Python爬虫完整代码拿走不谢
对于新手做Python爬虫来说是有点难处的,前期练习的时候可以直接套用模板,这样省时省力还很方便。
使用Python爬取某网站的相关数据,并保存到同目录下Excel。
直接上代码:
import re
import urllib.error
import urllib.requestimport xlwt
from bs4 import BeautifulSoupdef main():baseurl ="http://jshk.com.cn"datelist = getDate(baseurl)savepath=".\jshk.xls"saveDate(datelist,savepath)# askURL("http://jshk.com.cn/")findlink = re.compile(r'<a href="(.*?)">')
findimg = re.compile(r'<img.*src="(.*?)"',re.S)
findtitle = re.compile(r'<span class="title">(.*)</span')
findrating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span')
findjudge = re.compile(r'<span>(d*)人评价</span>')
findinq= re.compile(r'<span class="inq">(.*)</span>')def getDate(baseurl):datalist =[]for i in range(0,10):url=baseurl+str(i*25)html=askURL(url)soup = BeautifulSoup(html,"html.parser")for item in soup.find_all('div',class_="item"):data = []item = str(item)link = re.findall(findlink,item)[0]data.append(link)img=re.findall(findimg,item)[0]data.append(img)title=re.findall(findtitle,item)[0]rating=re.findall(findrating,item)[0]data.append(rating)judge=re.findall(findjudge,item)[0]data.append(judge)inq=re.findall(findinq,item)if len(inq)!=0:inq=inq[0].replace("。","")data.append(inq)else:data.append(" ")print(data)datalist.append(data)print(datalist)return datalistdef askURL(url):head = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36"}request=urllib.request.Request(url,headers=head)html=""try:response=urllib.request.urlopen(request)html=response.read().decode("utf-8")# print(html)except urllib.error.URLError as e:if hasattr(e,"code"):print(e.code)if hasattr(e,"reason"):print(e.reason)return htmldef saveDate(datalist,savepath):workbook = xlwt.Workbook(encoding='utf-8')worksheet = workbook.add_sheet('电影',cell_overwrite_ok=True)col =("电影详情","图片","影片","评分","评价数","概况")for i in range(0,5):worksheet.write(0,i,col[i])for i in range(0,250):print("第%d条" %(i+1))data=datalist[i]for j in range(0,5):worksheet.write(i+1,j,data[j])workbook.save(savepath)if __name__ == '__main__':main()print("爬取完毕")
直接复制粘贴就行。
若要更改爬取网站,则需要更改URL以及相应的html格式(代码中的“item”)。
相关文章:

Python爬虫完整代码拿走不谢
对于新手做Python爬虫来说是有点难处的,前期练习的时候可以直接套用模板,这样省时省力还很方便。 使用Python爬取某网站的相关数据,并保存到同目录下Excel。 直接上代码: import re import urllib.error import urllib.request…...

MLA:多头潜在注意力
MLA:多头潜在注意力 多头潜在注意力(MLA)机制是一种在深度学习模型中用于处理序列数据的注意力机制的改进形式,以下是对其原理和示例的详细介绍: 原理 低秩键值联合压缩:MLA机制利用低秩键值联合压缩来消除注意力模块中的某些计算,从而提高模型的运行速度和性能。在传…...

阿里云大模型ACP高级工程师认证模拟试题
阿里云大模型ACP高级工程师认证模拟试题 0. 引言1. 模拟试题单选题多选题单选题多选题单选题多选题单选题多选题单选题多选题单选题多选题单选题多选题单选题多选题单选题多选题单选题多选题单选题多选题单选题多选题单选题多选题单选题单选题单选题多选题多选题单选题多选题单…...

游戏引擎学习第67天
reviewing “apron”概念以更新区域 我们正在进行模拟区域的扩展工作,目标是通过增加一个更大的区域来支持更丰富的互动,尤其是那些可能超出摄像机视野的内容。现有的模拟区域包括摄像机能看到的区域和其周围的环境区域,但为了保证更高效的游…...

Nginx知识详解(理论+实战更易懂)
目录 一、Nginx架构和安装 1.1 Nginx 概述 1.1.1 nginx介绍 1.1.2?Nginx 功能介绍 1.1.3?基础特性 1.1.4?Web 服务相关的功能 1.2?Nginx 架构和进程 1.2.1?Nginx 进程结构 1.2.2?Nginx 进程间通信 1.2.3?Nginx 启动和 HTTP 连接建立 1.2.4?HTTP 处理过程 1…...

