操作系统动态分区分配算法-首次适应算法c语言实现
目录
一、算法原理
二、算法特点
1.优先利用低址空闲分区:
2.查找开销:
3.内存碎片:
三、内存回收四种情况
1.回收区上面(或后面)的分区是空闲分区:
2.回收区下面(或前面)的分区是空闲分区:
3.回收区上面和下面的分区都是空闲分区:
4.回收区上面和下面的分区都不是空闲分区:
四、实现要求
1.实验数据
2.要求
五、代码实现
六、实现效果
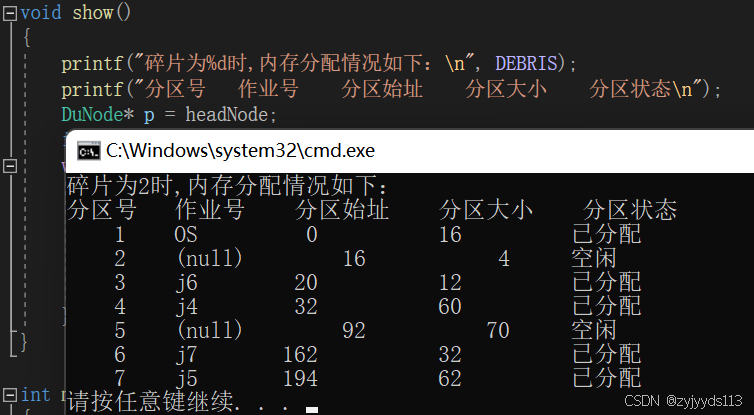
1.碎片为2
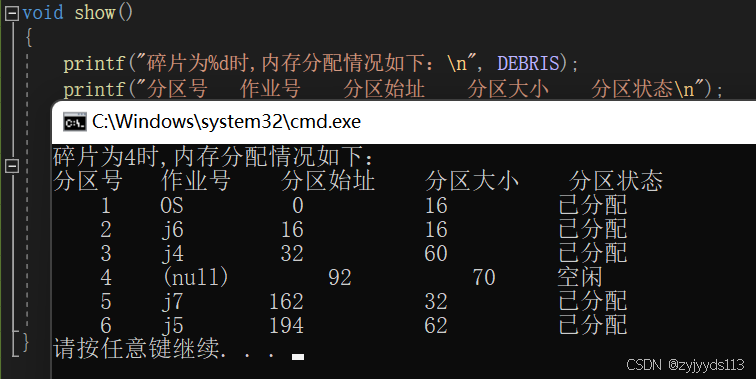
2.碎片为4
一、算法原理
首次适应算法要求空闲分区链按地址递增的次序链接。在分配内存时,从链首开始顺序查找,直到找到一个大小能满足要求的空闲分区,在根据作业大小把余下的空间与碎片大小进行比较,如果小于等于碎片大小,就全部分配给作业,否则将余下的空间仍留在空闲链中。若从链首直至链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。
二、算法特点
1.优先利用低址空闲分区:
首次适应算法倾向于优先利用内存中低址部分的空闲分区,从而保留了高址部分的大空闲区。这为以后到达的大作业分配大的内存空间创造了条件。
2.查找开销:
由于每次查找都是从低址部分开始的,这会增加查找可用空闲分区的开销。然而,由于算法简单且易于实现,这种开销在大多数情况下是可以接受的。
3.内存碎片:
首次适应算法容易产生内存碎片。当一个较大的分区被分配给较小的作业后,该分区的剩余部分可能无法再分配给其他较大的作业,导致内存碎片的产生。这些碎片无法被有效利用,从而降低了内存的利用率。
三、内存回收四种情况
1.回收区上面(或后面)的分区是空闲分区:
在这种情况下,操作系统会将回收区与上面的空闲分区合并,形成一个新的、更大的空闲分区。这样,就可以减少内存中的碎片数量,提高内存的利用率。
2.回收区下面(或前面)的分区是空闲分区:
与第一种情况类似,操作系统会将回收区与下面的空闲分区合并,形成一个新的空闲分区。这种合并操作同样有助于减少内存碎片,提高内存的连续性。
3.回收区上面和下面的分区都是空闲分区:
在这种情况下,操作系统会将回收区与上、下两个空闲分区都合并起来,形成一个更大的、连续的空闲分区。这种合并操作对于减少内存碎片、提高内存利用率具有显著的效果。
4.回收区上面和下面的分区都不是空闲分区:
在这种情况下,操作系统无法将回收区与其他空闲分区合并。此时,回收区将作为一个独立的空闲分区被加入到空闲分区表中。虽然这种情况下无法减少内存碎片,但操作系统仍然可以通过其他方式(如紧凑技术)来优化内存的使用。
需要注意的是,内存回收的过程不仅涉及到空闲分区的合并和更新,还需要考虑到操作系统的内存管理策略、进程调度策略等多个方面。此外,在不同的操作系统和内存管理算法中,内存回收的具体实现方式可能会有所不同。
四、实现要求
1.实验数据

