源码编译llama.cpp for android
源码编译llama.cpp for android
我这有已经编译好的版本,直接下载使用:
https://github.com/turingevo/llama.cpp-build/releases/tag/b4331
准备 android-ndk
已下载:
/media/wmx/ws1/software/qtAndroid/Sdk/ndk/23.1.7779620
版本 : llama.cpp-b4331
下载源码
切换到 llama.cpp/目录
编译脚本 llama.cpp/build-android.sh
#!/bin/bashANDROID_NDK_PATH=/media/wmx/ws1/software/qtAndroid/Sdk/ndk/23.1.7779620
build_dir=build-android
src_dir=.
install_dir=bin/androidcmake \-DCMAKE_TOOLCHAIN_FILE=${ANDROID_NDK_PATH}/build/cmake/android.toolchain.cmake \-DANDROID_ABI=arm64-v8a \-DANDROID_PLATFORM=android-28 \-DCMAKE_C_FLAGS="-march=armv8.7a" \-DCMAKE_CXX_FLAGS="-march=armv8.7a" \-DGGML_OPENMP=OFF \-DGGML_LLAMAFILE=OFF \-B ${build_dir} \-S ${src_dir}cmake --build ${build_dir} --config Release -j48cmake --install ${build_dir} --prefix ${install_dir} --config Release
push 到android设备测试
下面是 华为mate40pro 上的测试结果
build llama.cpp/bin/android
adb shell "mkdir /data/local/tmp/llama.cpp"
adb push bin/android /data/local/tmp/llama.cpp/
adb push qwen2.5-0.5b-instruct-q4_k_m.gguf /data/local/tmp/llama.cpp/adb shell
cd /data/local/tmp/llama.cpp/androidtouch test.sh
chmod a+x test.sh
cat " LD_LIBRARY_PATH=lib ./bin/llama-simple -m qwen2.5-0.5b-instruct-q4_k_m.gguf -p \"你是谁?\" " > test.sh./test.shHWNOH:/data/local/tmp/llama.cpp/android $ ./test.sh
llama_model_loader: loaded meta data with 26 key-value pairs and 291 tensors from /sdcard/a-wmx/models/qwen2.5-0.5b-instruct-q4_k_m.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen2
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = qwen2.5-0.5b-instruct
llama_model_loader: - kv 3: general.version str = v0.1
llama_model_loader: - kv 4: general.finetune str = qwen2.5-0.5b-instruct
llama_model_loader: - kv 5: general.size_label str = 630M
llama_model_loader: - kv 6: qwen2.block_count u32 = 24
llama_model_loader: - kv 7: qwen2.context_length u32 = 32768
llama_model_loader: - kv 8: qwen2.embedding_length u32 = 896
llama_model_loader: - kv 9: qwen2.feed_forward_length u32 = 4864
llama_model_loader: - kv 10: qwen2.attention.head_count u32 = 14
llama_model_loader: - kv 11: qwen2.attention.head_count_kv u32 = 2
llama_model_loader: - kv 12: qwen2.rope.freq_base f32 = 1000000.000000
llama_model_loader: - kv 13: qwen2.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 14: general.file_type u32 = 15
llama_model_loader: - kv 15: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 16: tokenizer.ggml.pre str = qwen2
llama_model_loader: - kv 17: tokenizer.ggml.tokens arr[str,151936] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 18: tokenizer.ggml.token_type arr[i32,151936] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 19: tokenizer.ggml.merges arr[str,151387] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
llama_model_loader: - kv 20: tokenizer.ggml.eos_token_id u32 = 151645
llama_model_loader: - kv 21: tokenizer.ggml.padding_token_id u32 = 151643
llama_model_loader: - kv 22: tokenizer.ggml.bos_token_id u32 = 151643
llama_model_loader: - kv 23: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 24: tokenizer.chat_template str = {%- if tools %}\n {{- '<|im_start|>...
llama_model_loader: - kv 25: general.quantization_version u32 = 2
llama_model_loader: - type f32: 121 tensors
llama_model_loader: - type q5_0: 133 tensors
llama_model_loader: - type q8_0: 13 tensors
llama_model_loader: - type q4_K: 12 tensors
llama_model_loader: - type q6_K: 12 tensors
llm_load_vocab: control token: 151659 '<|fim_prefix|>' is not marked as EOG
llm_load_vocab: control token: 151656 '<|video_pad|>' is not marked as EOG
llm_load_vocab: control token: 151655 '<|image_pad|>' is not marked as EOG
llm_load_vocab: control token: 151653 '<|vision_end|>' is not marked as EOG
llm_load_vocab: control token: 151652 '<|vision_start|>' is not marked as EOG
llm_load_vocab: control token: 151651 '<|quad_end|>' is not marked as EOG
llm_load_vocab: control token: 151649 '<|box_end|>' is not marked as EOG
llm_load_vocab: control token: 151648 '<|box_start|>' is not marked as EOG
llm_load_vocab: control token: 151646 '<|object_ref_start|>' is not marked as EOG
llm_load_vocab: control token: 151644 '<|im_start|>' is not marked as EOG
