掌握大数据处理利器:Flink 知识点全面总结【上】
1.Flink的特点
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。

- 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
- 结果的准确性。Flink提供了事件时间(event--time)和处理时间(processing-time)语义。
- 精确一次(exactly-once)的状态一致性保证。
- 可以连接到最常用的外部系统,如Kafka、Hive、JDBC、HDFS、Redis等。
- 高可用。本身高可用的设置,加上与K8s,YARN和Mesos的紧密集成,再加上从故障中
2.分层API


有状态流处理:通过底层API〔处理函数),对最原始数据加工处理。底层API与DataStream API相集成,可以处理复杂的计算。
DataStream API(流处理)和DataSet API(批处理)封装了底层处理函数,提供了通用的模块,比如转换(transformations,包括map、flatmap等),连接(joins),聚合(aggregations),窗口(windows)操作等。注意:Flink1.l2以后,DataStream API已经实现真正的流批一体,所以DataSet API已经过时。
Table API是以表为中心的声明式编程,其中表可能会动态变化。Table API遵循关系模型:表有二维数据结构,类似于关系数据库中的表:同时API提供可比较的操作,例如select,project、join,group-by,aggregate等。我们可以在表与DataStream/DataSet之间无缝切换,以允许程序将Table API与DataStream以及DataSet混合使用。
SQL这一层在语法与表达能力上与Table API类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
3.流式数据,批量数据
批处理的特点是有界、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
而在flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。

无界数据流:
无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
有界数据流:
有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
4.单作业模式
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。

单作业模式,就是严格的一对一,集群只为这个作业而生。同样由客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。
这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
需要注意的是,Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如 YARN、Kubernetes。
5.并行度优先级

一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
Stream在算子之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。
- One-to-one:
stream(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着flatmap 算子的子任务看到的元素的个数以及顺序跟source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap等算子都是one-to-one的对应关系。类似于spark中的窄依赖
- Redistributing:
stream(map()跟keyBy/window之间或者keyBy/window跟sink之间)的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如,keyBy()基于hashCode重分区、broadcast和rebalance会随机重新分区,这些算子都会引起redistribute过程,而redistribute过程就类似于Spark中的shuffle过程。类似于spark中的宽依赖
并行度可以有如下几种指定方式
-
Operator Level(算子级别)(可以使用)
一个算子、数据源和sink的并行度可以通过调用 setParallelism()方法来指定

-
Execution Environment Level(Env级别)(可以使用)
执行环境(任务)的默认并行度可以通过调用setParallelism()方法指定。为了以并行度3来执行所有的算子、数据源和data sink, 可以通过如下的方式设置执行环境的并行度:执行环境的并行度可以通过显式设置算子的并行度而被重写

-
Client Level(客户端级别,推荐使用)(可以使用)
并行度可以在客户端将job提交到Flink时设定。
对于CLI客户端,可以通过-p参数指定并行度
./bin/flink run -p 10 WordCount-java.jar -
System Level(系统默认级别,尽量不使用)
在系统级可以通过设置flink-conf.yaml文件中的parallelism.default属性来指定所有执行环境的默认并行度
并行度的优先级:算子级别 > env级别 > Client级别 > 系统默认级别 (越靠前具体的代码并行度的优先级越高)
6.任务调度执行图
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)。


1)逻辑流图(StreamGraph)
这是根据用户通过 DataStream API编写的代码生成的最初的DAG图,用来表示程序的拓扑结构。这一步一般在客户端完成。
2)作业图(JobGraph)
StreamGraph经过优化后生成的就是作业图(JobGraph),这是提交给 JobManager 的数据结构,确定了当前作业中所有任务的划分。主要的优化为:将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。JobGraph一般也是在客户端生成的,在作业提交时传递给JobMaster。
我们提交作业之后,打开Flink自带的Web UI,点击作业就能看到对应的作业图。

3)执行图(ExecutionGraph)
JobMaster收到JobGraph后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。与JobGraph最大的区别就是按照并行度对并行子任务进行了拆分,并明确了任务间数据传输的方式。
4)物理图(Physical Graph)
JobMaster生成执行图后,会将它分发给TaskManager;各个TaskManager会根据执行图部署任务,最终的物理执行过程也会形成一张“图”,一般就叫作物理图(Physical Graph)。这只是具体执行层面的图,并不是一个具体的数据结构。
物理图主要就是在执行图的基础上,进一步确定数据存放的位置和收发的具体方式。有了物理图,TaskManager就可以对传递来的数据进行处理计算了。
7.转换算子
数据源读入数据之后,我们就可以使用各种转换算子,将一个或多个DataStream转换为新的DataStream。

基本转换算子
1. 映射(map)
map 是大家非常熟悉的大数据操作算子,主要用于将数据流中的数据进行转换,形成新的数据流。简单来说,就是一个“一 一映射”,消费一个元素就产出一个元素

