HuggingFace datasets - 下载数据
文章目录
- 下载数据
- 修改默认保存地址 TRANSFORMERS_CACHE
- 保存到本地 & 本地加载
- 保存
- 加载
- 读取 `.arrow` 数据
下载数据
1、Python 代码下载
from datasets import load_dataset
imdb = load_dataset("imdb")
# name参数为full或mini,full表示下载全部数据,mini表示下载部分少量数据
# dataset = load_dataset(model_name, name="full")
imdb
'''
DatasetDict({train: Dataset({features: ['text', 'label'],num_rows: 25000})test: Dataset({features: ['text', 'label'],num_rows: 25000})unsupervised: Dataset({features: ['text', 'label'],num_rows: 50000})
})
'''
默认保存在 ~/.cache/huggingface 文件夹
数据格式如下:
$ cd datasets/imdb/
$ tree
.
└── plain_text└── 0.0.0├── e6281661ce1c48d982bc483cf8a173c1bbeb5d31│ ├── dataset_info.json│ ├── imdb-test.arrow│ ├── imdb-train.arrow│ └── imdb-unsupervised.arrow├── e6281661ce1c48d982bc483cf8a173c1bbeb5d31.incomplete_info.lock└── e6281661ce1c48d982bc483cf8a173c1bbeb5d31_builder.lock3 directories, 6 files
2、huggingface-cli 命令下载
这样下载也会保存到 ~/.cache/huggingface 文件夹
huggingface-cli download --repo-type dataset imdb
3、git

