【源码】Sharding-JDBC源码分析之SQL中影子库ShadowSQLRouter路由的原理
Sharding-JDBC系列
1、Sharding-JDBC分库分表的基本使用
2、Sharding-JDBC分库分表之SpringBoot分片策略
3、Sharding-JDBC分库分表之SpringBoot主从配置
4、SpringBoot集成Sharding-JDBC-5.3.0分库分表
5、SpringBoot集成Sharding-JDBC-5.3.0实现按月动态建表分表
6、【源码】Sharding-JDBC源码分析之JDBC
7、【源码】Sharding-JDBC源码分析之SPI机制
8、【源码】Sharding-JDBC源码分析之Yaml分片配置文件解析原理
9、【源码】Sharding-JDBC源码分析之Yaml分片配置原理(一)
10、【源码】Sharding-JDBC源码分析之Yaml分片配置原理(二)
11、【源码】Sharding-JDBC源码分析之Yaml分片配置转换原理
12、【源码】Sharding-JDBC源码分析之ShardingSphereDataSource的创建原理
13、【源码】Sharding-JDBC源码分析之ContextManager创建中mode分片配置信息的持久化存储的原理
14、【源码】Sharding-JDBC源码分析之ContextManager创建中ShardingSphereDatabase的创建原理
15、【源码】Sharding-JDBC源码分析之分片规则生成器DatabaseRuleBuilder实现规则配置到规则对象的生成原理
16、【源码】Sharding-JDBC源码分析之配置数据库定义的表的元数据解析原理
17、【源码】Sharding-JDBC源码分析之ShardingSphereConnection的创建原理
18、【源码】Sharding-JDBC源码分析之ShardingSpherePreparedStatement的创建原理
19、【源码】Sharding-JDBC源码分析之Sql解析的原理
20、【源码】Sharding-JDBC源码分析之SQL路由及SingleSQLRouter单表路由
21、【源码】Sharding-JDBC源码分析之SQL中分片键路由ShardingSQLRouter的原理
22、【源码】Sharding-JDBC源码分析之SQL中读写分离路由ReadwriteSplittingSQLRouter的原理
23、 【源码】Sharding-JDBC源码分析之SQL中读写分离动态策略、数据库发现规则及DatabaseDiscoverySQLRouter路由的原理
24、【源码】Sharding-JDBC源码分析之SQL中影子库ShadowSQLRouter路由的原理
前言
ShardingSphere 影子库是一个在数据库层面解决全链路在线压测问题的有效工具。影子库是实际中使用的数据库的完整数据拷贝,用于接收测试数据,以防止测试数据污染生产数据库。影子库应与正式的生产库保持相同的配置,以确保测试结果的准确性。
在正式环境中进行全链路压测时,使用影子库可以隔离测试数据,可以模拟生产环境,进行各种测试,而不会对生产数据库造成任何影响。
本篇从源码的角度,分析 ShardingSphere 中影子库路由的实现原理,其对应的路由器对象为ShadowSQLRouter。
ShardingSpherePreparedStatement回顾
在【源码】Sharding-JDBC源码分析之SQL路由及SingleSQLRouter单表路由-CSDN博客中分析在执行SQL语句前,会进行SQL路由,创建RouteContext对象,在RouteContext路由上下文对象中,包含了SQL真正执行的数据源、逻辑表及真实表的映射。
SQL路由时,循环执行配置的路由器,进行路由上下文RouteContext对象的创建或装饰。如果配置了影子库,将会在路由器集合中最后执行影子库路由器 ShadowSQLRouter。
ShadowSQLRouter
ShadowSQLRouter的源码如下:
package org.apache.shardingsphere.shadow.route;/*** SQL影子库路由器*/
public final class ShadowSQLRouter implements SQLRouter<ShadowRule> {@Overridepublic RouteContext createRouteContext(final QueryContext queryContext, final ShardingSphereDatabase database,final ShadowRule rule, final ConfigurationProperties props, final ConnectionContext connectionContext) {// TODOreturn new RouteContext();}/*** 装饰路由上下文。根据 SQL 语句类型,创建一个ShadowRouteEngine,执行ShadowRouteEngine.route()方法* @param routeContext 路由上下文* @param queryContext 查询上下文* @param database 数据库信息* @param rule 影子库规则对象* @param props 配置的属性* @param connectionContext 连接上下文*/@Overridepublic void decorateRouteContext(final RouteContext routeContext, final QueryContext queryContext, final ShardingSphereDatabase database,final ShadowRule rule, final ConfigurationProperties props, final ConnectionContext connectionContext) {ShadowRouteEngineFactory.newInstance(queryContext).route(routeContext, rule);}@Overridepublic int getOrder() {return ShadowOrder.ORDER;}@Overridepublic Class<ShadowRule> getTypeClass() {return ShadowRule.class;}
}ShadowSQLRouter的源码很简单,通过ShadowRouteEngineFactory的newInstance()获取一个ShadowRouteEngine对象,执行ShadowRouteEngine的route()方法。
ShadowRouteEngineFactory
ShadowRouteEngineFactory的源码如下:
package org.apache.shardingsphere.shadow.route.engine;/*** 影子路由引擎工厂*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class ShadowRouteEngineFactory {/*** 创建影子路由引擎。不同的SQL语句,使用不同的处理方式* @param queryContext* @return*/public static ShadowRouteEngine newInstance(final QueryContext queryContext) {SQLStatement sqlStatement = queryContext.getSqlStatementContext().getSqlStatement();// 插入语句if (sqlStatement instanceof InsertStatement) {return createShadowInsertStatementRoutingEngine(queryContext);}// 删除语句if (sqlStatement instanceof DeleteStatement) {return createShadowDeleteStatementRoutingEngine(queryContext);}// 修改语句if (sqlStatement instanceof UpdateStatement) {return createShadowUpdateStatementRoutingEngine(queryContext);}// 选择语句if (sqlStatement instanceof SelectStatement) {return createShadowSelectStatementRoutingEngine(queryContext);}// 其他语句return createShadowNonMDLStatementRoutingEngine(queryContext);}private static ShadowRouteEngine createShadowNonMDLStatementRoutingEngine(final QueryContext queryContext) {return new ShadowNonDMLStatementRoutingEngine(queryContext.getSqlStatementContext());}private static ShadowRouteEngine createShadowSelectStatementRoutingEngine(final QueryContext queryContext) {return new ShadowSelectStatementRoutingEngine((SelectStatementContext) queryContext.getSqlStatementContext(), queryContext.getParameters());}private static ShadowRouteEngine createShadowUpdateStatementRoutingEngine(final QueryContext queryContext) {return new ShadowUpdateStatementRoutingEngine((UpdateStatementContext) queryContext.getSqlStatementContext(), queryContext.getParameters());}private static ShadowRouteEngine createShadowDeleteStatementRoutingEngine(final QueryContext queryContext) {return new ShadowDeleteStatementRoutingEngine((DeleteStatementContext) queryContext.getSqlStatementContext(), queryContext.getParameters());}/*** 传入插入语句的路由引擎* @param queryContext* @return*/private static ShadowRouteEngine createShadowInsertStatementRoutingEngine(final QueryContext queryContext) {return new ShadowInsertStatementRoutingEngine((InsertStatementContext) queryContext.getSqlStatementContext());}
