基于深度可分离卷积的MNIST手势识别
基于深度可分离膨胀卷积的MNIST手写体识别
Github链接
项目背景:
MNIST手写体数据集是深度学习领域中一个经典的入门数据集,包含了从0到9的手写数字图像,用于评估不同模型在图像分类任务上的性能。在本项目中,我们通过设计一种基于深度可分离膨胀卷积的神经网络模型,解决模型参数量大与特征提取能力不足之间的矛盾,同时实现对MNIST手写数字的高效识别。
核心技术:
- 深度卷积:
深度卷积(Depthwise Convolution)将标准卷积分解为每个通道独立的卷积操作,从而显著减少计算量。相比传统卷积操作,深度卷积只需要处理每个通道的卷积,不会引入通道间的冗余计算。 - 点卷积:
点卷积(Pointwise Convolution)采用1×1的卷积核,用于整合深度卷积生成的特征,将通道间信息融合,增强表达能力。点卷积是深度可分离卷积不可或缺的部分,负责重建多通道的全局信息。 - 膨胀卷积:
膨胀卷积(Dilated Convolution)通过在卷积核间插入空洞扩展感受野,允许模型捕获更大范围的上下文信息,特别适合处理具有稀疏特征的任务,同时避免了增加参数量的开销。

实现流程:
- 数据准备:
- 加载MNIST数据集,进行标准化预处理。
- 将数据分为训练集和测试集,保证模型的评估结果具备可靠性。
- 模型设计:
- 构建基于深度卷积、点卷积及膨胀卷积的神经网络结构,重点在于设计轻量化且具有良好表达能力的卷积模块。
- 使用ReLU激活函数和全连接层对提取的特征进行分类处理。
- 模型训练与测试:
- 使用交叉熵损失函数和Adam优化器训练模型,记录损失值变化以监控收敛情况。
- 测试阶段,评估模型在MNIST测试集上的分类准确率,并验证其泛化能力。
- 参数量对比分析:
- 对比标准卷积和深度可分离卷积在参数量上的差异,直观展示优化效果。
- 在同等条件下,深度可分离卷积显著减少参数量,同时保持了分类性能的稳定性。
项目成果:
通过本项目的实验,模型在MNIST数据集上的分类准确率达到了接近 98.7% 的水平。结合深度可分离膨胀卷积的轻量化设计,我们在大幅减少参数量的同时,实现了与传统卷积模型媲美的性能。此方法为资源受限的场景(如移动设备和嵌入式系统)提供了一种有效的解决方案。
结论与展望:
本项目展示了深度可分离膨胀卷积在图像分类任务中的强大能力,特别是在参数量和计算量优化方面。未来的工作可以尝试将该方法应用于更复杂的数据集和任务场景,例如自然图像分类、目标检测或语义分割,从而进一步验证其通用性与潜力。
# @Time : 28/12/2024 上午 10:00
# @Author : Xuan
# @File : 基于深度可分离膨胀卷积的MNIST手写体识别.py
# @Software: PyCharmimport torch
import torch.nn as nn
import einops.layers.torch as elt
from torchvision import datasets, transforms
import matplotlib.pyplot as plt# 定义数据转换
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])# 下载并加载训练集
train_dataset = datasets.MNIST(root='./dataset', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)# 下载并加载测试集
test_dataset = datasets.MNIST(root='./dataset', train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=False)# 检查数据集大小
print(f'Train dataset size: {len(train_dataset)}') # Train dataset size: 60000
print(f'Test dataset size: {len(test_dataset)}') # Test dataset size: 10000class Model(nn.Module):def __init__(self):super(Model, self).__init__()# 深度、可分离、膨胀卷积self.conv = nn.Sequential(nn.Conv2d(1, 12, kernel_size=7),nn.ReLU(),nn.Conv2d(in_channels=12, out_channels=12, kernel_size=3, groups=6, dilation=2),nn.Conv2d(in_channels=12, out_channels=24, kernel_size=1),nn.ReLU(),nn.Conv2d(24, 6, kernel_size=7),)self.logits_layer = nn.Linear(in_features=6 * 12 * 12, out_features=10)def forward(self, x):x = self.conv(x)x = elt.Rearrange('b c h w -> b (c h w)')(x)logits = self.logits_layer(x)return logitsdevice = "cuda" if torch.cuda.is_available() else "cpu"
model = Model().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)epochs = 10
for epoch in range(epochs):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()if batch_idx % 100 == 0:print(f'Epoch: {epoch}, Batch: {batch_idx}, Loss: {loss.item()}')# Save the model
torch.save(model.state_dict(), './modelsave/mnist.pth')# Load the model
model = Model().to(device)
model.load_state_dict(torch.load('./modelsave/mnist.pth'))# Evaluation
model.eval()
correct = 0
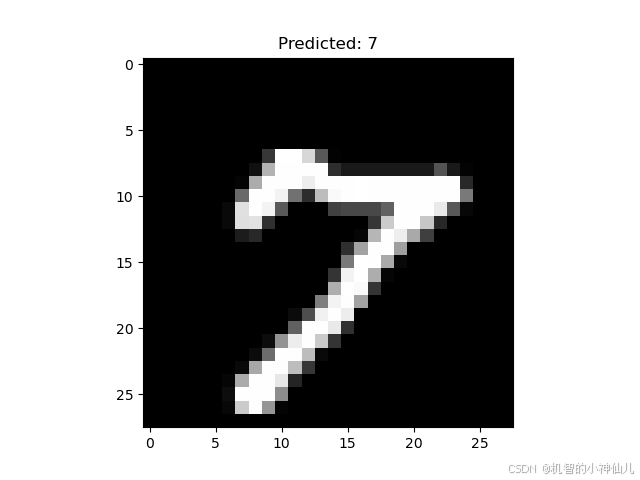
first_image_displayed = False
with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()# Display the first image and its predictionif not first_image_displayed:plt.imshow(data[0].cpu().numpy().squeeze(), cmap='gray')plt.title(f'Predicted: {pred[0].item()}')plt.show()first_image_displayed = Trueprint(f'Test set: Accuracy: {correct / len(test_loader.dataset):.4f}') # Test set: Accuracy: 0.9874# 深度可分离卷积参数比较
# 普通卷积参数量
conv = nn.Conv2d(in_channels=3 ,out_channels=3, kernel_size=3) # in(3) * out(3) * k(3) * k(3) + out(3) = 84
conv_params = sum(p.numel() for p in conv.parameters())
print('conv_params:', conv_params) # conv_params: 84# 深度可分离卷积参数量
depthwise = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, groups=3) # in(3) * k(3) * k(3) + out(3) = 30
pointwise = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=1) # in(3) * out(3) * k(1) * k(1) + out(3) = 12
depthwise_separable = nn.Sequential(depthwise, pointwise)
depthwise_separable_params = sum(p.numel() for p in depthwise_separable.parameters())
print('depthwise_separable_params:', depthwise_separable_params) # depthwise_separable_params: 42
相关文章:
基于深度可分离卷积的MNIST手势识别
基于深度可分离膨胀卷积的MNIST手写体识别 Github链接 项目背景: MNIST手写体数据集是深度学习领域中一个经典的入门数据集,包含了从0到9的手写数字图像,用于评估不同模型在图像分类任务上的性能。在本项目中,我们通过设计一种基…...

