C语言-数据结构-图
目录
一,图的概念
1,图的定义
2,图的基本术语
二,图的存储结构
1,邻接矩阵
2,邻接表
三,图的遍历
1,深度优先搜索
2,广度优先搜素
四,生成树和最小生成树
1,生成树的特点:
2,最小生成树
(1)普利姆算法Prim
(2)普里姆算法思路
五,最短路径
1,Dijkstra算法
2,Floyd算法
六,拓扑排序
七,关键路径
一,图的概念
1,图的定义
| 在图G中,如果代表边的顶点对是无序的,则称G为无向图。用圆括号 序偶表示无向边。 |  |
| 如果表示边的顶点对是有序的,则称G为有向图。用尖括号序偶表示 有向边。 |  |
2,图的基本术语
| 1,端点和连接点 | 无向图:若点若 存在一条边(i,j) 顶点i和顶点j为端点,它们互为邻接 | |
| 有向图:若 存在一条边<i,j> 顶点i为起始端点(简称为起点), 顶点j为终止端点(简称终点),它们互为邻接点。 | ||
| 2,顶点的度、入度和出度 | 无向图:以顶点 i为端点的边数称为该顶点的度。 | |
| 有向图: 以顶点i为终点的入边的数目,称为该 顶点的入度。以顶点i为始点的出边的数目,称为该顶点的出度。一个顶点的入度与出度的和为该顶点的度。 | ||
| 3、完全图 | 无向图:每 两个顶点之间都存在着一条边,称为完全无向图,包含有 n(n-1)/2条边。 |  |
| 有向图:每 两个顶点之间都存在着方向相反的两条边,称为完全有向 图,包含有n(n-1)条边。 |  | |
| 4、子图 | 设有两个图G=(V,E)和G'=(V',E'),若V'是V的子集, 且E'是E的子集,则称G'是G的子图。 | |
| 5, 路径长度 | 路径长度是指一条路径上经过的边的数目。 | |
| 6,简单路径 | 若一条路径上除开始点和结束点可以相同外,其余顶点均不相同,则称 此路径为简单路径。 | |
| 7、回路或环 | 若一条路径上的开始点与结束点为同一个顶点,则此路径被称为回 路或环。开始点与结束点相同的简单路径被称为简单回路或简单环。 | |
| 8、连通、连通图和连通分量 | 无向图: (1)若从顶点i到顶点j有路径,则称顶点i和j是连通的。 (2)若图中任意两个顶点都连通,则称为连通图,否则称为非连通图。 (3)无向图G中的极大连通子图称为G的连通分量。显然,任何连通图的连 通分量只有一个,即本身,而非连通图有多个连通分量。 |  |
| 有向图: (1)若从顶点i到顶点j有路径,则称从顶点i到j是连通的。 (2)若图G中的任意两个顶点i和j都连通,即从顶点i到j和从顶点j到i都存在 路径,则称图G是强连通图。 (3)有向图G中的极大强连通子图称为G的强连通分量。显然,强连通图 只有一个强连通分量,即本身。非强连通图有多个强连通分量。 |  | |
| 9、权和网 | 图中每一条边都可以附带有一个对应的数值,这种与边相关的数 值称为权。边上带有权的图称为带权图,也称作网。 |  |
寻找非强连通图的强连通分量:
① 在图中找有向环。
② 扩展该有向环:如果某个顶点到该环中任一顶点有路径,并且该环 中任一顶点到这个顶点也有路径,则加入这个顶点。

二,图的存储结构
1,邻接矩阵
| (1)如果G是无向图,则: A[i][j]=1:若(i,j)∈E(G) 0:其他 |
| (2)如果G是有向图,则: A[i][j]=1:若∈E(G) 0:其他 |
| (3)如果G是带权无向图,则: A[i][j]= wij :若i≠j且(i,j)∈E(G) 0:i=j ∞:其他 |
| (4)如果G是带权有向图,则: A[i][j]= wij :若i≠j且∈E(G) 0:i=j ∞:其他 |
 结论:无向图的邻接矩阵是对称的,顶点i的度=第i行(列)中1的个数
结论:无向图的邻接矩阵是对称的,顶点i的度=第i行(列)中1的个数
特别:完全图的邻接矩阵中,对角线元素为0,其余元素为1

