【NLP 18、新词发现和TF·IDF】
目录
一、新词发现
1.新词发现的衡量标准
① 内部稳固
② 外部多变
2.示例
① 初始化类 NewWordDetect
② 加载语料信息,并进行统计
③ 统计指定长度的词频及其左右邻居字符词频
④ 计算熵
⑤ 计算左右熵
编辑
⑥ 统计词长总数
⑦ 计算互信息
⑧ 计算每个词的价值
⑨ 新词检测
编辑
二、挑选重要词
1.数学角度刻画重要词
例:
编辑
TF·IDF其他计算方式
2.算法特点
3.算法示例
① 构建TF·IDF字典
② 根据tf值和idf值计算tf·idf
③ 计算给定语料库中每个文档的TF-IDF值
④ 提取每个文本的前top个高频词
⑤ tf·idf的计算和使用
4.TF·IDF应用 —— 搜索引擎
① 对于已有的所有网页(文本),计算每个网页中,词的TF·IDF值
② 对于一个输入query(查询)进行分词
③ TF·IDF实现简单搜索引擎
5.TF·IDF应用 —— 文本摘要
① 加载文档数据,并计算每个文档的TF·IDF值
② 计算生成每一篇文章的摘要
③ 生成文档摘要,并将摘要添加到原始文档中
④ TF·IDF实现简单文本摘要
6.TF·IDF应用 —— 文本相似度计算
① 加载文档数据并计算TF-IDF值
② 将文章转换为向量
③ 文档转换为向量表示
④ 计算两个向量间的余弦相似度
⑤ 计算输入文本与语料库所有文档的相似度
⑥ TF·IDF实现文本相似度计算
7.TF·IDF的优势
① 可解释性好
② 计算速度快
③ 对标注数据依赖小
④ 可以与很多算法组合使用
8.TF·IDF的劣势
① 受分词效果影响大
② 词与词之间没有语义相似度
③ 没有语序信息
④ 能力范围有限
⑤ 样本不均衡会对结果有很大影响
⑥ 类内样本间分布不被考虑
死亡不是生命的终点,被遗忘才是
—— 24.12.21
一、新词发现
词相当于一种固定搭配
1.新词发现的衡量标准
① 内部稳固
词的内部应该是稳固的,用内部稳固度衡量
内部稳固度:词语中几个字的固定搭配出现的次数除以词语中每个字单独出现的概率的乘积
公式:
② 外部多变
词的外部应该是多变的,用左右熵衡量
左右熵: 将词语外部出现的所有字再除以出现的总词频数,得到出现某个字的频率pi,代入公式进行求和后取反,得到词语两边的左右熵,词语的外部两侧出现一个固定字的频率应该较低,换句话说,词的外部应该是多变的,而不是固定的,左右熵的值大小可以衡量词的外部值是否多变,左右熵的值越大,词的外部越多变
用两个指标计算分数,根据分数衡量一些文字组合是否是新词
公式:
2.示例

① 初始化类 NewWordDetect
Ⅰ 初始化参数:
设置词语最高长度为5个字符
初始化三个字典:word_count 统计词频,left_neighbor 和 right_neighbor 分别记录每个词的左邻词和右邻词
Ⅱ 加载语料库:调用 load_corpus 方法加载语料库数据
Ⅲ 计算指标:计算互信息(PMI),熵,以及词的价值
class NewWordDetect:def __init__(self, corpus_path):# 设置词语最高长度 1 - 5 四个字的词语self.max_word_length = 5self.word_count = defaultdict(int)self.left_neighbor = defaultdict(dict)self.right_neighbor = defaultdict(dict)self.load_corpus(corpus_path)self.calc_pmi()self.calc_entropy()self.calc_word_values()② 加载语料信息,并进行统计

Ⅰ 打开文件:打开并读取指定路径的文件,编码为UTF-8
Ⅱ 处理文件:对文件中的每一行进行处理,去除首尾空白字符
Ⅲ 句子统计:对每个句子按不同长度(从1到self.max_word_length)进行n-gram统计
Ⅳ 计数操作:调用self.ngram_count方法进行具体的n-gram计数操作
#加载语料数据,并进行统计def load_corpus(self, path):with open(path, encoding="utf8") as f:for line in f:sentence = line.strip()for word_length in range(1, self.max_word_length):self.ngram_count(sentence, word_length)return
③ 统计指定长度的词频及其左右邻居字符词频
Ⅰ 遍历句子:通过循环遍历句子中的每个位置,提取长度为word_length的子串
Ⅱ 统计词频:将提取的子串作为键,更新其在self.word_count字典中的计数
Ⅲ 统计左邻居字符:如果当前子串有左邻居字符,则更新self.left_neighbor字典中该子串对应左邻居字符的计数
Ⅳ 统计右邻居字符:如果当前子串有右邻居字符,则更新self.right_neighbor字典中该子串对应右邻居字符的计数
#按照窗口长度取词,并记录左邻右邻出现过的字及次数def ngram_count(self, sentence, word_length):for i in range(len(sentence) - word_length + 1):word = sentence[i:i + word_length]self.word_count[word] += 1if i - 1 >= 0:char = sentence[i - 1]self.left_neighbor[word][char] = self.left_neighbor[word].get(char, 0) + 1if i + word_length < len(sentence):char = sentence[i +word_length]self.right_neighbor[word][char] = self.right_neighbor[word].get(char, 0) + 1return
④ 计算熵

sum():通过 sum(word_count_dict.values()) 计算所有单词的总出现次数
计算熵:遍历每个单词的出现次数,使用公式 -(c / total) * math.log((c / total), 10) 计算每个单词对熵的贡献,并累加这些值
返回熵值:将计算得到的熵值返回
#计算熵def calc_entropy_by_word_count_dict(self, word_count_dict):total = sum(word_count_dict.values())entropy = sum([-(c / total) * math.log((c / total), 10) for c in word_count_dict.values()])return entropy⑤ 计算左右熵

