Vivado - TCL 命令(DPU脚本、v++命令、impl策略)
目录
1. 简介
2. TCL 示例
2.1 DPU TCL 脚本
2.1.1 源码-精简
2.1.2 依赖关系
2.1.3 查 v++ 步骤列表
2.1.4 生成 DPU.XO
2.2 CPU 示例
2.2.1 源码-框架
2.2.2 示例设计详解
2.3 创建运行脚本
2.3.1 Generate scripts
2.3.2 runme.sh 文件
2.3.3 design_1_wrapper.tcl
2.3.4 write_project_tcl
3. v++ 命令
3.1 impl 策略
3.2 interactive
3.3 reuse_impl
3.4 reuse_bit
3.5 xclbinutil
4. 总结
1. 简介
本文旨在介绍在使用 Xilinx FPGA 进行加速应用开发时,三个关键方面的相关技术和命令:DPU 脚本、v++ 命令以及实现(impl)策略。
DPU脚本: 通过平台文件 XSA 创建 DPU 的主要 TCL 代码。
v++ 命令涵盖了以下主要功能:
- 编译: 将内核代码编译成硬件描述语言(HDL)或中间表示形式(IR)。
- 链接: 将编译后的内核与平台硬件资源连接起来,生成硬件比特流。
- 打包: 将比特流、内核元数据和其他必要的文件打包成一个可部署的软件包。
impl 策略: 实现策略指的是在Vivado工具中,针对设计进行布局布线(Place & Route)和时序优化的策略。
2. TCL 示例
2.1 DPU TCL 脚本
2.1.1 源码-精简
DIR_PRJ = $(shell pwd)/${BOARD}
DIR_TRD = $(shell pwd)/DPUCZDX8Gall : check_env dpu.xclbincheck_env :@echo "BOARD: ${BOARD}"@echo "VITIS_PLATFORM: ${DIR_PRJ}/platform.xsa"bash check_env.sh${DIR_PRJ}/kernel_xml/dpu/kernel.xml:@mkdir -p $(@D)cp -rf ${DIR_TRD}/prj/Vitis/kernel_xml/dpu/kernel.xml $@# 创建脚本目录,并逐个拷贝脚本
${DIR_PRJ}/scripts:@mkdir -p $@
${DIR_PRJ}/scripts/gen_dpu_xo.tcl: $(DIR_PRJ)/scriptscp -f ${DIR_TRD}/prj/Vitis/scripts/gen_dpu_xo.tcl $@
${DIR_PRJ}/scripts/bip_proc.tcl : $(DIR_PRJ)/scriptscp -f ${DIR_TRD}/prj/Vitis/scripts/bip_proc.tcl $@
${DIR_PRJ}/scripts/package_dpu_kernel.tcl: $(DIR_PRJ)/scriptscp -f ${DIR_TRD}/prj/Vitis/scripts/package_dpu_kernel.tcl $@sed -i 's/set path_to_hdl "..\/..\/dpu_ip"/set path_to_hdl "..\/DPUCZDX8G\/dpu_ip"/' $@DPU_HDLSRCS= \${DIR_PRJ}/kernel_xml/dpu/kernel.xml \${DIR_PRJ}/scripts/package_dpu_kernel.tcl \${DIR_PRJ}/scripts/gen_dpu_xo.tcl \${DIR_PRJ}/scripts/bip_proc.tcl \${DIR_PRJ}/dpu_conf.vh \${DIR_TRD}/dpu_ip/Vitis/dpu/hdl/DPUCZDX8G.v \${DIR_TRD}/dpu_ip/Vitis/dpu/inc/arch_def.vh \${DIR_TRD}/dpu_ip/Vitis/dpu/xdc/*.xdc \${DIR_TRD}/dpu_ip/DPUCZDX8G_*/hdl/DPUCZDX8G_*_dpu.sv \${DIR_TRD}/dpu_ip/DPUCZDX8G_*/inc/function.vh \${DIR_TRD}/dpu_ip/DPUCZDX8G_*/inc/arch_para.vh# 生成dpu.xo文件
binary_container_1/dpu.xo: ${DPU_HDLSRCS}@mkdir -p ${DIR_PRJ}/binary_container_1-@rm -f ${DIR_PRJ}/$@cd ${DIR_PRJ} ;\$(XILINX_VIVADO)/bin/vivado -mode batch -source scripts/gen_dpu_xo.tcl -notrace -tclargs $@ DPUCZDX8G hw ${BOARD}# 生成dpu.xclbin文件
dpu.xclbin: binary_container_1/dpu.xo ${DIR_PRJ}/platform.xsacd ${DIR_PRJ} ;\v++ -l \-t hw \--platform ${DIR_PRJ}/platform.xsa \--save-temps \--config ${DIR_PRJ}/prj_config \--temp_dir binary_container_1 \--log_dir binary_container_1/logs \--package.no_image \--remote_ip_cache binary_container_1/ip_cache \-o ${DIR_PRJ}/binary_container_1/$@ $< \--xp param:compiler.userPostSysLinkOverlayTcl=${DIR_TRD}/prj/Vitis/syslink/strip_interconnects.tclcp -f ${DIR_PRJ}/binary_container_1/link/vivado/vpl/prj/prj.gen/sources_1/bd/*/hw_handoff/*.hwh ${DIR_PRJ}/dpu.hwhcp -f ${DIR_PRJ}/binary_container_1/link/vivado/vpl/prj/prj.runs/impl_1/*.bit ${DIR_PRJ}/dpu.bitcp -f ${DIR_PRJ}/binary_container_1/$@ ${DIR_PRJ}/dpu.xclbin.PHONY: all check_envv++: 这是 Vitis 编译器的可执行文件。
- -l: 启用链接器。
- -t hw: 指定目标平台为硬件 (hardware)。
