Adversarial Machine Learning(对抗机器学习)
之前把机器学习(Machine Learning)的安全问题简单记录了一下,这里有深入研究了一些具体的概念,这里记录一下方便以后查阅。
Adversarial Machine Learning(对抗机器学习)
- Adversarial Examples 相关内容
- Evading Machine Learning
- Adversarial Examples
- Adversarial Examples 的特点
- Adversarial Examples 的形式化定义
- Adversarial Examples 的生成方法
- Adversarial Examples 的防御方法
- Non-targeted Adversarial Examples
- 为什么会有 Adversarial Examples
- 攻击方式的分类
- Gradient-based attacks
- Confidence score attacks
- Hard label attacks
- Surrogate model attacks
- Brute-force attacks
- 如何防御 Adversarial Examples
- Formal Methods
- Empirical Defenses
- Adversarial training
- Gradient masking
- Input modification
- Detection
- Extra (NULL) Class
- Adversarial Attacks 和 Adversarial Defenses
- 对抗攻击(Adversarial Attacks)
- Adversarial attacks 的目标
- Adversarial attacks 的攻击方法
- 对抗样本(Adversarial Examples)
- Adversarial attacks 的影响
- 对抗防御(Adversarial Defenses)
- 对抗训练(Adversarial Training)
- 输入预处理(Input Preprocessing)
- 模型正则化(Model Regularization)
- 输入转换(Input Transformation)
- 模型架构的鲁棒性设计
- 使用对抗样本的检测方法(Detection)
- Randomized Neural Networks
- Randomized neural networks 的关键特性
- Randomized neural networks 的常见类型
- Extreme Learning Machines (ELMs)
- Random Vector Functional Link (RVFL)
- Stochastic Neural Networks (SNNs)
- Dropout & Randomized Activation
- Randomized neural networks 的理论基础
- 参考资料
Adversarial Examples 相关内容
机器学习技术的发展令人兴奋。然而,就像任何新技术或发明一样,机器学习不仅带来了新的惊人功能,而且不幸的是,也带来了新的漏洞。
Evading Machine Learning
对抗式 ML 领域的领军人物之一巴蒂斯塔-比吉奥(Battista Biggio)在一篇论文中指出,**对抗式机器学习(Adversarial ML)**领域最早可以追溯到 2004 年。当时,人们在垃圾邮件过滤的背景下对对抗性实例进行了研究,结果表明线性分类器很容易被垃圾邮件内容中一些精心设计的变化所欺骗。
完整时间表:

对抗样本(adversarial examples) 的 “新颖性 ”其实是在深度学习中发现的。2013 年,谷歌人工智能公司的克里斯蒂安-塞格迪(Christian Szegedy)正在研究神经网络如何 “思考”,却发现了一个所有神经网络似乎都具备的有趣特性–容易被微小扰动所迷惑。鉴于深度学习已经变得如此重要, adversarial example 和 Adversarial ML 领域最终成为了焦点。
下面是一些例子:
图片:用对抗眼镜欺骗人脸检测。

视频:DEFCON 上的隐形 T 恤。



音频:语音到文本的转录。

语言:情感分析和文本关联。

Adversarial Examples
通过对输入数据进行精心设计的微小扰动,生成的特殊样本。这些扰动在对人类观察者来说通常不可察觉,但会导致机器学习模型做出错误或意外的预测结果。

Adversarial Examples 的特点
-
精心设计的扰动(Adversarial Perturbations):
- 对抗样本并不是随机产生的,而是通过某种算法(如梯度攻击方法)有意生成的。
- 这些扰动的目标是改变模型的决策边界,使其产生错误输出。
-
对人类而言不可见:
- 人类观察者通常无法分辨正常样本与对抗样本之间的差别。
- 例如,一张图片的对抗样本可能只改变了像素的很小一部分,肉眼看不出差异,但深度学习模型却被误导。
-
目标模型依赖性:
- 对抗样本通常针对特定的模型生成,称为白盒攻击(White-Box Attack),即攻击者完全了解目标模型。
- 在黑盒攻击(Black-Box Attack)中,即使对目标模型不了解,攻击仍可能有效(通过迁移性特征)。
Adversarial Examples 的形式化定义
给定一个分类模型 f ( x ) f(x) f(x),原始输入 x x x,目标类别 y y y,对抗样本 x ′ x' x′ 满足以下条件:
- 相似性:对抗样本 x ′ x' x′ 与原始输入 x x x 的差异很小,可以通过某种度量(如 ∥ x − x ′ ∥ p \|x - x'\|_p ∥x−x′∥p)衡量。
- 误导性:模型预测结果发生变化,即 f ( x ′ ) ≠ f ( x ) f(x') \neq f(x) f(x′)=f(x)。
例如:
- 对于图像分类任务,输入 x x x 是一张狗的图片,模型预测为“狗”。
- 添加了对抗扰动后的 x ′ x' x′ 仍然看起来像狗,但模型预测为“猫”。
Adversarial Examples 的生成方法
一些常见的对抗样本生成算法包括:
- FGSM(Fast Gradient Sign Method):
- 使用目标模型的梯度信息,快速生成能够最大化误差的微小扰动。
- PGD(Projected Gradient Descent):
- 多步优化的版本,通过多次迭代精确调整扰动。
- DeepFool:
- 尝试找到最小的扰动,使样本跨过模型的决策边界。
- C&W(Carlini and Wagner Attack):
- 利用优化目标函数生成更强的对抗样本。
Adversarial Examples 的防御方法
- 对抗训练:
- 在训练过程中加入对抗样本,使模型学习到对抗扰动的模式。
- 输入预处理:
- 对输入数据进行平滑、裁剪或其他变换,以减少对抗扰动的影响。
- 正则化技术:
- 引入鲁棒性损失函数,提高模型对噪声的免疫力。
- 模型架构优化:
- 设计新的网络结构,使模型更加稳健。
Non-targeted Adversarial Examples
上面是一个常见的 targeted adversarial example,人眼无法检测到图像的变化。而 non-targeted adversarial examples 则是我们不用太在意对抗示例对人眼是否有意义,它对人眼来说可能只是随机噪音。