Ⅰ 初始化空字典:初始化两个空字典 self.word_left_entropy 和 self.word_right_entropy
Ⅱ 计算左熵:遍历 self.left_neighbor,对每个词调用 calc_entropy_by_word_count_dict 计算左熵,并存入 self.word_left_entropy
Ⅲ 计算右熵:遍历 self.right_neighbor,对每个词调用 calc_entropy_by_word_count_dict 计算右熵,并存入 self.word_right_entropy
#计算左右熵def calc_entropy(self):self.word_left_entropy = {}self.word_right_entropy = {}for word, count_dict in self.left_neighbor.items():self.word_left_entropy[word] = self.calc_entropy_by_word_count_dict(count_dict)for word, count_dict in self.right_neighbor.items():self.word_right_entropy[word] = self.calc_entropy_by_word_count_dict(count_dict)
⑥ 统计词长总数

Ⅰ 初始化:初始化一个默认值为0的字典 self.word_count_by_length
Ⅱ 更新不同词长下的词总数:遍历 self.word_count,对于每个单词和它的计数,根据单词长度更新 self.word_count_by_length
#统计每种词长下的词总数def calc_total_count_by_length(self):self.word_count_by_length = defaultdict(int)for word, count in self.word_count.items():self.word_count_by_length[len(word)] += countreturn⑦ 计算互信息

Ⅰ 初始化:调用 calc_total_count_by_length 方法,计算不同长度的词频总数
Ⅱ 初始化 PMI 字典:创建一个空字典 self.pmi
Ⅲ 遍历词语:遍历 self.word_count 中的每个词语及其出现次数
Ⅳ 计算词语概率:计算词语的概率 p_word
Ⅴ 计算字符概率乘积:计算组成该词语的每个字符的概率乘积 p_chars
Ⅵ 计算 PMI 值:根据公式 math.log(p_word / p_chars, 10) / len(word) 计算 PMI,并存入 self.pmi
#计算互信息(pointwise mutual information 凝固度)def calc_pmi(self):self.calc_total_count_by_length()self.pmi = {}for word, count in self.word_count.items():p_word = count / self.word_count_by_length[len(word)]p_chars = 1for char in word:p_chars *= self.word_count[char] / self.word_count_by_length[1]self.pmi[word] = math.log(p_word / p_chars, 10) / len(word)return⑧ 计算每个词的价值
Ⅰ 初始化:初始化 self.word_values 为空字典
Ⅱ 遍历:
如果词长度小于2或包含逗号,则跳过该词
获取词的PMI值、左熵和右熵,若不存在则设为极小值(1e-3)
使用PMI、左熵和右熵综合评估词的价值,公式为 pmi * max(le, re)
def calc_word_values(self):self.word_values = {}for word in self.pmi:if len(word) < 2 or "," in word:continuepmi = self.pmi.get(word, 1e-3)le = self.word_left_entropy.get(word, 1e-3)re = self.word_right_entropy.get(word, 1e-3)# 通过三个指标综合评估词的价值# self.word_values[word] = pmi + le + re# self.word_values[word] = pmi * min(le, re)self.word_values[word] = pmi * max(le, re)# self.word_values[word] = pmi + le * re# self.word_values[word] = pmi * le * re⑨ 新词检测

Ⅰ 初始化:创建 NewWordDetect 对象,加载语料库
Ⅱ 计算特征:计算词语的频率、左右邻词、PMI、左右熵等特征
Ⅲ 排序并输出:根据总分对词语进行排序,分别输出长度为2、3、4的前十个高分词
import math
from collections import defaultdictclass NewWordDetect:def __init__(self, corpus_path):# 设置词语最高长度 1 - 5 四个字的词语self.max_word_length = 5self.word_count = defaultdict(int)self.left_neighbor = defaultdict(dict)self.right_neighbor = defaultdict(dict)self.load_corpus(corpus_path)self.calc_pmi()self.calc_entropy()self.calc_word_values()#加载语料数据,并进行统计def load_corpus(self, path):with open(path, encoding="utf8") as f:for line in f:sentence = line.strip()for word_length in range(1, self.max_word_length):self.ngram_count(sentence, word_length)return#按照窗口长度取词,并记录左邻右邻出现过的字及次数def ngram_count(self, sentence, word_length):for i in range(len(sentence) - word_length + 1):word = sentence[i:i + word_length]self.word_count[word] += 1if i - 1 >= 0:char = sentence[i - 1]self.left_neighbor[word][char] = self.left_neighbor[word].get(char, 0) + 1if i + word_length < len(sentence):char = sentence[i +word_length]self.right_neighbor[word][char] = self.right_neighbor[word].get(char, 0) + 1return#计算熵def calc_entropy_by_word_count_dict(self, word_count_dict):total = sum(word_count_dict.values())entropy = sum([-(c / total) * math.log((c / total), 10) for c in word_count_dict.values()])return entropy#计算左右熵def calc_entropy(self):self.word_left_entropy = {}self.word_right_entropy = {}for word, count_dict in self.left_neighbor.items():self.word_left_entropy[word] = self.calc_entropy_by_word_count_dict(count_dict)for word, count_dict in self.right_neighbor.items():self.word_right_entropy[word] = self.calc_entropy_by_word_count_dict(count_dict)#统计每种词长下的词总数def calc_total_count_by_length(self):self.word_count_by_length = defaultdict(int)for word, count in self.word_count.items():self.word_count_by_length[len(word)] += countreturn#计算互信息(pointwise mutual information 凝固度)def calc_pmi(self):self.calc_total_count_by_length()self.pmi = {}for word, count in self.word_count.items():p_word = count / self.word_count_by_length[len(word)]p_chars = 1for char in word:p_chars *= self.word_count[char] / self.word_count_by_length[1]self.pmi[word] = math.log(p_word / p_chars, 10) / len(word)returndef calc_word_values(self):self.word_values = {}for word in self.pmi:if len(word) < 2 or "," in word:continuepmi = self.pmi.get(word, 1e-3)le = self.word_left_entropy.get(word, 1e-3)re = self.word_right_entropy.get(word, 1e-3)# 通过三个指标综合评估词的价值# self.word_values[word] = pmi + le + re# self.word_values[word] = pmi * min(le, re)self.word_values[word] = pmi * max(le, re)# self.word_values[word] = pmi + le * re# self.word_values[word] = pmi * le * reif __name__ == "__main__":nwd = NewWordDetect("sample_corpus.txt")value_sort = sorted([(word, count) for word, count in nwd.word_values.items()], key=lambda x:x[1], reverse=True)print([x for x, c in value_sort if len(x) == 2][:10])print([x for x, c in value_sort if len(x) == 3][:10])print([x for x, c in value_sort if len(x) == 4][:10])