修改默认保存地址 TRANSFORMERS_CACHE
环境变量添加
export TRANSFORMERS_CACHE='path/'
代码中使用
import os
os.environ['TRANSFORMERS_CACHE']=''
保存到本地 & 本地加载
保存
save_path = '/Users/xx/Downloads/imdb'
imdb.save_to_disk(save_path)
'''
Saving the dataset (1/1 shards): 100%|█| 25000/25000 [00:00<00:00, 97903.42 exam
Saving the dataset (1/1 shards): 100%|█| 25000/25000 [00:00<00:00, 251032.07 exa
Saving the dataset (1/1 shards): 100%|█| 50000/50000 [00:00<00:00, 88591.53 exam
'''imdb2 = load_from_disk(save_path)
imdb2
'''
DatasetDict({train: Dataset({features: ['text', 'label'],num_rows: 25000})test: Dataset({features: ['text', 'label'],num_rows: 25000})unsupervised: Dataset({features: ['text', 'label'],num_rows: 50000})
})
'''
存储格式如下:
$ cd imdb/
$ tree
.
├── dataset_dict.json
├── test
│ ├── data-00000-of-00001.arrow
│ ├── dataset_info.json
│ └── state.json
├── train
│ ├── data-00000-of-00001.arrow
│ ├── dataset_info.json
│ └── state.json
└── unsupervised├── data-00000-of-00001.arrow├── dataset_info.json└── state.json3 directories, 10 files
加载
# 指定加载测试集
save_path1 = '/Users/xx/Downloads/imdb/test'
imdb3 = load_from_disk(save_path1)
imdb3
'''
Dataset({features: ['text', 'label'],num_rows: 25000
})
'''imdb4 = load_dataset('imdb') # 默认加载 `.cache` 中的数据 imdb4 = load_dataset(path='/Users/xx/Downloads/imdb')
'''
Generating train split: 1 examples [00:00, 69.32 examples/s]
Generating test split: 1 examples [00:00, 277.31 examples/s]
'''
imdb4
'''
DatasetDict({train: Dataset({features: ['_data_files', '_fingerprint', '_format_columns', '_format_kwargs', '_format_type', '_output_all_columns', '_split'],num_rows: 1})test: Dataset({features: ['_data_files', '_fingerprint', '_format_columns', '_format_kwargs', '_format_type', '_output_all_columns', '_split'],num_rows: 1})
})
'''# 指定加载文件 - 失败
save_path2 = '/Users/xx/Downloads/imdb/test/data-00000-of-00001.arrow'
imdb4 = load_from_disk(save_path2)
'''
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "/Users/xx/miniconda3/lib/python3.11/site-packages/datasets/load.py", line 2215, in load_from_diskraise FileNotFoundError(
FileNotFoundError: Directory /Users/xx/Downloads/imdb/test/data-00000-of-00001.arrow is neither a `Dataset` directory nor a `DatasetDict` directory.
'''
无法从 .cache/huggingface/datasets 加载
path = '/Users/xx/.cache/huggingface/datasets/imdb'
from datasets import load_from_diskimdb2 = load_from_disk(path)
'''
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "/Users/xx/miniconda3/lib/python3.11/site-packages/datasets/load.py", line 2215, in load_from_diskraise FileNotFoundError(
FileNotFoundError: Directory /Users/xx/.cache/huggingface/datasets/imdb is neither a `Dataset` directory nor a `DatasetDict` directory.
'''path1 = '/Users/xx/.cache/huggingface/datasets/imdb/plain_text/0.0.0/e6281661ce1c48d982bc483cf8a173c1bbeb5d31/imdb-test.arrow' imdb2 = load_from_disk(path1)
'''
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "/Users/xx/miniconda3/lib/python3.11/site-packages/datasets/load.py", line 2215, in load_from_diskraise FileNotFoundError(
