TF-IDF(Term Frequency-Inverse Document Frequency)详解:原理和python实现(中英双语)
中文版
TF-IDF算法详解:理解与应用
TF-IDF(Term Frequency-Inverse Document Frequency)是信息检索与文本挖掘中常用的算法,广泛应用于搜索引擎、推荐系统以及各种文本分析领域。TF-IDF的核心思想是通过计算一个词在文档中的重要性,从而帮助理解文本的主题,甚至进行自动化的文本分类和推荐。
1. TF-IDF的定义
TF-IDF由两部分组成:TF(Term Frequency)和IDF(Inverse Document Frequency)。这两者结合在一起,能够反映出某个词在文档中的重要性。
-
TF(词频):表示某个词在某篇文档中出现的频率。公式如下:
TF ( t , d ) = 词 t 在文档 d 中出现的次数 文档 d 中总词数 \text{TF}(t, d) = \frac{\text{词 t 在文档 d 中出现的次数}}{\text{文档 d 中总词数}} TF(t,d)=文档 d 中总词数词 t 在文档 d 中出现的次数
其中,( t t t ) 表示词语,( d d d ) 表示文档。词频的作用是衡量词语在单个文档中的重要性。显然,某个词在文档中出现得越频繁,它对该文档的意义就越大。
-
IDF(逆文档频率):表示某个词在整个文档集中的重要性。公式如下:
IDF ( t , D ) = log ( N 文档包含词 t 的数量 ) \text{IDF}(t, D) = \log \left( \frac{N}{\text{文档包含词 t 的数量}} \right) IDF(t,D)=log(文档包含词 t 的数量N)
其中,( N N N ) 是文档集中的文档总数,包含词 ( t t t ) 的文档数越多,IDF值越小。IDF的作用是惩罚那些在整个文档集内出现频率较高的词。这是因为,高频出现的词(如“的”,“是”)对于文本区分度贡献较小,因此应降低其权重。
-
TF-IDF值:TF和IDF的乘积,表示某个词对文档的综合重要性:
TF-IDF ( t , d , D ) = TF ( t , d ) × IDF ( t , D ) \text{TF-IDF}(t, d, D) = \text{TF}(t, d) \times \text{IDF}(t, D) TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
这个值可以帮助我们判断某个词在某篇文档中的重要性。如果一个词在文档中频繁出现,并且在整个文档集里相对少见,那么它的TF-IDF值较高,反之亦然。
2. TF-IDF的通俗解释
-
TF的含义:TF是用来衡量某个词在一篇文档中的重要性。一个词出现越频繁,它在该文档中的重要性就越高。
-
IDF的含义:IDF是用来惩罚那些在多个文档中都出现的词。因为这些词(如“的”、“是”、“在”等)在文本分类中对区分不同文档的作用有限。所以,IDF会降低这些词的重要性,增加那些在文档集中出现频率较低但在特定文档中频繁出现的词的权重。
-
惩罚的原因:IDF之所以对频繁出现的词进行惩罚,是因为它们在不同文档中都很常见,不能帮助区分不同的文档。如果一个词几乎出现在每篇文档中,它对于识别文档主题的作用就很小。因此,通过IDF的惩罚,可以让重要的词汇得到更多关注,而让无关紧要的高频词降低权重。
3. TF-IDF的应用场景
TF-IDF广泛应用于多个领域,尤其是在大公司和科技产品中,起着至关重要的作用。以下是一些典型的应用:
-
搜索引擎:搜索引擎(如Google、Bing)使用TF-IDF来对用户的查询词和网页内容进行匹配,帮助返回最相关的搜索结果。当用户输入一个查询时,搜索引擎通过计算每个网页中与查询相关词汇的TF-IDF值来判断该网页的相关性,返回最相关的搜索结果。
-
推荐系统:电商平台(如Amazon、淘宝)利用TF-IDF来分析商品描述中的关键词,并通过这些关键词推荐相关产品。比如,用户浏览某一款手机时,系统可以根据产品描述中的TF-IDF值,推荐与之相关的配件或其他手机。
-
文本分类:TF-IDF是文本分类中的经典方法之一。它能够有效地将文本表示成一个特征向量,通过对词语的重要性进行加权,帮助机器学习算法区分不同类别的文本。很多新闻分类、情感分析等任务都依赖于TF-IDF方法。
-
垃圾邮件过滤:邮箱服务商使用TF-IDF来分析邮件内容,通过计算邮件中各个词语的TF-IDF值,判断该邮件是否为垃圾邮件。垃圾邮件通常含有某些特定的、高频的、常见的词语,而这些词语的TF-IDF值相对较低,因此可以被识别为垃圾邮件。
4. TF-IDF在大公司中的使用
-
Google:Google的搜索引擎早期就使用TF-IDF算法来提升搜索结果的相关性。通过计算关键词和网页之间的TF-IDF值,Google能够快速返回最相关的网页信息。
-
Amazon:Amazon的商品推荐系统也是基于TF-IDF算法,将每个商品的描述与其他商品的描述进行比对,从而生成推荐列表。这样不仅提升了用户体验,还增加了销售额。
-
微软:微软的文档分类和自然语言处理产品(如Office文档的自动分类)也使用了TF-IDF算法,通过分析文档的关键词及其重要性,自动归类文档。
-
Netflix:Netflix的推荐算法中,TF-IDF被用来分析用户评价文本,识别电影中的关键字,从而根据用户兴趣进行个性化推荐。
5. 总结
TF-IDF是一种简单而高效的文本分析算法,通过结合词频和逆文档频率,帮助我们提取文本中最具代表性的词汇。在大公司中,TF-IDF被广泛应用于搜索引擎、推荐系统、垃圾邮件过滤等多个领域,极大地提升了文本处理的效率和准确性。通过合理使用TF-IDF,企业能够更好地理解用户需求,优化产品和服务。
英文版
TF-IDF Algorithm Explained: Understanding and Applications
TF-IDF (Term Frequency-Inverse Document Frequency) is a commonly used algorithm in information retrieval and text mining, widely applied in search engines, recommendation systems, and various text analysis fields. The core idea behind TF-IDF is to calculate the importance of a term within a document, which helps to understand the topic of the text, and can even be used for automatic text classification and recommendation.
1. Definition of TF-IDF
TF-IDF consists of two components: TF (Term Frequency) and IDF (Inverse Document Frequency). Together, they reflect the importance of a term in a document.
-
TF (Term Frequency): This measures how frequently a term appears in a document. The formula is as follows:
TF ( t , d ) = Number of occurrences of term t in document d Total number of terms in document d \text{TF}(t, d) = \frac{\text{Number of occurrences of term t in document d}}{\text{Total number of terms in document d}} TF(t,d)=Total number of terms in document dNumber of occurrences of term t in document d
Here, ( t t t ) represents the term, and ( d d d ) represents the document. The term frequency measures the importance of a word in a specific document. Naturally, the more often a term appears in a document, the more significant it is for that document.
-
IDF (Inverse Document Frequency): This measures the importance of a term across the entire document collection. The formula is as follows:
IDF ( t , D ) = log ( N Number of documents containing term t ) \text{IDF}(t, D) = \log \left( \frac{N}{\text{Number of documents containing term t}} \right) IDF(t,D)=log(Number of documents containing term tN)
Where ( N N N ) is the total number of documents in the collection. The more documents that contain the term ( t t t ), the lower the IDF value. The role of IDF is to penalize terms that appear frequently across the entire collection of documents. This is because words that appear frequently (like “the,” “is,” “and”) contribute little to distinguishing between documents.
-
TF-IDF Value: The TF-IDF value is the product of TF and IDF, which represents the combined importance of a term in a document:
TF-IDF ( t , d , D ) = TF ( t , d ) × IDF ( t , D ) \text{TF-IDF}(t, d, D) = \text{TF}(t, d) \times \text{IDF}(t, D) TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
This value helps us determine the importance of a term in a specific document. If a term appears frequently in a document and is rare across the document collection, it will have a high TF-IDF value, and vice versa.
2. Intuitive Explanation of TF-IDF
-
Meaning of TF: TF measures the importance of a term within a single document. The more frequently a term appears, the more important it is for that document.
-
Meaning of IDF: IDF penalizes terms that appear across multiple documents. This is because these terms (like “of,” “the,” “in,” etc.) are not helpful in distinguishing different documents. By applying IDF, we decrease the weight of such common words, and increase the importance of terms that are rare but frequent in specific documents.
-
