例
13612345678
13612345678abc
24654897132
12306123456
匹配手机号码
简易版本
1[3456789]\d{9}$
说明:【$】表示以\d{9},也就是9个数字结尾,具体用法见出面的边界。如果不写【$】13612345678abc也会被匹配
6、边界
如何表示一个字符串的起始位置和结束位置呢,这便是我们要讲的边界,这里先给几个简单的边界表示
| 边界匹配器 | 描述 |
|---|---|
^ | 一行的开头,^hi.*,以hi开头的行 |
$ | 一行的结尾,.+\.jpg$,以.jpg结尾的行 |
\b | 单词,边界,指的是占位的字符左右的间隙位置,\bor\b,匹配两边是边界的or |
\B | 非单词,边界 |
注意:
- 单词指的是
\w可以匹配的字符,即数字、大小写字母以及下划线[0-9a-zA-Z_]- 边界 指的是占位的字符左右的间隙位置,边界是零宽断言,只匹配位置, 不匹配字符
举例
Zhangsan like orange or apple
将or替换为and
【老师你也太坏了,不我是让你爱上正则表达式】
查找框里写:\bor\b
替换框里写:and
7、选择、分组和、向后引用
1)选择(或分支)
正则表达式里的选择条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用 | 把不同的规则分隔开。
X|Y 任何一个X或者Y
比如要识别如下两种固话号码,
0991-8585671
023-58102054
(0991)8585671
(023)58102054
则可以写成
0\d{2,3}-?\d{7,8}|\(0\d{2,3}\)\d{7,8}
2)分组
概念
可以使用小括号( )来指定一个子表达式(也叫分组),例如:
(http)(www.*com)
(http)?(www.*com) http作为一个整体,可有可无
组号
捕获组通过从左到右计算它们的左括号来编号
例如,在表达式 ((A)(B(C))) 中,有四个这样的组:
1号分组:((A)(B(C)))
2号分组: (A)
3号分 :(B(C))
4号分组 :(C)
注意:分组编号是从1开始的,0号分组代表整个表达式
例子
还记得刚写的两种固话的匹配吗,可以写成
(\(0\d{2,3}\)|0\d{2,3}-?)\d{7,8}
3)分组捕获与后向引用
作用:将前面分组匹配到的结果(内容),以组号的方式引用,给到后续表达式继续使用。
说明:默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
例子
请找到出左右对称的信息
===welcome===
==hello==
==你好=
==吃了吗===
例子
匹配重复单词的字符串
go go
kitty kitty
\b(\w+)\b\s+\1\b
说明:\1中的1表示组号,在这里表示(\w+)的匹配结果
8、贪婪、懒惰
先来看个例子:
123abc123456abc
如果想找出123abc和123456abc两个字符串,你兴奋的写下了.*abc,结果发现只匹配了一次,把整个字符串匹配了。这便是我们要讲的匹配模式。
1)贪婪
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符,这被称为贪婪匹配
示例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索 aabab的话,它会匹配整个字符串aabab。
属于贪婪模式的量词,也叫做匹配优先量词,包括:“{m,n}”、“{m,}”、“?”、“*”和“+”。
2)懒惰
如果想要匹配尽可能少的字符呢,这就是懒惰匹配模式。
只要在量词后面加上一个问号?就可以了。
比如前面的示例,你只需要将正则表达式写为如下形式即可:
.*?abc
懒惰匹配总是出现在有量词的地方,有如下懒惰量词:
| 语法 | 描述 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
| {m,n}? | 重复m到n次,但尽可能少重复 |
注意
问号(?):问号有两种场景
- 一是以量词方式使用,表示
?前面的子表达式或者字符出现1次或者0次;- 二是出现在量词后面,表示懒惰匹配。
三、在String类中使用正则
String类提供了3个实例方法支持正则操作
① matches 匹配
boolean matches(String regex)判断此字符串是否与给定的 正则表达式 匹配。
例如:
// 判断是不是一个正确的电话号码
String tel = "023-58580000";
boolean matches = tel.matches("\\d+-\\d+");
System.out.println(matches);
② split 拆分
String[] split(String regex)围绕给定 正则表达式 的匹配项拆分此字符串。
String[] split(String regex, int limit)围绕给定 正则表达式 的匹配项拆分此字符串。
例如:
// 按正则对字符串进行拆分
String stuInfo = "zhangsan china-cq 1985/11/12";
//String[] rst = stuInfo.split(" |-|/");
String[] rst = stuInfo.split("[ -/]");
for (String item : rst) {System.out.println(item);
}
③ replace相关
String replace(String old, String new)
String replaceFirst(String regex, String replacement)使用replacement替换regex的第一个匹配。
