多种注意力机制详解及其源码
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙



目录
概述
注意力机制的特点
捕获长距离依赖
并行化处理
重要性的加权
灵活性
解释性
减少参数
促进模型创新
Transformer Attention
Transformer Attention代码
其他注意力机制详解及代码
SENet
ELA
BAM 瓶颈注意力模块
A2Attention 双重注意力
AgentAttention
本文所有资源均可在该地址处获取。
概述
注意力机制的发展历程体现了人工智能领域对模型表达能力和效率的不断追求。从最初在序列模型中的应用,到Transformer模型的提出,再到当前在各个领域的广泛应用,注意力机制已经成为现代人工智能模型的核心组成部分。随着研究的深入,注意力机制将继续演化,推动人工智能技术的发展。因此提出更好的注意力机制,对于模型性能的提升很有帮助。
注意力机制的特点
注意力机制在人工智能模型中的重要性体现在以下几个方面:
捕获长距离依赖
在传统的序列处理模型中,长距离的元素之间的依赖关系往往难以捕捉。注意力机制通过直接建立远程元素之间的联系,有效地解决了这一问题,这对于翻译、文本摘要等任务尤为重要。
并行化处理
尽管RNN及其变体可以处理序列数据,但它们通常是按顺序处理信息的,这限制了并行处理的能力。而注意力机制可以同时考虑序列中的所有元素,使得模型能够更高效地利用现代计算资源进行并行计算。
重要性的加权
注意力机制允许模型为输入序列的不同部分分配不同的权重,这样可以更加聚焦于对当前任务更为重要的信息,提高了模型处理信息的效率和质量。
灵活性
注意力机制能够以灵活的方式整合到各种模型结构中,不仅限于序列到序列的任务,也可以用于图像识别、语音识别等其他领域。
解释性
注意力权重可以为模型的决策提供一定的解释性,通过观察权重分布,我们可以了解模型在做出预测时关注哪些输入部分,这在某些需要模型可解释性的应用场景中非常重要。
减少参数
在处理长序列时,如果不使用注意力机制,模型可能需要大量的参数来存储长距离的信息。而注意力机制通过动态权重连接不同元素,减少了模型的参数数量。
适应不同类型的注意力:注意力机制可以根据不同的任务需求设计成多种形式,如自注意力(self-attention)、多头注意力(multi-head attention)、全局注意力和局部注意力等,这使得模型能够更好地适应不同的应用场景。
促进模型创新
注意力机制的提出推动了后续一系列研究和新模型的发展,如Transformer、BERT、GPT等,这些模型在自然语言处理、计算机视觉等领域都取得了突破性的成果。
Transformer Attention
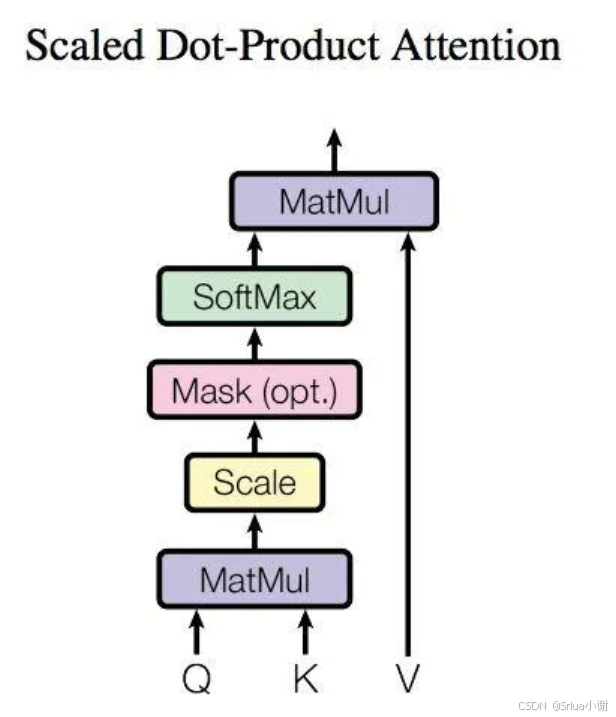
MatMul(矩阵乘法):首先对输入数据进行两次矩阵乘法操作,分别得到Q(Query)、K(Key)和V(Value)。这一步是为了从原始数据中提取出查询、键和值向量。
Scale(缩放):由于点积可能会产生很大的数值,为了保持数值稳定性,通常会对点积进行缩放处理。在Scaled Dot-Product Attention中,缩放的因子是1dkdk1,其中dkdk是键向量的维度。
SoftMax:经过缩放处理的点积结果会通过一个SoftMax函数转换为概率分布。SoftMax函数确保了所有输出的概率之和为1,从而可以解释为一个有效的注意力权重分布。
Mask(可选,掩码):在某些情况下,可能需要对某些位置的信息进行屏蔽,比如在序列任务中未来的信息不应该影响当前的处理。这时就会用到掩码来设置这些位置的权重为0。
第二次MatMul:最后,将得到的注意力权重与V(Value)向量进行第二次矩阵乘法,以加权求和的方式融合来自不同位置的值信息,得到最终的输出。
Transformer Attention代码
import torch
import torch.nn as nnx=torch.rand(16,100,768)
model=nn.MultiheadAttention(embed_dim=768,num_heads=4)
print(model(x,x,x))
其他注意力机制详解及代码
SENet
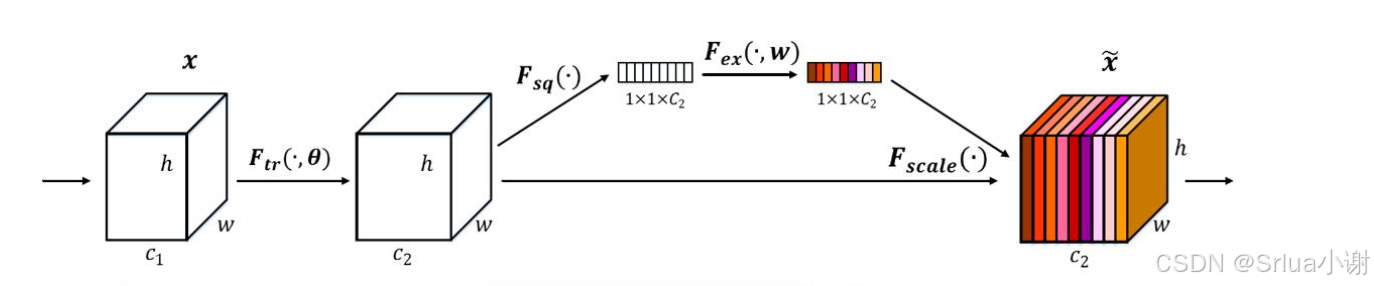
SENet(Squeeze-and-Excitation Networks)通道注意力机制通过显式地建模通道之间的依赖关系来提高网络的表示能力。