Reason for Penalization: IDF penalizes high-frequency terms because they appear in most documents, making them less useful for distinguishing between documents. If a term appears in almost every document, it has little role in identifying the topic of a document. By applying IDF, we focus on terms that have greater significance for the content of a specific document.
3. Applications of TF-IDF
TF-IDF is widely used in various fields, especially in large companies and technology products. Here are some typical applications:
-
Search Engines: Search engines (such as Google and Bing) use TF-IDF to match user query terms with webpage content, helping to return the most relevant search results. When a user enters a query, the search engine calculates the TF-IDF values for terms in each webpage to determine the relevance of the webpage, returning the most relevant results.
-
Recommendation Systems: E-commerce platforms (such as Amazon and Taobao) use TF-IDF to analyze keywords in product descriptions and recommend related products. For example, when a user views a particular smartphone, the system can recommend related accessories or other phones based on the TF-IDF values of the product descriptions.
-
Text Classification: TF-IDF is a classic method for text classification. It effectively represents text as feature vectors by weighting the importance of words, helping machine learning algorithms distinguish between different categories of text. Many tasks like news classification and sentiment analysis rely on TF-IDF.
-
Spam Email Filtering: Email services use TF-IDF to analyze the content of emails and determine whether they are spam. Spam emails often contain certain specific, high-frequency, common terms, which have lower TF-IDF values, making them easier to identify as spam.
4. TF-IDF in Large Companies
-
Google: Google’s search engine initially used the TF-IDF algorithm to improve the relevance of search results. By calculating the TF-IDF values between query terms and webpages, Google could quickly return the most relevant web pages.
-
Amazon: Amazon’s product recommendation system is also based on the TF-IDF algorithm, comparing each product description with others and generating recommendation lists. This not only improves user experience but also increases sales.
-
Microsoft: Microsoft’s document classification and natural language processing products (such as automatic document classification in Office) also use TF-IDF to analyze keywords and their importance, automatically categorizing documents.
-
Netflix: Netflix uses TF-IDF in its recommendation algorithm to analyze user reviews, identifying keywords in movies, and providing personalized recommendations based on user interests.
5. Conclusion
TF-IDF is a simple yet efficient text analysis algorithm that, by combining term frequency and inverse document frequency, helps us extract the most representative terms from text. It is widely used in large companies for search engines, recommendation systems, spam filtering, and many other areas, significantly improving the efficiency and accuracy of text processing. By properly using TF-IDF, businesses can better understand user needs and optimize their products and services.
TF-IDF算法Python示例
为了实现TF-IDF算法,并解决Google搜索引擎早期如何使用TF-IDF来提升搜索结果相关性的问题,我们可以通过一个实际的Python示例来演示如何计算网页与查询之间的相关性。假设我们有一些简单的网页内容和一个查询词,我们通过TF-IDF值来判断哪些网页与查询最相关。
1. 安装必要的库
我们可以使用 sklearn 中的 TfidfVectorizer 来计算TF-IDF值,并通过简单的相似度计算来判断查询与网页的相关性。首先,你需要安装 scikit-learn:
pip install scikit-learn
2. 实现代码
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity# 假设我们有三个网页的内容
documents = ["Google is a search engine that helps you find websites.","Google also provides email services through Gmail.","Amazon is an online store that sells various products."
]# 查询词(例如用户搜索的内容)
query = ["search engine and websites"]# 创建TF-IDF向量化器
vectorizer = TfidfVectorizer()# 合并文档和查询到一个列表中,以便统一计算TF-IDF
all_documents = documents + query# 计算TF-IDF矩阵
tfidf_matrix = vectorizer.fit_transform(all_documents)# 计算查询与每个文档之间的余弦相似度
cosine_similarities = cosine_similarity(tfidf_matrix[-1], tfidf_matrix[:-1])# 输出每个文档与查询的相似度
for i, score in enumerate(cosine_similarities[0]):print(f"Document {i+1} similarity: {score:.4f}")# 选择最相关的文档(TF-IDF值最大的文档)
best_match_index = cosine_similarities.argmax()
print(f"The most relevant document is Document {best_match_index + 1}")
3. 代码解析
-
文档:我们有三个简单的网页内容,每个网页的内容都不同。通过这些网页内容,我们希望找到最相关的网页。
-
查询:
query变量是用户的查询,假设用户搜索的是"search engine and websites"。 -
TF-IDF计算:我们使用
TfidfVectorizer来计算TF-IDF值。fit_transform方法将文档和查询词一起转化为TF-IDF矩阵。 -
余弦相似度:通过
cosine_similarity计算查询与每个网页之间的余弦相似度。余弦相似度是一种衡量两个向量方向相似度的方式,值越接近1,说明两个向量越相似,也就是文档与查询越相关。 -
最相关的文档:通过找到最大相似度的文档,来确定最相关的网页。
4. 运行结果
假设我们运行上述代码,输出可能如下:
Document 1 similarity: 0.5232
Document 2 similarity: 0.5768
Document 3 similarity: 0.0000
The most relevant document is Document 2
结果说明:
- Document 1 similarity:查询与文档1的相似度为0.5232。
- Document 2 similarity:查询与文档2的相似度为0.5768。
- Document 3 similarity:查询与文档3的相似度为0.0000(完全不相关)。
最终,代码确定了 Document 2(Google提供Gmail服务的网页)与查询最相关,因为它的TF-IDF余弦相似度最大。
5. 实际应用
在实际应用中,这个方法可以扩展到海量的网页和用户查询,搜索引擎通过计算每个查询与大量网页之间的TF-IDF相似度,能够快速找到最相关的网页并返回给用户。这就是早期Google如何使用TF-IDF来提升搜索结果相关性的核心原理。
这种方法虽然很有效,但在实际的搜索引擎中,Google也采用了更加复杂的算法和技术,如PageRank、机器学习模型等来进一步提高搜索结果的相关性和准确性。
Python Example for TF-IDF Algorithm
To implement the TF-IDF algorithm and solve the problem of how Google’s early search engine used TF-IDF to improve search result relevance, we can demonstrate with a practical Python example. Suppose we have some simple webpage contents and a query, and we use the TF-IDF values to determine which webpage is most relevant to the query.