Linux服务器pm2 运行chatgpt-on-wechat,搭建微信群ai机器人
安装 1.拉取项目 项目地址: chatgpt-on-wechat 2.安装依赖 pip3 install -r requirements.txt pip3 install -r requirements-optional.txt3、获取API信息 当前免费的有百度的文心一言,讯飞的个人认证提供500万token的额度。 控制台-讯飞开放平台 添加链接描述…...

Word批量更改题注
文章目录 批量更改批量去除空格 在写文章的时候,往往对图片题注有着统一的编码要求,例如以【图 1- xx】。一般会点击【引用】->【插入题注】来插入题注,并且在引用的时候,点击【引用】->【交叉引用】,并且在交叉…...

Springboot配置嵌入式服务器
一.如何定制和修改Servlet容器的相关配置 修改和server有关的配置(ServerProperties); server.port8081 server.context‐path/tx server.tomcat.uri‐encodingUTF‐8 在yml配置文件的写法: server:port: 8081servlet:context-pa…...
正交三角函数全面阐述
目录 1. 正交性定义 2. 正交三角函数 常见的正交三角函数 3. 正交三角函数的特性 4. 正交三角函数在傅里叶分析中的应用 5. 正交三角函数的应用领域 6. 总结 正交三角函数是指在特定条件下,三角函数之间的内积为零。更具体地说,在数学分析、信号处…...