}在newInstance()方法中,根据当前SQL语句的操作类型,创建不同的ShadowRouteEngine影子路由引擎对象。如针对插入语句,创建ShadowInsertStatementRoutingEngine路由引擎。
ShadowInsertStatementRoutingEngine
ShadowInsertStatementRoutingEngine的源码如下:
package org.apache.shardingsphere.shadow.route.engine.dml;/*** 插入语句影子路由引擎*/
@RequiredArgsConstructor
public final class ShadowInsertStatementRoutingEngine extends AbstractShadowDMLStatementRouteEngine {// 插入语句上下文private final InsertStatementContext insertStatementContext;/*** 插入语句中涉及的表* @return*/@Overrideprotected Collection<SimpleTableSegment> getAllTables() {return insertStatementContext.getAllTables();}@Overrideprotected ShadowOperationType getShadowOperationType() {return ShadowOperationType.INSERT;}/*** 获取插入语句中的注释段信息* @return*/@Overrideprotected Optional<Collection<String>> parseSQLComments() {Collection<String> result = new LinkedList<>();insertStatementContext.getSqlStatement().getCommentSegments().forEach(each -> result.add(each.getText()));return result.isEmpty() ? Optional.empty() : Optional.of(result);}@Overrideprotected Iterator<Optional<ShadowColumnCondition>> getShadowColumnConditionIterator(final String shadowColumn) {return new ShadowColumnConditionIterator(shadowColumn, parseColumnNames().iterator(), insertStatementContext.getInsertValueContexts());}/*** 解析插入语句中的参数名称* @return*/private Collection<String> parseColumnNames() {return insertStatementContext.getInsertColumnNames();}/*** 影子列条件迭代器*/private class ShadowColumnConditionIterator implements Iterator<Optional<ShadowColumnCondition>> {private int index;// 影子列private final String shadowColumn;// 插入语句中的列名迭代器private final Iterator<String> iterator;// 插入值上下文集合。每个插入值上下文中包含单条记录的参数信息private final List<InsertValueContext> insertValueContexts;ShadowColumnConditionIterator(final String shadowColumn, final Iterator<String> iterator, final List<InsertValueContext> insertValueContexts) {index = 0;this.shadowColumn = shadowColumn;this.iterator = iterator;this.insertValueContexts = insertValueContexts;}@Overridepublic boolean hasNext() {return iterator.hasNext();}/*** 遍历下一个参数,如果不是影子列,返回空* @return*/@Overridepublic Optional<ShadowColumnCondition> next() {String columnName = iterator.next();// 不是影子列,返回空if (!shadowColumn.equals(columnName)) {index++;return Optional.empty();}// 如果是影子列Optional<Collection<Comparable<?>>> columnValues = getColumnValues(insertValueContexts, index);index++;return columnValues.map(each -> new ShadowColumnCondition(getSingleTableName(), columnName, each));}/*** 获取列的值* @param insertValueContexts* @param columnIndex 当前投影列在列名集合中的下标* @return*/private Optional<Collection<Comparable<?>>> getColumnValues(final List<InsertValueContext> insertValueContexts, final int columnIndex) {Collection<Comparable<?>> result = new LinkedList<>();for (InsertValueContext each : insertValueContexts) {// 获取参数值或参数在sql语句中的下标Object valueObject = each.getLiteralValue(columnIndex).orElseThrow(() -> new UnsupportedShadowInsertValueException(columnIndex));if (valueObject instanceof Comparable<?>) {result.add((Comparable<?>) valueObject);} else {return Optional.empty();}}return result.isEmpty() ? Optional.empty() : Optional.of(result);}}
}ShadowInsertStatementRoutingEngine继承抽象类AbstractShadowDMLStatementRouteEngine,其实现的核心逻辑都在父类AbstractShadowDMLStatementRouteEngine中,具体SQL语句的实现类核心功能在于获取对应影子列的值的获取。
在ShadowInsertStatementRoutingEngine中,主要功能如下:
1)获取插入SQL语句中的所有表部分;
2)获取插入SQL语句中的注解;
3)获取投影列的条件迭代器;
迭代器提供了获取插入语句中配置了投影的列及对应列准备插入的值。在抽象父类中,通过列及对应的值,结合配置的算法,确认是否要将数据源替换为对应的投影数据源;
AbstractShadowDMLStatementRouteEngine
AbstractShadowDMLStatementRouteEngine的源码如下:
package org.apache.shardingsphere.shadow.route.engine.dml;/*** DML语句的影子路由引擎*/
@Getter
