深度学习:基于MindSpore NLP的数据并行训练
什么是数据并行?

数据并行(Data Parallelism, DP)的核心思想是将大规模的数据集分割成若干个较小的数据子集,并将这些子集分配到不同的 NPU 计算节点上,每个节点运行相同的模型副本,但处理不同的数据子集。
1. 将数据区分为不同的mini-batch
将数据集切分为若干子集,每个mini-batch又不同的设备独立处理。如你有4个GPU,可以把数据集分为4分,每个GPU处理一个字数据集。
2. 模型参数同步
可以通过某一进程初始化全部模型参数后,向其他进程广播模型参数,实现同步。
3. 前向运算
每个设备独立计算前向运算。
4. 反向运算
每个设备计算损失的梯度。
5. 梯度聚合
当所有设备计算完各自的梯度后,对所有设备的梯度取平均,每个设备的模型参数根据平均梯度进行更新。
6. 参数更新
数据并行的参数更新是在数据切分、模型参数同步后进行的。更新前,每个进程的参数相同;更新时,平均梯度相同;故更新后,每个进程的参数也相同。
数据并行的基本操作
Reduce 归约
归约是函数式编程的概念。数据归约包括通过函数将一组数字归约为较小的一组数字。
如sum([1, 2, 3, 4, 5])=15, multiply([1, 2, 3, 4, 5])=120。
AllReduce
等效于执行Reduce操作后,将结果广播分配给所有进程。

MindSpore AllReduce
import numpy as np
from mindspore.communication import init
from mindspore.communication.comm_func import all_reduce
from mindspore import Tensorinit()
input_tensor = Tensor(np.ones([2, 8]).astype(np.float32))
output = all_reduce(input_tensor)数据并行的主要计算思想
Parameter-Server
主要思想:所有node被分为server node和worker node
Server node:负责参数的存储和全局的聚合操作
Worker node:负责计算
Parameter-Server的问题:
- 假设有N=5张卡,GPU0作为Server,其余作为Worker
- 将大小为K的数据拆分为N-1份,分给每个Worker GPU
- 每个GPU计算得到local gradients
- N-1块GPU将计算所得的local gradients发送给GPU 0
- GPU 0对所有local gradients进行all reduce操作得到全局梯度,参数更新
- 将该新模型的参数返回给每张GPU
假设单个Worker到Server的通信开销为C,那么将local gradients送到GPU 0上的通信成本为C * (N - 1)。收到GPU 0通信带宽的影响,通信成本随着设备数的增加而线性增长。

Pytorch DataParallel
Pytorch DP在Parameter-Server的基础上,把GPU 0即当作Server也当作Worker。
1. 切分数据,但不切分Label
每个GPU进行正向计算之后,将正向计算结果聚合回GPU 0计算Loss,GPU 0计算完Loss的gradient之后,将梯度分发回其他worker GPU。随后各个GPU计算整个模型的grad,再将grad聚合回GPU 0,进行AllReduce。
 2. 切分数据,同时切分Label
2. 切分数据,同时切分Label
每张卡自己计算Loss即可,减少一次聚合操作。

Pytorch DataParallel 问题:
1. 为摆脱Parameter-Server模式,性能差。
2. 需要额外的GPU进行梯度聚合/ GPU 0需要额外的显存。GPU 0限制了其他GPU的上限。
Ring AllReduce

每张卡单向通讯,通讯开销一定。
每张卡占用的显存相同。
第一步:Scatter-Reduce

假设每张卡上各自计算好了梯度。
每张GPU依次传值:


重复直至:

第二步:All-Gather

将每一个累计值a / b / c逐个发送至个张卡

直至每张卡都有每层的梯度累计值。

两步分别做了四次通讯,便可以实现并行计算。
Ring AllReduce计算开销
- N-1次Scatter-Reduce
- N-1次All-Gather
- 每个GPUGPU一次通讯量为:K/N,K为总数据大小
- 每个GPU通信次数为:2(N-1)
总通信量为:
当N足够多时,通信量为一个常数2K。
Gradient Bucketing
集合通信在大张量上更有效。因此,可以在短时间内等待并将多个梯度存储到一个数据桶(Bucket),然后进行AllReduce操作。而不是对每个梯度立刻启动AllReduce操作。
MindSpore数据并行
def forward_fn(data, target):logits = net(data)loss = loss_fn(logits, target)return loss, logitsgrad_fn = ms.value_and_grad(forward_fn, None, net_trainable_param(), has_aux=True)
# 初始化reducer
grad_gather = nn.DistributedGradReducer(optimizer.parameters)for epoch in range(10):i = 0for image, label in data_set:(loss_value, _), grads = grad_fn(image, label)# 进行通讯grads = grad_reducer(grads)optimizer(grads)# ...MindNLP数据并行
def update_gradient_by_distributed_type(self, model: nn.Module) -> None:'''update gradient by distributed_type'''if accelerate_distributed_type == DistributedType.NO:returnif accelerate_distributed_type == DistrivutedType.MULTI_NPU:from mindspore.communication import get_group_sizefrom mindspore.communication.comm_func iport all_reducerank_size = get_group_size()for parameter in model.parameters():# 进行all_reducenew_grads_mean = all_reduce(parameter.grad) / rank_sizeparameter.grad = new_grads_mean数据并行的局限性
要求单卡可以放下模型
多卡训练时内存冗余,相同模型参数复制了多份。
MindSopre中的数据并行
1. 在启智社区创建云脑任务或华为云创建notebook
环境选择:mindspore==2.3.0, cann==8.0,昇腾910 * 2
2. 更新MindSpore框架版本
pip install --upgrade mindspore
同时可以查看NPU信息:
npu--smi info
3. 配置项目环境
克隆mindnlp项目
git clone https://github.com/mindspore-lab/mindnlp.git下载mindnlp
cd mindnlp
bash scripts/build_and_reinstall.sh下载完成后,卸载mindformers、soundfile
pip uninstall mindformers4. 运行训练脚本
cd mindnlp/llm/parallel/bert_imdb_finetune_dp
msrun --worker_num=2 --local_worker_num=2 --master_port=8118 bert_imdb_finetune_cpu_mindnlp_trainer_npus_same.py 发现两个NPU都被占用

日志文件开始记录模型训练进度

成功实现数据并行!