- --platform /kv260_v1/platform.xsa: 指定使用的硬件平台。
- --save-temps: 保存编译过程中的中间文件,用于调试和分析。
- --config /kv260_v1/prj_config: 指定项目配置文件。
- --xp param:compiler.userPostSysLinkOverlayTcl=/boards/DPUCZDX8G/prj/Vitis/syslink/strip_interconnects.tcl: 在系统链接 (SysLink) 阶段之后执行一个自定义的 Tcl 脚本 strip_interconnects.tcl,该脚本可能用于优化或修改生成的硬件连接。
- --temp_dir binary_container_1: 指定临时文件的存放目录。
- --log_dir binary_container_1/logs: 指定日志文件的存放目录。
- --package.no_image: 不生成可引导的镜像文件。
- --remote_ip_cache binary_container_1/ip_cache: 指定远程 IP 核缓存的路径。
- -o /kv260_v1/binary_container_1/dpu.xclbin: 指定输出文件的路径和名称,即生成的硬件二进制文件 dpu.xclbin。
- binary_container_1/dpu.xo: 指定输入文件的路径和名称,即经过编译和优化后的设计文件。
2.1.2 依赖关系
当执行 make all(也即 make BOARD=kv260_som)时,make 将首先检查 dpu.xclbin 的依赖项
- binary_container_1/dpu.xo
- ${DIR_PRJ}/platform.xsa(由用户指定)
为了构建 dpu.xo 这个目标,make 将检查 DPU_HDLSRCS 中所有列出的文件:
DPU_HDLSRCS= \${DIR_PRJ}/kernel_xml/dpu/kernel.xml \${DIR_PRJ}/scripts/package_dpu_kernel.tcl \${DIR_PRJ}/scripts/gen_dpu_xo.tcl \${DIR_PRJ}/scripts/bip_proc.tcl \${DIR_PRJ}/dpu_conf.vh \${DIR_TRD}/dpu_ip/Vitis/dpu/hdl/DPUCZDX8G.v \${DIR_TRD}/dpu_ip/Vitis/dpu/inc/arch_def.vh \${DIR_TRD}/dpu_ip/Vitis/dpu/xdc/*.xdc \${DIR_TRD}/dpu_ip/DPUCZDX8G_*/hdl/DPUCZDX8G_*_dpu.sv \${DIR_TRD}/dpu_ip/DPUCZDX8G_*/inc/function.vh \${DIR_TRD}/dpu_ip/DPUCZDX8G_*/inc/arch_para.vh此时,以下文件将被复制:
${DIR_PRJ}/kernel_xml/dpu/kernel.xml:@mkdir -p $(@D)cp -rf ${DIR_TRD}/prj/Vitis/kernel_xml/dpu/kernel.xml $@${DIR_PRJ}/scripts:@mkdir -p $@
${DIR_PRJ}/scripts/gen_dpu_xo.tcl: $(DIR_PRJ)/scriptscp -f ${DIR_TRD}/prj/Vitis/scripts/gen_dpu_xo.tcl $@
${DIR_PRJ}/scripts/bip_proc.tcl : $(DIR_PRJ)/scriptscp -f ${DIR_TRD}/prj/Vitis/scripts/bip_proc.tcl $@
${DIR_PRJ}/scripts/package_dpu_kernel.tcl: $(DIR_PRJ)/scriptscp -f ${DIR_TRD}/prj/Vitis/scripts/package_dpu_kernel.tcl $@sed -i 's/set path_to_hdl "..\/..\/dpu_ip"/set path_to_hdl "..\/DPUCZDX8G\/dpu_ip"/' $@2.1.3 查 v++ 步骤列表
1)通过以下命令即可找到硬件构建的链接进程的步骤列表:
v++ --list_steps --target hw --link2)默认步骤:
- system_link
- vpl
- vpl.create_project
- vpl.create_bd
- vpl.update_bd
- vpl.generate_target
- vpl.config_hw_runs
- vpl.synth
- vpl.impl
- vpl.impl.opt_design
- vpl.impl.place_design
- vpl.impl.route_design
- vpl.impl.write_bitstream
- rtdgen
- xclbinutil
- xclbinutilinfo
- generate_sc_driver
3)可选步骤:
- vpl.impl.power_opt_design
- vpl.impl.post_place_power_opt_design
- vpl.impl.phys_opt_design
- vpl.impl.post_route_phys_opt_design
2.1.4 生成 DPU.XO
执行 make XO 来单独运行构建 binary_container_1/dpu.xo,在 Makefile 中添加如下行:
XO: binary_container_1/dpu.xo2.2 CPU 示例
《Vivado Design Suite User Guide: Using Tcl Scripting (UG894)》
2.2.1 源码-框架
使用项目流程进行编译,以下脚本展示了一个项目流程,该流程综合设计并执行完整的实现,包括比特流生成。它基于Vivado 安装目录中提供的 CPU 示例设计。
#
# 步骤#1:定义输出目录区域。
#
set outputDir ./Tutorial_Created_Data/cpu_project
file mkdir $outputDir
create_project project_cpu_project ./Tutorial_Created_Data/cpu_project \-part xc7k70tfbg676-2 -force#
# 步骤#2:设置设计源文件和约束文件
#
add_files -fileset sim_1 ./Sources/hdl/cpu_tb.v
add_files [ glob ./Sources/hdl/bftLib/*.vhdl ]
add_files ./Sources/hdl/bft.vhdl