我们只需要基于 DataStrema 调用 map()方法就可以进行转换处理。方法需要传入的参数是接口 MapFunction 的实现;返回值类型还是 DataStream。
public class TransMapTest {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));//1.自定义类,实现mapfunction接口SingleOutputStreamOperator<String> result1 = stream.map(new UserExtractor());// 2.传入匿名类,实现MapFunctionSingleOutputStreamOperator<String> result2 = stream.map(new MapFunction<Event, String>() {@Overridepublic String map(Event value) throws Exception {return value.user;}});//3.传入lambda表达式SingleOutputStreamOperator<String> result3 = stream.map(data -> data.user);result1.print();//result2.print();//result3.print();env.execute();}public static class UserExtractor implements MapFunction<Event, String> {@Overridepublic String map(Event value) throws Exception {return value.user;}}
}MapFunction 实现类的泛型类型,与输入数据类型和输出数据的类型有关。
在实现 MapFunction 接口的时候,需要指定两个泛型,分别是输入事件和输出事件的类型,还
需要重写一个 map()方法,定义从一个输入事件转换为另一个输出事件的具体逻辑。
2. 过滤(filter)
filter转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为true则元素正常输出,若为false则元素被过滤掉。

进行filter转换之后的新数据流的数据类型与原数据流是相同的。filter转换需要传入的参数需要实现FilterFunction接口,而FilterFunction内要实现filter()方法,就相当于一个返回布尔类型的条件表达式。
public class TransFilterTest {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));//1.传入实现filterfunction的自定义类SingleOutputStreamOperator<Event> result1 = stream.filter(new UserFilter());// 2.传入匿名类实现FilterFunctionSingleOutputStreamOperator<Event> result2 = stream.filter(new FilterFunction<Event>() {@Overridepublic boolean filter(Event e) throws Exception {return e.user.equals("Bob");}});//3.传入lambda表达式SingleOutputStreamOperator<Event> result3 = stream.filter(data -> data.user.equals("Bob"));result1.print();// result2.print();// result3.print();env.execute();}public static class UserFilter implements FilterFunction<Event> {@Overridepublic boolean filter(Event e) throws Exception {return e.user.equals("Mary");}}
}3. 扁平映射(flatMap))
flatMap 操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生 0 到多个元素。flatMap 可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理.

同 map 一样,flatMap 也可以使用 Lambda 表达式或者 FlatMapFunction 接口实现类的方式
来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。
public class TransFlatmapTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));//1.实现自定义的flatmapfunctionstream.flatMap(new MyFlatMap()).print("1");//2.传入lambda表达式stream.flatMap((Event value,Collector<String> out)-> {if (value.user.equals("Marry"))out.collect(value.url);else if(value.user.equals("Bob"))out.collect(value.user);out.collect(value.url);out.collect(value.timestamp.toString());}).returns(new TypeHint<String>() {}).print("2");env.execute();}public static class MyFlatMap implements FlatMapFunction<Event, String> {@Overridepublic void flatMap(Event value, Collector<String> out) throws Exception {out.collect(value.user);out.collect(value.url);out.collect(value.timestamp.toString());}}}
flatMap 操作会应用在每一个输入事件上面,FlatMapFunction 接口中定义了 flatMap 方法,
用户可以重写这个方法,在这个方法中对输入数据进行处理,并决定是返回 0 个、1 个或多个
结果数据。因此 flatMap 并没有直接定义返回值类型,而是通过一个“收集器”(Collector)来
指定输出。希望输出结果时,只要调用收集器的.collect()方法就可以了;这个方法可以多次调
用,也可以不调用。所以 flatMap 方法也可以实现 map 方法和 filter 方法的功能,当返回结果
是 0 个的时候,就相当于对数据进行了过滤,当返回结果是 1 个的时候,相当于对数据进行了
简单的转换操作。
聚合算子(Aggregation)
1. 按键分区(keyBy)
对于Flink而言,DataStream是没有直接进行聚合的API的。因为我们对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在Flink中,要做聚合,需要先进行分区;这个操作就是通过keyBy来完成的。
keyBy是聚合前必须要用到的一个算子。keyBy通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务。
基于不同的key,流中的数据将被分配到不同的分区中去;这样一来,所有具有相同的key的数据,都将被发往同一个分区。