基于MindSpore微调Roberta+数据并行
数据集:imdb影评数据集
微调代码:roberta.py
#!/usr/bin/env python
# coding: utf-8
"""
unset MULTI_NPU && python bert_imdb_finetune_cpu_mindnlp_trainer_npus_same.py
bash bert_imdb_finetune_npu_mindnlp_trainer.sh
"""
import mindspore.dataset as ds
from mindnlp.dataset import load_dataset# loading dataset
imdb_ds = load_dataset('imdb', split=['train', 'test'])
imdb_train = imdb_ds['train']
imdb_test = imdb_ds['test']imdb_train.get_dataset_size()import numpy as npdef process_dataset(dataset, tokenizer, max_seq_len=512, batch_size=4, shuffle=False):is_ascend = mindspore.get_context('device_target') == 'Ascend'def tokenize(text):if is_ascend:tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)else:tokenized = tokenizer(text, truncation=True, max_length=max_seq_len)return tokenized['input_ids'], tokenized['attention_mask']if shuffle:dataset = dataset.shuffle(batch_size)# map datasetdataset = dataset.map(operations=[tokenize], input_columns="text", output_columns=['input_ids', 'attention_mask'])dataset = dataset.map(operations=transforms.TypeCast(mindspore.int32), input_columns="label", output_columns="labels")# batch datasetif is_ascend:dataset = dataset.batch(batch_size)else:dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),'attention_mask': (None, 0)})return datasetfrom mindnlp.transformers import AutoTokenizer
import mindspore
import mindspore.dataset.transforms as transforms
# tokenizer
tokenizer = AutoTokenizer.from_pretrained('roberta-base')dataset_train = process_dataset(yelp_ds_train, tokenizer, shuffle=True)
from mindnlp.transformers import AutoModelForSequenceClassification# set bert config and define parameters for training
model = AutoModelForSequenceClassification.from_pretrained('AI-ModelScope/roberta-base', num_labels=2, mirror='modelscope')from mindnlp.engine import TrainingArgumentstraining_args = TrainingArguments(output_dir="./",save_strategy="epoch",logging_strategy="epoch",num_train_epochs=3,learning_rate=2e-5
)training_args = training_args.set_optimizer(name="adamw", beta1=0.8)from mindnlp.engine import Trainertrainer = Trainer(model=model,args=training_args,train_dataset=dataset_train
)print('start training')
trainer.train()
运行命令:
msrun --worker_num=2 --local_worker_num=2 --master_port=8118 roberta.py
相关文章:
深度学习:基于MindSpore NLP的数据并行训练
什么是数据并行? 数据并行(Data Parallelism, DP)的核心思想是将大规模的数据集分割成若干个较小的数据子集,并将这些子集分配到不同的 NPU 计算节点上,每个节点运行相同的模型副本,但处理不同的数据子集。…...
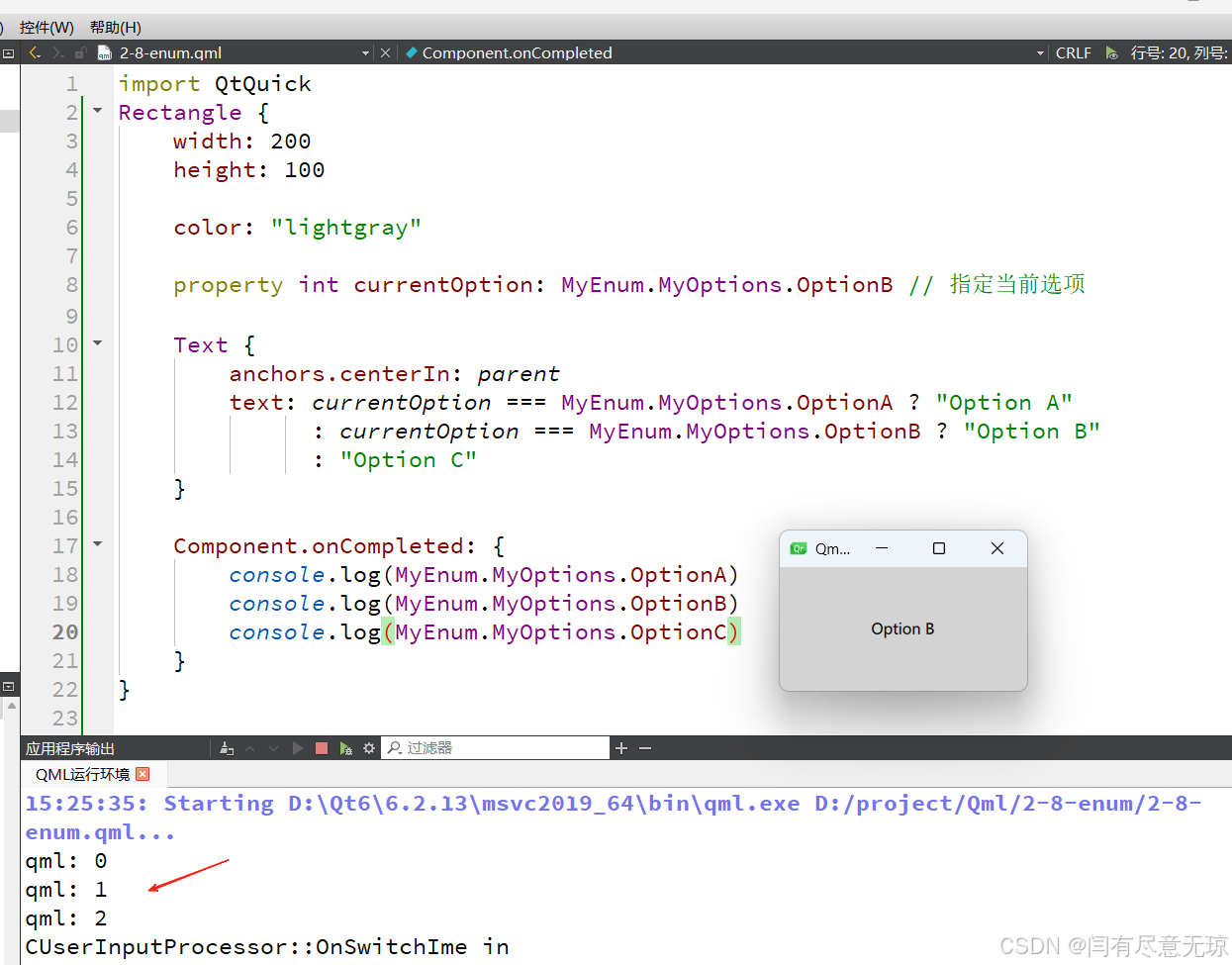
Qt6之QML——枚举
在 QML 中,枚举 (Enumeration) 是一种用于定义一组固定值的功能。通过枚举,可以便捷地提供一组可选值,使用更加明确和精简。 一、枚举的特点 固定值定义: 枚举可以预先定义一组字面值,通常用于需要定义限制值范围的场景…...