结论:有向图的邻接矩阵可能是不对称的,顶点的出度=第i行元素之和;顶点的入度=第i列元素之和

邻接矩阵的存储需要用到两个表,一个表位顶点表,用一维数组表示,里面存储顶点.第二个表表示邻接矩阵,用二维数组表示
#define MAXInt 32767 //表示无穷大
#define MVNum 100 //最大顶点数
typedef char VerTexType;//顶点的数据类型为char
typedef int ArcType;//设置边的权值为整型typedef struct {VerTexType vexs[MVNum];//顶点表ArcType arcs[MVNum][MVNum];//邻接矩阵int vexnum, arcnum; //图当前的顶点数和边数
}AMGraph;无网图初始化:
//无向网
Status CreateUDN(AMGraph &G)
{ //采用邻接矩阵表示法,创建无向网G
cin>>G.vexnum>>G.arcnum; //输入总顶点数,总边数 for(i =0; i<G.vexnum; ++i) cin>>G.vexs[i]; //依次输入点的信息 for(i = 0; i<G.vexnum;++i) //初始化邻接矩阵 for(j=0;j<G.vexnum;++j) G.arcs[i][j] = Maxlnt; //边的权值均置为极大值 for(k = 0; k<G.arcnum;++k)
{ //构造邻接矩阵 cin>>v1>>v2>>w; //输入一条边所依附的顶点及边的权值 i = LocateVex(G, v1);j = LocateVex(G, v2); //确定v1和v2在G中的位置 G.arcs[i][j]=W; //边<v1,v2>的权值置为w G.arcs[j][i]= G.arcs[i][j]; //置<v1, v2>的对称边<v2,v1>的权值为w
} return OK;
}邻接矩阵的主要特点:
| 一个图的邻接矩阵表示是唯一的。 |
| 特别适合于稠密图的存储。邻接矩阵的存储空间为O(n2) |
| 优点:只管,简单,好理解,方便寻找任意两顶点之间是否存在边,方便计算顶点的度 |
| 缺点:不便于增加和删除顶点,如果为稀疏图,就会有大量的无效元素,浪费空间;统计边数,浪费时间 |
2,邻接表
分为两种节点,一种是头节点,头节点分为两个部分一部分是顶点信息,另一部分是指向第一条依附于该顶点的边的指针.边节点,第一部分是该边所指向的顶点的位置,第二部分是指向下一条边的指针,第三部分是边的相关信息,例如权,顶点,按照编号的顺序将顶点数据储存在一维数组中,相关联的的边,用线性链表进行连接

无向图:

邻接表并不唯一,边节点的顺序不唯一,若无向图有n个顶点,e条边,则邻接表需要n个头节点和2e个边节点,所以空间复杂度为O(n+2e)
无向图中的顶点v1的度为第i个单链表中的节点数
有向图:如果为邻接表,那么头节点指向的是该顶点的出度边,逆邻接表头节点指向的是该顶点的入度边.
由此,邻接表出度为第i单链表中的节点数,找出度容易,找入度难需要遍历整个图才可知. 逆邻接表入度为第i单链表中的节点数,找入度容易,出度困难