add_files [ glob ./Sources/hdl/*.v ]
add_files [ glob ./Sources/hdl/mgt/*.v ]
add_files [ glob ./Sources/hdl/or1200/*.v ]
add_files [ glob ./Sources/hdl/usbf/*.v ]
add_files [ glob ./Sources/hdl/wb_conmax/*.v ]
add_files -fileset constrs_1 ./Sources/top_full.xdc
set_property library bftLib [ get_files [ glob ./Sources/hdl/bftLib/*.vhdl ]]#
# 在 project_cpu.srcs/sources_1/ 导入目录中物理导入文件
import_files -force -norecurse
#
# 在 project_cpu.srcs/constrs_1/ 导入目录中物理导入 bft_full.xdc
import_files -fileset constrs_1 -force -norecurse ./Sources/top_full.xdc# 更新文件集 'sources_1' 的编译顺序
set_property top top [current_fileset]
update_compile_order -fileset sources_1
update_compile_order -fileset sim_1#
# 步骤#3:运行综合和默认的利用率报告。
#
launch_runs synth_1
wait_on_run synth_1#
# 步骤#4:运行逻辑优化、布局、物理逻辑优化、布线和比特流生成。生成设计检查点、利用率和时序报告,以及自定义报告。
#
set_property STEPS.PHYS_OPT_DESIGN.IS_ENABLED true [get_runs impl_1]
set_property STEPS.OPT_DESIGN.TCL.PRE [pwd]/pre_opt_design.tcl [get_runs impl_1]
set_property STEPS.OPT_DESIGN.TCL.POST [pwd]/post_opt_design.tcl [get_runs impl_1]
set_property STEPS.PLACE_DESIGN.TCL.POST [pwd]/post_place_design.tcl [get_runs impl_1]
set_property STEPS.PHYS_OPT_DESIGN.TCL.POST [pwd]/post_phys_opt_design.tcl [get_runs impl_1]
set_property STEPS.ROUTE_DESIGN.TCL.POST [pwd]/post_route_design.tcl [get_runs impl_1]launch_runs impl_1 -to_step write_bitstream
wait_on_run impl_1puts "Implementation done!"2.2.2 示例设计详解
1)项目是通过 create_project 命令创建的。指定了项目目录和目标设备。如果项目目录尚不存在,则会自动创建。在此示例中,用于保存各种报告的输出目录与项目目录相同。
2)项目中使用的所有文件都需要明确声明并添加到项目中。这通过 add_files 命令完成。当文件被添加到项目中时,它会被添加到一个特定的文件集。文件集是一个将文件按用途分组的容器。在这个示例脚本中,大多数文件被添加到默认文件集(sources_1)中。只有 Verilog 测试平台 cpu_tb.v 被添加到默认仿真文件集 sim_1 中。
这些文件还通过 import_files 命令复制到项目目录中。这样,项目指向的是本地复制的源文件,而不再跟踪原始源文件。
3)通过在后台启动综合运行(launch_run synth_1),设计被综合。Vivado IDE 自动生成所有必要的脚本,以便在一个单独的 Vivado 会话中运行综合。由于综合是在不同的进程中运行,因此在继续当前脚本之前,需要等待其完成。这通过使用 wait_on_run 命令来实现。
一旦综合运行完成,可以使用 open_run synth_1 命令将结果加载到内存中。一个不带约束的检查点被保存在项目目录中,即综合运行的地方。在这个示例中,它可以在以下位置找到:
./Tutorial_Created_Data/cpu_project/project_cpu.runs/synth_1/top.dcp
注意:synth_1 和 impl_1 是综合和实现运行的默认名称。可以使用 create_run 命令创建其他运行。
4)实现是通过使用 launch_run 命令完成的。从预布局优化到写入比特流的完整布局布线流程可以通过一个命令来执行。在这个示例脚本中,实现一直进行到比特流生成(launch_run impl_1 -to_step write_bitstream)。
可选步骤 phys_opt_design 在脚本中通过属性 STEPS.PHYS_OPT_DESIGN.IS_ENABLED 启用。与允许根据用户定义的条件动态调用实现命令的非项目流程不同,项目流程的运行必须在启动之前静态配置。这就是为什么在这个示例中,物理逻辑优化步骤在放置后不检查时序松弛值的情况下启用的原因,这与使用非项目流程进行编译的示例不同。
通过使用运行 Tcl 钩子属性 STEPS.<STEPNAME>.TCL.PRE 和 STEPS.<STEPNAME>.TCL.POST,在每个实现步骤之前或之后生成各种报告。这些属性允许用户在使用运行基础设施时指定 Tcl 脚本在流程中的执行位置。有关更多信息,请参见定义 Tcl 钩子脚本。
由于实现运行是在一个单独的 Vivado 会话中执行的,所有的 Tcl 变量和过程都需要在该会话中初始化,以便脚本使用。这可以通过几种方式完成:
- 方法1:在 Vivado_init.tcl 中定义 Tcl 变量和过程(请参见初始化 Tcl 脚本)。这将对您所有的 Vivado 项目和会话生效。
- 方法2:将包含变量和过程的 Tcl 脚本添加到运行所使用的约束集中。当在内存中打开设计时,它将始终作为您约束的一部分被加载。
- 方法3:将 STEPS.OPT_DESIGN.TCL.PRE 设置为包含变量和过程的 Tcl 脚本。只有在 OPT_DESIGN 步骤启用时(默认情况下为启用),该脚本才会被加载。
2.3 创建运行脚本
2.3.1 Generate scripts
如果想导出并创建运行目录和运行脚本,但不希望立即启动运行脚本,可以选择 “Generate scripts only” 选项。该脚本可以稍后在 Vivado IDE 工具之外运行。

