C语言——数据在内存中的存储
目录
前言
一数据类型
类型归类
二整形在内存中的存储
原反补码
大小端
相关练习题
三浮点数在内存中的储存
浮点数储存规则
前言
只有取学习数据在内存中的存储,我们在以后才能定义好(用好)各种类型的数据!
一数据类型
前面我们已经学习了基本的内置类型,和它们所占存储空间的大小。
char //字符数据类型short //短整型int //整形long //长整型long long //更长的整形float //单精度浮点数double //双精度浮点数类型的意义:
1. 使用这个类型开辟内存空间的大小(大小决定了使用范围)。
2. 如何看待内存空间的视角
类型归类
整形家族
char //== (默认是) signed char?这个C语言没规定//为什么char被归为整行家族? 因为字符在内存储存时按照ASCALL码来的!unsigned charsigned charshortunsigned short [int]signed short [int]int //== (默认是) signed intunsigned intsigned intlongunsigned long [int]signed long [int]浮点数家族
floatdouble构造家族(后面学)
数组类型结构体类型 struct枚举类型 enum联合类型指针家族
int *pi;char *pc;float* pf;void* pv;空家族
void 表示空类型(无类型) 通常应用于函数的返回类型、函数的参数、指针类型
二整形在内存中的存储
我们之前讲过一个变量的创建是要在内存中开辟空间的,它的大小是根据不同的类型而决定的
那如何储存?
原反补码
计算机中的整数有三种2进制表示方法:即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”;
正数的原、反、补码都相同;
负数需要从原码转成补码~
原码
直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码
将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码
反码+1就得到补码。
对于一个整形来说:数据存放内存中其实存放的是补码
为什么??
原因在于,使用补码,可以将符号位和数值域统一处理;(如1+ (-1) 是就不用担心符号位要不要加的问题:-1转成补码后与1相加结果有33位,第一位(1)符号位丢弃就是答案0)
同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路
但在内存中我们发现:存的顺序有点不对劲,怎么是倒着存的??

大小端
什么大端小端?
大端(存储)模式:是指数据的低位,保存在内存的高地址中,而数据的高位,保存在内存的低地址中;(低高高低) 数据的低位和高位是从bit位从右向左(从低到高)来看的
小端(存储)模式:是指数据的低位,保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。(低低高高)
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题:因此就导致了大端存储模式和小端存储模式。在我看来,这就只不过定了一个规矩:下次从内存中拿字节时知道怎么拿出来而已~
设计一个小程序来判断当前机器的字节序
#include<stdio.h>int check_sys(int i)
{char* p = (char*)&i;//(char)i 这时不对的:这只是对值进行转化!return *p;
}int main()
{if (check_sys(1)) printf("小端\n");else printf("大端\n");return 0;
}相关练习题
#include <stdio.h>
int main()
{char a= -1;signed char b=-1;unsigned char c=-1;printf("a=%d,b=%d,c=%d",a,b,c);return 0;
}
#include <stdio.h>
int main()
{char a = -128;char b = 128;printf("%u\n",a);printf("%u\n",b);return 0;
}
#include<stdio.h>int main()
{int i= -20;unsigned int j = 10;printf("%d\n", i+j);return 0;
}
int main()
{char a[1000];int i;for (i = 0; i < 1000; i++){a[i] = -1 - i;}printf("%d", strlen(a));return 0;
}
三浮点数在内存中的储存
以一段代码来引出接下来的内容:
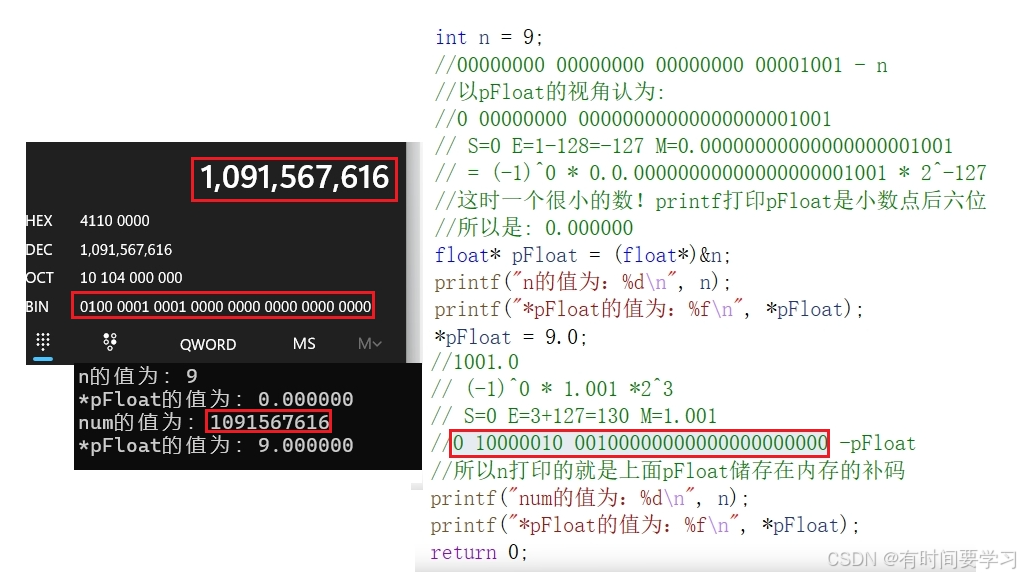
int main()
{int n = 9;float* pFloat = (float*)&n;printf("n的值为:%d\n", n);printf("*pFloat的值为:%f\n", *pFloat);*pFloat = 9.0;printf("num的值为:%d\n", n);printf("*pFloat的值为:%f\n", *pFloat);return 0;
}以上运行结果是什么呢??