有向图和网空间复杂度为O(n+e)
#define MVNum 100 //最大顶点数typedef struct VNode {VerTexType deta;ArcNode* firstarc;
}VNode,AdjList[MVNum];typedef int OtherInfo;typedef struct ArcNode { //边节点int adjvex; //该边所指向的顶点的位置struct ArcNode* nextarc;//指向下一条边的指针OtherInfo info;//和边相关的信息,例如:权
}ArcNode;
typedef struct {AdjList vertices;int vexnum, arcnum;//图当前的顶点数和边数
}ALGraph;无向网的初始化:
//无向图
Status CreateUDG(ALGraph &G){ //采用邻接表表示法,创建无向图G
cin>>G.vexnum>>G.arcnum; //输入总顶点数,总边数 for(i = 0; i<G.vexnum; ++i) //输入各点,构造表头结点表
{ cin>> G.vertices[i].data; //输入顶点值G.vertices[i].firstarc=NULL;
}for(k = 0; k<G.arcnum;++k){ cin>>V1>>v2; //输入一条边依附的两个顶点i = LocateVex(G, v1); j = LocateVex(G, v2);p1=new ArcNode; //生成一个新的边结点*p1p1->adjvex=j; //邻接点序号为j p1->nextarc=G.vertices[i].firstarc; G.vertices[i].firstarc=p1; //将新结点*p1插入顶点vi的边表头部p2=new ArcNode; //生成另一个对称的新的边结点*p2->adjvex=i; //邻接点序号为i p2->nextarc= G.vertices[j].firstarc; G.vertices[j].firstarc=p2; //将新结点*p2插入顶点vj的边表头部
}邻接表的主要特点:
| 优点:方便找任意顶点的邻接点,节约稀疏图的空间,需要有向图:(n+e),无向图:(n+2e)的空间 |
| 缺点:有向图,不方便统计度的总数 |
| 联系: |
| 邻接表中的一行对应邻接矩阵中的一行,邻接表中的节点个数等于邻接矩阵中一行非零元素的个数 |
| 区别: |
| 邻接矩阵空间复杂度为O(n^2),邻接表的空间复杂度为O(n+1) |
| 邻接矩阵是唯一的,但是邻接表不是唯一的 |
| 邻接矩阵适用于稠密图,邻接表适用于稀疏图 |
三,图的遍历
1,深度优先搜索
■在访问图中某一起始顶点 v后,由 v出发,访问它的任一邻接顶点 w;
■再从 w 出发,访问与 w邻接但还未被访问过的顶点 W2;
■然后再从 w2出发,进行类似的访问,…
■ 如此进行下去,直至到达所有的邻接顶点都被访问过的顶点 u 为止。
■ 接着,退回一步,退到前一次刚访问过的顶点,看是否还有其它没有被访问的邻接顶点。
■ 如果有,则访问此顶点,之后再从此顶点出发,进行与前述类似的访问;
■如果没有,就再退回一步进行搜索。重复上述过程,直到连通图中 搜索 所有顶点都被访问过为止。
创建一个visited数组,用来储存该顶点是否被访问过:![]() visited[i]=0表示顶点i没有访问;visited[i]=1表示顶点i已经访问过。
visited[i]=0表示顶点i没有访问;visited[i]=1表示顶点i已经访问过。
void DFS (AMGraph G,int v)
{cout<<v;visitd[v]=true;for(w=0;w<G.vexnum;W++){if(G.arcs[v][w]!=0&&(!visited[w]))DFS(G,w);}邻接矩阵来扫描时间复杂度为O(n^2)
void DFS(ALGraph *G,int v){ArcNode *p; int w;visited[v]=1; //置已访问标记printf("%d ",v); //输出被访问顶点的编号p=G->Adjlist[v].firstarc; //p指向顶点v的第一条边的边头节点while (p!=NULL){w=p->adjvex;if (visited[w]==0)DFS(G,w); //若w顶点未访问,递归访问它p=p->nextarc; //p指向顶点v的下一条边的边头节点}}邻接表来扫描,时间复杂度为O(n+e)
2,广度优先搜素
方法:从图的某一结点出发,首先依次访问该结点的所有邻点 Vi, Vib, …, Vi,再按这些顶点被访问的先后次序依次访问与它们相邻接的所有未被访问的顶点 重复此过程,直至所有顶点均被访问为止。
邻接表的BFS算法:
void BFS(ALGraph *G,int v){ArcNode *p; int w,i;int queue[MAXV],front=0,rear=0; //定义循环队列int visited[MAXV];for (i=0;i<G->n;i++)visited[i]=0; //访问标志数组初始化printf("%2d",v); //输出被访问顶点的编号visited[v]=1; //置已访问标记rear=(rear+1)%MAXV;queue[rear]=v;//v进队while (front!=rear) //队列不空时循环{front=(front+1)%MAXV;w=queue[front];//出队并赋给wp=G->adjlist[w].firstarc; //找w的第一个的邻接点while (p!=NULL){if (visited[p->adjvex]==0){printf(“%2d”,p->adjvex); //访问之visited[p->adjvex]=1;rear=(rear+1)%MAXV; //相邻顶点进队queue[rear]=p->adjvex;}p=p->nextarc;}}}
DFS算法和BFS算法比较:
| 空间复杂度相同,都是O(n)前者借用了堆栈,后者借用了队列 |
| 时间复杂度只与存储结构(邻接矩阵/邻接表)有关,与搜索路径无关 |
四,生成树和最小生成树
1,生成树的特点:
| 一个图有许多不同的生成树 |
| 生成树的顶点树与图的顶点数相同 |
| 生成树是图的极小连通子图,去掉一条边则非连通,再加一条边必然形成回路 |
| 有n个顶点的连通图的生成树有n-1条边 |
| 生成树中任意两个顶点之间的路径是唯一的 |
深度优先生成树/广度优先生成树
广度优先生成树高度 ≤ 深度优先生成树高度