二、挑选重要词
假如一个词在某类文本(假设为A类)中出现次数很多,而在其他类别文本(非A类)出现很少,那么这个词是A类文本的重要词(高权重词)
反之,如果一个词出现在很多领域,则其对于任意类别的重要性都很差
是否能够根据一个词来区分其属于哪个领域
1.数学角度刻画重要词
TF · IDF:刻画某一个词对于某一领域的重要程度
TF:词频,某个词在某类别中出现的次数/该类别词的总数
IDF:逆文档频率,N代表文本总数,dfi代表包含词qi的文本中的总数
逆文档频率高 ——> 该词很少出现在其他文档

和语料库的文档总数成正比,和包含这个词的文档总数成反比
例:

TF在某一分类的值越大,则TF项在某一分类中更为重要,例如:a只出现在A文档中,则a对A文档的标志性比较大
TF·IDF其他计算方式
TF:
IDF:
每个词对于每个类别都会得到一个TF·IDF值
TF·IDF高 -> 该词对于该领域重要程度高,低则相反
2.算法特点
1.tf · idf 的计算非常依赖分词结果,如果分词出错,统计值的意义会大打折扣
2.每个词,对于每篇文档,有不同的tf-idf值,所以不能脱离数据讨论tf·idf
3.假如只有一篇文本,不能计算tf·idf
4.类别数据均衡很重要
5.容易受各种特殊符号影响,最好做一些预处理
3.算法示例
① 构建TF·IDF字典
Ⅰ 初始化字典:
tf_dict:记录每个文档中每个词的出现频率
idf_dict:记录每个词出现在多少个文档中
Ⅱ 遍历语料库:
对于每篇文档,遍历其中的每个词,更新tf_dict和idf_dict
Ⅲ 转换idf_dict:
将idf_dict中的集合转换为文档数量
Ⅳ 返回结果:
返回tf_dict和idf_dict
#统计tf和idf值
def build_tf_idf_dict(corpus):tf_dict = defaultdict(dict) #key:文档序号,value:dict,文档中每个词出现的频率idf_dict = defaultdict(set) #key:词, value:set,文档序号,最终用于计算每个词在多少篇文档中出现过for text_index, text_words in enumerate(corpus):for word in text_words:if word not in tf_dict[text_index]:tf_dict[text_index][word] = 0tf_dict[text_index][word] += 1idf_dict[word].add(text_index)idf_dict = dict([(key, len(value)) for key, value in idf_dict.items()])return tf_dict, idf_dict② 根据tf值和idf值计算tf·idf
Ⅰ 初始化:
创建一个默认字典 tf_idf_dict 来存储每个文本中每个词的TF-IDF值
Ⅱ 遍历文本:
遍历输入的 tf_dict,其中键是文本索引,值是该文本中每个词的词频计数字典
Ⅲ 计算TF:
对于每个词,计算其在当前文本中的词频(TF),即该词出现次数除以该文本中所有词的总次数
Ⅳ 计算TF·IDF:
根据公式 tf · idf = tf * log(D / (idf + 1)) 计算TF·IDF值,其中 D 是文本总数,idf 是逆文档频率
Ⅴ 存储结果:
将计算得到的TF-IDF值存入 tf_idf_dict 中
Ⅵ 返回结果:
返回包含所有文本中每个词的TF-IDF值的字典
#根据tf值和idf值计算tfidf
def calculate_tf_idf(tf_dict, idf_dict):tf_idf_dict = defaultdict(dict)for text_index, word_tf_count_dict in tf_dict.items():for word, tf_count in word_tf_count_dict.items():tf = tf_count / sum(word_tf_count_dict.values())#tf-idf = tf * log(D/(idf + 1))tf_idf_dict[text_index][word] = tf * math.log(len(tf_dict)/(idf_dict[word]+1))return tf_idf_dict③ 计算给定语料库中每个文档的TF-IDF值
Ⅰ分词处理:
使用jieba.lcut对语料库中的每个文本进行分词
Ⅱ 构建TF和IDF字典:
调用build_tf_idf_dict函数,生成每个文档的词频(TF)字典和逆文档频率(IDF)字典
Ⅲ 计算TF-IDF:
调用calculate_tf_idf函数,根据TF和IDF字典计算每个文档的TF-IDF值
Ⅳ 返回结果:
返回包含每个文档TF-IDF值的字典。
#输入语料 list of string
def calculate_tfidf(corpus):#先进行分词corpus = [jieba.lcut(text) for text in corpus]tf_dict, idf_dict = build_tf_idf_dict(corpus)tf_idf_dict = calculate_tf_idf(tf_dict, idf_dict)return tf_idf_dict④ 提取每个文本的前top个高频词
Ⅰ 初始化:
创建一个空字典topk_dict用于存储结果
Ⅱ 遍历文本:
遍历输入的tfidf_dict,对每个文本的TF-IDF值进行排序,取前top个词存入topk_dict
Ⅲ 打印输出:
如果print_word为真,则打印当前文本索引、路径及前top个词
Ⅳ 返回结果:
返回包含每个文本前top个高频词的字典
#根据tfidf字典,显示每个领域topK的关键词
def tf_idf_topk(tfidf_dict, paths=[], top=10, print_word=True):topk_dict = {}for text_index, text_tfidf_dict in tfidf_dict.items():word_list = sorted(text_tfidf_dict.items(), key=lambda x:x[1], reverse=True)topk_dict[text_index] = word_list[:top]if print_word:print(text_index, paths[text_index])for i in range(top):print(word_list[i])print("----------")return topk_dict⑤ tf·idf的计算和使用
import jieba
import math
import os
import json
from collections import defaultdict"""
tfidf的计算和使用
"""#统计tf和idf值
def build_tf_idf_dict(corpus):tf_dict = defaultdict(dict) #key:文档序号,value:dict,文档中每个词出现的频率idf_dict = defaultdict(set) #key:词, value:set,文档序号,最终用于计算每个词在多少篇文档中出现过for text_index, text_words in enumerate(corpus):for word in text_words:if word not in tf_dict[text_index]:tf_dict[text_index][word] = 0tf_dict[text_index][word] += 1idf_dict[word].add(text_index)idf_dict = dict([(key, len(value)) for key, value in idf_dict.items()])return tf_dict, idf_dict#根据tf值和idf值计算tfidf
def calculate_tf_idf(tf_dict, idf_dict):tf_idf_dict = defaultdict(dict)for text_index, word_tf_count_dict in tf_dict.items():for word, tf_count in word_tf_count_dict.items():tf = tf_count / sum(word_tf_count_dict.values())#tf-idf = tf * log(D/(idf + 1))tf_idf_dict[text_index][word] = tf * math.log(len(tf_dict)/(idf_dict[word]+1))return tf_idf_dict#输入语料 list of string
#["xxxxxxxxx", "xxxxxxxxxxxxxxxx", "xxxxxxxx"]
def calculate_tfidf(corpus):#先进行分词corpus = [jieba.lcut(text) for text in corpus]tf_dict, idf_dict = build_tf_idf_dict(corpus)tf_idf_dict = calculate_tf_idf(tf_dict, idf_dict)return tf_idf_dict#根据tfidf字典,显示每个领域topK的关键词
def tf_idf_topk(tfidf_dict, paths=[], top=10, print_word=True):topk_dict = {}for text_index, text_tfidf_dict in tfidf_dict.items():word_list = sorted(text_tfidf_dict.items(), key=lambda x:x[1], reverse=True)topk_dict[text_index] = word_list[:top]if print_word:print(text_index, paths[text_index])for i in range(top):print(word_list[i])print("----------")return topk_dictdef main():dir_path = r"category_corpus/"corpus = []paths = []for path in os.listdir(dir_path):path = os.path.join(dir_path, path)if path.endswith("txt"):corpus.append(open(path, encoding="utf8").read())paths.append(os.path.basename(path))tf_idf_dict = calculate_tfidf(corpus)tf_idf_topk(tf_idf_dict, paths)if __name__ == "__main__":main()
4.TF·IDF应用 —— 搜索引擎
① 对于已有的所有网页(文本),计算每个网页中,词的TF·IDF值

