[机器学习]XGBoost(3)——确定树的结构
XGBoost的目标函数详见[机器学习]XGBoost(2)——目标函数(公式详解)
确定树的结构
之前在关于目标函数的计算中,均假设树的结构是确定的,但实际上,当划分条件不同时,叶子节点包含的样本不同,计算的 H j H_j Hj 和 G j G_j Gj不同,每个叶子节点的W值也就不同
每一棵树都有属于自己最优的 O b j ∗ Obj^* Obj∗,因此要找一种最优的划分方式,即要找出使得 O b j ∗ Obj^* Obj∗最小的树作为基学习器的决策树
- 穷举法:计算所有可能的组合情况,然后选出最小的 O b j ∗ Obj^* Obj∗
缺点:在实际应用中,穷举所有可能的分裂点通常是不可行的,因为计算成本太高。 - 精确贪心算法:每次选择最优的分裂点
XGBoost用的是精确贪心算法
精确贪心算法
在XGBoost中,用精确贪心算法在构建决策树的过程中选择最优的分裂点。这种方法旨在找到能够最大化目标函数增益的分裂点,从而提高模型的预测性能。
核心思想:
- 贪心选择:在每一步分裂决策中,算法不是寻找全局最优解,而是做出局部最优选择。这意味着在当前步骤中,选择能够最大程度降低目标函数(损失函数和正则化项之和)的分裂点。
- 精确计算:对于每个可能的分裂点,精确计算分裂后的增益。增益是通过比较分裂前后的目标函数值来计算的,即增益等于分裂前的目标函数值减去分裂后所有子节点目标函数值的总和。
- 递归分裂:一旦选择了最优分裂点,算法将递归地对每个子节点重复分裂过程,直到满足停止条件(如达到最大树深度、增益小于阈值或子节点中的样本数小于某个阈值)。
算法步骤
-
初始化:开始时,所有样本都在根节点。初始化目标函数 Obj 为所有样本的损失之和。
-
计算增益:对于每个可能的分裂点,计算分裂后的增益。增益是通过比较分裂前后的目标函数值来计算的,即增益 = 父节点的目标函数值 - 子节点的目标函数值之和。
- 对于每个子节点 j,目标函数 Obj_j 可以表示为 O b j j = γ + 0.5 ∗ ( G j 2 / ( H j + λ ) ) Obj_j = γ + 0.5 * (G_j^2 / (H_j + λ)) Objj=γ+0.5∗(Gj2/(Hj+λ))
其中 G j G_j Gj 是子节点上所有样本梯度的和, H j H_j Hj 是Hessian的和,这两个都是可以计算的。 - 增益 Gain 可以表示为: G a i n = O b j p a r e n t − [ O b j l e f t + O b j r i g h t ] Gain = Obj_{parent} - [Obj_{left} + Obj_{right}] Gain=Objparent−[Objleft+Objright]
其中, O b j p a r e n t Obj_{parent} Objparent 是父节点的目标函数值, O b j l e f t Obj_{left} Objleft 和 O b j r i g h t Obj_{right} Objright 是分裂后左右子节点的目标函数值。
- 对于每个子节点 j,目标函数 Obj_j 可以表示为 O b j j = γ + 0.5 ∗ ( G j 2 / ( H j + λ ) ) Obj_j = γ + 0.5 * (G_j^2 / (H_j + λ)) Objj=γ+0.5∗(Gj2/(Hj+λ))
-
选择最佳分裂:在所有可能的分裂点中,选择增益最大的分裂点作为最优分裂。这个分裂点将被用来将当前节点分裂为两个子节点。
-
更新目标函数:使用最优分裂点分裂节点后,更新目标函数。计算每个子节点上的 G j G_j Gj和 H j H_j Hj,并更新 O b j Obj Obj。
-
递归构建:对每个新创建的子节点重复步骤2-4,直到满足停止条件(如达到最大深度或增益小于阈值)。
什么时候停止划分?
-
最大增益小于一个很小的数:如果进一步划分带来的增益小于预设的最小增益阈值(min_split_gain),则不会进行分裂。这个阈值用于控制只有当分裂能够显著提高模型性能时,才会进行分裂。
-
叶子节点包含样本个数小于等于1:如果一个叶子节点中的样本数量小于或等于1,那么这个叶子节点将不再进一步划分。这是为了防止树的过拟合,因为单个样本的分裂不会提供泛化能力。
-
达到最大树深度:如果树的深度已经达到预设的最大深度(max_depth),则停止进一步划分。
算法伪代码