2. 简单聚合
有了按键分区的数据流KeyedStream,我们就可以基于它进行聚合操作了。Flink为我们内置实现了一些最基本、最简单的聚合API,主要有以下几种:
- sum():在输入流上,对指定的字段做叠加求和的操作。
- min():在输入流上,对指定的字段求最小值。
- max():在输入流上,对指定的字段求最大值。
- minBy():与min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而minBy()则会返回包含字段最小值的整条数据。
- maxBy():与max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
简单聚合算子使用非常方便,语义也非常明确。这些聚合方法调用时,也需要传入参数;但并不像基本转换算子那样需要实现自定义函数,只要说明聚合指定的字段就可以了。指定字段的方式有两种:指定位置,和指定名称。
public class TransformSimpleAggTest {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice","./prod?id=100", 3000L),new Event("Bob","./prod?id=1", 3300L),new Event("Bob", "./home", 3500L),new Event("Alice","./prod?id=200", 3200L),new Event("Bob","./prod?id=2", 3800L),new Event("Bob","./prod?id=3", 4200L));// 按键分组之后进行聚合,提取当前用户最后一次访问数据stream.keyBy(new KeySelector<Event, String>() {@Overridepublic String getKey(Event value) throws Exception {return value.user;}}).max("timestamp").print("max:");stream.keyBy(data -> data.user).maxBy("timestamp").print("maxBy:");env.execute();}
}
3. 归约聚合(reduce)
与简单聚合类似,reduce 操作也会将 KeyedStream 转换为 DataStream。它不会改变流的元素数据类型,所以输出类型和输入类型是一样的。
调用 KeyedStream 的 reduce 方法时,需要传入一个参数,实现 ReduceFunction 接口。接口在源码中的定义如下:
public interface ReduceFunction<T> extends Function, Serializable {
T reduce(T value1, T value2) throws Exception;
}
ReduceFunction 接口里需要实现 reduce()方法,这个方法接收两个输入事件,经过转换处理之后输出一个相同类型的事件;所以,对于一组数据,我们可以先取两个进行合并,然后再将合并的结果看作一个数据、再跟后面的数据合并,最终会将它“简化”成唯一的一个数据,这也就是 reduce“归约”的含义。在流处理的底层实现过程中,实际上是将中间“合并的结果”作为任务的一个状态保存起来的;之后每来一个新的数据,就和之前的聚合状态进一步做归约。
public class TransformReduceTest {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice","./prod?id=100", 3000L),new Event("Bob","./prod?id=1", 3300L),new Event("Alice","./prod?id=200", 3200L),new Event("Bob", "./home", 3500L),new Event("Bob","./prod?id=2", 3800L),new Event("Bob","./prod?id=3", 4200L));//1. 统计每个用户的访问频次SingleOutputStreamOperator<Tuple2<String, Long>> clicksByUser = stream.map(new MapFunction<Event, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> map(Event value) throws Exception {return Tuple2.of(value.user, 1L);}}).keyBy(data -> data.f0).reduce(new ReduceFunction<Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {return Tuple2.of(value1.f0, value1.f1 + value2.f1);}});//2. 选取当前最活跃的用户SingleOutputStreamOperator<Tuple2<String, Long>> result = clicksByUser.keyBy(data -> "key").reduce(new ReduceFunction<Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {return value1.f1 > value2.f1 ? value1 : value2;}});result.print();env.execute();}
}
8.输出算子sink
连接到外部系统
Flink作为数据处理框架,最终还是要把计算处理的结果写入外部存储,为外部应用提供支持。

Flink的DataStream API专门提供了向外部写入数据的方法:addSink。与addSource类似,addSink方法对应着一个“Sink”算子,主要就是用来实现与外部系统连接、并将数据提交写入的;Flink程序中所有对外的输出操作,一般都是利用Sink算子完成的。
Sink 一词有“下沉”的意思,有些资料会相对于“数据源”把它翻译为“数据汇”。不论怎样理解,Sink 在 Flink 中代表了将结果数据收集起来、输出到外部的意思,所以我们这里统一把它直观地叫作“输出算子”。
与 Source 算子非常类似,除去一些 Flink 预实现的 Sink,一般情况下 Sink 算子的创建是通过调用 DataStream 的.addSink()方法实现的。
stream.addSink(new SinkFunction(…));
addSource 的参数需要实现一个 SourceFunction 接口;类似地,addSink 方法同样需要传入一个参数,实现的是 SinkFunction 接口。在这个接口中只需要重写一个方法 invoke(),用来将指定的值写入到外部系统中。这个方法在每条数据记录到来时都会调用:
default void invoke(IN value, Context context) throws Exception
SinkFuntion 多数情况下同样并不需要我们自己实现。Flink 官方提供了一部分的框架的 Sink 连接器。
列出了 Flink 官方目前支持的第三方系统连接器:

除 Flink 官方之外,Apache Bahir 作为给 Spark 和 Flink 提供扩展支持的项目,也实现了一些其他第三方系统与 Flink 的连接器:

除此以外,就需要用户自定义实现 sink 连接器了。
输出到文件
Flink 为此专门提供了一个流式文件系统的连接器:StreamingFileSink,它继承自抽象类RichSinkFunction,而且集成了 Flink 的检查点(checkpoint)机制,用来保证精确一次(exactly once)的一致性语义。
StreamingFileSink 为批处理和流处理提供了一个统一的 Sink,它可以将分区文件写入 Flink支持的文件系统。它可以保证精确一次的状态一致性,大大改进了之前流式文件 Sink 的方式。它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶”的操作;默认的分桶方式是基于时间的,我们每小时写入一个新的桶。换句话说,每个桶内保存的文件,记录的都是 1 小时的输出数据。
StreamingFileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如 Parquet)格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用StreamingFileSink 的静态方法:
public class SinkToFileTest {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(4);DataStream<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice", "./prod?id=100", 3000L),new Event("Bob", "./prod?id=1", 3300L),new Event("Alice", "./prod?id=300", 3200L),new Event("Bob", "./home", 3500L),new Event("Bob", "./prod?id=2", 3800L),new Event("Bob", "./prod?id=3", 4200L));StreamingFileSink<String> fileSink = StreamingFileSink.<String>forRowFormat(new Path("./output"),new SimpleStringEncoder<>("UTF-8")).withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(TimeUnit.MINUTES.toMillis(15)).withInactivityInterval(TimeUnit.MINUTES.toMillis(5)).withMaxPartSize(1024 * 1024 * 1024).build()).build();// 将Event转换成String写入文件stream.map(data -> data.toString()).addSink(fileSink);env.execute();}
}输出到Kafka
我们要将数据输出到 Kafka,整个数据处理的闭环已经形成,所以可以完整测试如下:
(1)添加 Kafka 连接器依赖
由于我们已经测试过从 Kafka 数据源读取数据,连接器相关依赖已经引入,这里就不重复
介绍了。
(2)启动 Kafka 集群
(3)编写输出到 Kafka 的示例代码
1.启动zookeeper
命令:bin/zkServer.sh start
2.启动kafka
命令:bin/kafka-server-start.sh -daemon config/server.properties
3.创建生产者
命令:./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic clicks
addSink 传入的参数是一个 FlinkKafkaProducer。这也很好理解,因为需要向 Kafka 写入数据,自然应该创建一个生产者。FlinkKafkaProducer 继承了抽象类TwoPhaseCommitSinkFunction,这是一个实现了“两阶段提交”的 RichSinkFunction。两阶段提交提供了 Flink 向 Kafka 写入数据的事务性保证,能够真正做到精确一次(exactly once)的状态一致性。
4. 运行代码,另开启一个master01窗口,启动一个消费者, 查看是否收到数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic events
public class SinkToKafkaTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);Properties properties = new Properties();properties.put("bootstrap.servers", "master01:9092");DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>("clicks",new SimpleStringSchema(),properties));SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {String[] fields = value.split(",");return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();}});result.addSink(new FlinkKafkaProducer<String>("master01:9092", "events", new SimpleStringSchema()));env.execute();}
}结果:

2025年的第一天我居然还在复习【枯死】
新的一年,梦虽遥,追则能达。愿虽艰,持则可圆。祝大家所愿皆所成,多喜乐,长安宁。
相关文章:
掌握大数据处理利器:Flink 知识点全面总结【上】
1.Flink的特点 Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。 Flink主要特点如下: 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。结果的准确性。Flink提供了事件时间(event--time)和处理时间(proces…...

人工智能知识分享第四天-线性回归
线性回归 线性回归介绍 线性回归概念 线性回归(Linear regression)是利用 回归方程(函数) 对 一个或多个自变量(特征值)和因变量(目标值)之间 关系进行建模的一种分析方式。 注意事项: 1 为什么叫线性模型?因为求解的w,都是w的零次幂&am…...

Appium 2.0:移动自动化测试的革新之旅
关注开源优测不迷路 大数据测试过程、策略及挑战 测试框架原理,构建成功的基石 在自动化测试工作之前,你应该知道的10条建议 在自动化测试中,重要的不是工具 在移动应用开发的领域中,Appium 作为一款强大的自动化测试工具…...

牛客网最新1129道 Java 面试题及答案整理
前言 面试,跳槽,每天都在发生,而对程序员来说"金三银四"更是面试和跳槽的高峰期,跳槽,更是很常见的,对于每个人来说,跳槽的意义也各不相同,可能是一个人更向往一个更大的…...
:自定义 Publisher 和 Subscriber)
Swift Combine 学习(六):自定义 Publisher 和 Subscriber
Swift Combine 学习(一):Combine 初印象Swift Combine 学习(二):发布者 PublisherSwift Combine 学习(三):Subscription和 SubscriberSwift Combine 学习(四&…...