llm_load_vocab: control token: 151661 '<|fim_suffix|>' is not marked as EOG
llm_load_vocab: control token: 151647 '<|object_ref_end|>' is not marked as EOG
llm_load_vocab: control token: 151660 '<|fim_middle|>' is not marked as EOG
llm_load_vocab: control token: 151654 '<|vision_pad|>' is not marked as EOG
llm_load_vocab: control token: 151650 '<|quad_start|>' is not marked as EOG
llm_load_vocab: special tokens cache size = 22
llm_load_vocab: token to piece cache size = 0.9310 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = qwen2
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 151936
llm_load_print_meta: n_merges = 151387
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 32768
llm_load_print_meta: n_embd = 896
llm_load_print_meta: n_layer = 24
llm_load_print_meta: n_head = 14
llm_load_print_meta: n_head_kv = 2
llm_load_print_meta: n_rot = 64
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 64
llm_load_print_meta: n_embd_head_v = 64
llm_load_print_meta: n_gqa = 7
llm_load_print_meta: n_embd_k_gqa = 128
llm_load_print_meta: n_embd_v_gqa = 128
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 4864
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 2
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 1000000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 32768
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = 1B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 630.17 M
llm_load_print_meta: model size = 462.96 MiB (6.16 BPW)
llm_load_print_meta: general.name = qwen2.5-0.5b-instruct
llm_load_print_meta: BOS token = 151643 '<|endoftext|>'
llm_load_print_meta: EOS token = 151645 '<|im_end|>'
llm_load_print_meta: EOT token = 151645 '<|im_end|>'
llm_load_print_meta: PAD token = 151643 '<|endoftext|>'
llm_load_print_meta: LF token = 148848 'ÄĬ'
llm_load_print_meta: FIM PRE token = 151659 '<|fim_prefix|>'
llm_load_print_meta: FIM SUF token = 151661 '<|fim_suffix|>'
llm_load_print_meta: FIM MID token = 151660 '<|fim_middle|>'
llm_load_print_meta: FIM PAD token = 151662 '<|fim_pad|>'
llm_load_print_meta: FIM REP token = 151663 '<|repo_name|>'
llm_load_print_meta: FIM SEP token = 151664 '<|file_sep|>'
llm_load_print_meta: EOG token = 151643 '<|endoftext|>'
llm_load_print_meta: EOG token = 151645 '<|im_end|>'
llm_load_print_meta: EOG token = 151662 '<|fim_pad|>'
llm_load_print_meta: EOG token = 151663 '<|repo_name|>'
llm_load_print_meta: EOG token = 151664 '<|file_sep|>'
llm_load_print_meta: max token length = 256
llm_load_tensors: tensor 'token_embd.weight' (q5_0) (and 290 others) cannot be used with preferred buffer type CPU_AARCH64, using CPU instead
llm_load_tensors: CPU_Mapped model buffer size = 462.96 MiB
.....................................................
llama_new_context_with_model: n_batch is less than GGML_KQ_MASK_PAD - increasing to 32
llama_new_context_with_model: n_seq_max = 1
llama_new_context_with_model: n_ctx = 64
llama_new_context_with_model: n_ctx_per_seq = 64
llama_new_context_with_model: n_batch = 32
llama_new_context_with_model: n_ubatch = 32
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 1000000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (64) < n_ctx_train (32768) -- the full capacity of the model will not be utilized
llama_kv_cache_init: CPU KV buffer size = 0.75 MiB
llama_new_context_with_model: KV self size = 0.75 MiB, K (f16): 0.38 MiB, V (f16): 0.38 MiB
llama_new_context_with_model: CPU output buffer size = 0.58 MiB
llama_new_context_with_model: CPU compute buffer size = 18.66 MiB
llama_new_context_with_model: graph nodes = 846
llama_new_context_with_model: graph splits = 1
-p 你是谁?我是阿里云开发的超大规模语言模型,我叫通义千问。通义是“通义天下”,千问是“千问天下
main: decoded 32 tokens in 2.21 s, speed: 14.49 t/sllama_perf_sampler_print: sampling time = 5.69 ms / 32 runs ( 0.18 ms per token, 5622.91 tokens per second)
llama_perf_context_print: load time = 1907.15 ms
llama_perf_context_print: prompt eval time = 165.11 ms / 5 tokens ( 33.02 ms per token, 30.28 tokens per second)
llama_perf_context_print: eval time = 2000.08 ms / 31 runs ( 64.52 ms per token, 15.50 tokens per second)
llama_perf_context_print: total time = 3950.19 ms / 36 tokens相关文章:

源码编译llama.cpp for android
源码编译llama.cpp for android 我这有已经编译好的版本,直接下载使用: https://github.com/turingevo/llama.cpp-build/releases/tag/b4331 准备 android-ndk 已下载: /media/wmx/ws1/software/qtAndroid/Sdk/ndk/23.1.7779620版本 &am…...

StarRocks 排查单副本表
文章目录 StarRocks 排查单副本表方式1 查询元数据,检查分区级的副本数方式2 SHOW PARTITIONS命令查看 ReplicationNum修改副本数命令 StarRocks 排查单副本表 方式1 查询元数据,检查分区级的副本数 # 方式一 查询元数据,检查分区级的副本数…...

Windows11 家庭版安装配置 Docker
1. 安装WSL WSL 是什么: WSL 是一个在 Windows 上运行 Linux 环境的轻量级工具,它可以让用户在 Windows 系统中运行 Linux 工具和应用程序。Docker 为什么需要 WSL: Docker 依赖 Linux 内核功能,WSL 2 提供了一个高性能、轻量级的…...

线程知识总结(二)
本篇文章以线程同步的相关内容为主。线程的同步机制主要用来解决线程安全问题,主要方式有同步代码块、同步方法等。首先来了解何为线程安全问题。 1、线程安全问题 卖票示例,4 个窗口卖 100 张票: class Ticket implements Runnable {priv…...

解决vscode ssh远程连接服务器一直卡在下载 vscode server问题
目录 方法1:使用科学上网 方法2:手动下载 方法3 在使用vscode使用ssh远程连接服务器时,一直卡在下载"vscode 服务器"阶段,但MobaXterm可以正常连接服务器,大概率是网络问题,解决方法如下: 方…...

【Cadence射频仿真学习笔记】IC设计中电感的分析、建模与绘制(EMX电磁仿真,RFIC-GPT生成无源器件及与cadence的交互)
一、理论讲解 1. 电感设计的两个角度 电感的设计可以从两个角度考虑,一个是外部特性,一个是内部特性。外部特性就是把电感视为一个黑盒子,带有两个端子,如果带有抽头的电感就有三个端子,需要去考虑其电感值、Q值和自…...

Definition of Done
Definition of Done English Version The team agrees on, a checklist of criteria which must be met before a product increment “often a user story” is considered “done”. Failure to meet these criteria at the end of a sprint normally implies that the work …...