ModiLeo交易平台:引领数字货币交易新未来
在当今数字化高速发展的时代,数字货币作为一种新兴的金融资产形式,正逐渐改变着全球金融格局。而此刻,由印度 ModiLeo 实验室联合全球顶级投行共同打造的全球领先的一站式数字货币交易平台——ModiLeo 即将上线,这无疑是数字货币领…...

[python SQLAlchemy数据库操作入门]-15.联合查询,跨表获取股票数据
哈喽,大家好,我是木头左! 在开始探讨如何利用SQLAlchemy实现复杂的联合查询之前,首先需要深入理解其核心组件——对象关系映射(ORM)。ORM允许开发者使用Python类来表示数据库中的表,从而以一种更直观、面向对象的方式来操作数据库。 SQLAlchemy中的JOIN操作详解 在SQLA…...

某网站手势验证码识别深入浅出(全流程)
注意,本文只提供学习的思路,严禁违反法律以及破坏信息系统等行为,本文只提供思路 如有侵犯,请联系作者下架 本文识别已同步上线至OCR识别网站: http://yxlocr.nat300.top/ocr/other/20 本篇文章包含经验和教训总结,我采用了两种方法进行识别,两种方法都各有优劣,其中一…...

在虚幻引擎4(UE4)中使用蓝图的详细教程
在虚幻引擎4(UE4)中使用蓝图的详细教程 虚幻引擎4(Unreal Engine 4,简称UE4)是一款功能强大的游戏引擎,广泛应用于游戏开发、虚拟现实、建筑可视化等领域。UE4 提供了一个强大的可视化脚本工具——蓝图&am…...

Junit如何禁用指定测试类,及使用场景
在JUnit中禁用指定测试类可以通过多种方式实现,具体取决于使用的JUnit版本(JUnit 4 或 JUnit 5)。以下是针对两个版本的详细说明以及它们可能的使用场景: JUnit 4 禁用整个测试类 可以使用Ignore注解来忽略整个测试类。这将导致…...

ICLR2015 | FGSM | 解释并利用对抗样本
Explaining and Harnessing Adversarial Examples 摘要-Abstract相关工作-Related Work对抗样本的线性解释-The Linear Explanation of Adversarial Examples非线性模型的线性扰动-Linear Pertubation of Non-Linear Models线性模型与权重衰减的对抗训练-Adversarial Training …...

Python 迭代器与生成器
Python 中的迭代器和生成器是处理集合元素的重要工具,它们在处理大量数据时特别有用,因为它们不需要一次性将所有数据加载到内存中。 迭代器(Iterator) 迭代器是一个实现了迭代器协议的对象,这意味着它有两个方法&am…...

MySQL数据库——索引结构之B+树
本文先介绍数据结构中树的演化过程,之后介绍为什么MySQL数据库选择了B树作为索引结构。 文章目录 树的演化为什么其他树结构不行?为什么不使用二叉查找树(BST)?为什么不使用平衡二叉树(AVL树)&a…...

3_TCP/IP连接三次握手与断开四次挥手
TCP/IP 通信是网络通信的基础协议,分为以下主要步骤: 1、建立连接(三次握手) 目的:保证双方建立可靠的通信连接。 过程: 1>客户端发送 SYN:客户端向服务器发送一个 SYN(同步&…...

【LC】3159. 查询数组中元素的出现位置
题目描述: 给你一个整数数组 nums ,一个整数数组 queries 和一个整数 x 。 对于每个查询 queries[i] ,你需要找到 nums 中第 queries[i] 个 x 的位置,并返回它的下标。如果数组中 x 的出现次数少于 queries[i] ,该查…...

《机器学习》——KNN算法
文章目录 KNN算法简介KNN算法——sklearnsklearn是什么?sklearn 安装sklearn 用法 KNN算法 ——距离公式KNN算法——实例分类问题完整代码——分类问题 回归问题完整代码 ——回归问题 KNN算法简介 一、KNN介绍 全称是k-nearest neighbors,通过寻找k个距…...

GAMES101:现代计算机图形学入门-作业五
作业五 这次作业给了许多脚本,我们现在可以把每个脚本的代码逐行细细分析一下。 main.cpp #include "Scene.hpp" #include "Sphere.hpp" #include "Triangle.hpp" #include "Light.hpp" #include "Renderer.hpp&quo…...