public abstract class AbstractShadowDMLStatementRouteEngine implements ShadowRouteEngine {// 表昵称和表名的映射private final Map<String, String> tableAliasNameMappings = new LinkedHashMap<>();/*** 影子库路由* @param routeContext route context* @param shadowRule shadow rule*/@Overridepublic void route(final RouteContext routeContext, final ShadowRule shadowRule) {decorateRouteContext(routeContext, shadowRule, findShadowDataSourceMappings(shadowRule));}/*** 查找影子库数据源映射。key为生产数据源、value为影子数据源* @param shadowRule* @return*/private Map<String, String> findShadowDataSourceMappings(final ShadowRule shadowRule) {// 从SQL语句中的所有表,查找配置影子规则的表Collection<String> relatedShadowTables = getRelatedShadowTables(getAllTables(), shadowRule);if (relatedShadowTables.isEmpty() && isMatchDefaultShadowAlgorithm(shadowRule)) {return shadowRule.getAllShadowDataSourceMappings();}ShadowOperationType shadowOperationType = getShadowOperationType();// 判断 sql 注释中是否有shadow的提示。如 影子算法为 SIMPLE_HINT,且sql语句中添加了 /* SHARDINGSPHERE_HINT: SHADOW=true */Map<String, String> result = findBySQLComments(relatedShadowTables, shadowRule, shadowOperationType);if (!result.isEmpty()) {return result;}// 查找表中的是否存在满足条件的影子列,如果存在,则返回对应表的数据源映射return findByShadowColumn(relatedShadowTables, shadowRule, shadowOperationType);}/*** 结合配置的规则,查找配置了影子规则的表* @param simpleTableSegments* @param shadowRule* @return*/private Collection<String> getRelatedShadowTables(final Collection<SimpleTableSegment> simpleTableSegments, final ShadowRule shadowRule) {Collection<String> tableNames = new LinkedHashSet<>();// 遍历表部分,解析出表名及表昵称映射for (SimpleTableSegment each : simpleTableSegments) {String tableName = each.getTableName().getIdentifier().getValue();String alias = each.getAlias().isPresent() ? each.getAlias().get() : tableName;tableNames.add(tableName);tableAliasNameMappings.put(alias, tableName);}// 从影子规则中获取相关的表return shadowRule.getRelatedShadowTables(tableNames);}/*** 是否匹配默认阴影算法* @param shadowRule* @return*/@SuppressWarnings("unchecked")private boolean isMatchDefaultShadowAlgorithm(final ShadowRule shadowRule) {Optional<Collection<String>> sqlComments = parseSQLComments();// 如果没有设置注释段,返回falseif (!sqlComments.isPresent()) {return false;}// 获取默认影子算法Optional<ShadowAlgorithm> defaultShadowAlgorithm = shadowRule.getDefaultShadowAlgorithm();if (defaultShadowAlgorithm.isPresent()) {ShadowAlgorithm shadowAlgorithm = defaultShadowAlgorithm.get();// 是Hint的影子算法if (shadowAlgorithm instanceof HintShadowAlgorithm<?>) {// 创建影子确定条件,影子操作类型为HINT_MATCHShadowDetermineCondition shadowDetermineCondition = new ShadowDetermineCondition("", ShadowOperationType.HINT_MATCH);// 是否在hint影子算法中。如sql注释中是否添加了 shadow 的hint提示return HintShadowAlgorithmDeterminer.isShadow((HintShadowAlgorithm<Comparable<?>>) shadowAlgorithm, shadowDetermineCondition.initSQLComments(sqlComments.get()), shadowRule);}}return false;}/*** 查找SQL的注释部分,获取数据源信息。key为生产数据源、value为影子数据源* @param relatedShadowTables sql语句中配置了影子规则的表* @param shadowRule 影子规则对象* @param shadowOperationType 当前sql操作的类型* @return*/private Map<String, String> findBySQLComments(final Collection<String> relatedShadowTables, final ShadowRule shadowRule, final ShadowOperationType shadowOperationType) {Map<String, String> result = new LinkedHashMap<>();// 遍历影子表for (String each : relatedShadowTables) {// 判断sql的注释中是否包含了shadow信息,如 /* SHARDINGSPHERE_HINT: SHADOW=true */if (isContainsShadowInSQLComments(each, shadowRule, new ShadowDetermineCondition(each, shadowOperationType))) {// 获取影子数据源映射。key为生产数据源、value为影子数据源result.putAll(shadowRule.getRelatedShadowDataSourceMappings(each));return result;}}return result;}/*** 判断sql语句的注释段是否包含了 shadow 的注释* @param tableName* @param shadowRule* @param shadowCondition* @return*/private boolean isContainsShadowInSQLComments(final String tableName, final ShadowRule shadowRule, final ShadowDetermineCondition shadowCondition) {// 获取解析后的 SQL 注释,判断注释中是否包含了 shadow 的信息return parseSQLComments().filter(each -> isMatchAnyHintShadowAlgorithms(shadowRule.getRelatedHintShadowAlgorithms(tableName), shadowCondition.initSQLComments(each), shadowRule)).isPresent();}/*** 是否匹配任意的Hint影子算法* @param shadowAlgorithms* @param shadowCondition* @param shadowRule* @return*/private boolean isMatchAnyHintShadowAlgorithms(final Collection<HintShadowAlgorithm<Comparable<?>>> shadowAlgorithms, final ShadowDetermineCondition shadowCondition, final ShadowRule shadowRule) {// 遍历hint影子算法for (HintShadowAlgorithm<Comparable<?>> each : shadowAlgorithms) {// 判断是否满足hint影子算法中的影子规则// 默认的hint影子算法为SimpleHintShadowAlgorithm,配置的type为SIMPLE_HINT// 该算法解析传入的shadowCondition中的sqlComment是否存在 /* SHARDINGSPHERE_HINT: SHADOW=true */ 的信息// 即判断对应的sql语句是否有 /* SHARDINGSPHERE_HINT: SHADOW=true */ 相关注解信息if (HintShadowAlgorithmDeterminer.isShadow(each, shadowCondition, shadowRule)) {return true;}}return false;}/*** 通过影子列查找数据源映射,key为生产数据源、value为影子数据源* @param relatedShadowTables 相关影子表* @param shadowRule 影子规则* @param shadowOperationType 影子操作类型* @return*/private Map<String, String> findByShadowColumn(final Collection<String> relatedShadowTables, final ShadowRule shadowRule, final ShadowOperationType shadowOperationType) {Map<String, String> result = new LinkedHashMap<>();// 遍历for (String each : relatedShadowTables) {// 获取相关影子表的影子列名称Collection<String> relatedShadowColumnNames = shadowRule.getRelatedShadowColumnNames(shadowOperationType, each);// 存在影子列 && 匹配任意列影子算法if (!relatedShadowColumnNames.isEmpty() && isMatchAnyColumnShadowAlgorithms(each, relatedShadowColumnNames, shadowRule, shadowOperationType)) {// 返回对应表的影子数据源映射return shadowRule.getRelatedShadowDataSourceMappings(each);}}return result;}/*** 匹配任意列投影算法* @param shadowTable 影子表* @param shadowColumnNames 设置影子的列* @param shadowRule* @param shadowOperation SQL的操作类型* @return*/private boolean isMatchAnyColumnShadowAlgorithms(final String shadowTable, final Collection<String> shadowColumnNames, final ShadowRule shadowRule, final ShadowOperationType shadowOperation) {// 遍历投影的列名for (String each : shadowColumnNames) {// 匹配任意列影子算法if (isMatchAnyColumnShadowAlgorithms(shadowTable, each, shadowOperation, shadowRule)) {return true;}}return false;}/*** 匹配任意列影子算法* @param shadowTable 影子表* @param shadowColumn 影子列(表中设置了影子的列)* @param shadowOperationType* @param shadowRule* @return*/private boolean isMatchAnyColumnShadowAlgorithms(final String shadowTable, final String shadowColumn, final ShadowOperationType shadowOperationType, final ShadowRule shadowRule) {// 从影子规则中获取 shadowColumn 列的影子算法Collection<ColumnShadowAlgorithm<Comparable<?>>> columnShadowAlgorithms = shadowRule.getRelatedColumnShadowAlgorithms(shadowOperationType, shadowTable, shadowColumn);if (columnShadowAlgorithms.isEmpty()) {return false;}// 获取影子列的条件迭代器Iterator<Optional<ShadowColumnCondition>> iterator = getShadowColumnConditionIterator(shadowColumn);ShadowDetermineCondition shadowDetermineCondition;// 遍历迭代器while (iterator.hasNext()) {// 获取SQL中下一个列的条件信息Optional<ShadowColumnCondition> next = iterator.next();// 如果找到影子列if (next.isPresent()) {for (ColumnShadowAlgorithm<Comparable<?>> each : columnShadowAlgorithms) {// 创建一个影子确定条件对象shadowDetermineCondition = new ShadowDetermineCondition(shadowTable, shadowOperationType);// 通过决策器进行影子判断if (ColumnShadowAlgorithmDeterminer.isShadow(each, shadowDetermineCondition.initShadowColumnCondition(next.get()))) {return true;}}}}return false;}/*** 获取sql语句中所有的表* @return*/protected abstract Collection<SimpleTableSegment> getAllTables();/*** 获取影子库映射类型,即当前sql语句的类型。如INSERT、UPDATE等* @return*/protected abstract ShadowOperationType getShadowOperationType();/*** 解析SQL语句的注释信息* @return*/protected abstract Optional<Collection<String>> parseSQLComments();/*** 获取投影列的条件迭代器* @param shadowColumn* @return*/protected abstract Iterator<Optional<ShadowColumnCondition>> getShadowColumnConditionIterator(String shadowColumn);/*** 获取第一个表名* @return*/protected String getSingleTableName() {return tableAliasNameMappings.entrySet().iterator().next().getValue();}
}在ShadowSQLRouter的decorateRouteContext()方法中,通过ShadowRouteEngineFactory的newInstance()获取一个ShadowRouteEngine对象,执行ShadowRouteEngine的route()方法。即执行AbstractShadowDMLStatementRouteEngine的route()方法。
route()方法执行如下:
1)执行findShadowDataSourceMappings()方法,查找影子库数据源映射。key为生产数据源、value为影子数据源;
1.1)从SQL语句中的所有表,查找配置影子规则的表;
1.2)如果没有满足的表 && 投影规则配置了默认投影算法,则返回配置的所有影子数据源;
1.3)否则:
1.3.1)查找SQL的注释部分,获取数据源信息。key为生产数据源、value为影子数据源,如果找到,返回结果;否则往下继续执行;
1.3.2)查找表中的是否存在满足条件的影子列,如果存在,则返回对应表的数据源映射;
2)执行父类ShadowRouteEngine的decorateRouteContext(),装饰路由上下文;
遍历当前路由上下文中的路由单元,根据路由单元中的实际数据源,执行如下:
2.1)如果实际数据源配置了影子规则,则继续执行;
2.2)从1)中查找对应的实际数据源在当前SQL语句中是否满足了影子的条件(如果存在就满足,不存在就不满足),存在则替换为影子数据源;
影子库配置示例
rules:- !SHADOWdataSources:ds1: # 投影组的逻辑数据源的名称productionDataSourceName: dsshadowDataSourceName: shadow_dstables:t_order:dataSourceNames:- ds1 # 以上 dataSources下的dsshadowAlgorithmNames:- user_id_insert_match_algorithm- sql_hint_algorithmshadowAlgorithms:user_id_insert_match_algorithm:type: REGEX_MATCHprops:operation: insertcolumn: user_idregex: "[1]"sql_hint_algorithm:type: SQL_HINT小结
以上为本篇分析的全部内容,以下做一个小结:
1)ShardingSphere 影子库是一个在数据库层面解决全链路在线压测问题的有效工具,影子库用于接收测试数据,以防止测试数据污染生产数据库;
2)影子库规则对应的路由器对象为ShadowSQLRouter,在ShardingSpherePreparedStatement执行SQL语句进行SQL路由创建RouteContext路由上下文时最后执行的路由器;
3)影子库路由器中,通过ShadowRouteEngineFactory的newInstance()创建影子库路由引擎;
不同的SQL操作语句,创建不同的路由引擎,如插入语句,创建ShadowInsertStatementRoutingEngine;
4)ShadowInsertStatementRoutingEngine插入语句的路由引擎,继承于抽象类AbstractShadowDMLStatementRouteEngine。父类负责整体逻辑允许,针对不同SQL操作语句的实现类路由引擎,提供对应影子库判断信息;
4.1)在父类AbstractShadowDMLStatementRouteEngine的route()路由方法中,查找SQL语句中满足影子库规则的数据源映射;
4.1.1)从SQL语句中的所有表,查找配置影子规则的表。如果没有满足的表 && 投影规则配置了默认投影算法,则返回配置的所有影子数据源;
4.1.2)查找SQL的注释部分,获取数据源信息。key为生产数据源、value为影子数据源,如果找到,返回结果;
4.1.3)查找表中的是否存在满足条件的影子列,如果存在,则返回对应表的数据源映射;
4.1.3.1)在ShadowInsertStatementRoutingEngine中,解析SQL的插入表及列,判断对应表的列是否配置了影子库路由规则,如果有配置,返回列及对应列的插入值;
4.1.3.2)在父类AbstractShadowDMLStatementRouteEngine中,获取子类提供的设置了影子列及值,执行影子库算法,判断值是否满足配置的规则,如果满足,保存对应表的数据源映射,最终返回满足条件的数据源映射;
4.2)遍历当前路由上下文的路由单元,替换数据源映射中的真实数据源为影子数据源名称;
关于本篇内容你有什么自己的想法或独到见解,欢迎在评论区一起交流探讨下吧。
相关文章:

【源码】Sharding-JDBC源码分析之SQL中影子库ShadowSQLRouter路由的原理
Sharding-JDBC系列 1、Sharding-JDBC分库分表的基本使用 2、Sharding-JDBC分库分表之SpringBoot分片策略 3、Sharding-JDBC分库分表之SpringBoot主从配置 4、SpringBoot集成Sharding-JDBC-5.3.0分库分表 5、SpringBoot集成Sharding-JDBC-5.3.0实现按月动态建表分表 6、【…...

雷池 WAF 搭配阿里云 CDN 使用教程
雷池 WAF(Web Application Firewall)是一款强大的网络安全防护产品,通过实时流量分析和精准规则拦截,有效抵御各种网络攻击。在部署雷池 WAF 的同时,结合阿里云 CDN(内容分发网络)可以显著提升网…...

3.银河麒麟V10 离线安装Nginx
1. 下载nginx离线安装包 前往官网下载离线压缩包 2. 下载3个依赖 openssl依赖,前往 官网下载 pcre2依赖下载,前往Git下载 zlib依赖下载,前往Git下载 下载完成后完整的包如下: 如果网速下载不到请使用网盘下载 通过网盘分享的文件…...

【模块一】kubernetes容器编排进阶实战之kubernetes 资源限制
kubernetes 资源限制 kubernetes中资源限制概括 1.如果运行的容器没有定义资源(memory、CPU)等限制,但是在namespace定义了LimitRange限制,那么该容器会继承LimitRange中的 默认限制。 2.如果namespace没有定义LimitRange限制,那么该容器可…...