FileNotFoundError: Directory /Users/xx/.cache/huggingface/datasets/imdb/plain_text/0.0.0/e6281661ce1c48d982bc483cf8a173c1bbeb5d31/imdb-test.arrow is neither a `Dataset` directory nor a `DatasetDict` directory.
'''path1 = '/Users/xx/.cache/huggingface/datasets/imdb/plain_text/0.0.0/e6281661ce1c48d982bc483cf8a173c1bbeb5d31/'
imdb2 = load_from_disk(path1)
'''
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "/Users/xx/miniconda3/lib/python3.11/site-packages/datasets/load.py", line 2215, in load_from_diskraise FileNotFoundError(
FileNotFoundError: Directory /Users/xx/.cache/huggingface/datasets/imdb/plain_text/0.0.0/e6281661ce1c48d982bc483cf8a173c1bbeb5d31/ is neither a `Dataset` directory nor a `DatasetDict` directory.
'''path1 = '/Users/xx/.cache/huggingface/datasets/imdb/plain_text/0.0.0/' imdb2 = load_from_disk(path1)
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "/Users/xx/miniconda3/lib/python3.11/site-packages/datasets/load.py", line 2215, in load_from_diskraise FileNotFoundError(
FileNotFoundError: Directory /Users/xx/.cache/huggingface/datasets/imdb/plain_text/0.0.0/ is neither a `Dataset` directory nor a `DatasetDict` directory.path1 = '/Users/xx/.cache/huggingface/datasets/imdb/plain_text/'
imdb2 = load_from_disk(path1)
'''
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "/Users/xx/miniconda3/lib/python3.11/site-packages/datasets/load.py", line 2215, in load_from_diskraise FileNotFoundError(
FileNotFoundError: Directory /Users/xx/.cache/huggingface/datasets/imdb/plain_text/ is neither a `Dataset` directory nor a `DatasetDict` directory.
'''
读取 .arrow 数据
双击 .arrow 文件无法直接查看,使用下面代码可以查看内容
def read_arrow_to_df_julia_ok(path):with open(path, "rb") as f:r = pyarrow.ipc.RecordBatchStreamReader(f)df = r.read_pandas()return dfpath = '/Users/xx/Downloads/imdb/test/data-00000-of-00001.arrow'
path = '/Users/xx/.cache/huggingface/datasets/imdb/plain_text/0.0.0/e6281661ce1c48d982bc483cf8a173c1bbeb5d31/imdb-test.arrow'
table = read_arrow_to_df_julia_ok(path)
# 打印数据
print('打印数据:\n', table)结果
打印数据:text label
0 I love sci-fi and am willing to put up with a ... 0
1 Worth the entertainment value of a rental, esp... 0
2 its a totally average film with a few semi-alr... 0
3 STAR RATING: ***** Saturday Night **** Friday ... 0
4 First off let me say, If you haven't enjoyed a... 0
... ... ...
24995 Just got around to seeing Monster Man yesterda... 1
24996 I got this as part of a competition prize. I w... 1
24997 I got Monster Man in a box set of three films ... 1
24998 Five minutes in, i started to feel how naff th... 1
24999 I caught this movie on the Sci-Fi channel rece... 1
相关文章:
HuggingFace datasets - 下载数据
文章目录 下载数据修改默认保存地址 TRANSFORMERS_CACHE保存到本地 & 本地加载保存加载 读取 .arrow 数据 下载数据 1、Python 代码下载 from datasets import load_dataset imdb load_dataset("imdb") # name参数为full或mini,full表示下载全部数…...
和 雅各比矩阵(Jacobian Matrix)的区别和联系:中英双语)
梯度(Gradient)和 雅各比矩阵(Jacobian Matrix)的区别和联系:中英双语
雅各比矩阵与梯度:区别与联系 在数学与机器学习中,梯度(Gradient) 和 雅各比矩阵(Jacobian Matrix) 是两个核心概念。虽然它们都描述了函数的变化率,但应用场景和具体形式有所不同。本文将通过…...