执行该步骤将会得到的文件:
design_1_wrapper.tcl
gen_run.xml
htr.txt
ISEWrap.js
ISEWrap.sh
project.wdf
rundef.js
runme.bat
runme.sh2.3.2 runme.sh 文件
1)设置环境变量:
- 检查 PATH 环境变量,PATH 告诉系统在哪里查找可执行程序。
- 定义了必要的 Vivado 和 ISE 目录的路径,确保可以访问 Vivado 工具。
- LD_LIBRARY_PATH,该变量指向 Vivado 所需的库。
2)设置工作目录:
- 定义了一个变量 HD_PWD,它指向项目中的特定运行目录 (true_preset.runs/impl_1)。
3)日志记录和脚本编写:
- runme.log 文件,捕获脚本的输出。
- 变量 ISEStep 存储名为 ISEWrap.sh 的脚本的路径。
- EAStep 的函数。此函数接受参数并使用 ISEWrap.sh 执行它们,将输出记录到 runme.log 并捕获任何错误。
4)运行 Vivado:
- 创建 .init_design.begin.rst 文件。
- 使用以下几个参数调用 EAStep 函数:
- vivado:这是主要的 Vivado 可执行文件。
- -log design_1_wrapper.vdi:这指定了 Vivado 本身的日志文件。
- -applog:启用应用程序级日志记录。
- -m64:这表示 64 位模式。
- -product Vivado:指定产品为 Vivado。
- -messageDb vivado.pb:定义消息数据库文件。
- -mode batch:启用批处理模式,用于从脚本运行 Vivado 命令。
- -source design_1_wrapper.tcl:Vivado 要执行的实际设计命令。
- -notrace:在执行期间禁用跟踪信息。
2.3.3 design_1_wrapper.tcl
该脚本主要用于执行 Vivado 设计流程中的实现阶段,具体步骤如下:
1)初始化
- 定义一些函数,例如 create_report 用于生成报告,start_step 和 end_step 用于创建和删除步骤标记文件。
- 连接到 Vivado 调度器(dispatch)(如果可用),用于日志记录。
2. 开始实现
- 创建消息数据库文件(init_design.pb)用于存储消息。
- 设置一些项目属性,例如设计模式、最大作业数等。
- 创建一个 内存中的项目,并指定目标器件、约束文件等信息。
- 添加设计源文件(.dcp 格式)和约束文件(.xdc 格式)到项目中。
- 设置顶层模块(design_1_wrapper)和目标器件。
- 读取约束文件。
- 调用 link_design 函数链接设计并指定顶层模块和目标器件。
- 执行一系列的实现步骤,包括优化(opt_design)、布局(place_design)、物理优化(phys_opt_design)、布线(route_design)、写比特流(write_bitstream)。
- 每个步骤都会调用相应的 Vivado Tcl 命令,例如 opt_design 和 route_design。
- 在每个步骤中,都会进行一些辅助操作,例如生成报告、创建检查点文件等。
3. 结束实现
- 关闭消息数据库文件。
- 根据执行结果 ($rc) 进行后续处理:
- 成功 ($rc 为 0) 则执行清理操作,例如删除步骤标记文件。
- 失败 ($rc 非 0) 则标记步骤失败并退出脚本。
4. 日志记录
- 脚本使用了 Vivado 的 OPTRACE 功能进行日志记录。
- 它记录了每个步骤的开始和结束,以及一些中间操作。
- 生成的日志文件可以帮助用户了解设计实现过程中的细节和问题。
2.3.4 write_project_tcl
write_project_tcl my_project.tcl这将生成一个名为 my_project.tcl 的脚本,其中包含了创建工程、添加源文件和运行综合的所有步骤。
你可以通过在 Vivado Tcl Console 中执行该脚本来重新创建相同的工程和运行相同的操作:
source my_project.tcl3. v++ 命令
3.1 impl 策略
《Vivado Design Suite User Guide: Implementation, UG904》
| Category | Purpose |
|-------------|----------------------------------------|
| Performance | Improve design performance |
| Area | Reduce LUT count |
| Power | Add full power optimization |
| Flow | Modify flow steps |
| Congestion | Reduce congestion and related problems |1)Vivado Implementation Defaults
- 在平衡运行时间的同时尝试实现时序收敛。
2)Performance_Explore
- 使用多种算法进行优化、布局和布线,以获得潜在的更好结果。
3)Performance_ExplorePostRoutePhysOpt
- 类似于Performance_Explore,但在布线后添加 phys_opt_design 以进行进一步改进。
4)Performance_LBlockPlacement
- 忽略放置块 RAM 和 DSP 的时序约束,使用线长代替。
5)Performance_LBlockPlacementFanoutOpt
- 忽略放置块 RAM 和 DSP 的时序约束,使用线长代替,并对高扇出驱动器进行激进复制。
6)Performance_EarlyBlockPlaceent
- 在全局布局的早期阶段完成块 RAM 和 DSP 的放置。
7)Performance_NetDelay_high
- 为了补偿乐观的延迟估计,增加额外的延迟成本到长距离和高扇出连接(高设置,最悲观)。
8)Performance_NetDelay_low
- 为了补偿乐观的延迟估计,增加额外的延迟成本到长距离和高扇出连接(低设置,较不悲观)。
9)Performance_Retiming
- 将 retiming 与 phys_opt_design 中的额外布局优化和更高的路由器延迟成本结合起来。
10)Performance_ExtraTimingOpt
- 运行额外的时序驱动优化以潜在地改善总体时序裕度。
11)Performance_RefinePlacement
- 增加放置器在后布局优化阶段的努力,并在路由器中禁用时序放松。
12)Performance_SpreadSLL
- 一种用于 SSI 设备的布局变体,倾向于水平扩展 SLR 交叉。
13)Performance_BalanceSLL
- 一种用于 SSI 设备的布局变体,具有更频繁的 SLR 边界交叉。
14)Congestion_SpreadLogic_high
- 在整个设备中扩展逻辑以避免创建拥挤区域(高设置是最高程度的扩展)。
15)Congestion_SpreadLogic_medium
- 在整个设备中扩展逻辑以避免创建拥挤区域(中等设置是中等程度的扩展)。
16)Congestion_SpreadLogic_low
- 在整个设备中扩展逻辑以避免创建拥挤区域(低设置是最低程度的扩展)。
17)Congestion_SpreadLogic_Explore
- 类似于 Congestion_SpreadLogic_high,但使用 Explore 指令进行路由。
18)Congestion_SSI_SpreadLogic_high
- 在整个设备中扩展逻辑以避免创建拥挤区域,适用于 SSI 设备(高设置是最高程度的扩展)。
19)Congestion_SSI_SpreadLogic_low
- 在整个设备中扩展逻辑以避免创建拥挤区域,适用于 SSI 设备(低设置是最低程度的扩展)。
20)Area_Explore
- 使用多种优化算法以减少 LUT 的数量。
21)Area_ExploreSequential
- 类似于 Area_Explore,但增加了跨顺序单元的优化。
22)Area_ExploreWithRemap
- 类似于 Area_Explore,但增加了重新映射优化以压缩逻辑级别。
23)Power_DefaultOpt
- 增加功耗优化(power_opt_design)以减少功耗。
24)Power_ExploreArea
- 将顺序面积优化与功耗优化(power_opt_design)结合以减少功耗。
25)Flow_RunPhysOpt
- 类似于 impl run 默认值,但启用了物理优化步骤(phys_opt_design)。
26)Flow_RunPostRoutePhysOpt
- 类似于 Flow_RunPhysOpt,但启用了后路由物理优化步骤,并使用 -directive Explore 选项。
27)Flow_RuntimeOptimized
- 每个实现步骤在设计性能和更好运行时间之间进行权衡。物理优化(phys_opt_design)被禁用。
28)Flow_Quick
- 最快的运行时间,所有时序驱动行为被禁用。适用于利用率估计。
3.2 interactive
v++ --interactive [ synth | impl ]v++ 会设置必要的环境并启动 Vivado IDE,以便进行综合或实现。
通过 v++ 交互式启动 Vivado IDE,链接过程会在 vpl 步骤停止,这等同于在 v++ 命令中使用 --to_step vpl 选项。当使用完 Vivado IDE 并保存了设计检查点(DCP)后,可以使用 -from_step 重新运行链接命令,从 vpl 过程继续执行。
在通过 --from_step 或 --to_step 使用可选步骤之前,必须先启用它。例如,要启用 vpl.impl.phys_opt_design 步骤,请使用 --config 选项传递一个包含以下内容的 ini 文件:
[vivado]
prop=run.impl_1.steps.phys_opt_design.is_enabled=13.3 reuse_impl
3.4 reuse_bit
《ug1393, ver 2022.2 之后》
使用 Vivado 工具生成的比特流文件来创建 project.xclbin:
v++ --link project.xo--platform <PLATFORM_NAME>--reuse_bit ./_x/link/vivado/project.bit-o'project.xclbin'注释:用于 --reuse_bit 的 project.bit 是部分 BIT 文件,而非完整 BIT 文件。
3.5 xclbinutil
xclbinutil--target hw--force--key-value SYS:dfx_enable:false--key-value SYS:PlatformVBNV:dd_kv260_kv260_pfm_preset_1_0--add-section BITSTREAM:RAW: /kv260_v1/binary_container_1/link/int/system.bit--add-section :JSON: /kv260_v1/binary_container_1/link/int/dpu.rtd--add-section CLOCK_FREQ_TOPOLOGY:JSON: /kv260_v1/binary_container_1/link/int/dpu_xml.rtd--add-section BUILD_METADATA:JSON: /kv260_v1/binary_container_1/link/int/dpu_build.rtd--add-section EMBEDDED_METADATA:RAW: /kv260_v1/binary_container_1/link/int/dpu.xml--add-section SYSTEM_METADATA:RAW: /kv260_v1/binary_container_1/link/int/systemDiagramModelSlrBaseAddress.json--output /kv260_v1/binary_container_1/dpu.xclbin4. 总结
本文主要分享三方面内容:
- DPU 脚本
- v++ 命令
- impl 策略