【漏洞复现】CVE-2023-37461 Arbitrary File Writing
漏洞信息 NVD - cve-2023-37461 Metersphere is an opensource testing framework. Files uploaded to Metersphere may define a belongType value with a relative path like ../../../../ which may cause metersphere to attempt to overwrite an existing file in the d…...

简单工厂模式和策略模式的异同
文章目录 简单工厂模式和策略模式的异同相同点:不同点:目的:结构: C 代码示例简单工厂模式示例(以创建图形对象为例)策略模式示例(以计算价格折扣策略为例)UML区别 简单工厂模式和策…...

HuggingFace datasets - 下载数据
文章目录 下载数据修改默认保存地址 TRANSFORMERS_CACHE保存到本地 & 本地加载保存加载 读取 .arrow 数据 下载数据 1、Python 代码下载 from datasets import load_dataset imdb load_dataset("imdb") # name参数为full或mini,full表示下载全部数…...
和 雅各比矩阵(Jacobian Matrix)的区别和联系:中英双语)
梯度(Gradient)和 雅各比矩阵(Jacobian Matrix)的区别和联系:中英双语
雅各比矩阵与梯度:区别与联系 在数学与机器学习中,梯度(Gradient) 和 雅各比矩阵(Jacobian Matrix) 是两个核心概念。虽然它们都描述了函数的变化率,但应用场景和具体形式有所不同。本文将通过…...

Vscode搭建C语言多文件开发环境
一、文章内容简介 本文介绍了 “Vscode搭建C语言多文件开发环境”需要用到的软件,以及vscode必备插件,最后多文件编译时tasks.json文件和launch.json文件的配置。即目录顺序。由于内容较多,建议大家在阅读时使用电脑阅读,按照目录…...

自定义 C++ 编译器的调用与管理
在 C 项目中,常常需要自动化地管理编译流程,例如使用 MinGW 或 Visual Studio 编译器进行代码的编译和链接。为了方便管理不同编译器和简化编译流程,我们开发了一个 CompilerManager 类,用于抽象编译器的查找、命令生成以及执行。…...
时间管理系统|Java|SSM|JSP|
【技术栈】 1⃣️:架构: B/S、MVC 2⃣️:系统环境:Windowsh/Mac 3⃣️:开发环境:IDEA、JDK1.8、Maven、Mysql5.7 4⃣️:技术栈:Java、Mysql、SSM、Mybatis-Plus、JSP、jquery,html 5⃣️数据库可…...