Vue-router知识点汇总
import Vue from vue import Router from vue-router Vue.use(Router) import Layout from /layout export const constantRoutes [{path: /forgetpsd,name: forgetPsd,// 命名路由 ,跳转<router-link :to"{ name: forgetPsdr, params: { userId: 123 }}&q…...
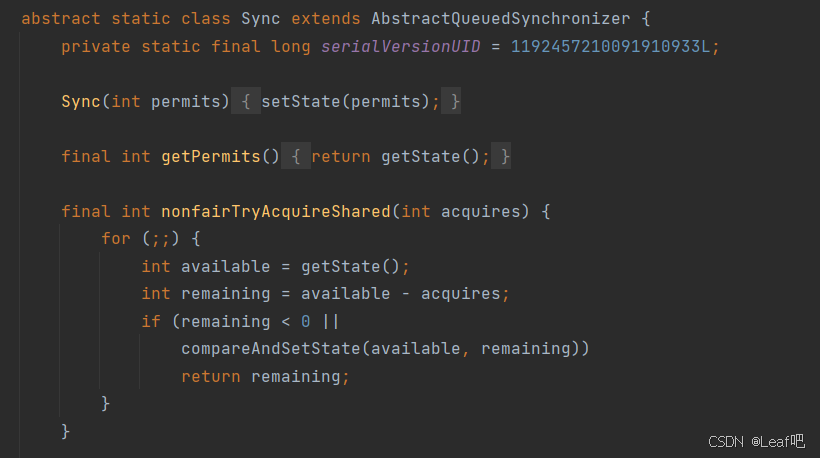
java AQS
什么是AQS AQS(AbstractQueuedSynchronizer,抽象队列同步器)是 Java 中并发控制的一种机制,位于 java.util.concurrent.locks 包下,它为构建锁、信号量等同步工具提供了一个框架。AQS 通过 队列 来管理多个线程之间的…...
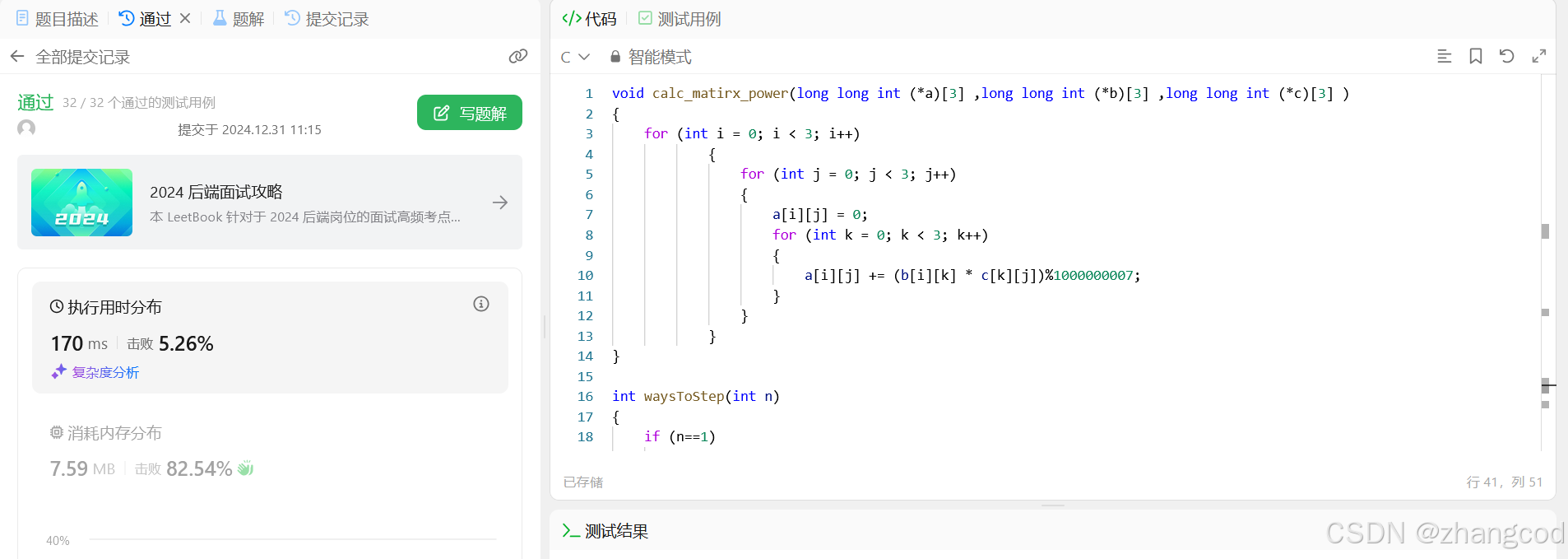
L25.【LeetCode笔记】 三步问题的四种解法(含矩阵精彩解法!)
目录 1.题目 2.三种常规解法 方法1:递归做 编辑 方法2:改用循环做 初写的代码 提交结果 分析 修改后的代码 提交结果 for循环的其他写法 提交结果 方法3:循环数组 提交结果 3.方法4:矩阵 算法 代码实践 1.先计算矩阵n次方 2.后将矩阵n次方嵌入递推式中 提…...

sdut-C语言实验-合数分解
sdut-C语言实验-合数分解 分数 12 全屏浏览 切换布局 作者 马新娟 单位 山东理工大学 合数是指在大于1的整数中,除了1和本身外,还能被其他数整除的数。例如,4、6、8、9、10等都是合数。把一个合数分解成若干个质因数乘积的形式(即求质因…...

深入理解 pytest Fixture 方法及其应用
在 Python 自动化测试领域,pytest 是当之无愧的王者。提到 pytest,不得不说它的一大核心功能——Fixture。Fixture 的强大,让复杂的测试流程变得井井有条,让测试代码更加灵活和可复用。 那么,pytest 的 Fixture 究竟是…...