class SELayer(nn.Module):def __init__(self, channel, reduction=16):super(SELayer, self).__init__()# 自适应平均池化层,将每个通道的空间维度(H, W)压缩到1x1self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全连接层序列,包含两个线性变换和中间的ReLU激活函数self.fc = nn.Sequential(# 第一个线性层,将通道数从 'channel' 缩减到 'channel // reduction'nn.Linear(channel, channel // reduction, bias=False),# ReLU激活函数,用于引入非线性nn.ReLU(inplace=True),# 第二个线性层,将通道数从 'channel // reduction' 恢复到 'channel'nn.Linear(channel // reduction, channel, bias=False),# Sigmoid激活函数,将输出限制在(0, 1)之间nn.Sigmoid())def forward(self, x):# 获取输入张量的形状b, c, h, w = x.size()# Squeeze:通过全局平均池化层,将每个通道的空间维度(H, W)压缩到1x1y = self.avg_pool(x).view(b, c)# Excitation:通过全连接层序列,对压缩后的特征进行处理y = self.fc(y).view(b, c, 1, 1)# 通过扩展后的注意力权重 y 调
ELA
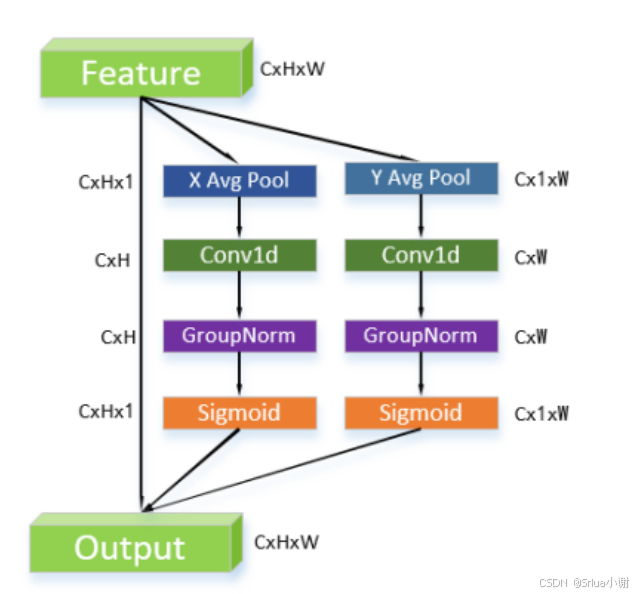
import torch
import torch.nn as nnclass EfficientLocalizationAttention(nn.Module):def __init__(self, channel, kernel_size=7):super(EfficientLocalizationAttention, self).__init__()self.pad = kernel_size // 2self.conv = nn.Conv1d(channel, channel, kernel_size=kernel_size, padding=self.pad, groups=channel, bias=False)self.gn = nn.GroupNorm(16, channel)self.sigmoid = nn.Sigmoid()def forward(self, x):b, c, h, w = x.size()# 处理高度维度x_h = torch.mean(x, dim=3, keepdim=True).view(b, c, h)x_h = self.sigmoid(self.gn(self.conv(x_h))).view(b, c, h, 1)# 处理宽度维度x_w = torch.mean(x, dim=2, keepdim=True).view(b, c, w)x_w = self.sigmoid(self.gn(self.conv(x_w))).view(b, c, 1, w)print(x_h.shape, x_w.shape)# 在两个维度上应用注意力return x * x_h * x_w
BAM 瓶颈注意力模块
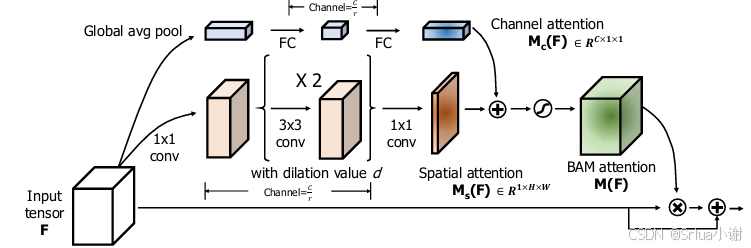
Bottleneck Attention Module(BAM)是一种用于计算机视觉领域的深度学习模型结构,旨在提高神经网络对图像特征提取和感受野处理的能力。BAM模块的核心在于引入了通道注意力机制和空间注意力机制,这两种机制可以自适应地调整特征通道和空间位置的重要性。
# 定义 BAMBlock 模块,结合通道和空间注意力
class BAMBlock(nn.Module):def __init__(self, channel=512, reduction=16, dia_val=2):super().__init__()# 初始化通道注意力和空间注意力模块self.ca = ChannelAttention(channel=channel, reduction=reduction)self.sa = SpatialAttention(channel=channel, reduction=reduction, dia_val=dia_val)self.sigmoid = nn.Sigmoid() # 使用 Sigmoid 激活函数来计算注意力权重def forward(self, x):# 输入 x 的形状为 (batch_size, channels, height, width)b, c, _, _ = x.size()# 计算空间注意力输出sa_out = self.sa(x)# 计算通道注意力输出ca_out = self.ca(x)# 将空间和通道注意力相加并通过 Sigmoid 激活函数计算注意力权重weight = self.sigmoid(sa_out + ca_out)# 结合输入和注意力权重out = (1 + weight) * xreturn out
A2Attention 双重注意力
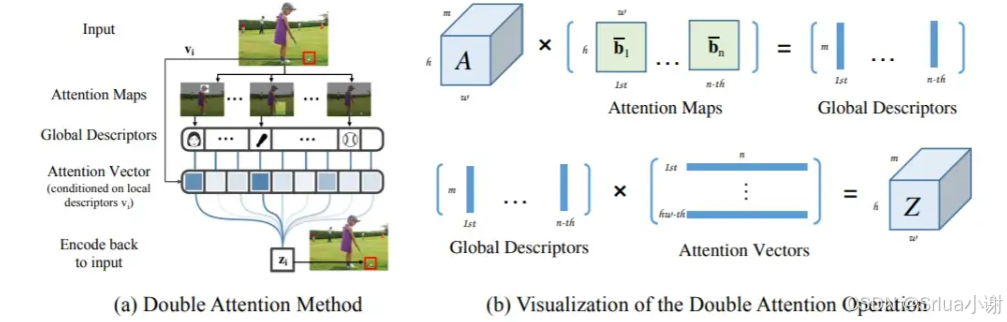
A2Attention模型的核心思想可以概括为两个主要步骤:
特征收集(Feature Gathering):这一步涉及从整个空间中收集关键特征到一个紧凑的集合中。这有助于捕捉输入图像或视频在整个时空空间中的全局特征。
特征分布(Feature Distribution):在收集关键特征之后,模型会自适应地将这些特征分布到每个位置。这样做即使后续的卷积层没有很大的接收域,也能感知整个空间的特征。
class DoubleAttention(nn.Module):def __init__(self, in_channels, c_m=128, c_n=128, reconstruct=True):super().__init__()self.in_channels = in_channelsself.reconstruct = reconstructself.c_m = c_mself.c_n = c_n# 定义三个 1x1 的卷积层self.convA = nn.Conv2d(in_channels, c_m, 1) # 用于计算特征 Aself.convB = nn.Conv2d(in_channels, c_n, 1) # 用于计算注意力映射 Bself.convV = nn.Conv2d(in_channels, c_n, 1) # 用于计算注意力向量 V# 如果需要重新构建输出通道数,定义一个 1x1 的卷积层if self.reconstruct:self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size=1)# 定义前向传播函数def forward(self, x):# 获取输入的形状b, c, h, w = x.shapeassert c == self.in_channels # 确保输入的通道数与定义的通道数一致A = self.convA(x) # 特征 A 的形状为 (b, c_m, h, w)B = self.convB(x) # 注意力映射 B 的形状为 (b, c_n, h, w)V = self.convV(x) # 注意力向量 V 的形状为 (b, c_n, h, w)# 重塑特征 A 为 (b, c_m, h*w)tmpA = A.view(b, self.c_m, -1)# 重塑并应用 softmax 到注意力映射 B,得到注意力权重,形状为 (b, c_n, h*w)attention_maps = F.softmax(B.view(b, self.c_n, -1), dim=-1)# 重塑并应用 softmax 到注意力向量 V,得到注意力权重,形状为 (b, c_n, h*w)attention_vectors = F.softmax(V.view(b, self.c_n, -1), dim=-1)# 第一步:特征门控global_descriptors = torch.bmm(tmpA, attention_maps.permute(0, 2, 1)) # 计算特征 A 与注意力映射 B 的批量矩阵乘法,得到全局描述符,形状为 (b, c_m, c_n)# 第二步:特征分布tmpZ = global_descriptors.matmul(attention_vectors) # 将全局描述符与注意力向量 V 相乘,得到新的特征映射 Z,形状为 (b, c_m, h*w)tmpZ = tmpZ.view(b, self.c_m, h, w) # 重塑 Z 为 (b, c_m, h, w)if self.reconstruct:tmpZ = self.conv_reconstruct(tmpZ)return tmpZAgentAttention
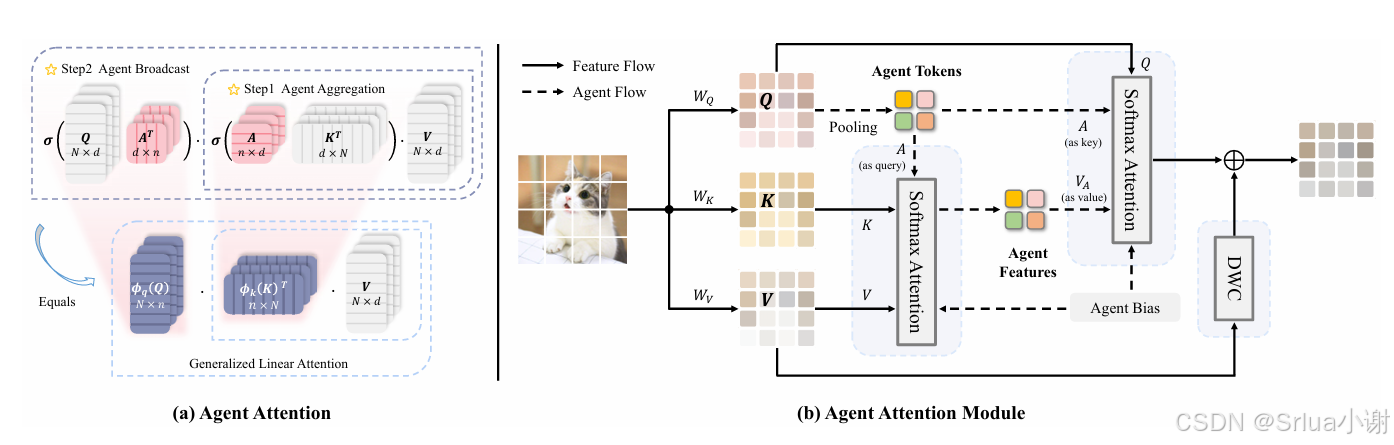
Agent Attention是一种由清华大学研究者提出的新的注意力模型。该模型主要针对视觉Transformer模型在处理视觉任务时遇到的挑战,如分类、分割和检测等。Agent Attention的核心创新在于它整合了Softmax注意力和线性注意力的优势,以解决传统全局自注意力计算量大和效率问题。
模型特点:
传统注意力机制的局限性:传统的Softmax注意力在视觉任务中由于特征数量多,计算复杂度为平方级别,导致计算量过大。而线性注意力虽然降低了计算复杂度到线性级别,但其效果通常不如Softmax注意力。
代理注意力(Agent Attention):为了克服上述问题,Agent Attention在标准的注意力三元组(Q, K, V)基础上引入了一组额外的代理向量A,形成了一种新的四元注意力机制(Q, A, K, V)。这些代理向量A首先作为查询向量Q的代理,从键K和值V中聚合信息,然后将这些信息广播回Q。
效率和表达能力的平衡:通过这种方式,Agent Attention既保留了全局注意力的高表达能力,又通过降低计算复杂度提高了效率。
注:附件包含的即插即用的注意力模块:A2Attention,AgentAttention,BAM,Biformer,CAA,CBAM,ECA,EMA,MCA,MLCA,SENet等