为什么会有 Adversarial Examples
目前存在多种假设:
-
第一个也是最原始的假说来自 Szegedy 自己的论文,试图解释 adversarial examples,他们认为 adversarial examples 的存在是由于流形(manifold )中存在低概率的 “口袋(pockets)”(即太多非线性)以及网络正则化不良。
-
一种相反的理论,该理论由 Goodfellow 首创,他认为现代机器学习,尤其是深度学习系统中的线性度太高导致了 adversarial examples 的出现。古德费洛认为,像 ReLU 和 Sigmoid 这样的激活函数在中间基本上都是直线(恰好我们喜欢在中间保留梯度,以防止它们爆炸或消失)。因此,在神经网络中,你会看到大量的线性函数,它们相互延续输入,方向一致。如果你在某些输入上添加微小的扰动(这里和那里的几个像素),这些扰动就会在网络的另一端累积成巨大的差异,然后它就会吐出胡言乱语。
-
第三种也可能是目前最普遍采用的假设是倾斜边界(tilted boundary)。简而言之,作者认为,由于模型永远无法完美拟合数据(否则测试集的准确率就会始终保持在 100%),因此在分类器的边界和采样数据的实际子阈值之间总会存在一些不利的输入。他们还根据经验推翻了前两种方法。
-
麻省理工学院最近发表的一篇论文认为,对抗性示例并不是一个错误,而是神经网络观察世界的一个特征。我们人类局限于三维空间,无法将噪声模式区分开来,但这并不意味着这些噪声模式不是好的特征。我们的眼睛只是糟糕的传感器。因此,我们真正面对的是一台比我们自己更复杂的模式识别机器–与其把我们不理解的模式称为 “adversarial examples”,不如接受这个世界比我们看到的要复杂得多。如果整篇论文太长,我强烈推荐这篇 11 分钟的博客摘要。
攻击方式的分类
攻击者对目标系统(或其 “能力”)的了解非常重要。他们对您的模型及其构建方式了解得越多,就越容易对其发起攻击。
在 Calypso,将规避攻击(evasion attacks)分为五类:
- 使用梯度的攻击
- 使用置信度的攻击
- 使用硬标签的攻击
- 使用代理模型的攻击
- 暴力攻击
Gradient-based attacks
基于梯度的攻击(Gradient-based attacks) 顾名思义需要访问模型的梯度,因此是一种白盒攻击。这些攻击无疑是最强大的,因为攻击者可以利用他们对模型思考方式(梯度)的详细了解,从数学上优化攻击。
这也是攻击加固模型最有效的技术。事实上,研究表明,如果攻击者可以访问模型的梯度,他们就总能制作出一组新的 adversarial examples 来欺骗模型。这就是为什么 adversarial examples 如此重要的原因–抛开隐蔽性的安全性不谈,要防御对抗示例其实非常困难。
Confidence score attacks
置信度得分攻击(Confidence score attacks) 使用输出的分类置信度来估计模型的梯度,然后执行与上述基于梯度的攻击类似的智能优化。这种方法不需要攻击者了解模型的任何信息,因此属于黑盒攻击。
Hard label attacks
硬标签攻击(Hard label attacks) 只依赖模型输出的标签(“猫”、“狗”、“热狗”),不需要置信度分数。这让攻击变得更加愚蠢,但也可以说更加现实(你知道有多少公共端点会输出分类分数?) 这类攻击中最强大的仍然是边界攻击。
Surrogate model attacks
代用模型攻击(Surrogate model attacks) 与基于梯度的攻击非常相似,只是需要额外的步骤。如果对手无法访问模型的内部结构,但仍想发动 WhiteBox 攻击,他们可以尝试首先在自己的机器上重建目标的模型。他们有几种选择:
- 如果目标模型可以作为一个预测器(oracle)来使用,攻击者可以通过反复查询端点和观察输入输出对来学习它(逆向工程 )。
- 如果目标模型应用于标准分类任务(如人脸检测)–攻击者很可能只需猜测模型的架构和训练数据,并以此为基础构建一个副本。
- 如果攻击者根本不掌握任何信息,由于我们前面讨论过的可转移性,他们可以简单地使用任何现成的图像分类器,并生成不完美但功能正常的对抗示例
Brute-force attacks
最后是 “暴力 ”攻击(brute-force attacks)。这些攻击完全不使用优化来生成对抗示例,而是采用简单的方法,例如:
- 随机旋转/平移图像
- 应用常见的扰动
- 添加大 SD 值的高斯噪声
如何防御 Adversarial Examples
Formal Methods
让我们从 形式化方法(formal methods) 开始,因为它们更容易讨论。在芯片设计或航空航天与国防等行业工作过的人,对形式化方法一定不会陌生。对于其他人来说,形式化方法是一种数学技术,用于保证软件/硬件系统的鲁棒性。
在大多数软件中,如果设计或构建错误,可能会导致一些停机时间和一些愤怒的客户评论,但可能不会造成人员伤亡。但在某些行业,这种缺陷是不可接受的。你不可能在制造了 100 万个芯片后才发现芯片的某些部分存在缺陷,你也不可能把一架飞机送上天空,除非你用数学方法验证了每个部件都能按预期工作。
形式化方法的工作方式非常简单,就是尝试每一种可能的情况,并观察其结果如何。在规避攻击领域,这意味着在一定的扰动半径内,尝试生成每一种可能的对抗实例。举个例子,假设你有一张只有两个灰度像素的图像,比方说 180 和 80。然后,假设你决定每个方向的扰动范围为 3。这样就有 (3+1+3)² 或 49 种组合可供选择–如果你想正式验证这些组合都不具有对抗性,就必须将每种组合都放入你的模型中,看看另一端会出现什么。