# 【鸿蒙开发】多线程之Worker的使用
【鸿蒙开发】多线程之Worker的使用 文章目录 【鸿蒙开发】多线程之Worker的使用前言一、Worker的介绍二、注意事项三、Worker使用示例1.新建一个Worker2.主线程使用Worker3.子线程Worker的使用 四、效果展示 前言 本文主要介绍了多线程的方法之一,使用Worker开启多…...

TKG-DM – 基于Latent Diffusion模型的“原生”色度提取生成具有透明通道的图像
概述 原文地址:https://www.unite.ai/improving-green-screen-generation-for-stable-diffusion/ 论文地址:https://arxiv.org/pdf/2411.15580 尽管社区研究和投资者对图像生成人工智能充满热情,但此类系统的输出并不总是可以直接用于产品开…...

告别 Windows 迟缓!多维度优化策略开启流畅新体验
在日常使用 Windows 系统的过程中,随着时间推移和软件安装卸载,系统可能会出现运行缓慢、卡顿等问题。本文中简鹿办公将详细介绍一系列 Windows 系统优化方法,涵盖多个关键层面,助力您的电脑重焕生机。 一、磁盘清理与优化 磁盘…...

亚马逊国际站商品爬虫:Python实战指南
在数字化时代,数据的价值不言而喻。对于电商领域而言,获取竞争对手的商品信息、价格、评价等数据,对于市场分析和策略制定至关重要。本文将带你了解如何使用Python编写爬虫,以亚马逊国际站为例,按照关键字搜索并获取商…...

RabbitMQ基础篇之Java客户端快速入门
文章目录 需求 项目设置与依赖管理 配置RabbitMQ的连接信息创建队列与消息发送创建消费者(消息接收)环境准备与操作 需求 利用控制台创建队列 simple.queue在 publisher 服务中,利用 SpringAMQP 直接向 simple.queue 发送消息在 consumer 服…...

深度学习:基于MindSpore NLP的数据并行训练
什么是数据并行? 数据并行(Data Parallelism, DP)的核心思想是将大规模的数据集分割成若干个较小的数据子集,并将这些子集分配到不同的 NPU 计算节点上,每个节点运行相同的模型副本,但处理不同的数据子集。…...
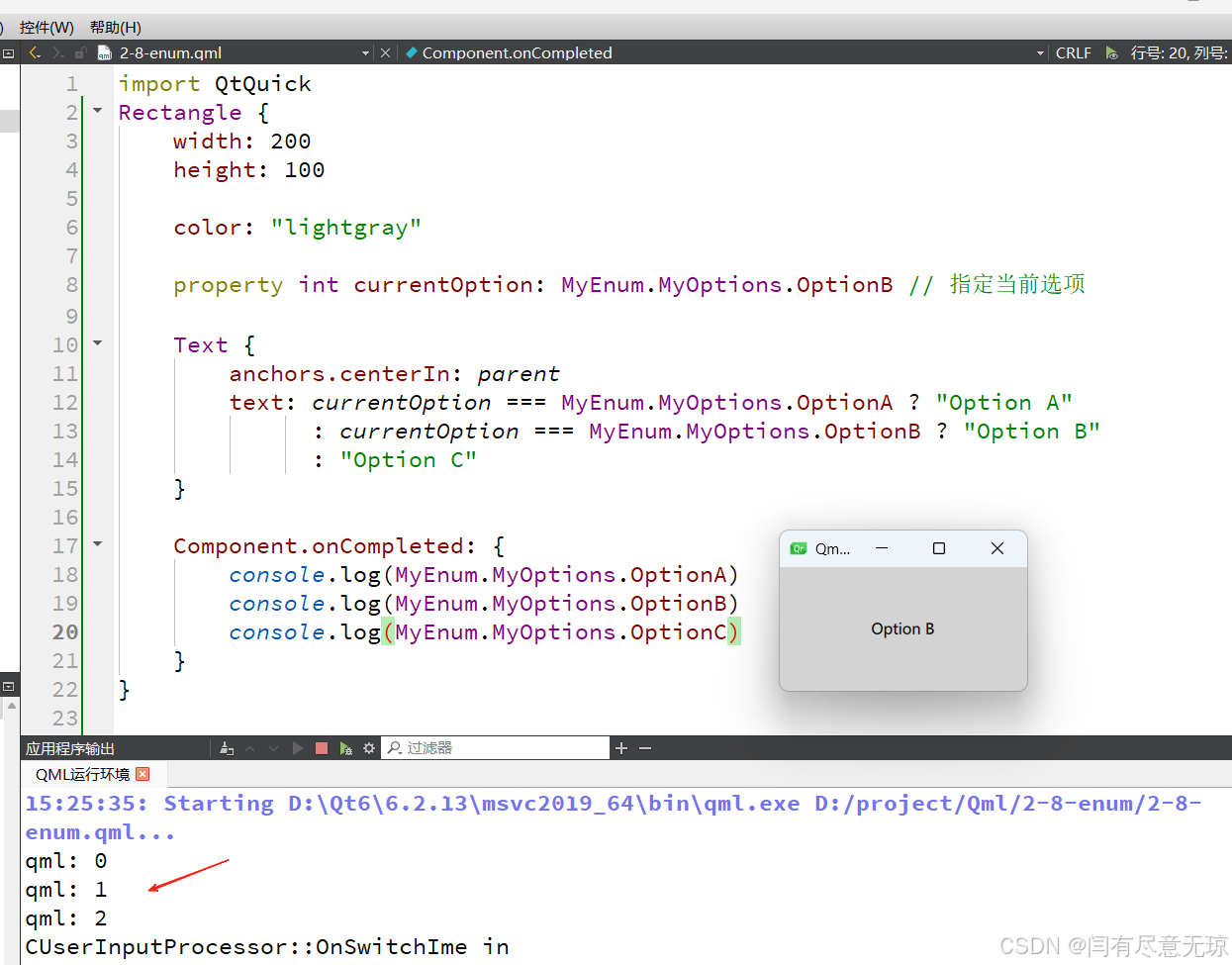
Qt6之QML——枚举
在 QML 中,枚举 (Enumeration) 是一种用于定义一组固定值的功能。通过枚举,可以便捷地提供一组可选值,使用更加明确和精简。 一、枚举的特点 固定值定义: 枚举可以预先定义一组字面值,通常用于需要定义限制值范围的场景…...