2,最小生成树
对于带权连通图G,其中权 值之和最小的生成树称为图的最小生成树。最小生成树可能不唯一.
(1)普利姆算法Prim
初始化U={v}。v到其他顶点的所有边为候选边;重复以下步骤n-1次,使得其他n-1个顶点被加入到U中: 从候选边中挑选权值最小的边输出,设该边在V-U中的顶点是k,将 k加入U中;考察当前V-U中的所有顶点j,修改候选边:若(j,k)的权值小于原来和顶点k关联的候选边,则用(k,j)取代后者作为候选边。



(2)克鲁斯卡尔算法
设连通网 N=(V,E),令最小生成树初始状态为只有 n个顶点而无边的非连通图7=(V, ()),每个顶点自成一个连通分量。 在E中选取代价最小的边,若该边依附的顶点落在 T中不同的连通分量上(即:不能形成环)则将此边加入到T中;否则,舍去此边,选取下一条代价最小的边。 依此类推,直至7中所有顶 寿島大 点都在同一连通分量上为止。

| 普利姆算法 | 克鲁斯卡尔算法 | |
| 算法思想 | 选择点 | 选择边 |
| 时间复杂度 | O(n^2) | O(elog2e) |
| 适应范围 | 稠密图 | 稀疏图 |
五,最短路径
从源点到终点可能不止一条路径,把路径长度最短的那条路径 称为最短路径。
1,Dijkstra算法
1,单源最短路径(Dijkstra算法)
1.初始化:先找出从源点v0到各终点vk的直达路径(Vo.Vk), 即通过一条弧到达的路径。
2.选择:从这些路径中找出一条长度最短的路径(Vo,u)。
3更新:然后对其余各条路径进行适当调整: 若在图中存在弧(u,vk),且(Vo,U)+(U.Vk)<(Vo,Vk), 则以路径(Vo,u,Vk)代替(Vo.v)。 在调整后的各条路径中,再找长度最短的路径, 依此类推。
按长度递增的顺序求出图的某顶点到其余顶点的最短路径

时间复杂度:O(n2)
2,Floyd算法
所有顶点间的最短路径(Floyd算法)
逐个顶点试探,从vi到vj的所以可能存在的路径中选出一条最短路径

时间复杂度:O(n3)
六,拓扑排序
设G=(V,E)是一个具有n个顶点的有向图(AOV/AOE),V中顶点序列v1 , v2 ,…,vn 称为一个拓扑序列,当且仅当该顶点序列满足下列条件: 若是图中的边(或从顶点i->j有一条路径):则在拓扑序列中顶点i必须排在顶点j之前。在一个有向图中找一个拓扑序列的过程称为拓扑排序[有向图中不允许又回路]
拓扑排序步骤(AOV):
(1)在有向图中选一个没有前驱的顶点且输出
(2)从图中删除该顶点和所有以它为尾的弧
(3)重复上述两步,直到全部的顶点均已输出,或者图中不存在无前驱的顶点为止(代表有向图中有环)