一张 2 个像素的无色图像就有 49 种组合。那么一张 1000 x 1000 像素的彩色图像,每个方向的扰动范围都是 3 呢?这需要检查 ( 3 + 1 + 3 ) ( 3 ∗ 1000 ∗ 1000 ) (3+1+3)^{(3*1000*1000)} (3+1+3)(3∗1000∗1000) 种组合(EXCEL 拒绝生成数字)!
形式化方法它们并不便宜,而且从计算角度来看往往完全难以解决。事实上,就神经网络而言,当今最先进的形式化方法技术无法验证超过几层深度的网络。因此,就目前而言,这是一个值得实现但难以实现的愿望。
Empirical Defenses
经验防御(empirical defenses),顾名思义,就是依靠实验来证明防御的有效性。例如,你可能会对一个模型进行两次攻击–首先是一个正常的、未设防的版本,然后是一个加固的版本–并观察每个版本的易骗程度(希望加固的模型表现得更好)。
因此,formal methods 试图计算每一种可能的情况,并在计算过程中验证是否存在 adversarial examples,而 empirical methods 则采取 “你看到它有效,为什么还要计算 ”的方法。
下面我们就来介绍几种比较流行的方法:
- Adversarial training
- Gradient masking
- Input modification
- Detection
- Extra class
Adversarial training
对抗训练(Adversarial training)–当今最受关注的防御方法,也可以说是最有效的防御方法。在对抗训练过程中,防御者使用训练池中的对抗样本对模型进行再训练,但标注的是正确的标签。这可以教会模型忽略噪声,只从 “强大 ”的特征中学习。
对抗训练的问题在于,它只能使模型抵御用于制作训练池中初始样本的相同攻击。因此,如果有人使用不同的算法发起优化攻击,或发起自适应攻击(即对已防御模型发起白盒攻击),他们就能重新欺骗分类器,就像没有防御一样。
你可能会认为,你可以一遍又一遍地使用新伪造的对抗性示例来重新训练模型,但到了一定程度,你已经在训练集中插入了太多的虚假数据,以至于模型学习到的边界基本上变得毫无用处。