2.要求
要求计算碎片分别是2K和4K时内存的分配情况。(要求分配时从高地址开始)。
五、代码实现
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>#define OSSIZE 16
#define MAXSIZE 256
#define DEBRIS 2 //碎片
//#define DEBRIS 4 //碎片
char* osname = "OS";
typedef struct areadata//空闲区
{ char* ID;//作业号 int address;//分区始址int size;//分区大小int state;//分区状态,0为空闲,1为已分配
} areadata;typedef struct DuNode//双向链表
{areadata data;struct DuNode* prior;struct DuNode* next;
} DuNode, * DuNodeList;DuNodeList headNode;
DuNodeList lastNode;
void initList()//双向链表初始化
{headNode = (DuNodeList)malloc(sizeof(DuNode));lastNode = (DuNodeList)malloc(sizeof(DuNode));if (headNode == NULL || lastNode == NULL){printf("动态内存开辟错误\n");exit(-1);}headNode->prior = NULL;headNode->next = lastNode;lastNode->prior = headNode;lastNode->next = NULL;headNode->data.ID = osname;headNode->data.address = 0;headNode->data.size = OSSIZE;headNode->data.state = 1;lastNode->data.address = OSSIZE;lastNode->data.size = MAXSIZE- OSSIZE;lastNode->data.ID = NULL;lastNode->data.state = 0;}
//首次适应算法
int firstFitAlloc(char* ID, int size)
{DuNode* p = headNode->next;while (p){if (p->data.size < size || p->data.state == 1){p = p->next;continue;}if (p->data.size - size <= DEBRIS){p->data.state = 1;p->data.ID = ID;return 1;}else{DuNodeList temp = (DuNodeList)malloc(sizeof(DuNode));if (temp == NULL) {printf("动态内存开辟错误\n");exit(-1);}temp->data.ID = ID;temp->data.size = size;temp->data.state = 1;temp->data.address = (p->data.address + p->data.size) - size;temp->next = p->next;temp->prior = p;if (temp->next){temp->next->prior = temp;}p->next = temp;p->data.size -= size;return 1;}p = p->next;}return 0;
}
//内存回收四种情况
void freeNode(char* ID)
{DuNode* p = headNode->next;while (p){if (p->data.ID == ID){p->data.ID = NULL;p->data.state = 0;//回收区前面的分区是空闲分区if (!(p->prior->data.state) && (p->next == NULL || p->next->data.state)){p->prior->data.size += p->data.size;p->prior->next = p->next;if (p->next != NULL)p->next->prior = p->prior;free(p);break;}//回收区后面的分区是空闲分区if (p->next != NULL && (!(p->next->data.state) && p->prior->data.state)){DuNode* tmp;tmp = p->next;p->data.size += p->next->data.size;if (p->next->next){p->next->next->prior = p;}p->next = p->next->next;free(tmp);break;}//回收区上面和下面的分区都是空闲分区if (p->next != NULL && (!(p->prior->data.state) && !(p->next->data.state))){p->prior->data.size += p->data.size + p->next->data.size;p->prior->next = p->next->next;if (p->next->next != NULL){p->next->next->prior = p->prior;}free(p->next);free(p);break;}break;}p = p->next;}
}
//输出打印信息
void show()
{printf("碎片为%d时,内存分配情况如下:\n", DEBRIS);printf("分区号 作业号 分区始址 分区大小 分区状态\n");DuNode* p = headNode;int a = 1;while (p != NULL) {printf("%5d ", a++);printf(" %s", p->data.ID);printf("%10d%12d", p->data.address, p->data.size);printf("\t %s\n", p->data.state == 0 ? "空闲" : "已分配"); p = p->next;}
}int main()
{initList();firstFitAlloc("j1", 134);firstFitAlloc("j2", 30);firstFitAlloc("j3", 64);freeNode("j1");freeNode("j3");firstFitAlloc("j4", 60);firstFitAlloc("j5", 62);freeNode("j2");firstFitAlloc("j6", 12);firstFitAlloc("j7", 32);show();return 1;
}六、实现效果
1.碎片为2
2.碎片为4
相关文章:
操作系统动态分区分配算法-首次适应算法c语言实现
目录 一、算法原理 二、算法特点 1.优先利用低址空闲分区: 2.查找开销: 3.内存碎片: 三、内存回收四种情况 1.回收区上面(或后面)的分区是空闲分区: 2.回收区下面(或前面)的…...