String replaceAll(String regex, String replacement)使用replacement替换regex的所有匹配。
例如:
(86)023-12345670
021:12345671
010-12345672
需要得到如下结果
(023)12345670
(021)12345671
(010)12345672
String stuInfo = """(86)023-12345670021:12345671010-12345672""";String string = stuInfo.replaceAll("(\\(86\\))?(\\d{3})(-|:)", "($2)");
System.out.println(string);
四、Pattern类和Matcher类
- Matcher类不能单独使用,用于配合Pattern类。
- Pattern类根据正则表达式创建匹配规则,Matcher根据匹配规则执行具体的匹配操作。
1、创建匹配模式(规则)
使用 Pattern.compile() 静态方法,编译正则表达式字符串,形成模式对象(匹配规则)
static Pattern compile(String regex)将给定的正则表达式字符串,编译成一个模式。
static Pattern compile(String regex, int flags)将给定的正则表达式字符串,编译成具有【给定标志】的模式。【flags可以取以下值】Pattern.CANON_EQ 启用规范等价。Pattern.CASE_INSENSITIVE 启用不区分大小写的匹配。【重要】Pattern.COMMENTS 模式中允许空格和注解。Pattern.DOTALL 启用 dotall 模式。【重要】Pattern.LITERAL 启用模式的文字解析。Pattern.MULTILINE 启用多行模式。【重要】Pattern.UNICODE_CASE 启用 Unicode 感知大小写折叠。Pattern.UNICODE_CHARACTER_CLASS 启用Unicode版本预定义字符类和POSIX字符类.Pattern.UNIX_LINES 启用 Unix 行模式。
例如:
String phone = "13100000000";
// 获得模式对象(匹配规则)
Pattern pattern = Pattern.compile("1[345789]\\d{9}");
2、创建匹配器
根据模式(匹配规则)生成匹配器。使用 Pattern对象的 matcher(CharSequence input) 方法,创建匹配器
Matcher类用于,在给定的Pattern实例的模式控制下进行字符串的匹配工作。
例如:
String phone = "13100000000";
Pattern pattern = Pattern.compile("1[345789]\\d{9}"); // 匹配规则
Matcher matcher = pattern.matcher(phone); // 匹配器
3、匹配器的常用方法
匹配器,Matcher的实例对象
① matches匹配
"abc".matches("\w{3}")
boolean matches()字符串,是否与正则表达式【完全】匹配
例如:
String phone = "13100000000";
Pattern pattern = Pattern.compile("1[345789]\\d{9}"); // 编译后的模式
Matcher matcher = pattern.matcher(phone);
System.out.println(matcher.matches());
② lookingAt匹配
boolean lookingAt()字符串的【开始位置】,是否有和正则表达式匹配的内容
例如:
③ find匹配
boolean find()字符串中,是否有【与位置无关】和正则表达式匹配的内容
boolean find(int start)字符串中【从start指定的地方开始】,是否有【与位置无关】和正则表达式匹配的内容
例如:
④ groupCount 匹配
int groupCount()返回匹配到的分组(结果)个数
例如:
⑤ group
获得匹配结果,注意 要先调用匹配方法,后才能获得匹配结果,否则报错
String group(); String group(0);//返回匹配到的【整体】结果
String group(int group);//根据【分组编号,0表示完整结果,组号从1开始】,获取匹配到的结果
例如:
⑥ replaceAll
String replaceAll(String replacement)将正则表达式对应的【所有】【完整匹配】结果,使用字符串替换,并返回替换后的新字符串
例如:
⑦ replaceFirst
String replaceFirst(String replacement)将正则表达式对应的【第一个】【完整匹配】结果,使用字符串替换,并返回替换后的新字符串
例如:
⑧ 其他方法见API手册
4、其它相关用法
① 使用 pattern 匹配字符串
使用 Pattern.matches() 静态方法,判断正则表达式与字符串【完全】匹配。
Static boolean matches(String regex, CharSequence input)
例如:
// 判断手机号格式是否正确
String phone = "13100000000";
System.out.println(Pattern.matches("1[345789]\\d{9}", phone));
② 使用 pattern 拆分字符串
Pattern.compile("[ -/]").split("张三 中国/重庆/巴南 2011-11-11");
相关文章:

javase-15、正则表达式
一、初识正则表达式 1、概念 正则表达式是对字符串操作的一种逻辑公式,它会将事先定义好的一些特定字符,以及这些特定字符的组合,组成一个规则字符串,并且通过这个规则字符串表达对给定字符串的过滤逻辑。 一条正则表达式也称为…...

【SpringSecurity】SpringSecurity+JWT实现登录
1. SpringSecurity介绍 Spring Security 是一个功能强大且高度可定制的身份验证和访问控制框架。它是为Java应用程序设计的,特别是那些基于Spring的应用程序。Spring Security是一个社区驱动的开源项目,它提供了全面的安全性解决方案,包括防…...

jmeter连接mysql
查询mysql数据库版本 SELECT VERSION(); 下载jmeter mysql 驱动jar包,版本低于mysql版本,放在jmeter的lib 路径下 MySQL :: Download MySQL Connector/J (Archived Versions) 添加JDBC Connection Configuration 填写 variable name 及数据库信息 注意…...

图书馆管理系统(三)基于jquery、ajax
任务3.4 借书还书页面 任务描述 这部分主要是制作借书还书的界面,这里我分别制作了两个网页分别用来借书和还书。此页面,也是通过获取books.txt内容然后添加到表格中,但是借还的操作没有添加到后端中去,只是一个简单的前端操作。…...

Nginx Location 配置块全解析与示例
Nginx Location 配置块全解析与示例 摘要: 本文深入探讨了 Nginx 中 location 配置块的功能、语法规则以及多种实际应用场景下的配置示例,旨在帮助读者全面理解并熟练掌握 location 配置块,以便在 Nginx 服务器配置中灵活运用,实…...
ReentrantReadWriteLock)
javalock(八)ReentrantReadWriteLock
ReentrantReadWriteLock: 同时实现了共享锁和排它锁。内部有一个sync,同时实现了tryAcquire/tryReleases、tryAcquireShared/tryReleasesShared,一共四个函数,然后ReentrantReadWriteLock内部还实现了一个ReadLock和一个WriteLock,…...

反射和设计模式
一、反射 1. 相关概念 (1) 类的对象:基于定义好的一个类,创建该类的实例,即利用 new 创建的实例就为类的对象。 (2) 类对象:类加载的产物,封装了一个类的所有信息 ( 包名、类名、父类、接口、属性、方法、构造方…...

双指针---和为s的两个数字
这里写自定义目录标题 题目链接问题分析代码解决执行用时 题目链接 购物车内的商品价格按照升序记录于数组 price。请在购物车中找到两个商品的价格总和刚好是 target。若存在多种情况,返回任一结果即可。 问题分析 暴⼒解法,会超时 (两层…...

LLaMA-Factory 单卡3080*2 deepspeed zero3 微调Qwen2.5-7B-Instruct
环境安装 git clone https://gitcode.com/gh_mirrors/ll/LLaMA-Factory.git 下载模型 pip install modelscope modelscope download --model Qwen/Qwen2.5-7B-Instruct --local_dir /root/autodl-tmp/models/Qwen/Qwen2.5-7B-Instruct 微调 llamafactory-cli train \--st…...

智慧农业云平台与水肥一体化:道品科技引领农业现代化新潮流
在当今科技飞速发展的时代,农业也正经历着一场深刻的变革。智慧农业云平台和水肥一体化技术的出现,为农业生产带来了前所未有的机遇和挑战。 一、智慧农业云平台:农业生产的 “智慧大脑” 智慧农业云平台就像是农业生产的 “智慧大脑”&…...

241207_MindNLP中的大模型微调
241207_基于MindNLP的大模型高效微调 现在的大模型体量非常庞大,全量微调所需要的算力也特别庞大,个人开发者没有条件微调。参数量达到7B的模型才刚刚有涌现能力,但是我们要微调7B的模型的话,就需要328G的显存,至少需…...

MongoDB、Mongoose使用教程
文章目录 一:MongoDB 简介1.1 什么是 MongoDB1.2 特点1.3 与关系数据库的区别:1.4 资源链接: 二:安装 MongoDB2.1 安装前的准备2.2 安装、启动 MongoDB2.3 创建用户 MongoDB 三、连接四:MongoDB 基础操作4.1 库操作&am…...
)
单片机:实现控制步进电机正反转(附带源码)
1. 步进电机概述 步进电机(Step Motor)是一种能够将电能转换为机械能的电动机。其独特之处在于能够精确地控制转动角度,因此被广泛应用于需要精确控制的场合,如打印机、机器人、数控机床、自动化设备等。 步进电机的转动是以“步…...