Vscode搭建C语言多文件开发环境
一、文章内容简介 本文介绍了 “Vscode搭建C语言多文件开发环境”需要用到的软件,以及vscode必备插件,最后多文件编译时tasks.json文件和launch.json文件的配置。即目录顺序。由于内容较多,建议大家在阅读时使用电脑阅读,按照目录…...

自定义 C++ 编译器的调用与管理
在 C 项目中,常常需要自动化地管理编译流程,例如使用 MinGW 或 Visual Studio 编译器进行代码的编译和链接。为了方便管理不同编译器和简化编译流程,我们开发了一个 CompilerManager 类,用于抽象编译器的查找、命令生成以及执行。…...
时间管理系统|Java|SSM|JSP|
【技术栈】 1⃣️:架构: B/S、MVC 2⃣️:系统环境:Windowsh/Mac 3⃣️:开发环境:IDEA、JDK1.8、Maven、Mysql5.7 4⃣️:技术栈:Java、Mysql、SSM、Mybatis-Plus、JSP、jquery,html 5⃣️数据库可…...

用SparkSQL和PySpark完成按时间字段顺序将字符串字段中的值组合在一起分组显示
用SparkSQL和PySpark完成以下数据转换。 源数据: userid,page_name,visit_time 1,A,2021-2-1 2,B,2024-1-1 1,C,2020-5-4 2,D,2028-9-1 目的数据: user_id,page_name_path 1,C->A 2,B->D PySpark: from pyspark.sql import SparkSes…...
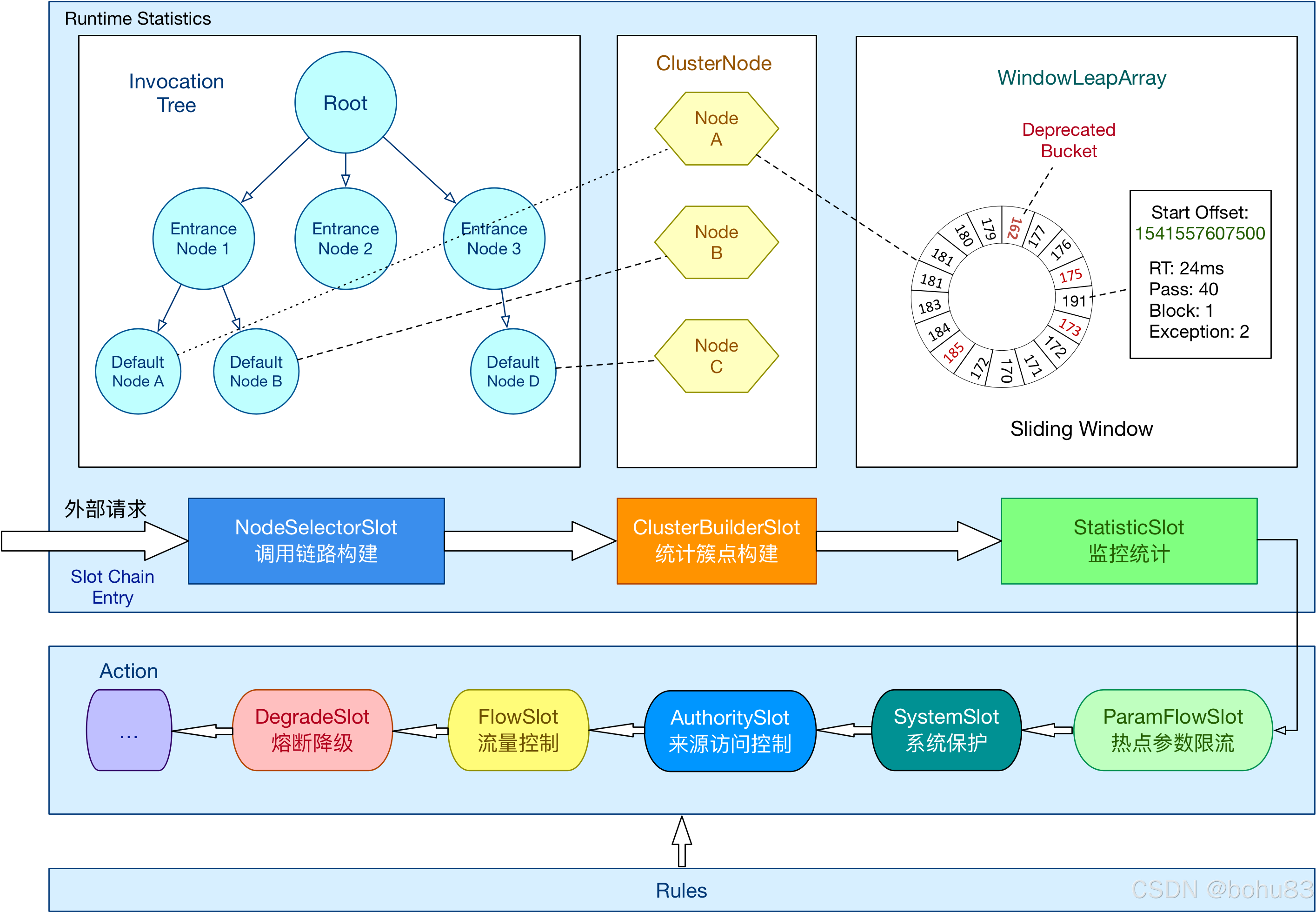
Sentinel 学习笔记3-责任链与工作流程
本文属于sentinel学习笔记系列。网上看到吴就业老师的专栏,原文地址如下: https://blog.csdn.net/baidu_28523317/category_10400605.html 上一篇梳理了概念与核心类:Sentinel 学习笔记2- 概念与核心类介绍-CSDN博客 补一个点:…...

Latex 转换为 Word(使用GrindEQ )(英文转中文,毕业论文)
效果预览 第一步: 告诉chatgpt: 将latex格式中的英文翻译为中文(符号和公式不要动),给出latex格式第二步: Latex 转换为 Word(使用GrindEQ ) 视频 https://www.bilibili.com/video/BV1f242…...

使用Chat-LangChain模块创建一个与用户交流的机器人
当然!要使用Chat-LangChain模块创建一个与用户交流的机器人,你需要安装并配置一些Python库。以下是一个基本的步骤指南和示例代码,帮助你快速上手。 安装依赖库 首先,你需要安装langchain库,它是一个高级框架&#x…...

国家认可的人工智能从业人员证书如何报考?
一、证书出台背景 为进一步贯彻落实中共中央印发《关于深化人才发展体制机制改革的意见》和国务院印发《关于“十四五”数字经济发展规划》等有关工作的部署要求,深入实施人才强国战略和创新驱动发展战略,加强全国数字化人才队伍建设,持续推…...