七,关键路径
AOE网: 用一个带顶点权有向图(DAG)描述工程的预计进度。 表示事件,有向边表示活动,边e的权c(e)表示完成活动e所需的 时间(比如天数)。 图中入度为0的顶点表示工程的开始事件(如开工仪式),出度为0的 顶点表示工程结束事件
关键路径:从AOE网中源点到汇点的最长路径,具有最大长度的路径叫 关键路径。
| 事件v最早开始时间 | 规定源点事件的最早开始时间为0。定义图中任 一事件v的最早开始时间(early event)ee(v) |
| 事件v最迟开始时间 | 定义在不影响整个工程进度的前提下,事件v必 须发生的时间称为v的最迟开始时间(late event) ,记作le(v)。 |
| 活动a的最早开始时间 | e(a)指该活动起点x事件的最早开始时间, |
| 活动a的最迟开始时间 | l(a)指该活动终点y事件的最迟开始时间与该 活动所需时间之差 |
计算公式:
| 事件v最早开始时间 | ee(v)=MAX{ee(x)+a,ee(y)+b,ee(z)+c} |
| 事件v最迟开始时间 | le(v)=MIN{le(x)-a,le(y)-b,le(z)-c} |
| 活动a的最早开始时间 | e(a)=ee(x) |
| 活动a的最迟开始时间 | l(a)=le(y)-c |
| 关键活动:d(a)=l(a)-e(a),若d(a)为0,则称活动a为关键活动 | |




| 在AOE网中可能存在多条关键路径 |
| 关键活动不按期完成就会影响整个工程的完成时间 |
| 所有关键活动都提前完成,整个工程也将提前完成 |
相关文章:
C语言-数据结构-图
目录 一,图的概念 1,图的定义 2,图的基本术语 二,图的存储结构 1,邻接矩阵 2,邻接表 三,图的遍历 1,深度优先搜索 2,广度优先搜素 四,生成树和最小生成树 1,生成树的特点: 2,最小生成树 (1)普利姆算法Prim (2)普里姆算法思路 五,最短路径 1,Dijkstra算法 2,Fl…...
android sqlite 数据库简单封装示例(java)
sqlite 数据库简单封装示例,使用记事本数据库表进行示例。 首先继承SQLiteOpenHelper 使用sql语句进行创建一张表。 public class noteDBHelper extends SQLiteOpenHelper {public noteDBHelper(Context context, String name, SQLiteDatabase.CursorFactory fact…...

“宠物服务的跨平台整合”:多设备宠物服务平台的实现
2.1 SSM框架介绍 本课题程序开发使用到的框架技术,英文名称缩写是SSM,在JavaWeb开发中使用的流行框架有SSH、SSM、SpringMVC等,作为一个课题程序采用SSH框架也可以,SSM框架也可以,SpringMVC也可以。SSH框架是属于重量级…...

关于最新MySQL9.0.1版本zip自配(通用)版下载、安装、环境配置
一、下载 从MySQL官网进行下载MySQL最新版本,滑到页面最下面点击社区免费版,(不是企业版) 点击完成后选择自己想要下载的版本,选择下载zip压缩,不用debug和其他的东西。 下载完成后进入解压,注…...

【Halcon】例程讲解:基于形状匹配与OCR的多图像处理(附图像、程序下载链接)
1. 开发需求 在参考图像中定义感兴趣区域(ROI),用于形状匹配和文本识别。通过形状匹配找到图像中的目标对象位置。对齐多幅输入图像,使其与参考图像保持一致。在对齐后的图像上进行OCR识别,提取文本和数字信息。以循环…...

B站推荐模型数据流的一致性架构
01 背景 推荐系统的模型,通过学习用户历史行为来达到个性化精准推荐的目的,因此模型训练依赖的样本数据,需要包括用户特征、服务端推荐的视频特征,以及用户在推荐视频上是否有一系列的消费行为。 推荐模型数据流,即为…...

不安全物联网的轻量级加密:综述
Abstract 本文综述了针对物联网(IoT)的轻量级加密解决方案。这项综述全面覆盖了从轻量级加密方案到不同类型分组密码的比较等多个方面。同时,还对硬件与软件解决方案之间的比较进行了讨论,并分析了当前最受信赖且研究最深入的分组…...

mysql_init的概念和使用案例
mysql_init 是 MySQL C API 中的一个函数,用于初始化一个 MYSQL 结构,这个结构在后续的 MySQL 数据库操作中会被频繁使用。mysql_init 的调用是建立与 MySQL 数据库连接的第一步。 函数原型: MYSQL *mysql_init(MYSQL *mysql);参数说明&…...

3GPP R18 MT-SDT
Rel-17 指定MO-SDT允许针对UL方向的数据包进行小数据包传输。对于DL,MT-SDT(即DL触发的小数据)可带来类似的好处,即 通过不转换到 RRC_CONNECTED来减少信令开销和UE功耗,并通过允许快速传输(小而少见的)数据包(例如用于定位)来减少延迟。 在R17中,NR_SmallData_INACTIVE的工…...