Ⅰ 初始化:
调用 jieba.initialize() 初始化分词工具
Ⅱ 读取文件:
打开指定路径的文件,并读取其中的 JSON 数据
Ⅲ 构建语料库:
遍历每个文档,将标题和内容拼接成一个字符串,并添加到语料库列表中
Ⅳ 计算 TF-IDF:
调用 calculate_tfidf 函数,传入构建好的语料库,计算每个文档的 TF-IDF 值
Ⅴ 返回结果:
返回计算好的 TF-IDF 字典和语料库
#根据tfidf字典,显示每个领域topK的关键词
def tf_idf_topk(tfidf_dict, paths=[], top=10, print_word=True):topk_dict = {}for text_index, text_tfidf_dict in tfidf_dict.items():word_list = sorted(text_tfidf_dict.items(), key=lambda x:x[1], reverse=True)topk_dict[text_index] = word_list[:top]if print_word:print(text_index, paths[text_index])for i in range(top):print(word_list[i])print("----------")return topk_dict② 对于一个输入query(查询)进行分词
对于文档D,计算query中的词在文档D中的TF·IDF值总和,作为query和文档的相关性得分
Ⅰ分词查询:使用 jieba.lcut 对输入的查询进行分词
Ⅱ 计算得分:遍历 tf_idf_dict 中的每篇文档,根据查询词在文档中的 TF-IDF 值累加得分
Ⅲ 排序结果:将所有文档按得分从高到低排序
Ⅳ 输出结果:打印得分最高的前 top 篇文档内容,并返回包含所有文档及其得分的结果列表。
def search_engine(query, tf_idf_dict, corpus, top=3):query_words = jieba.lcut(query)res = []for doc_id, tf_idf in tf_idf_dict.items():score = 0for word in query_words:score += tf_idf.get(word, 0)res.append([doc_id, score])res = sorted(res, reverse=True, key=lambda x:x[1])for i in range(top):doc_id = res[i][0]print(corpus[doc_id])print("--------------")return res③ TF·IDF实现简单搜索引擎
import jieba
import math
import os
import json
from collections import defaultdict
from calculate_tfidf import calculate_tfidf, tf_idf_topk
"""
基于tfidf实现简单搜索引擎
"""jieba.initialize()#加载文档数据(可以想象成网页数据),计算每个网页的tfidf字典
def load_data(file_path):corpus = []with open(file_path, encoding="utf8") as f:documents = json.loads(f.read())for document in documents:corpus.append(document["title"] + "\n" + document["content"])tf_idf_dict = calculate_tfidf(corpus)return tf_idf_dict, corpusdef search_engine(query, tf_idf_dict, corpus, top=3):query_words = jieba.lcut(query)res = []for doc_id, tf_idf in tf_idf_dict.items():score = 0for word in query_words:score += tf_idf.get(word, 0)res.append([doc_id, score])res = sorted(res, reverse=True, key=lambda x:x[1])for i in range(top):doc_id = res[i][0]print(corpus[doc_id])print("--------------")return resif __name__ == "__main__":path = "news.json"tf_idf_dict, corpus = load_data(path)while True:query = input("请输入您要搜索的内容:")search_engine(query, tf_idf_dict, corpus)5.TF·IDF应用 —— 文本摘要
抽取式摘要
① 加载文档数据,并计算每个文档的TF·IDF值
Ⅰ 初始化:调用 jieba.initialize() 初始化分词工具
Ⅱ 读取文件:打开并读取文件内容,解析为JSON格式的文档列表
Ⅲ 数据处理:遍历每个文档,确保标题和内容中不包含换行符,然后将标题和内容拼接成一个字符串并加入语料库
Ⅳ 计算TF-IDF:使用 calculate_tfidf 函数计算语料库的TF-IDF值
Ⅴ 返回结果:返回TF-IDF字典和语料库
jieba.initialize()#加载文档数据(可以想象成网页数据),计算每个网页的tfidf字典
def load_data(file_path):corpus = []with open(file_path, encoding="utf8") as f:documents = json.loads(f.read())for document in documents:assert "\n" not in document["title"]assert "\n" not in document["content"]corpus.append(document["title"] + "\n" + document["content"])tf_idf_dict = calculate_tfidf(corpus)return tf_idf_dict, corpus② 计算生成每一篇文章的摘要
Ⅰ 句子分割:将文章按句号、问号、感叹号分割成句子列表
Ⅱ 过滤短文章:如果文章少于5个句子,返回None,因为太短的文章不适合做摘要
Ⅲ 计算句子得分:对每个句子进行分词,并根据TF-IDF词典计算句子得分
Ⅳ 排序并选择重要句子:根据句子得分排序,选择得分最高的前top个句子,并按原文顺序排列
Ⅴ 返回摘要:将选中的句子拼接成摘要返回
#计算每一篇文章的摘要
#输入该文章的tf_idf词典,和文章内容
#top为人为定义的选取的句子数量
#过滤掉一些正文太短的文章,因为正文太短在做摘要意义不大
def generate_document_abstract(document_tf_idf, document, top=3):sentences = re.split("?|!|。", document)#过滤掉正文在五句以内的文章if len(sentences) <= 5:return Noneresult = []for index, sentence in enumerate(sentences):sentence_score = 0words = jieba.lcut(sentence)for word in words:sentence_score += document_tf_idf.get(word, 0)sentence_score /= (len(words) + 1)result.append([sentence_score, index])result = sorted(result, key=lambda x:x[0], reverse=True)#权重最高的可能依次是第10,第6,第3句,将他们调整为出现顺序比较合理,即3,6,10important_sentence_indexs = sorted([x[1] for x in result[:top]])return "。".join([sentences[index] for index in important_sentence_indexs])
③ 生成文档摘要,并将摘要添加到原始文档中

