使用 AOP 在 Spring Boot 中实现跟踪和日志记录
在现代应用程序中,尤其是使用微服务构建的应用程序,跟踪和日志记录在跟踪流经各种服务的请求方面起着至关重要的作用。跟踪可帮助开发人员诊断问题、监控性能并了解用户在多个系统中的旅程。
在此博客中,我们将介绍如何使用traceId从前端生成的代码在 Spring Boot 应用程序中实现跟踪和日志记录,我们还将探索在微服务环境中进行分布式跟踪的选项。
什么是追踪?
跟踪是指为traceId请求分配一个唯一标识符(通常称为),并确保该标识符在请求经过应用程序中的不同层或服务时随请求一起移动。这对于了解请求流至关重要,尤其是在排查错误或性能瓶颈时。
traceId为什么从前端生成并发送?
在微服务架构中,请求通常会流经多个服务和组件。traceId在前端生成请求具有以下几个优点:
- 端到端可视性:
traceId从用户交互开始,可以更轻松地跟踪从前端到后端服务的请求。这确保了对整个堆栈中用户操作的完全可视性。 - 一致跟踪:通过在前端生成
traceId并将其包含在每次请求中,相同的内容traceId会传播到所有服务。这可以实现跨多个 API 调用和服务的一致跟踪。 - 会话级跟踪:当用户会话开始时,前端可以生成一个会话
traceId并将其用于该会话中的所有请求。这允许开发人员跟踪用户在单个会话中执行的所有操作。
步骤 1:traceId从 React生成并发送
让我们首先在 React 前端生成traceId并将其与每个 API 请求一起发送。
traceId在 React 中生成
我们将使用该uuid库为每个会话生成一个唯一的标识符:
npm install uuid然后,创建一个生成或检索的实用函数traceId:
import { v4 as uuidv4 } from 'uuid' ; function getOrCreateTraceId ( ) { let traceId = localStorage . getItem ( 'traceId' ); if (!traceId) { traceId = uuidv4 (); // 为 traceId 生成一个新的 UUID localStorage . setItem ( 'traceId' , traceId); // 存储它以供将来的请求使用} return traceId;
}添加traceIdAxios 拦截器
为了确保traceId自动包含在每个 API 请求中,我们更新了 Axios 拦截器:
const axios = require('axios');
import { getOrCreateTraceId } from './traceIdUtil';const instanceUrl = axios.create({baseURL: 'http://localhost:8080/',transformRequest: [function (data, headers) {let jwt = localStorage.getItem('jwt');if (jwt) {headers.Authorization = 'Bearer ' + jwt;}// Include traceId in every request headerheaders['X-Trace-Id'] = getOrCreateTraceId();return JSON.stringify(data);}],headers: {'Content-Type': 'application/json','Cache-Control': 'no-cache',Pragma: 'no-cache'}
});现在,从 React 前端发送的每个请求都将在标头traceId中包含X-Trace-Id。
第 2 步:traceId在 Spring Boot 中处理
在 Spring Boot 后端,我们需要捕获此信息traceId并确保在整个应用程序生命周期中始终使用它进行日志记录。我们使用 SpringMapped Diagnostic Context (MDC)来存储traceId和userId。
设置过滤器以捕获traceId
我们将使用 Spring Boot 中的过滤器来拦截每个传入请求,从请求标头中提取traceId,并将其存储在 MDC 中:
import org.slf4j.MDC;
import org.springframework.security.core.Authentication;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.stereotype.Component;import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.http.HttpFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.UUID;@Component
public class TraceAndUserFilter extends HttpFilter {private static final String TRACE_ID = "traceId";private static final String USER_ID = "userId";private static final String HEADER_TRACE_ID = "X-Trace-Id";@Overrideprotected void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain chain)throws IOException, ServletException {// Get traceId from the request header, or generate a new one if missingString traceId = request.getHeader(HEADER_TRACE_ID);if (traceId == null || traceId.isEmpty()) {traceId = UUID.randomUUID().toString();}MDC.put(TRACE_ID, traceId);// Retrieve userId from the security contextAuthentication authentication = SecurityContextHolder.getContext().getAuthentication();String userId = (authentication != null && authentication.isAuthenticated()) ? authentication.getName() : "ANONYMOUS";MDC.put(USER_ID, userId);try {chain.doFilter(request, response); // Continue with the next filter in the chain} finally {// Remove traceId and userId from MDC after the request is processedMDC.remove(TRACE_ID);MDC.remove(USER_ID);}}@Overridepublic void init(FilterConfig filterConfig) throws ServletException {super.init(filterConfig);}@Overridepublic void destroy() {super.destroy();}
}步骤 3:使用 AOP(面向方面编程)进行日志记录
通过将traceId和userId存储在 MDC 中,我们可以使用 Spring AOP 来记录整个系统中的方法进入和退出。这种方法允许我们在调用方法时自动记录,而不会使业务逻辑变得混乱。
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.slf4j.MDC;
import org.springframework.stereotype.Component;@Aspect
@Component
@Slf4j
public class LoggingAspect {private static final String TRACE_ID = "traceId";private static final String USER_ID = "userId";@Around("execution(* com.example.application..*(..))")public Object logAround(ProceedingJoinPoint joinPoint) throws Throwable {String traceId = MDC.get(TRACE_ID);String userId = MDC.get(USER_ID);String className = joinPoint.getSignature().getDeclaringTypeName();String methodName = joinPoint.getSignature().getName();// Log entering the methodlog.info("TraceId: {}, UserId: {}, Class: {}, Entering method {} with parameters {}", traceId, userId, className, methodName, joinPoint.getArgs());Object result;try {result = joinPoint.proceed(); // Proceed with the method execution} catch (Throwable throwable) {log.error("TraceId: {}, UserId: {}, Class: {}, Exception in method {}: {}", traceId, userId, className, methodName, throwable.getMessage());throw throwable;}// Log exiting the methodif (result != null) {log.info("TraceId: {}, UserId: {}, Class: {}, Exiting method {} with return value {}", traceId, userId, className, methodName, result);} else {log.info("TraceId: {}, UserId: {}, Class: {}, Exiting method {} with no return value", traceId, userId, className, methodName);}return result;}
}步骤 4:配置日志记录以包括traceId和userId
配置您的日志系统以在所有日志条目中包含traceId和userId。例如,在 Logback 中,您可以修改logback.xml以包含以下值:
<configuration><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg [traceId=%X{traceId}] [userId=%X{userId}]%n</pattern></encoder></appender><root level="INFO"><appender-ref ref="STDOUT" /></root>
</configuration>步骤 5:分布式跟踪选项
虽然从前端发送traceId有助于追踪用户在系统中的旅程,但在更复杂的微服务架构中,通常需要分布式跟踪工具才能获得跨多个服务的整体视图。
以下是微服务环境中分布式跟踪的一些选项:
- Jaeger:Uber 构建的开源端到端分布式跟踪工具。它与 Spring Boot 集成良好,有助于可视化请求如何在服务之间传播。Jaeger
允许您监控服务的延迟和性能,并提供服务交互的详细视图。 - Zipkin:一种流行的开源跟踪系统,可帮助收集解决微服务架构中的延迟问题所需的时间数据。Zipkin 可捕获跟踪并帮助可视化服务之间的依赖关系。Zipkin
设置简单,广泛用于分布式系统的性能监控。 - OpenTelemetry :一个
高度可扩展的框架,用于收集和导出跟踪数据。OpenTelemetry 支持多个后端(Jaeger、Zipkin、Prometheus 等),并且可以轻松集成到 Spring Boot 中。OpenTelemetry正在成为分布式系统中跟踪和指标收集的标准。
结论
通过从前端发送traceId并使用 Spring Boot 和 AOP 将其传播到整个后端,我们可以实现有效的跟踪以实现端到端可见性。此外,Jaeger、Zipkin 和 OpenTelemetry 等分布式跟踪工具可以帮助您跟踪跨多个服务的请求,从而使微服务中的调试和监控变得更加容易。
通过此设置,您可以跟踪整个系统的请求,无论是单个应用程序还是复杂的微服务网络,确保易于追踪问题并快速识别性能瓶颈。
相关文章:

使用 AOP 在 Spring Boot 中实现跟踪和日志记录
在现代应用程序中,尤其是使用微服务构建的应用程序,跟踪和日志记录在跟踪流经各种服务的请求方面起着至关重要的作用。跟踪可帮助开发人员诊断问题、监控性能并了解用户在多个系统中的旅程。 在此博客中,我们将介绍如何使用traceId从前端生成…...

如何永久解决Apache Struts文件上传漏洞
Apache Struts又双叒叕爆文件上传漏洞了。 自Apache Struts框架发布以来,就存在多个版本的漏洞,其中一些漏洞涉及到文件上传功能。这些漏洞可能允许攻击者通过构造特定的请求来绕过安全限制,从而上传恶意文件。虽然每次官方都发布补丁进行修…...

FPGA远程升级 -- FLASH控制
简介 前文讲到如何实现XILINX芯片程序跳转,但升级程序是事先通过VIVADO工具将两个程序合成一个BIN文件实现升级的,并不能在线更新升级。要实现远程升级的能力需要对FPGA的FLASH进行在线写入升级程序。 FLASH介绍 本次设计FLASH选用的是S25FL128芯片&…...

企业内训|高智能数据构建、Agent研发及AI测评技术内训-吉林省某汽车厂商
吉林省某汽车厂商为提升员工在AI大模型技术方面的知识和实践能力,举办本次为期8天的综合培训课程。本课程分为两大部分:面向全体团队成员的AI大模型技术结构与行业应用,以及针对技术团队的高智能数据构建与Agent研发。课程内容涵盖非结构化数…...

ARM异常处理 M33
1. ARMv8-M异常类型及其详细解释 ARMv8-M Exception分为两类:预定义系统异常(015)和外部中断(1616N)。 各种异常的状态可以通过Status bit查看,获取更信息的异常原因: CFSR是由UFSR、BFSR和MMFSR组成: 下面列举HFSR、MMFSR、…...

(补)算法刷题Day24: BM61 矩阵最长递增路径
题目链接 思路 方法一:dfs暴力回溯 使用原始used数组4个方向遍历框架 , 全局添加一个最大值判断最大的路径长度。 方法二:加上dp数组记忆的优雅回溯 抛弃掉used数组,使用dp数组来记忆遍历过的节点的最长递增路径长度。每遍历到已…...

探索 Bokeh:轻松创建交互式数据可视化的强大工具
探索 Bokeh:轻松创建交互式数据可视化的强大工具 在数据科学和数据分析领域,交互式数据可视化是一项不可或缺的技能。Bokeh 是一个强大的 Python 库,它可以帮助我们快速构建高质量的交互式图表和仪表盘,同时兼具高性能和灵活性。…...

【Rust自学】6.1. 定义枚举
喜欢的话别忘了点赞、收藏加关注哦,对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 6.1.1. 什么是枚举 枚举允许我们列举所有可能的值来定义一个类型。这与其他编程语言中的枚举类似,但 Rust 的枚举更加灵活和强…...

【Java基础面试题035】什么是Java泛型的上下界限定符?
回答重点 Java泛型的上下界限定符用于对泛型类型参数进行范围限制,主要有上界限定符和下届限定符。 1)上界限定符 (? extends T): 定义:通配符?的类型必须是T或者T的子类,保证集合元素一定是T或者T的子类作用&…...

0基础学前端系列 -- 深入理解 HTML 布局
在现代网页设计中,布局是至关重要的一环。良好的布局不仅能提升用户体验,还能使内容更具可读性和美观性。HTML(超文本标记语言)结合 CSS(层叠样式表)为我们提供了多种布局方式。本文将详细介绍流式布局、Fl…...

【python高级】342-TCP服务器开发流程
CS模式:客户端-服务端模式 TCP客户端开发流程介绍(五步)(C端) 1.创建客户端套接字对象 2.和服务端套接字建立连接 3.发送数据 4.接收数据 5.关闭客户端套接字 TCP服务端开发流程(七步)…...

《计算机组成及汇编语言原理》阅读笔记:p48-p81
《计算机组成及汇编语言原理》学习第 4 天,p48-p81 总结,总计 34 页。 一、技术总结 1.CISC vs RISC p49, complex instruction set computing For example, a complex instruction set computing (CISC) chip may be able to move a lar…...