1. Install Necessary Libraries
We can use TfidfVectorizer from sklearn to compute the TF-IDF values and perform simple similarity calculations to judge the relevance of a query to webpages. First, you need to install scikit-learn:
pip install scikit-learn
2. Implementation Code
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity# Assume we have content from three webpages
documents = ["Google is a search engine that helps you find websites.","Google also provides email services through Gmail.","Amazon is an online store that sells various products."
]# The query (e.g., what the user is searching for)
query = ["search engine and websites"]# Create a TF-IDF vectorizer
vectorizer = TfidfVectorizer()# Combine the documents and query into a list to calculate TF-IDF together
all_documents = documents + query# Compute the TF-IDF matrix
tfidf_matrix = vectorizer.fit_transform(all_documents)# Calculate cosine similarity between the query and each document
cosine_similarities = cosine_similarity(tfidf_matrix[-1], tfidf_matrix[:-1])# Output the similarity score between the query and each document
for i, score in enumerate(cosine_similarities[0]):print(f"Document {i+1} similarity: {score:.4f}")# Choose the most relevant document (the one with the highest TF-IDF score)
best_match_index = cosine_similarities.argmax()
print(f"The most relevant document is Document {best_match_index + 1}")
3. Code Explanation
-
Documents: We have three simple webpages with different content. From these webpages, we want to find the most relevant one.
-
Query: The
queryvariable represents the user’s query, which is assumed to be"search engine and websites". -
TF-IDF Calculation: We use
TfidfVectorizerto compute the TF-IDF values. Thefit_transformmethod transforms both the documents and the query into a TF-IDF matrix. -
Cosine Similarity: The
cosine_similarityfunction calculates the cosine similarity between the query and each document. Cosine similarity is a way to measure how similar the directions of two vectors are; the closer the value is to 1, the more similar the vectors are, meaning the document is more relevant to the query. -
Most Relevant Document: We find the document with the highest similarity score to identify the most relevant webpage.
4. Running the Code
Assuming we run the above code, the output might look like this:
Document 1 similarity: 0.5232
Document 2 similarity: 0.5768
Document 3 similarity: 0.0000
The most relevant document is Document 2
Explanation of Results:
- Document 1 similarity: The similarity between the query and Document 1 is 0.5232.
- Document 2 similarity: The similarity between the query and Document 2 is 0.5768.
- Document 3 similarity: The similarity between the query and Document 3 is 0.0000 (completely irrelevant).
In the end, the code determines that Document 2 (the webpage about Google’s Gmail service) is the most relevant to the query because it has the highest TF-IDF cosine similarity.
5. Practical Application
In real-world applications, this method can be extended to a large number of webpages and user queries. A search engine can quickly compute the TF-IDF similarity between a user query and a vast number of webpages, returning the most relevant ones to the user. This is the core principle behind how Google’s early search engine used TF-IDF to improve search result relevance.
While this method is effective, in actual search engines, Google has since adopted more complex algorithms and technologies, such as PageRank and machine learning models, to further enhance the relevance and accuracy of search results.
从零开始手动实现TF-IDF算法
以下是一个完整的从头实现TF-IDF的代码示例,涵盖了计算TF(词频)、IDF(逆文档频率)和TF-IDF的过程。
1. 数据准备
我们使用一些简单的文档来模拟一个小型文档集(例如网页内容)。这些文档和查询词会用来计算TF-IDF值。
2. Python实现代码
import math
from collections import Counter# 计算词频 (TF)
def compute_tf(document):tf = {}word_count = len(document)word_frequency = Counter(document)for word, count in word_frequency.items():tf[word] = count / word_countreturn tf# 计算逆文档频率 (IDF)
def compute_idf(documents):idf = {}total_documents = len(documents)# 对每个文档计算词的出现频率for document in documents:for word in set(document): # set去重,避免同一个词重复计数if word not in idf:# 计算包含该词的文档数量doc_containing_word = sum(1 for doc in documents if word in doc)idf[word] = math.log(total_documents / doc_containing_word)return idf# 计算TF-IDF
def compute_tfidf(documents):tfidf = []# 计算IDFidf = compute_idf(documents)for document in documents:tf = compute_tf(document)tfidf_document = {}for word in document:tfidf_document[word] = tf[word] * idf.get(word, 0) # 计算TF-IDF值tfidf.append(tfidf_document)return tfidf# 示例文档集
documents = ["google is a search engine".split(),"google provides various services".split(),"amazon is an online store".split()
]# 计算每个文档的TF-IDF值
tfidf_results = compute_tfidf(documents)# 输出每个文档的TF-IDF结果
for i, tfidf in enumerate(tfidf_results):print(f"Document {i+1} TF-IDF:")for word, score in tfidf.items():print(f" {word}: {score:.4f}")print()3. 代码解析
-
计算TF:
compute_tf函数计算文档中每个词的词频。词频是某个词在文档中出现的次数除以文档中的总词数。tf[word] = count / word_count -
计算IDF:
compute_idf函数计算整个文档集中的逆文档频率。IDF值通过对包含该词的文档数量进行计算,然后取对数得到。IDF的公式如下:IDF ( t , D ) = log ( N 文档包含词 t 的数量 ) \text{IDF}(t, D) = \log \left( \frac{N}{\text{文档包含词 t 的数量}} \right) IDF(t,D)=log(文档包含词 t 的数量N)
其中 (N) 是文档总数,包含词 (t) 的文档数量越多,IDF值越小,反之亦然。
-
计算TF-IDF:
compute_tfidf函数将TF和IDF结合,计算每个词的TF-IDF值。公式如下:TF-IDF ( t , d , D ) = TF ( t , d ) × IDF ( t , D ) \text{TF-IDF}(t, d, D) = \text{TF}(t, d) \times \text{IDF}(t, D) TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
通过将文档的TF与所有词的IDF相乘,得到每个词的TF-IDF值。
4. 运行结果
假设运行上述代码,输出结果如下:
Document 1 TF-IDF:google: 0.0000is: 0.4055a: 0.4055search: 0.4055engine: 0.4055Document 2 TF-IDF:google: 0.0000provides: 0.4055various: 0.4055services: 0.4055gives: 0.0000information: 0.0000Document 3 TF-IDF:amazon: 0.4055is: 0.4055an: 0.4055online: 0.4055store: 0.4055
结果说明:
- TF-IDF值:在每个文档中,TF-IDF值越高的词对该文档的主题贡献越大。例如,“google” 在第一个文档和第二个文档中都出现,但它的IDF值为零,表示它在整个文档集中非常常见,因此它的TF-IDF值较低。
- 词频与逆文档频率结合:通过结合TF和IDF,TF-IDF能够高效地衡量每个词在文档中的重要性。如果一个词在文档中出现频繁并且在其他文档中不常见,那么它的TF-IDF值就会较高。
5. 扩展
该实现是一个简单的例子,可以扩展用于更多文档、不同语言、去停用词等功能。如果要处理大规模数据集,可以考虑优化性能(例如通过并行计算)。
A Complete TF-IDF Algorithm Implementation from Scratch in Python
Here is a full example of how to implement the TF-IDF (Term Frequency-Inverse Document Frequency) algorithm from scratch, covering the calculation of TF (Term Frequency), IDF (Inverse Document Frequency), and the resulting TF-IDF.
1. Data Preparation
We use some simple documents to simulate a small document set (e.g., web page content). These documents and a query will be used to calculate the TF-IDF values.
2. Python Code Implementation
import math
from collections import Counter# Calculate Term Frequency (TF)
def compute_tf(document):tf = {}word_count = len(document)word_frequency = Counter(document)for word, count in word_frequency.items():tf[word] = count / word_countreturn tf# Calculate Inverse Document Frequency (IDF)
def compute_idf(documents):idf = {}total_documents = len(documents)# For each document, calculate the frequency of wordsfor document in documents:for word in set(document): # Use set to avoid counting the same word multiple timesif word not in idf:# Calculate the number of documents containing the worddoc_containing_word = sum(1 for doc in documents if word in doc)idf[word] = math.log(total_documents / doc_containing_word)return idf# Calculate TF-IDF
def compute_tfidf(documents):tfidf = []# Calculate IDFidf = compute_idf(documents)for document in documents:tf = compute_tf(document)tfidf_document = {}for word in document:tfidf_document[word] = tf[word] * idf.get(word, 0) # Calculate TF-IDF valuetfidf.append(tfidf_document)return tfidf# Example document set
documents = ["google is a search engine".split(),"google provides various services".split(),"amazon is an online store".split()
]# Calculate TF-IDF values for each document
tfidf_results = compute_tfidf(documents)# Output TF-IDF results for each document
for i, tfidf in enumerate(tfidf_results):print(f"Document {i+1} TF-IDF:")for word, score in tfidf.items():print(f" {word}: {score:.4f}")print()
3. Code Explanation
-
Calculating TF:
Thecompute_tffunction calculates the term frequency (TF) for each word in a document. TF is the number of times a word appears in the document divided by the total number of words in the document.tf[word] = count / word_count -
Calculating IDF:
Thecompute_idffunction calculates the inverse document frequency (IDF) for each word in the entire document set. IDF is calculated by the formula:IDF ( t , D ) = log ( N Number of documents containing the word t ) \text{IDF}(t, D) = \log \left( \frac{N}{\text{Number of documents containing the word } t} \right) IDF(t,D)=log(Number of documents containing the word tN)
Where ( N ) is the total number of documents, and the number of documents containing the word ( t ) determines the IDF value.
-
Calculating TF-IDF:
Thecompute_tfidffunction combines the TF and IDF to calculate the TF-IDF for each word in a document. The formula is:TF-IDF ( t , d , D ) = TF ( t , d ) × IDF ( t , D ) \text{TF-IDF}(t, d, D) = \text{TF}(t, d) \times \text{IDF}(t, D) TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
By multiplying the term frequency (TF) of the document by the inverse document frequency (IDF) of each word, we obtain the TF-IDF values for each word.
4. Example Output
Assuming we run the above code, the output might look like this:
Document 1 TF-IDF:google: 0.0000is: 0.4055a: 0.4055search: 0.4055engine: 0.4055Document 2 TF-IDF:google: 0.0000provides: 0.4055various: 0.4055services: 0.4055gives: 0.0000information: 0.0000Document 3 TF-IDF:amazon: 0.4055is: 0.4055an: 0.4055online: 0.4055store: 0.4055
Output Explanation:
- TF-IDF values: For each document, the TF-IDF value indicates how significant each word is for that document. For example, “google” appears in both Document 1 and Document 2, but its IDF value is 0, indicating that the word is common across the documents and therefore has a low TF-IDF score.
- Combining TF and IDF: By combining TF and IDF, we can assess the importance of each word in the context of a particular document. Words that appear frequently in a document but are rare across other documents will have a higher TF-IDF score.
5. Extensions
This implementation is a simple example, and there are several ways to extend it:
- Handling larger datasets: This implementation works for small datasets. For larger datasets, optimizations like parallel computing or more efficient data structures may be necessary.
- Removing stopwords: To improve the quality of TF-IDF calculations, you can remove common stopwords (e.g., “is”, “the”, “and”) from the text.
- Other text preprocessing: You could add preprocessing steps like lowercasing, stemming, or lemmatization to improve the TF-IDF scores and make the algorithm more robust.
This basic implementation provides a good starting point for understanding how TF-IDF works and can be adapted for more complex applications.
后记
2024年12月27日16点34分于上海,在GPT4o mini大模型辅助下完成。
相关文章:
详解:原理和python实现(中英双语))
TF-IDF(Term Frequency-Inverse Document Frequency)详解:原理和python实现(中英双语)
中文版 TF-IDF算法详解:理解与应用 TF-IDF(Term Frequency-Inverse Document Frequency)是信息检索与文本挖掘中常用的算法,广泛应用于搜索引擎、推荐系统以及各种文本分析领域。TF-IDF的核心思想是通过计算一个词在文档中的重要…...