相关文章:
多种注意力机制详解及其源码
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...
VMWare 的克隆操作
零、碎碎念 VMWare 的这个克隆操作很简单,单拎出来成贴的目的是方便后续使用。 一、操作步骤 1.1、在“源”服务器上点右键,选择“管理--克隆” 1.2、选择“虚拟机的当前状态”为基础制作克隆,如下图所示,然后点击“下一页” 1.3、…...

Y3编辑器教程7:界面编辑器
文章目录 一、简介1.1 导航栏1.2 画板1.3 场景界面1.4 控件1.4.1 空节点1.4.2 按钮1.4.3 图片1.4.4 模型1.4.5 文本1.4.6 输入框1.4.7 进度条1.4.8 列表 1.5 元件1.5.1 简介1.5.2 差异说明1.5.3 元件实例的覆盖、还原与禁止操作1.5.4 迷雾控件 1.6 属性1.7 事件(动画…...

「Mac畅玩鸿蒙与硬件45」UI互动应用篇22 - 评分统计工具
本篇将带你实现一个评分统计工具,用户可以对多个选项进行评分。应用会实时更新每个选项的评分结果,并统计平均分。这一功能适合用于问卷调查或评分统计的场景。 关键词 UI互动应用评分统计状态管理数据处理多目标评分 一、功能说明 评分统计工具允许用…...
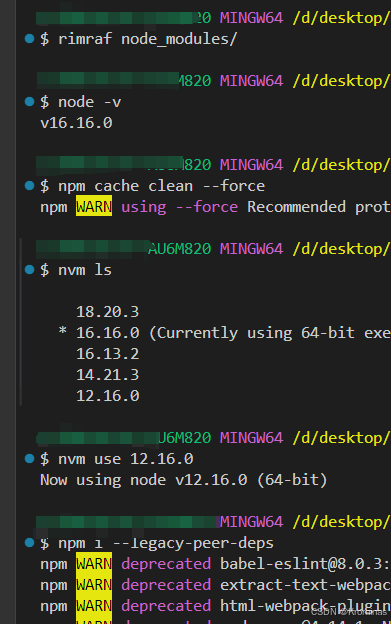
run postinstall error, please remove node_modules before retry!
下载 node_modules 报错:run postinstall error, please remove node_modules before retry! 原因:node 版本出现错误,我的项目之前是在 12 下运行的。解决方法: 先卸载node_modules清除缓存将node版本切换到12重新下载即可...

详细解读TISAX认证的意义
详细解读TISAX认证的意义,犹如揭开信息安全领域的一颗璀璨明珠,它不仅代表了企业在信息安全管理方面的卓越成就,更是通往全球汽车供应链信任桥梁的关键一环。TISAX,即“Trusted Information Security Assessment Exchange”&#…...

【开源项目】数字孪生轨道~经典开源项目数字孪生智慧轨道——开源工程及源码
飞渡科技数字孪生轨道可视化平台,基于国产数字孪生引擎,结合物联网IOT、大数据、激光雷达等技术,对交通轨道进行超远距、高精度、全天侯的监测,集成轨道交通运营数据,快速准确感知目标,筑牢轨交运营生命线。…...

云原生是什么
云原生是一种构建和运行应用程序的方法,它充分利用了云计算的优势。它不仅仅是指在云上运行应用程序,更重要的是指应用程序的设计、开发、部署和运维方式都充分考虑了云环境的特性,从而能够更好地利用云的弹性、可扩展性和灵活性。 更详细地…...