AI在传统周公解梦中的技术实践与应用
本文深入探讨了人工智能在传统周公解梦领域的技术实践与应用。首先介绍了传统周公解梦的背景与局限性,随后详细阐述了 AI 技术如何应用于梦境数据的采集、整理与分析,包括自然语言处理技术对梦境描述的理解,机器学习算法构建解梦模型以及深度…...

GIS数据处理/程序/指导,街景百度热力图POI路网建筑物AOI等
简介其他数据处理/程序/指导!!!(1)街景数据获取(2)街景语义分割后像素提取,指标计算代码(绿视率,天空开阔度、视觉熵/景观多样性等)(3…...

ssr实现方案
目录 序言 一、流程 二、前端要做的事情 三、节点介绍 四、总结 序言 本文不是详细的实现过程,是让你最快最直接的理解ssr的真正实现方法,有前端经验的同学,能够很好的理解过程,细节根据具体项目实现 一、前端要做的事情 1.…...

手动修改nginx-rtmp模块,让nginx-rtmp-module支持LLHLS
文章目录 1. 背景2. 开发环境搭建2.1 ffmpeg在ubuntu上安装2.2 nginx-rtmp-module在ubuntu上安装2.3 安装vscode环境2. 修改nginx-rtmp-module2.1 主要更新内容2.2 新增配置项2.3 代码更新3. LLHLS验证方法3.1 配置验证3.2 功能验证4. 注意事项5. 已知问题6. 后续计划1. 背景 …...

gitee别人仓库再上传自己仓库
一、新建一个自己的Git仓库 如果没有注册账号的朋友,可以先去注册一个Gitee的账号,用于管理自己的代码特别好用!!! 接下来就是在gitee上新建一个自己的仓库,如下图所示 二、右建 Git Bush Here删除.git文件…...
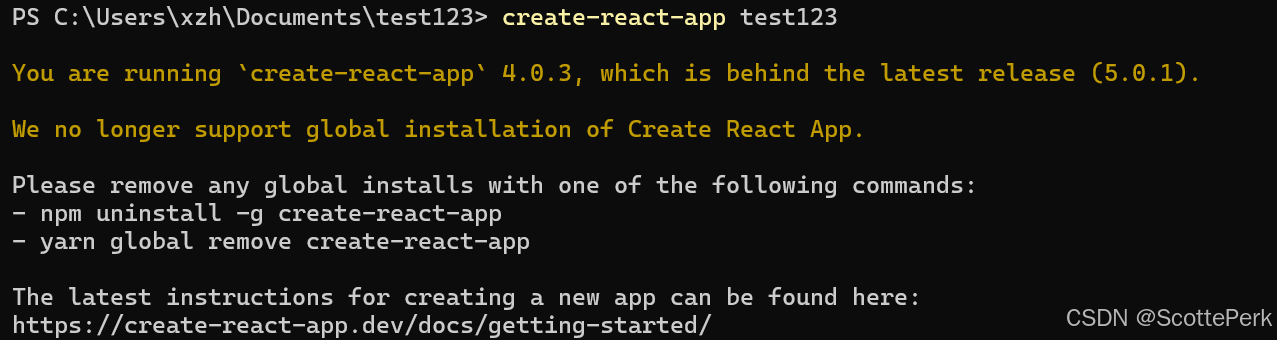
create-react-app 创建react项目报错 ERESOLVE unable to resolve dependency tree
会报下面这样一个错误,这个错误以前是没有的,最近才出现这个错误。这个非常的蛋疼,意思是testing-library这个库的版本需要react18,但现在安装的是react19。 create-react-app的github是有这个issue的,但官方好像没给…...