ModiLeo交易平台:引领数字货币交易新未来
在当今数字化高速发展的时代,数字货币作为一种新兴的金融资产形式,正逐渐改变着全球金融格局。而此刻,由印度 ModiLeo 实验室联合全球顶级投行共同打造的全球领先的一站式数字货币交易平台——ModiLeo 即将上线,这无疑是数字货币领…...

[python SQLAlchemy数据库操作入门]-15.联合查询,跨表获取股票数据
哈喽,大家好,我是木头左! 在开始探讨如何利用SQLAlchemy实现复杂的联合查询之前,首先需要深入理解其核心组件——对象关系映射(ORM)。ORM允许开发者使用Python类来表示数据库中的表,从而以一种更直观、面向对象的方式来操作数据库。 SQLAlchemy中的JOIN操作详解 在SQLA…...

某网站手势验证码识别深入浅出(全流程)
注意,本文只提供学习的思路,严禁违反法律以及破坏信息系统等行为,本文只提供思路 如有侵犯,请联系作者下架 本文识别已同步上线至OCR识别网站: http://yxlocr.nat300.top/ocr/other/20 本篇文章包含经验和教训总结,我采用了两种方法进行识别,两种方法都各有优劣,其中一…...

在虚幻引擎4(UE4)中使用蓝图的详细教程
在虚幻引擎4(UE4)中使用蓝图的详细教程 虚幻引擎4(Unreal Engine 4,简称UE4)是一款功能强大的游戏引擎,广泛应用于游戏开发、虚拟现实、建筑可视化等领域。UE4 提供了一个强大的可视化脚本工具——蓝图&am…...

Junit如何禁用指定测试类,及使用场景
在JUnit中禁用指定测试类可以通过多种方式实现,具体取决于使用的JUnit版本(JUnit 4 或 JUnit 5)。以下是针对两个版本的详细说明以及它们可能的使用场景: JUnit 4 禁用整个测试类 可以使用Ignore注解来忽略整个测试类。这将导致…...

ICLR2015 | FGSM | 解释并利用对抗样本
Explaining and Harnessing Adversarial Examples 摘要-Abstract相关工作-Related Work对抗样本的线性解释-The Linear Explanation of Adversarial Examples非线性模型的线性扰动-Linear Pertubation of Non-Linear Models线性模型与权重衰减的对抗训练-Adversarial Training …...