输入参数:
- I:当前节点的所有样本实例。
- d:特征的维度,即数据集中特征的数量。
初始化:
- gain:初始化为0,用来存储在所有可能的分裂中找到的最大增益值。
- G:所有样本梯度的总和。
- H:所有样本Hessian的总和。
算法步骤:
-
遍历所有特征:对于每个特征 k(从1到特征总数 m),执行以下操作。
-
初始化左右子树的梯度和Hessian和: G L G_L GL 和 H L H_L HL 分别初始化为0,用来存储左子树的梯度和和Hessian和。
-
对样本按特征值排序:将样本集 I 按照特征 k 的值进行排序。
注意:不同特征会划分出不同的样本集,所以每次排序都要重新排。当特征非常多时,排序操作非常耗时 -
计算左右子树的统计量:遍历排序后的样本,逐步构建左子树的统计量(GL 和 HL),同时计算右子树的统计量(GR = G - GL 和 HR = H - HL)。
-
计算分裂增益:使用公式计算当前分裂点的增益 score:
score = G L 2 H L + λ + G R 2 H R + λ − G 2 H + λ \text{score} = \frac{G_L^2}{H_L + \lambda} + \frac{G_R^2}{H_R + \lambda} - \frac{G^2}{H + \lambda} score=HL+λGL2+HR+λGR2−H+λG2
如果当前分裂点的增益大于之前记录的最大增益 gain,则更新 gain。 -
选择最佳分裂:在所有特征和所有可能的分裂点中,选择增益最大的分裂点作为最终的分裂点。
输出:
具有最大增益的分裂点,这将用于构建决策树的节点分裂。
算法优化——近似算法
针对不同特征会划分出不同的样本集,所以每次排序都要重新排的问题进行优化(以牺牲精度为代价)
- 压缩特征
- 采样特征值
压缩特征——列采样
按树随机采样(Tree-wise Subsampling):
在构建每棵树之前,从所有特征中随机选择一部分特征进行考虑。例如一共有X1……X10个特征,选3个特征X1,X5,X7,之后每次计算都只用这三个特征
优点:
- 减少每棵树的计算量,因为每次分裂只考虑一部分特征,可能的分裂点减少,gain值的个数减少。
- 有助于防止过拟合,因为模型不会对所有特征都过于敏感。
缺点:
- 固定随机选择的特征可能会忽略一些对模型预测性能有重要影响的特征,导致模型无法充分利用所有特征信息。(每次都只用X1,X5,X7,可能忽略其他特征的信息)
按层随机采样(Level-wise Subsampling):
在构建树的每个层级时,都重新对特征进行采样。例如一共有X1……X10个特征,第一层根节点选3个特征X1,X5,X7,之后每次计算都重新选三个特征,第二层左节点用X2,X3,X4,第二层右节点用X1,X8,X10……
优点:
- 减少每棵树的计算量,因为每次分裂只考虑一部分特征,可能的分裂点减少,gain值的个数减少。
- 确保每一层的分裂都有新的随机特征选择,增加了模型的多样性。
- 通常比按树随机采样更复杂,但可能提供更好的性能。
分桶采样特征值
在构建树的每个层级时,对特征的值进行采样,而不是使用全部特征值。例如,对于每个特征 X i,将其值域分成 k 组,从每个特征的 k 组中随机选择一个值,这样总共选择了 k 个特征值。
优点:
- 减少每个特征的计算量,因为每个特征的计算只考虑一部分特征值, H j H_j Hj和 G j G_j Gj计算量变小。
注意:
- 不是随机选取,是先分桶,再从每个桶里选一个代表
- 理想化假设特征值均匀分布,每个桶里的特征值数量应该尽量接近,但实际并不是这样的,因此用加权分位法
加权分位法
-
收集梯度和Hessian:对于每个特征,收集所有样本的梯度 g i g_i gi 和Hessian h i h_i hi
-
计算权重:样本权重通常与梯度和Hessian有关。在XGBoost中,样本权重可以是Hessian的函数表示。