买卖股票的最佳时机 IV - 困难
************* C topic:188. 买卖股票的最佳时机 IV - 力扣(LeetCode) ************* Stock angin: Still stocks. Intuitively, it feels hard. For once: class Solution { public:int maxProfit(vector<int>& prices) {in…...

linux源码编译php提示:No package ‘oniguruma‘ found
编译遇到缺少Oniguruma开发包,处理办法1 安装epel仓库、安装 Oniguruma 开发包 [rootiZwz98gb9fzslgpnomg3ceZ php-8.1.29]# yum install epel-release [rootiZwz98gb9fzslgpnomg3ceZ php-8.1.29]# yum install oniguruma oniguruma-devel 方法2:去On…...
2024技能大赛Vue流程复现
1. 关于版本的控制 vue/cli 5.0.8vscode 最新下载版本 2. 创建vuecli项目 若没有安装vuecli则可以先安装 npm install -g vue/cli # 默认下载最新版本。vue --version vue -V # 查看版本,两个选一 使用vuecli来创建一个新的vue项目,vs code打开…...
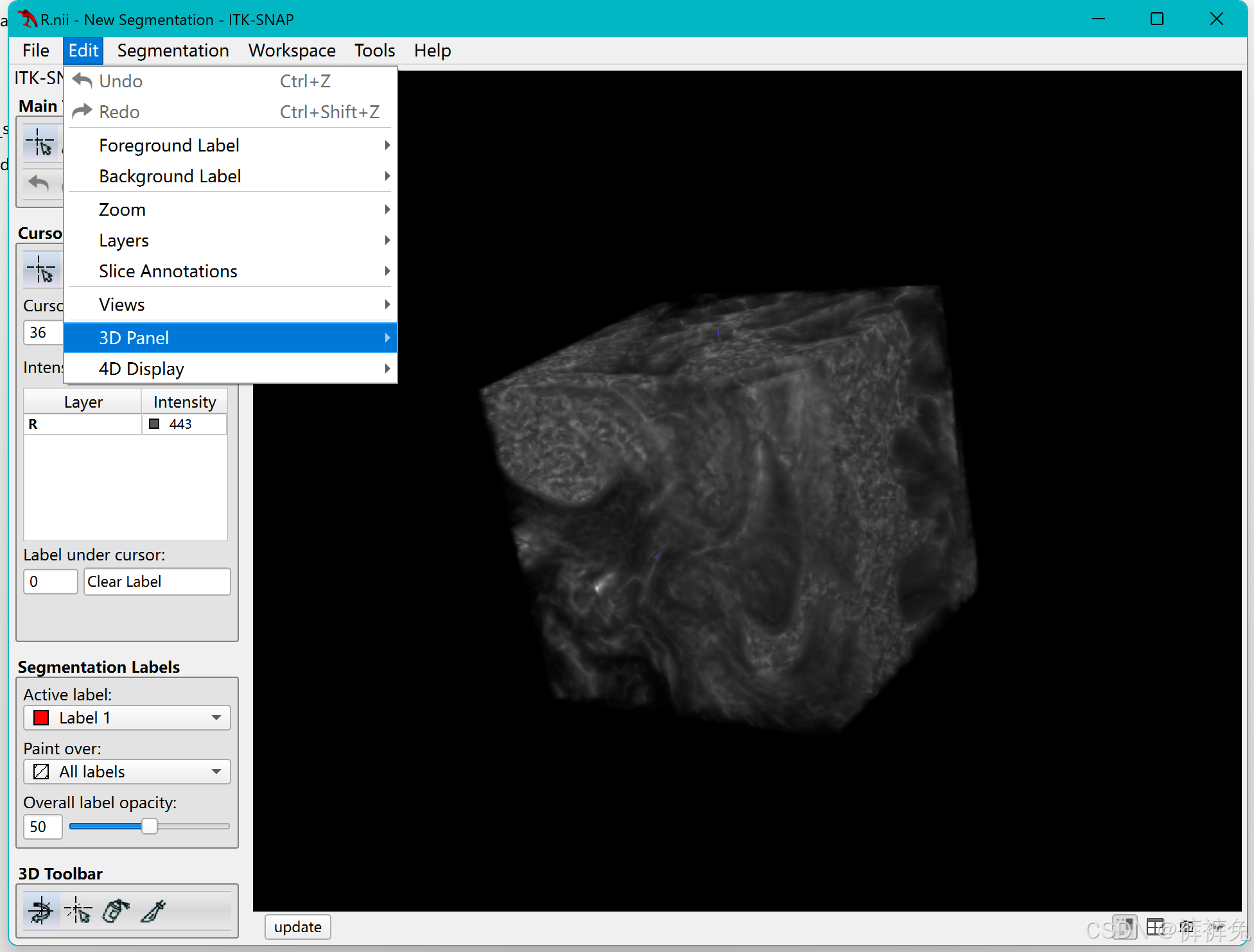
MATLAB截取图像的一部分并保存导出,在itksnap中3D展示
**问题描述:**输入nifti图像,截取图像的一部分并输出,比如截取图像的101010这一块,并导出为nii文件 inputFile D:\aa\dcm\input.nii; % 输入文件路径subsetSize [10 10 10]; % 截取的图像块大小 subsetStart [1 1 1]; % 截取的…...
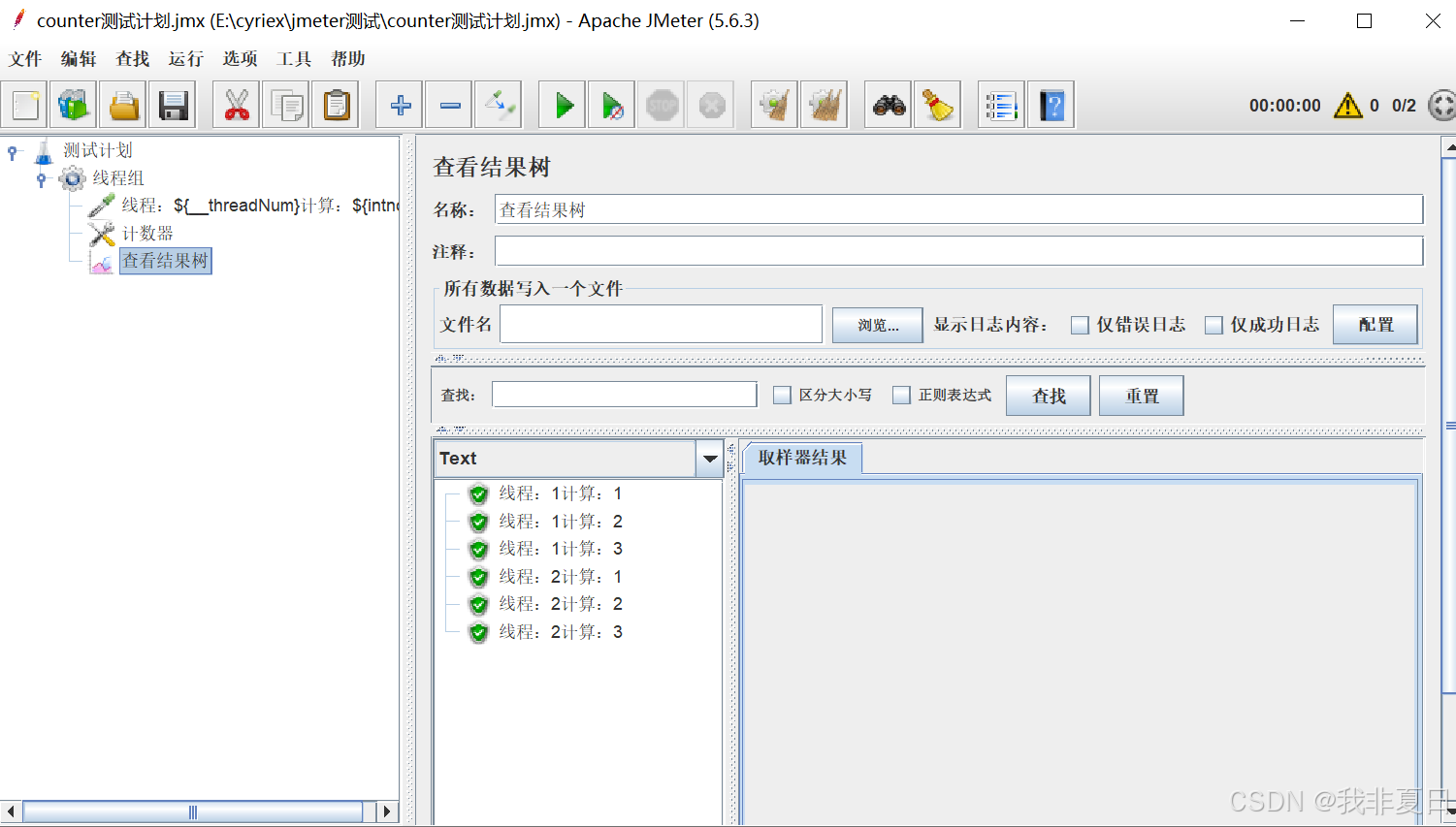
JMeter配置原件-计数器
一、面临的问题: 由于本人的【函数助手对话框】中counter计数器每次加2,且只显示偶数(如下图所示),因此借助【配置原件-计数器】来实现计数功能。 如果有大佬知道解决方式,麻烦评论区解答一下,谢谢。 二、配置原件-c…...