【网络云计算】2024第51周-每日【2024/12/17】小测-理论-解析
文章目录 1. 计算机网络有哪些分类2. 计算机网络中协议与标准的区别3. 计算机网络拓扑有哪些结构4. 常用的网络设备有哪些,分属于OSI的哪一层5. IEEE802局域网标准有哪些 【网络云计算】2024第51周-每日【2024/12/17】小测-理论-解析 1. 计算机网络有哪些分类 计算…...
每日十题八股-2024年12月19日
1.Bean注入和xml注入最终得到了相同的效果,它们在底层是怎样做的? 2.Spring给我们提供了很多扩展点,这些有了解吗? 3.MVC分层介绍一下? 4.了解SpringMVC的处理流程吗? 5.Handlermapping 和 handleradapter有…...
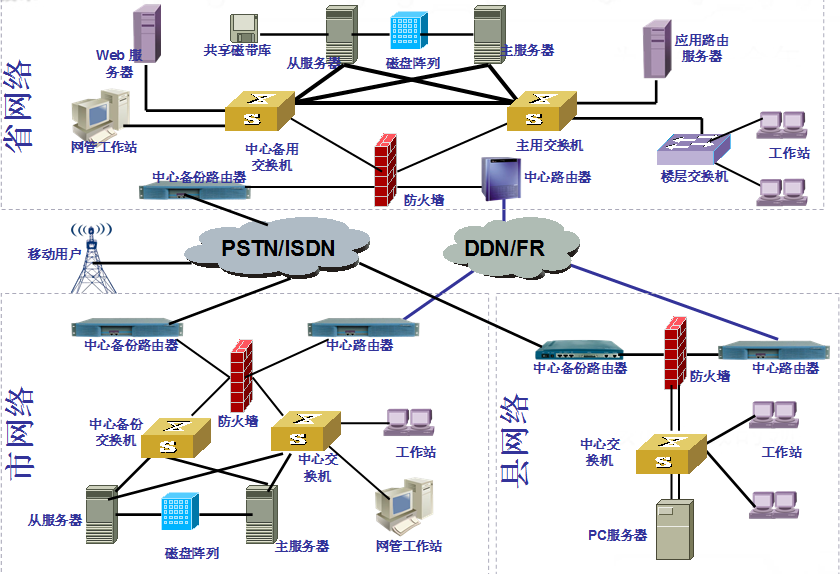
网络方案设计
一、网络方案设计目标 企业网络系统的构成 应用软件 计算平台 物理网络及拓扑结构 网络软件及工具软件 网络互连设备 广域网连接 无论是复杂的,还是简单的计算机网络,都包括了以下几个基本元素 : 应用软件----支持用户完成专门操作的软件。…...

学习记录:electron主进程与渲染进程直接的通信示例【开箱即用】
electron主进程与渲染进程直接的通信示例 1. 背景: electronvue实现桌面应用开发 2.异步模式 2.1使用.send 和.on的方式 preload.js中代码示例: const { contextBridge, ipcRenderer} require(electron);// 暴露通信接口 contextBridge.exposeInMa…...