GPU 进阶笔记(二):华为昇腾 910B GPU
大家读完觉得有意义记得关注和点赞!!! 1 术语 1.1 与 NVIDIA 术语对应关系1.2 缩写2 产品与机器 2.1 GPU 产品2.2 训练机器 底座 CPU功耗操作系统2.3 性能3 实探:鲲鹏底座 8*910B GPU 主机 3.1 CPU3.2 网卡和网络3.3 GPU 信息 3.3…...
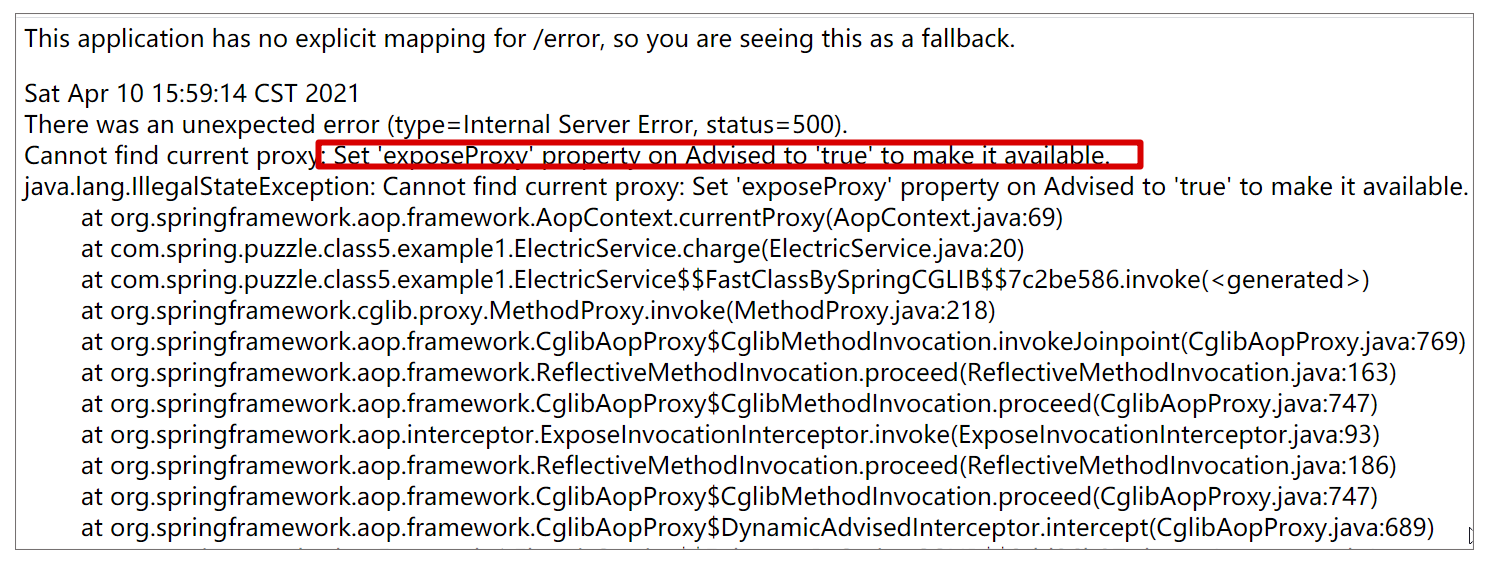
Spring AOP:this 调用当前类方法无法被拦截
问题复现 假设我们正在开发一个宿舍管理系统,这个模块包含一个负责电费充值的类 ElectricService,它含有一个充电方法 charge(): Service public class ElectricService {public void charge() throws Exception {System.out.println("E…...

K8S-LLM:用自然语言轻松操作 Kubernetes
在 Kubernetes (K8s) 的日常管理中,复杂的命令行操作常常让开发者感到头疼。无论是部署应用、管理资源还是调试问题,都需要记住大量的命令和参数。Kubernetes 作为容器编排的行业标准,其强大的功能伴随着陡峭的学习曲线和复杂的命令行操作。这…...

lua和C API库一些记录
相关头文件解释 lua.h:声明lua提供的基础函数,所有内容都有个前缀lua_; luaxlib.h:声明辅助库提供的函数,所有内容都有个前缀luaL_; lualib.h:声明了打开标准库的函数; 辅助库对…...