也就是说,如果目标只是让攻击者更难绕过分类器,那么对抗训练就是一个不错的选择。
Gradient masking
梯度掩蔽(gradient masking),这基本上是一种非防御手段。有一段时间,对抗性机器学习社区认为,由于需要梯度来计算对模型的强大攻击,因此隐藏梯度应该可以解决问题,但很快就被证明是错误的。
梯度掩蔽不能作为防御策略的原因是因为对抗样本的可转移性。即使您成功隐藏了模型的梯度,攻击者仍然可以构建代理,攻击它,然后传输示例。
Input modification
当输入在传递给模型之前以某种方式“清理”以消除对抗性噪声时,就会发生输入修改(input modification)。示例包括各种降噪解决方案(自动编码器、高级代表性降噪器)、颜色位深度缩减、平滑、重组 GAN、JPEG 压缩、注视点、像素偏转、通用基函数变换等等。
Detection
一些 检测(detection) 方法与输入修改密切相关——因为一旦输入被清理,它的预测就可以与原始预测进行比较,如果两者相距甚远,则输入可能已被篡改。这里有几个例子。
还一种方式。例如,在这里,他们实际上训练了一个单独的检测网络,其唯一的工作是确定输入是否是对抗性的。
一般来说,输入修改和检测方法很棒,因为它们可以应用于已经训练好的模型,并且不需要数据科学家重新训练模型。
Extra (NULL) Class
最后,还有额外的(NULL)类方法。这个想法很简单。分类器是根据非常特殊的数据分布进行训练的,根据定义,分类器在超出该分布范围时将毫无头绪。因此,与其在分类器显然不知道标签是什么的情况下强迫它猜测标签,不如给它放弃的选择。这就是 NULL 类所实现的功能(论文)。
Adversarial Attacks 和 Adversarial Defenses
对抗攻击(Adversarial Attacks)
对抗攻击是指恶意攻击者通过对输入数据进行精心设计的扰动,误导机器学习模型产生错误预测或决策的过程。这些扰动通常是微小的,不容易被人类察觉,但对于深度学习模型来说,它们可能会导致严重的错误。
对抗攻击通常基于以下几种方式:
Adversarial attacks 的目标
- 误分类(Misclassification):目标是使模型做出错误的预测。
- 目标攻击(Targeted Attack):攻击者希望模型输出特定的错误类别。
- 非目标攻击(Untargeted Attack):攻击者只希望模型输出错误类别,而不关心是哪个类别。
Adversarial attacks 的攻击方法
对抗攻击可以分为白盒攻击(White-box Attack)和黑盒攻击(Black-box Attack)两种主要类型。
-
白盒攻击(White-box Attack):
- 攻击者知道目标模型的所有信息,包括模型架构、权重参数等。
- 攻击者通常会利用梯度信息来生成对抗样本。
- 常见的白盒攻击方法有:
- FGSM (Fast Gradient Sign Method):利用目标模型的梯度信息,生成对抗样本。
- PGD (Projected Gradient Descent):多次迭代的改进版,生成更强的对抗样本。
- C&W Attack (Carlini & Wagner):通过优化目标函数来生成最小扰动的对抗样本。
-
黑盒攻击(Black-box Attack):
- 攻击者不知晓目标模型的具体结构和参数。
- 攻击者通过观察模型的输入输出(例如,通过API)来推测模型行为并生成对抗样本。
- 黑盒攻击的方式包括:
- 转移攻击(Transferability Attack):在一个模型上生成对抗样本并将其应用于另一个模型(即使目标模型不同)。
- 生成对抗网络(GAN):使用生成模型来创建对抗样本,通常也能迁移到其他模型。
对抗样本(Adversarial Examples)
对抗样本是通过对原始数据进行精心设计的小扰动生成的。这些扰动被设计为:
- 对人类观察者不可察觉;
- 对模型却能产生误导作用。
例如:
- 一张猫的图片可能经过轻微的调整后仍然是猫,但深度学习模型却把它误识别为“狗”。
- 一段正常的语音输入可能被扰动,使得语音识别系统误听为完全不同的指令。
Adversarial attacks 的影响
- 安全性威胁:对抗攻击可能使得机器学习系统变得不可靠,尤其是在关键领域(如自动驾驶、医疗诊断)中。
- 模型泛化能力差:对抗样本揭示了模型的脆弱性,表明模型在应对现实世界中的多样化数据时可能表现不稳定。
对抗防御(Adversarial Defenses)
对抗防御是指一系列技术,用于提高模型的鲁棒性,使其能够抵御对抗攻击,减少对抗样本的影响。以下是一些常见的对抗防御方法:
对抗训练(Adversarial Training)
- 核心思想:将对抗样本添加到训练数据中,强制模型学习如何正确处理这些被攻击的样本。
- 方法:
- 在训练过程中生成对抗样本,并将其与原始样本一起输入模型。
- 目标是让模型在训练时学习到鲁棒的特征,能够识别和应对扰动。
- 优点:
- 显著提高模型对抗攻击的鲁棒性。
- 缺点:
- 训练时间长,计算资源消耗大。
- 可能对正常样本的准确度造成一定影响。
输入预处理(Input Preprocessing)
- 核心思想:通过对输入数据进行预处理,减少对抗扰动的影响。
- 方法:
- 去噪(Denoising):去除输入中的噪声或扰动。