在Linux上获取MS(如Media Server)中的RTP流并录制为双轨PCM格式的WAV文件
在Linux上获取MS(如Media Server)中的RTP流并录制为双轨PCM格式的WAV文件 一、RTP流与WAV文件格式二、实现步骤三、伪代码示例四、C语言示例代码五、关键点说明六、总结在Linux操作系统上,从媒体服务器(如Media Server,简称MS)获取RTP(Real-time Transport Protocol)流…...
Midjourney技术浅析(八):交互与反馈
Midjourney 的用户交互与反馈通过用户输入(User Input)和用户反馈(User Feedback)机制,不断优化和改进图像生成的质量和用户满意度。 一、用户交互与反馈模块概述 用户交互与反馈模块的主要功能包括: 1.…...
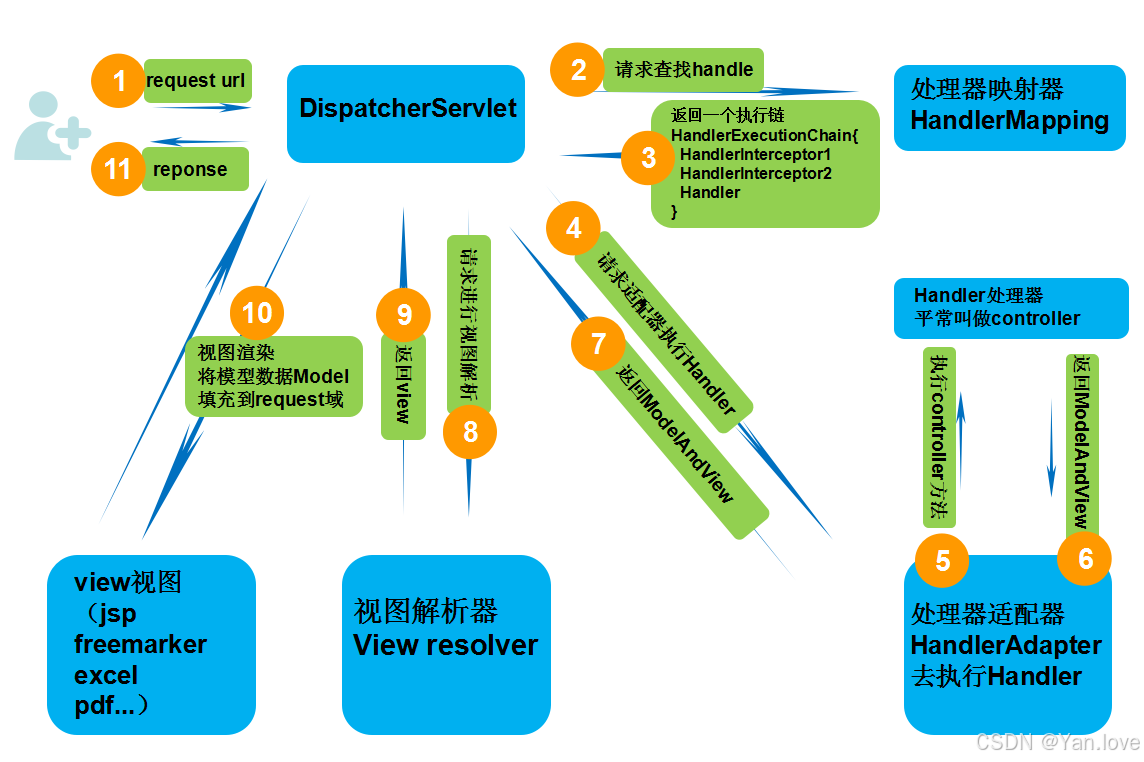
【Spring MVC 核心机制】核心组件和工作流程解析
在 Web 应用开发中,处理用户请求的逻辑常常会涉及到路径匹配、请求分发、视图渲染等多个环节。Spring MVC 作为一款强大的 Web 框架,将这些复杂的操作高度抽象化,通过组件协作简化了开发者的工作。 无论是处理表单请求、生成动态页面&#x…...
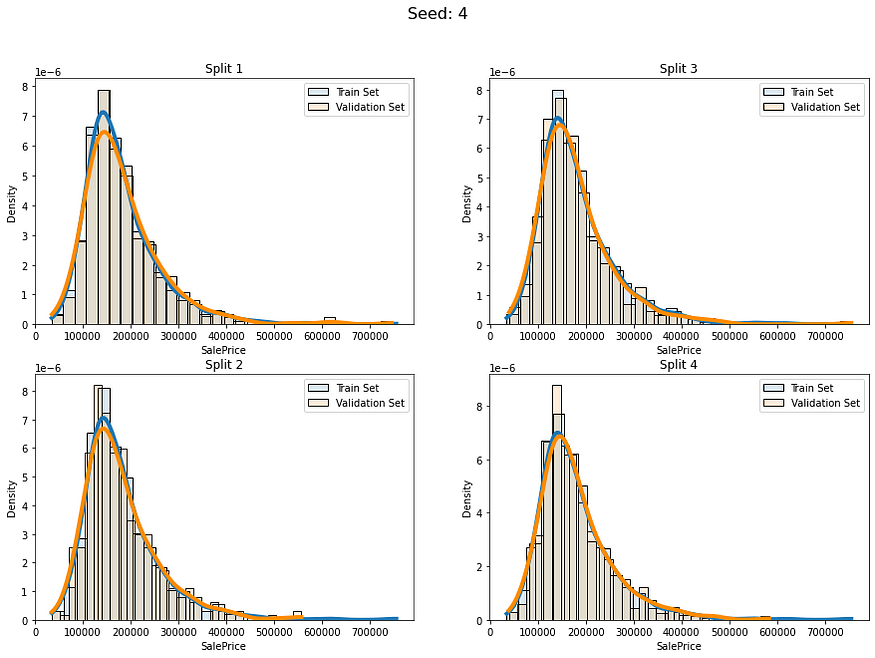
回归问题的等量分层
目录 一、说明 二、什么是分层抽样? 三、那么回归又如何呢? 四、回归分层(Stratification on Regression) 一、说明 在同一个数据集中,我们可以看成是一个抽样体。然而,我们如果将这个抽样体分成两份&#…...
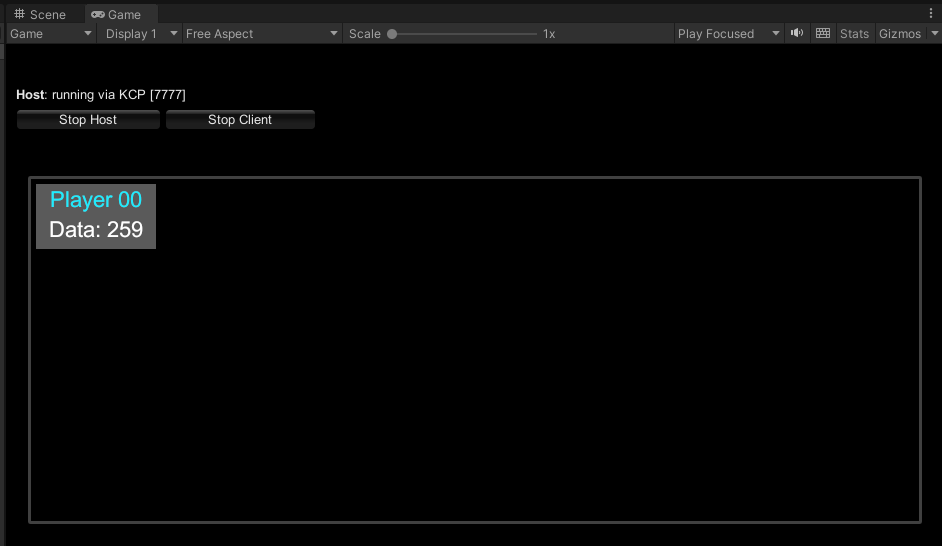
Unity-Mirror网络框架-从入门到精通之Basic示例
文章目录 前言Basic示例场景元素预制体元素代码逻辑BasicNetManagerPlayer逻辑SyncVars属性Server逻辑Client逻辑 PlayerUI逻辑 最后 前言 在现代游戏开发中,网络功能日益成为提升游戏体验的关键组成部分。Mirror是一个用于Unity的开源网络框架,专为多人…...