SpringSecurity中的过滤器链与自定义过滤器
关于 Spring Security 框架中的过滤器的使用方法,系列文章: 《SpringSecurity中的过滤器链与自定义过滤器》 《SpringSecurity使用过滤器实现图形验证码》 1、Spring Security 中的过滤器链 Spring Security 中的过滤器链(Filter Chain)是一个核心的概念,它定义了一系列过…...

Slate文档编辑器-Decorator装饰器渲染调度
Slate文档编辑器-Decorator装饰器渲染调度 在之前我们聊到了基于文档编辑器的数据结构设计,聊了聊基于slate实现的文档编辑器类型系统,那么当前我们来研究一下slate编辑器中的装饰器实现。装饰器在slate中是非常重要的实现,可以为我们方便地…...
)
Matlab串口通信上位机开发:从零搭建实时数据采集系统(附完整代码)
Matlab串口通信上位机开发实战:从零构建工业级数据采集系统 在工业自动化、物联网设备调试和科研实验数据采集领域,串口通信作为最基础也最可靠的数据传输方式,至今仍发挥着不可替代的作用。Matlab凭借其强大的数值计算能力和丰富的可视化工具…...

2026届学术党必备的AI写作工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 大语言模型DeepSeek,于论文写作中能予以多维度辅助。在文献检索阶段,…...

Qwen3.5-9B实战教程:WebSocket流式响应+前端实时渲染优化方案
Qwen3.5-9B实战教程:WebSocket流式响应前端实时渲染优化方案 1. 项目概述与核心能力 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,在多个领域展现出强大的能力: 强逻辑推理:能够处理复杂的逻辑问题,适合需要深度…...
)
3分钟搞定Goods查询页:Map传参+StringUtils分割符实战(附避坑指南)
3分钟搞定商品查询页:Map传参与字符串分割的高效实践 商品查询功能作为电商系统的核心模块,其性能与用户体验直接影响转化率。本文将聚焦查询页开发中的两个关键技术点:Map传参优化与StringUtils分割技巧,通过可落地的代码示例&a…...

5电平三相MMC的VSG控制及其MATLAB-Simulink仿真模型:调频调压效果验证
模块化多电平变流器/MMC/的VSG控制/虚拟同步发电机控制/MATLAB–Simulink仿真模型 5电平三相MMC,采用VSG控制。 受端接可编辑三相交流源,直流侧接无穷大电源提供调频能量。 设置频率波动和电压波动的扰动,可以验证VSG控制的调频调压效果最近在…...

OpenClaw开源贡献:为Phi-3-mini开发新技能指南
OpenClaw开源贡献:为Phi-3-mini开发新技能指南 1. 为什么选择为Phi-3-mini开发OpenClaw技能? 去年夏天,我在尝试用OpenClaw自动化处理日常工作报告时,发现现有的技能库对小型语言模型的支持相当有限。当时正好接触到微软开源的P…...

langchain学习--提示词
langchain提示词学习要点提示词(Prompt)在LangChain中扮演着核心角色,直接影响模型输出的质量和准确性。以下是关键学习方向和实践方法:基础结构设计明确指令:直接说明任务要求,例如"生成一份关于气候…...
总体韭)
【OpenClaw】通过 Nanobot 源码学习架构---()总体韭
核心摘要:这篇文章能帮你 ?? 1. 彻底搞懂条件分支与循环的适用场景,告别选择困难。 ?? 2. 掌握遍历DOM集合修改属性的标准姿势与性能窍门。 ?? 3. 识别流程控制中的常见“坑”,并学会如何优雅地绕过去。 ?? 主要内容脉络 ?? 一、痛…...

Python AOT编译不再依赖LLVM:2026插件如何实现纯Python源码→本地机器码直编?下载链接+SHA3-512校验值全公开
第一章:Python 原生 AOT 编译方案 2026 插件下载与安装Python 原生 AOT(Ahead-of-Time)编译方案 2026 是 CPython 官方实验性扩展项目,旨在为 Python 提供无需运行时解释器即可生成独立可执行文件的能力。该方案基于 PEP 712 和 L…...
)
从硬件小白到项目上线:我的第一个STM32物联网项目(小熊派智慧路灯踩坑实录)
从硬件小白到项目上线:我的第一个STM32物联网项目(小熊派智慧路灯踩坑实录) 第一次拿到小熊派开发板时,那种既兴奋又忐忑的心情至今记忆犹新。作为一个刚转行物联网开发的菜鸟,我对着这块印着卡通熊标志的绿色电路板发…...