- 裁剪(Clipping):将输入数据限制在某个特定范围内,防止过大的扰动。
- 平滑化(Smoothing):平滑输入数据,减少对抗扰动的影响。
- 优点:
- 可以在不改变模型的情况下提高模型的鲁棒性。
- 缺点:
- 有时会降低模型对原始输入的准确性。
模型正则化(Model Regularization)
- 核心思想:通过添加正则化项,增加模型的复杂度限制,从而增强其对抗鲁棒性。
- 方法:
- 梯度惩罚(Gradient Penalty):惩罚模型梯度的过大波动,以防止过拟合对抗样本。
- 网络结构的鲁棒性:设计更加复杂的神经网络结构,使其对微小扰动不敏感。
- 优点:
- 提高了模型在不同输入下的稳定性。
- 缺点:
- 可能导致训练过程更加复杂,并且无法完全防止对抗样本的生成。
输入转换(Input Transformation)
- 核心思想:通过对输入进行某种变换,扰动会被减少或消除。
- 方法:
- 图像转换:如旋转、缩放、裁剪等图像变换。
- 加密(Encryption):对输入数据进行加密处理,使得攻击者无法有效生成对抗样本。
- 优点:
- 在实际部署中简单有效。
- 缺点:
- 可能降低模型的效率和性能。
模型架构的鲁棒性设计
- 核心思想:设计网络架构,使其对抗扰动具有天然的鲁棒性。
- 方法:
- 采用更深或更复杂的网络架构,提高模型对输入扰动的免疫力。
- 使用正则化技术、卷积层(在图像处理中)等方法提高模型的泛化能力。
- 优点:
- 提升模型整体性能,增强鲁棒性。
- 缺点:
- 架构复杂性增加,可能导致计算成本增加。
使用对抗样本的检测方法(Detection)
- 核心思想:利用专门的检测器来识别是否有对抗样本存在。
- 方法:
- 异常检测:监测输入是否与正常输入数据有显著差异。
- 模型行为分析:分析模型输出的稳定性,检查是否存在异常预测。
Randomized Neural Networks
Randomized Neural Networks (随机化神经网络) 是一种利用随机化策略设计的神经网络模型。它们的特点是部分或全部网络的参数是随机初始化的,并在训练过程中保持固定,或者以随机方式参与计算。这种方法广泛用于减少计算复杂性、提升泛化能力,以及探索神经网络的鲁棒性。
Randomized neural networks 的关键特性
-
随机性(Randomization):
- 权重随机化:随机初始化权重,并在训练过程中保持不变,或者仅对部分层进行优化。
- 结构随机化:通过随机选择神经元或连接方式,生成多样化的网络结构。
- 输入或噪声随机化:在训练或推理过程中,向输入或中间层添加随机噪声以增强鲁棒性。
-
固定性:
- 在某些随机化神经网络中,随机权重是固定的,这意味着无需优化这些参数。这种方法有助于降低训练复杂性。
-
快速计算:
- 因为部分参数无需优化,计算和存储需求显著减少,适用于资源受限的环境。
Randomized neural networks 的常见类型
以下是随机化神经网络的一些典型实现:
Extreme Learning Machines (ELMs)
- 这是随机化神经网络的经典示例。
- 核心思想:
- 隐藏层的权重随机初始化并固定。
- 仅优化输出层权重(通常通过线性回归求解)。
- 优点:
- 训练速度极快。
- 简单高效,适用于小规模数据集。
- 缺点:
- 对随机权重敏感,泛化能力可能受限。
Random Vector Functional Link (RVFL)
- 是对传统神经网络的扩展。
- 核心思想:
- 在网络中添加随机生成的特征(通过随机化权重获得)。
- 通过连接这些随机特征和原始特征提高表达能力。
Stochastic Neural Networks (SNNs)
- 在每个神经元或连接中引入随机性。
- 应用场景:
- 提高鲁棒性和模型的不确定性量化。
- 在生成模型中,比如生成对抗网络(GANs)。
Dropout & Randomized Activation
- Dropout 是一种常见的随机化技术,用于训练过程中随机丢弃部分神经元。
- 随机化激活函数选择可以增加模型的多样性。
Randomized neural networks 的理论基础
-
随机特征的理论支持:
- 在高维空间中,随机映射可以生成良好的特征表示。
- 核函数理论(Kernel Theory)表明,随机权重生成的隐层表示可以近似核映射。
-
泛化能力:
- 随机化策略通过增加模型的多样性,通常有助于提升模型的泛化能力。
-
鲁棒性:
- 随机化神经网络在对抗攻击和噪声处理方面往往表现较好,因为它们对输入扰动的敏感性降低。
参考资料
About Adversarial Examples
Evasion attacks on Machine Learning (or “Adversarial Examples”)
Tricking Neural Networks: Create your own Adversarial Examples
什么是对抗样本、对抗攻击(详解)
相关文章:
Adversarial Machine Learning(对抗机器学习)
之前把机器学习(Machine Learning)的安全问题简单记录了一下,这里有深入研究了一些具体的概念,这里记录一下方便以后查阅。 Adversarial Machine Learning(对抗机器学习) Adversarial Examples 相关内容Eva…...