mybatis-plus自动填充时间的配置类实现
mybatis-plus自动填充时间的配置类实现 在实际操作过程中,我们并不希望创建时间、修改时间这些来手动进行,而是希望通过自动化来完成,而mybatis-plus则也提供了自动填充功能来实现这一操作,接下来,就来了解一下mybatis…...

Vite内网ip访问,两种配置方式和修改端口号教程
目录 问题 两种解决方式 结果 总结 preview.host preview.port 问题 使用vite运行项目的时候,控制台会只出现127.0.0.1(localhost)本地地址访问项目。不可以通过公司内网ip访问,其他团队成员无法访问,这是因为没…...

【星海随笔】删除ceph
cephadm shell ceph osd set noout ceph osd set norecover ceph osd set norebalance ceph osd set nobackfill ceph osd set nodown ceph osd set pause参考文献: https://blog.csdn.net/lyf0327/article/details/90294011 systemctl stop ceph-osd.targetyum re…...
HarmonyOS NEXT实战:自定义封装多种样式导航栏组件
涉及知识点和装饰器 ComponentV2,Local, Builder,BuilderParam,Extend, Require ,Param,Event等第三方库:ZRouter ,如项目中本来就用了ZRouter路由库,案例中…...
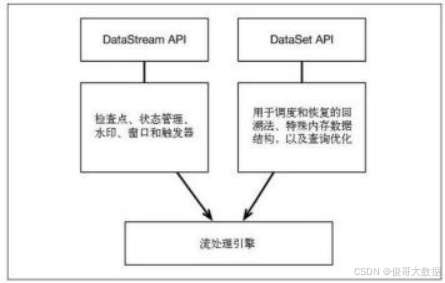
大数据面试笔试宝典之Flink面试
1.Flink 是如何支持批流一体的? F link 通过一个底层引擎同时支持流处理和批处理. 在流处理引擎之上,F link 有以下机制: 1)检查点机制和状态机制:用于实现容错、有状态的处理; 2)水印机制:用于实现事件时钟; 3)窗口和触发器:用于限制计算范围,并定义呈现结果的…...

pytorch整体环境打包安装到另一台电脑上
步骤一:安装conda-pack 首先利用 pip list 指令检查conda环境安装在哪里,在系统环境(base)下,于是我是使用的conda指令完成的。 # 使用Conda安装(如果已安装conda) conda install conda-pack …...