【Java数据结构】ArrayList类
List接口 List是一个接口,它继承Collection接口,Collection接口中的一些常用方法 List也有一些常用的方法。List是一个接口,它并不能直接实例化,ArrayList和LinkedList都实现了List接口,它们的常用方法都很相似。 Ar…...
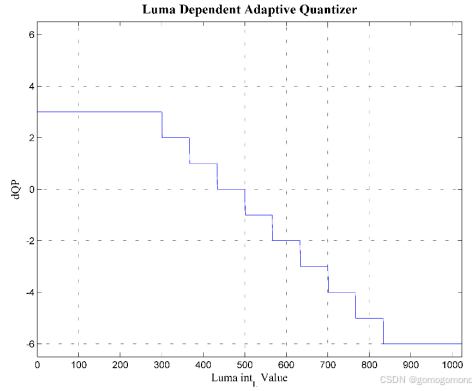
HDR视频技术之十:MPEG 及 VCEG 的 HDR 编码优化
与传统标准动态范围( SDR)视频相比,高动态范围( HDR)视频由于比特深度的增加提供了更加丰富的亮区细节和暗区细节。最新的显示技术通过清晰地再现 HDR 视频内容使得为用户提供身临其境的观看体验成为可能。面对目前日益…...
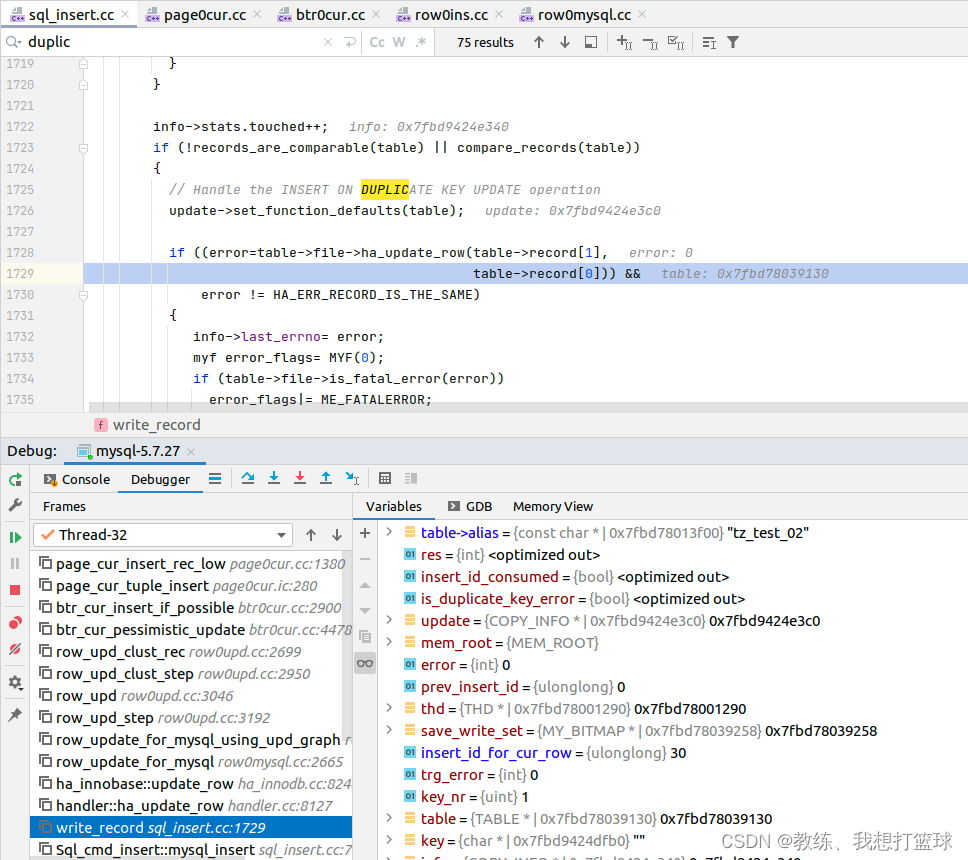
71 mysql 中 insert into ... on duplicate key update ... 的实现