【开源】一款基于SpringBoot的智慧小区物业管理系统
一、下载项目文件 项目文件源码链接:https://pan.quark.cn/s/3998d958e182如出现网盘空间不够存的情况!!!解决办法是先用夸克手机app注册,然后保存上方链接,就可以得到1TB空间了!!&…...

Goland:专为Go语言设计的高效IDE
本文还有配套的精品资源,点击获取 简介:Goland是JetBrains公司开发的集成开发环境(IDE),专为Go语言设计,提供了高效的代码编辑、强大的调试工具和丰富的项目管理功能。其智能代码补全、强大的调试与测试支…...

云手机与Temu矩阵:跨境电商运营新引擎
云手机与 Temu 矩阵结合的基础 云手机技术原理 云手机基于先进的 ARM 虚拟化技术,在服务器端运行 APP。通过在服务器上利用容器虚拟化软件技术,能够虚拟出多个独立的手机操作系统实例,每个实例等同于一部单独的手机,可独立运行各…...

仓颉编程笔记1:变量函数定义,常用关键字,实际编写示例
本文就在网页版上体验一下仓颉编程,就先不下载它的SDK了 基本围绕着实际摸索的编程规则来写的 也没心思多看它的文档,写的不太明确,至少我是看的一知半解的 文章提供测试代码讲解、测试效果图: 目录 仓颉编程在线体验网址&…...
、中括号[ ]和大括号{}代表什么)
Python小括号( )、中括号[ ]和大括号{}代表什么
python语言最常见的括号有三种,分别是:小括号( )、中括号[ ]和大括号也叫做花括号{ },分别用来代表不同的python基本内置数据类型。 小括号():struct结构体,但不能改值 python中的小括号( )&am…...

React里使用lodash工具库
安装 使用命令 npm install lodash 页面引入 常见的引入方式 引入整个lodash对象: import _ from lodash按名称引入特定的函数: import { orderBy } from "lodash"; tips: 这两种引入方式都会引入整个lodash库, 体积大&#x…...

【免费分享】mysql笔记,涵盖查询、缓存、存储过程、索引,优化。
概括 本篇笔记涵盖基础查询、视图、存储过程、函数、索引、优化、分库分表。适合在学完mysql后进行时常观看。下面展示部分内容。如果需要可以在文章底部的链接进行下载查看。 简介 数据库 数据库:DataBase,简称 DB,存储和管理数据的仓库…...