Ⅰ 初始化结果列表:创建一个空列表 res 用于存储最终的结果
Ⅱ 遍历文档:通过 tf_idf_dict.items() 遍历每个文档的TF-IDF字典
Ⅲ 分割标题和内容:从 corpus 中获取当前文档的内容,并按换行符分割为标题和正文
Ⅳ 生成摘要:调用 generate_document_abstract 函数生成摘要,如果摘要为空则跳过该文档
Ⅴ 更新文档并保存结果:将生成的摘要添加到原始文档中,并将标题、正文和摘要存入结果列表
Ⅵ 返回结果:返回包含所有文档摘要的信息列表
#生成所有文章的摘要
def generate_abstract(tf_idf_dict, corpus):res = []for index, document_tf_idf in tf_idf_dict.items():title, content = corpus[index].split("\n")abstract = generate_document_abstract(document_tf_idf, content)if abstract is None:continuecorpus[index] += "\n" + abstractres.append({"标题":title, "正文":content, "摘要":abstract})return res④ TF·IDF实现简单文本摘要
import jieba
import math
import os
import random
import re
import json
from collections import defaultdict
from calculate_tfidf import calculate_tfidf, tf_idf_topk
"""
基于tfidf实现简单文本摘要
"""jieba.initialize()#加载文档数据(可以想象成网页数据),计算每个网页的tfidf字典
def load_data(file_path):corpus = []with open(file_path, encoding="utf8") as f:documents = json.loads(f.read())for document in documents:assert "\n" not in document["title"]assert "\n" not in document["content"]corpus.append(document["title"] + "\n" + document["content"])tf_idf_dict = calculate_tfidf(corpus)return tf_idf_dict, corpus#计算每一篇文章的摘要
#输入该文章的tf_idf词典,和文章内容
#top为人为定义的选取的句子数量
#过滤掉一些正文太短的文章,因为正文太短在做摘要意义不大
def generate_document_abstract(document_tf_idf, document, top=3):sentences = re.split("?|!|。", document)#过滤掉正文在五句以内的文章if len(sentences) <= 5:return Noneresult = []for index, sentence in enumerate(sentences):sentence_score = 0words = jieba.lcut(sentence)for word in words:sentence_score += document_tf_idf.get(word, 0)sentence_score /= (len(words) + 1)result.append([sentence_score, index])result = sorted(result, key=lambda x:x[0], reverse=True)#权重最高的可能依次是第10,第6,第3句,将他们调整为出现顺序比较合理,即3,6,10important_sentence_indexs = sorted([x[1] for x in result[:top]])return "。".join([sentences[index] for index in important_sentence_indexs])#生成所有文章的摘要
def generate_abstract(tf_idf_dict, corpus):res = []for index, document_tf_idf in tf_idf_dict.items():title, content = corpus[index].split("\n")abstract = generate_document_abstract(document_tf_idf, content)if abstract is None:continuecorpus[index] += "\n" + abstractres.append({"标题":title, "正文":content, "摘要":abstract})return resif __name__ == "__main__":path = "news.json"tf_idf_dict, corpus = load_data(path)res = generate_abstract(tf_idf_dict, corpus)writer = open("abstract.json", "w", encoding="utf8")writer.write(json.dumps(res, ensure_ascii=False, indent=2))writer.close()

6.TF·IDF应用 —— 文本相似度计算
① 加载文档数据并计算TF-IDF值
Ⅰ 读取文件:从指定路径读取JSON格式的文档数据
Ⅱ 构建语料库:将每个文档的标题和内容拼接成一个字符串,存入语料库列表
Ⅲ 计算TF-IDF:调用calculate_tfidf函数计算语料库的TF-IDF值
Ⅳ 提取重要词:调用tf_idf_topk函数提取每篇文档中TF-IDF值最高的前5个词
Ⅴ 构建词汇表:将所有文档的重要词去重后存入集合,最终转换为列表
Ⅵ 返回结果:返回TF-IDF字典、词汇表和语料库。
jieba.initialize()#加载文档数据(可以想象成网页数据),计算每个网页的tfidf字典
#之后统计每篇文档重要在前10的词,统计出重要词词表
#重要词词表用于后续文本向量化
def load_data(file_path):corpus = []with open(file_path, encoding="utf8") as f:documents = json.loads(f.read())for document in documents:corpus.append(document["title"] + "\n" + document["content"])tf_idf_dict = calculate_tfidf(corpus)topk_words = tf_idf_topk(tf_idf_dict, top=5, print_word=False)vocab = set()for words in topk_words.values():for word, score in words:vocab.add(word)print("词表大小:", len(vocab))return tf_idf_dict, list(vocab), corpus② 将文章转换为向量