安装指南|OpenCSG Starship上架GitHub Marketplace
在代码开发的日常中,你是否常常被以下问题困扰? 代码审查耗时太长,拖慢项目进度? 审查质量参差不齐,一些关键问题被遗漏? 复杂代码变更看不懂,审查者需要大量时间理解意图? 别担…...
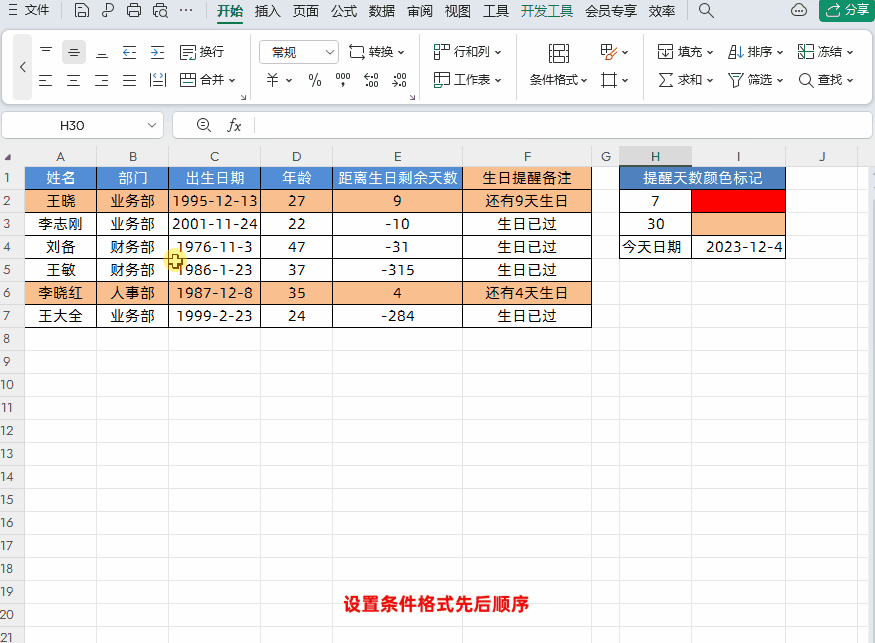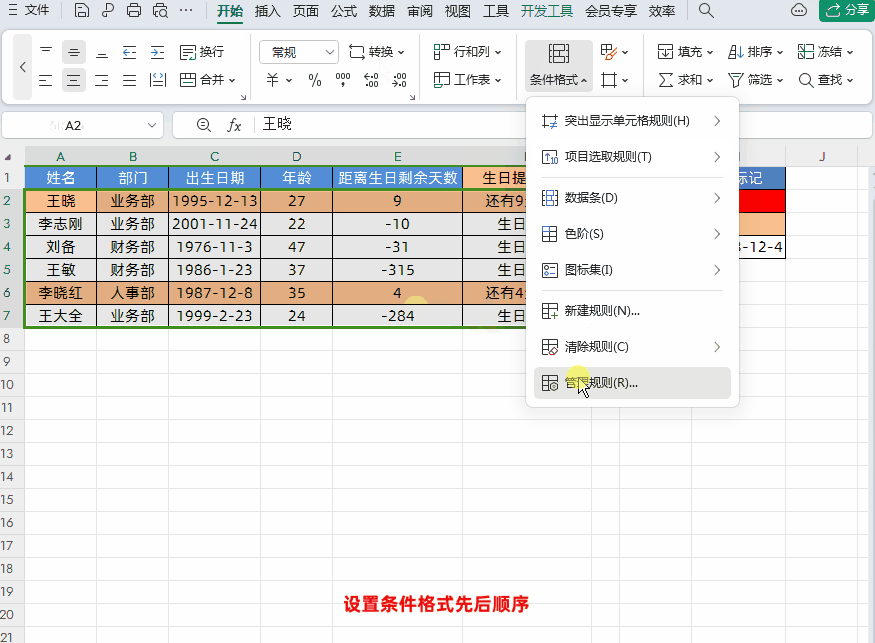