《Vue3 四》Vue 的组件化
组件化:将一个页面拆分成一个个小的功能模块,每个功能模块完成自己部分的独立的功能。任何应用都可以被抽象成一棵组件树。 Vue 中的根组件: Vue.createApp() 中传入对象的本质上就是一个组件,称之为根组件(APP 组件…...
)
linux中,mysql数据库分片(分库分表)
1.mysql分库分表:解决单个mysql存储上限问题1.实现方法:存储层面:利用分布式存储解决方案分库分表:拆分库和表到其它服务器2.常用设计思路:垂直分库(库里面的表分开)水平分表(表里面的数据分开)分库:数据库分为多个,每个数据库里面都有表,数据均匀存储分库分表:在分的每库里面,…...

springboot503基于Sringboot+Vue个人驾校预约管理系统(论文+源码)_kaic
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装个人驾校预约管理系统软件来发挥其高效地信息处理的作用&am…...
Docker应用-项目部署及DockerCompose
文章目录 Docker应用-项目部署1. 项目部署-后端1.1 修改配置1.2 项目打包1.3 编写Dockerfile1.4 创建镜像1.5 创建并运行容器1.6 测试 2. 项目部署-前端2.1 html前端静态目录2.2 nginx.config编写2.3 部署宿主机服务器2.4 创建容器并挂载2.5 测试 3. DockerCompose3.1 基本语法…...

从0入门自主空中机器人-2-1【无人机硬件框架】
关于本课程: 本次课程是一套面向对自主空中机器人感兴趣的学生、爱好者、相关从业人员的免费课程,包含了从硬件组装、机载电脑环境设置、代码部署、实机实验等全套详细流程,带你从0开始,组装属于自己的自主无人机,并让…...

Kafka高性能设计
高性能设计概述 Kafka高性能是多方面协同的结果,包括集群架构、分布式存储、ISR数据同步及高效利用磁盘和操作系统特性等。主要体现在消息分区、顺序读写、页缓存、零拷贝、消息压缩和分批发送六个方面。 消息分区 存储不受单台服务器限制,能处理更多数据…...

Redis字符串底层结构对数值型的支持常用数据结构和使用场景
字符串底层结构 SDS (Simple Dynamic Strings) 是 Redis 中用于实现字符串类型的一种数据结构。SDS 的设计目标是提供高效、灵活的字符串操作,同时避免传统 C 字符串的一些缺点。 struct sdshdr {int len; // 已使用的长度int free; // 未使用的长度char bu…...

uniapp 微信小程序 数据空白展示组件
效果图 html <template><view class"nodata"><view class""><image class"nodataimg":src"$publicfun.locaAndHttp()?localUrl:$publicfun.httpUrlImg(httUrl)"mode"aspectFit"></image>&l…...

在vscode的ESP-IDF中使用自定义组件
以hello-world为例,演示步骤和注意事项 1、新建ESP-IDF项目 选择模板 从hello-world模板创建 2、打开项目 3、编译结果没错 正在执行任务: /home/azhu/.espressif/python_env/idf5.1_py3.10_env/bin/python /home/azhu/esp/v5.1/esp-idf/tools/idf_size.py /home…...

目标检测,语义分割标注工具--labelimg labelme
1 labelimg labelimg可以用来标注目标检测的数据集, 提供多种格式的输出, 如Pascal Voc, YOLO等。 1.1 安装 pip install labelimg1.2 使用 命令行直接输入labelimg即可打开软件主界面进行操作。 使用非常简单, 不做过细的介绍࿰…...

发明专利与实用新型专利申请过程及自助与代办方式对比
申请专利(发明专利、实用新型专利、外观设计专利)有两种方式:1、自己直接向国家知识产权局申请。2、通过专利代办处申请。以下是对这两种专利类型(发明专利、实用新型专利)申请过程及两种申请方式的详细介绍和对比,参考…...

Datawhale AI冬令营(第二期)动手学AI Agent task2--学Prompt工程,优化Agent效果
目录 如何写好Prompt? 工具包神器1:Prompt框架——CO-STAR 框架 工具包神器2:Prompt结构优化 工具包神器3:引入案例 案例:构建虚拟女友小冰 1. 按照 CO-STAR框架 梳理目标 2. 撰写Prompt 3. 制作对话生成应用&…...

基于python对网页进行爬虫简单教程
python对网页进行爬虫 基于BeautifulSoup的爬虫—源码 """ 基于BeautifulSoup的爬虫###?一、BeautifulSoup简介1.?Beautiful?Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供…...