go面试问题
1 Go的内存逃逸如何分析 go build -gcflags-m main_pointer.go 2 http状态码 300 请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 301 永久移动。请求的资源已被永久的移动到新U…...

springboot 配置Kafka 关闭自启动连接
这里写自定义目录标题 springboot 配置Kafka 关闭自启动连接方法一:使用 ConditionalOnProperty方法二:手动管理Kafka监听器容器方法三:使用 autoStartupfalse结语 springboot 配置Kafka 关闭自启动连接 在Spring Boot应用程序中,…...
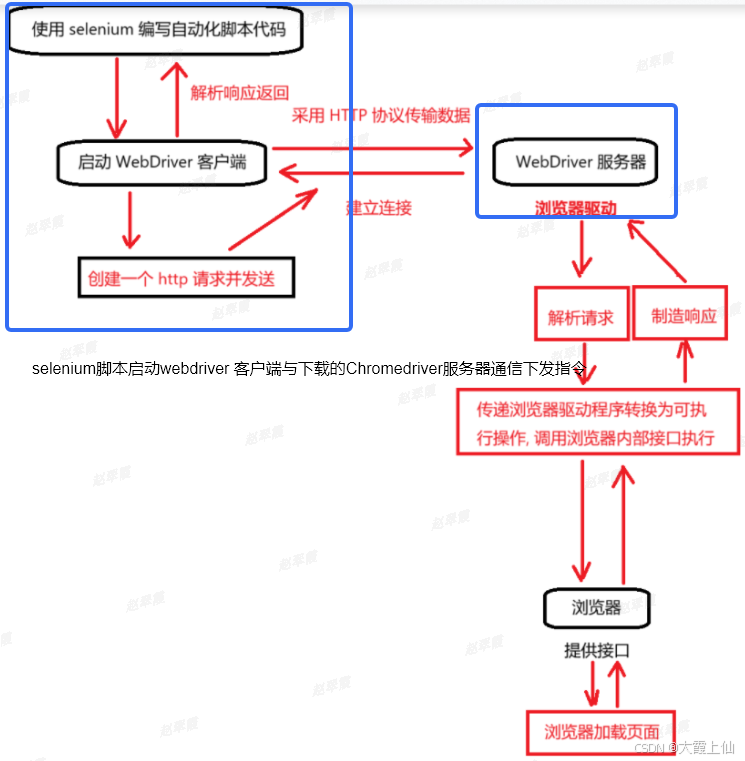
selenium工作原理
原文链接:https://blog.csdn.net/weixin_67603503/article/details/143226557 启动浏览器和绑定端口 当你创建一个 WebDriver 实例(如 webdriver.Chrome())时,Selenium 会启动一个新的浏览器实例,并为其分配一个特定的…...
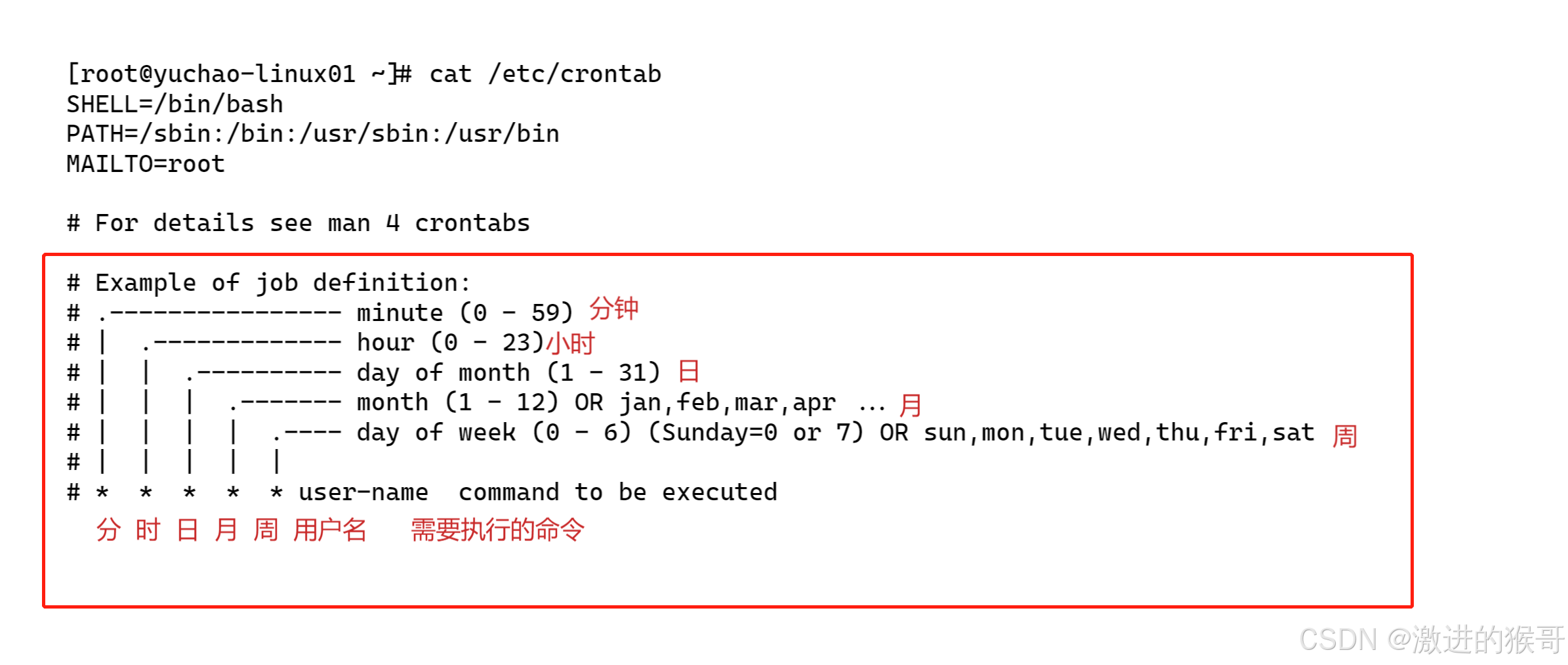
day14-16系统服务管理和ntp和防火墙
一、自有服务概述 服务是一些特定的进程,自有服务就是系统开机后就自动运行的一些进程,一旦客户发出请求,这些进程就自动为他们提供服务,windows系统中,把这些自动运行的进程,称为"服务" window…...

Hadoop、Hbase使用Snappy压缩
1. 前期准备 系统环境:centos7.9 配置信息:8C8G100G hadoop和hbase为单节点部署模式 jdk版本jdk1.8.0_361 1.1. 修改系统时间 timedatectl set-timezone <TimeZone> 1.2. 修改主机名以及主机名和IP的映射 vim /etc/hosts #将自己的主机名以及…...