每日十题八股-2024年12月23日
1.MySQL如何避免重复插入数据? 2.CHAR 和 VARCHAR有什么区别? 3.Text数据类型可以无限大吗? 4.说一下外键约束 5.MySQL的关键字in和exist 6.mysql中的一些基本函数,你知道哪些? 7.SQL查询语句的执行顺序是怎么样的&…...

Android Studio新建项目在源码中编译
新建空白项目 用AS新建默认空项目,代码目录如下: MyApplication$ tree -L 4 . ├── Android.bp // bp编译脚本 ├── Android.mk.bak // mk编译脚本 ├── app // 下面目录结构是AS新建工程目录 │ ├── build.gradle │ ├── pro…...

ubuntu使用ffmpeg+ZLMediaKit搭建rtsp推流环境
最方便的方式,ubuntu上安装vlc播放器,通过vlc来推流,在网上有很多教程。这里采用ffmpegZLMediaKit 必备条件: 1、安装ffmpeg 2、安装ZLMediaKit 一、安装ffmpeg sudo apt update sudo apt install ffmpeg 二、安装ZLMediaKit…...

vue中的css深度选择器v-deep 配合!important
当 <style> 标签有 scoped 属性时,它的 CSS 只作用于当前组件中的元素,父组件的样式将不会渗透到子组件。 如果你希望 scoped 样式中的一个选择器能够作用得“更深”,例如影响子组件,你可以使用深度选择器。 ::v-deep { } 举…...

Python读写JSON文件
import jsondef writeJSONFile(self):with open(g_updateFilePath, "w" encodingutf-8) as fiel:json.dump(dictData, fiel, indent4, ensure_asciiFalse)fiel.close()def readJsonToDict(file):with open(file, r, encodingutf-8) as f: # 确保文件以 UTF-8 编码打…...

重温设计模式--外观模式
文章目录 外观模式(Facade Pattern)概述定义 外观模式UML图作用 外观模式的结构C 代码示例1C代码示例2总结 外观模式(Facade Pattern)概述 定义 外观模式是一种结构型设计模式,它为子系统中的一组接口提供了一个统一…...

云原生服务网格Istio实战
基础介绍 1、Istio的定义 Istio 是一个开源服务网格,它透明地分层到现有的分布式应用程序上。 Istio 强大的特性提供了一种统一和更有效的方式来保护、连接和监视服务。 Istio 是实现负载平衡、服务到服务身份验证和监视的路径——只需要很少或不需要更改服务代码…...

linux蓝牙模块和手机配对
在 Linux 系统下,将蓝牙模块与手机配对和连接通常涉及以下几个步骤。以下是详细的步骤和命令,帮助你实现蓝牙模块与手机的配对和连接。 1. 确认蓝牙服务已启动 首先,确保蓝牙服务已在 Linux 系统上运行。 systemctl status bluetooth如果服…...

dockerfile文档编写(1):基础命令
目录 Modelscope-agentARGFROMWORKDIRCOPYRUNENVCMD run_loopy Modelscope-agent ARG BASE_IMAGEregistry.cn-beijing.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda12.1.0-py310-torch2.1.2-tf2.14.0-1.12.0FROM $BASE_IMAGEWORKDIR /home/workspaceCOPY . /hom…...

在 Go 中利用 ffmpeg 进行视频和音频处理
在 Go 中利用 ffmpeg 进行视频和音频处理 ffmpegutil 包概述主要功能介绍1. 视频格式转换2. 提取音频3. 获取视频信息4. 创建视频缩略图5. 提取随机帧无线程版本:多线程版本: 总结 ffmpeg 是一款功能强大的多媒体处理工具,支持视频和音频的编…...

【机器学习】探索机器学习与人工智能:驱动未来创新的关键技术
探索机器学习与人工智能:驱动未来创新的关键技术 前言:人工智能的核心技术深度学习:自然语言处理(NLP):计算机视觉: 机器学习与人工智能的驱动创新医疗健康领域金融行业智能制造与工业互联网智慧…...

React Refs 完整使用指南
React Refs 完整使用指南 1. Refs 基础用法 1.1 创建和访问 Refs // 类组件中使用 createRef class MyComponent extends React.Component {constructor(props) {super(props);this.myRef React.createRef();}componentDidMount() {// 访问 DOM 节点console.log(this.myRef…...

程控电阻箱应用中需要注意哪些安全事项?
程控电阻箱是一种用于精确控制电路中电流和电压的电子元件,广泛应用于电子实验、测试设备以及精密测量仪器中。在应用程控电阻箱时,为确保安全和设备的正常运行,需要注意以下几个安全事项: 1. 正确连接:确保电阻箱与电…...
)
C/C++基础知识复习(43)
1) 什么是运算符重载?如何在 C 中进行运算符重载? 运算符重载是指在 C 中为现有的运算符定义新的行为,使得它们能够用于用户定义的数据类型(如类或结构体)。通过运算符重载,可以让自定义类型像内置数据类型…...