相关文章:
Vivado - TCL 命令(DPU脚本、v++命令、impl策略)
目录 1. 简介 2. TCL 示例 2.1 DPU TCL 脚本 2.1.1 源码-精简 2.1.2 依赖关系 2.1.3 查 v 步骤列表 2.1.4 生成 DPU.XO 2.2 CPU 示例 2.2.1 源码-框架 2.2.2 示例设计详解 2.3 创建运行脚本 2.3.1 Generate scripts 2.3.2 runme.sh 文件 2.3.3 design_1_wrapper…...

【JDBC】数据库连接的艺术:深入解析数据库连接池、Apache-DBUtils与BasicDAO
文章目录 前言🌍 一.连接池❄️1. 传统获取Conntion问题分析❄️2. 数据库连接池❄️3.连接池之C3P0技术🍁3.1关键特性🍁3.2配置选项🍁3.3使用示例 ❄️4. 连接池之Druid技术🍁 4.1主要特性🍁 4.2 配置选项…...

hadoop-common的下载位置分享
1.GitHub - steveloughran/winutils: Windows binaries for Hadoop versions (built from the git commit ID used for the ASF relase) 2.GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows 3.winutils: hadoop winutils 镜像...

【机器学习】SVM支持向量机(一)
介绍 支持向量机(Support Vector Machine, SVM)是一种监督学习模型,广泛应用于分类和回归分析。SVM 的核心思想是通过找到一个最优的超平面来划分不同类别的数据点,并且尽可能地最大化离该超平面最近的数据点(支持向量…...

Spring Boot介绍、入门案例、环境准备、POM文件解读
文章目录 1.Spring Boot(脚手架)2.微服务3.环境准备3.1创建SpringBoot项目3.2导入SpringBoot相关依赖3.3编写一个主程序;启动Spring Boot应用3.4编写相关的Controller、Service3.5运行主程序测试3.6简化部署 4.Hello World探究4.1POM文件4.1.1父项目4.1.2父项目的父…...