Ⅰ 初始化:初始化一个长度为词汇表大小的零向量 vector
Ⅱ 分词:使用 jieba.lcut 将文章分词为一个词语列表 passage_words
Ⅲ 更新词表:遍历词汇表中的每个词,计算其在文章中的出现频率,并更新到 vector 中
Ⅳ 返回结果:返回最终的向量
#passage是文本字符串
#vocab是词列表
#向量化的方式:计算每个重要词在文档中的出现频率
def doc_to_vec(passage, vocab):vector = [0] * len(vocab)passage_words = jieba.lcut(passage)for index, word in enumerate(vocab):vector[index] = passage_words.count(word) / len(passage_words)return vector③ 文档转换为向量表示
Ⅰ 输入参数:
corpus:一个包含多个文档的列表,每个文档是一个字符串
vocab:词汇表,一个包含所有可能单词的列表
Ⅱ 处理逻辑:
使用列表推导式遍历语料库中的每个文档 c,调用 doc_to_vec 函数将其转换为向量
doc_to_vec 函数会根据词汇表 vocab 计算文档中每个词的频率,并返回一个向量表示
最终返回一个包含所有文档向量的列表 corpus_vectors
#先计算所有文档的向量
def calculate_corpus_vectors(corpus, vocab):corpus_vectors = [doc_to_vec(c, vocab) for c in corpus]return corpus_vectors④ 计算两个向量间的余弦相似度
计算点积:通过 zip 函数将两个向量对应元素相乘并求和,得到点积 x_dot_y
计算模长:分别计算两个向量的模长 sqrt_x 和 sqrt_y
处理特殊情况:如果任一向量的模长为0,返回0
计算相似度:返回点积除以两个模长的乘积,并加上一个小常数 1e-7 防止分母为0
#计算向量余弦相似度
def cosine_similarity(vector1, vector2):x_dot_y = sum([x*y for x, y in zip(vector1, vector2)])sqrt_x = math.sqrt(sum([x ** 2 for x in vector1]))sqrt_y = math.sqrt(sum([x ** 2 for x in vector2]))if sqrt_y == 0 or sqrt_y == 0:return 0return x_dot_y / (sqrt_x * sqrt_y + 1e-7)
⑤ 计算输入文本与语料库所有文档的相似度

Ⅰ 将输入文本转换为向量:调用 doc_to_vec 方法,将输入文本 passage 转换为词频向量 input_vec
Ⅱ 计算相似度:遍历语料库中的每个文档向量,使用 cosine_similarity 方法计算输入向量与每个文档向量的余弦相似度
向量夹角余弦值计算公式:
Ⅲ 排序并返回结果:将所有相似度分数按降序排列,返回前4个最相似的文档索引及其相似度分数
#输入一篇文本,寻找最相似文本
def search_most_similar_document(passage, corpus_vectors, vocab):input_vec = doc_to_vec(passage, vocab)result = []for index, vector in enumerate(corpus_vectors):score = cosine_similarity(input_vec, vector)result.append([index, score])result = sorted(result, reverse=True, key=lambda x:x[1])return result[:4]⑥ TF·IDF实现文本相似度计算
#coding:utf8
import jieba
import math
import os
import json
from collections import defaultdict
from calculate_tfidf import calculate_tfidf, tf_idf_topk"""
基于tfidf实现文本相似度计算
"""jieba.initialize()#加载文档数据(可以想象成网页数据),计算每个网页的tfidf字典
#之后统计每篇文档重要在前10的词,统计出重要词词表
#重要词词表用于后续文本向量化
def load_data(file_path):corpus = []with open(file_path, encoding="utf8") as f:documents = json.loads(f.read())for document in documents:corpus.append(document["title"] + "\n" + document["content"])tf_idf_dict = calculate_tfidf(corpus)topk_words = tf_idf_topk(tf_idf_dict, top=5, print_word=False)vocab = set()for words in topk_words.values():for word, score in words:vocab.add(word)print("词表大小:", len(vocab))return tf_idf_dict, list(vocab), corpus#passage是文本字符串
#vocab是词列表
#向量化的方式:计算每个重要词在文档中的出现频率
def doc_to_vec(passage, vocab):vector = [0] * len(vocab)passage_words = jieba.lcut(passage)for index, word in enumerate(vocab):vector[index] = passage_words.count(word) / len(passage_words)return vector#先计算所有文档的向量
def calculate_corpus_vectors(corpus, vocab):corpus_vectors = [doc_to_vec(c, vocab) for c in corpus]return corpus_vectors#计算向量余弦相似度
def cosine_similarity(vector1, vector2):x_dot_y = sum([x*y for x, y in zip(vector1, vector2)])sqrt_x = math.sqrt(sum([x ** 2 for x in vector1]))sqrt_y = math.sqrt(sum([x ** 2 for x in vector2]))if sqrt_y == 0 or sqrt_y == 0:return 0return x_dot_y / (sqrt_x * sqrt_y + 1e-7)#输入一篇文本,寻找最相似文本
def search_most_similar_document(passage, corpus_vectors, vocab):input_vec = doc_to_vec(passage, vocab)result = []for index, vector in enumerate(corpus_vectors):score = cosine_similarity(input_vec, vector)result.append([index, score])result = sorted(result, reverse=True, key=lambda x:x[1])return result[:4]if __name__ == "__main__":path = "news.json"tf_idf_dict, vocab, corpus = load_data(path)corpus_vectors = calculate_corpus_vectors(corpus, vocab)passage = "WGT"for corpus_index, score in search_most_similar_document(passage, corpus_vectors, vocab):print("相似文章:\n", corpus[corpus_index].strip())print("得分:", score)print("--------------")
7.TF·IDF的优势
① 可解释性好
可以清晰地看到关键词
即使预测结果出错,也很容易找到原因
② 计算速度快
分词本身占耗时最多,其余为简单统计计算
③ 对标注数据依赖小
可以使用无标注语料完成一部分工作
④ 可以与很多算法组合使用
可以看做是词权重的体现
8.TF·IDF的劣势
① 受分词效果影响大
② 词与词之间没有语义相似度
同义词之间也不会进行关联,不会被同等的对待
③ 没有语序信息
TF·IDF本质上是一个词袋模型,计算搜索信息中每一个词的TF·IDF值的总和,作为搜索信息与文档信息相关性的得分
④ 能力范围有限
无法完成复杂任务,如机器翻译和实体挖掘等
深度学习可以处理几乎所有任务,只是效果好坏区别,同时可以考虑语序、考虑词与词之间的相似度、也不依赖分词的结果
⑤ 样本不均衡会对结果有很大影响
词的总数多少也会影响TF·IDF值的大小,影响结果的好坏
⑥ 类内样本间分布不被考虑
将每篇独立的文章混合在一起,导致TF·IDF值的计算有误差
相关文章:
【NLP 18、新词发现和TF·IDF】
目录 一、新词发现 1.新词发现的衡量标准 ① 内部稳固 ② 外部多变 2.示例 ① 初始化类 NewWordDetect ② 加载语料信息,并进行统计 ③ 统计指定长度的词频及其左右邻居字符词频 ④ 计算熵 ⑤ 计算左右熵 编辑 ⑥ 统计词长总数 ⑦ 计算互信息 ⑧ 计算每个词…...