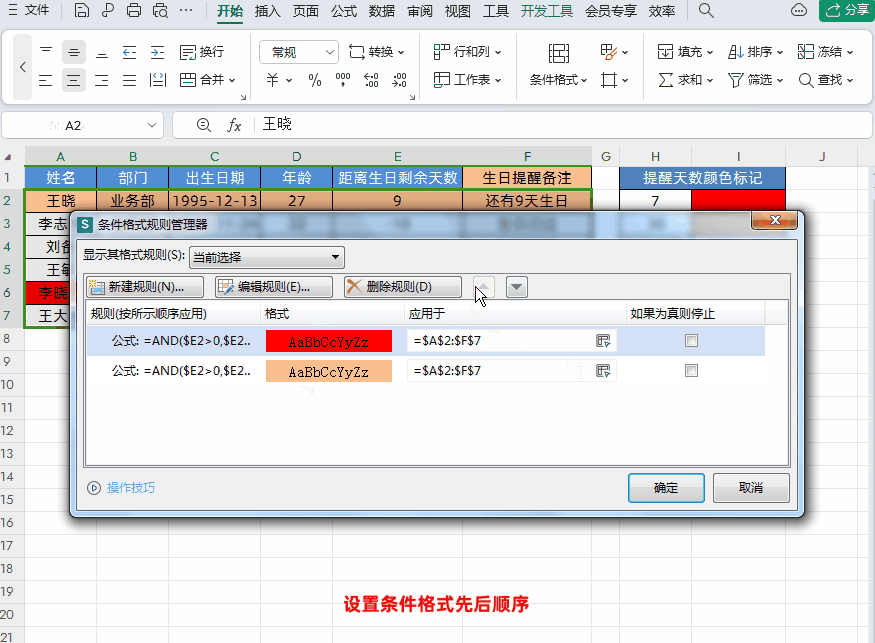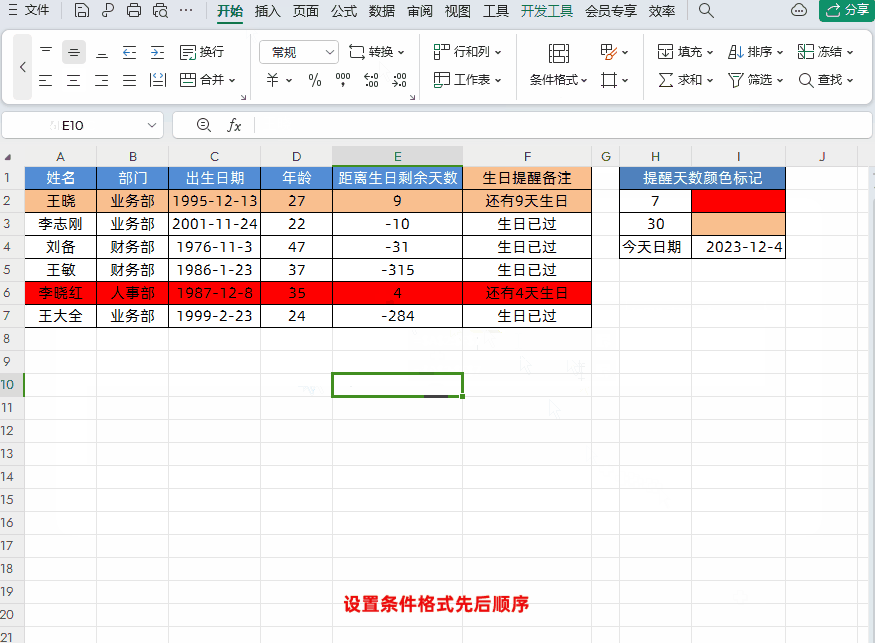
Excel设置生日自动智能提醒,公式可直接套用!
大家好,我是小鱼。 今天跟大家分享一个WPS表格中根据出生日期,设置生日提醒,并且根据距离生日天数自动标记数据颜色。简单又实用,一个公式轻松搞定! 接下来我们先学习一下需要使用到的函数,然后再根据实例让…...