-
排序:根据样本权重对特征的所有可能值进行排序。具有更高权重的样本在排序中会有更大的影响力。
-
计算分位数:在排序后的特征值上,根据预设的桶数量(由参数 max_bin 控制)计算分位数。这些分位数将用作桶的边界。
-
分桶:使用计算出的分位数将特征值域分割成若干个桶。每个桶代表特征值的一个区间。
-
选择代表值:从每个桶中选择一个代表值,这个值将用于构建模型。在XGBoost中,这个值通常是桶中所有样本梯度和的加权平均值。
策略
- 全局策略
分一次桶,以后每次都按这个分法来分 - 局部策略
每次都重新分一次桶
缺失值处理 Sparsity-aware Split Finding
实际场景拿到的数据是很稀疏的,有大量缺失值,因此需要处理缺失值
- 穷举法:为所有组合计算增益,选最大的
- 贪心法:把每个缺失值分别放到左边和右边计算gain,比较两个gain的大小,这样要计算
2*缺失值个数次 - 论文采用的方法:把所有缺失值当成整体看待,都同时放到左边计算一个gain,再把所有缺失值放到右边计算一个gain,比较两个gain的大小,然后把所有缺失值样本全部放到gain大的那边。这样只用计算
2次
注意:加权分位法中缺失值不参与排序和分桶
学习率 shrinkage
目的:为了防止过拟合

相关文章:
[机器学习]XGBoost(3)——确定树的结构
XGBoost的目标函数详见[机器学习]XGBoost(2)——目标函数(公式详解) 确定树的结构 之前在关于目标函数的计算中,均假设树的结构是确定的,但实际上,当划分条件不同时,叶子节点包含的…...

PHP阶段一
PHP 一门编程语言 运行在服务器端 专门用户开发网站的 脚本后缀名.php 与HTML语言进行混编,脚本后缀依然是.php 解释型语言,不要编译直接运行 PHP运行需要环境: Windows phpstudy Linux 单独安装 Web 原理简述 1、打开浏览器 2、输入u…...

用人话讲计算机:Python篇!(十五)迭代器、生成器、装饰器
一、迭代器 (1)定义 标准解释:迭代器是 Python 中实现了迭代协议的对象,即提供__iter__()和 __next__()方法,任何实现了这两个方法的对象都可以被称为迭代器。 所谓__iter__(),即返回迭代器自身 所谓__…...

5G -- 5G网络架构
5G组网场景 从4G到5G的网络演进: 1、UE -> 4G基站 -> 4G核心网 * 部署初中期,利用存量网络,引入5G基站,4G与5G基站并存 2、UE -> (4G基站、5G基站) -> 4G核心网 * 部署中后期,引入5G核心网&am…...

VR线上展厅的色彩管理如何影响用户情绪?
VR线上展厅的色彩管理对用户情绪的影响是多方面的,以下是专业从事VR线上展厅制作的圆桌3D云展厅平台为大家介绍的一些关键点: 情感共鸣:色彩能够激发特定的情感反应。例如,暖色调(如红色、橙色)通常与活力和…...

Vue3:uv-upload图片上传
效果图: 参考文档: Upload 上传 | 我的资料管理-uv-ui 是全面兼容vue32、nvue、app、h5、小程序等多端的uni-app生态框架 (uvui.cn) 代码: <view class"greenBtn_zw2" click"handleAddGroup">添加班级群</vie…...

大数据机器学习算法和计算机视觉应用07:机器学习
Machine Learning Goal of Machine LearningLinear ClassificationSolutionNumerical output example: linear regressionStochastic Gradient DescentMatrix Acceleration Goal of Machine Learning 机器学习的目标 假设现在有一组数据 x i , y i {x_i,y_i} xi,yi&…...

基于asp.net游乐园管理系统设计与实现
博主介绍:专注于Java(springboot ssm 等开发框架) vue .net php python(flask Django) 小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆不然下次找…...

一区牛顿-拉夫逊算法+分解+深度学习!VMD-NRBO-Transformer-GRU多变量时间序列光伏功率预测
一区牛顿-拉夫逊算法分解深度学习!VMD-NRBO-Transformer-GRU多变量时间序列光伏功率预测 目录 一区牛顿-拉夫逊算法分解深度学习!VMD-NRBO-Transformer-GRU多变量时间序列光伏功率预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.中科院一区…...

uniapp使用腾讯地图接口的时候提示此key每秒请求量已达到上限或者提示此key每日调用量已达到上限问题解决
要在创建的key上添加配额 点击配额之后进入分配页面,分配完之后刷新uniapp就可以调用成功了。...

WPF 完美解决改变指示灯的颜色
WPF 完美解决改变指示灯的颜色 原有:自己再做WPF页面设计后发现直接去查找页面多个控件嵌套情况下找不到指示灯(Button实现的,详细可以看这篇文章 这里),具体看看来如何实现 加粗样式思路:无论多级嵌套&a…...