C# 从控制台应用程序入门
总目录 前言 从创建并运行第一个控制台应用程序,快速入门C#。 一、新建一个控制台应用程序 控制台应用程序是C# 入门时,学习基础语法的最佳应用程序。 打开VS2022,选择【创建新项目】 搜索【控制台】,选择控制台应用(.NET Framew…...

怿星科技联合赛力斯举办workshop活动,进一步推动双方合作
12月18日,由怿星科技与赛力斯汽车联合举办的workshop活动在赛力斯五云湖总部展开,双方嘉宾围绕智能汽车发展趋势、行业前沿技术、汽车电子网络与功能测试等核心议题展开了深度对话与交流,并现场参观演示了多套前沿产品。怿星科技CEO潘凯、汽车…...

JVM和数据库面试知识点
JVM内存结构 主要有几部分:堆、栈、方法区和程序计数器 堆是JVM中最大的一块内存区域,用于存储对象实例,一般通过new创建的对象都存放在堆中。堆被所有的线程共享,但是它的访问时线程不安全的,通常通过锁的机制来保证线…...

批量提取zotero的论文构建知识库做问答的大模型(可选)——含转存PDF-分割统计PDF等
文章目录 提取zotero的PDF上传到AI平台保留文件名代码分成20个PDF视频讲解 提取zotero的PDF 右键查看目录 发现目录为 C:\Users\89735\Zotero\storage 写代码: 扫描路径‘C:\Users\89735\Zotero\storage’下面的所有PDF文件,全部复制一份汇总到"C:\Users\89735\Downl…...

Codeforces Round 993 (Div. 4)个人训练记录
Codeforces Round 993 (Div. 4) 只选择对我有价值的题目记录 E. Insane Problem 题目描述 给定五个整数 k k k, l 1 l_1 l1, r 1 r_1 r1, l 2 l_2 l2 和 r 2 r_2 r2,Wave 希望你帮助她计算满足以下所有条件的有序对 …...

【优选算法---分治】快速排序三路划分(颜色分类、快速排序、数组第K大的元素、数组中最小的K个元素)
一、颜色分类 题目链接: 75. 颜色分类 - 力扣(LeetCode) 题目介绍: 给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地 对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序…...

Spring Cloud OpenFeign
概述 Feign是一个声明式web服务客户端。可以像写接口一样定义http客户端。Feign还支持可插拔的编码器和解码器。Spring Cloud增加了对Spring MVC注释和使用Spring Web中默认使用的HttpMessageConverter的支持。Spring Cloud集成了Ribbon和Eureka,以及Spring Cloud L…...
)
Oracle 数据库函数的用法(一)
Oracle数据库提供了大量的内置函数,可以用于完成各种操作,如字符串操作,数学计算,日期时间处理,条件判断,序列生成,聚合统计等。以下是一些常用的Oracle数据库函数: 一、oracle 使用…...

【C2C+GRCC】Exploring Disentangled Content Information for Face Forgery Detection
文章目录 Exploring Disentangled Content Information for Face Forgery Detection背景key points研究贡献方法增强解纠缠特性的独立性实验数据内评估跨方法评估跨数据集评估消融实验总结Exploring Disentangled Content Information for Face Forgery Detection 会议/期刊:…...

springboot461学生成绩分析和弱项辅助系统设计(论文+源码)_kaic
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装学生成绩分析和弱项辅助系统软件来发挥其高效地信息处理的作…...

Unity复刻胡闹厨房复盘 模块一 新输入系统订阅链与重绑定
本文仅作学习交流,不做任何商业用途 郑重感谢siki老师的汉化教程与代码猴的免费教程以及搬运烤肉的小伙伴 版本:Unity6 模板:3D 核心 渲染管线:URP ------------------------------…...

使用“NodeMCU”、“红外模块”实现空调控制
项目思路 空调遥控器之所以能够实现对空调的控制,是因为它能够向空调发射出特定的红外信号。从理论上来说,任何能够发射出这种相同红外信号的红外发射器,都可以充当空调遥控器(这也正是手机能够控制多种不同品牌空调的原因所在&a…...

2023年西南大学数学建模C题天气预报解题全过程文档及程序
2023年西南大学数学建模 C题 天气预报 原题再现: 天气现象与人类的生产生活、社会经济、军事活动等方方面面都密切相关,大到国家,小到个人,都受到极端天气的影响。2022年6月,全球陆地地区出现了自1850年代末人类有系…...

【大模型】使用DPO技术对大模型Qwen2.5进行微调
前言 定义 DPO(Direct Preference Optimization)即直接偏好优化算法,是一种在自然语言处理领域,特别是在训练语言模型时使用的优化策略。它的主要目的是使语言模型的输出更符合人类的偏好。 背景和原理 在传统的语言模型训练中&a…...