同步异步日志系统:前置知识
一、日志项目的介绍 1.1 为什么要有日志系统 1、⽣产环境的产品为了保证其稳定性及安全性是不允许开发⼈员附加调试器去排查问题,可以借助日志系统来打印⼀些⽇志帮助开发⼈员解决问题 为什么不直接printf打印在屏幕上呢??因为现实中没有…...

微服务设计原则——功能设计
文章目录 1.ID生成2.数值精度3.DB操作4.性能测试5.版本兼容5.1 向旧兼容5.2 向新兼容 6.异步时序问题7.并发问题7.1 并发时序7.2 并发数据竞争 参考文献 1.ID生成 在分布式系统中,生成全局唯一ID是非常重要的需求,因为需要确保不同节点、服务或实例在并…...

低代码软件搭建自学的第一天——熟悉PyQt
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 学习计划第 1 步:环境搭建1.1 安装 Python1.2 安装 PyQt安装命令:验证安装: 第 2 步:PyQt 基础知识2.1 创建第一个窗…...

基于Python3编写的Golang程序多平台交叉编译自动化脚本
import argparse import os import shutil import sys from shutil import copy2from loguru import loggerclass GoBuild:"""一个用于构建跨平台执行文件的类。初始化函数,设置构建的主文件、生成的执行文件名称以及目标平台。:param f: 需要构建的…...

远程桌面连接
电脑A:使用机 电脑B:被控制的另一个 方法1: 在电脑B上操作 ①winr输入cmd进入命令行窗口,输入ipconfig查询本机地址 ②我的电脑/此电脑 右键点击“属性” ③选择屏幕右边“远程桌面” ④打开“启用远程桌面” ⑤打开设置&am…...

收藏!小白程序员轻松入门大模型:3个月实现转岗高薪offer的秘诀
本文针对传统程序员转行AI大模型的困境,提出三条实用路径:RAG应用工程、Agent应用开发、模型微调与部署。强调工程能力在AI应用中的重要性,建议通过解决实际问题积累经验,而非单纯堆砌技术栈。文章指出,懂业务、善工程…...

从零构建卡组构筑器:React+TS实战与复杂状态管理解析
1. 项目概述:从零构建一个卡组构筑器最近在GitHub上看到一个挺有意思的项目,叫guladam/deck_builder_tutorial。光看名字,很多朋友可能第一反应是“哦,一个教你怎么做卡组构筑器的教程”。但如果你真的点进去,或者像我…...

MPLAB® Harmony嵌入式框架实战:从架构解析到项目开发避坑指南
1. 项目概述:从零到一,理解MPLAB Harmony的价值如果你是一位嵌入式开发者,尤其是长期与Microchip的PIC或SAM系列MCU打交道的朋友,那么“MPLAB Harmony”这个名字你一定不陌生。它可能出现在官方文档的角落里,在论坛的讨…...

郎朗乐境音乐会定档7月5日深圳:以破界之姿,开启全维感官盛宴
2026年7月5日,郎朗乐境音乐会将在深圳市宝安体育中心体育馆启幕,作为“深圳国际形象大使”的郎朗,将在这座以创新著称的国际化都市,,进一步探索艺术表达形式的多重可能,呈现一场融合音乐、文化与多维感官体…...
)
手把手教你用TI TICS Pro配置LMX2594时钟芯片(附寄存器导出与SPI写入指南)
手把手教你用TI TICS Pro配置LMX2594时钟芯片(附寄存器导出与SPI写入指南) 在高速数字系统设计中,时钟信号的稳定性和精确度往往决定着整个系统的性能上限。作为射频与通信领域的工程师,我深刻体会过时钟配置失误带来的调试噩梦—…...

Arm Cortex-A78处理器仿真技术与Iris架构实践
1. Arm Cortex-A78AE/A78C处理器仿真技术解析在半导体设计领域,处理器仿真技术已经成为芯片开发流程中不可或缺的关键环节。作为Armv8.2-A架构的代表性产品,Cortex-A78AE和A78C处理器采用了创新的Iris组件体系进行建模,这种基于指令集架构(IS…...

工业级加密漏洞检测工具Cryptoscope解析
1. Cryptoscope:工业级加密漏洞检测工具解析在软件开发领域,加密技术的正确使用一直是个棘手问题。我见过太多项目因为加密实现不当导致数据泄露——有的使用了已被证明不安全的算法,有的密钥管理存在严重缺陷,还有的甚至把加密密…...

CTF新手必看:用010 Editor修复PNG图片CRC错误,轻松拿下BUUCTF那道‘一叶障目’题
CTF新手实战:用010 Editor修复PNG图片CRC校验错误 拿到一张打不开的PNG图片,显示"CRC校验失败"?别急着放弃,这可能是CTF比赛中故意设置的陷阱。作为MISC方向的经典题型,修改PNG文件头参数是常见的出题套路。…...

BilibiliDown:专业级B站视频下载工具,高效构建个人媒体库
BilibiliDown:专业级B站视频下载工具,高效构建个人媒体库 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.co…...

MySQL的知识阶段小总结
1.MySQL的库操作1.1 MySQL 显示已建库操作语法格式:show databases;注意事项:是databases而不是database,要加s。使用该SQL语句,可以查找当前服务器所有的数据库。huan如上图所示,画红框的Java13和test113是用户自己创…...