对结果是不是感到很奇怪:
num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大?
接下来我们来介绍浮点数的储存规则
浮点数储存规则
根据国际标准IEE(电气和电子工程协会)754:任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^S 表示符号位,当S=0,V为正数;当S=1,V为负数;
M 表示有效数字:范围大于等于1,小于2;
2^E 表示指数位
例如:
十进制的5.0,写成二进制是 101.0 ,相当于 (-1)^ 0 * 1.01 * 2^2 。那么,按照上面V的格式得出:
S=0,M=1.01,E=2
而这些数跟浮点数储存有什么关系呢?
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位S,接着的8位是指数E,剩下的23位为有效数字M

对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M

对于有效数字M:
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的小数点后面的数;等到读取的时候,再把第一位的1加上去;这样做的目的,是节省1位有效数字,在内存中可以多出来1位表达
对于指数E:
首先规定了E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。 但是,我们知道,科学计数法中的E是可以出现负数的! 所以在存入内存时E的真实值必须再加上一个中间数进行'矫正'; 对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023
那究竟在内存中是不是这样呢?我们用一个例子要演示下:

而E从内存中取出来时分三种情况:
1 E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将
有效数字M前补上第一位的1;
2 E全为0
这时,浮点数的指数E等于 1-127(或者1-1023)即为真实值,
有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于
0的很小的数字;
3 E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s)
有了上面的铺垫,在来解释开头的代码,此时应该就能理解啦
以上便是全部内容,有错误欢迎再评论区指出,感谢观看~
相关文章:
C语言——数据在内存中的存储
目录 前言 一数据类型 类型归类 二整形在内存中的存储 原反补码 大小端 相关练习题 三浮点数在内存中的储存 浮点数储存规则 前言 只有取学习数据在内存中的存储,我们在以后才能定义好(用好)各种类型的数据! 一数据类型…...
Python(二)str、list、tuple、dict、set
string name abcdefprint(name[0]) #a # 切片:取部分数据 print(name[0:3]) # 取 下标为0,1,2的字符 abc print(name[2:]) # 取 下标为2开始到最后的字符 cdef print(name…...
如何在谷歌浏览器中设置邮件客户端
在日常生活和工作中,电子邮件已经成为不可或缺的沟通工具。对于使用谷歌浏览器的用户来说,将Chrome设置为默认邮件客户端可以带来诸多便利。本文将详细介绍如何在谷歌浏览器中设置邮件客户端,帮助大家轻松实现这一目标。 在谷歌浏览器中设置邮…...

Robot Framework搭建自动化测试框架
1.配置环境 需要安装jdk8,andrid sdk(安装adb),pycharm编译环境以及软件 安装Robot Framework 首先,你需要安装Robot Framework,可以使用 pip 进行安装: pip install robotframework安装所需的…...

Linux——字符设备驱动控制LED
目录 驱动模块的加载和卸载 驱动程序Makefile编写 字符设备注册与注销 字符设备驱动模板 应用程序对驱动读写操作 iounmap函数 LED寄存器物理地址映射到虚拟地址 应用程序代码编写 Linux驱动的两种运行方式: 1、将驱动编译进Linux内核中,也就是zIm…...