【python】OpenCV—Image Moments
文章目录 1、功能描述2、图像矩3、代码实现4、效果展示5、完整代码6、涉及到的库函数cv2.moments 7、参考 1、功能描述 计算图像的矩,以质心为例 2、图像矩 什么叫图像的矩,在数字图像处理中有什么作用? - 谢博琛的回答 - 知乎 https://ww…...
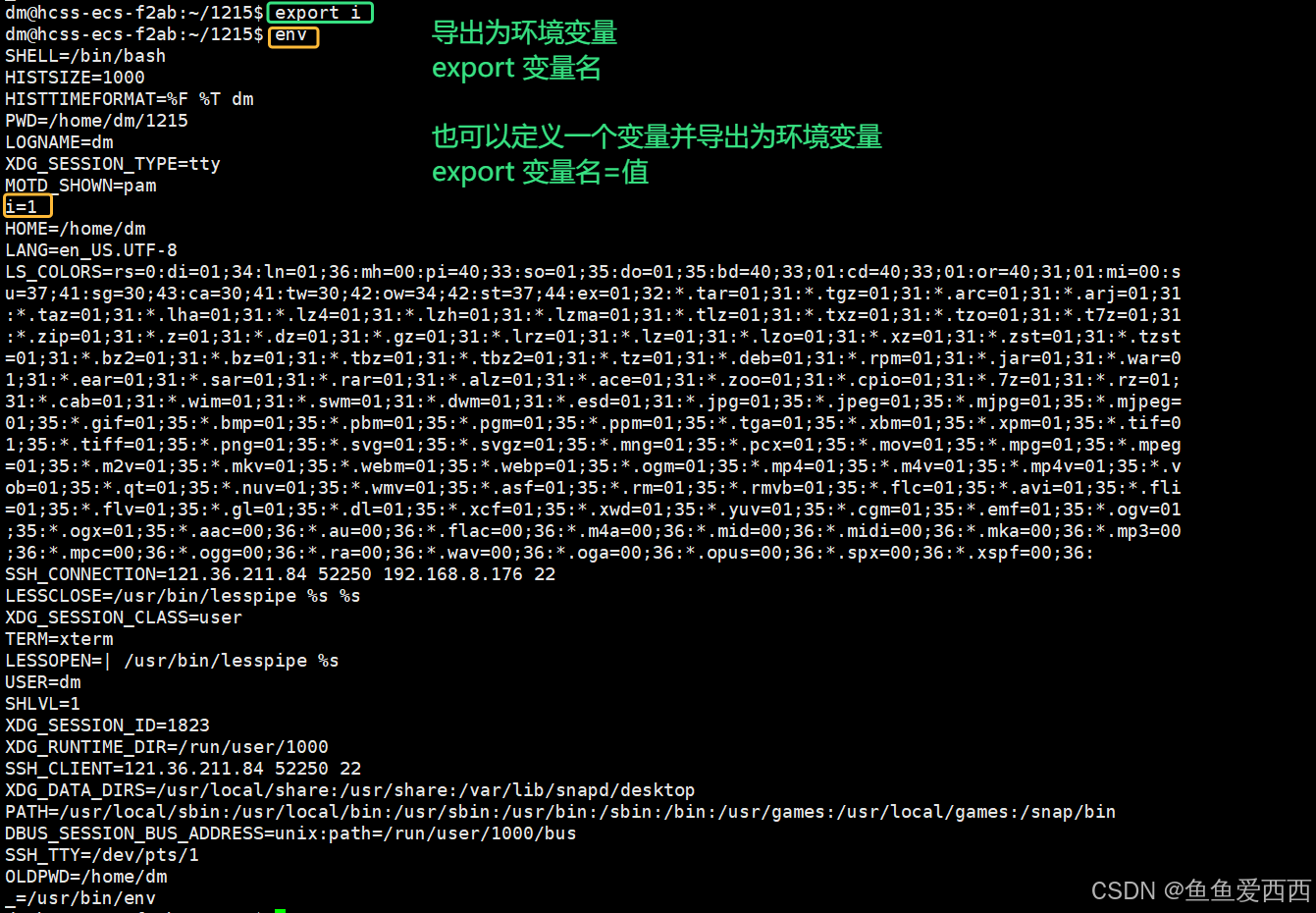
环境变量的知识
目录 1. 环境变量的概念 2. 命令行参数 2.1 2.2 创建 code.c 文件 2.3 对比 ./code 执行和直接 code 执行 2.4 怎么可以不带 ./ 2.4.1 把我们的二进制文件拷贝到 usr/bin 路径下,也不用带 ./ 了 2.4.2 把我们自己的路径添加到环境变量里 3. 认识PATH 3.…...

打破设计孤岛:用AI思维重新连接Figma与代码编辑器
打破设计孤岛:用AI思维重新连接Figma与代码编辑器 【免费下载链接】cursor-talk-to-figma-mcp TalkToFigma: MCP integration between AI Agent (Cursor, Claude Code) and Figma, allowing Agentic AI to communicate with Figma for reading designs and modifyin…...

nRF52840开发板移植CircuitPython实战:从编译到蓝牙应用
1. 项目概述与核心价值 如果你手头有一块基于 Nordic nRF52840 芯片的开发板,比如官方的 nRF52840-DK 或者 Particle 的 Argon/Xenon,并且厌倦了在 C 语言和复杂的 SDK 中挣扎,想用 Python 的简洁语法快速实现一个蓝牙传感器节点或者物联网设…...

测试RPA自动化发布-FastAPI实战
# FastAPI 简介这是一篇通过 Playwright 自动发布的测试文章。我们的代码正在测试中......

Wonder3D终极指南:如何用单张图片快速生成高质量3D模型
Wonder3D终极指南:如何用单张图片快速生成高质量3D模型 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 你是否曾梦想过将一张普通的2D图片瞬间变成生…...

基于RT-Thread与HMI-BOARD的直线推杆智能测试系统设计与实现
1. 项目概述与核心价值在工业自动化领域,直线推杆作为一种常见的执行机构,广泛应用于医疗床、升降桌、工业阀门、农业机械等设备中。一个推杆从设计图纸到批量生产,中间有一个至关重要的环节:寿命与可靠性测试。传统的测试方案&am…...
)
WinHex不只是编辑器:手把手教你用它做磁盘镜像与克隆(避坑指南)
WinHex专业磁盘镜像与克隆实战指南:从取证备份到避坑技巧 1. 为什么WinHex是磁盘操作的首选利器 在数据恢复和取证领域,专业工具的选择往往决定了工作的成败。WinHex作为一款久经考验的十六进制编辑器,其功能远超出普通用户的想象。不同于常规…...

3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具
3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk gInk屏幕画笔工具是一款专为Windows用户设计的实时…...

别再死记硬背GPIO寄存器了!用STM32 HAL库和CubeMX快速实现LED流水灯与按键控制
解放双手:用STM32CubeMX和HAL库玩转GPIO控制 在嵌入式开发的世界里,GPIO控制就像学习编程时的"Hello World"一样基础而重要。但有多少开发者还在为记忆繁琐的寄存器配置而头疼?当项目周期压缩到以天为单位计算时,我们是…...

那个号称能把安全厂商、操作系统厂商桌子都掀了的Anthropic Mythos到底是吹牛还是真牛
权力的杠杆与认知的泡沫:Anthropic Mythos 模型在网络安全领域的真实效能与战略叙事深度评估2026年4月7日,Anthropic 公司发布了名为 Claude Mythos Preview 的新型前沿模型,这一事件在人工智能与网络安全交叉领域引发了前所未有的剧烈震荡。…...
)
不止于测温:用MAX31855和K型热电偶搭建一个低成本高精度温度监控系统(附STM32源码)
从热电偶到云端:基于MAX31855的高精度温度监测系统全栈开发指南 在工业自动化、实验室监测甚至家庭酿造等场景中,温度数据的精确采集与实时监控往往成为项目成败的关键。传统温度传感器虽然简单易用,但在高温、腐蚀性环境或需要极高精度的场合…...