时频转换 | Matlab暂态提取变换transient-extracting transform一维数据转二维图像方法
目录 基本介绍程序设计参考资料获取方式 基本介绍 时频转换 | Matlab暂态提取变换transient-extracting transform一维数据转二维图像方法 程序设计 clear clc % close all load x.mat % 导入数据 x x(1:5120); % 本数据只选择5120个点进行分析 fs 6400 ; % 数据采样频…...

.NET Framework 逐渐过时,.NET 8和 .NET 9引领未来
随着科技的不断进步,软件开发的工具和技术也在不断更新换代。.NET Framework,曾是微软的旗舰开发平台,曾经在软件开发领域占据了主导地位。然而,随着技术的演变和开发需求的变化,.NET Framework逐渐显得力不从心&#…...
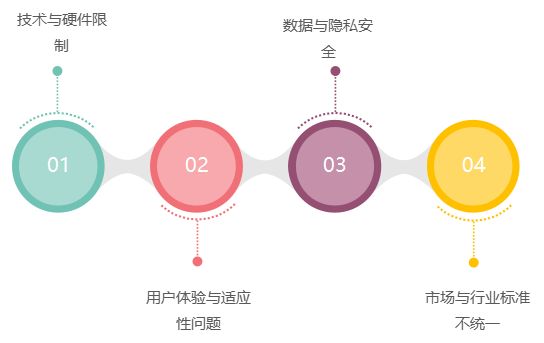
从虚拟到现实:AI与AR/VR技术如何改变体验经济?
引言:体验经济的崛起 在当今消费环境中,产品与服务早已不再是市场竞争的唯一焦点,能够提供深刻感知和独特体验的品牌,往往更能赢得消费者的青睐。这种转变标志着体验经济的崛起。体验经济不仅仅是简单的买卖行为,而是通…...

在K8S中,Ingress该如何使用?
在Kubernetes中,Ingress是一种API对象,它提供了对外部请求进入集群内部服务的一种统一入口和路由机制。Ingress控制器是一个运行在集群中的守护进程,它监听Ingress对象的变化并配置相应的负载均衡器或代理服务,以便根据定义的规则…...

Ubuntu24.04安装NVIDIA驱动及工具包
Ubuntu24.04安装NVIDIA驱动及工具包 安装nvidia显卡驱动安装cuda驱动安装cuDNN安装Anaconda 安装nvidia显卡驱动 NVIDIA 驱动程序(NVIDIA Driver)是专为 NVIDIA 图形处理单元(GPU)设计的软件,它充当操作系统与硬件之间…...

【每日学点鸿蒙知识】组件封装通用方法、callback和await性能对比、Web组件下拉刷新、hsp包报错、WebView圆角
1、HarmonyOS 自定义的组件如何封装一些通用的属性和方法,例如 Java 中的继承? export class Animal{name:stringage:stringconstructor(name:string,age:string) {this.name namethis.age age} }export class Person extends Animal{reading:stri…...

Excel批量设置行高,Excel表格设置自动换行后打印显示不全,Excel表格设置最合适的行高后打印显示不全,完美解决方案!!!
文章目录 说个问题(很严重!!!)写个方案会Python看这里Python环境搭建不存在多行合并存在多行合并 不会Python看这里 说个问题(很严重!!!) 平时处理Excel表格…...

Web Bluetooth API 开发记录
搞了一天的蓝牙串口协议被几个软件和AI带沟里面去了。 1.00001101-0000-1000-8000-00805f9b34fb 是spp协议。但是我用的称是使用的49535343-fe7d-4ae5-8fa9-9fafd205e455蓝牙低功耗spp协议 2.推荐一款软件Android-nRF-Connect github地址:https://github.com/Nor…...

python基础知识(二)
元组 元组与列表类似,不同之处在于,元组的元素不能修改,元组使用()。 集合 集合是一个无序且不重复的元素列表。 基本功能是 进行成员关系测试和删除重复元素。 创建集合使用大括号或者set()函数。 例子: 注意:创建一…...