苍穹外卖-day05redis 缓存的学习
苍穹外卖-day05 课程内容 Redis入门Redis数据类型Redis常用命令在Java中操作Redis店铺营业状态设置 学习目标 了解Redis的作用和安装过程 掌握Redis常用的数据类型 掌握Redis常用命令的使用 能够使用Spring Data Redis相关API操作Redis 能够开发店铺营业状态功能代码 功能实…...
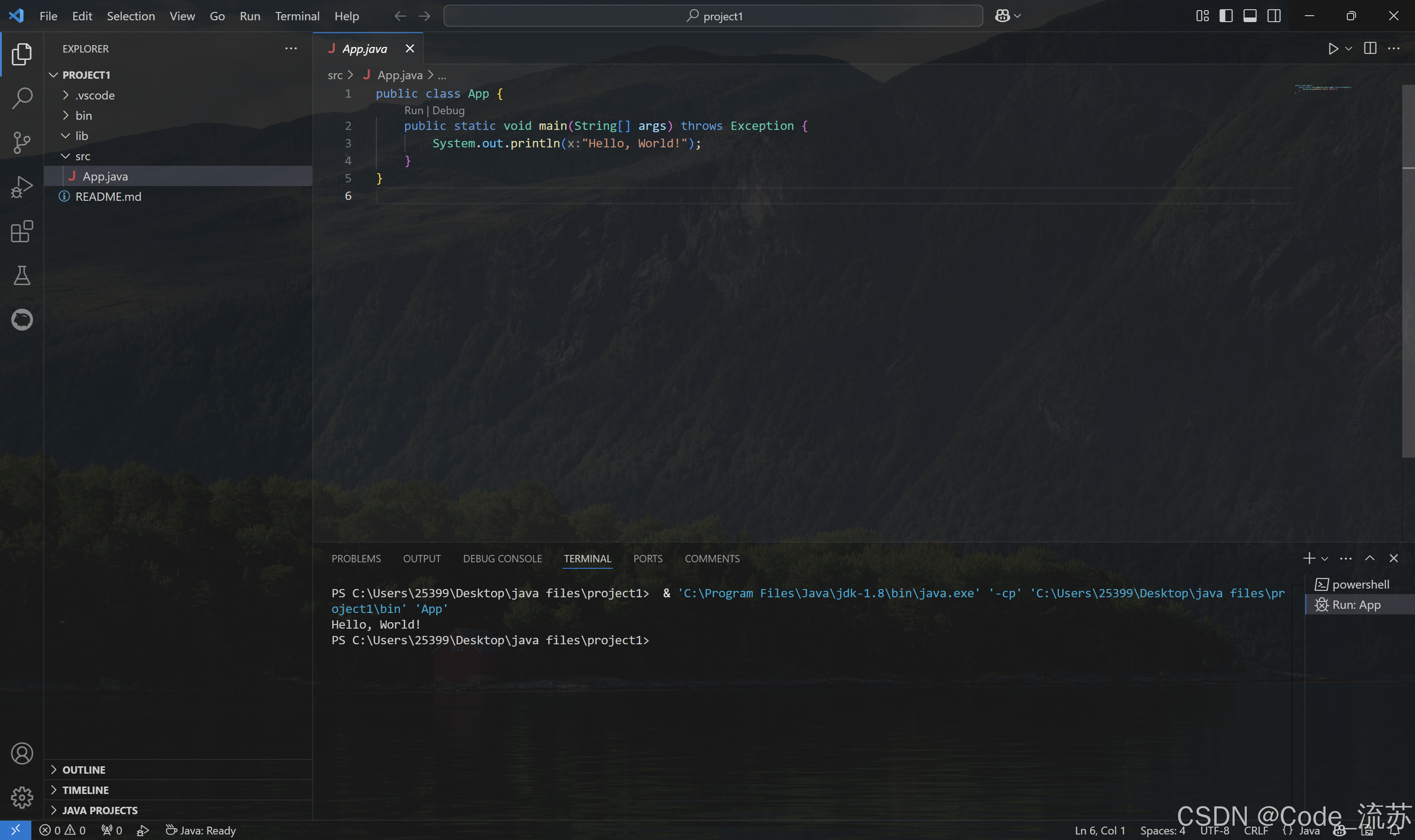
VSCode搭建Java开发环境 2024保姆级安装教程(Java环境搭建+VSCode安装+运行测试+背景图设置)
名人说:一点浩然气,千里快哉风。—— 苏轼《水调歌头》 创作者:Code_流苏(CSDN) 目录 一、Java开发环境搭建二、VScode下载及安装三、VSCode配置Java环境四、运行测试五、背景图设置 很高兴你打开了这篇博客,更多详细的安装教程&…...