用SparkSQL和PySpark完成按时间字段顺序将字符串字段中的值组合在一起分组显示
用SparkSQL和PySpark完成以下数据转换。 源数据: userid,page_name,visit_time 1,A,2021-2-1 2,B,2024-1-1 1,C,2020-5-4 2,D,2028-9-1 目的数据: user_id,page_name_path 1,C->A 2,B->D PySpark: from pyspark.sql import SparkSes…...
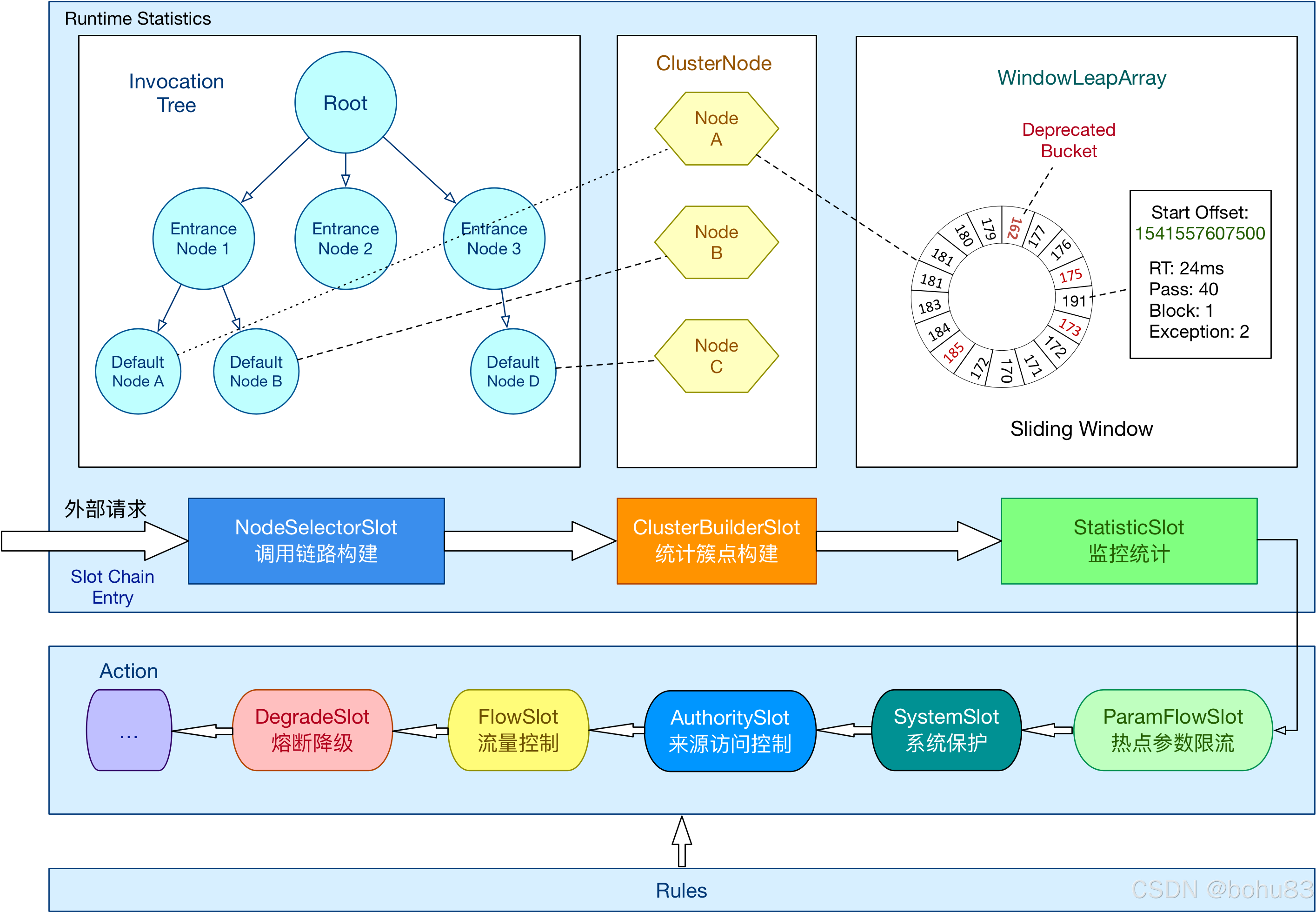
Sentinel 学习笔记3-责任链与工作流程
本文属于sentinel学习笔记系列。网上看到吴就业老师的专栏,原文地址如下: https://blog.csdn.net/baidu_28523317/category_10400605.html 上一篇梳理了概念与核心类:Sentinel 学习笔记2- 概念与核心类介绍-CSDN博客 补一个点:…...

Latex 转换为 Word(使用GrindEQ )(英文转中文,毕业论文)
效果预览 第一步: 告诉chatgpt: 将latex格式中的英文翻译为中文(符号和公式不要动),给出latex格式第二步: Latex 转换为 Word(使用GrindEQ ) 视频 https://www.bilibili.com/video/BV1f242…...

使用Chat-LangChain模块创建一个与用户交流的机器人
当然!要使用Chat-LangChain模块创建一个与用户交流的机器人,你需要安装并配置一些Python库。以下是一个基本的步骤指南和示例代码,帮助你快速上手。 安装依赖库 首先,你需要安装langchain库,它是一个高级框架&#x…...