Maven 生命周期
文章目录 Maven 生命周期- Clean 生命周期- Build 生命周期- Site 生命周期 Maven 生命周期 Maven 有以下三个标准的生命周期: Clean 生命周期: clean:删除目标目录中的编译输出文件。这通常是在构建之前执行的,以确保项目从一个…...
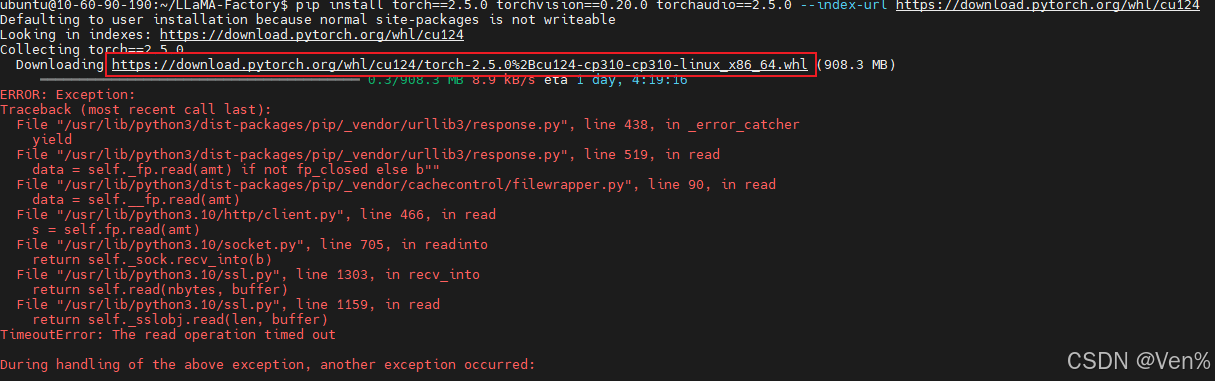
网络不通该如何手动下载torch
如果遇到pip install torch2.5.0 下载不了的情况,大部分是网络的问题.可以考虑下载wheel文件在去安装 查看对应的cuda版本(举个例子:cuda为12.4,找到这个版本的 复制到服务器上下载): 有conda和pip下载的两种方式,二者选其一:如果没有安装anaconda,就直接使用pip的方式下载 如…...

基础电路的学习
1、戴维南定理 ①左边的图可简化为一个电阻+一个电压源。② ③电压源可相当于开路。将R2移到左边,R1和R2相当于并联。RR1//R2 Rx和Rt相等时,灵敏度最大,因此使Rt10K。 104电容是0.1uf。 三位数字的前两位数字为标称容量的有效数…...

对 MYSQL 架构的了解
MySQL 是一种广泛使用的关系型数据库管理系统,其架构主要包括以下几个关键部分: 一、连接层 客户端连接管理:MySQL 服务器可以同时处理多个客户端的连接请求。当客户端应用程序(如使用 Java、Python 等语言编写的程序)…...

C#中方法参数传值和传引用的情况
对于引用类型 - 传类类型的具体值时 此时传的是引用 - 单纯传类类型 此时传的是个test引用的副本,在方法内修改的是这个副本的指向 传string,集合同理,只要是指向新对象,就是引用副本在指向 对于值类型 - 传普通值类型 …...

从零开始构建FPGA项目:ADI HDL开发实战经验分享
从零开始构建FPGA项目:ADI HDL开发实战经验分享 【免费下载链接】hdl HDL libraries and projects 项目地址: https://gitcode.com/gh_mirrors/hd/hdl ADI HDL(Analog Devices HDL)是一套功能强大的硬件描述语言库,专为FPG…...

如何用AntiMicroX解决PC游戏手柄兼容性问题:终极手柄映射工具完全指南
如何用AntiMicroX解决PC游戏手柄兼容性问题:终极手柄映射工具完全指南 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gi…...

如何用SMUDebugTool完全掌控AMD Ryzen处理器性能
如何用SMUDebugTool完全掌控AMD Ryzen处理器性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.com/gh_mir…...

Blender-Armatures
导航 (返回顶部) 1. Blender-Armatures 1.1 骨架位置1.2 分类1.3 骨骼结构 2. 编辑 2.1 骨骼扭转2.2 拆分 split2.3 分离骨骼 separate2.4 切换方向 3. 镜像编辑 3.1 镜像挤出3.2 命名惯例3.3 对称 4. 属性 4.1 属性结构表4.2 柔性骨骼 Bendy Bones4.3 姿态4.4 关系 5. 骨骼约束…...

港澳通行证照片怎么手机拍?2026 手机拍摄规格要求和实用方法全解
准备办理港澳通行证却被照片规格搞得不知所措?其实用手机就能拍出符合要求的证件照,关键是掌握正确的拍摄方法和规格标准。这篇文章将详细讲解港澳通行证照片的手机拍摄方法,包括规格要求、拍摄步骤,以及如何后期处理让照片完美达…...

【实操经验】拒答能力不达标,大模型备案怎么过
在生成式 AI 监管趋严的 2026 年,拒答率≥95% 是大模型备案的硬性门槛(GB/T 45644-2025)。不少自研或二次开发模型因安全对齐不足、拒答逻辑薄弱,测试时频繁 “翻车”—— 敏感问题答非所问、违法指令直接执行、多轮诱导轻易妥协&…...

即时通讯IM:从聊天工具到企业数字底座
即时通讯IM在2026年已不再只是员工桌面上用来收发消息的软件。它正经历一场深刻的角色蜕变——从“聊天工具”升级为支撑企业核心业务运转的“数字底座”。即时通讯系统已成为支撑企业核心运营的关键基础设施,IM正在被赋予连接一切、打通信息流的关键角色。 这种进化…...

网络工程师面试必看:通过一个华为ENSP综合实验,拆解中小型网络规划的核心思路
网络工程师面试必看:中小型网络规划的设计思维与实战解析 当面试官抛出"请描述你如何设计一个中小型网络"这个问题时,大多数求职者会陷入两种极端:要么机械罗列配置命令,要么泛泛而谈架构概念。真正能打动面试官的&…...

Ubuntu20.04安装Mapviz避坑指南:解决Qt与OpenCV冲突,手把手配置天地图
Ubuntu20.04安装Mapviz避坑指南:解决Qt与OpenCV冲突,手把手配置天地图 在ROS开发中,地图可视化工具Mapviz因其强大的插件系统和高度可定制性备受青睐。然而,Ubuntu20.04环境下安装Mapviz时,Qt版本冲突和OpenCV链接错误…...

在华为擎云L420上从源码编译ARM GCC 10.3,为Betaflight开发铺路
在华为擎云L420上构建ARM GCC 10.3工具链:Betaflight开发环境实战指南 当国产化硬件遇上开源飞控开发,技术探索的边界正在被不断拓展。华为擎云L420作为一款基于ARM64架构的笔记本电脑,为开发者提供了在国产平台上进行嵌入式开发的独特机会。…...