C语言-数据结构-图
目录 一,图的概念 1,图的定义 2,图的基本术语 二,图的存储结构 1,邻接矩阵 2,邻接表 三,图的遍历 1,深度优先搜索 2,广度优先搜素 四,生成树和最小生成树 1,生成树的特点: 2,最小生成树 (1)普利姆算法Prim (2)普里姆算法思路 五,最短路径 1,Dijkstra算法 2,Fl…...
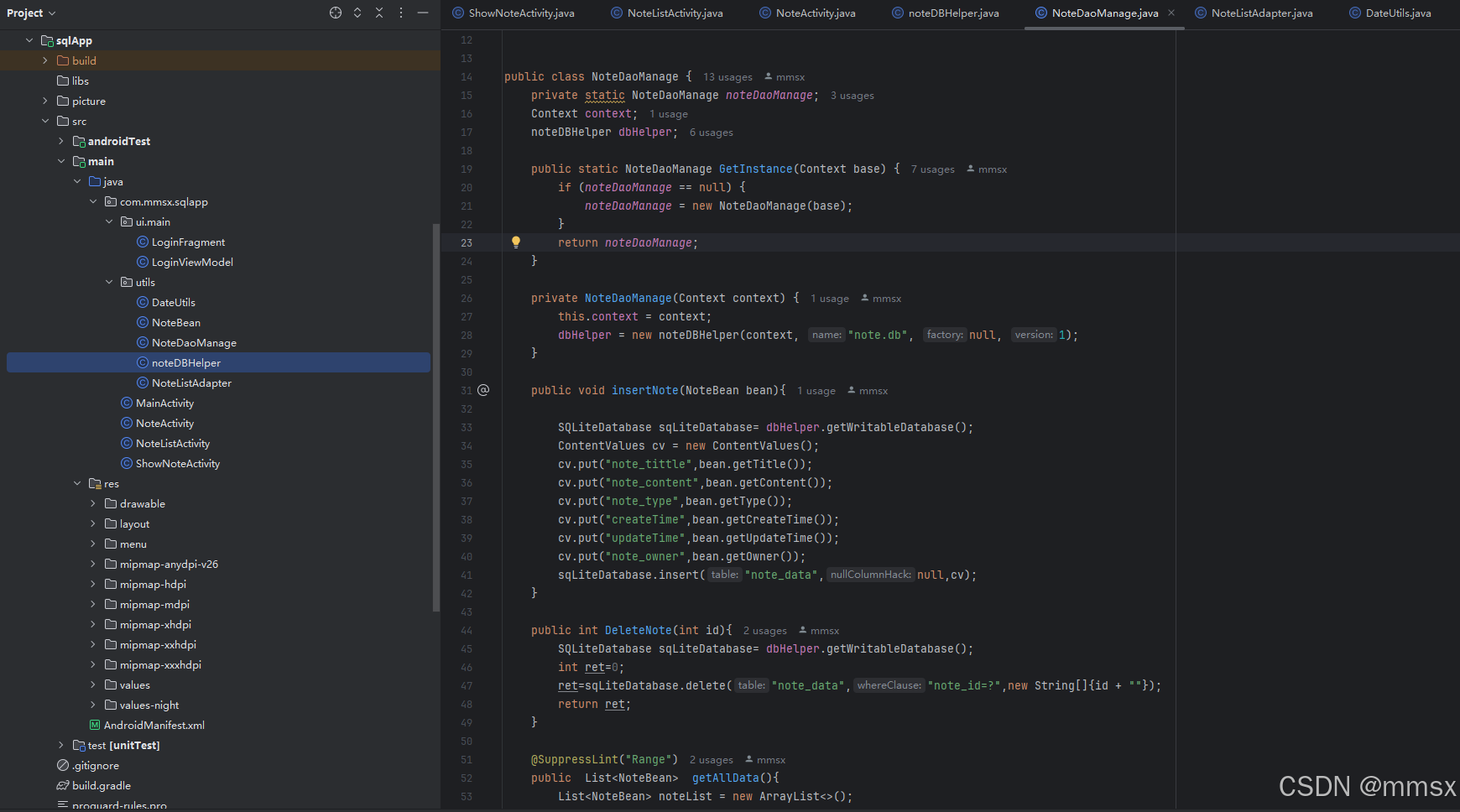
android sqlite 数据库简单封装示例(java)
sqlite 数据库简单封装示例,使用记事本数据库表进行示例。 首先继承SQLiteOpenHelper 使用sql语句进行创建一张表。 public class noteDBHelper extends SQLiteOpenHelper {public noteDBHelper(Context context, String name, SQLiteDatabase.CursorFactory fact…...

“宠物服务的跨平台整合”:多设备宠物服务平台的实现
2.1 SSM框架介绍 本课题程序开发使用到的框架技术,英文名称缩写是SSM,在JavaWeb开发中使用的流行框架有SSH、SSM、SpringMVC等,作为一个课题程序采用SSH框架也可以,SSM框架也可以,SpringMVC也可以。SSH框架是属于重量级…...

关于最新MySQL9.0.1版本zip自配(通用)版下载、安装、环境配置
一、下载 从MySQL官网进行下载MySQL最新版本,滑到页面最下面点击社区免费版,(不是企业版) 点击完成后选择自己想要下载的版本,选择下载zip压缩,不用debug和其他的东西。 下载完成后进入解压,注…...

【Halcon】例程讲解:基于形状匹配与OCR的多图像处理(附图像、程序下载链接)
1. 开发需求 在参考图像中定义感兴趣区域(ROI),用于形状匹配和文本识别。通过形状匹配找到图像中的目标对象位置。对齐多幅输入图像,使其与参考图像保持一致。在对齐后的图像上进行OCR识别,提取文本和数字信息。以循环…...