CSS 图片廊:网页设计的艺术与技巧
CSS 图片廊:网页设计的艺术与技巧 引言 在网页设计中,图片廊是一个重要的组成部分,它能够以视觉吸引的方式展示图片集合,增强用户的浏览体验。CSS(层叠样式表)作为网页设计的主要语言之一,提供…...

AI 发展的第一驱动力:人才引领变革
在科技蓬勃发展的当下,AI 成为了时代的焦点,然而其发展并非一帆风顺,究竟什么才是推动 AI 持续前行的关键力量呢? 目录 AI 发展现状剖析 期望与现实的落差 落地困境根源 人才:AI 发展的核心动力编辑 技术突破的…...
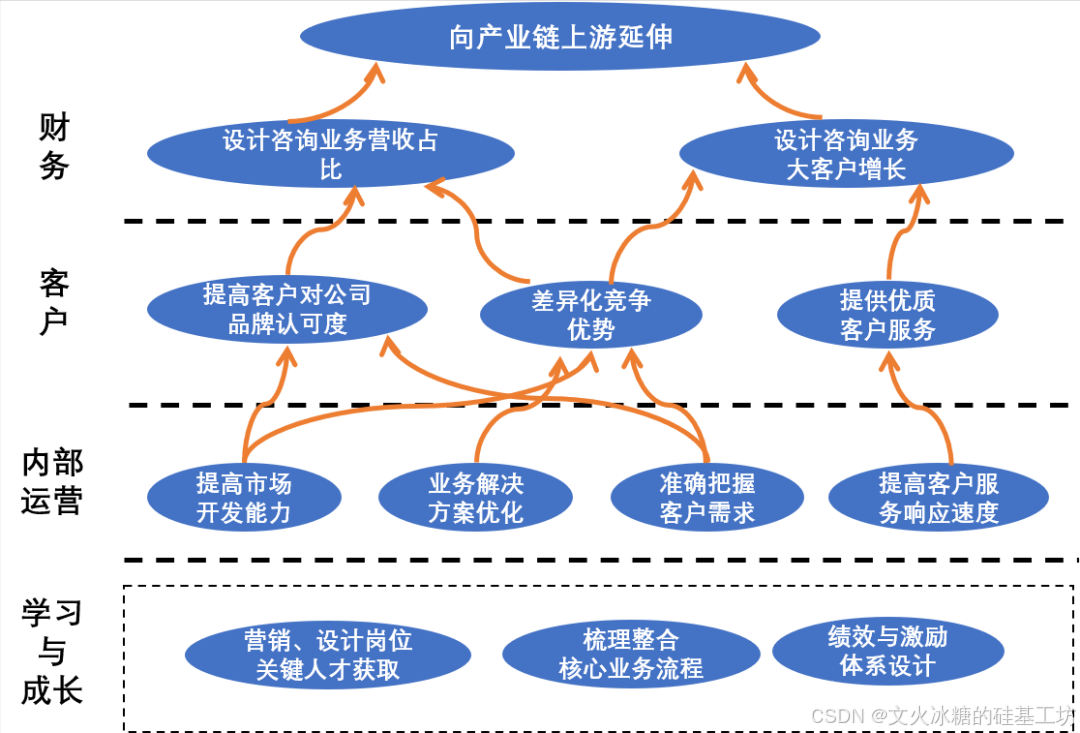
[创业之路-229]:《华为闭环战略管理》-5-平衡记分卡与战略地图
目录 一、平衡记分卡 1. 财务角度: 2. 客户角度: 3. 内部运营角度: 4. 学习与成长角度: 二、BSC战略地图 1、核心内容 2、绘制目的 3、绘制方法 4、注意事项 一、平衡记分卡 平衡记分卡(Balanced Scorecard&…...
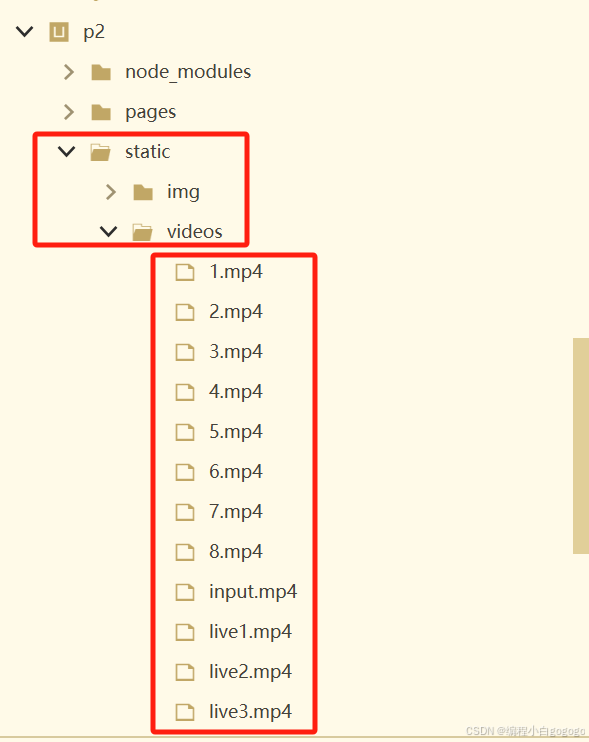
用uniapp写一个播放视频首页页面代码
效果如下图所示 首页有导航栏,搜索框,和视频列表, 导航栏如下图 搜索框如下图 视频列表如下图 文件目录 视频首页页面代码如下 <template> <view class"video-home"> <!-- 搜索栏 --> <view class…...