Flutter/Dart:使用日志模块Logger Easier
Flutter笔记 Flutter/Dart:使用日志模块Logger Easier Logger Easier 是一个为 Dart 和 Flutter 应用程序量身定制的现代化日志管理解决方案。它提供了一个高度灵活、功能丰富的日志记录系统,旨在简化开发者的日志管理工作,同时提供一定的定制…...
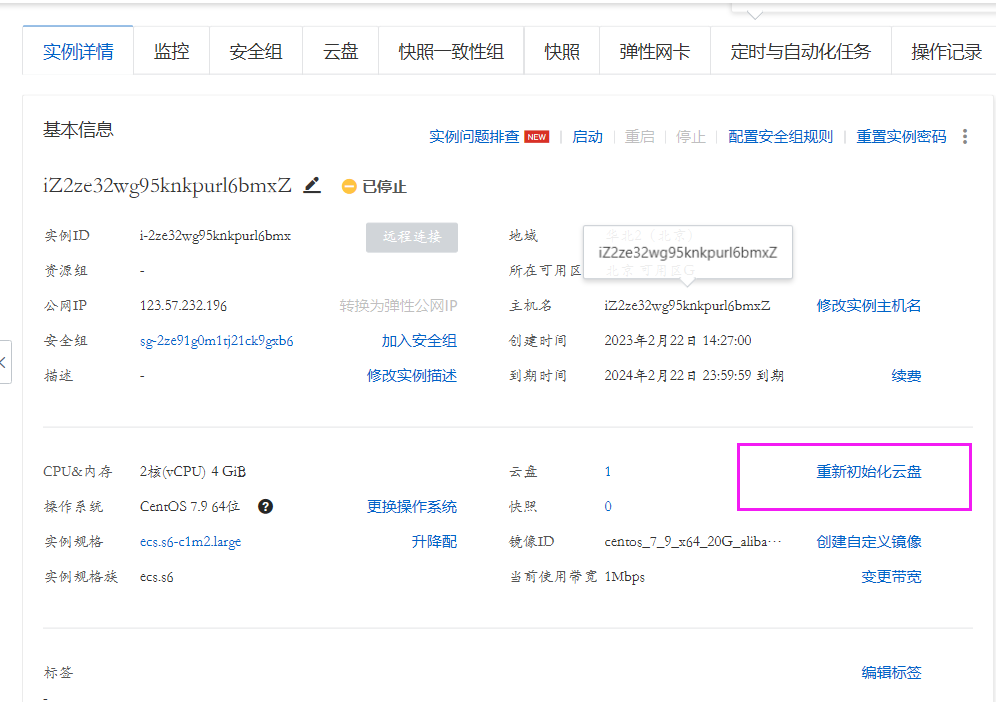
阿里云云服务器初始化
如果我们的云服务器出现无法挽回的错误时,我们可以尝试初始化云服务器进行解决。 首先搜索阿里云(你要先确认自己已经购买了阿里云的云服务器): 登录账号后主页向下划 进入后点击管理控制台 点击进入后可以看到正在运行࿰…...

Python中SKlearn的K-means使用详解
文章目录 Python中SKlearn的K-means使用详解一、引言二、K-means算法原理三、使用SKlearn进行K-means聚类的步骤1、导入必要的库2、生成数据集3、创建K-means模型并设置参数4、训练模型5、预测簇标签6、可视化结果 四、总结 Python中SKlearn的K-means使用详解 一、引言 K-mea…...

红帽RHCE认证适用哪些人学习
红帽 RHCE工程师认证有着广泛的适用人群。对于初入 IT 行业的新手来说,RHCE 是快速建立专业基础、提升自身竞争力的绝佳途径。它能帮助新人系统地学习 Linux 系统知识,从基础的安装配置到复杂的网络服务管理,一步一个脚印地构建起坚实的技术框…...

FFmpeg 框架简介和文件解复用
文章目录 ffmpeg框架简介libavformat库libavcodec库libavdevice库 复用(muxers)和解复用(demuxers)容器格式FLVScript Tag Data结构(脚本类型、帧类型)Audio Tag Data结构(音频Tag)V…...

《Java核心技术I》Swing中的边框
边框 BorderFactory静态方法创建边框,凹斜面,凸斜面,蚀刻,直线,蒙版,空白。 边框添加标题,BorderFactory.createTitledBorder 组合边框,BorderFactory.createCompoundBorder JCo…...