【每日学点鸿蒙知识】初始化BigInt、包体积瘦身、Tabs嵌套Grid、老年化适配、Release打包失败
1、HarmonyOS 在一个类中,怎么初始化一个BigInt类型的属性? 可以通过BigInt关键字来初始化,如: let a BigInt(1); let b BigInt("2"); 关于Uint8Array与string互转,示例: // string 转Uint8…...

Android service framework笔记
1. 网络摘录如何添加一个Application Framework Service(一)(without native code) 如何添加一个Application Framework Service(二)(with native code) 2.书籍摘录...

CodeMaker:让编码效率提升3倍的智能代码生成工具
CodeMaker:让编码效率提升3倍的智能代码生成工具 【免费下载链接】CodeMaker A idea-plugin for Java/Scala, support custom code template. 项目地址: https://gitcode.com/gh_mirrors/co/CodeMaker 一、核心价值:重新定义开发效率 你是否也曾…...

小麦联合收割机的设计【说明书+SW三维+CAD图纸】
小麦联合收割机作为现代农业机械化的核心装备,其设计需兼顾效率、可靠性与适应性。该设备通过集成收割、脱粒、清选及集粮功能,实现小麦收获环节的连续作业,显著缩短田间作业周期,降低人工劳动强度。其核心作用体现在三方面&#…...

PFC5.0代码:含三种矿物组成的岩石或类岩石材料GBM单轴压缩2d算例代码,仅供学习与提升
PFC5.0代码,含三种矿物组成的岩石或者类岩石材料,GBM,单轴压缩2d,算例代码仅供学习以及提升 打开PFC5.0的建模界面,突然想把花岗岩里的石英、长石、云母做成颗粒组合。先整点暴力的——直接拿球体颗粒拼成矿物晶粒&…...

终极Chromium性能优化方案:Thorium浏览器让你的上网体验快如闪电
终极Chromium性能优化方案:Thorium浏览器让你的上网体验快如闪电 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Windows and MacOS/Raspi/Android/Special builds are in different repositories, links are towards the top of…...

SDMatte多风格抠图作品集:从商品白底图到艺术创意合成
SDMatte多风格抠图作品集:从商品白底图到艺术创意合成 1. 开篇:当抠图遇上AI 还记得那些年用Photoshop一点一点抠图的痛苦经历吗?边缘总是处理不干净,头发丝永远抠不完整,遇到复杂背景更是让人抓狂。现在,…...

Magisk完整实践指南:从Root权限获取到系统级定制
Magisk完整实践指南:从Root权限获取到系统级定制 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为Android系统Root权限管理的主流解决方案,提供了系统级定制能力而无需修…...

Ostrakon-VL-8B效果展示:看AI如何从店铺图片中识别问题与机会
Ostrakon-VL-8B效果展示:看AI如何从店铺图片中识别问题与机会 1. 引言:当AI成为你的店铺巡检专家 想象一下这样的场景:你是一家连锁超市的运营经理,每天需要检查数十家门店的货架陈列、商品摆放和卫生状况。传统方法需要派遣大量…...

VMware Workstation 16开机自启踩坑实录:从环境变量报错到bat脚本优化,一篇搞定
VMware Workstation 16开机自启全攻略:从环境变量到脚本优化的深度实践 每次重启服务器后手动打开虚拟机实在是个体力活。上周我负责维护的测试环境又因为忘记启动虚拟机导致整个团队阻塞了半天,这种低级错误让我决定彻底解决VMware Workstation的开机自…...

Fish Speech-1.5镜像资源管理:模型热更新与多版本共存部署方案
Fish Speech-1.5镜像资源管理:模型热更新与多版本共存部署方案 1. 引言:语音合成的新选择 想象一下,你需要为产品演示视频添加多语言配音,或者为在线课程制作不同语言的语音内容。传统方法要么成本高昂,要么效果生硬…...

手把手教你用DrissionPage搭建个人新闻聚合器:自动抓取百度热搜并保存到Excel
用DrissionPage打造智能新闻聚合器:从百度热搜抓取到Excel自动化分析 每天手动刷新闻不仅耗时,还容易错过重要信息。想象一下,如果有个私人助手能自动收集全网热点,整理成结构化的报告,甚至生成直观的可视化图表——这…...