【视觉SLAM:八、后端Ⅰ】
视觉SLAM的后端主要解决状态估计问题,它是优化相机轨迹和地图点的过程,从数学上看属于非线性优化问题。后端的目标是结合传感器数据,通过最优估计获取系统的状态(包括相机位姿和场景结构),在状态估计过程中…...

开关电源功率因数校正:从谐波失真到PFC电路设计实践
1. 项目概述:从“相移”到“失真”,理解开关整流器的功率因数挑战在通信、数据中心乃至我们日常使用的各类开关电源适配器中,高频开关整流器是电能转换的核心。作为一名电源工程师,我经常被问到:“为什么我们设备的输入…...

米尔RK3562开发板深度评测:工业边缘AI网关的性价比之选
1. 项目概述:为什么关注米尔RK3562开发板?最近在给一个工业边缘计算项目选型,核心需求是在一个环境相对严苛的车间里,部署一个集成了视觉识别、多路传感器数据采集和本地轻量级推理的网关设备。性能不能太弱,否则处理不…...
)
保姆级教程:用Sen2Cor批量处理Sentinel-2 L1C到L2A(Win/Linux通用,附避坑清单)
遥感数据处理实战:Sen2Cor高效批量处理Sentinel-2 L1C至L2A全流程指南 当面对数百景Sentinel-2 L1C数据需要转换为L2A级别时,手动逐景处理不仅效率低下,还容易因操作失误导致数据不一致。本文将分享一套经过实际项目验证的批处理方案…...

影刀RPA跨境店群运营架构:Python协同Chromium底层调度与高并发容器化架构
定了。在这场旷日持久的跨境电商反爬风控拉锯战中,我们终于用一套基于 Python 深度协同的分布式微服务调度架构,重塑了跨境千店矩阵的自动化底座。 这几天,科技圈被“DeepSeek V4 首发华为昇腾芯片,国产 AI 开始打破英伟达 CUDA …...

用AnyLogic 8.8.1复现地铁站客流仿真:从行人流线到安检流程的保姆级建模
用AnyLogic 8.8.1构建地铁站客流仿真:从零到一的实战指南 地铁站作为城市交通枢纽,其客流管理效率直接影响数百万人的出行体验。AnyLogic作为多方法仿真平台,能精准模拟行人流线与服务设施交互。本文将基于8.8.1版本,手把手构建包…...

CSP认证202305-1题保姆级攻略:用C++的map轻松搞定国际象棋局面去重
CSP认证202305-1题深度解析:从字符串处理到STL高效去重 国际象棋对局中的局面重复判定是一个经典的字符串处理问题,也是CSP认证考试中常见的题型。这道题看似简单,却蕴含了算法选择与数据结构应用的核心思想。本文将带您从题目分析、解法对比…...

3步打造智能设计转换桥梁:从Figma到Unity的无缝对接方案
3步打造智能设计转换桥梁:从Figma到Unity的无缝对接方案 【免费下载链接】UnityFigmaBridge Easily bring your Figma Documents, Components, Assets and Prototypes to Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityFigmaBridge 在现代游戏开发…...

大模型应用开发指南:从入门到实践,收藏这份从Demo到生产落地的完整攻略
本文分享了AI应用开发中从Demo到生产落地的完整实践,涵盖技术选型、架构设计、核心算法优化及部署经验。通过LangGraph、RAGFlow和Langfuse等工具,解决上下文超限、Prompt管理混乱等问题,最终实现准确率提升25%的工业级AI系统。适合程序员和小…...

5分钟快速上手SignTools:自托管iOS应用签名平台完整教程
5分钟快速上手SignTools:自托管iOS应用签名平台完整教程 【免费下载链接】SignTools ✒ A free, self-hosted platform to sideload iOS apps without a computer 项目地址: https://gitcode.com/gh_mirrors/si/SignTools 想要在iOS设备上自由安装第三方应用…...

从Pikachu靶场看CSRF Token防护:为什么你的Token机制可能被绕过?聊聊设计缺陷与加固思路
从Pikachu靶场看CSRF Token防护:为什么你的Token机制可能被绕过?聊聊设计缺陷与加固思路 在Web安全领域,CSRF(跨站请求伪造)攻击一直是开发者需要重点防范的威胁之一。而CSRF Token作为最常用的防护手段,其…...