基于Spring Boot + Vue3实现的在线商品竞拍管理系统源码+文档
前言 基于Spring Boot Vue3实现的在线商品竞拍管理系统是一种现代化的前后端分离架构的应用程序,它结合了Java后端框架Spring Boot和JavaScript前端框架Vue.js的最新版本(Vue 3)。该系统允许用户在线参与商品竞拍,并提供管理后台…...
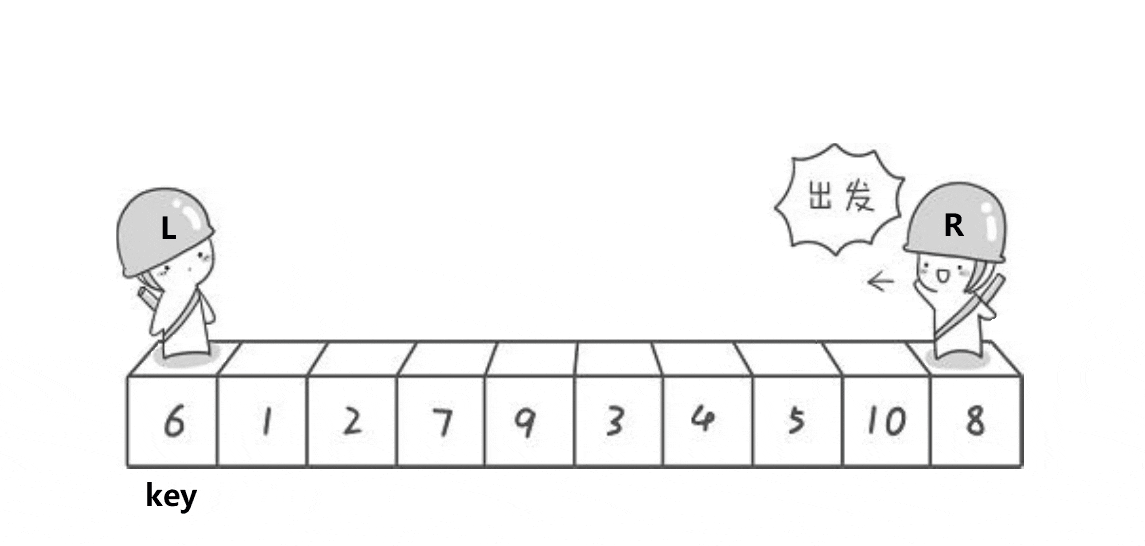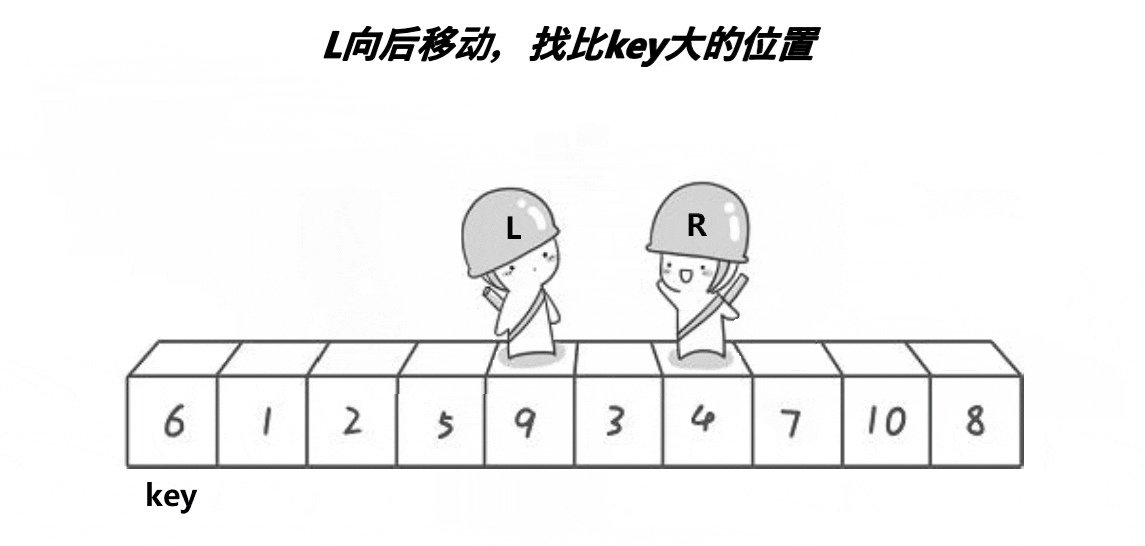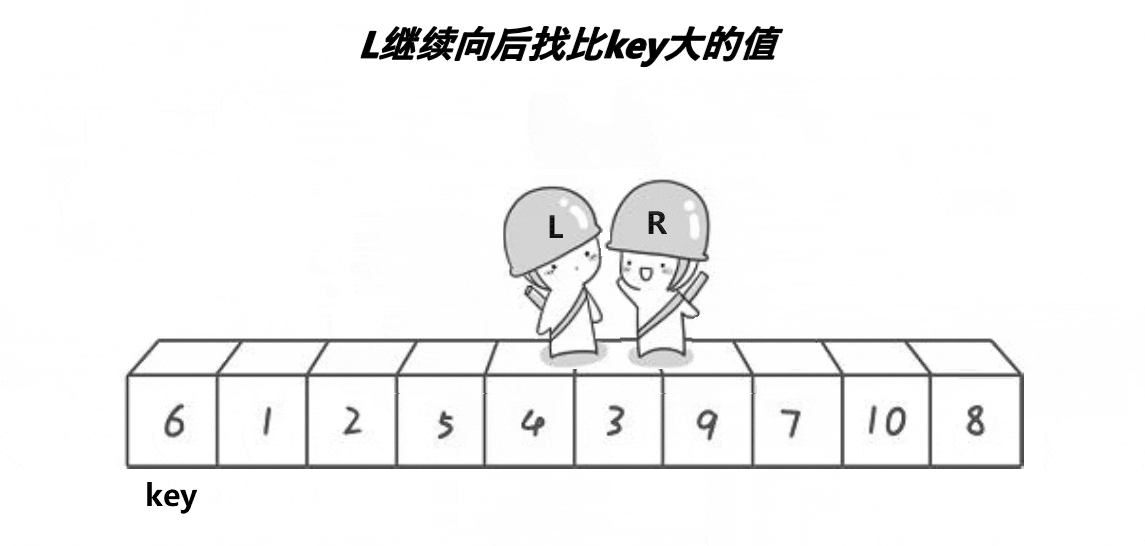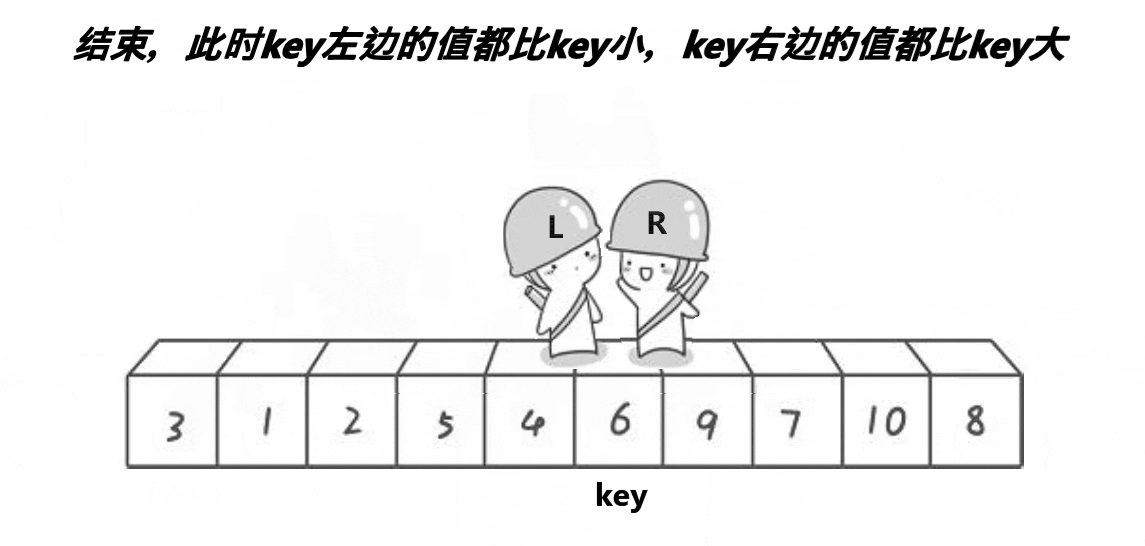
LeetCode--排序算法(堆排序、归并排序、快速排序)
排序算法 归并排序算法思路代码时间复杂度 堆排序什么是堆?如何维护堆?如何建堆?堆排序时间复杂度 快速排序算法思想代码时间复杂度 归并排序 算法思路 归并排序算法有两个基本的操作,一个是分,也就是把原数组划分成…...