云边端架构的优势是什么?面临哪些挑战?
一、云边端架构的优势 降低网络延迟:在传统集中式架构中,数据需传输到云计算中心处理,导致网络延迟较高。而云边端架构将计算和存储推向边缘设备,可在离用户更近的地方处理数据,大大降低了网络延迟,提升了用…...

Effective C++ 条款 01:视 C++ 为一个语言联邦
文章目录 条款 01:视 C 为一个语言联邦关键点 条款 01:视 C 为一个语言联邦 C 是一个复杂而多样化的编程语言,可以将其视为由多个子语言(sublanguage)组成的联邦。为了更好地理解和使用 C,需要认识它的四个…...

Redis分布式锁释放锁是否必须用lua脚本?
无lua脚本释放锁: public void unlock(String key, String uniqueValue) {String value redisDao.getString(key);if (value ! null && value.equals(uniqueValue))redisDao.delete(key); }使用lua脚本释放锁: // LUA脚本 -> 分布式锁解锁原…...

JVM系列(十三) -常用调优工具介绍
最近对 JVM 技术知识进行了重新整理,再次献上 JVM系列文章合集索引,感兴趣的小伙伴可以直接点击如下地址快速阅读。 JVM系列(一) -什么是虚拟机JVM系列(二) -类的加载过程JVM系列(三) -内存布局详解JVM系列(四) -对象的创建过程JVM系列(五) -对象的内存分…...

数据中心虚拟化与高可用性架构实施指南
数据中心虚拟化与高可用性架构实施指南 项目背景 随着业务的不断扩展和技术的迭代更新,公司决定采用虚拟化技术和构建高可用性架构来提高数据中心的资源利用率和业务连续性。本项目旨在详细描述运维人员在实施数据中心虚拟化和高可用性架构过程中的关键步骤和任务…...

对文件内的文件名生成目录,方便查阅
import os import re# 定义要查找的目录路径 path r"J:\...\顺序目录" # 要遍历的主目录路径# 定义输出的目录文件路径 output_file r"J:\...\目录_中文文件.txt" # 保存结果的文件路径# 判断文件名是否包含中文字符 def contains_chinese(text):retur…...

leetcode hot100 轮转数组
189. 轮转数组 已解答 中等 相关标签 相关企业 提示 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮…...

定位方式:css
使用相对路径 div ul #div下的所有ul,空格表示相对路径(这个实际中用的多一些) 绝对路径-一般不用绝对路径 html>head>div,“>”表示根路径 使用class名称定位 使用.表示 使用id定位 使用#表示 使用属性定位 [属性名…...

谷歌浏览器的网络连接问题解决方案
在数字化时代,网络浏览器已成为日常工作和生活中不可或缺的工具。谷歌浏览器以其快速、稳定和丰富的功能深受用户喜爱。然而,就像其他软件一样,谷歌浏览器也可能遇到网络连接问题,这可能由多种因素引起。本文将为您提供一系列解决…...

保护模式基本概念
CPU 架构 RISC(Reduced Instruction Set Computer) 中文即"精简指令集计算机”。RISC构架的指令格式和长度通常是固定的(如ARM是32位的指令)、且指令和寻址方式少而简单、大多数指令在一个周期内就可以执行完毕 CISC&…...
| 学习笔记)
Linux程序设计(第四版)| 学习笔记
上次学习Linux相关内容还是上学的时候为了应付考试,最近有项目涉及Linux,重新学习以下。 很多年前关于Linux的总结 一、入门 1.概念 (1) UNIX 1)定义:指的是一种遵循特定规范的计算机操作系统。 2)特点:简单性、集中性、可重用…...

【Python-中级】Python中的线程池:ThreadPoolExecutor
Python中的线程池:from concurrent.futures import ThreadPoolExecutor 在Python中,实现多线程编程的方法有很多,而ThreadPoolExecutor 是一个简单且高效的线程池工具。它提供了高层次的接口,用于并发地运行任务,同时隐藏了许多复杂的底层细节,非常适合日常的多线程任务…...

医疗信息系统有哪些
医疗信息系统(Health Information Systems, HIS)是用于管理和存储患者健康数据、医疗记录、医院运营数据等信息的技术平台。这些系统通过自动化、集成和分析数据,提高医疗服务的效率、质量和安全性。以下是一些主要的医疗信息系统及其功能&am…...