PostgreSQL 数据库连接
title: PostgreSQL 数据库连接 date: 2024/12/29 updated: 2024/12/29 author: cmdragon excerpt: PostgreSQL是一款功能强大的开源关系数据库管理系统,在现代应用中广泛应用于数据存储和管理。连接到数据库是与PostgreSQL进行交互的第一步,这一过程涉及到多个方面,包括连…...
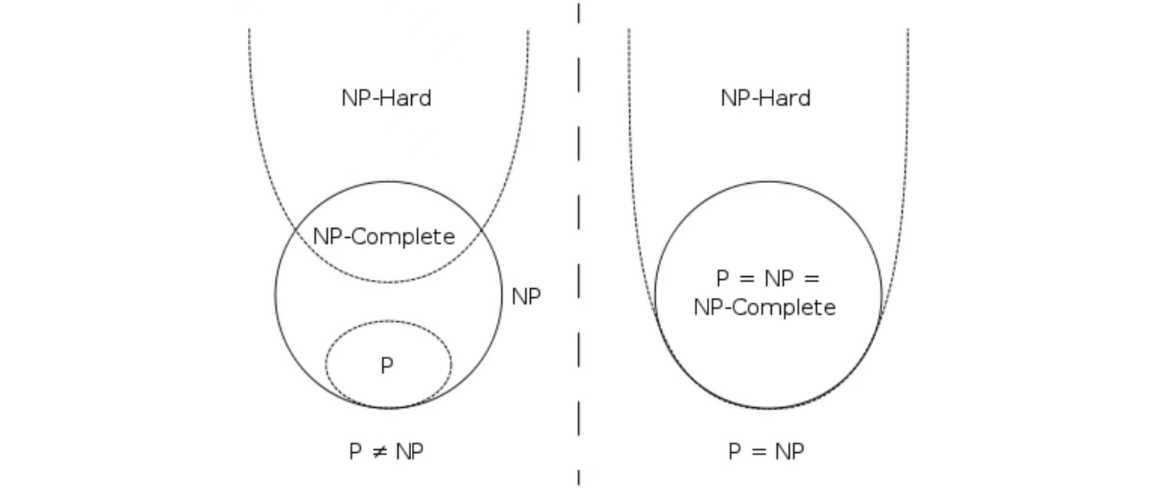
【算法】复杂性理论初步
六、算法复杂性初步 重要的复杂性类 P P P 的定义 多项式时间内可解的问题 若 L ∈ P L∈P L∈P,则存在确定性多项式时间的图灵机 M M M,使得 M ( x ) 1 ⟺ x ∈ L M(x)1⟺x∈L M(x)1⟺x∈L N P NP NP 的定义 多项式时间内可验证验证解的正确性 &…...

HarmonyOS NEXT应用开发实战:免费练手的网络API接口分享
学习一项技能,最好也最快的办法就是直接动手实战。在实战中不断的总结经验和收获成就感。这里分享些好用且免费的网络API练手接口,这对于想要提升自己网络开发能力的开发者来说,无疑是极大的福音。今天,我将详细介绍一个API接口集…...

C++的第一个程序
前言 在学习c之前,你一定还记得c语言的第一个程序 当时刚刚开始进行语言学习 因此告诉到,仅仅需要记住就可以 #include <stdio.h>int main(){printf("Hello World");return 0; }而对于c中的第一个程序,似乎有所变化 C的…...