前言 这个也是我们经常可能会使用到的相关的特殊语句 当插入数据存在 唯一索引 或者 主键索引 相关约束的时候, 如果存在 约束冲突, 则更新目标记录 这个处理是类似于 逻辑上的 save 操作 insert into tz_test_02 (field1, field2) values (field11, 11) on duplicate …...
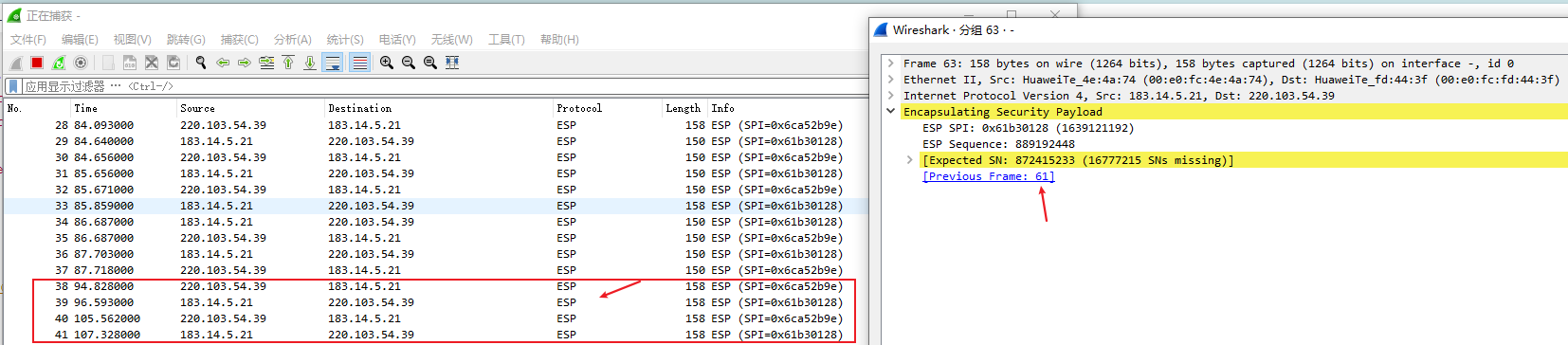
计算机网络-GRE Over IPSec实验
一、概述 前情回顾:上次基于IPsec VPN的主模式进行了基础实验,但是很多高级特性没有涉及,如ike v2、不同传输模式、DPD检测、路由方式引入路由、野蛮模式等等,以后继续学习吧。 前面我们已经学习了GRE可以基于隧道口实现分支互联&…...
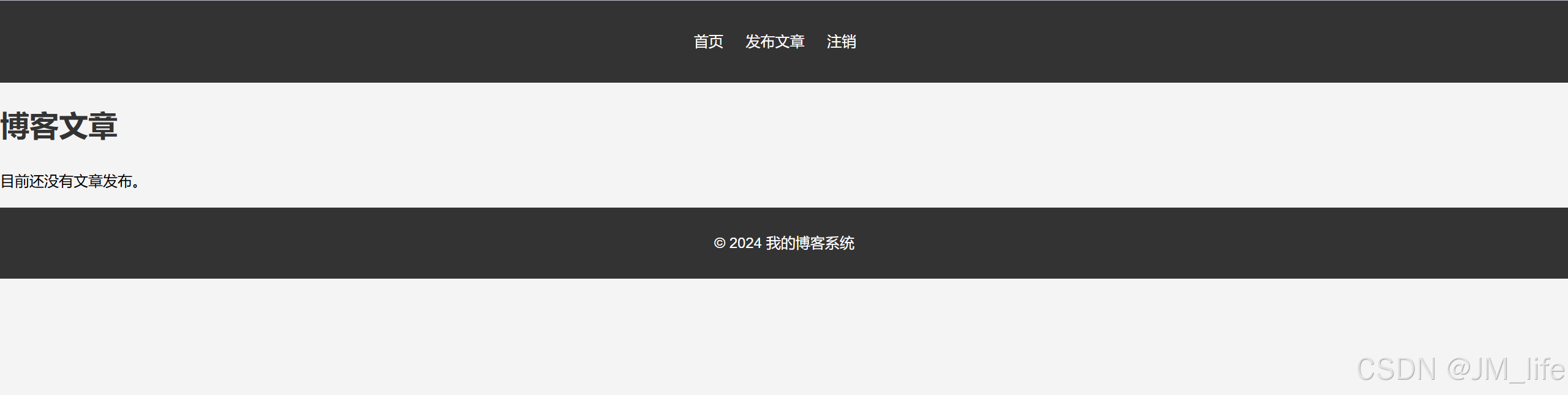
你的第一个博客-第一弹
使用 Flask 开发博客 Flask 是一个轻量级的 Web 框架,适合小型应用和学习项目。我们将通过 Flask 开发一个简单的博客系统,支持用户注册、登录、发布文章等功能。 步骤: 安装 Flask 和其他必要库: 在开发博客之前,首…...