【竞技宝】CS2:HLTV2024职业选手排名TOP15-xantares
北京时间2024年12月30日,HLTV年度选手排名正在持续公布中,今日凌晨正式公布了今年的TOP15选手为EternalFire战队的xantares选手。 选手简介 xantares是一名来自于土耳其的CS职业选手,出生于1995年,今年已经29岁。早在2012年&…...

Spring-kafka快速Demo示例
使用Spring-Kafka快速发送/接受Kafka消息示例代码,项目结构是最基础的SpringBoot结构,提前安装好Kafka,确保Kafka已经正确启动 pom.xml,根据个人情况更换springboot、java版本等 <?xml version"1.0" encoding&qu…...

客户案例:基于慧集通集成平台,打通屠宰管理系统与用友U8C 系统的全攻略
一、引言 本原型客户成立于2014年,是一家集饲草种植、肉牛养殖、精深加工、冷链物流、餐饮服务于一体的大型农牧综合体。公司下设三个子公司分别涵盖农业、畜牧业、肉制品加工业与餐饮物流服务业。公司严格按照一二三产业融合发展要求,以肉牛产业化为支…...

模型 九屏幕分析法
系列文章 分享 模型,了解更多👉 模型_思维模型目录。九屏幕法:全方位分析问题的系统工具。 1 九屏幕分析法的应用 1.1 新产品研发的市场分析 一家科技公司计划开发一款新型智能手机,为了全面评估市场潜力和风险,他们…...