Java 中 Stream 流的使用详解
Java 中 Stream 流的使用详解 什么是 Stream? Stream 是 Java 8 引入的一种全新的操作集合的方式。它支持通过声明性方式对集合进行复杂的数据操作(如过滤、排序、聚合等),避免使用大量的 for 循环,提高代码的可读性…...
【UE5.3.2】生成vs工程并rider打开
Rider是跨平台的,UE也是,当前现在windows上测试首先安装ue5.3.2 会自动有右键的菜单: windows上,右键,生成vs工程 生成的结果 sln默认是vs打开的,我的是vs2022,可以open with 选择 rider :Rider 会弹出 RiderLink是什么插...

ssh免密码登陆配置
ssh 命令本身不支持直接在命令中带上密码,出于安全考虑,SSH 协议不允许将密码明文写在命令中。直接在命令行中输入密码是一种不推荐的做法,因为它会暴露密码,增加安全风险。 如果你希望实现自动化登录而不手动输入密码࿰…...

Hive之import和export使用详解
在hive-0.8.0后引入了import/export命令。 Export命令可以导出一张表或分区的数据和元数据信息到一个输出位置,并且导出数据可以被移动到另一个hadoop集群或hive实例,并且可以通过import命令导入数据。 当导出一个分区表,原始数据可能在hdf…...

数据库锁的深入探讨
数据库锁(Database Lock)是多用户环境中用于保证数据一致性和隔离性的机制。随着数据库系统的发展,特别是在高并发的场景下,锁的机制变得尤为重要。通过使用锁,数据库能够防止并发操作导致的数据冲突或不一致。本文将深…...

【每日学点鸿蒙知识】沉浸式状态栏、类似ref 属性功能属性实现、自定义对话框背景透明、RichEditor粘贴回调、自动滚动列表
1、HarmonyOS 沉浸式状态栏? 实现沉浸式状态栏功能时,能够实现,但是目前每个自定义组件都需要padding top 状态栏的高度才行,有办法实现统一设置吗?不需要每个自定义组件中都padding top 状态栏的高度? 暂…...
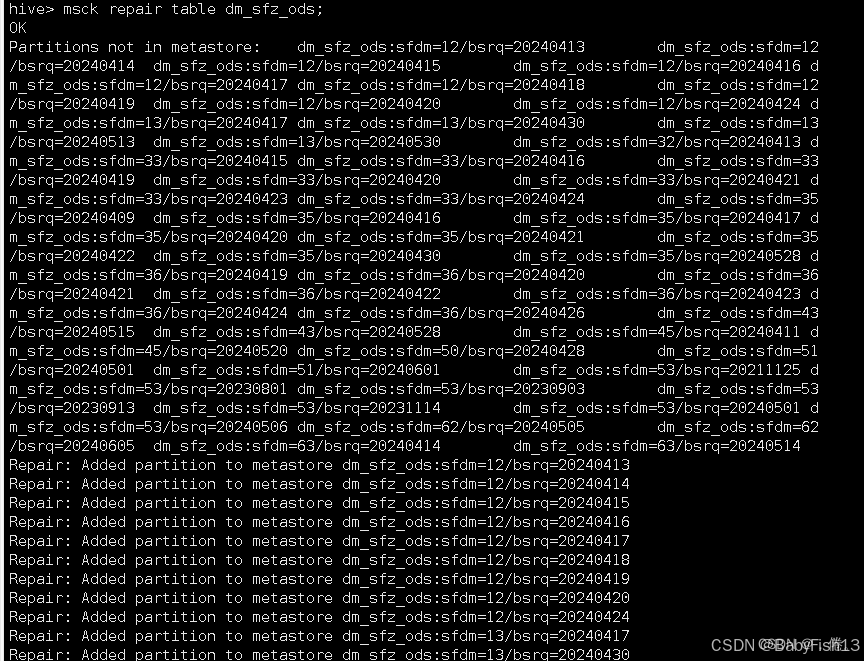
Hive刷分区MSCK
一、MSCK刷分区 我们平时通常是通过alter table add partition方式增加Hive的分区的,但有时候会通过HDFS put/cp命令或flink、flum程序往表目录下拷贝分区目录,如果目录多,需要执行多条alter语句,非常麻烦。Hive提供了一个"…...