Python 迭代器与生成器
Python 中的迭代器和生成器是处理集合元素的重要工具,它们在处理大量数据时特别有用,因为它们不需要一次性将所有数据加载到内存中。 迭代器(Iterator) 迭代器是一个实现了迭代器协议的对象,这意味着它有两个方法&am…...

MySQL数据库——索引结构之B+树
本文先介绍数据结构中树的演化过程,之后介绍为什么MySQL数据库选择了B树作为索引结构。 文章目录 树的演化为什么其他树结构不行?为什么不使用二叉查找树(BST)?为什么不使用平衡二叉树(AVL树)&a…...

Kali渗透测试环境搭建:一站式部署Docker与ARL资产侦察灯塔
1. Kali渗透测试环境搭建的必要性 渗透测试是网络安全工作中不可或缺的一环,而Kali Linux作为最流行的渗透测试操作系统,内置了数百种安全工具。但原生Kali在实际使用中往往面临工具版本老旧、环境依赖冲突等问题。这时候Docker就派上了大用场 - 它能将每…...

轴向磁通电机仿真避坑指南:ANSYS Maxwell 3D建模时气隙与对称性的7个关键设置
轴向磁通电机3D仿真进阶指南:从参数校准到高效求解的实战技巧 轴向磁通电机因其紧凑结构和高效能特性,正在新能源车、航空航天等领域获得广泛应用。但不同于传统径向电机,其三维电磁场分布的复杂性使得仿真过程常成为工程师的"噩梦"…...

3分钟搞懂增量式PID:为什么你的温控系统更适合用这个?
增量式PID:工业温控系统抗干扰的隐秘武器 车间里的温度控制系统突然开始剧烈震荡,显示屏上的曲线像心电图一样疯狂跳动——这种场景对PLC工程师来说再熟悉不过了。当传统的位置式PID在噪声干扰下"失控"时,增量式PID往往能成为稳定系…...

深信服防火墙AF8.0实战配置指南:从零搭建安全防护体系
1. 初识深信服AF8.0防火墙 第一次接触深信服AF8.0防火墙时,我完全理解新手管理员面对这台设备时的茫然感。这台黑色机箱看起来就像个神秘盒子,但别担心,它其实是企业网络安全的"守门人"。AF8.0作为下一代防火墙,不仅能做…...
)
Abaqus GUI界面中文乱码终极解决方案(含插件兼容指南)
1. Abaqus中文乱码问题全解析 第一次打开Abaqus发现菜单栏全是"口口口"的时候,我差点以为软件装坏了。这种中文乱码问题在工程仿真领域特别常见,尤其是使用中文操作系统的用户。经过多次实践,我发现根本原因是Abaqus默认的locale设…...

FreeRTOS任务跑飞别慌!教你用PSP和uxTaskGetStackHighWaterMark锁定罪魁祸首
FreeRTOS任务跑飞排查实战:从PSP追踪到栈溢出的全链路分析 当你在深夜调试一个复杂的FreeRTOS项目时,突然发现某个任务毫无征兆地崩溃进入HardFault_Handler——这种经历对嵌入式开发者来说简直如同噩梦。与裸机环境不同,RTOS的多任务特性让问…...

Chatbox AI客户端实践手册:全平台AI助手部署与应用解析
Chatbox AI客户端实践手册:全平台AI助手部署与应用解析 【免费下载链接】chatbox Powerful AI Client 项目地址: https://gitcode.com/GitHub_Trending/ch/chatbox Chatbox是一款面向开发者和技术工作者的桌面AI助手客户端,支持ChatGPT、Claude、…...
)
如何用AGORA数据集快速提升你的3D人体姿态估计模型(附SMPL-X真值使用技巧)
如何用AGORA数据集快速提升你的3D人体姿态估计模型(附SMPL-X真值使用技巧) 在计算机视觉领域,3D人体姿态估计一直是研究热点,但高质量标注数据的获取成本极高。AGORA数据集的出现为这一难题提供了突破性解决方案——它通过高度逼…...

告别手动整理!用快马AI生成脚本,自动化处理论文参考文献格式
最近在赶毕业论文,最让我头疼的就是参考文献的格式整理。不同期刊要求不同,手动调整费时费力还容易出错。后来发现用Python写个自动化脚本能省不少时间,今天就把我的实现思路分享给大家。 首先明确需求,脚本需要处理的核心问题包括…...

m4s-converter:3分钟搞定B站缓存视频的终极转换方案
m4s-converter:3分钟搞定B站缓存视频的终极转换方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站视频突然下架而烦恼…...