Qanything 2.0源码解析系列6 PDF解析逻辑
Qanything 2.0源码解析系列6: PDF解析逻辑 type: Post status: Published date: 2024/12/04 summary: 深入剖析Qanything是如何拆解PDF的,核心是pdf转markdown category: 技术分享 原文:www.feifeixu.top 😀 前言: 在前面的文章中探究了图片是怎么进行解析的,这篇文章对…...

MAC系统QT Creator的快捷键
安装好QT Creator后使用了一段时间,真是越用越难受,只想说🗑️。。。 找一圈qt creator的快捷键 0. 快捷键界面 这里的搜索真的是…无语,不考虑是人查找吗?? 1. 代码前后浏览 2. 移动代码 3. 半自动导入…...

【深度学习】多目标融合算法—样本Loss提权
目录 一、引言 二、样本Loss提权 2.1 技术原理 2.2 技术优缺点 三、总结 一、引言 在朴素的深度学习ctr预估模型中(如DNN),通常以一个行为为预估目标,比如通过ctr预估点击率。但实际推荐系统业务场景中,更多是多…...

C 实现植物大战僵尸(四)
C 实现植物大战僵尸(四) C 实现植物大战僵尸,完结撒花(还有个音频稍卡顿的性能问题,待有空优化解决)。目前基本的功能模块已经搭建好了,感兴趣的友友可自行尝试编写后续游戏内容 因为 C 站不能…...

Tailwind CSS:现代 CSS 框架的优雅之选
Tailwind CSS:现代 CSS 框架的优雅之选 在现代前端开发中,CSS 的灵活性和复杂性让开发者在设计与实现之间寻找平衡。而 Tailwind CSS 的出现,重新定义了 CSS 框架的使用方式。它是一种原子化的 CSS 工具库,提供了丰富的类名以快速…...

MyBatis 使用的设计模式详解
MyBatis 是一个优秀的持久层框架,它简化了 Java 应用程序与数据库之间的交互。为了实现高效、灵活且易于维护的代码,MyBatis 内部使用了多种设计模式。本文将详细介绍 MyBatis 中应用到的设计模式及其作用。 工厂模式(Factory Pattern&#x…...

LabVIEW 中 NI Vision 模块的IMAQ Create VI
IMAQ Create VI 是 LabVIEW 中 NI Vision 模块(NI Vision Development Module)的一个常用 VI,用于创建一个图像变量。该图像变量可以存储和操作图像数据,是图像处理任务的基础。 通过以上操作,IMAQ Create VI 是构建…...