B站推荐模型数据流的一致性架构
01 背景 推荐系统的模型,通过学习用户历史行为来达到个性化精准推荐的目的,因此模型训练依赖的样本数据,需要包括用户特征、服务端推荐的视频特征,以及用户在推荐视频上是否有一系列的消费行为。 推荐模型数据流,即为…...

不安全物联网的轻量级加密:综述
Abstract 本文综述了针对物联网(IoT)的轻量级加密解决方案。这项综述全面覆盖了从轻量级加密方案到不同类型分组密码的比较等多个方面。同时,还对硬件与软件解决方案之间的比较进行了讨论,并分析了当前最受信赖且研究最深入的分组…...

mysql_init的概念和使用案例
mysql_init 是 MySQL C API 中的一个函数,用于初始化一个 MYSQL 结构,这个结构在后续的 MySQL 数据库操作中会被频繁使用。mysql_init 的调用是建立与 MySQL 数据库连接的第一步。 函数原型: MYSQL *mysql_init(MYSQL *mysql);参数说明&…...

3GPP R18 MT-SDT
Rel-17 指定MO-SDT允许针对UL方向的数据包进行小数据包传输。对于DL,MT-SDT(即DL触发的小数据)可带来类似的好处,即 通过不转换到 RRC_CONNECTED来减少信令开销和UE功耗,并通过允许快速传输(小而少见的)数据包(例如用于定位)来减少延迟。 在R17中,NR_SmallData_INACTIVE的工…...

原创:黄大年茶思屋难题揭榜第141期|5道核心题精简公开·未获技术反馈求指正
黄大年茶思屋难题揭榜第141期|5道核心题精简公开未获技术反馈求指正 作者:华夏之光永存 摘要 这五道题我们已完整解题并提交黄大年茶思屋难题揭榜,最终被退回,但平台未给出任何具体技术驳回意见、未指明缺陷、未提供修改方向。我们…...

认知迷雾计划:用废话消耗AI算力
被低效会议吞噬的AI资源在软件测试领域,AI驱动工具正逐步承担自动化测试、缺陷预测、日志分析等高价值任务。然而,一种名为“认知迷雾”的隐形威胁——即低效会议产生的海量冗余信息——正在持续消耗宝贵算力资源。本文从测试工程视角,剖析废…...

ESP32-IDF开发实战:内置JTAG与OpenOCD高效调试指南
1. 为什么选择ESP32内置JTAG调试? 第一次接触ESP32开发时,你可能会有疑问:市面上这么多调试工具,为什么非要折腾内置JTAG?我刚开始用串口打印调试信息,后来发现这种方法在排查复杂逻辑时效率太低。直到尝试…...

交叉调整率差的5大根源—变压器、绕组、反馈、拓扑、元件
Q1:导致交叉调整率差的第一大根源是什么?变压器漏感与绕组耦合不良。漏感使能量不能完全传递到辅路,各绕组漏感不一致,负载变化时电压漂移更明显。耦合系数越接近 1,交叉调整率越好。Q2:绕组绕制方式对交叉…...

面试回答第十五问:类加载
类加载简介 类加载是JVM能够识别类信息,分配空间创建对象实例的基础。 类加载一共分为五阶段,分别是加载,验证,准备,解析,初始化五阶段。这不是顺序,不是加载之后才能验证,验证之后才…...

别再重装OriginPro了!遇到盗版弹窗,试试这个修改Hosts文件的永久方案
彻底解决OriginPro授权验证问题的技术指南 引言:为何传统方法无法根治授权问题 许多科研工作者和数据分析师都曾遇到过这样的困扰:明明已经安装了正版OriginPro软件,却频繁遭遇"盗版提示"弹窗。更令人沮丧的是,重装系统…...

流程越来越规范,但员工体验却越来越差
在很多企业推进 IT 管理规范化的过程中,流程建设往往是重点。 审批流程更加清晰,操作步骤更加标准,所有请求都可以通过系统统一管理。从管理角度来看,这是明显的进步。 流程可控、操作可追溯、风险也更容易管理。但从员工的实际体…...

基于RexUniNLU的Linux系统日志智能分析方案
基于RexUniNLU的Linux系统日志智能分析方案 1. 引言 每天面对海量的Linux系统日志,是不是感觉头大?服务器突然卡顿,排查问题就像大海捞针,一行行翻日志看得眼睛都花了。传统的关键词搜索和正则匹配已经跟不上现代运维的需求&…...

不同品牌路由器也能玩桥接?TP-LINK AC1200主路由+FAST FWR303副路由详细配置指南
跨品牌路由器桥接实战:TP-LINK AC1200与FAST FWR303混合组网全解析 现代家庭网络环境中,信号死角问题如同房间角落的灰尘一样难以避免。特别是当房屋结构复杂或面积较大时,单台路由器往往力不从心。此时,利用家中闲置的旧路由器进…...

智能求职工具GetJobs:让你的投递效率提升300%的全流程指南
智能求职工具GetJobs:让你的投递效率提升300%的全流程指南 【免费下载链接】get_jobs 💼【找工作最强助手】全平台自动投简历脚本:(boss、前程无忧、猎聘、拉勾、智联招聘) 项目地址: https://gitcode.com/gh_mirrors/ge/get_jobs 每天…...