【JavaEE进阶】@RequestMapping注解
目录 📕前言 🌴项目准备 🌲建立连接 🚩RequestMapping注解 🚩RequestMapping 注解介绍 🎄RequestMapping是GET还是POST请求? 🚩通过Fiddler查看 🚩Postman查看 …...

【WebAR-图像跟踪】在Unity中基于Imagine WebAR实现AR图像识别
写在前面的话 感慨一下, WebXR的发展是真的快,20年的时候,大多都在用AR.js做WebAR。随着WebXR标准发展,现在诸如Threejs、AFrame、Unity等多个平台都支持里WebXR。 本文将介绍在Unity中使用 Image Tracker实现Web端的AR图像识别功…...

打字侠全面支持三大五笔输入法:初学者快速上手指南
1. 五笔输入法:为什么值得初学者投入时间? 在拼音输入法大行其道的今天,很多初学者可能会疑惑:为什么要花时间学习看起来更复杂的五笔输入法?其实答案很简单——效率。我十年前刚开始接触五笔时也有同样的困惑…...

云容笔谈在自媒体内容生产中的提效实践:日更国风配图效率提升300%
云容笔谈在自媒体内容生产中的提效实践:日更国风配图效率提升300% 1. 自媒体内容创作的痛点与挑战 作为自媒体创作者,每天最头疼的就是配图问题。特别是做国风内容的账号,既要保持东方美学韵味,又要保证日更频率,传统…...

别再死记硬背公式了!用Simulink玩转单相全桥逆变,从方波驱动到IGBT参数设置全解析
用Simulink玩转单相全桥逆变:从方波驱动到IGBT参数设置的实战指南 电力电子领域的学习常常陷入公式推导的泥潭,而Simulink提供的可视化仿真环境就像一盏明灯。想象一下,当你调整一个参数就能立即看到波形变化,比纸上推导要直观十倍…...

微信小程序物流信息对接实战:发货接口的完整实现指南
1. 微信小程序物流对接的核心价值 对于电商类小程序来说,物流信息同步是用户体验的关键环节。当用户下单后,最关心的就是"我的包裹到哪了"。传统做法需要用户手动复制单号到第三方平台查询,而通过微信官方物流接口,可以…...

终极指南:如何构建现代化微服务架构 - Zend Framework Expressive完整教程
终极指南:如何构建现代化微服务架构 - Zend Framework Expressive完整教程 【免费下载链接】zendframework Official Zend Framework repository 项目地址: https://gitcode.com/gh_mirrors/ze/zendframework 在当今快速发展的微服务架构时代,PHP…...

保姆级教程:在Windows系统本地部署Qwen3-14B-Int4-AWQ对话模型
保姆级教程:在Windows系统本地部署Qwen3-14B-Int4-AWQ对话模型 1. 前言:为什么选择本地部署? 在个人电脑上运行大语言模型听起来可能有些遥不可及,但随着模型量化技术的进步,现在即使是消费级显卡也能流畅运行14B参数…...

Excel VBA图像处理:如何在单元格中显示并调整图片大小
在Excel中处理图片时,VBA(Visual Basic for Applications)是一个强大的工具。今天我们将讨论如何通过VBA代码在Excel的单元格中插入并调整图片大小,以及如何解决一些常见的问题。 背景介绍 假设你有一个Excel工作表,A列从A2开始存放了几个图片文件名,如"test.jpg&…...

用VSCode+PlatformIO给ESP32做个简易手表:基于LVGL和1.3寸屏的UI实战
基于LVGL的ESP32智能手表开发实战:从硬件驱动到UI设计全流程 在创客圈里,ESP32凭借其出色的性价比和丰富的功能接口,一直是物联网项目的热门选择。而当我们把目光投向更直观的人机交互领域时,LVGL(Light and Versatile…...

Mac用户的移动Win10工坊:从WTG配置到驱动、激活、文件共享的完整避坑指南
Mac用户的移动Win10工坊:从WTG配置到驱动、激活、文件共享的完整避坑指南 当Mac用户需要运行Windows应用时,双系统方案往往是最佳选择。而通过Windows To Go(WTG)技术将Win10安装在移动硬盘上,不仅保留了Mac原生系统的…...

AntdUI实战:用WinForm和.NET 6给老旧内部管理系统“换肤”的完整记录
AntdUI实战:用WinForm和.NET 6给老旧内部管理系统“换肤”的完整记录 当企业内部的WinForm系统运行超过十年,那些灰底蓝框的界面早已与现代审美格格不入。去年接手某制造业ERP系统改造时,我面对的是一个基于.NET Framework 4.0的"古董&q…...