JVM系列(十二) -常用调优命令汇总
最近对 JVM 技术知识进行了重新整理,再次献上 JVM系列文章合集索引,感兴趣的小伙伴可以直接点击如下地址快速阅读。 JVM系列(一) -什么是虚拟机JVM系列(二) -类的加载过程JVM系列(三) -内存布局详解JVM系列(四) -对象的创建过程JVM系列(五) -对象的内存分…...

修改采购订单BAPI学习研究-BAPI_PO_CHANGE
这里是修改采购订单BAPI,修改订单数量的简单应用 代码 *&---------------------------------------------------------------------* *& Report Z_BAPI_PO_CHANGE *&---------------------------------------------------------------------* *& C…...

第六周作业xy
文章目录1.数码管显示6个91.1效果展示1.2代码显示2.数码管显示2个7(一头一尾)2.1效果展示2.2代码显示3.数码管轮播显示6位3.1效果展示3.2代码显示4.数码管轮播显示两位4.1效果展示4.2代码显示5.数码管跑马灯5.1效果展示5.2代码显示6.小数点数码管6.1效果…...
---HITL(Human In The Loop)鬃)
【GUI-Agent】阶跃星辰 GUI-MCP 解读---()---HITL(Human In The Loop)鬃
插件化架构 v3 版本最大的变化是引入了模块化插件系统。此前版本中集成在核心包里的原生功能,现在被拆分成独立的插件。 每个插件都是一个独立的 Composer 包,包含 Swift 和 Kotlin 代码、权限清单以及原生依赖。开发者只需安装实际用到的插件࿰…...

【数据库系统】数据库系统概论——第十二章 数据库管理系统
第十二章 数据库管理系统 文章目录 第十二章 数据库管理系统 12.1数据库管理系统的基本功能 12.2数据库管理系统的系统结构 12.2.1数据库管理系统的层次结构 12.2.2关系数据库管理系统的运行过程示例 12.3语言处理层 12.3.1语言处理层的任务和工作步骤 12.3.2解释方法 12.3.3预…...
【MATLAB源码-第405期】基于matlab的OFDM深度学习信道估计仿真,对比LS,MMSE,CNN,LSTM、Transformer.
操作环境:MATLAB 2024a1、算法描述摘要 OFDM作为现代无线通信系统中极具代表性的多载波传输技术,因其频谱利用率高、抗多径能力强以及易于与高速数字信号处理技术结合等优点,被广泛应用于宽带移动通信、无线局域网、卫星通信以及新一代智能通…...

嵌入式c语言——关键字4
typedef 给数据类型起个别名,使得对程序的可读性更高吗,同时和#define不一样typedeff是关键字,对已经存在的数据类型取别名。 在编译阶段处理,会进行类型检查,只能在定义的作用域内使用。 define是预处理指令ÿ…...

Blazor组件化演进终极指南:2026年必须掌握的5大架构范式与3种反模式规避清单
第一章:Blazor组件化演进的底层动因与2026技术坐标系Blazor 的组件化并非单纯语法糖的迭代,而是对 Web 前端架构范式、.NET 生态边界以及现代云原生交付链路三重压力下的系统性响应。其底层动因根植于三个不可逆趋势:WebAssembly 运行时成熟度…...

[资源] 【百度网盘 】最终幻想战略版 伊瓦利斯编年史 豪华中文 Build.20688883+全DLC-支持手柄
受太阳与圣印保佑,由双头狮统治的国家――――Ivalice。Ivalice与邻国Ordallia展开“The Fifty Years’ War”却战败。一年后先王病逝,而将要继承王位的王子年仅两岁。此后为争夺监护人的头衔与实权,在“The Fifty Years’ War”立下战功的两…...

别再数据线了!用FastAPI 分钟搭个局域网文件+剪贴板神器志
为 HagiCode 添加 GitHub Pages 自动部署支持 本项目早期代号为 PCode,现已正式更名为 HagiCode。本文记录了如何为项目引入自动化静态站点部署能力,让内容发布像喝水一样简单。 背景/引言 在 HagiCode 的开发过程中,我们遇到了一个很现实的问…...

突破平台壁垒:3种方法让Windows直接运行安卓应用
突破平台壁垒:3种方法让Windows直接运行安卓应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 当你在电脑前急需使用手机专属办公软件,却只能…...

打字不如说话,说话不如截图——AI 代码助手的多模态输入实践不
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...