在Ubuntu下通过Docker部署Mastodon服务器
嘿,朋友们,今天咱们来聊聊如何在Ubuntu上通过Docker部署Mastodon服务器。想要拥有自己的社交媒体平台?Mastodon就是个不错的选择!🌐🚀 Docker与Mastodon简介 Docker是一个开源的容器化平台,让…...
【EtherCATBasics】- KRTS C++示例精讲(2)
EtherCATBasics示例讲解 目录 EtherCATBasics示例讲解结构说明代码讲解 项目打开请查看【BaseFunction精讲】。 结构说明 EtherCATBasics:应用层程序,主要用于人机交互、数据显示、内核层数据交互等; EtherCATBasics.h : 数据定义…...

YOLOv8 智能交通违章检测 - 疲劳/分心驾驶检测详解
YOLOv8 智能交通违章检测 - 疲劳/分心驾驶检测详解 疲劳驾驶和分心驾驶检测属于驾驶员状态监测(DMS, Driver Monitoring System)的核心功能。与外部交通违章不同,这需要摄像头安装在车内,对准驾驶员面部。 由于人脸关键点(眼睛、嘴巴)的微小变化对精度要求极高,单纯的…...

5分钟彻底解锁Mac百度网盘限速:开源加速插件完整实战指南
5分钟彻底解锁Mac百度网盘限速:开源加速插件完整实战指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否曾在Mac上使用百度网盘下载…...

7种音频格式一键转换:FlicFlac便携工具完全指南
7种音频格式一键转换:FlicFlac便携工具完全指南 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 在数字音频处理中,格式转换是每个…...

SDMatte多GPU并行推理配置:提升企业级批量处理吞吐量
SDMatte多GPU并行推理配置:提升企业级批量处理吞吐量 1. 为什么需要多GPU并行推理 当企业需要处理大批量图片时,单张GPU往往难以满足需求。想象一下,你有一家电商公司,每天需要处理上万张商品图片的背景替换。如果只用一张GPU&a…...

案例速递|手机摄像头模组底壳检测
东莞市沃德普自动化科技有限公司 www.wordop.com 检测背景: 在手机摄像头模组的精密制造流程中,模组底壳是镜头、CMOS传感器、VCM马达的核心承载与定位基准,其表面质量直接决定模组的装配精度、光学性能与长期使用可靠性。 检测需求&#x…...

BEYOND REALITY Z-Image保姆级教程:5分钟部署,零基础生成高清人像
BEYOND REALITY Z-Image保姆级教程:5分钟部署,零基础生成高清人像 1. 前言:为什么选择BEYOND REALITY Z-Image? 如果你正在寻找一款能够生成专业级写真人像的AI工具,BEYOND REALITY Z-Image可能是目前最值得尝试的选…...

GPT-6「土豆」4月14日发布:性能暴涨40%,国内用户怎么第一时间用上?
TL;DR:OpenAI 内部代号「土豆」的 GPT-6 定档 4 月 14 日发布,代码和 Agent 能力较前代提升 40%,上下文扩至 200 万 Token。本文拆解它的核心能力变化,并整理国内用户第一时间用上的可行方案。GPT-6 到底升级了什么 4 月 7 日&…...

C++复习录
1.命名空间 namespace nn{int a; } //名字空间指令 using namespace nn;//从这行代码开始,nn中的标识符在当前作用域可见(位于可见表)//名字空间声明 using nn::a;//从这行代码开始,nn中的a引入当前作用域(相当于定义,位于定义表) gcc/g++针对每个函数都和制作两张表,…...

智能抖音批量下载工具:自动化无水印资源获取的高效解决方案
智能抖音批量下载工具:自动化无水印资源获取的高效解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

Honey Select 2终极增强指南:200+插件整合补丁一键优化游戏体验
Honey Select 2终极增强指南:200插件整合补丁一键优化游戏体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2》游戏体验不…...