PHP MySQL 插入多条数据
PHP MySQL 插入多条数据 在Web开发中,PHP和MySQL的组合是非常常见的。PHP是一种服务器端脚本语言,而MySQL是一种流行的数据库管理系统。在许多情况下,我们可能需要一次性向MySQL数据库插入多条数据。这可以通过几种不同的方法实现࿰…...

Oracle安装报错:将配置数据上载到资料档案库时出错
环境:联想服务器 windows2022安装Oracle11g 结论:禁用多余网卡先试试,谢谢。 以下是问题描述和处理过程: 网上处理方式: hosts文件添加如下: 关闭防火墙 暂时无法测试通过。 发现ping不是本地状态,而是…...

JavaScript 中通过Array.sort() 实现多字段排序、排序稳定性、随机排序洗牌算法、优化排序性能,JS中排序算法的使用详解(附实际应用代码)
目录 JavaScript 中通过Array.sort() 实现多字段排序、排序稳定性、随机排序洗牌算法、优化排序性能,JS中排序算法的使用详解(附实际应用代码) 一、为什么要使用Array.sort() 二、Array.sort() 的使用与技巧 1、基础语法 2、返回值 3、…...

RedTeam_BlueTeam_HW蓝队视角:如何构建坚不可摧的安全防线
RedTeam_BlueTeam_HW蓝队视角:如何构建坚不可摧的安全防线 【免费下载链接】RedTeam_BlueTeam_HW 红蓝对抗以及护网相关工具和资料,内存shellcode(csmsf)和内存马查杀工具 项目地址: https://gitcode.com/gh_mirrors/re/RedTeam…...
Pixel Script Temple 性能对比展示:不同参数下的生成速度与质量
Pixel Script Temple 性能对比展示:不同参数下的生成速度与质量 1. 开场白:为什么需要性能测试 当你第一次接触Pixel Script Temple这个强大的图像生成工具时,可能会被它丰富的参数设置搞得有点懵。生成步数调多少合适?分辨率选…...

DeepAnalyze在供应链管理中的预测分析应用
DeepAnalyze在供应链管理中的预测分析应用 1. 引言 想象一下,一家零售企业的库存经理每天面对这样的困境:某些商品堆积如山却卖不出去,而热销商品却频频缺货。传统的供应链管理系统往往依赖历史数据和简单算法,难以准确预测市场…...
)
避坑指南:FCOS环境配置与训练中那些版本依赖的“坑”和解决方案(PyTorch 1.0+)
FCOS实战避坑手册:从环境配置到训练优化的全流程解决方案 如果你正在尝试部署FCOS目标检测模型,却频繁遭遇环境配置失败、版本冲突或训练异常等问题,这篇文章将为你提供一份详尽的避坑指南。不同于常规教程,这里聚焦于那些官方文档…...

Qwen3.5-9B代码生成效果:单元测试自动生成+边界条件覆盖分析
Qwen3.5-9B代码生成效果:单元测试自动生成边界条件覆盖分析 1. 开篇:认识Qwen3.5-9B代码生成能力 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,在代码生成领域展现出惊人的能力。不同于普通代码补全工具,它能理解复杂编程逻辑…...

如何用BilibiliDown轻松下载B站视频:免费跨平台视频下载器终极指南
如何用BilibiliDown轻松下载B站视频:免费跨平台视频下载器终极指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/…...

源码级交付的低代码革命:基于 Spring Boot 的 AI 视频中台二次开发实战
引言:从“项目定制”到“产品化”的跨越之痛 作为一名在安防行业摸爬滚打多年的架构师,我深知行业内的一个悖论:客户想要的是“开箱即用”的成熟产品,而现实场景却要求“千企千面”的深度定制。传统的开发模式下,为了满…...

第三十三课:LIF神经元模型与SpikingJelly实战解析
1. LIF神经元模型:从生物启发的数学原理说起 第一次看到LIF(Leaky Integrate-and-Fire)神经元时,我脑海中浮现的是中学物理课上那个总在漏电的电容器。这种神经元模型之所以被称为"漏电积分放电",正是因为它…...

全自动铺布机选购指南:核心指标与品牌实力评估
投资一台全自动铺布机是企业的重要决策。如何在海量品牌中做出最优选择?关键在于穿透营销宣传,从“硬指标”和“软实力”两个维度进行综合评估。核心性能指标张力控制精度:这是衡量铺布机性能的核心指标。直接决定能否处理针织、弹力、真丝等…...

Google将NotebookLM深度整合进Gemini,AI研究工具再升级
NotebookLM深度嵌入Gemini,打造便捷研究新体验近日,Google宣布将AI驱动的研究工具NotebookLM深度整合至Gemini应用中。此次更新带来了显著变化,用户能够直接在Gemini侧边栏创建“笔记本”,并且可添加PDF、文档、网址、YouTube视频…...