若依启动项目时配置为 HTTPS 协议
文章目录 1、需求提出2、应用场景3、解决思路4、注意事项5、完整代码第一步:修改 vue.config.js 文件第二步:运行项目第三步:处理浏览器警告 6、运行结果 1、需求提出 在开发本地项目时,默认启动使用的是 HTTP 协议。但在某些测试…...

别再手动画图了!WPS PPT里这个‘转智能图形’功能,3秒让文字变高级图示
WPS PPT智能图形进阶指南:3秒实现专业级视觉表达 在快节奏的职场环境中,演示文档的视觉呈现往往决定着信息传递的效率。传统PPT制作中,将文字列表转换为可视化图形需要经历形状绘制、文字排版、配色调整等多道工序,耗时且难以保证…...

告别踩坑!手把手教你用Cobalt Strike 4.7在Kali Linux上快速搭建团队服务器并上线第一台主机
Kali Linux环境下Cobalt Strike 4.7团队服务器部署与主机上线实战指南 在渗透测试和红队演练中,Cobalt Strike作为一款成熟的商业框架,其团队协作功能和丰富的攻击模拟能力备受安全从业者青睐。本文将基于Kali Linux系统,详细解析Cobalt Stri…...

对比直接使用官方 API,Taotoken 在计费透明性上的优势体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API,Taotoken 在计费透明性上的优势体验 对于需要调用多种大语言模型的开发者而言,成本控…...

Deskreen:如何将任何浏览器设备变成你的第二屏幕?
Deskreen:如何将任何浏览器设备变成你的第二屏幕? 【免费下载链接】deskreen Deskreen turns any device with a web browser into a secondary screen for your computer. ⭐️ Star to support our work! 项目地址: https://gitcode.com/gh_mirrors/…...

dvcs-ripper快速入门:5分钟掌握Git仓库提取技巧 [特殊字符]
dvcs-ripper快速入门:5分钟掌握Git仓库提取技巧 🚀 【免费下载链接】dvcs-ripper Rip web accessible (distributed) version control systems: SVN/GIT/HG... 项目地址: https://gitcode.com/gh_mirrors/dv/dvcs-ripper dvcs-ripper 是一个强大的…...

使用Taotoken后我的API调用延迟与用量清晰可见
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后我的API调用延迟与用量清晰可见 作为一名频繁调用各类大语言模型的独立开发者,管理多个API密钥、追踪不…...

终极指南:如何使用IDM激活脚本实现永久免费下载体验
终极指南:如何使用IDM激活脚本实现永久免费下载体验 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Download Manager(IDM&…...
)
Midjourney构图进阶实战指南(98%用户从未调过的--sref与--style参数协同逻辑大揭秘)
更多请点击: https://intelliparadigm.com 第一章:Midjourney构图进阶实战指南(98%用户从未调过的--sref与--style参数协同逻辑大揭秘) 在Midjourney V6中, --sref(Style Reference)与 --style…...
)
别再让ROS2节点间通信拖慢你的机器人:手把手配置Fast DDS共享内存传输(附XML配置文件)
ROS2高性能通信实战:Fast DDS共享内存传输深度优化指南 当机器人系统需要处理高频率的激光雷达点云或4K摄像头图像时,传统网络传输方式可能成为性能瓶颈。我曾在一个工业分拣机器人项目中发现,仅图像传输就占用了30%的CPU资源,这促…...

你的旋钮漂移吗?EC11编码器在51单片机上的硬件消抖与软件滤波实战避坑指南
EC11编码器实战:从硬件消抖到软件滤波的稳定性优化全攻略 在嵌入式控制领域,旋转编码器作为人机交互的重要组件,其稳定性直接影响用户体验。EC11作为经济实用的机械编码器代表,广泛应用于音量调节、参数设置等场景。但当电机干扰、…...