MySQL 中的常见错误与排查
在 MySQL 数据库的日常运维中,管理员可能会遇到各种错误。无论是查询性能问题、连接异常、数据一致性问题,还是磁盘空间不足等,及时排查并解决这些问题是保证数据库稳定运行的关键。本文将列出 MySQL 中一些常见的错误及其排查方法。 一、连接…...

SQL 查询方式比较:子查询与自连接
在 SQL 中,子查询和自连接是两种常见的查询方式,它们的功能虽然可以相同,但实现的方式不同。本文通过具体示例,深入探讨这两种查询方式,并配合数据展示,帮助大家理解它们的使用场景和差异。 数据示例 假设…...

Linux下学【MySQL】所有常用类型详解( 配实操图 通俗易懂 )
每日激励:“当你觉得你会幸运时,幸运就会眷顾你,所以努力吧,只要你把事情做好,并觉得你会幸运,你将会变得幸运且充实。” 绪论: 本章继续学习MySQL的知识,本章主要讲到mysql中的所…...

Llama-3.2V-11B-cot多轮对话效果展示:复杂技术问题拆解与解答
Llama-3.2V-11B-cot多轮对话效果展示:复杂技术问题拆解与解答 最近在测试各种大模型时,我特意找了一个比较“刁钻”的场景:让模型来解答一个复杂的系统设计问题。这类问题通常不是一两句话能说清的,它需要模型有很强的逻辑推理能…...

Umi-OCR批量文字识别终极指南:免费离线OCR工具快速上手
Umi-OCR批量文字识别终极指南:免费离线OCR工具快速上手 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/Git…...

文本风格转换技术:数字手写化工具的创新应用与实践指南
文本风格转换技术:数字手写化工具的创新应用与实践指南 【免费下载链接】text-to-handwriting So your teacher asked you to upload written assignments? Hate writing assigments? This tool will help you convert your text to handwriting xD 项目地址: h…...

笔记工具模板系统实用指南:从效率提升到知识管理进阶
笔记工具模板系统实用指南:从效率提升到知识管理进阶 【免费下载链接】OB_Template OB_Templates is a Obsidian reference for note templates focused on new users of the application using only core plugins. 项目地址: https://gitcode.com/gh_mirrors/ob/…...

开源项目版本冲突解决指南:从现象到实践的深度解析
开源项目版本冲突解决指南:从现象到实践的深度解析 【免费下载链接】ComfyUI-Impact-Pack 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-Impact-Pack 问题现象:版本不匹配的警告信号 在开源项目开发中,你是否遇到过这样的情…...

5分钟搞懂幂等矩阵:从定义到Python实现
5分钟搞懂幂等矩阵:从定义到Python实现 第一次听到"幂等矩阵"这个词时,我正坐在线性代数课的最后一排昏昏欲睡。教授在黑板上写下"AA"这个看似简单的等式时,我完全没意识到这个概念会在后来的机器学习项目中反复出现。今…...

如何用VarifocalNet提升目标检测性能?从FCOS到VFNet的实战解析
从FCOS到VFNet:实战解析VarifocalNet如何突破目标检测性能瓶颈 目标检测领域近年来涌现出大量创新算法,但性能提升逐渐进入平台期。传统方法如FCOS虽然简洁高效,但在处理密集物体和复杂场景时仍存在明显局限。本文将深入剖析VarifocalNet(VFN…...

Qwen3-0.6B-FP8部署与Git工作流结合:AI代码审查助手
Qwen3-0.6B-FP8部署与Git工作流结合:AI代码审查助手 你有没有遇到过这种情况?团队里新来的小伙伴提交了一段代码,语法上挑不出大毛病,但总觉得逻辑有点绕,或者命名风格不太统一。你作为资深开发,想提点建议…...

[特殊字符] Nano-Banana参数详解:LoRA权重对部件排布影响的实证分析
Nano-Banana参数详解:LoRA权重对部件排布影响的实证分析 1. 项目简介 Nano-Banana是一款专为产品拆解和平铺展示风格设计的轻量化文本生成图像系统。这个项目的核心价值在于深度融合了专属的Turbo LoRA微调权重,专门针对Knolling平铺、爆炸图、产品部件…...

2025最新版Shenyu API网关实战:30分钟快速搭建微服务流量控制中心
2025最新版Shenyu API网关实战:30分钟快速搭建微服务流量控制中心 你还在为微服务架构中的API管理和流量控制烦恼吗?面对日益复杂的服务调用关系,如何高效实现请求路由、安全防护和流量监控?本文将带你30分钟内从零开始搭建基于S…...