国家认可的人工智能从业人员证书如何报考?
一、证书出台背景 为进一步贯彻落实中共中央印发《关于深化人才发展体制机制改革的意见》和国务院印发《关于“十四五”数字经济发展规划》等有关工作的部署要求,深入实施人才强国战略和创新驱动发展战略,加强全国数字化人才队伍建设,持续推…...

【网络云计算】2024第51周-每日【2024/12/17】小测-理论-解析
文章目录 1. 计算机网络有哪些分类2. 计算机网络中协议与标准的区别3. 计算机网络拓扑有哪些结构4. 常用的网络设备有哪些,分属于OSI的哪一层5. IEEE802局域网标准有哪些 【网络云计算】2024第51周-每日【2024/12/17】小测-理论-解析 1. 计算机网络有哪些分类 计算…...

告别 API 收费!OpenClaw 对接 Ollama,本地大模型免费无限用
OpenClaw 连接 Ollama 本地模型教程 前置准备 已安装并能正常打开 OpenClaw Windows 客户端OpenClaw 顶部 Gateway 状态保持在线电脑可正常联网,能访问 Ollama 官网磁盘空间充足(本地模型占用空间较大)提前确认待下载的模型名称(…...

别再一股脑塞Prompt了!Claude/GPT-3.5-Turbo-16k实测:关键信息放开头还是结尾?
大模型长文本处理实战:关键信息位置对生成效果的影响机制与优化策略 当开发者面对Claude、GPT-3.5-Turbo-16k这类支持长上下文的大语言模型时,常陷入一个典型困境:明明已将全部资料塞入上下文窗口,模型却依然遗漏关键信息或给出偏…...

如何永久激活IDM?2024终极免费激活与试用重置完全指南
如何永久激活IDM?2024终极免费激活与试用重置完全指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script IDM Activation Script是一款专为Internet Dow…...

终极指南:如何用TrafficMonitor股票插件打造桌面投资监控中心
终极指南:如何用TrafficMonitor股票插件打造桌面投资监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为错过重要股票行情而烦恼吗?想在工作时…...

US Visa Bot:开源智能预约解决方案,告别签证等待焦虑
US Visa Bot:开源智能预约解决方案,告别签证等待焦虑 【免费下载链接】us-visa-bot US Visa Bot 项目地址: https://gitcode.com/gh_mirrors/us/us-visa-bot 您是否曾经为了一个美国签证面试日期而反复刷新页面,却总是错过最佳时机&am…...

不用命令行!OpenClaw 2.7.5 Win11 专属部署,双击直达本地 AI 助手
前言 本教程专为Windows用户设计,提供可视化部署方案。通过专用部署包实现全程图形化操作,彻底告别命令行和手动配置环境。即使是零基础用户也能轻松完成部署,快速搭建专属数字员工系统,显著提升工作效率。教程完美适配Windows 1…...

UV-UI终极指南:如何在30分钟内构建跨平台应用
UV-UI终极指南:如何在30分钟内构建跨平台应用 【免费下载链接】uv-ui uv-ui 破釜沉舟之兼容vue32、app、h5、小程序等多端基于uni-app和uView2.x的生态框架,支持单独导入,开箱即用,利剑出击。 项目地址: https://gitcode.com/gh…...

长期使用Taotoken Token Plan套餐在项目开发中的成本优势体会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐在项目开发中的成本优势体会 在项目开发中,尤其是涉及大模型API调用的场景࿰…...

【蒸汽波风格工业化生产标准】:基于1372张MJ出图数据建模,定义饱和度/噪点/复古失真三维黄金阈值
更多请点击: https://kaifayun.com 第一章:蒸汽波美学的数字解构与范式迁移 蒸汽波(Vaporwave)并非仅是一种视觉风格或音乐流派,而是一场对晚期资本主义数字界面的戏仿性考古——它通过降速采样、CRT扫描线模拟、80年…...

英雄联盟Akari助手:一键智能配置,释放你的游戏潜能 [特殊字符]
英雄联盟Akari助手:一键智能配置,释放你的游戏潜能 🚀 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在…...