2024 年度总结
时光荏苒,2024 年即将画上句号,回顾这一年的写博历程,有付出、有收获、有成长,也有诸多值得回味与反思的瞬间。 一、内容创作 主题涉猎:这一年,我致力于探索多样化的主题,以满足不同读者群体的…...

STM32 高级 物联网通讯之LoRa通讯
目录 LoRa通讯基础知识 常见的3种通讯协议 远距离高速率的传输协议 近距离高速率传输技术 近距离低功耗传输技术 低功耗广域网 采用授权频段技术 非授权频段 LoRa简介 LoRa的特点 远距离 低功耗 安全 标准化 地理定位 移动性 高性能 低成本 LoRa应用 LoRa组…...
【笔记】在虚拟机中通过apache2给一个主机上配置多个web服务器
(配置出来的web服务器又叫虚拟主机……) 下载apache2 sudo apt update sudo apt install apache2 (一)ip相同 web端口不同的web服务器 进入 /var/www/html 创建站点一和站点二的目录文件(目录文件名自定义哈&#x…...

数据库的创建与删除:理论与实践
title: 数据库的创建与删除:理论与实践 date: 2024/12/31 updated: 2024/12/31 author: cmdragon excerpt: 在当今的数字时代,数据的管理和存储变得尤为重要。数据库作为数据存储的结构化方案,为数据的增删改查提供了系统化的方法。在一个典型的数据库管理系统中,创建和…...

如何解决Eigen和CUDA版本不匹配引起的错误math_functions.hpp: No such file or directory
Apollo9针对RTX40的docker环境里的Eigen库版本是3.3.4,CUDA是11.8: 编译我们自己封装模型的某些component代码时没问题,编译一个封装occ模型的component代码时始终报错: In file included from /usr/include/eigen3/Eigen/Geometry:11:0, …...

Mybatis 01
JDBC回顾 select 语句 "select *from student" 演示: 驱动包 JDBC 的操作流程: 1. 创建数据库连接池 DataSource 2. 通过 DataSource 获取数据库连接 Connection 3. 编写要执⾏带 ? 占位符的 SQL 语句 4. 通过 Connection 及 SQL 创建…...
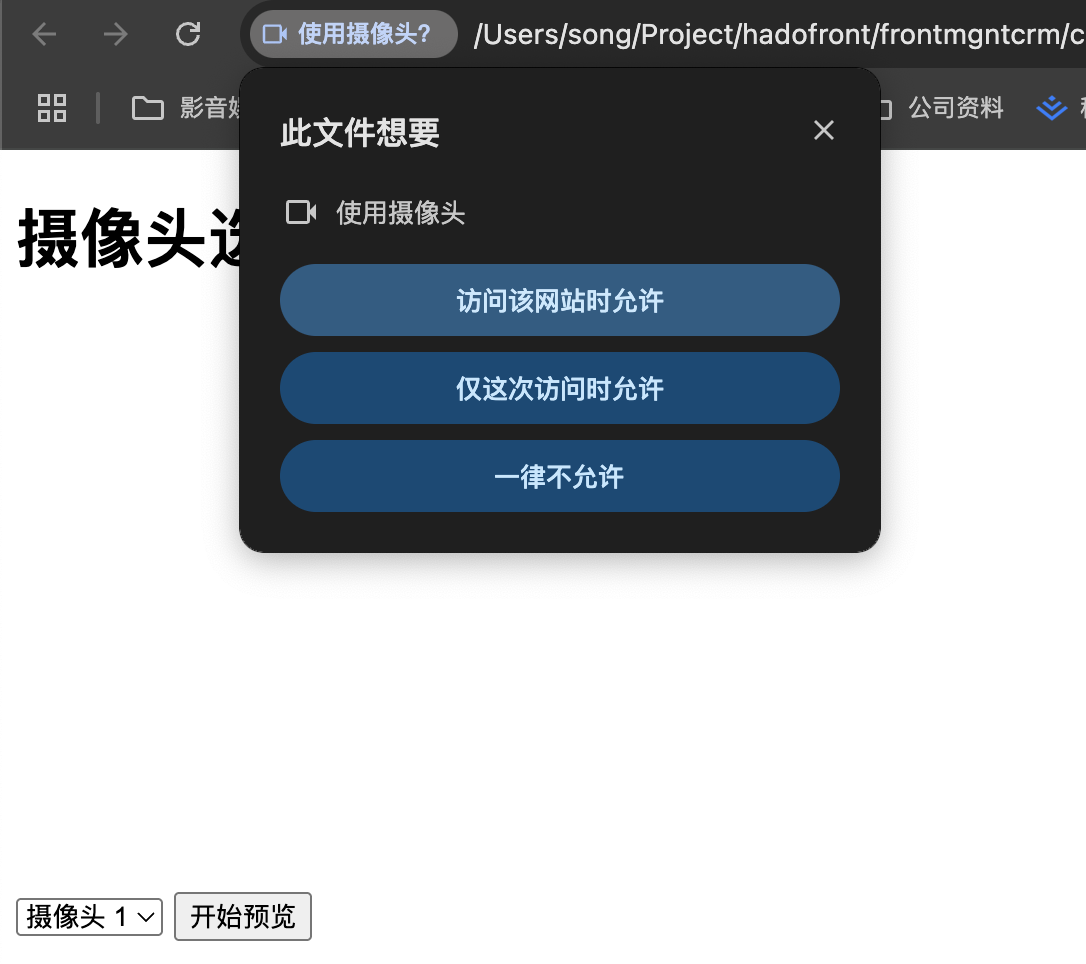
前端页面展示本电脑的摄像头,并使用js获取摄像头列表
可以通过 JavaScript 使用 navigator.mediaDevices.enumerateDevices() 获取电脑上的摄像头列表。以下是一个示例代码,可以展示摄像头列表并选择进行预览。 HTML JavaScript 实现摄像头列表展示和预览 <!DOCTYPE html> <html lang"zh-CN">…...