华诺星空 Java 开发工程师笔试题 - 解析
单选题 1.Math.round(-11.5)等于多少?(B) A.-11.5 B.-11 C.-12 D.11.5 2.下列哪个没有继承自Collection接口。( C ) A.List B.Set C.Map D.全部 3.下列说法正确的有(B) A.在类方法中可用this来调用本类的类方法 B.在类方法中调用本类的类方法时可直接调用 C.在类…...

QT:一个TCP客户端自动连接的测试模型
版本 1:没有取消按钮 测试效果: 缺陷: 无法手动停止 测试代码 CMakeLists.txt cmake_minimum_required(VERSION 3.19) project(AutoConnect LANGUAGES CXX)find_package(Qt6 6.5 REQUIRED COMPONENTS Core Widgets Network)qt_standard_project_setup(…...

关于启动vue项目,出现:Error [ERR_MODULE_NOT_FOUND]: Cannot find module ‘xxx‘此类错误
目录 一、问题报错 二、原因分析 三、解决方法 一、问题报错 node环境变量配置有问题: (base) xxxM73H-15:~/VueProject/pproject-vue$ npm run dev /usr/bin/env: “node”: 没有那个文件或目录vue项目启动有问题: (base) xxx:~/VueProject/pproj…...

电路元件与电路基本定理
电流、电压和电功率 电流 1 定义: 带电质点的有序运动形成电流 。 单位时间内通过导体横截面的电量定义为电流强度, 简称电流,用符号 i 表示,其数学表达式为:(i单位:安培(A&#x…...

指针之矢:C 语言内存幽境的精准飞梭
一、内存和编码 指针理解的2个要点: 指针是内存中一个最小单元的编号,也就是地址平时口语中说的指针,通常指的是指针变量,是用来存放内存地址的变量 总结:指针就是地址,口语中说的指针通常指的是指针变量。…...

uniapp下载打开实现方案,支持安卓ios和h5,下载文件到指定目录,安卓文件管理内可查看到
uniapp下载&打开实现方案,支持安卓ios和h5 Android: 1、申请本地存储读写权限 2、创建文件夹(文件夹不存在即创建) 3、下载文件 ios: 1、下载文件 2、保存到本地,需要打开文件点击储存 使用方法&…...

免费干净!付费软件的平替款!
今天给大家介绍一个非常好用的电脑录屏软件,完全没有广告界面,非常的干净简洁。 电脑录屏 无广告的录屏软件 这个软件不需要安装,打开就能看到界面直接使用了。 软件可以全屏录制,也可以自定义尺寸进行录制。 录制的声音选择也非…...