从git上下载的项目不完整,关于git lfs
文章目录 问题一、git lfs是什么?二、如何获取git lfs中的文件1.安装 Git LFS2.下载文件 问题 在git上下载的项目无法执行,打开相关文件后发现如下内容: git lfs pull version https://git-lfs.github.com/spec/v1 oid sha256:00920b6723bb39321eea748fd96279f8a…...

sqlite3,一个轻量级的 C++ 数据库库!
宝子们,今天咱来唠唠 sqlite3 这个超棒的轻量级 C 数据库库。它就像是一个小巧但功能齐全的“数据仓库”,能帮咱们轻松地存储、查询和管理数据,无论是开发小型的桌面应用,还是做一些简单的数据处理程序,它都能派上大用…...
如何用5分钟彻底解决BT下载速度慢的问题?终极Tracker列表指南
如何用5分钟彻底解决BT下载速度慢的问题?终极Tracker列表指南 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 还在为BT下载速度慢如蜗牛而烦恼吗?每…...

Taskr性能优化秘籍:从毫秒级任务到大规模项目的最佳实践
Taskr性能优化秘籍:从毫秒级任务到大规模项目的最佳实践 【免费下载链接】taskr A fast, concurrency-focused task automation tool. 项目地址: https://gitcode.com/gh_mirrors/ta/taskr Taskr是一款专注于并发的快速任务自动化工具,作为与Gulp…...

实测Phi-4-mini-reasoning:让AI帮你写作业,数学逻辑题轻松应对
实测Phi-4-mini-reasoning:让AI帮你写作业,数学逻辑题轻松应对 1. 引言:你的智能作业助手来了 作为一名学生,你是否经常被数学作业和逻辑推理题困扰?或者作为家长,你是否为辅导孩子作业而头疼?…...
面试题精选:10道高频考题+答案解析(附PDF))
小米AI研发工程师(汽车架构)面试题精选:10道高频考题+答案解析(附PDF)
小米汽车AI研发简介 小米汽车作为小米集团“手机AIoT”战略的核心延伸,致力于打造智能电动汽车。小米汽车AI研发团队聚焦自动驾驶、智能座舱、车路协同等前沿领域,技术栈涵盖深度学习、计算机视觉、强化学习、大模型等。面试重点考察候选人AI算法基础、工程实践能力、以及对…...

Neeshck-Z-lmage_LYX_v2企业应用:LoRA权重数字签名与版本溯源机制
Neeshck-Z-lmage_LYX_v2企业应用:LoRA权重数字签名与版本溯源机制 1. 引言:从工具到系统,企业级应用的新挑战 你可能已经体验过Neeshck-Z-lmage_LYX_v2这个轻量化绘画工具。它确实很方便——基于Z-Image底座模型,支持动态切换Lo…...
)
BUUCTF平台实战:手把手教你利用Struts2漏洞获取flag(附工具推荐)
BUUCTF平台实战:从Struts2漏洞入门到flag获取全指南 第一次接触CTF比赛时,看到那些复杂的漏洞利用过程总让人望而生畏。直到在BUUCTF平台上遇到了Struts2系列漏洞,才发现原来漏洞利用也可以如此"标准化"。本文将带你从零开始&#…...

FourWireFan库:嵌入式四线风扇高精度闭环控制方案
1. FourWireFan库概述:面向嵌入式系统的四线风扇全功能控制方案FourWireFan是一个专为微控制器平台设计的开源风扇控制库,核心目标是实现对标准PC冷却风扇(三线/四线制式)的高精度转速测量、闭环调速、软启动控制及运行状态监控。…...

2023年iMac 21.5寸内存与SSD升级实战指南
1. 为什么你的iMac需要升级内存和SSD? 2019款iMac 21.5寸标配的8GB内存和机械硬盘(或小容量Fusion Drive)放在2023年确实有点力不从心了。我去年接手朋友这台机器时,开个Photoshop都要等半分钟,更别说同时运行几个设计…...
)
uniapp安卓调试进阶:用Chrome开发者工具调试手机Webview页面(2023最新版)
Uniapp安卓Webview深度调试指南:Chrome DevTools实战解析 在混合应用开发领域,Uniapp凭借其跨平台优势已成为移动开发的热门选择。但当应用内嵌Webview页面出现样式错乱、接口异常或性能瓶颈时,仅靠基础调试工具往往难以快速定位问题根源。本…...

智能对象替换引擎:重新定义Adobe Illustrator设计自动化的范式转换
智能对象替换引擎:重新定义Adobe Illustrator设计自动化的范式转换 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在当今设计工作流中,设计师平均37%的工作…...