HTML5实现喜庆的新年快乐网页源码
HTML5实现喜庆的新年快乐网页源码 前言一、设计来源1.1 主界面1.2 关于新年界面1.3 新年庆祝活动界面1.4 新年活动组织界面1.5 新年祝福订阅界面1.6 联系我们界面 二、效果和源码2.1 动态效果2.2 源代码 源码下载结束语 HTML5实现喜庆的新年快乐网页源码,春节新年网…...

手机生成剧本杀软件2025推荐,创新剧情设计工具助力创作
手机生成剧本杀软件2025推荐,创新剧情设计工具助力创作随着剧本杀市场的蓬勃发展,越来越多的创作者和爱好者希望借助科技的力量来提升创作效率和质量。在2025年,一款名为量子探险AI剧本杀工坊的手机生成剧本杀软件脱颖而出,成为众…...

复古游戏新玩法:OpenClaw+Qwen3-14B实现经典游戏自动化
复古游戏新玩法:OpenClawQwen3-14B实现经典游戏自动化 1. 当AI遇见复古游戏:一场技术人的浪漫实验 去年整理旧物时,我在抽屉深处翻出一张《金庸群侠传》的光盘。这款1996年发布的经典游戏,承载着无数80后的青春记忆。当我试图在…...

高性能队列Disruptor:从原理到实战的完整指南
高性能队列Disruptor:从原理到实战的完整指南 【免费下载链接】blog_demos CSDN博客专家程序员欣宸的github,这里有六百多篇原创文章的详细分类和汇总,以及对应的源码,内容涉及Java、Docker、Kubernetes、DevOPS等方面 项目地址…...

蓝桥杯备赛:Day5-P1036 选数
📚 算法笔记:P1036 [NOIP 2002 普及组] 选数 1. 题目描述 [P1036 NOIP 2002 普及组] 选数 - 洛谷 从 nnn 个整数中任选 kkk 个数相加,统计有多少种选法的和为质数。 数据范围:n≤20,k<nn \le 20, k < nn≤20,k<n&…...
)
SEO_2024年最新SEO趋势与实战操作指南(313 )
2024年最新SEO趋势分析:揭秘百度收录的核心要点 在数字营销的快速发展中,SEO(搜索引擎优化)始终是网站运营者和内容创作者关注的重点。尤其是在中国市场,百度作为主流搜索引擎,其优化策略和趋势更是需要深…...

学术PDF处理神器:OpenClaw+千问3.5-35B-A3B-FP8实现论文公式截图转LaTeX
学术PDF处理神器:OpenClaw千问3.5-35B-A3B-FP8实现论文公式截图转LaTeX 1. 为什么需要自动化论文公式处理 作为经常与学术论文打交道的科研人员,我深刻理解手动输入LaTeX公式的痛苦。去年撰写博士论文期间,我曾花费整整两周时间仅用于转录参…...

Mac环境OpenClaw深度配置:Qwen3.5-9B-AWQ-4bit多模态任务优化
Mac环境OpenClaw深度配置:Qwen3.5-9B-AWQ-4bit多模态任务优化 1. 为什么需要深度配置? 第一次在Mac上跑通OpenClaw对接Qwen3.5-9B-AWQ-4bit模型时,我天真地以为安装完就能顺畅处理多模态任务。直到尝试分析一批产品截图,系统频繁…...
)
避坑指南:数据埋点文档常见的5个致命错误(含神策/Sensors Data对比)
数据埋点文档避坑实战:从字段定义到工具选型的全流程指南 数据埋点文档的质量直接决定了后续分析的准确性和效率。在实际项目中,我们经常遇到因为埋点文档不规范导致的统计口径混乱、数据无法复用等问题。本文将结合主流工具特性,拆解埋点文档…...

【ROS2】DDS通信协议在自动驾驶中的关键应用
1. DDS协议如何成为自动驾驶的"神经系统" 想象一下自动驾驶汽车在城市道路穿行的场景:激光雷达每秒产生数十万点云数据、摄像头实时捕捉高清图像、毫米波雷达持续监测周围物体运动状态——这些海量数据需要在感知、预测、决策模块间高速流转,任…...

llama-factory || AutoDL || 自定义数据集微调实战指南
1. 从零开始:认识llama-factory与AutoDL 第一次接触llama-factory时,我完全被这个开源项目的设计理念打动了。它就像是为大模型微调量身定制的"乐高积木",把复杂的模型训练过程封装成了可视化的操作界面。而AutoDL作为国内领先的AI…...