软路由系统 iStoreOS 中部署 Minecraft 服务器
商业转载请联系作者获得授权,非商业转载请注明出处。协议(License): 知识共享署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)作者(Author): lhDream链接(URL): https://blog.luhua.site/archives/1734968846131 软路由系统 iStoreOS 中部署 Minecraft…...
第 29 章 - ES 源码篇 - 网络 IO 模型及其实现概述
前言 本文介绍了 ES 使用的网络模型,并介绍 transport,http 接收、响应请求的代码入口。 网络 IO 模型 Node 在初始化的时候,会创建网络模块。网络模块会加载 Netty4Plugin plugin。 而后由 Netty4Plugin 创建对应的 transports࿰…...

细说STM32F407单片机IIC总线基础知识
目录 一、 I2C总线结构 1、I2C总线的特点 2、I2C总线通信协议 3、 STM32F407的I2C接口 二、 I2C的HAL驱动程序 1、 I2C接口的初始化 2、阻塞式数据传输 (1)函数HAL_I2C_IsDeviceReady() (2)主设备发送和接收数据 &#…...

从头开始学MyBatis—04缓存、逆向工程、分页插件
介绍了MyBatis的缓存、逆向工程和分页插件的使用 目录 1.Mybatis的缓存 1.1MyBatis的一级缓存 1.2MyBatis的二级缓存 1.3二级缓存的相关配置 1.4MyBatis缓存查询的顺序 1.5整合第三方缓存EHCache 1.5.1添加依赖 1.5.2各jar包功能 1.5.3创建EHCache的配置文件ehcache.x…...

Artec Space Spider助力剑桥研究团队解码古代社会合作【沪敖3D】
挑战:考古学家需要一种安全的方法来呈现新出土的陶瓷容器,对比文物形状。 解决方案:Artec Space Spider, Artec Studio 效果:本项目是REVERSEACTION项目的一部分,旨在研究无国家社会中复杂的古代技术。研究团队在考古地…...

《探索PyTorch计算机视觉:原理、应用与实践》
《探索PyTorch计算机视觉:原理、应用与实践》 一、PyTorch 与计算机视觉的奇妙相遇二、核心概念解析(一)张量:计算机视觉的数据基石(二)神经网络:视觉任务的智慧大脑(三)…...
:物料系统之内置组件库)
AI驱动的Vue3应用开发平台深入探究(十):物料系统之内置组件库
内置组件库(Element Plus、Ant Design Vue、Vant) VTJ 通过其统一的物料系统架构,与三个流行的 Vue 组件库提供了全面的集成。这一抽象层使开发者能够利用熟悉的组件模式,同时保持低代码的可扩展性和跨库的可移植性。该系统将组件…...

极客玩法:OpenClaw+Qwen3-32B实现命令行AI增强
极客玩法:OpenClawQwen3-32B实现命令行AI增强 1. 为什么需要命令行AI助手? 作为一个常年与终端打交道的开发者,我发现自己每天要重复输入大量命令:查日志、部署服务、处理数据……这些操作往往需要记住复杂的参数组合࿰…...

3步快速修复Netgear路由器变砖的终极解决方案
3步快速修复Netgear路由器变砖的终极解决方案 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 路由器变砖是许多网络设备用户最头疼的问题之一,特别是当固件升级失败或意外断电导致设备无法启动…...

Go Routine 调度器架构分析
Go Routine调度器架构分析 Go语言凭借其轻量级的并发模型在开发者中广受欢迎,而Go Routine调度器正是这一模型的核心。它高效地管理成千上万的协程,确保它们在有限的系统线程上合理运行。本文将深入分析Go Routine调度器的架构设计,帮助读者…...

AI 模型推理引擎性能对比
AI模型推理引擎性能对比:如何选择最优方案 随着AI技术在各行业的广泛应用,模型推理引擎的性能成为影响落地效果的关键因素。不同的推理引擎在计算效率、资源占用、兼容性等方面表现各异,如何选择最适合的引擎成为开发者关注的焦点。本文将从…...

AI破壁者:OpenClaw+nanobot镜像跨软件自动化方案
AI破壁者:OpenClawnanobot镜像跨软件自动化方案 1. 为什么我们需要跨软件自动化 作为一名经常需要处理设计数据的分析师,我每天都要在Photoshop、Excel和PowerPoint之间来回切换。上周五下午,当我第17次手动复制粘贴数据时,终于…...

解析大数据领域Elasticsearch的分词器原理
解析大数据领域Elasticsearch的分词器原理:从"切菜"到"调味"的文本处理之旅 关键词:Elasticsearch、分词器、文本处理、字符过滤、词元过滤、中文分词、搜索优化 摘要:在大数据搜索场景中,“如何让机器读懂人…...
)
别再傻傻格式化!RC522读不出NFC卡数据?试试这几组万能密钥(附Arduino代码)
RC522读卡失败急救指南:万能密钥库与自动破解方案 当你兴奋地将RC522模块连接到Arduino,准备读取NFC卡数据时,突然发现卡片无法识别——这种挫败感我深有体会。三年前我第一次接触RFID项目时,曾因为一张价值200元的工牌被"锁…...

ContextMenuManager:高效管理Windows右键菜单的全方案
ContextMenuManager:高效管理Windows右键菜单的全方案 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单是我们日常操作电脑时最常用的…...

不只是改IP:群晖Docker版与套件版Gitea配置迁移与地址变更全攻略
群晖NAS上Gitea部署方案对比与地址变更深度指南 在私有云和代码托管领域,群晖NAS凭借其稳定的硬件性能和丰富的软件生态,成为许多开发者和技术团队搭建私有Git服务的首选平台。Gitea作为轻量级的自托管Git服务,因其简洁高效的特点,…...